1. Introduction
The distributed assembly scheduling problem is a derivative and extension of the assembly scheduling problems. It is mainly used to produce multiple products assembled from different parts. In a decentralized and globalized economy, the current economic trend of customization and intelligent manufacturing has led to the rapid development of assembly production. Internationally, international companies with multiple production centers or plants are even more common. This shows that distributed and intelligent production plays a pivotal and irreplaceable role in the modern manufacturing industry. Currently, this type of scheduling is widely used in the supply chain and manufacturing industry. In order to maintain a competitive position in a rapidly changing market, managers must quickly make the right decisions about how to allocate work to plants and how to schedule each plant efficiently. Therefore, the distributed scheduling problem has become a hot research topic among scholars and researchers.
The distributed assembly permutation flowshop scheduling problem (DAPFSP) is of great importance to both the industrial industry and the research community. As we all know, DAPFSP consists of two phases, including production and assembly. In detail, the production phase corresponds to a distributed displacement flowshop scheduling problem, where n jobs are assigned to be processed in f plants with m identical machines in a flowshop line. Each job belongs to a certain product. The processes contained in each product cannot be interrupted or inserted by processes of other products during the production process. The assembly phase corresponds to the assembly flow shop scheduling problem, where s products are made in an assembly plant with a single assembly machine, and each product must be assembled after all processes produced in the production phase are completed.
Total completion time has been identified as a more relevant and meaningful goal in today’s dynamic manufacturing environment when a batch of work needs to be completed as quickly as possible. This allows the objective function to minimize the flow of work and efficiently improve resource utilization. DPFSP is an NP-hard with
m greater than or equal to 2, and is a derivation and extension of the traditional permutation flow shop scheduling problem with this criterion. Similarly, DAPFSP can be seen as an extension of DPFSP, which is more complex than DPFSP. Therefore, the DAPFSP with completion time as the objective function is also a strong NP-hard problem. In recent years, as a simple yet efficient method, the bat algorithm has solved many scheduling problems in academia, including the job shop scheduling problem [
1], the open shop scheduling problem [
2], the task scheduling problem [
3], and the production scheduling problem [
4], by continuously performing local search in the neighborhood of the current solution to obtain the optimal solution.
In this paper, an improved hybrid bat algorithm, IHBA, is proposed for solving the DAPFSP with maximum makespan based on the original bat algorithm. The main contributions of this paper are:
The algorithm firstly designs the population classification to increase the diversity of the population and solve the difficult trade-off between convergence and diversity of the bat algorithm.
A selection mechanism is used to update the speed and location of bats, solving the difficulty of the algorithm to trade-off exploration and mining capacity.
Gaussian learning strategy and elite learning strategy assist the whole population to jump out of the local optimal frontier.
This paper is organized as described below.
Section 2 reviews the closely related literature.
Section 3 presents the DAPFSP problem and its mathematical model. In
Section 4, the hybrid bat algorithm proposed in this paper is described in detail. In addition, the parameter calibration and simulation calculation results are analyzed in
Section 5. In the last section, the paper is summarized, and future work is provided.
2. Literature Review
It is well known that the distributed permutation flowshop scheduling problem (PFSP) is one of the most well-known production scheduling problems. It has a strong engineering background by having the same work order on all machines. The problem has been shown to be a strong NP-hard problem when more than two machines are involved.The problem of distributed assembly permutation flowshop scheduling problem (DAPFSP) has been gaining attention and popularity among scholars and researchers. The most leading exponent is Hatami et al. [
5], whose work is very enlightening. He was the first to optimize and improve the DAPFSP for modeling and studying complex supply chains in 2013. They also introduced the mixed integer linear programming model, proposed three construction algorithms, tested the variable neighborhood descent (VND) algorithm, and demonstrated the good performance of the VND algorithm in solving this scheduling problem. Similarly, he went on to expand on his previous paper by adding time for sequence-related setups in both the production and assembly stages [
6]. In 2015, Hatami et al. [
7] considered a distributed assembly scheduling problem with sequence-dependent setup times and the goal of minimizing production time. The setup times of both phases are sequence-dependent, which also lays the theoretical foundation for the sequences in this paper. Heuristics and meta-heuristics are also proposed to solve it. Based on his literature and views, many of these ideas and opinions have been studied and explored in greater depth by many scholars. Based on these rather cutting-edge ideas, many scholars have built on and deepened their research, and Ying et al. [
8] extended the DAPFSP for flexible assembly and sequence-independent setup times in supply chains. Using completion time as an optimization criterion, construction heuristic and custom meta-heuristic algorithms are proposed to solve this emerging scheduling extension. Gonzalez-Neira et al. [
9] studied a stochastic version of the DAPFSP and proposed a hybrid algorithm to solve the stochastic problem, integrating biased randomization and simulation techniques. Wang [
10] introduced a just-in-time constraint between the two phases of the traditional DAPFSP to form a just-in-time DAPFSP to minimize the maximum weighted tardiness cost. A variable neighborhood search based on memory algorithm is proposed. From the above reviewed studies, it can be concluded that these scholars and researchers have extended and improved this problem, and most of them have an objective function based on minimizing the makespan, which provides a theoretical basis for the objective function in this paper.
Most scheduling problems are NP-hard and exact methods simply cannot find the optimal solution in reasonable computational time. Therefore, heuristic and meta-heuristic algorithms have been used to find the optimal solution and near-optimal solutions in reasonable computation time. Zhang et al. [
11] pointed out that the DAPFSP is a typical NP-hard combinatorial optimization problem, and proposed an innovative three-dimensional matrix cube-based distribution estimation algorithm to address the difficulties of the proposed DAPFSP-T model. Likewise, Zhang et al. [
12] also assumed this idea, and their team integrated the problem with two machine environments, distributed production and flexible assembly, which can assemble job processing into customized products, and proposed a mixed integer linear programming model to characterize the problem nature and solve the small-scale problem. An efficient modulo algorithm is further proposed. They affirm that the modal algorithm is an efficient algorithm to solve the DAPFSP, while some scholars prefer to use the greedy algorithm to solve the problem. For example, Pan et al. [
13] solved a novel DAPFSP by proposing a mixed integer linear model, three construction heuristics, two variable neighborhood search methods, and an iterative greedy algorithm to obtain important problem-specific knowledge to improve the effectiveness of the algorithm. Similarly, Ochi et al. [
14] studied the DAPFSP with the objective of minimizing completion time and, proposed an iterative greedy based approach called bounded search iterative greedy algorithm. Similarly, in order to coordinate production and transportation scheduling, Yang [
15] proposed a novel DAPFSP-FABD model. The objective is to minimize the total cost of delivery and delay, and four heuristic algorithms, a variable neighborhood descent algorithm, and two iterative greedy algorithms are proposed. Liu et al. [
16] proposed a memory algorithm for DAPFSP based on variable neighborhood search with the objective function of, i.e., makespan. And, the initialization based on NEH heuristic is applied to the product ordering. The neighborhood structure is introduced into VNS and used to perturb the job assignment of the factory and adjust the job order of the factory. Huang et al. [
17] considered the DAPFSP with a total flow time criterion, and proposed an improved iterative greedy algorithm based on groupthink to solve the problem. It can be seen that the exact algorithm is no longer able to solve the problem, and this has promoted the development of heuristic and meta-heuristic algorithms, which can very definitely find the optimal solution as a solution to this scheduling problem.
More and more scholars are focusing more on the improvement of algorithmic aspects. For the no-wait flow shop scheduling problem that depends on time series, Hu et al. [
18] proposed an enhanced differential evolutionary algorithm. Subsequently, Seidgar [
19] took minimizing the weighted sum of expected completion time and average completion time as the solution objective and proposed four metaheuristic algorithms; namely, genetic algorithm, imperialistic competition algorithm, cloud theory-based simulated annealing, and adaptive differential evolution algorithm. Moreover, Li et al. [
20] argued that the imperialist competition algorithm can solve the fuzzy distributed assembly flow shop scheduling problem. Furthermore, Al-Behadili et al. [
21] proposed a multi-objective optimization model and particle swarm optimization solution method for the robust dynamic scheduling of permutation flow shops with uncertainty. Likewise, Zhang [
22] emphasized that DAPFSP is a new generalization of the distributed displacement flow shop scheduling problem and the assembly flow shop scheduling problem, proposed an enhanced population-based metaheuristic genetic algorithm, and designed an effective crossover strategy based on local search to accelerate convergence. Li et al. [
23] studied the minimization problem of DAPFSP and proposed a genetic algorithm with an enhanced crossover strategy and three different local searches. It is no coincidence that Mao et al. [
24] advocated an improved discrete artificial bee colony algorithm to solve the DAPFSP with preventive maintenance operator, optimized by the completion time criterion. Moreover, a local search method with insertion and exchange operators is used to generate adjacent solutions in the hiring bee phase and the bystander bee phase. Song and Lin [
25] jointly proposed a genetic programming hyperheuristic algorithm to solve the DAPFSP with sequence-dependent setup times, minimizing the completion time as the objective. For the improvement of the algorithm, these scholars further study the genetic algorithm and particle swarm algorithm. This also provides a reference basis for our subsequent simulation experiments.
3. Problem Description
The traditional distributed assembly permutation flowshop scheduling problem (DAPFSP) can be divided into two phases; namely, the production phase and the assembly phase. In this section, the two-stage DAPFSP problem is extended to a three-stage DAPFSP, named the production stage, the transportation stage, and the assembly stage, and the problem is described as follows.
The job consists of operations , and . In the production stage, there are n work processes and f identical plants, and job needs to be assigned to any plant for processing, and each plant is equipped with the same m machines, , which correspond to the same assembly line shop for part processing. Operations are processed on machine , and require time units. Machine can process at most one job at a time. The production and transport operations will be executed on machine and take time units. The rule is that in each assembly permutation flowshop, all jobs need to be processed on the same path in the order of machine i, which is equivalent to first on machine , then on . This goes on, until the end on machine . Parts belonging to the same product must be processed continuously, and no partial parts are allowed to pass through. All jobs start timing at time and on machine .
The subsequent phase is the transport stage, which means that after the completion of the first one in the first stage of the product operation, the transport machine collects all parts of the product and moves to the assembly stage.
In the assembly stage, there are s products and an assembly machine . Each product has a defined part of the operation. The assembly operation will be executed on the machine and uses time units. The rule is that the assembly of a product can only start when the work contained in the product is completed and the assembly machine is idle. Continuous processing stages are part of the same product operation. The next product operation can only be performed after all jobs belonging to a product have been processed.
From this, it is clear that the objective function of the problem is to determine the allocation of products to plants, and the sequence of parts and products to each plant in order to minimize the completion time or maximum completion time for all products. Based on the above description of the problem, the minimization of the completion time is denoted as
. To satisfy the above constraint, a feasible schedule
is found for
n jobs, such that the completion time
is minimized. This is the same where
is also equivalent to the time to complete the last job on the last machine. The Equation (
1) is as follows.
In the transportation phase, it is necessary to ensure that the completion time distance between two adjacent jobs is determined by the processing time of the two processes, independent of the other jobs in the arrangement. Therefore, the completion time distance is defined between each pair of jobs. The completion time distance between two adjacent job processes
and
is calculated as
In order to build a mathematical model based on the above description, the constraints, parameters and variables are as follows.
Subject to,
where
represents a binary variable. It is equal to 1 if job
j is the predecessor of job
k. Otherwise,
= 0. The same is true for
. The product
r is equal to 1 if it is the predecessor of the product
t. Otherwise,
.
is the completion time of job
j on machine
i, and
is the completion time of product
r.
is the assembly time of product
r, and
is the total number of jobs contained in the first
r products in the product sequence. In addition,
g is a large enough positive number.
is the number of jobs contained in product
t. It is worth noting that
.
Equation (
1) shows that the goal of the mathematical model is to minimize the completion time. The constraint sets (
3) and (
4) indicate that each job must have only one preceding job and one following job. Constraint sets (
5) and (
6) show that the preceding and following jobs of virtual job 0 are forced to be executed
f times. Constraint set (
7) ensures that a job cannot be both a predecessor and a successor of another job. Constraint set (
8) ensures that jobs belonging to the same product are processed consecutively. Constraint set (
9) indicates that job
j can be processed on machine
only after it is processed on machine
i. Constraint set (
10) indicates that job
j can only be processed on machine
i after completing the processing of job
k if job
j is a successor to job
k, where
g is positive and has a sufficiently large scale volume. The constraint sets (
11) and (
12) ensure that each product must have only one preorder and one subsequent job. Constraint set (
13) ensures that a product cannot be both a preorder and a successor of another product. Constraint set (
14) ensures that each product cannot enter the assembly stage before the production of the part of the job it contains is complete. Constraint set (
15) shows that if product
t is a preceding job of product
r, then product
r cannot start the assembly job until product
t is completed. Constraint set (
16) defines the minimum completion time. Constraint sets (
17) to (
20) define the domains of the decision variables.
The model uses a sequence-based variable and a set of
virtual parts. The sequence starts with a virtual part and ends with a virtual part. These virtual parts divide all parts into
subsequences, each corresponding to a plant. Parts belonging to the same product are never separated. Thus, the product sequence is implicitly included in the part sequence. For example,
.
Table 1 shows the machining times of parts and products.
One of the feasible solutions is . The sequence of parts is , consisting of the subsequences and .
4. Materials and Methods
To improve the local search capability of the algorithm, this section introduces the mathematical representation of feasible solutions, classification of populations, selection mechanism, domain structure and Gaussian learning strategy and elite learning strategy. A hybrid bat algorithm adapted to the three-stage DAPFSP problem is proposed.
4.1. Mathematical Expression of the Feasible Solution of the Three-Stage DAPFSP
The representation of feasible solutions is a crucial and important step in every meta-heuristic approach. The addition of a transportation process to the DAPFSP solved in this paper. The result is that the original expression for the process permutation of the PFSP is not adequate for this scheduling problem. Therefore, in this section, the feasible solution is divided into a sequence of products and a sequence of s processes based on the model of the three-stage DAPFSP model and the properties of the bat algorithm. Each sequence of these s processes corresponds to a product. The processes of a part can be viewed as the sequence of product assembly on the assembly flowshop.
In the production and transportation stages, parts need to be allocated one by one according to the product order. When allocating parts, their processes are sequentially arranged to the corresponding factories according to the process order of the product, and a minimum manufacturing cycle is obtained. Only after all the processes included in the current part are completed can the next part be produced. When a product has completed all processes, the product can proceed to the assembly stage for the installation and assembly stages. As an example, suppose a set of sequences
f is used to represent a feasible solution, and each plant has one and only one solution. Each sequence is an ordering of all the parts assigned to that plant, indicating the order in which the parts enter the flow shop. Thus, the order of processed products in the assembly stage is also implied, and the feasible solution can be expressed as
, where
is the sequence associated with sequence associated with plant
k and
is the total number of parts assigned to plant
k. For the example in
Section 3, the representation corresponding to this feasible solution is
and
.
In the feasible solution of the original DAPFSP problem, the first stage represents the arrangement of all N processes, and the second stage represents the plants to which these N processes are assigned respectively. In this section, the concept of product priority is introduced to determine the order of product assembly, and a novel feasible solution of the three-stage DAPFSP is proposed. Specifically, the feasible solution in the first stage is expressed as the processing priority of the product, and the parts assembly of each product is equal to the number of processes that constitute that product. The specific steps are, firstly, calculating the total processing time of the product at each stage and randomly initializing the sequence of products. Second, the first two products in the initial product sequence are selected for evaluation, and whichever sequence is better is chosen as the current sequence. Again, this is done by placing it among the product sequences that are already scheduled properly. Finally, an optimal schedule can be obtained to select the current best sequence for the next iteration of the process. The second stage is represented as the processing priority of all processes, where the processes belonging to the same product are arranged in a random order. The smaller the number of its columns, the higher the priority of the element values; the third stage is the plant priority assignment vector, where each part is represented as the plant assigned to the corresponding process. The specific steps are to assign a part of the processes to the factories one by one in order, then select a process and find the minimum completion time by placing it after the last process in each factory. The best part assignment is selected for the next iteration.
Table 2 describes how the three-stage DAPFSP representation is decoded into a schedule. Suppose there are 3 products (
) consisting of 9 jobs (
) processed in 3 plants (
). The mathematical representation is
,
,
. According to the last two stages, called job sequence and factory assignment, it can be observed that jobs 5, 4, and 8 are assigned to the first factory and are processed in the order of 5, 4, and 8 according to the priority specified in layer 2. Then, it is instantly obtained that the partial scheduling of the factories can be decoded as
. Similarly, the partial scheduling of the remaining two plants can be decoded as
and
, respectively. According to the values of the first stage specifying the product assembly priority, the value of 1 in the table corresponds to jobs 5 and 7 belonging to product 3. It can be concluded that after the processing stage, product 3 should be assembled first. In a similar way, it can be concluded that product 1 is assembled for the second time immediately after product 2.
In the context of the traditional representation of feasible solutions, the order of assembly of all products follows a first-come, first-served rule. This results in products being ranked in the processing stage in ascending order of the total completion time of their component operations. In contrast, the priority of products in the assembly phase is determined by the order of arrival at the assembly, and there is no way to specify it. This observation is confirmed by a study of the two-stage assembly scheduling problem by Tozkapan [
26]. The efficiency may be higher if the sequence of operations in the processing phase is different from the sequence of operations in the assembly phase under the total delay objective. With a very late delivery date, for example, the assembly of the product may be delayed, even if the entire processing phase of the product’s component operations has been completed.
4.2. Population Classification
The optimization process is divided into two stages. The first stage is that when the individual bat is in a better search position and is close to the optimal solution, its loudness and pulse emission rate reach the best state. This process is called the search phase, its population is called the search-type population. The second stage is the population of bats in a disadvantaged search position; that is, the capture population, so two populations with different functions are obtained. After each iteration, by updating the search direction and step length, the loudness and pulse emission rate of the bat algorithm are improved to find the optimal solution. By adjusting the weights and deviations of the network, the difference between the average value and the standard deviation of the bat algorithm can be minimized.
4.2.1. Search-Type Population
The combination of the back propagation (BP) algorithm based on mean square error (MSE) and gradient descent method minimizes the mean square error [
27]. The formula based on the mean square error measurement is shown in (
21):
where
represents the
n-th element of the required signal, and
represents the nth actual output. In the training process, the weight vector in the
iteration is updated by (
23). Where
is the learning rate or step length,
is the weight vector of the previous iteration and
is the gradient vector, which can be calculated by (
22) and (
23).
In (
23),
e is the MSE error output in the
t-th step of the training process and
is derived from the MSE error on each element of the
w vector. The weight is expressed as
,
will be adjusted to an appropriate value to achieve better convergence. At this time, suppose the probability pops of the search-type population, its loudness and pulse emission rate are updated to:
4.2.2. Captive Population
As a branch of the gradient descent method, the conjugate gradient method (CG) is applied to nonlinear unconstrained optimization problems. This method has strong local and global convergence [
26,
27,
28]. According to the cloud computing resource scheduling problem, the CG method uses (
26) to generate a weight sequence:
where
is the result of the line search method, which can be an exact line search or an inaccurate line search, which is expressed as a step size here. In (
26),
is in the descending direction, which is expressed as the search direction here, and its formula is shown in (
27):
In (
27),
is the conjugate parameter,
is the gradient of the objective function concerning the weight at step
, and represents the direction of the last step, and the first step is
.
In the iterative process, the loudness
and the pulse emission rate
will also change. As the bat moves closer to its prey, its loudness will decrease, and the pulse emission rate will increase. At this time, the probability of the catching population is
and
. In summary, the loudness and pulse emission rate of the bat algorithm are updated to:
4.3. Selection Mechanism
When it comes to the bat algorithm as a learning algorithm, each individual in the population needs to learn from the individually optimal and globally optimal individuals in order to find the optimal solution. In the field of multi-objective optimization, there is no single optimal solution, and the optimal selection mechanism needs to be redesigned. Which strategy is used to update the individual optimal and the global optimal respectively, thus connecting the decision variable space and the objective space, is particularly important for weighing the exploration and exploitation capabilities of the algorithm evolution process. In this paper, we consider fully mining individuals with better diversity and convergence to assist populations to jump out of the local Pareto frontier. Three guides are selected from the searching and capturing populations to guide the entire individual bat flight, and how the guides are selected from the two populations is specified below.
Unlike the traditional bat algorithm, this algorithm first generates a set of with solutions and performs a local search process for the optimal solution in the set . Subsequently, IHBA enters the iterative phase. In the iteration, the solution is selected using the selection mechanism in the set . The solution is applied to the search phase and two partial sequences can be obtained, one for the solution with the products and processes removed, and the other for the remaining part of the solution . The local search for the products is applied to , and the suboptimal solution is generated. IHBA again reinserts the removed products and jobs into . This process is called the capture phase, and a complete solution is regenerated. A local search is performed on to generate . Finally, acceptance criteria are used to determine whether the new solution updates the set.
Therefore, in scheduling problems, the selection mechanism is to select a solution from the solution set at the beginning of each iteration, and the selected solution is noted as , and proceeds to the subsequent stages such as search and capture. In this scheduling problem, the minimum completion time and the number of iterations are often used as selection factors. So, the proposed selection mechanism consists of two random options, both of which have a 50% probability of being selected. That is, two solutions are randomly selected in the set and the one with the lower minimum completion time is chosen as . Alternatively, two solutions are randomly selected in , and the one with the lower number of iterations is chosen.
The main focus of , and osd wizard selection mechanisms is on the target space, implying how to fully exploit the candidate solutions with good convergence and diversity in the target space. These wizards serve as a bridge between the target space and the decision variable space, and the new wizard selection mechanism can weigh the ability of exploration and exploitation of the decision variable space in an integrated way.
4.4. Three Neighborhood Structures Based on Insert Operator
To solve the three-stage DAPFSP problem, this paper introduces three neighborhood structures based on the INSERT operator, which constitutes the three-stage bat algorithm (3SBA). The insert operator is considered by many scholars as a superior performance operator, which is described as follows.
Product-based Neighborhood (PBN)
Regarding the order of product assembly, a randomly selected product is inserted into another random position.
Factory-based Neighborhood (FBN)
A process is randomly selected from the representation of the solution and assigned to another randomly selected plant. For this plant, all possible positions where jobs can be inserted are considered and the part of the job sequence with the earliest completion time is selected. It is worth noting that the sequence of jobs assigned to other plants remains unchanged during this process.
Job Sequence-based Neighborhood (JSBN)
A plant is randomly selected and its sequence of jobs is extracted from the solution representation. Next, a job is randomly selected from this partial sequence, and another location is randomly inserted. Finally, the jobs in this partial sequence along with their product priorities and plants are placed in an orderly manner in the distribution solution representation, which is partially the location belonging to that plant.
4.5. Local Search Method Based on Variable Neighborhood Structure
Based on the above three neighborhoods named PBN, FBN and JSBN, this section proposes a local search method with variable neighborhood search. Equation denotes that the neighborhood structure and other parameters are consistent with the original bat algorithm, implying that the maximum number of iterations for each neighborhood at the same frequency is noted as and the frequency f is initialized as . In 3SBA, all three neighborhoods are iterated sequentially, avoiding premature convergence throughout the search process.
Variable neighborhood descent (VND) is the simplest variant of variable neighborhood search [
29]. It has been shown to be effective in solving the flow shop [
30] and distributed scheduling problems [
31]. VND searches for different neighborhood structures from minimum to maximum. First, starting from the initial solution, VND searches the first neighborhood to find the local optimum. Then, while searching the second region, if a better local optimum solution is found, the algorithm returns to the first neighborhood. Otherwise, it continues searching the third neighborhood and so on. The algorithm does not end until a local optimum is found with respect to all neighborhoods. Therefore, to facilitate the differentiation of the VNDs in this paper, two versions were developed based on the characteristics and features of the bat algorithm. The first one uses three neighborhood structures, named VND3BA, and the second one uses two neighborhood structures, named VND2BA, respectively. A VND that best fits the bat algorithm and the scheduling problem is selected by calibration through simulation experiments.
4.5.1. VND3BA Local Search Method Based on Three Neighborhood Structures
The first method is applied to each product contained in the plant. After removing each part of the product in succession, it is tested at all possible locations within the product. If a better manufacturing span is found, the part sequence is updated. This method runs until all parts contained in the plant have been taken into account and no further improvements are found; then, it can be stopped and ended. It can be named as Local Search Inside Product() and Part Local Search Inside Factory(). The former mainly searches individual products, while the latter searches the whole factory by calling the former, each in its own way.
The second method is a local search of the products within the factory. The principle of this method is to remove the products one by one from the beginning to the end and try to find the best position for them, equivalent to the optimal solution of this problem. If, in the process, a better manufacturing span is found, the sequence of parts in the plant is updated. The process is repeated until no products are found that can be improved.
The third method focuses on finding the most suitable location for a product that crosses plants. First, all plants are checked and the plant with the maximum completion time p is found. Then, the first product is removed and is tested in all possible locations in the remaining plants. If the generated best completion time is lower than the original completion time , this product is inserted into the current location. The principle is that the algorithm iterates by finding the plant with the maximum completion time again, until a local optimum is found.
4.5.2. VND2BA Local Search Method Based on Two Neighborhood Structures
Since VND3BA considers the neighborhood of parts and the neighborhood of products separately, some available feasible solutions may be missed. Therefore, in this section, two local search algorithms are proposed to consider these two neighborhoods in an integrated manner.
The first approach explores the interior of the plant by extracting the range of products and finding the best location of the products within the plant. This step is to extend the scope of the local search. This method also adaptively finds the best part order for the product when inserting it.
The second approach exploits the local search capability of the bat algorithm itself to explore the optimal solution across plants. Therefore, it can be viewed as a combination of two processes named ProductLocalSearchBetweenFactories() and LocalSearchInsideProduct().
4.6. Gaussian Learning Strategy and Elite Learning Strategy
Gaussian learning strategy (GLS) [
32] and elite learning strategy (ELS) [
33] can assist individuals of bats to jump out of the local frontier and improve the local search ability of the algorithm. If the feasible solution is not updated many times, the whole bat population is most likely to fall into local optimum, and then only the GLS reset strategy can be executed, which is given by
The collaborative learning mechanism of and ensures that the exploration and exploitation capability of the entire bat population is enhanced, allowing the algorithm to quickly jump out of the local frontier to approximate the true frontier.
Although the use of GLS can assist individual bats to jump out of the local frontier, this strategy alone still cannot meet the requirements of the bat algorithm for solving the DAPFSP. To further improve the performance of the bat algorithm, ELS is introduced to solve the scheduling problem with the following mathematical expressions.
where
and
represent the upper and lower bounds of the
j-th dimensional decision variable, respectively, and
represents the random number with a mean value of 0 and a variance of 1.




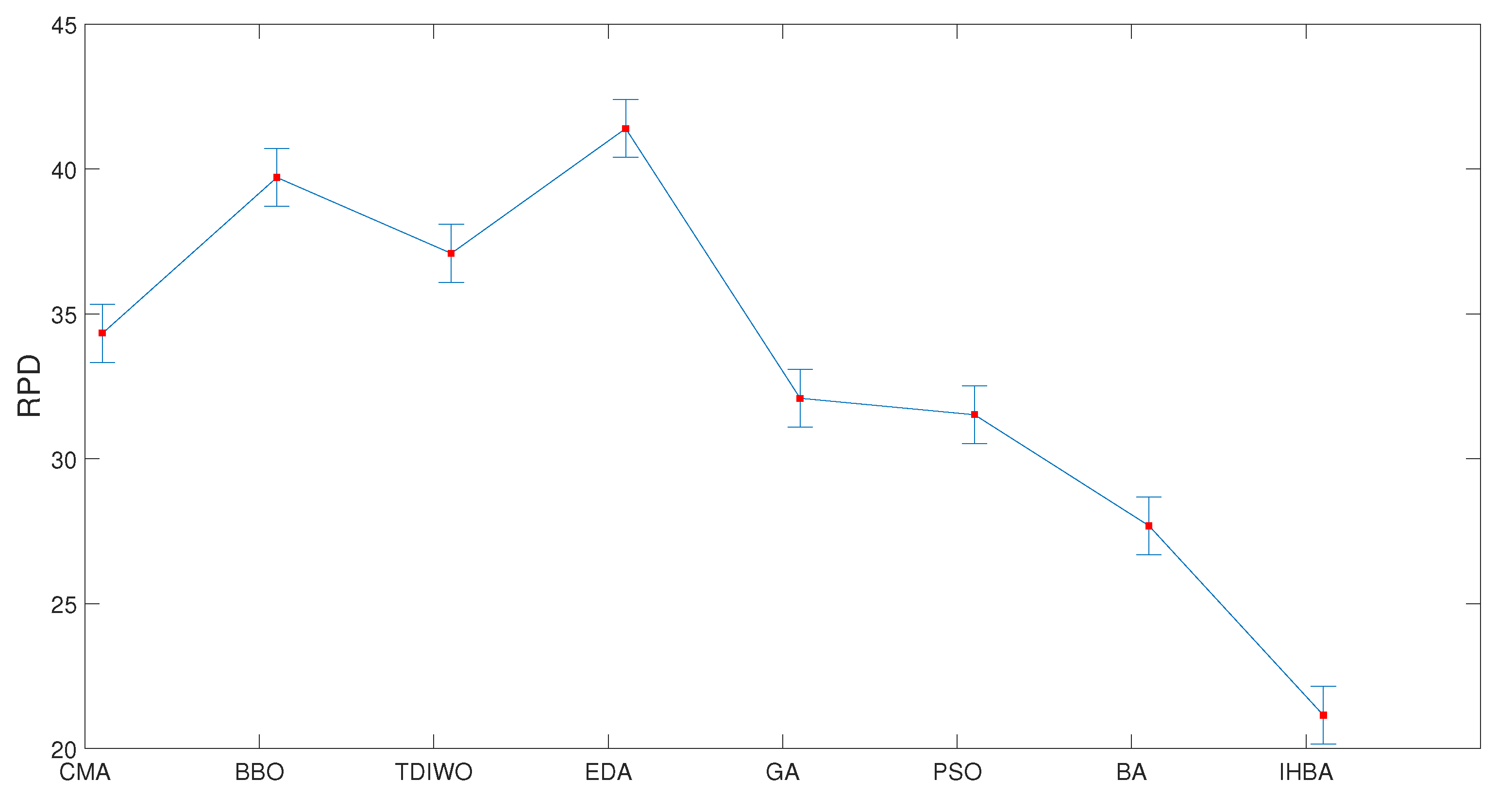
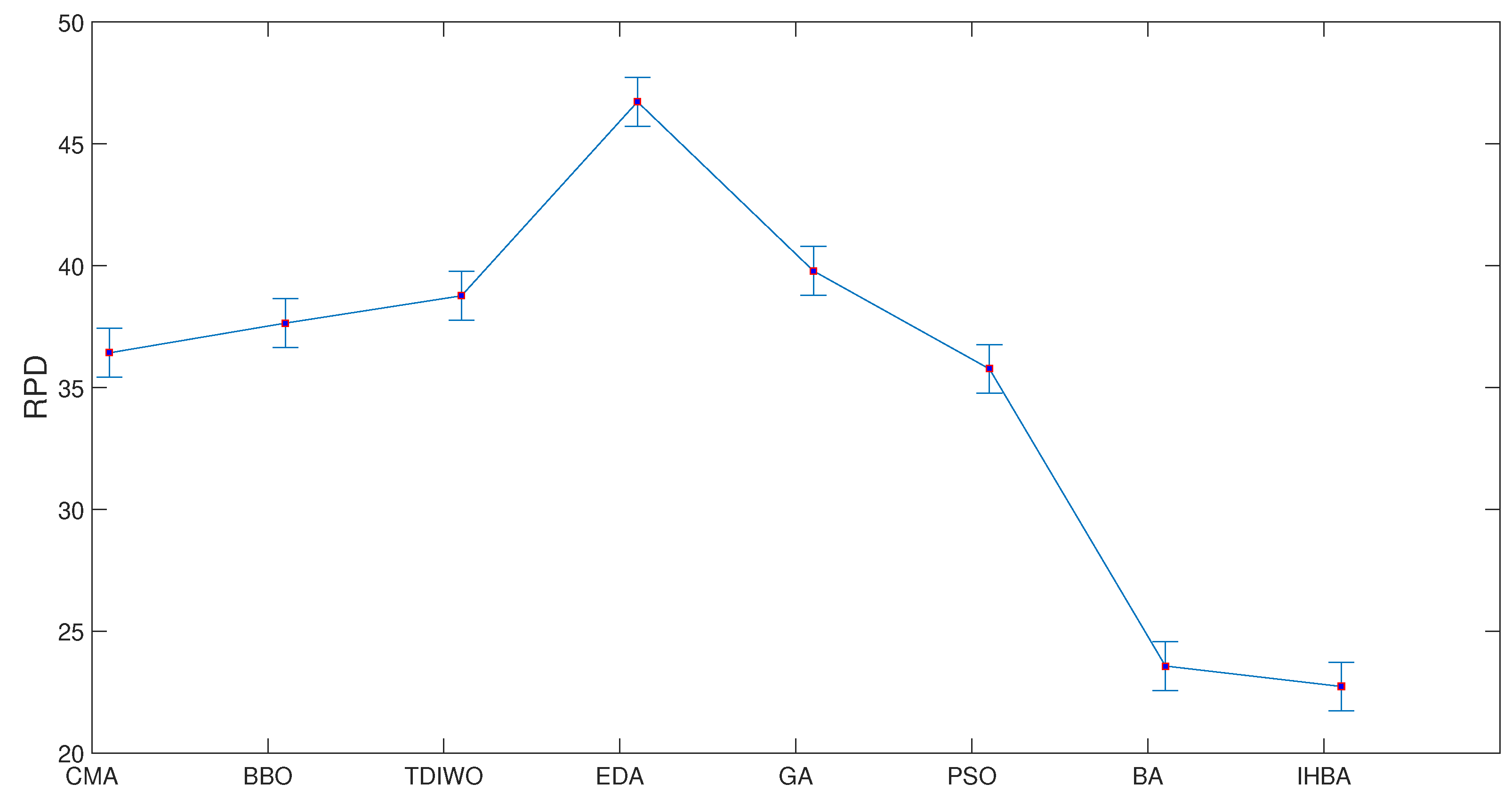
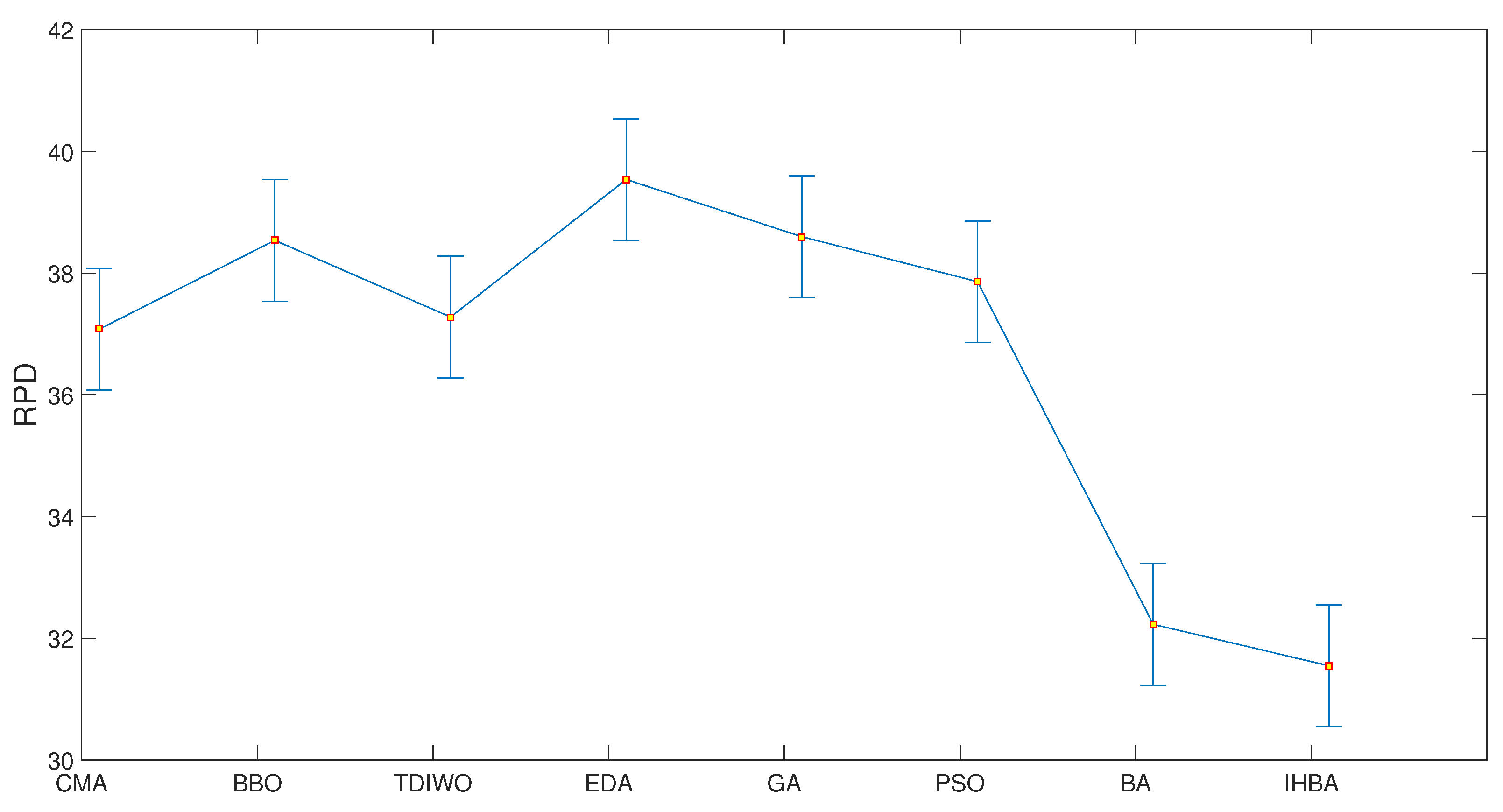

{kind=link}
{kind=link}
{kind=link}