
Hierarchical Visual Place Recognition Based on Semantic-Aggregation


Abstract
1. Introduction
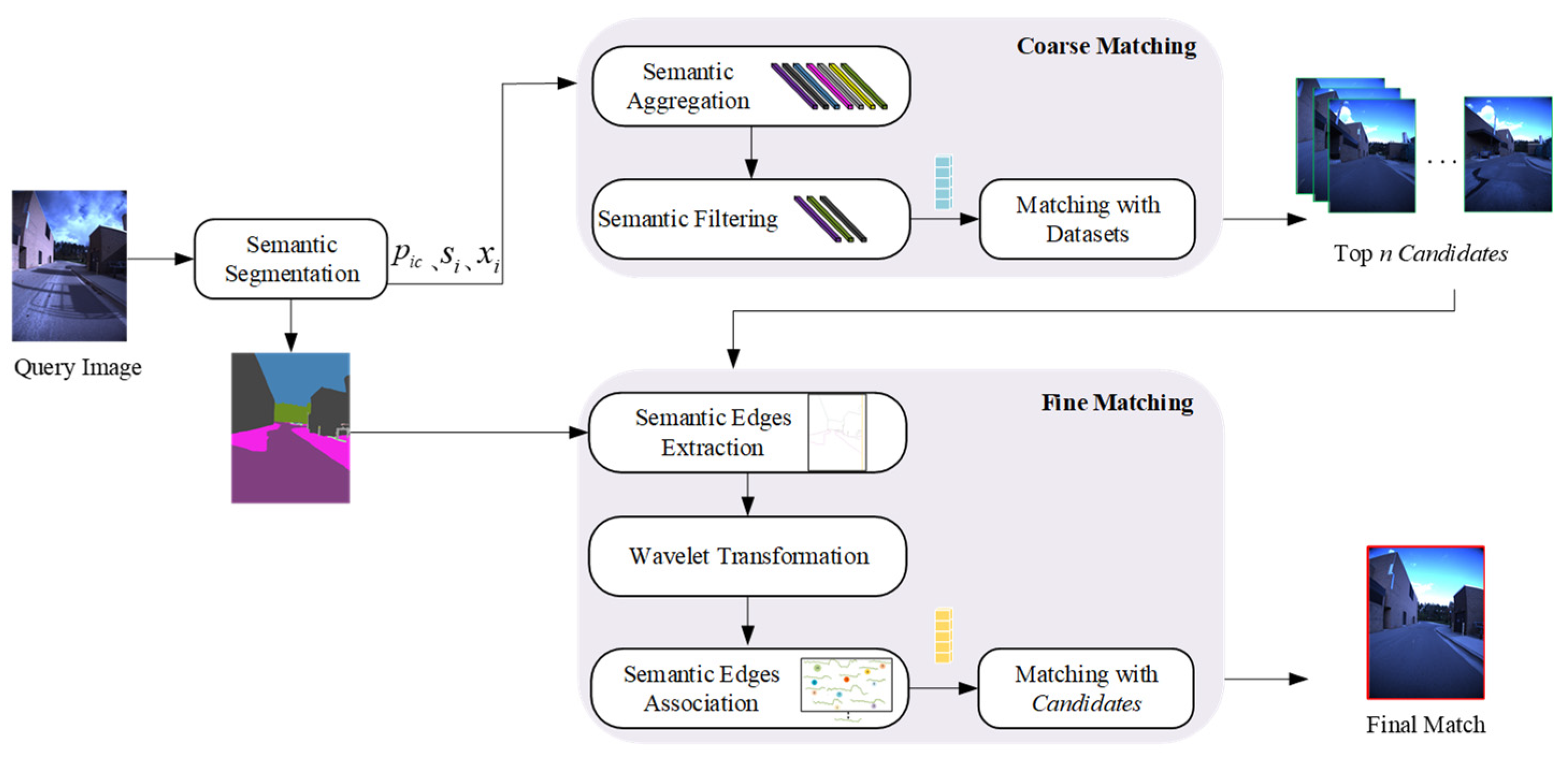
2. Hierarchical Visual Place Recognition Based on Semantic-Aggregation
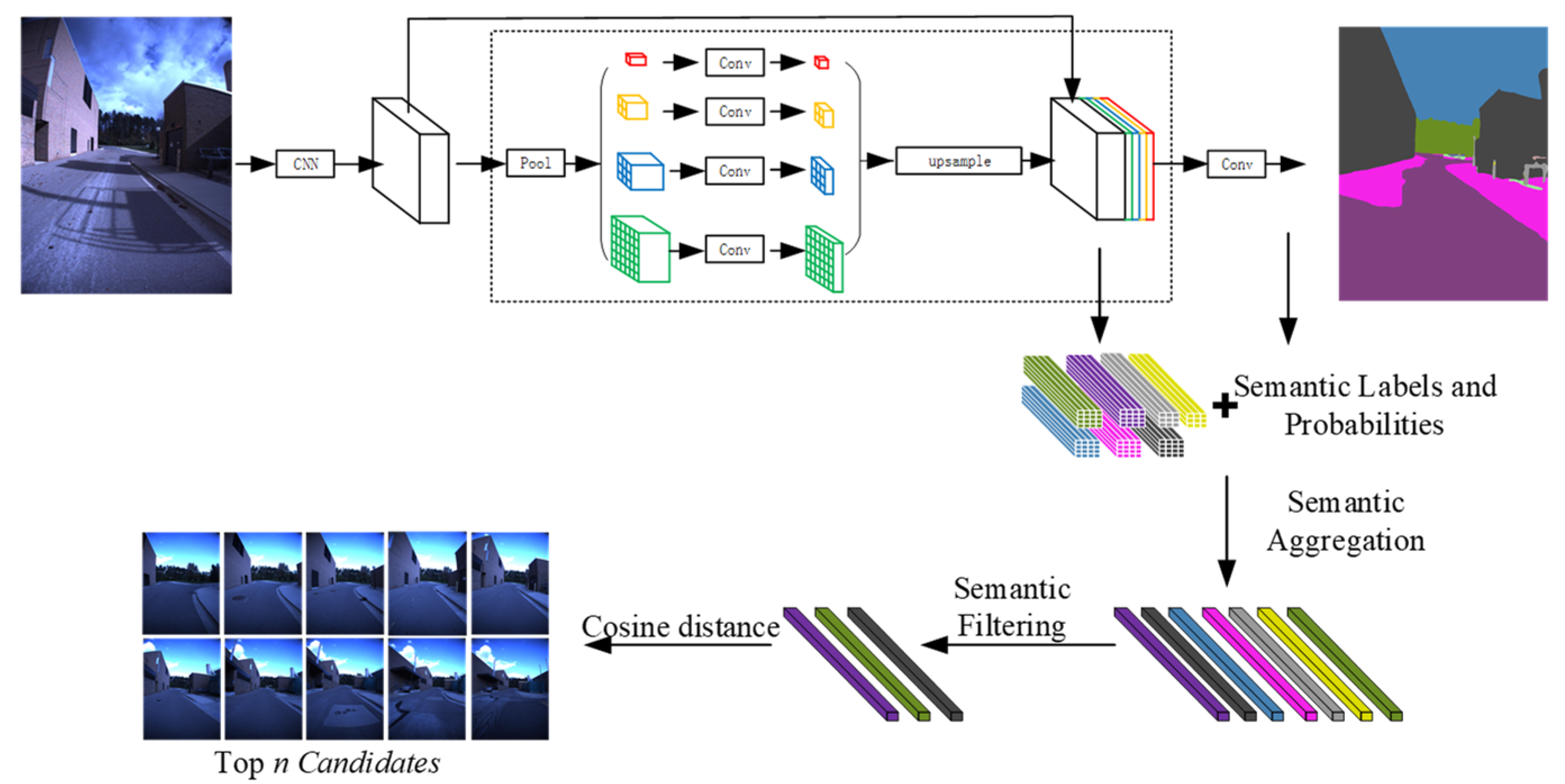
2.1. Coarse Matching
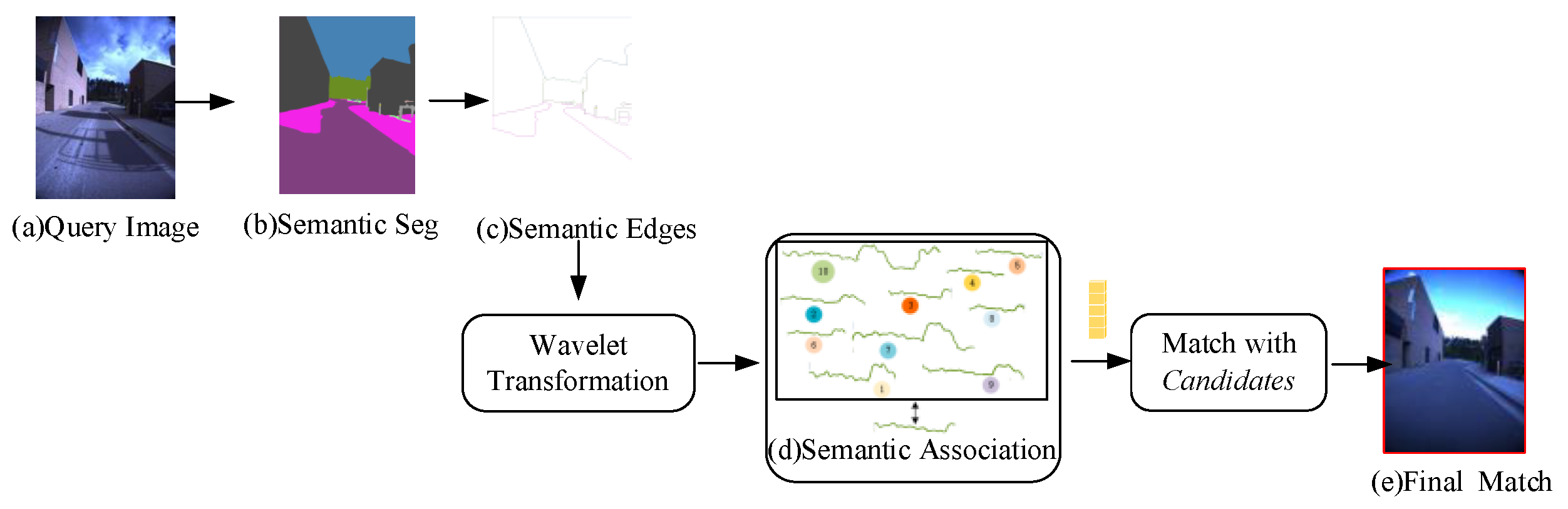
2.2. Fine Matching
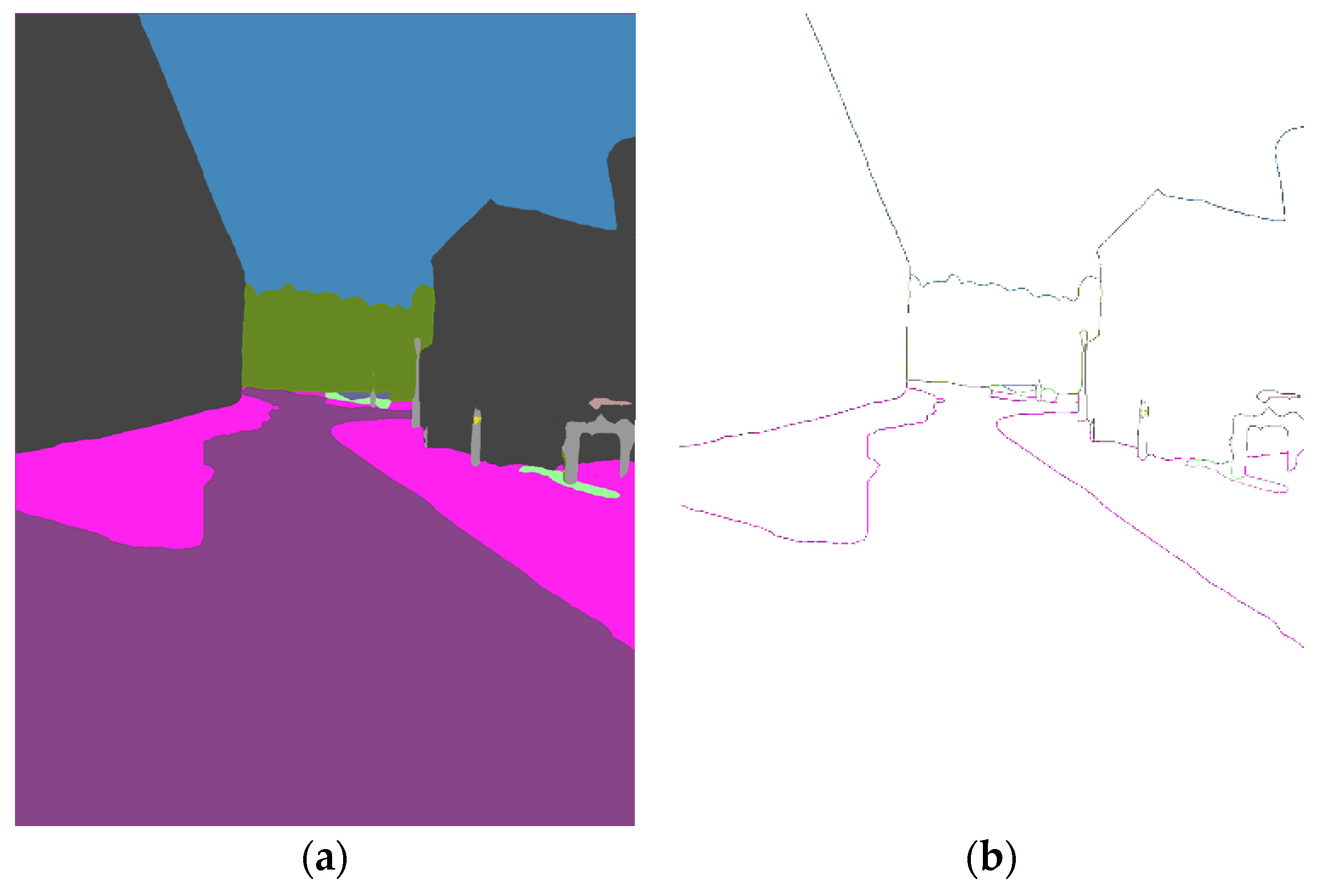
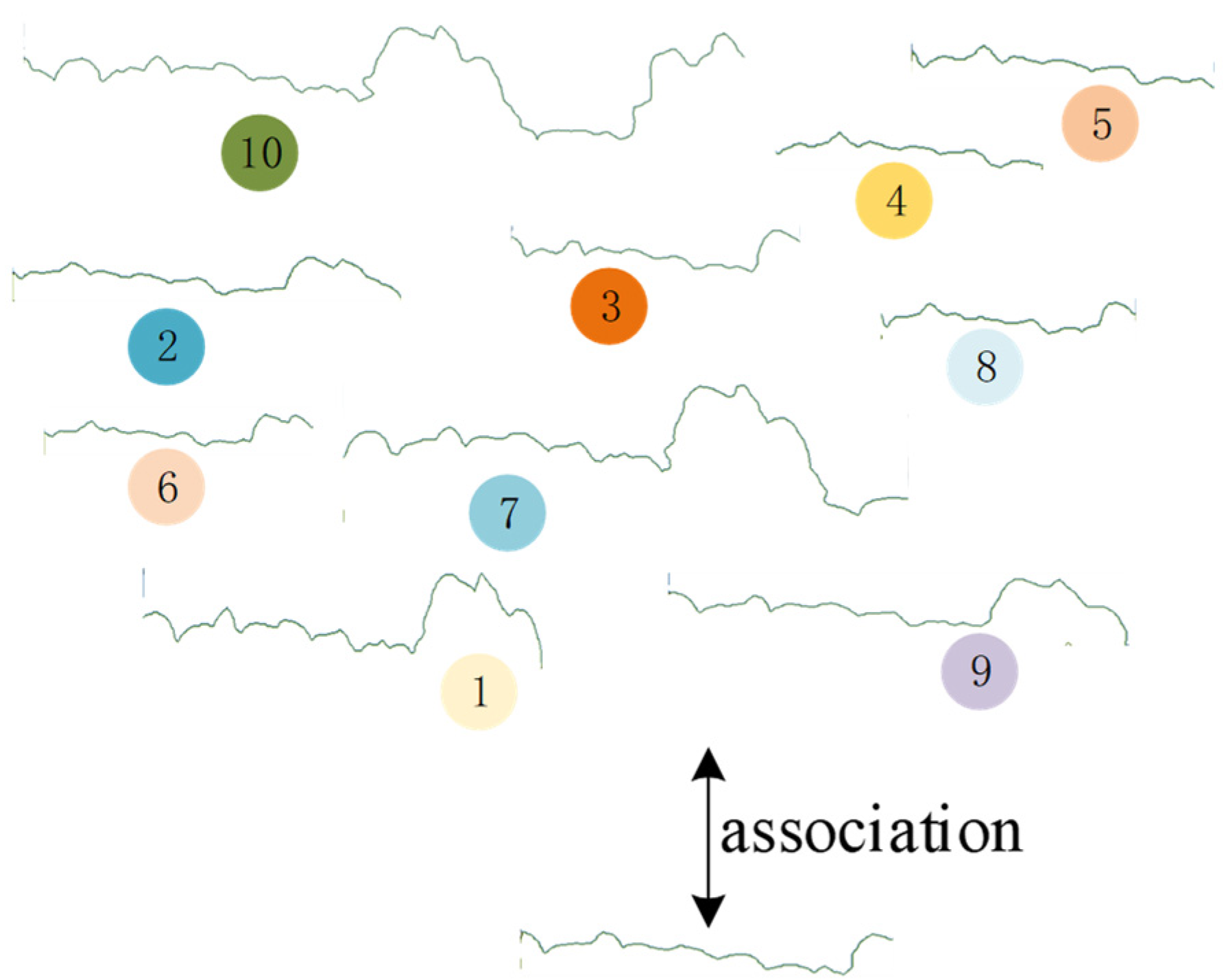
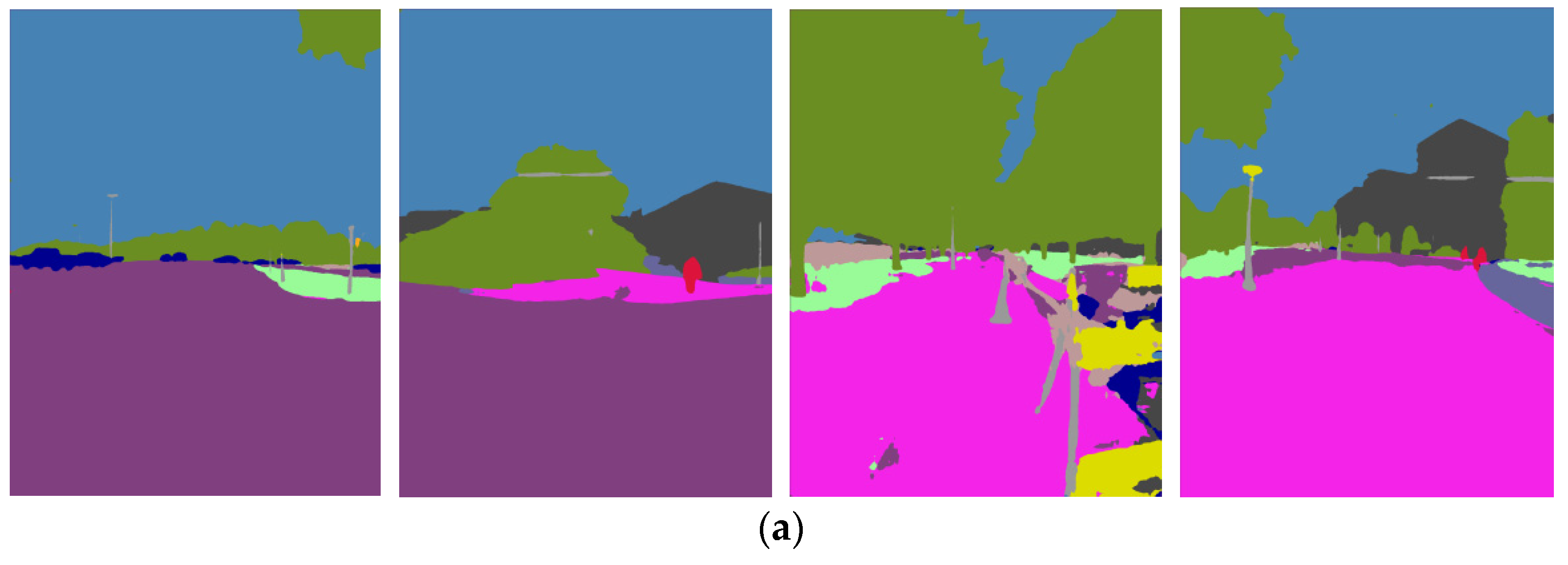
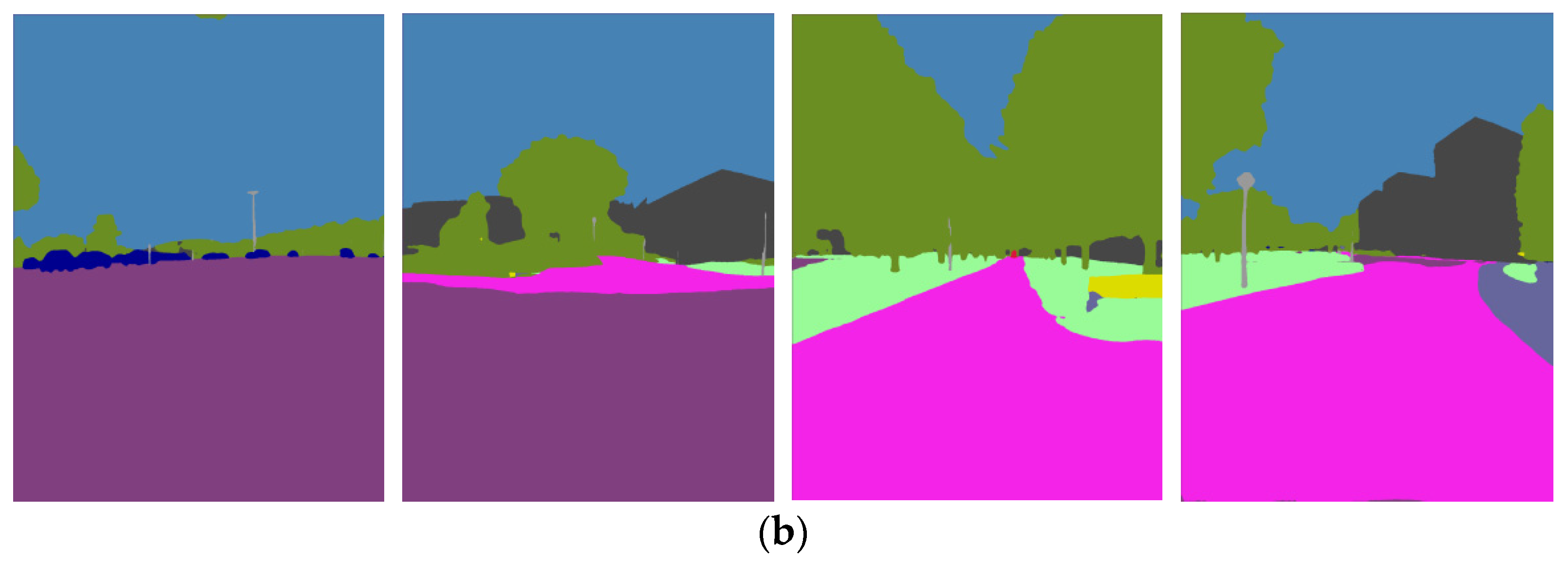
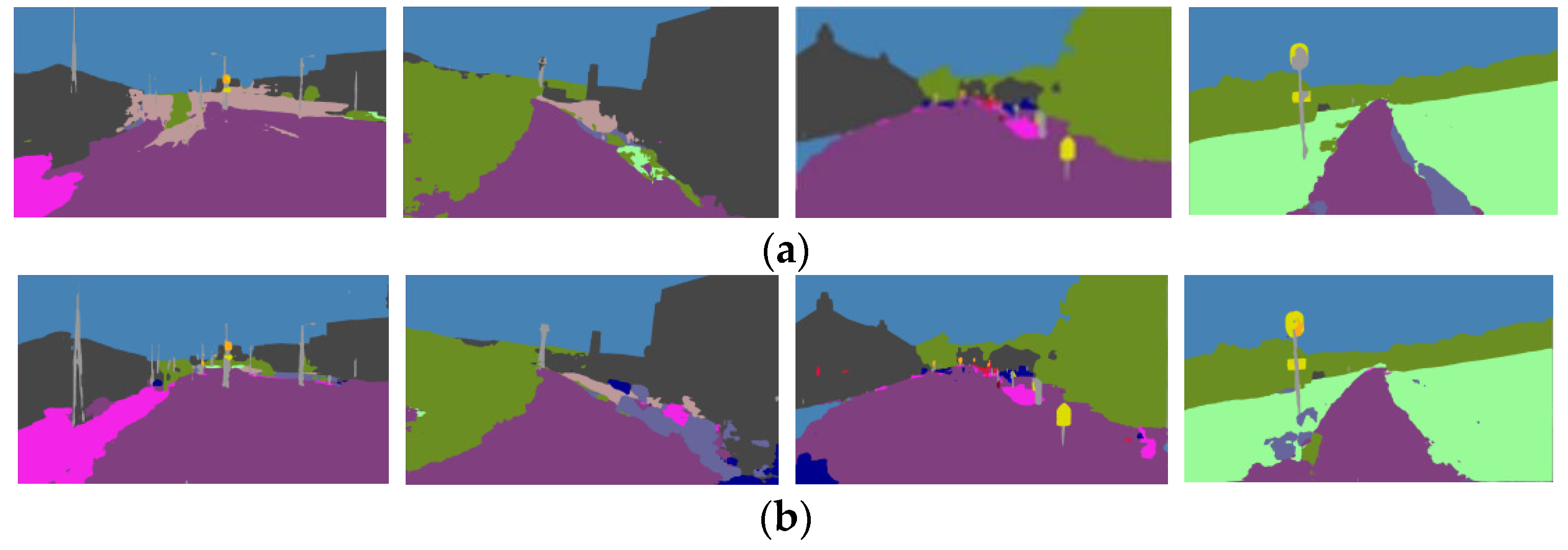
2.2.1. Semantic Edges Extraction and Description
2.2.2. Semantic Association and Matching
3. Experiments and Results
3.1. Datasets and Performance Evaluations
3.1.1. North Campus Dataset
3.1.2. Norland Dataset
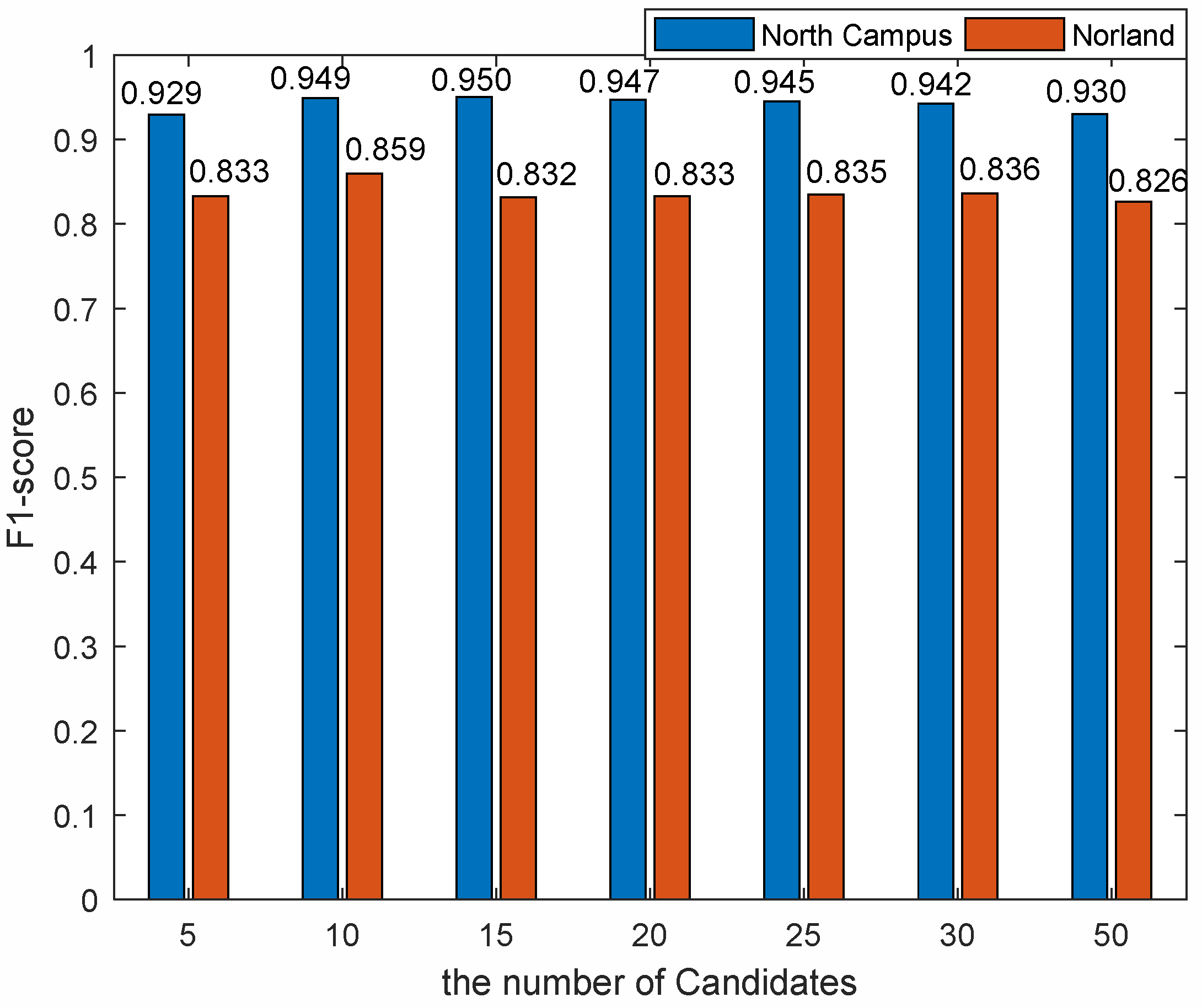
3.1.3. Performance Evaluations
3.2. Experimental Setup
3.3. Ablation Study (Effects for Hierarchy and Candidates)
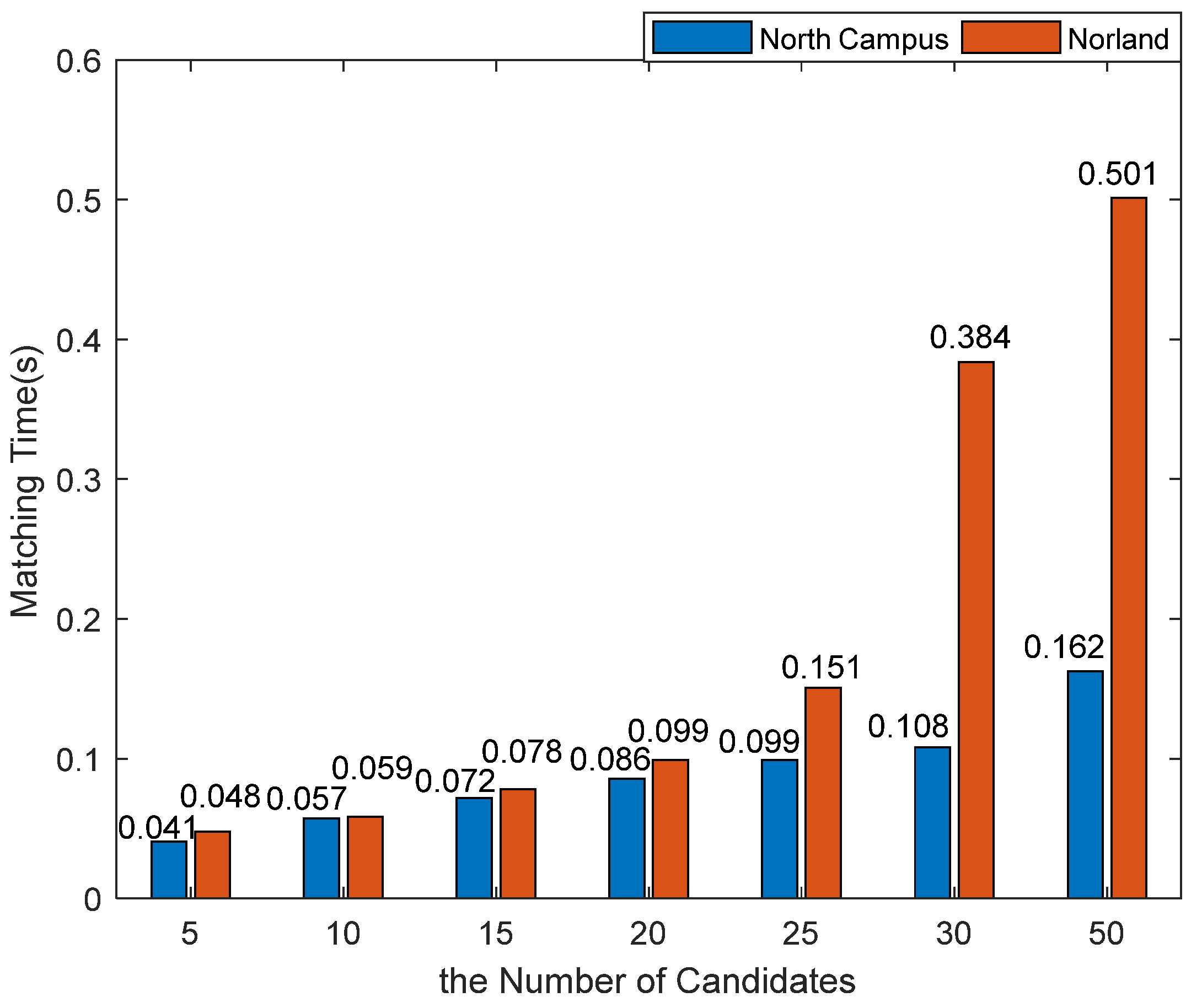
3.3.1. The Number of Candidates
3.3.2. Hierarchy or Single
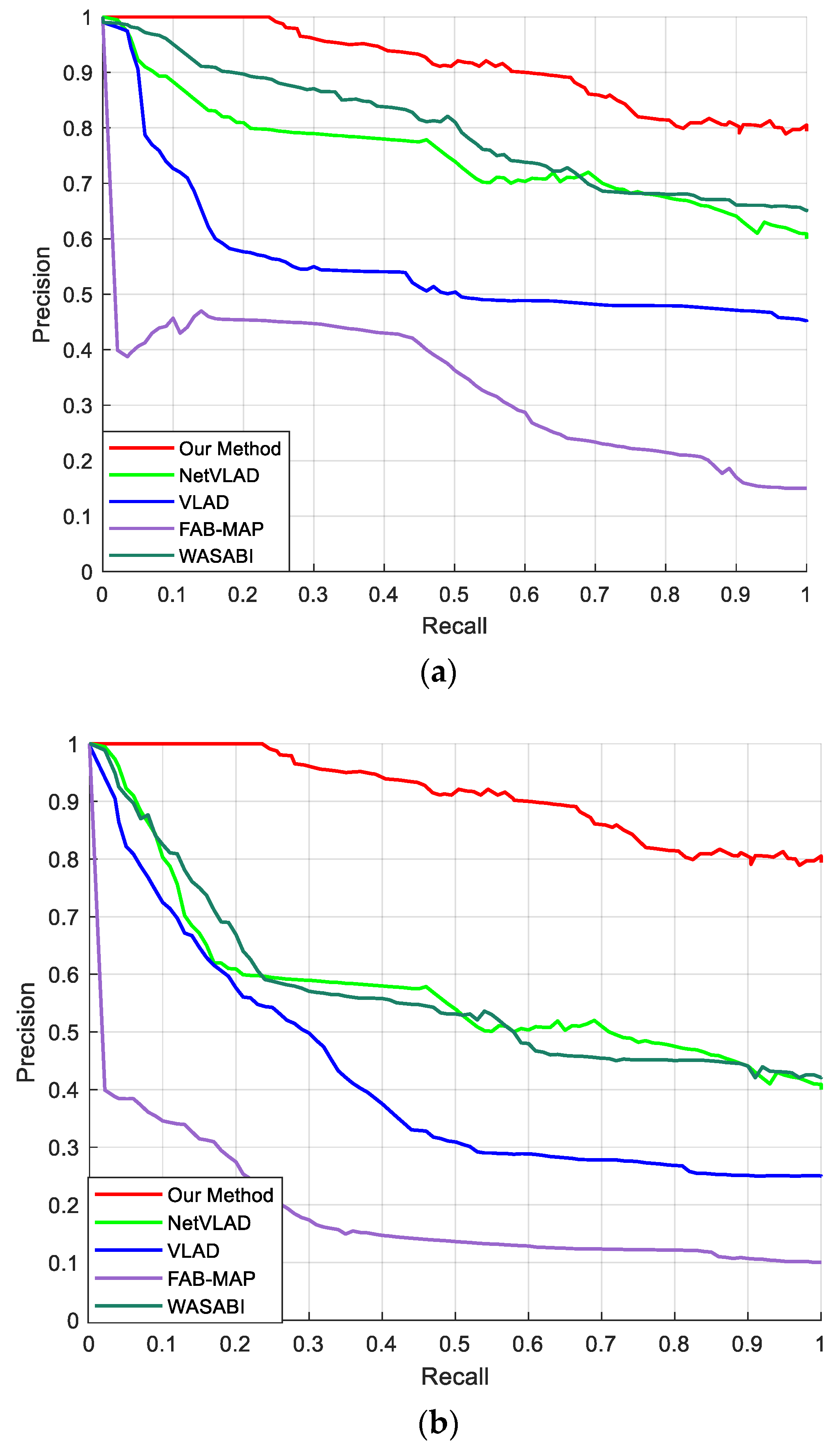
3.4. Comparison with the State-of-Art Methods
3.5. Runtime Analysis
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Sattler, T.; Leibe, B.; Kobbelt, L. Efficient & Effective Prioritized Matching for Large-Scale Image-Based Localization. IEEE Trans. Patt. Anal. Mac. Intell. 2016, 39, 1744–1756. [Google Scholar]
- Sattler, T.; Maddern, W.; Toft, C. Benchmarking 6dof outdoor visual localization in changing conditions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8601–8610. [Google Scholar]
- Brahmbhatt, S.; Gu, J.; Kim, K. Geometry-aware learning of maps for camera localization. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 2616–2625. [Google Scholar]
- Cummins, M.; Newman, P. FAB-MAP: Probabilistic localization and mapping in the space of appearance. Int. J. Robot. Res. 2008, 27, 647–665. [Google Scholar] [CrossRef]
- Galvez-Lpez, D.; Tardos, J.D. Bags of Binary Words for Fast Place Recognition in Image Sequences. IEEE Trans. Robot. 2012, 28, 1188–1197. [Google Scholar] [CrossRef]
- Lowry, S.; Sunderhauf, N.; Newman, P.; Leonard, J.J.; Cox, D.; Corke, P.; Milford, M.J. Visual Place Recognition: A Survey. IEEE Trans. Robot. 2016, 32, 1–19. [Google Scholar] [CrossRef]
- Milford, M.J.; Wyeth, G.F. SeqSLAM: Visual route-based navigation for sunny summer days and stormy winter nights. In Proceedings of the 2012 IEEE International Conference on Robotics and Automation (ICRA), Melbourne, Australia, 9–13 July 2012; pp. 1643–1649. [Google Scholar]
- Sattler, T.; Havlena, M.; Schindler, K.; Pollefeys, M. Large-scale location recognition and the geometric burstiness problem. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1582–1590. [Google Scholar]
- Lowe, D.G. Distinctive image features from scale-invariant keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Bay, H.; Ess, A.; Tuytelaars, T. Speeded-up robust features (SURF). Comput. Vis. Image Understand. 2008, 110, 346–359. [Google Scholar] [CrossRef]
- Nicosevici, T.; Garcia, R. Automatic visual bag-of-words for online robot navigation and mapping. IEEE Trans. Robot. 2012, 28, 886–898. [Google Scholar] [CrossRef]
- Milford, M.; Scheirer, W.; Vig, E. Condition-invariant top-down visual place recognition. In Proceedings of the 2014 IEEE International Conference on Robotics and Automation (ICRA), Hong Kong, China, 31 May–5 June 2014; pp. 5571–5577. [Google Scholar]
- Amato, G.; Bolettieri, P.; Falchi, F. Large scale image retrieval using vector of locally aggregated descriptors. In Proceedings of the International Conference on Similarity Search and Applications, A Coruña, Spain, 2–4 October 2013; Springer; Berlin/Heidelberg, Germany, 2013; pp. 245–256. [Google Scholar]
- Cadena, C.D.; Galvez-Lopez, D.; Tardos, J.D. Robust Place Recognition With Stereo Sequences. IEEE Trans. Robot. 2012, 28, 871–885. [Google Scholar] [CrossRef]
- Lu, F.; Chen, B.; Guo, Z. Visual sequence place recognition with improved dynamic time warping. In Proceedings of the 2019 IEEE 31st International Conference on Tools with Artificial Intelligence (ICTAI), Portland, OR, USA, 4–6 November 2019; pp. 1034–1041. [Google Scholar]
- Chen, B.; Yuan, D.; Liu, C.; Wu, Q. Loop closure detection based on multi-scale deep feature fusion. Appl. Sci. 2019, 9, 1120. [Google Scholar] [CrossRef]
- Wang, T.H.; Huang, H.J.; Lin, J.T.; Hu, C.W.; Zeng, K.H.; Sun, M. Omnidirectional cnn for visual place recognition and navigation. In Proceedings of the 2018 IEEE International Conference on Robotics and Automation (ICRA), Brisbane, Australia, 21–25 May 2018; pp. 2341–2348. [Google Scholar]
- Chen, Z.; Lin, O.; Jacobson, A. Convolutional neural network-based place recognition. arXiv 2014, arXiv:1411.1509. [Google Scholar]
- Sunderhauf, N.; Shirazi, S.; Dayoub, F. On the performance of convnet for place recognition. In Proceedings of the 2015 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Hamburg, Germany, 28 September–3 October 2015; pp. 4297–4304. [Google Scholar]
- Arandjelovic, R.; Gronat, P.; Torii, A. NetVLAD: CNN architecture for weakly supervised place recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 5297–5307. [Google Scholar]
- Chen, Z.; Maffra, F.; Sa, I. Only look once, mining distinctive landmarks from convnet for visual place recognition. In Proceedings of the 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Vancouver, BC, Canada, 24–28 September 2017; pp. 9–16. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net:Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; Springer; Cham, Switzerland, 2015; pp. 234–241. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. Segnet:A deep convolutional encoder-decoder architecture for image segmentation. IEEE Trans. Patt. Anal. Mach. Int. 2017, 39, 2481–2495. [Google Scholar] [CrossRef]
- Chen, L.C.; Papandreou, G.; Kokkinos, I. Deeplab:Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. IEEE Trans. Patt. Anal. Mach. Int. 2017, 40, 834–848. [Google Scholar] [CrossRef] [PubMed]
- Chen, L.C.; Papandreou, G.; Schroff, F. Rous Convolution of Semantic Image Segmentation. arXiv 2017, arXiv:1706.05587. [Google Scholar]
- Zhao, H.; Shi, J.; Qi, X. Pyramid scene parsing network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2881–2890. [Google Scholar]
- He, K.; Gkioxari, G.; Yuan, P. Mask R-CNN. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Garg, S.; Suenderhauf, N.; Milford, M. Don’t look back:Robustifying place categorization for viewpoint-and condition-invariant place recognition. In Proceedings of the 2018 IEEE International Conference on Robotics and Automation (ICRA), Brisbane, Australia, 21–25 May 2018; pp. 3645–3652. [Google Scholar]
- Garg, S.; Suenderhauf, N.; Milford, M. Semantic-geometric visual place recognition: A new perspective for reconciling opposing views. Int. J. Robot. Res. 2019. [Google Scholar] [CrossRef]
- Benbihi, A.; Arravechia, S.; Geist, M. Image-based place recognition on bucolic environment across seasons from semantic edge description. In Proceedings of the 2020 IEEE International Conference on Robotics and Automation (ICRA), Paris, France, 31 May–31 August 2020; pp. 3032–3038. [Google Scholar]
- Maohai, L.; Lining, S.; Qingcheng, H. Robust omnidirectional vision based mobile robot hierarchical localization and autonomous navigation. Inf. Technol. J. 2011, 10, 29–39. [Google Scholar] [CrossRef][Green Version]
- Garcia-Fidalgo, E.; Ortiz, A. Hierarchical place recognition for topological mapping. IEEE Trans. Robot. 2017, 33, 1061–1074. [Google Scholar] [CrossRef]
- Hausler, S.; Milford, M. Hierarchical multi-process fusion for visual place recognition. In Proceedings of the 2020 IEEE International Conference on Robotics and Automation (ICRA), Paris, France, 30 May–5 June 2020; pp. 3327–3333. [Google Scholar]
- Larsson, M.; Stenborg, E.; Hammarstrand, L. A cross-season correspondence dataset for robust semantic segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 9532–9542. [Google Scholar]
- He, K.; Zhang, X.; Ren, S. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Kokkinos, I. Semantic image segmentation with deep convolutional nets and fully connected crfs. arXiv 2014, arXiv:1412.7062. [Google Scholar]
- Yu, F.; Koltun, V. Multi-scale context aggregation by dilated convolutions. arXiv 2015, arXiv:1511.07122. [Google Scholar]
- Chuang, C.H.; Kuo, C. Wavelet descriptor of planar curves: Theory and applications. IEEE Trans. Image Proc. 1996, 5, 56–70. [Google Scholar] [CrossRef]
- Carlevaris-Bianco, N.; Ushani, A.K.; Eustice, R.M. University of Michigan North Campus long-term vision and lidar dataset. Int. J. Robot. Res. 2016, 35, 1023–1035. [Google Scholar] [CrossRef]
- Olid, D.; Fácil, J.M.; Civera, J. Single-view place recognition under seasonal changes. arXiv 2018, arXiv:1808.06516. [Google Scholar]
- Cordts, M.; Omran, M.; Ramos, S. The cityscapes dataset for semantic urban scene understanding. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 3213–3223. [Google Scholar]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| North Campus | Norland | |
|---|---|---|
| Environment | University of Michigan’s North Campus | Train ride |
| Collection tools | Segway robot | Train |
| No. of frames (Reference/Query) | 501/501 | 3600/3600 |
| Distance between adjacent images | 5 m | 20 m |
| Viewpoint variation | Severe | None |
| Illumination variation | Severe | Severe |
| Seasonal variation | Severe | Severe |
| Tolerance (frames) | 1 | 1 |
| The North Campus Dataset | The Norland Dataset | |
|---|---|---|
| Hierarchical strategy with Candidates 10. | 0.94856 | 0.85944 |
| Hierarchical strategy with Candidates 15. | 0.95046 | 0.83152 |
| Coarse matching only | 0.85045 | 0.75051 |
| Fine matching only | 0.90979 | 0.80217 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, B.; Song, X.; Shen, H.; Lu, T. Hierarchical Visual Place Recognition Based on Semantic-Aggregation. Appl. Sci. 2021, 11, 9540. https://doi.org/10.3390/app11209540
Chen B, Song X, Shen H, Lu T. Hierarchical Visual Place Recognition Based on Semantic-Aggregation. Applied Sciences. 2021; 11(20):9540. https://doi.org/10.3390/app11209540
Chicago/Turabian StyleChen, Baifan, Xiaoting Song, Hongyu Shen, and Tao Lu. 2021. "Hierarchical Visual Place Recognition Based on Semantic-Aggregation" Applied Sciences 11, no. 20: 9540. https://doi.org/10.3390/app11209540
APA StyleChen, B., Song, X., Shen, H., & Lu, T. (2021). Hierarchical Visual Place Recognition Based on Semantic-Aggregation. Applied Sciences, 11(20), 9540. https://doi.org/10.3390/app11209540