
Earthquake Damage Assessment in Three Spatial Scale Using Naive Bayes, SVM, and Deep Learning Algorithms


Abstract
:1. Introduction
2. Literature Review
3. Data and Case Study
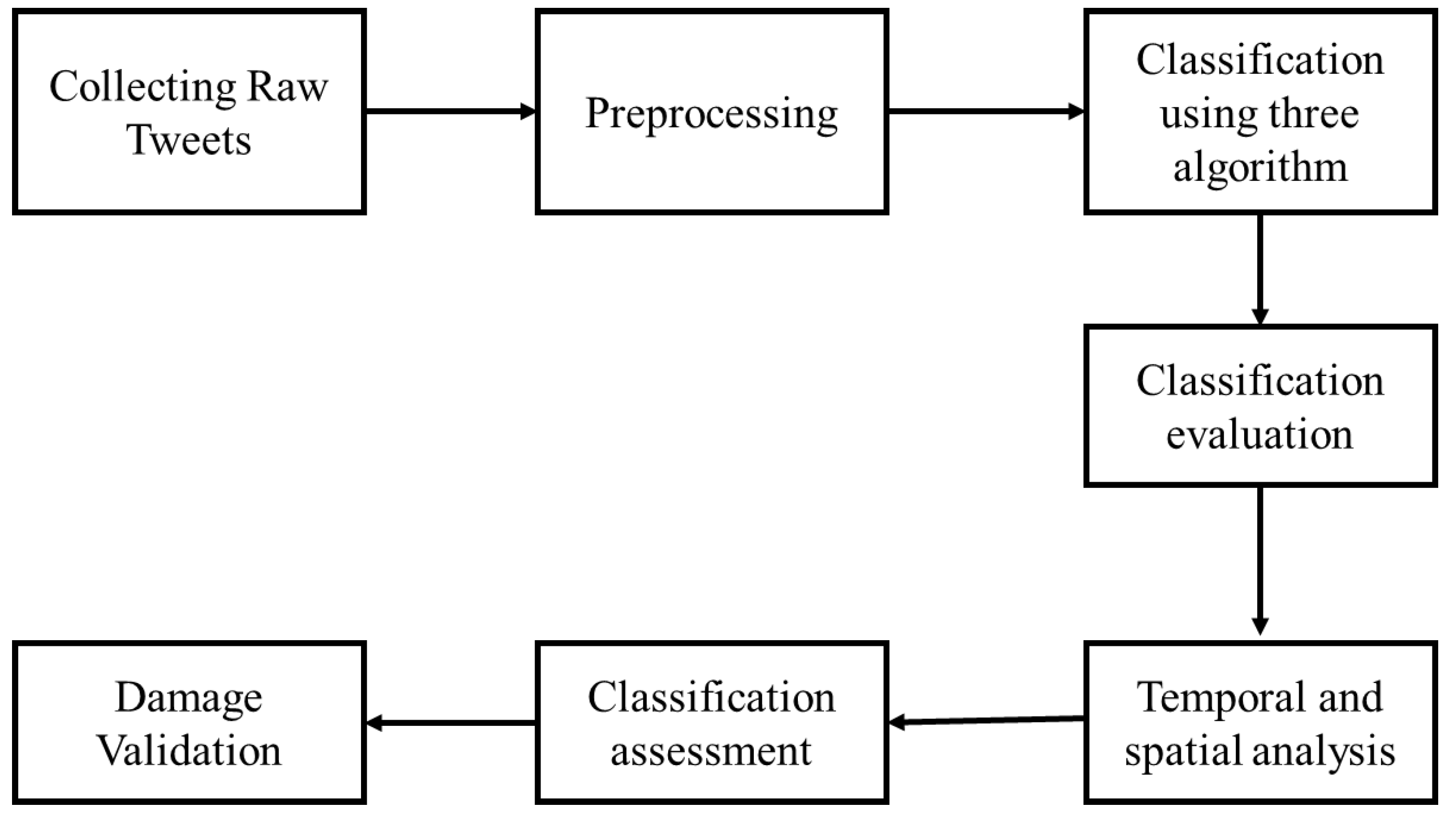
4. Methodology
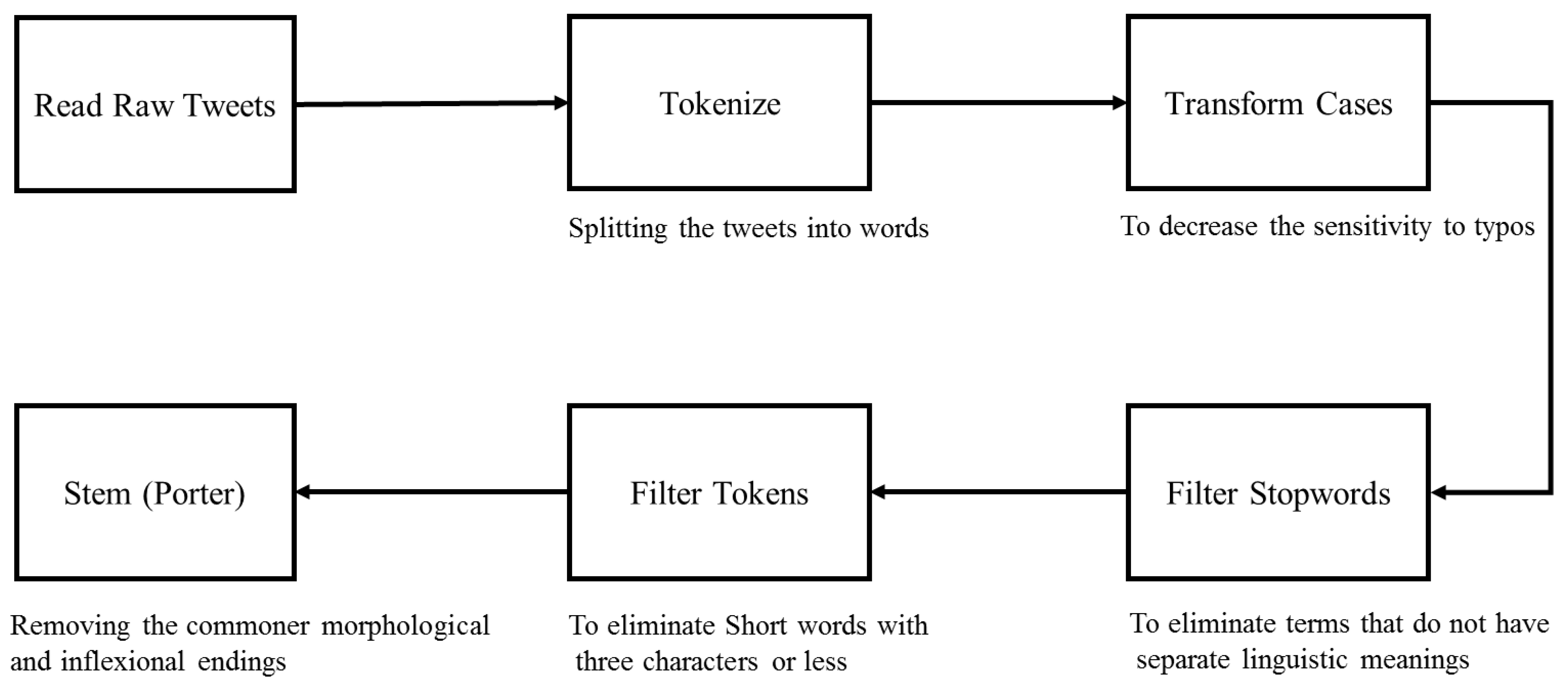
4.1. Data Preprocessing
4.2. Classification
- Naive Bayes
- SVM
- Deep learning
4.3. Assessment Performance of Classification
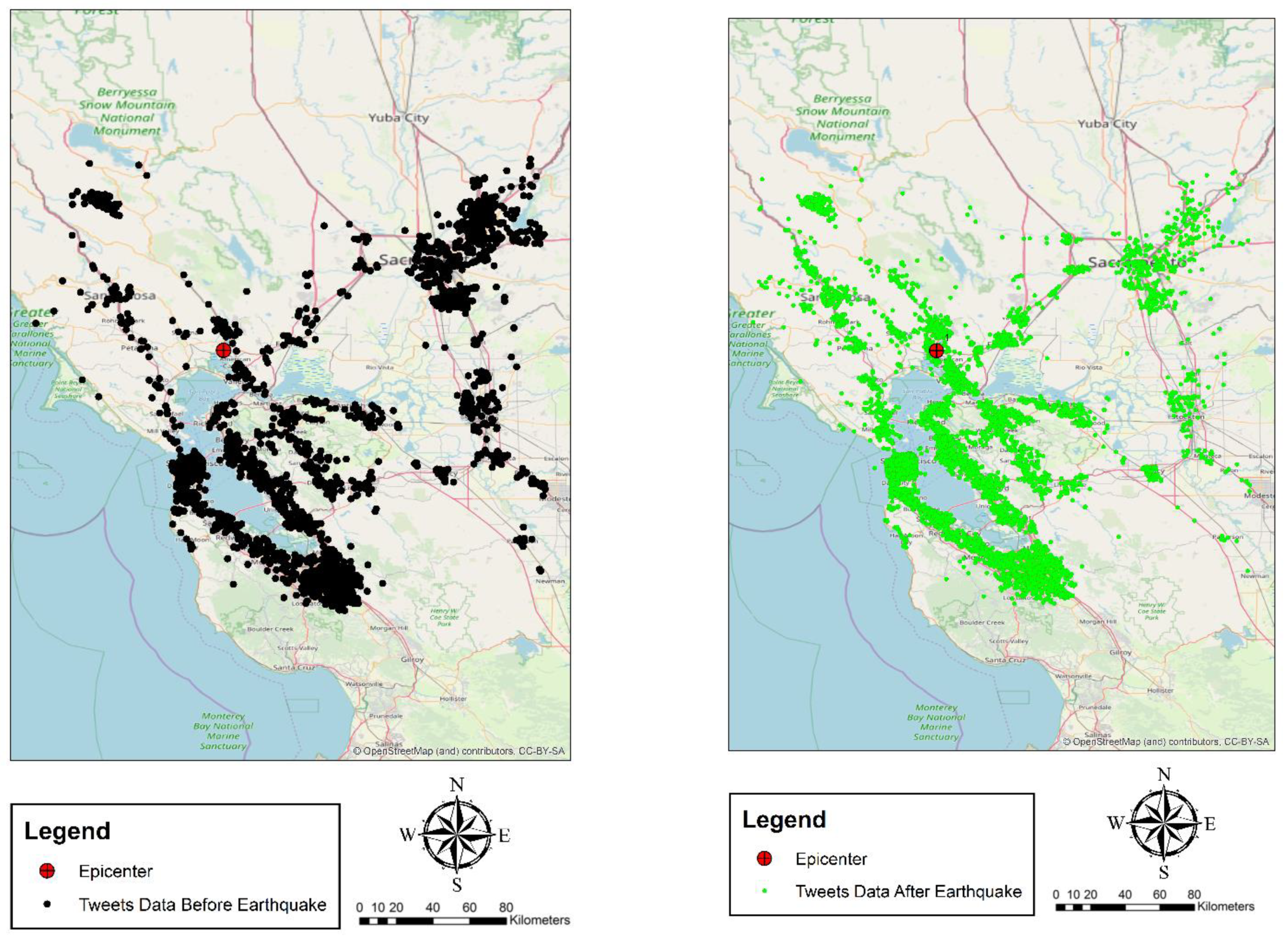
4.4. Temporal and Spatial Analysis
- Temporal analysis
- Spatial analysis (identifying region-particular topic)
4.5. Damage Assessment
4.6. Validation
- True Positives (TP): These are items in which predicted damage was also damage in reality.
- True Negatives (TN): Predicted non-damage was, in reality, non-damage.
- False Positives (FP): Predicted damage was, in reality, non-damage.
- False Negatives (FN): Predicted non-damage was, in reality, damage.
5. Results
5.1. Classification
- Binary classification
- Multi-class classification
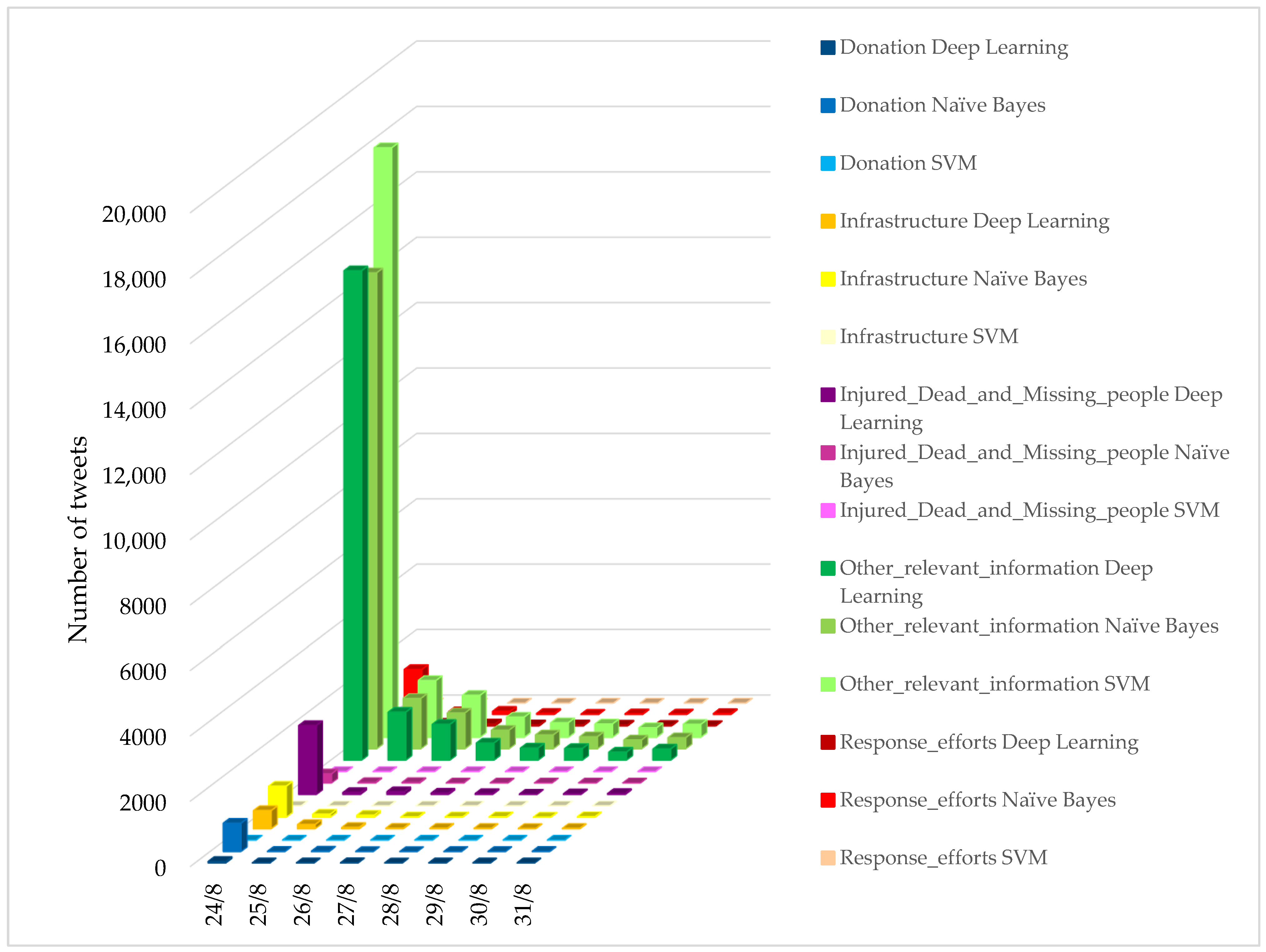
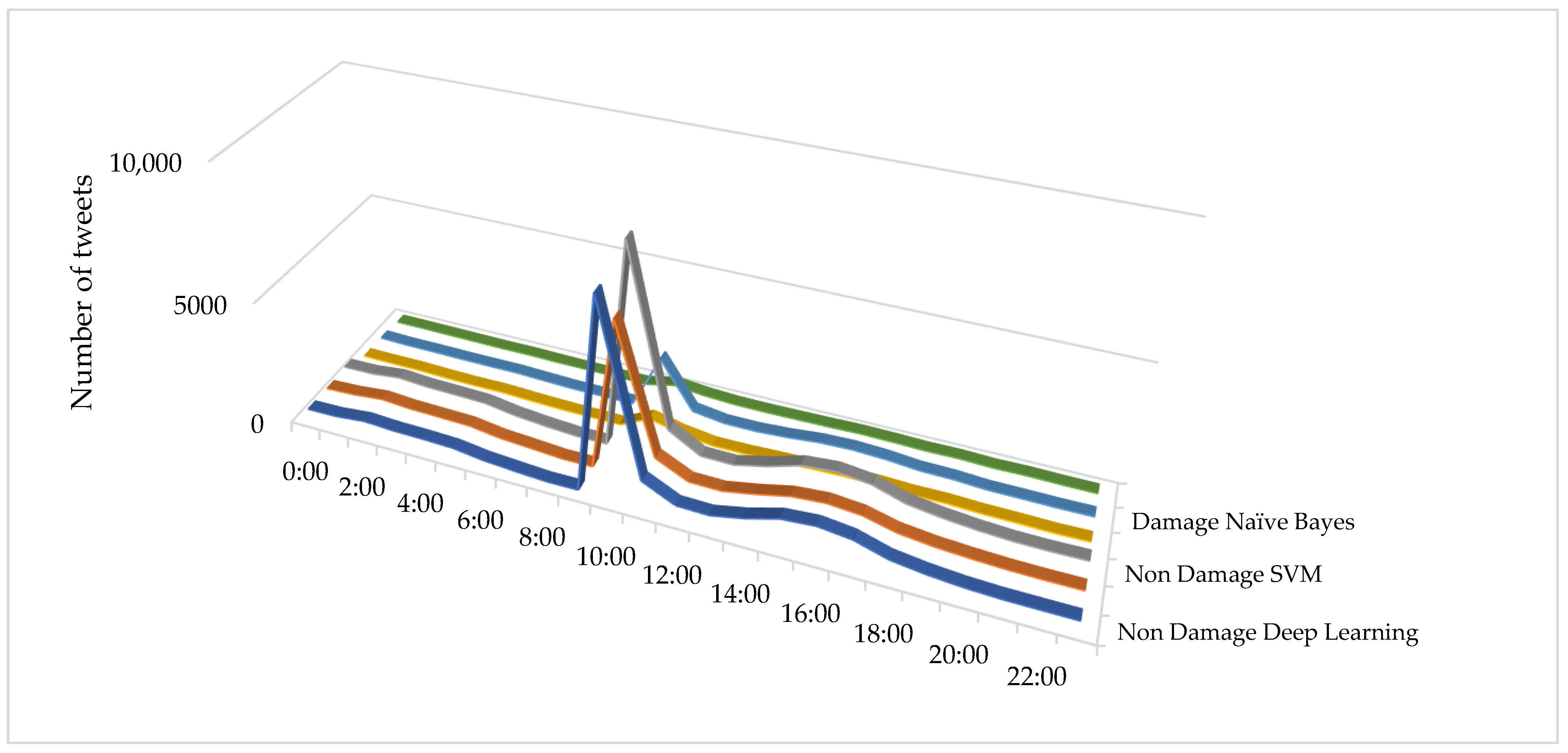
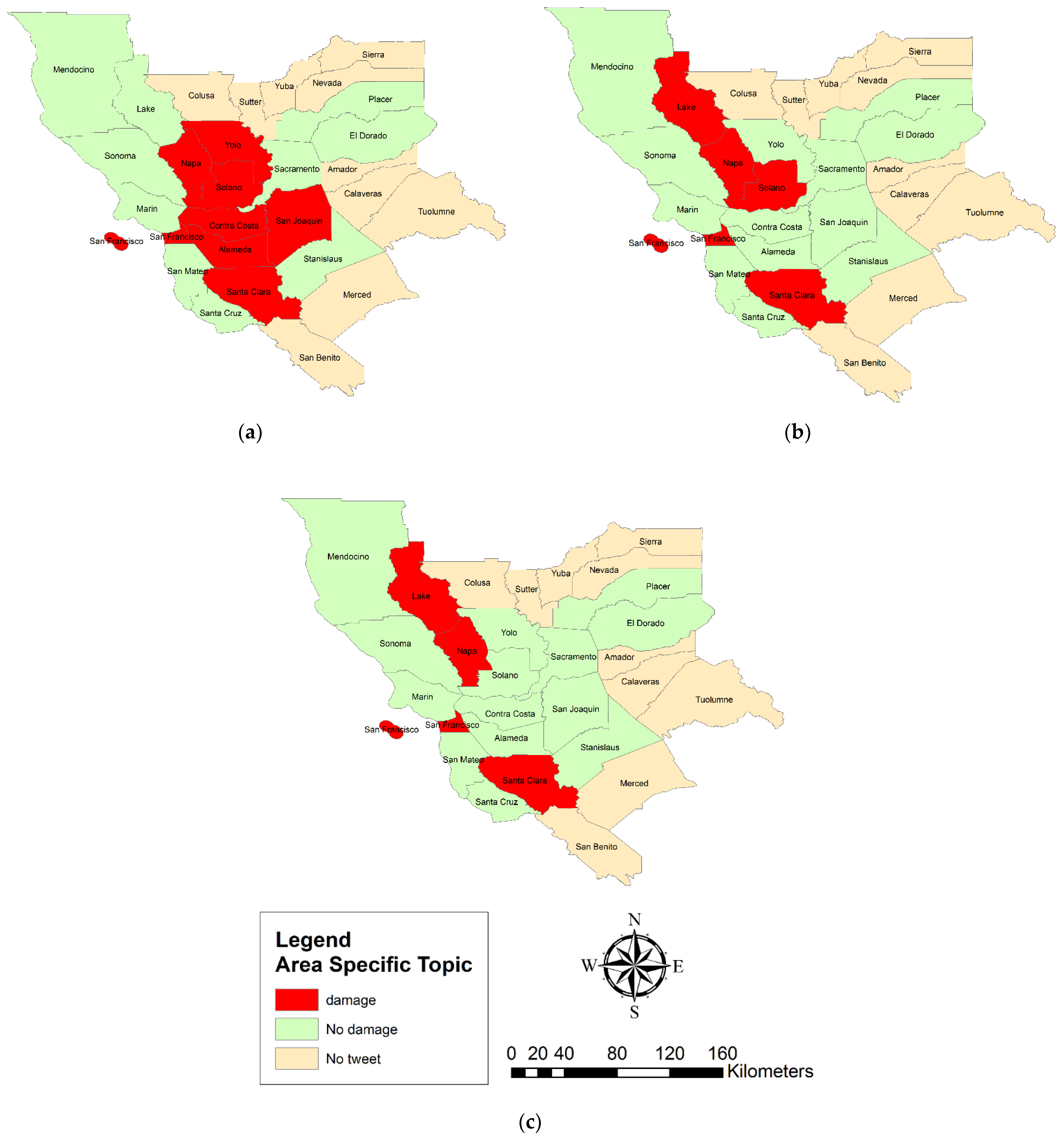
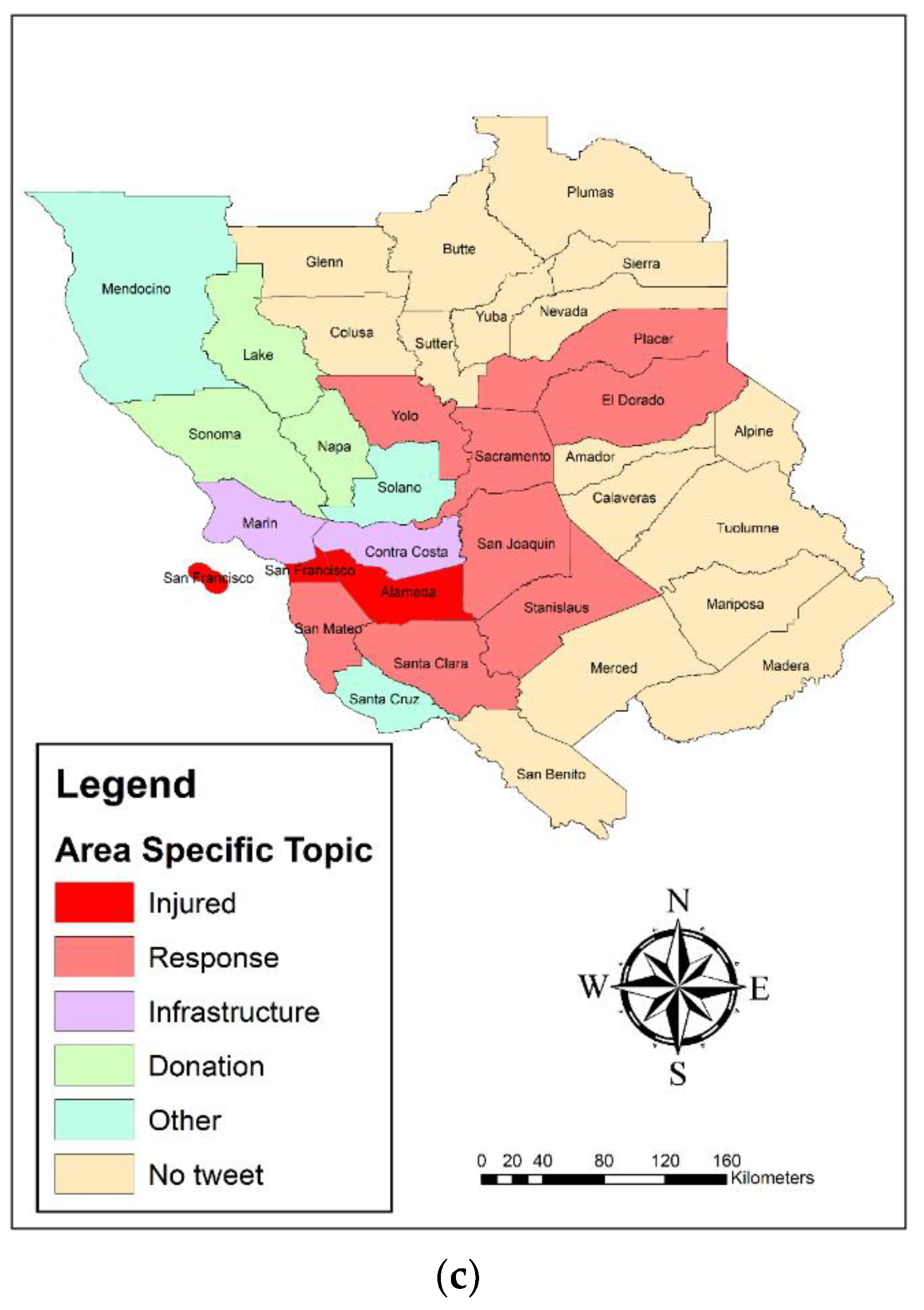
5.2. Temporal and Spatial Analysis
- Temporal analysis
- Spatial topic concentration
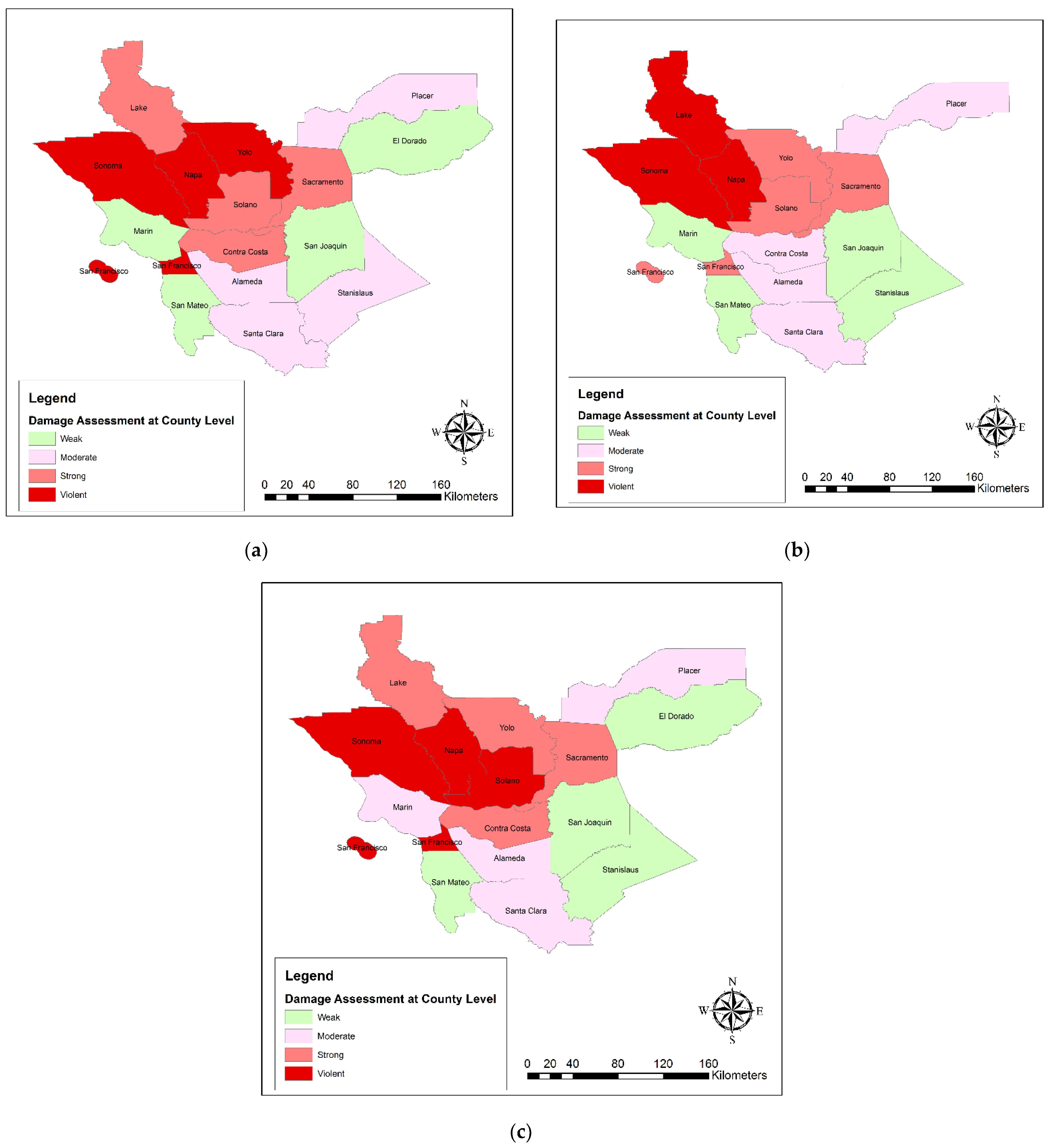
5.3. Damage Estimation
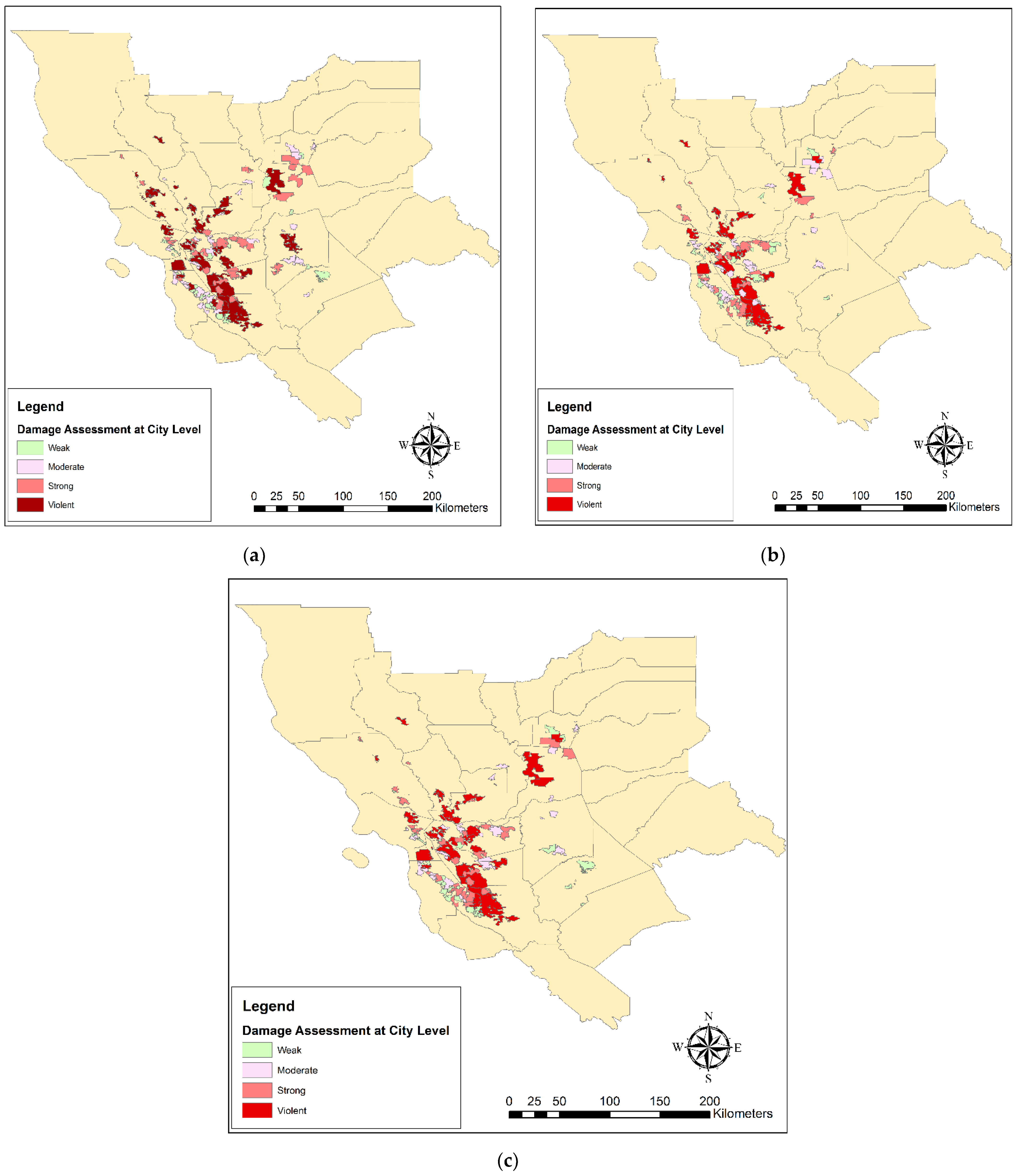
- Damage Estimation at the county scale
- Damage Estimation at the city scale
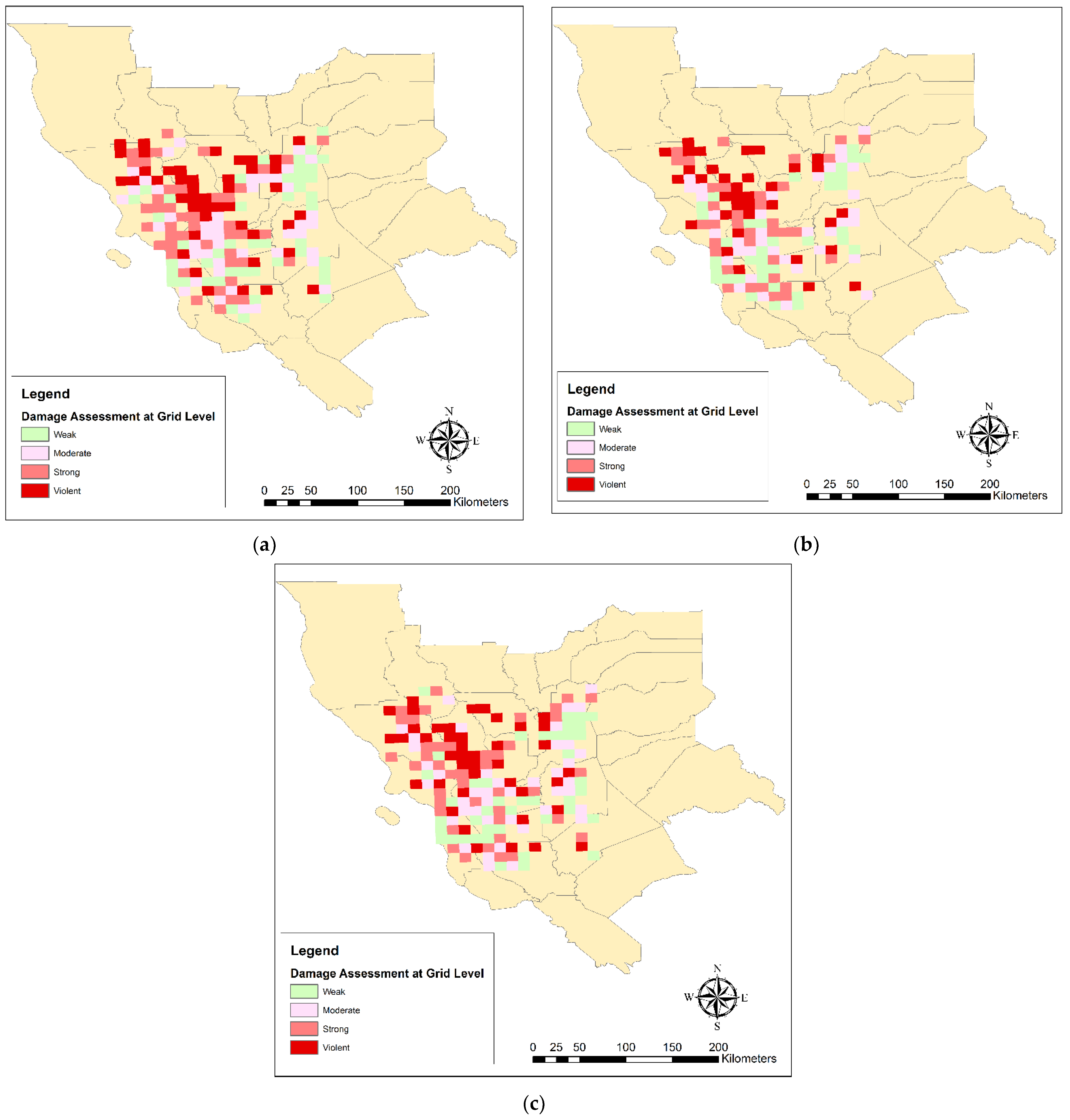
- Damage Estimation at the 10 × 10 km grids scale
5.4. Damage Validation
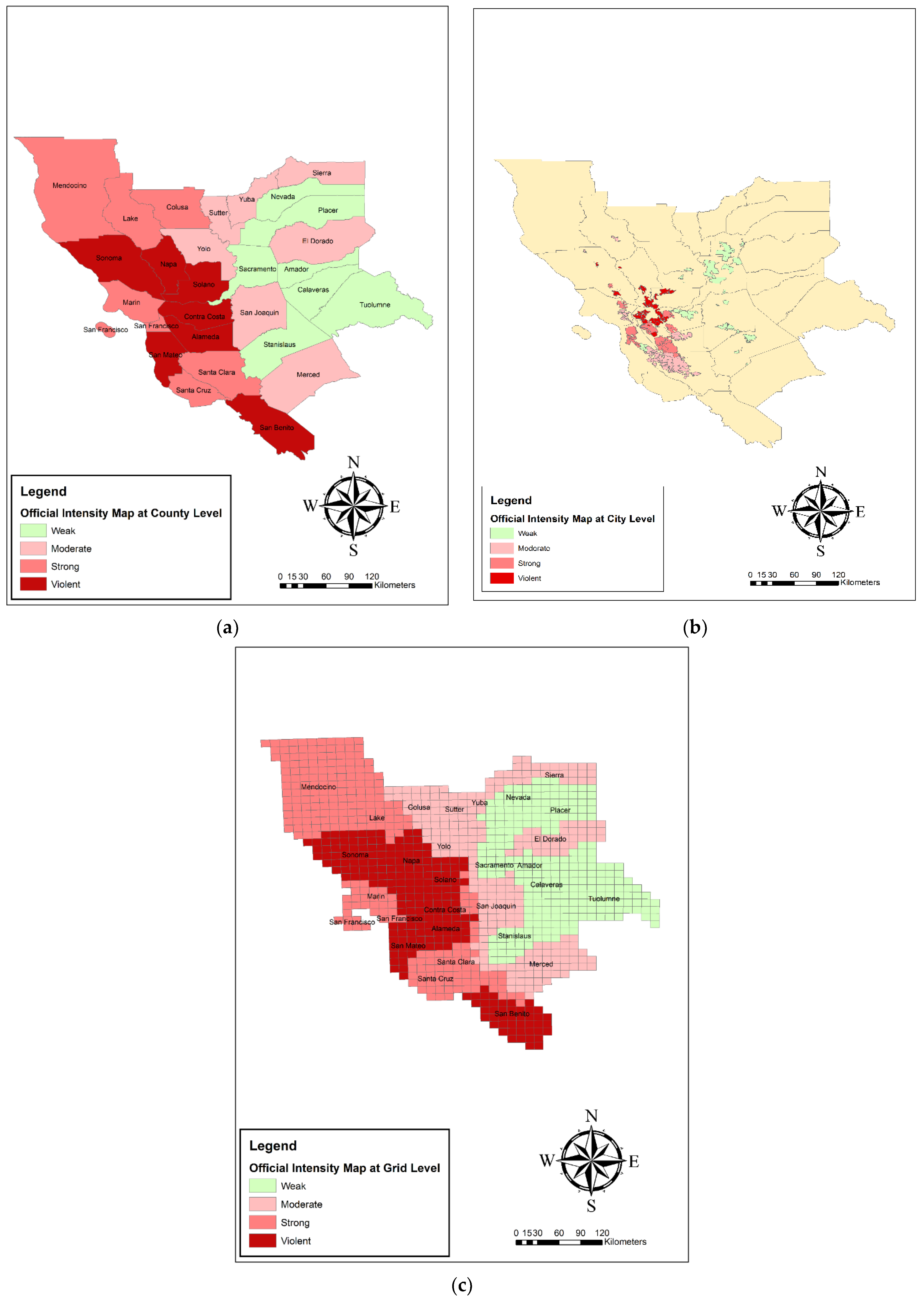
- Damage validation at the county scale
- Damage validation at city scale
- Damage Validation at the 10 × 10 km grids scale
6. Conclusions and Suggestions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Wang, Y.; Ruan, S.; Wang, T.; Qiao, M. Rapid estimation of an earthquake impact area using a spatial logistic growth model based on social media data. Int. J. Digit. Earth 2018, 12, 1–20. [Google Scholar] [CrossRef]
- Musaev, A.; Pu, C. Landslide information service based on composition of physical and social sensors. In Proceedings of the 2017 IEEE 33rd International Conference on Data Engineering (ICDE), San Diego, CA, USA, 19–22 April 2017; IEEE: Piscataway, NJ, USA; pp. 1415–1416. [Google Scholar]
- Burks, L.; Miller, M.; Zadeh, R. Rapid estimate of ground shaking intensity by combining simple earthquake characteristics with Tweets. In Proceedings of the Tenth US National Conference on Earthquake Engineering Frontiers of Earthquake Engineering, Anchorage, USA, 21–25 July 2014. [Google Scholar]
- Cheng, C.; Zhang, T.; Su, K.; Gao, P.; Shen, S. Assessing the Intensity of the Population Affected by a Complex Natural Disaster Using Social Media Data. ISPRS Int. J. Geo-Inf. 2019, 8, 358. [Google Scholar] [CrossRef] [Green Version]
- Resch, B.; Usländer, F.; Havas, C. Combining machine-learning topic models and spatiotemporal analysis of social media data for disaster footprint and damage assessment. Cartogr. Geogr. Inf. Sci. 2018, 45, 362–376. [Google Scholar] [CrossRef] [Green Version]
- Li, X.; Caragea, D.; Zhang, H.; Imran, M. Localizing and quantifying infrastructure damage using class activation mapping approaches. Soc. Netw. Anal. Min. 2019, 9, 44. [Google Scholar] [CrossRef]
- Peters, R.; de Albuquerque, J.P. Investigating images as indicators for relevant social media messages in disaster management. In Proceedings of the ISCRAM 2015 Conference, Kristiansand, Norway, 24–27 May 2015. [Google Scholar]
- Gründer-Fahrer, S.; Schlaf, A.; Wiedemann, G.; Heyer, G. Topics and topical phases in German social media communication during a disaster. Nat. Lang. Eng. 2018, 24, 221–264. [Google Scholar] [CrossRef]
- Shan, S.; Zhao, F.; Wei, Y.; Liu, M. Disaster management 2.0: A real-time disaster damage assessment model based on mobile social media data—A case study of Weibo (Chinese Twitter). Safety Sci. 2019, 115, 393–413. [Google Scholar] [CrossRef]
- Alam, F.; Ofli, F.; Imran, M. Descriptive and visual summaries of disaster events using artificial intelligence techniques: Case studies of Hurricanes Harvey, Irma, and Maria. Behav. Inf. Technol. 2019, 39, 1–31. [Google Scholar] [CrossRef]
- Eivazy, H.; Malek, M.R. Simulation of natural disasters and managing rescue operations via geospatial crowdsourcing services in tensor space. Arab. J. Geosci. 2020, 13, 1–15. [Google Scholar] [CrossRef]
- Wu, K.; Wu, J.; Ding, W.; Tang, R. Extracting disaster information based on Sina Weibo in China: A case study of the 2019 Typhoon Lekima. Int. J. Dis. Risk Reduct. 2021, 60, 102304. [Google Scholar] [CrossRef]
- Corbane, C.; Lemoine, G.; Kauffmann, M. Relationship between the spatial distribution of SMS messages reporting needs and building damage in 2010 Haiti disaster. Nat. Hazards Earth Syst. Sci. 2012, 12, 255–265. [Google Scholar] [CrossRef] [Green Version]
- Liang, Y.; Caverlee, J.; Mander, J. Text vs. images: On the viability of social media to assess earthquake damage. In Proceedings of the 22nd international conference on world wide web, Rio de Janeiro, Brazil, 13–17 May 2013; ACM: New York, NY, USA; pp. 1003–1006. [Google Scholar]
- Cresci, S.; Avvenuti, M.; La Polla, M.; Meletti, C.; Tesconi, M. Nowcasting of earthquake consequences using big social data. IEEE Int. Comput. 2017, 21, 37–45. [Google Scholar] [CrossRef]
- Nguyen, D.T.; Ofli, F.; Imran, M.; Mitra, P. Damage assessment from social media imagery data during disasters. In Proceedings of the 2017 IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining 2017, Sydney, Australia, 31 July 2017; ACM: New York, NY, USA; pp. 569–576. [Google Scholar]
- Avvenuti, M.; Cresci, S.; Del Vigna, F.; Tesconi, M. On the need of opening up crowdsourced emergency management systems. AI Soc. 2017, 33, 55–60. [Google Scholar] [CrossRef]
- Avvenuti, M.; Cresci, S.; Del Vigna, F.; Fagni, T.; Tesconi, M. CrisMap: A big data crisis mapping system based on damage detection and geoparsing. Inf. Syst. Front. 2018, 20, 993–1011. [Google Scholar] [CrossRef]
- Zou, L.; Lam, N.S.; Cai, H.; Qiang, Y. Mining Twitter data for improved understanding of disaster resilience. Ann. Am. Assoc. Geogr. 2018, 108, 1422–1441. [Google Scholar] [CrossRef]
- Mouzannar, H.; Rizk, Y.; Awad, M. Damage Identification in Social Media Posts using Multimodal Deep Learning. In Proceedings of the 15th ISCRAM Conference, Rochester, NY, USA, 20–23 May 2018. [Google Scholar]
- Kropivnitskaya, Y.; Tiampo, K.F.; Qin, J.; Bauer, M.A. Real-time earthquake intensity estimation using streaming data analysis of social and physical sensors. In Earthquakes and Multi-Hazards Around the Pacific Rim; Birkhäuser: Cham, Switzerland, 2018; pp. 137–155. [Google Scholar]
- Fernandez-Marquez, J.L.; Francalanci, C.; Mohanty, S.; Mondardini, R.; Pernici, B.; Scalia, G. E 2 mC: Improving Rapid Mapping with Social Network Information. In Organizing for the Digital World; Springer: Cham, Switzrtland, 2019; pp. 63–74. [Google Scholar]
- Mendoza, M.; Poblete, B.; Valderrama, I. Nowcasting earthquake damages with Twitter. EPJ Data Sci. 2019, 8, 3. [Google Scholar] [CrossRef] [Green Version]
- Ahadzadeh, S.; Malek, M.R. Earthquake Damage Assessment Based on User Generated Data in Social Networks. Sustainability 2021, 13, 4814. [Google Scholar] [CrossRef]
- Sakaki, T.; Okazaki, M.; Matsuo, Y. Earthquake shakes Twitter users: Real-time event detection by social sensors. In Proceedings of the 19th international conference on World wide web, Raleigh North Carolina USA, 26–30 April 2010; ACM: New York, NY, USA; pp. 851–860. [Google Scholar]
- Earle, P.S.; Bowden, D.C.; Guy, M. Twitter earthquake detection: Earthquake monitoring in a social world. Ann. Geophys. 2012, 54, 708–715. [Google Scholar]
- Huang, Q.; Cervone, G.; Jing, D.; Chang, C. DisasterMapper: A CyberGIS framework for disaster management using social media data. In Proceedings of the 4th International ACM SIGSPATIAL Workshop on Analytics for Big Geospatial Data, Seattle, WA, USA, 3 November 2015; ACM: New York, NY, USA; pp. 1–6. [Google Scholar]
- Wang, Z.; Ye, X. Space, time, and situational awareness in natural hazards: A case study of Hurricane Sandy with social media data. Cartogr. Geogr. Inf. Sci. 2019, 46, 334–346. [Google Scholar] [CrossRef]
- Yin, J.; Lampert, A.; Cameron, M.; Robinson, B.; Power, R. Using social media to enhance emergency situation awareness. IEEE Int. Syst. 2012, 27, 52–59. [Google Scholar] [CrossRef]
- Kireyev, K.; Palen, L.; Anderson, K. Applications of topics models to analysis of disaster-related Twitter data. In NIPS Workshop on Applications for Topic Models: Text and Beyond; NIPS: Whistler, BC, Canada, 2009; Volume 1. [Google Scholar]
- Khare, P.; Burel, G.; Maynard, D.; Alani, H. Cross-Lingual Classification of Crisis Data. In International Semantic Web Conference; Springer: Cham, Switzerland, 2018; pp. 617–633. [Google Scholar]
- Neppalli, V.K.; Caragea, C.; Caragea, D. Deep Neural Networks versus Naive Bayes Classifiers for Identifying Informative Tweets during Disasters. In Proceedings of the 15th ISCRAM Conference, Rochester, NY, USA, 20–23 May 2018. [Google Scholar]
- Ragini, J.R.; Anand, P.R.; Bhaskar, V. Mining crisis information: A strategic approach for detection of people at risk through social media analysis. Int. J. Disaster Risk Reduct. 2018, 27, 556–566. [Google Scholar] [CrossRef]
- Burel, G.; Alani, H. Crisis Event Extraction Service (CREES)-Automatic Detection and Classification of Crisis-related Content on Social Media. In Proceedings of the 15th ISCRAM Conference, Rochester, NY, USA, 20–23 May 2018. [Google Scholar]
- Qu, Y.; Huang, C.; Zhang, P.; Zhang, J. Microblogging after a major disaster in China: A case study of the 2010 Yushu earthquake. In Proceedings of the ACM 2011 Conference on Computer Supported Cooperative Work, Hangzhou, China, 19–23 March 2011; ACM: New York, NY, USA; pp. 25–34. [Google Scholar]
- Imran, M.; Elbassuoni, S.; Castillo, C.; Diaz, F.; Meier, P. Extracting information nuggets from disaster-related messages in social media. In Proceedings of the 10th International ISCRAM Conference, Baden-Baden, Germany, 20–23 May 2013. [Google Scholar]
- USGS (US Geological Survey). M6.0 South Napa, California Earthquake–August 24, 2014. Available online: https://www.usgs.gov/natural-hazards/earthquake-hazards/science/m60-south-napa-california-earthquake-august-24-2014?qt-science_center_objects=0#qt-science_center_objects (accessed on 20 November 2019).
- Chen, R.; Jaiswal, K.S.; Bausch, D.; Seligson, H.; Wills, C.J. Annualized earthquake loss estimates for California and their sensitivity to site amplification. Seismol. Res. Lett. 2016, 87, 1363–1372. [Google Scholar] [CrossRef]
- Parilla-Ferrer, B.E.; Fernandez, P.L.; Ballena, J.T. Automatic classification of disaster-related Tweets. In Proceedings of the International Conference on Innovative Engineering Technologies (ICIET), Barcelona, Spain, 16–17 December 2014. [Google Scholar]
- Li, H.; Caragea, D.; Caragea, C.; Herndon, N. Disaster response aided by tweet classification with a domain adaptation approach. J. Conting. Crisis Manag. 2018, 26, 16–27. [Google Scholar] [CrossRef] [Green Version]
- Joachims, T.A. support vector method for multivariate performance measures. In Proceedings of the 22nd International Conference on Machine Learning, Lausanne, Switzerland, 11–14 September 2005; pp. 377–384. [Google Scholar]
- Cresci, S.; Cimino, A.; Dell’Orletta, F.; Tesconi, M. Crisis mapping during natural disasters via text analysis of social media messages. In Proceedings of the International Conference on Web Information Systems Engineering, Miami, FL, USA, 1–3 November 2015; Springer: Cham, Switzerland, 2015; pp. 250–258. [Google Scholar]
- Ben-David, A. Comparison of classification accuracy using Cohen’s Weighted Kappa. Exp. Syst. Appl. 2008, 34, 825–832. [Google Scholar] [CrossRef]
- Bica, M.; Palen, L.; Bopp, C. Visual representations of disaster. In Proceedings of the 2017 ACM Conference on Computer Supported Cooperative Work and Social Computing, Jersey City, NJ, USA, 3–7 November 2017; pp. 1262–1276. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Binary Classification Algorithm | Accuracy | F-measure | Recall | Precision | Kappa |
|---|---|---|---|---|---|
| Naive Bayes | 71.22% | 63.03% | 64.91% | 61.25% | 0.249 |
| Deep Learning | 84.74% | 76.17% | 75.64% | 76.71% | 0.520 |
| SVM | 89.30% | 81.22% | 79.08% | 85.61% | 0.634 |
| Multi-Class Classification Algorithm | Accuracy | F-Measure | Recall | Precision | Kappa |
|---|---|---|---|---|---|
| Naive Bayes | 79.81% | 78.46% | 81.33% | 75.79% | 0.662 |
| Deep Learning | 86.76% | 83.43% | 80.26% | 86.86% | 0.762 |
| SVM | 90.25% | 81.22% | 88.58% | 93.26% | 0.825 |
| Algorithm | Spearman’s Rho | Pearson Correlation | Kendall’s Tau |
|---|---|---|---|
| Naive Bayes | 0.647 | 0.539 | 0.550 |
| Deep Learning | 0.8205 | 0.5217 | 0.6666 |
| SVM | 0.6655 | 0.5191 | 0.5714 |
| Algorithm | Spearman’s Rho | Pearson Correlation | Kendall’S Tau |
|---|---|---|---|
| Naive Bayes | −0.2132 | 0.4485 | −0.1424 |
| Deep Learning | 0.3216 | 0.4705 | 0.1975 |
| SVM | 0.4131 | 0.53 | 0.3607 |
| Algorithm | Spearman’s Rho | Pearson Correlation | Kendall’s Tau |
|---|---|---|---|
| Naive Bayes | 0.90 | 0.18 | 0.79 |
| Deep Learning | 0.9065 | 0.1821 | 0.7983 |
| SVM | 0.922 | 0.157 | 0.824 |
| Algorithm | Accuracy | Precision | Recall | F-Score |
|---|---|---|---|---|
| Naive Bayes | 35.20% | 35% | 42.7% | 38.66% |
| Deep Learning | 30.20% | 30.2% | 32.85% | 31.47% |
| SVM | 29.40% | 29.69% | 32% | 30.80% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ahadzadeh, S.; Malek, M.R. Earthquake Damage Assessment in Three Spatial Scale Using Naive Bayes, SVM, and Deep Learning Algorithms. Appl. Sci. 2021, 11, 9737. https://doi.org/10.3390/app11209737
Ahadzadeh S, Malek MR. Earthquake Damage Assessment in Three Spatial Scale Using Naive Bayes, SVM, and Deep Learning Algorithms. Applied Sciences. 2021; 11(20):9737. https://doi.org/10.3390/app11209737
Chicago/Turabian StyleAhadzadeh, Sajjad, and Mohammad Reza Malek. 2021. "Earthquake Damage Assessment in Three Spatial Scale Using Naive Bayes, SVM, and Deep Learning Algorithms" Applied Sciences 11, no. 20: 9737. https://doi.org/10.3390/app11209737
APA StyleAhadzadeh, S., & Malek, M. R. (2021). Earthquake Damage Assessment in Three Spatial Scale Using Naive Bayes, SVM, and Deep Learning Algorithms. Applied Sciences, 11(20), 9737. https://doi.org/10.3390/app11209737