
An Improved Multiple Features and Machine Learning-Based Approach for Detecting Clickbait News on Social Networks

 ,
,  ,
,  ,
,  ,
,  ,
,  ,
,  , and
, and
Abstract
:1. Introduction
- We constructed the first Arabic clickbait headline news dataset. The raw dataset is available publicly for research purpose.
- We extracted a set of user-based features and content-based features for the constructed Arabic clickbait dataset.
- We implemented six machine learning-based classifiers, including Random Forest (RF), Stochastic Gradient Descent (SGD), Support Vector Machine (SVM), Logistic Regression (LR), Multinomial Naïve Bayes (NB), and k-Nearest Neighbor (k-NN).
- We proposed an effective approach for enhancing the detection process using a feature selection technique, namely a one-way ANOVA F-test.
- We conducted extensive experiments, and the results show that the proposed model enhances the performance of some classifiers in terms of accuracy, precision, and recall.
2. Related Works
2.1. Characteristics of Clickbait News
2.2. Machine Learning and Deep Learning Methods for Clickbait Detection
2.3. Problem Formulation for Clickbait Detection
3. Materials and Methods
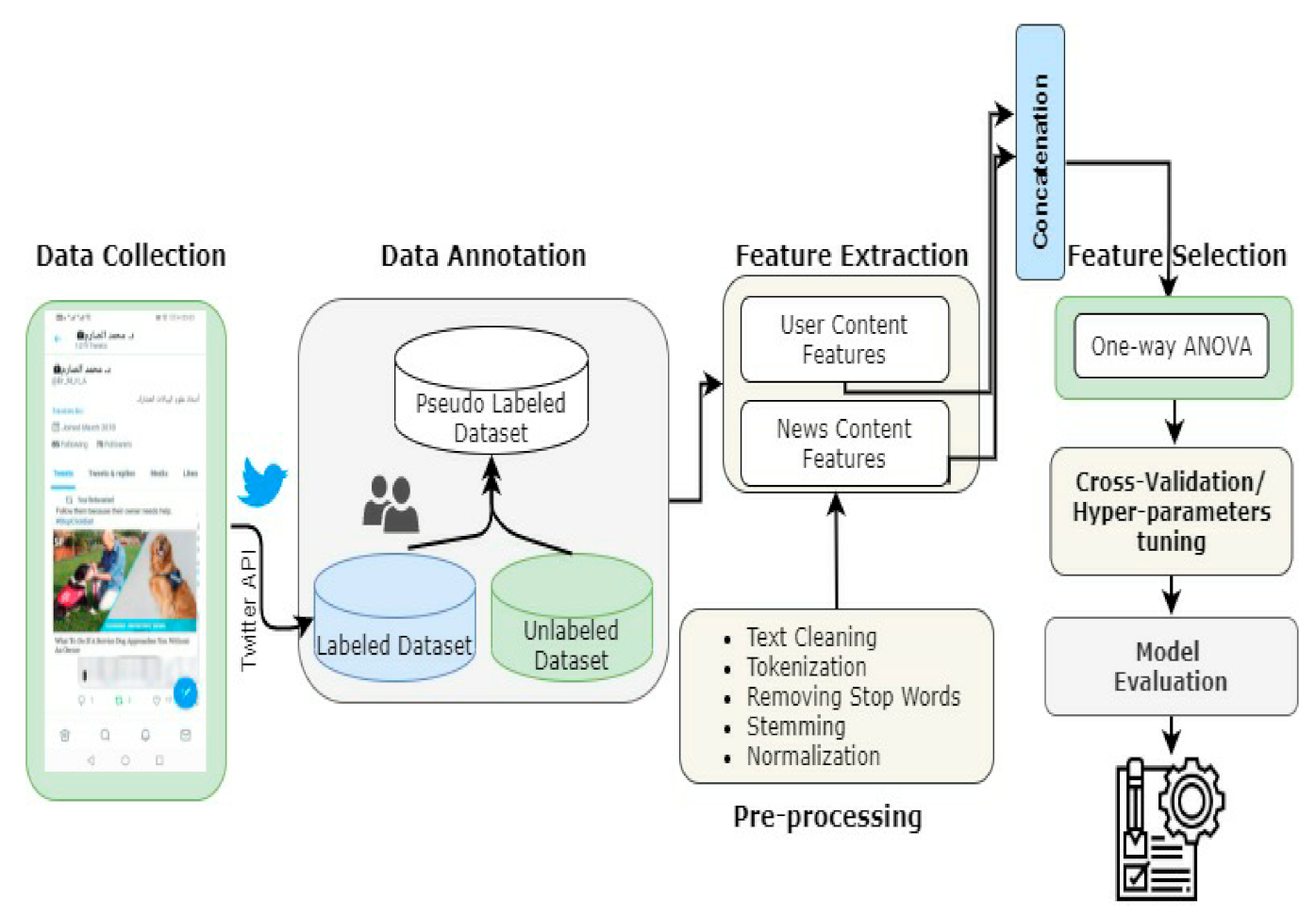
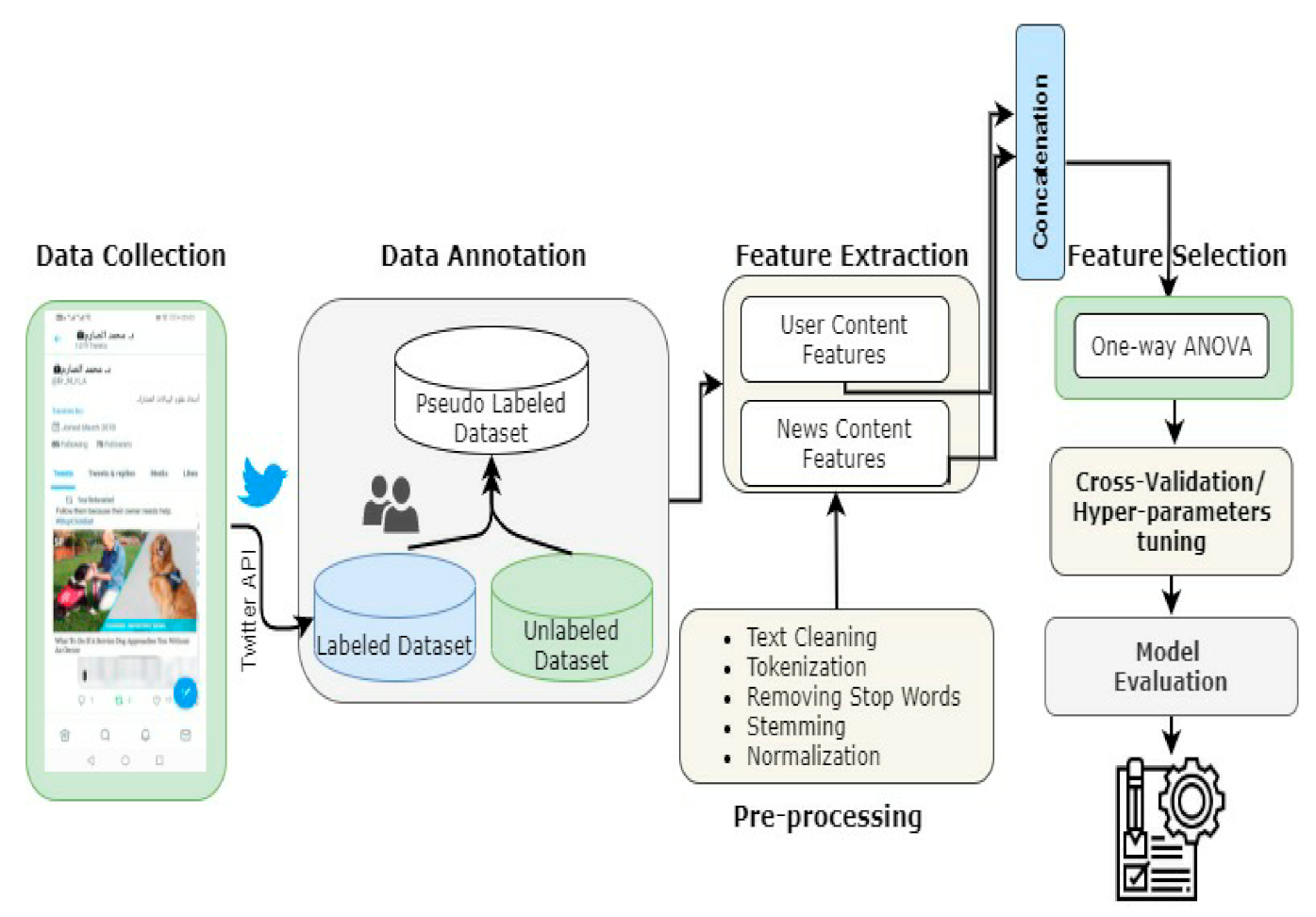
3.1. Data Collection
| Algorithm 1 Pseudocode of dataset collection process for extracting UFs and CFs |
| Input: A list of public Twitter breaking news agencies’ profiles |
| Output: Unlabelled dataset with UFs and CFs |
| For each profile do: |
| Access public page of |
| Retrieve all shared tweets |
| Pull out using Twitter APIs tweet’s features (USs) |
| If contains an external URL Then: |
| Visit the external webpage |
| For all html tags in do: |
| Find html tag that contains news full text (CFs)Compute similarity score between and |
| End |
| End if |
| Store the extracted features in csv format |
| End |
3.2. Data Annotation
3.3. Pre-Processing and Numeric Representation
3.3.1. Pre-Processing
3.3.2. Numeric Representation
3.4. Feature Selection
| Algorithm 2 Pseudocode for selecting features-based FV-ANOVA method. |
| Input: -dataset, features extracted as numeric representation by TF-IDF, -class label and percentile. |
| Output: subset of top-scoring features based on the given |
| number of classes in |
| number of features in |
| For each pair do: |
| Count number of samples per class |
| Compute (mean, standard deviation, standard error) of each with respect to |
| Compute degree of freedom between/within classes () |
| Compute sum of square of ) |
| Find mean square between groups as |
| Find mean square between groups as |
| End for |
| Sort in ascending order |
| Select the top-scoring features based on |
| Return |
3.5. Feature Selection
3.6. Model Evaluation
4. Experimental Design
5. Results and Findings
- When the content-based features were used, the classifiers performed well and SVM, NB, and RF achieved notable results using 10% of top-scoring features compared to their results in the baseline experiment. Among these methods, SVM obtained the best accuracy (91.83%) for content-based features.
- In most cases of experiments with content-based features, all classifiers showed good results when the one-way ANOVA method was used as feature selection, except k-NN and LR. It is notable that k-NN had the worst performance when the number of selected features increased to 10% and 15%.
- Increasing the percentage of the top-scoring features to more than 10% leads to a reduction in the performance of the ML classifiers.
- RF and SVM benefited more when the user-based features were used, compared to their results in the baseline experiment.
- The result for LR remained constant, and no change was observed when user-based features were fed into the classifier.
- The k-NN and SGD do not benefit from the ANOVA-based feature selection at all for user-based features.
- Combining user-based features and content-based features shows an improvement in the performance of ML classifiers and only LR and k-NN classifiers did not show any improvement.
- The SVM outperforms all other classifiers and benefited more when the proposed feature selection method was used for the combination of user-based features and content-based features. The highest accuracy achieved was 92.16%.
- As the total number of features for the combination of user-based and content-based features is 10,251, selecting the top 10% of these features (2194) was more suitable for SVM, which performed well with low dimensionality data.
- As shown in the results, using the user-based features achieved lower performance than using the content-based features for all ML methods. Therefore, the proposed model relies more on the content-based features and the combined ones.
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Chen, Y.; Conroy, N.J.; Rubin, V.L. Misleading Online Content: Recognizing Clickbait as “False News”. In Proceedings of the 2015 ACM on Workshop on Multimodal Deception Detection, Washington, DC, USA, 13 November 2015; pp. 15–19. [Google Scholar]
- Biyani, P.; Tsioutsiouliklis, K.; Blackmer, J. “8 Amazing Secrets for Getting More Clicks”: Detecting Clickbaits in News Streams Using Article Informality. In Proceedings of the Thirtieth AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 12–17 February 2016. [Google Scholar]
- Potthast, M.; Kopsel, S.; Stein, B.; Hagen, M. Clickbait Detection. In Advances in Information Retrieval. 38th European Conference on IR Research (ECIR 16); Springer: Cham, Switzerland, 2016; pp. 810–817. [Google Scholar]
- Chakraborty, A.; Paranjape, B.; Kakarla, S.; Ganguly, N. Stop clickbait: Detecting and preventing clickbaits in online news media. In Proceedings of the 2016 IEEE/ACM international conference on advances in social networks analysis and mining (ASONAM), Davis, CA, USA, 18–21 August 2016; pp. 9–16. [Google Scholar]
- Khater, S.R.; Al-sahlee, O.H.; Daoud, D.M.; El-Seoud, M. Clickbait detection. In Proceedings of the 7th International Conference on Software and Information Engineering, Cairo, Egypt, 4–6 May 2018; pp. 111–115. [Google Scholar]
- López-Sánchez, D.; Herrero, J.R.; Arrieta, A.G.; Corchado, J.M. Hybridizing metric learning and case-based reasoning for adaptable clickbait detection. Appl. Intell. 2017, 48, 2967–2982. [Google Scholar] [CrossRef]
- Agrawal, A. Clickbait Detection Using Deep Learning. In Proceedings of the 2016 2nd international conference on next generation computing technologies (NGCT), Dehradun, India, 14–16 October 2016; pp. 268–272. [Google Scholar]
- Kaur, S.; Kumar, P.; Kumaraguru, P. Detecting clickbaits using two-phase hybrid CNN-LSTM biterm model. Expert Syst. Appl. 2020, 151, 113350. [Google Scholar] [CrossRef]
- Zheng, H.T.; Chen, J.Y.; Yao, X.; Sangaiah, A.K.; Jiang, Y.; Zhao, C.Z. Clickbait convolutional neural network. Symmetry 2018, 10, 138. [Google Scholar] [CrossRef] [Green Version]
- Naeem, B.; Khan, A.; Beg, M.O.; Mujtaba, H. A deep learning framework for clickbait detection on social area network using natural language cues. J. Comput. Soc. Sci. 2020, 3, 231–243. [Google Scholar] [CrossRef]
- Bazaco, A.; Redondo, M.; Sánchez-García, P. Clickbait as a strategy of viral journalism: Conceptualisation and methodst. Rev. Lat. De Comun. Soc. 2019, 74, 94–115. [Google Scholar]
- Jain, M.; Mowar, P.; Goel, R.; Vishwakarma, D.K. Clickbait in Social Media: Detection and Analysis of the Bait. In Proceedings of the 2021 55th Annual Conference on Information Sciences and Systems (CISS), Baltimore, MD, USA, 24–26 March 2021; pp. 1–6. [Google Scholar]
- Chawda, S.; Patil, A.; Singh, A.; Save, A. A Novel Approach for Clickbait Detection. In Proceedings of the 2019 3rd International Conference on Trends in Electronics and Informatics (ICOEI), Tirunelveli, India, 23–25 April 2019; pp. 1318–1321. [Google Scholar]
- Aburas, A.A.; Gumah, M.E. Arabic Handwriting Recognition: Challenges and Solutions. In Proceedings of the 2008 International Symposium on Information Technology, Kuala Lumpur, Malaysia, 26–28 August 2008. [Google Scholar]
- Al-Nuzaili, Q.A.; Hashim, S.Z.M.; Saeed, F.; Khalil, M.S.; Mohamad, D.B. Pixel distribution-based features for offline Arabic handwritten word recognition. Int. J. Comput. Vis. Robot. 2017, 7, 99–122. [Google Scholar] [CrossRef]
- Al-Sarem, M.; Cherif, W.; Wahab, A.A.; Emara, A.H.; Kissi, M. Combination of stylo-based features and frequency-based features for identifying the author of short Arabic text. In Proceedings of the 12th International Conference on Intelligent Systems: Theories and Applications, Rabat, Morocco, 24–25 October 2018; pp. 1–6. [Google Scholar]
- Cao, X.; Le, T. Machine learning based detection of clickbait posts in social media. arXiv 2017, arXiv:1710.01977. [Google Scholar]
- Zhou, Y. Clickbait detection in tweets using self-attentive network. arXiv 2017, arXiv:1710.05364. [Google Scholar]
- Dong, M.; Yao, L.; Wang, X.; Benatallah, B.; Huang, C. Similarity-aware deep attentive model for clickbait detection. In Advances in Knowledge Discovery and Data Mining; Springer: Cham, Switzerland, 2009; Volume 11440, pp. 56–69. [Google Scholar]
- Sahoo, S.R.; Gupta, B.B. Multiple features based approach for automatic fake news detection on social networks using deep learning. Appl. Soft Comput. 2021, 100, 106983. [Google Scholar] [CrossRef]
- Lee, D.-H. Pseudo-Label: The Simple and Efficient Semi-Supervised Learning Method for Deep Neural Networks. In Workshop on Challenges in Representation Learning; ICML: Atlanta, GA, USA, 2013; Volume 3, p. 2. [Google Scholar]
- Al-Sarem, M.; Saeed, F.; Alsaeedi, A.; Boulila, W.; Al-Hadhrami, T. Ensemble methods for instance-based Arabic language authorship attribution. IEEE Access 2020, 8, 17331–17345. [Google Scholar] [CrossRef]
- Bahassine, S.; Madani, A.; Al-Sarem, M.; Kissi, M. Feature selection using an improved Chi-square for Arabic text classification. J. King Saud Univ.-Comput. Inf. Sci. 2020, 32, 225–231. [Google Scholar] [CrossRef]
- Elssied, N.O.F.; Ibrahim, O.; Osman, A.H. A novel feature selection based on one-way ANOVA F-test for e-mail spam classification. Res. J. Appl. Sci. Eng. Technol. 2014, 7, 625–638. [Google Scholar] [CrossRef]

{kind=link}
| Study | Dataset | Classificatio Method(s) | Accuracy of the Model(s) | Issues/Future Directions |
|---|---|---|---|---|
| [2] | The dataset includes 1349 clickbait and 2724 non-clickbait websites from different news websites whose pages surfaced on the Yahoo homepage. | Gradient Boosted Decision Trees (GBDT) | 0.76 | (1) Include the non-textual features (example: images and videos) and the comments of users on articles. (2) Find the most effective types of clickbait that can attract clicks and propose methods to block them. (3) Deep learning is proposed to be applied to obtain more indicators for clickbaits.The obtained performance needs to be improved. |
| [3] | The dataset includes 2992 tweets from Twitter, 767 of which are clickbait. | Logistic regression, naive Bayes, and random forest | 0.79 | The first evaluation corpus was proposed with baseline detection methods. However, this task needs more investigation to detect clickbait between different social media, and improving the performance of detection. The obtained performance needs to be improved |
| [17] | Clickbait Challenge 2017 Dataset includes over 21,000 headlines. | Random Forest Regression | 0.82 | Future works can be: (1) Extract more features; (2) apply other machine learning methods; (3) collect more high-quality data. The obtained performance needs to be improved. |
| [12] | CLDI dataset from Instagram includes 7769 instances and WCC dataset from Twitter includes 19538 instances. | KNN, LR, SVM, GNB, XGB, MLP, | 0.87 | Future works: Develop the model as a website or mobile application for Twitter and Instagram. The obtained performance needs to be improved. |
| [9] | The dataset contains 14,922 headlines, where half of them are clickbait. These headlines are taken from four famous Chinese news websites | Clickbait convolutional neural network (CBCNN) | 0.80 | The maximum length of the headline is limited. If the headlines are long, this might cause information loss. This needs more investigation to solve information-loss problem and including user-behavior analysis. The obtained performance needs to be improved. |
| [10] | Dataset of head-lines from Reddit,. The datasets includes 16,000 legitimate news and 16,000 clickbait samples. | LSTM using word2vec word embedding | 0.94 | The good accuracy was obtained due to the loop back approach that was employed by the LSTM that allows for a better understanding of the context and then better classification of headlines. |
| [6] | The dataset was collected from Reddit, Facebook and Twitter. It includes 814 clickbait samples and 1574 nonclickbait samples. | Convolutional neural network | 0.90 | Future works include (1) Find the most important features needed for learning process. (2) Gather more data to develop better models (3) Develop web application that can utilize this model and can alert the user to the clickbait websites. |
| [13] | The dataset includes 32,000 headlines that includes 16,000 clickbait and 16,000 non-clickbait titles. | Recurrent Convolutional Neural Network (RCNN) + Long Short Term Memory (LSTM) and Gated Recurrent Unit (GRU) | 0.97 | A larger dataset can be used. |
| [18] | The three datasets (A, B and C) from Clickbait Challenge 2017 were used. It includes 2495, 80,012 and 19,538 respectively. | Self-attentive RNN | 0.86 | The obtained performance needs to be improved. |
| [19] | Clickbait Challenge datasets include 20,000 pairs of training and validation posts. FNC dataset includes 49,972 pairs of training and validation posts. | Deep Semantic Similarity Model (DSSM) | 0. 86 | The other features like image information were not considered in this work. Also, the obtained performance needs to be improved. |
| # Feature | Feature Name | Description |
|---|---|---|
| User ID | Every user has one unique ID. | |
| Name | The name of the user who post news on Twitter | |
| Screen name | The screen name that this user identifies themselves with. | |
| Date of join | The creation time of the user account | |
| #Url | Number of URL provided by the user in association with their profile | |
| Profile description | A text that shows how the user describs his/her account | |
| Verified | A boolean indicator shows whether the user has a verified account or not | |
| Count of followers | Total number of followers | |
| Count of friends | Numeric value indicates how many friends that the user has | |
| Count of favorites’ accounts | Numeric value indicates how many tweets this user has liked | |
| Count of public lists | Total number of public lists that this user is a member of. | |
| Location | The geographical location | |
| Hashtage | The associated hashtag with the post | |
| Lang | The post language | |
| Number of post shared | Total number of content shared by the user |
| # Feature | Feature Name | Description |
|---|---|---|
| #Url | Number of external URLs provided by the user in association with news | |
| Source | Name of the source of the news article. | |
| Headline | The headline of the news article for catching the reader’s attention | |
| Tweet Text | The body of the tweet news | |
| Body Text | The full news in readable format, often with external content | |
| Retweet count | Total number of times this tweet has been retweeted. | |
| media | Boolean value indicates whether there are associated images or videos | |
| Similarity score | The score for similarity between headline text and body text. | |
| Creation date | The posted date of the news content |
| Type | Definition | Example of Arabic Clickbait News | Translation of the Arabic Clickbait News |
|---|---|---|---|
| Ambiguous | Title unclear or confusing to spur curiosity. | هذا الأمر لم يحدث في المملكة؟ | This matter did not happen in the kingdom. |
| Exaggeration | The title exaggerates the content of the landing page. | الراجل ده كريم أوى يا بابا.. زبون يأكل بـ20 دولار ويترك 1400 بقشيش بأمريكا | This man is kind father. In America, the customer eats for $20 and leaves 1400 tips |
| Inflamm-atory | Either phrasing or use of inappropriate/vulgar words. | اطباء تحت مسمى الطب ” الاطباء المجرمين “ | Doctors under the name of medicine “criminal doctors” |
| Teasing | Omission of details from title to build suspense: teasing. | بين ليلة وضحاها... أمريكي يربح مليار دولار | Overnight... an American wins a billion dollars |
| Formatt-ing | Excessive use of punctuation or exclamation marks. | “كيف أنتِ عمياء ومصوِّرة”؟!.. هذه العبارة السلبية كانت انطلاقة “المطيري” | “How are you blind and a photographer”?!.. This negative phrase was the launch of “Al-Mutairi” |
| Wrong | Just plain incorrect article: factually wrong. | 10أمور يقوم بها الأغنياء ولا تقوم بها نفسك! | 10 things rich people do that you don’t do yourself! |
| URL redirection | The thing promised/im-lied from the title is not on the landing page: it requires additional clicks or just missing. | كندا: ينمو الناتج المحلي الإجمالي الحقيقي بنسبة 0.7٪ في نوفمبر مقابل 0.4٪ المتوقعة | Canada: Real GDP grows 0.7% in November vs. 0.4% expected |
| Incomplete | The title is incomplete | عاجل :تطور في أرامكو و مدينة صناعية… - | Urgent: An improvement in Aramco and an industrial city |
| Parameter | # of Treated Data |
|---|---|
| Total news in dataset | 12,321 |
| Remaining baseline dataset | 11,068 |
| % of treated news in respect to the whole dataset | 17% |
| Clickbait news items, % | 4325, 35.1% |
| Legitimate news items, % | 6743, 54.72% |
| Incomplete posts, % | 1253, 10.16% |
| Number of external URLs | 4862 |
| Number of breaking news sources | 7 |
| Parameter | # of Treated Data |
|---|---|
| Total no. of news items in the dataset, | 54,893 |
| % of treated news items with respect to the whole dataset | 75.90% |
| No. of clickbait items, % of the total news items | 23,981, 43.69% |
| No. of legitimate news items, % of the total items | 30,912, 56.31% |
| Number of external URLs | 14,518 |
| Number of breaking news sources | 22 |
| ML Classifier | Hyper-Parameters Used for Tuning the Model | Best Values of Hyper-Parameters |
|---|---|---|
| RF | Criterion = [entropy, gini] max_depth = [10–1200] + [None] min_samples_leaf = [3–13] min_samples_split = [5–10] n_estimators = [150–1200] | Criterion = gini max_depth = 142 min_samples_leaf = 3 min_samples_split = 7 n_estimators: 300 |
| SGD | alpha = [, , , , 0.1, 1] loss = [log, hinge] max_iter= [10–1000] Penalty= [l2′, ‘l1’, ‘elasticnet’] | alpha= loss = log max_iter = 1000 Penalty = l2 |
| SVM | C = [0.1, 1, 10, , ] Gamma = [, , ,0.1, 1, 10, ] Kernel = [sigmoid, linear, rbf] | C = 10 Gamma = Kernel = rbf |
| LR | C = [, , 0.1, 1, 10, 100], fit_intercept = [True, False] | C = fit_intercept = True |
| NB | alpha = [, , , , 0.1, 1]fit_prior = [True, False] | alpha = fit_prior = True |
| K-NN | n_neighbors = [1, 40] | Number of neighbours = 7 |
| # | Type of Experiment | Number of Features |
|---|---|---|
| Baseline: | 15 | |
| F_values_5%: 5% of features | 4 | |
| F_values_10%: 10% of features | 7 | |
| F_values_15%: 15% of features | 9 | |
| Baseline: Including (TF-IDF) extracted features | 10,236 | |
| F_values_5%: 5% of features | 732 | |
| F_values_10%: 10% of features | 2187 | |
| F_values_15%: 15% of features | 5867 | |
| Baseline: | 10,251 | |
| F_values_5%: 5% of the extracted features | 736 | |
| F_values_10%: 10% of the extracted features | 2194 | |
| F_values_15%: 15% of the extracted features | 5876 |
| ML Classifier | Experiment | |||
|---|---|---|---|---|
| Baseline | F_Values_5% | F_Values_10% | F_Values_15% | |
| RF | 61.24 | 61.73 | 63.93 | 62.34 |
| SGD | 59.04 | 52.65 | 51.86 | 57.62 |
| SVM | 64.40 | 62.76 | 66.54 | 61.08 |
| LR | 61.87 | 61.87 | 61.87 | 61.87 |
| NB | 61.75 | 62.03 | 60.12 | 61.49 |
| k-NN | 60.57 | 46.83 | 42.72 | 41.33 |
| ML Classifier | Experiment | |||
|---|---|---|---|---|
| Baseline | F_Values_5% | F_Values_10% | F_Values_15% | |
| RF | 77.97 | 86.83 | 90.21 | 83.67 |
| SGD | 74.72 | 85.72 | 84.59 | 79.19 |
| SVM | 75.89 | 89.31 | 91.83 | 90.37 |
| LR | 77.65 | 75.43 | 75.76 | 75.09 |
| NB | 74.65 | 87.35 | 90.24 | 89.46 |
| k-NN | 76.99 | 73.77 | 65.08 | 65.08 |
| ML Classifier | Experiment | |||
|---|---|---|---|---|
| Baseline | F_Values_5% | F_Values_10% | F_Values_15% | |
| RF | 77.18 | 86.94 | 88.13 | 85.02 |
| SGD | 74.83 | 82.52 | 87.02 | 85.39 |
| SVM | 75.00 | 88.92 | 92.16 | 90.65 |
| LR | 76.77 | 76.73 | 75.00 | 75.87 |
| NB | 75.30 | 89.27 | 90.74 | 89.62 |
| k-NN | 77.05 | 74.41 | 71.02 | 71.61 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Al-Sarem, M.; Saeed, F.; Al-Mekhlafi, Z.G.; Mohammed, B.A.; Hadwan, M.; Al-Hadhrami, T.; Alshammari, M.T.; Alreshidi, A.; Alshammari, T.S. An Improved Multiple Features and Machine Learning-Based Approach for Detecting Clickbait News on Social Networks. Appl. Sci. 2021, 11, 9487. https://doi.org/10.3390/app11209487
Al-Sarem M, Saeed F, Al-Mekhlafi ZG, Mohammed BA, Hadwan M, Al-Hadhrami T, Alshammari MT, Alreshidi A, Alshammari TS. An Improved Multiple Features and Machine Learning-Based Approach for Detecting Clickbait News on Social Networks. Applied Sciences. 2021; 11(20):9487. https://doi.org/10.3390/app11209487
Chicago/Turabian StyleAl-Sarem, Mohammed, Faisal Saeed, Zeyad Ghaleb Al-Mekhlafi, Badiea Abdulkarem Mohammed, Mohammed Hadwan, Tawfik Al-Hadhrami, Mohammad T. Alshammari, Abdulrahman Alreshidi, and Talal Sarheed Alshammari. 2021. "An Improved Multiple Features and Machine Learning-Based Approach for Detecting Clickbait News on Social Networks" Applied Sciences 11, no. 20: 9487. https://doi.org/10.3390/app11209487
APA StyleAl-Sarem, M., Saeed, F., Al-Mekhlafi, Z. G., Mohammed, B. A., Hadwan, M., Al-Hadhrami, T., Alshammari, M. T., Alreshidi, A., & Alshammari, T. S. (2021). An Improved Multiple Features and Machine Learning-Based Approach for Detecting Clickbait News on Social Networks. Applied Sciences, 11(20), 9487. https://doi.org/10.3390/app11209487