1. Introduction
With the rapid development of science and technology and the modern manufacturing industry, the structures and functions of mechanical equipment are gradually shifting toward achieving integration, intelligence, refinement, and comprehensiveness. For a mechanical system, a high integration level and high complexity of the structure and function are associated with a high probability of failure. A fault in one of the mechanical components, or even in a tiny part, if not found and repaired in time, may cause the entire system to fail (so that the machine is unable to operate normally) or lead to property damage or even casualties [
1].
A gear pump has the advantages of a small volume, lightweight, good technicality, and strong self-suction. It is commonly used in construction engineering, metallurgy, aerospace, automobile manufacturing, shipping, and other fields. As the “heart” of a hydraulic transmission system, the stable operation of a gear pump is an important requirement for its normal operation. Therefore, conducting appropriate monitoring and maintenance and providing warnings of early failures of gear pumps are highly significant [
2].
At present, the methods of signal analysis, monitoring, and fault diagnosis of mechanical equipment are becoming increasingly mature, practical, and specialized. The methods of monitoring and fault diagnosis of mechanical equipment that are extensively used worldwide mainly include vibration analysis, sound analysis, oil sample analysis, and temperature monitoring [
3]. Among them, fault diagnosis methods based on vibration monitoring and analysis have the following main advantages: (1) Under the condition in which early failure of mechanical equipment is not evident, the collected vibration signals can still be analyzed to determine its position, degree, and cause. For example, Jiang et al. accurately identified the fault degree of rolling bearings based on a deep learning method [
3]; (2) there are various methods for analyzing vibration signals, and the analysis results are intuitive and reliable. Sinao et al. proposed a new method for vibration-based techniques to detect, monitor, and prevent pump cavitations [
4]; (3) different characteristic parameters of mechanical equipment vibration signals have different sensitivities to different types of faults, and they have practical physical relevance. Gajjar et al. proposed a Tennessee Eastman process fault detection and diagnosis method using sparse principal component analysis [
5]. Therefore, in the vibration analysis and fault diagnosis of mechanical equipment, fault diagnosis methods based on vibration monitoring and analysis have attracted increasing attention of researchers. Lei et al. pointed out that machinery intelligent fault diagnosis is a promising tool to deal with mechanical big data. [
6]. In 2019, Jiang et al. first proposed a fault identification method for axial piston pump based on voiceprint characteristics, which solved the problem of inconvenient installation of vibration sensors under special conditions [
7]. Because of the uniqueness of a hydraulic system, the installation method and location of a vibration sensor affect the signal acquisition. Moreover, a vibration sensor is frequently installed by pasting or using a magnetic base, which is inconvenient in some cases. Pressure is an important parameter of a hydraulic system, and pressure signals can be conveniently collected. The outlet pressure pulsation of a hydraulic pump is mostly related to its vibration. Therefore, this study considers the outlet pressure signals of a pump as the research object.
In the process of collecting the vibration signals of mechanical equipment, there is frequent interference from noise signals. To analyze a vibration signal accurately and yield the correct diagnosis result, it is necessary to alleviate the associated noise and interference. Zhang et al. [
8] applied the wavelet packets transform method to the fault diagnosis of rolling bearings and achieved good diagnosis results. Choe et al. [
9] defined wavelet packet transform modulus (WPTM) and presented a WPTM-based PQD feature detection method; experiments show that WPTM has advantages in feature detection. Zhu et al. [
10] proposed an adaptive extraction method based on extreme-point symmetric mode decomposition; it was applied to the trend term of machinery signal analysis, and good results were obtained. Hu et al. [
11] applied ensemble empirical mode decomposition to rolling bearing fault feature extraction. At the same time, many signal decomposition methods have been applied to signal denoising. For example, Jiang et al. [
12] applied local mean decomposition method to hydraulic pump fault signals demodulation. Naeem et al. [
13] applied weighted singular value decomposition to enhance the detection performance of a vibration sensor.
Because of its good time–frequency localization analysis ability, wavelet analysis based on Fourier analysis is commonly used in signal processing and other fields. Based on an improved wavelet packet transform method, Huang Yuqing et al. [
14] proposed the improved denoising method of fractional wavelet packet transformation, which was subsequently used for filtering and reducing noise signals and showed to have good noise reduction effects. Su Xiuhong [
15] combined the denoising method of EMD with the wavelet threshold method, which presents a remarkable signal denoising effect. Tang Ying et al. [
16] calculated the maximum singular value modulus of impact signals after wavelet transformation to determine their singular values and subsequently suppressed the maximum singular value to eliminate noise. Yi et al. [
17] proposed a novel signal adaptive decomposition algorithm processed in TF domain, which provides adequate information about the time-varying instantaneous frequency. Based on the wavelet theory, Zhang Guangtao et al. [
18] proposed the method of multi-wavelet analysis and denoising, which solves the correlation problem of multi-wavelet transform coefficients well and has a good denoising effect.
A pressure signal contains a large amount of useful information [
19,
20]. Accurate extraction of the key information is not only the basis for hydraulic pump fault diagnosis but also for determining the accuracy of the diagnosis results [
21]. The main purpose of feature extraction is to extract and filter out the useful information that can accurately characterize the fault characteristics of a hydraulic pump from pressure signals. At present, the extraction methods of mechanical equipment fault characteristic parameters mainly include time, frequency, and time–frequency domain analysis methods, with the last one combining time and frequency domain features [
22]. Because time and frequency domain analyses of gear pumps have the advantages of simple form and convenient calculation, the corresponding characteristic parameters are extensively studied and adopted for identifying the operating state of a gear pump [
23,
24].
If the maintenance personnel who repair a mechanical equipment can timely and accurately determine its remaining useful life (RUL), then a scientific and appropriate maintenance plan can be formulated and the property losses and casualties caused by untimely monitoring and maintenance can also be effectively avoided [
25,
26]. Therefore, it is essential to predict the RUL of mechanical equipment on time and accurately.
In recent years, with the rapid approach of the artificial intelligence and data “big bang” era, computer and information technologies have been frequently developed and integrated and artificial intelligence and machine learning methods are being constantly innovated and advanced [
27]. In the current research on the analysis and prediction of the RUL of mechanical equipment, artificial intelligence has become a prominent topic [
6]. Tan Yuanyuan et al. [
28] combined collected field data with accelerated life testing data and introduced conversion and environmental difference factors to improve the prediction and evaluation method of RUL. Sim et al. [
29] established a set of RUL prediction and evaluation models for gears and bearings. Kong Guojie et al. [
30] established an RUL prediction and evaluation model for artillery barrels and verified its accuracy with a large amount of actual data.
Just in time learning (JITL), a commonly used nonlinear modeling method [
31], is also known as lazy learning [
32] and locally weighted learning [
33]. It uses process data to build local models to achieve high prediction accuracy. Therefore, the JITL modeling method can effectively solve the modeling problems of strongly nonlinear and time-varying industrial processes, and it has been extensively used in the industry [
34]. Wang Li et al. [
35] first grouped variables by principal component analysis (PCA), subsequently selected similar sample data for each group of variables using the JITL method, and finally predicted the output by Gaussian process regression. The simulation and experimental results showed that the proposed method has good prediction performance. Qi Cheng et al. [
36] proposed a JITL method based on second-order similarity, and simulations and experiments verified that it can improve the prediction accuracy of a model. Jin et al. [
37] proposed an integrated soft-sensing modeling framework for JITL based on an evolutionary multi-objective optimization method. The experimental results showed the effectiveness and excellence of this method. Guo et al. [
38] proposed a JITL framework based on a variational adaptive encoder to solve the problem of non-consideration of the variable uncertainty in industrial processes, and showed the effectiveness of the method based on experiments.
Although the JITL method is commonly recognized, its utilization for predicting the RUL of mechanical equipment is rarely reported. Therefore, this study proposes a prediction method based on JITL to predict the RUL of mechanical equipment on time and accurately.
The evolution processes of many equipment faults follow a certain change rule. To detect faults on time, appropriate methods can be adopted to monitor the operating state of a mechanical equipment and observe the real-time changes in the equipment state [
39].
The performance of a mechanical equipment tends to decline during operation, and the performance degradation process is frequently irreversible. The performance degradation of mechanical equipment makes their continuous operation impossible. Timely early warning of machinery equipment failure can be provided using appropriate monitoring methods to monitor the working state of machinery and equipment in real time. This will not only help equipment users to establish an appropriate maintenance and repair plan to prevent unexpected shutdowns of the mechanical equipment during use but also effectively prolong its normal operation time and avoid the economic losses caused by unexpected equipment failures.
The most major feature of data-driven prediction is that it does not require establishing a complex mathematical model for the prediction and evaluation of mechanical equipment. It only needs collection of a large amount of data generated in the industrial field, based on which a model is built. The establishment of a data-driven model can utilize the real-time measurement data sampled by sensors; therefore, the characteristic parameters of the prediction model can be modified on time to accurately reflect the changes in the measured data. Data-driven prediction models mainly include the time-series prediction method [
40], artificial neural networks [
41], and support vector regression [
42]. In this study, the established data-driven prediction model mainly predicts the RUL of a gear pump from two aspects: determining the performance degradation index and constructing an RUL prediction model of a gear pump.
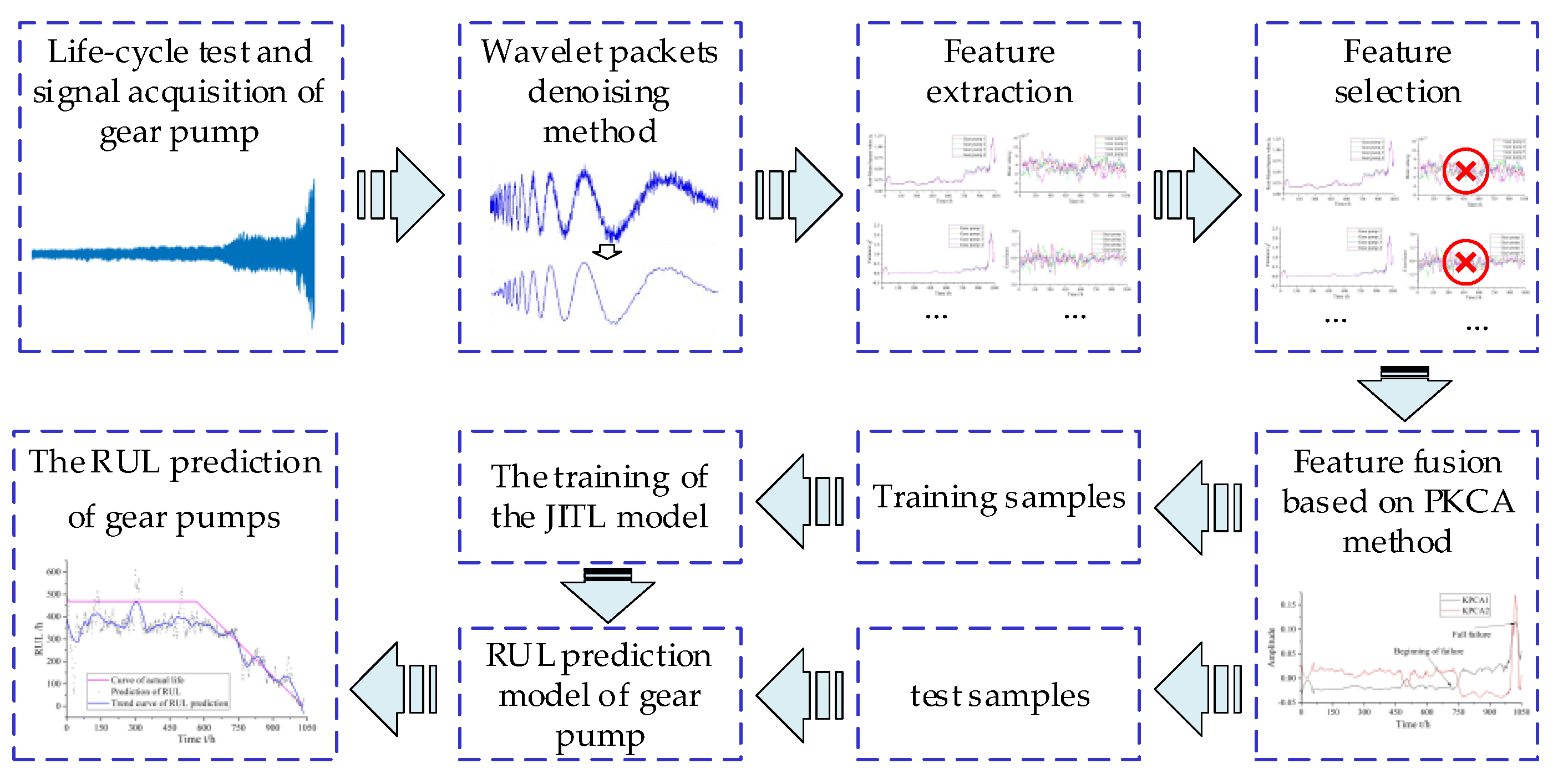
The main research steps of this study are shown in
Figure 1. First, the gear pump pressure signals at a pressure port were collected by a pressure sensor. After eliminating the DC component of the collected pressure signals, the wavelet packet denoising method was used to denoise the signals. After denoising, the time- and frequency-domain characteristic indices of the signals were extracted and preliminarily screened. Subsequently, the kernel PCA (KPCA) was used to analyze the screened time- and frequency-domain characteristic indices. The first and second principal components were extracted to identify the performance degradation index of a gear pump. Finally, based on the degradation index, a prediction model based on the k-vector nearest neighbor (k-VNN) JITL method was established for the RUL prediction of a gear pump. The method proposed in this paper was compared to the traditional JITL method based on k-nearest neighbor (k-NN). The results show that the proposed RUL prediction model of a gear pump has a higher prediction accuracy than the traditional method.
2. Wavelet Packet Denoising Method and KPCA Method
In actual field applications or industrial production, when a gear pump fails, the pressure pulsation of its oil pressure port changes. Moreover, most of the gear pump fault information is frequently contained in these pressure pulsations and impacts, such as gear pump fault type, fault location, and fault degree. The pressure signals of a gear pump collected by a sensor contain not only the effective state information but also the noise signals; the latter are unrelated to the state information of the gear pump. Therefore, to extract effective characteristic information from sampled original pressure signals, the first step is to denoise them.
2.1. Wavelet Packets Denoising Method
The wavelet packet transform analysis method is a technical improvement of the wavelet transform analysis method. It is a joint signal analysis method based on time and frequency domains. Compared with the signal analysis method of wavelet transform, the wavelet packet transform analysis method can decompose the low- and high-frequency parts of the upper layer simultaneously. Thus, it overcomes the deficiency of the wavelet transform analysis method, which only analyzes the low-frequency part of a signal.
The method of wavelet packet decomposition and denoising can perform orthogonal decomposition of the collected signals in all frequency bands. An orthonormal basis that can reflect the original characteristics of the signals can be obtained by reasonably selecting the optimal wavelet packet basis function and the decomposition layer number. As shown in
Figure 2a, after the original signal is decomposed by wavelet decomposition, the low-frequency coefficients will be decomposed again. As shown in
Figure 2b, wavelet packet decomposition not only re-decomposes the low-frequency decomposition coefficients after each layer decomposition, but also re-decomposes the high-frequency coefficients. So, the wavelet packet denoising method is more refined and has better localization ability in the frequency domain than the wavelet denoising method.
In multiresolution analysis, indicates that it is based on different scale factors j. The Hilbert space, , is decomposed into the orthogonal sums of all subspaces . Following signal filtering, the signals are expanded based on the wavelet packet basis. Specifically, the signal, , to be analyzed is filtered through a low-pass filter H and a high-pass filter G, and thus, a group of low- and high-frequency signals is obtained. Each signal decomposition further decomposes the l-th frequency band of the upper layer, j + 1, into two sub-bands 2l-th and (2l + 1)-th of the lower layer, j.
Wavelet packet decomposition method:
and
are calculated from
, and the wavelet packet decomposition formula is
where
denotes the low-pass filter coefficients,
denotes the high-pass filter coefficients, and
.
Wavelet packet reconstruction method:
is calculated from
and
, and the wavelet packet reconstruction formula is
where Daubechies 4 wavelet is selected for wavelet packet decomposition.
The steps of the wavelet packet denoising process are as follows:
- (1)
Optimal wavelet packet decomposition basis determination. The optimal wavelet packet decomposition basis is calculated based on the entropy standard.
- (2)
Wavelet packet decomposition of the signal. The number of decomposition layers, M, is determined, and the signal, , is decomposed by an M-layer wavelet packet. In this study, the number of decomposition layers, M, is 3.
- (3)
Threshold quantization of the wavelet packet decomposition coefficients. An appropriate threshold is selected to quantify each set of wavelet packet decomposition coefficients. In this study, the default threshold is used to denoise the signals.
- (4)
Wavelet packet reconstruction. After the threshold quantization processing in Step 3, the wavelet packet decomposition coefficients are reconstructed using the wavelet packet reconstruction method. Subsequently, after denoising, the time-domain signal, , is obtained.
2.2. Determining Performance Degradation Evaluation Index
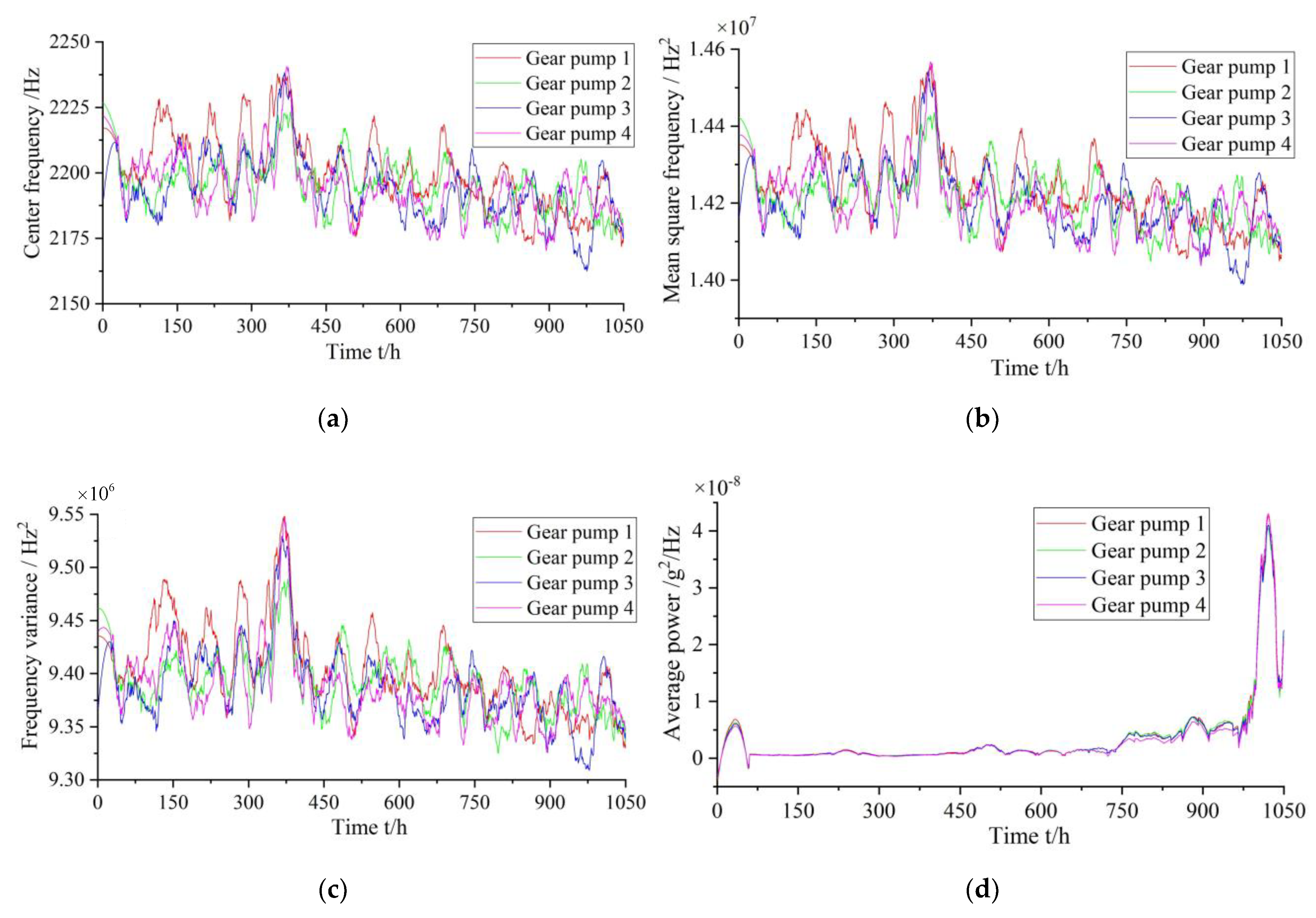
Owing to the different types and degrees of hydraulic pump faults, the extracted pressure signal characteristic parameters in the time domain are also different. In general, dimensionless indicators are not directly affected by the operating state of a mechanical equipment; they are only determined by its corresponding probability density functions. However, dimensional indicators are directly affected by the operating state of a mechanical equipment. Both dimensional and dimensionless indicators can directly or indirectly reflect the changing trend of gear pump performance degradation during operation. The time-domain characteristic parameter calculation methods of pressure signals are tabulated in
Table 1, where
represents the denoised pressure signal obtained after the wavelet packet denoising, where
and
N is the length of the original signal.
Feature extraction methods based on the time domain are frequently unable to accurately determine the performance degradation trend of mechanical equipment. Therefore, an extraction method based on frequency-domain features is used. First, the power spectral density of the collected mechanical equipment time-domain signals is calculated. Subsequently, the frequency-domain characteristics of the time-domain signals are calculated based on the power spectral density; therefore, the performance degradation trend of the mechanical equipment can be determined more intuitively and accurately. The calculation methods of the characteristic parameters in the relevant frequency domain are summarized in
Table 2.
The is the upper limit of the analysis frequency band and is the amplitude of the power spectrum at frequency .
2.3. KPCA Method
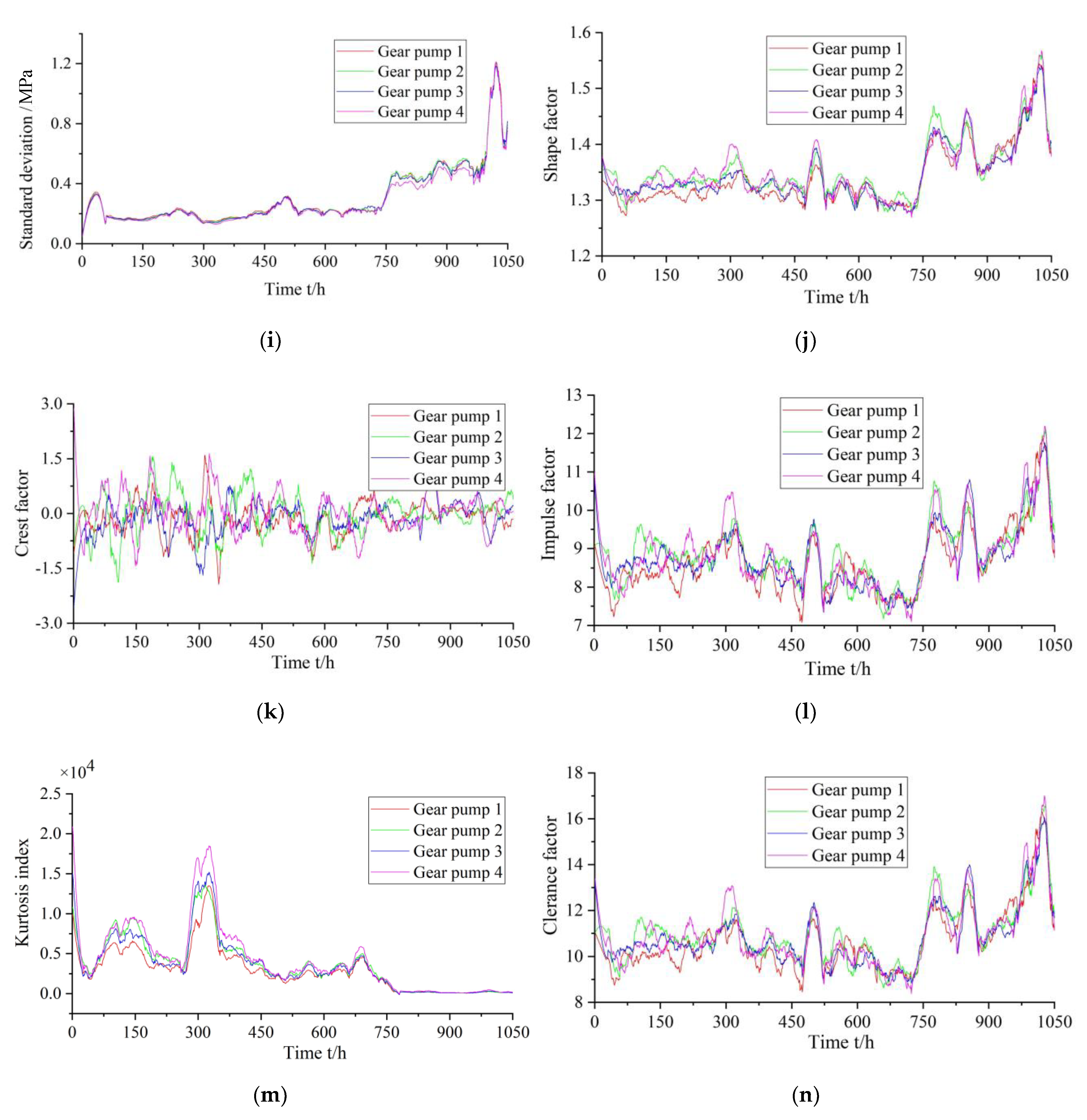
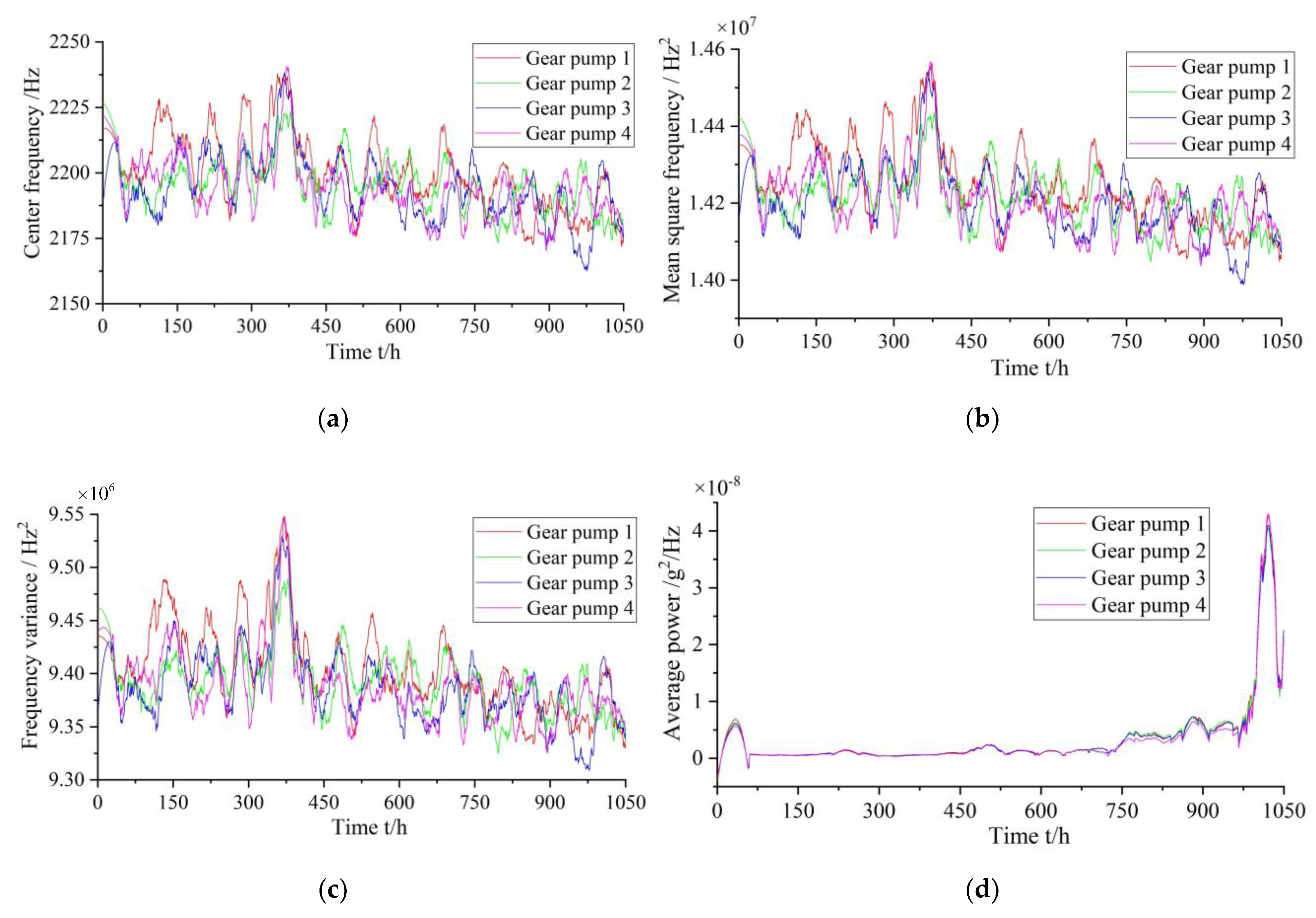
In traditional methods, as a gear pump performance degradation characteristic index, a single time- or frequency domain-characteristic index is frequently used as the basis. Owing to the variability and complexity of the gear pump operation process, a single index cannot accurately and comprehensively represent the faults and performance degradation information during its operation. Therefore, it is necessary to consider and extract multiple appropriate features to achieve comprehensive characterization of a gear pump performance degradation trend. For obtaining the performance degradation characteristic index of a gear pump, in this study, multiple characteristic parameters from the time and frequency domains are selected, including variance, root-mean-square value, peak value, root amplitude, peak-to-peak value, absolute mean value, standard deviation, shape factor, clearance factor, and average power. Subsequently, the dimensionality reduction calculation is performed for the selected multiple characteristic indicators. Finally, the characteristics after the dimensionality reduction are used as the performance degradation evaluation index of the gear pump.
PCA [
43] is a traditional mathematical linear transformation analysis method. The basic principle of the PCA method is the linear transformation of the original variables with some correlation into a set of uncorrelated variables, during which process the total variance remains unchanged. The KPCA method extracts the principal components from the original data information by a nonlinear transformation by some technical improvements of the PCA method. First, the input space is transformed into a high-dimensional space by a nonlinear transformation. Subsequently, the principal components in the information are nonlinearly analyzed in the high-dimensional space. The specific method is as follows:
Let the training sample set be
, where
is a column vector and
is the number of training samples. The KPCA method nonlinearly maps a
-dimensional original vector from the original input space,
, to a high-dimensional space,
, represented as
. The sample in
is represented as
, and it satisfies
. Therefore, the sample covariance matrix in the
space can be expressed as
The eigen decomposition of the covariance matrix,
, can be obtained as follows:
where
is the eigenvector corresponding to the eigenvalues,
, in the
space, and all eigenvalues of
are non-negative. Without the loss of generality,
are set, and the corresponding eigenvectors,
, can be expanded by the sample,
, in the
space as follows:
where
are the correlation coefficients.
The inner product of each sample
with Equation (4) is obtained as follows:
Based on Equations (5) and (6), the following can be obtained:
where
.
A
-dimensional matrix
is defined, where
and
. Because
is a symmetric matrix,
, Equation (7) can be expressed as
where
is the eigenvalue of
and
is the corresponding eigenvector. Let the eigenvectors corresponding to the eigenvalues greater than zero be
, respectively.
is normalized to obtain
; therefore, the projection of sample
on
is
where
is the
-th nonlinear principal component corresponding to
. All principal components are combined into vector
as the sample feature.
To overcome the problem that the high-dimensional
space makes solving
difficult, based on the Mercer theorem [
44], a kernel function
is used to replace the dot product operation of the
space. Therefore,
To solve the problem that the sampled data do not satisfy
, sample
in the
space can be replaced by Equation (11).
The kernel matrix,
, in Equation (8) is replaced by
.
where
is a
-dimensional identity matrix with coefficient
.
The radial basis function (RBF) kernel function has many advantages, such as wide convergence range, good positive definiteness of the transformation matrix, few parameters, and simple calculation. In data processing, the accuracy and speed of the RBF kernel function are better than those of other kernel functions. Therefore, the RBF kernel function is selected as the kernel function in the KPCA method as
The cumulative percent variances (CPVs) of the principal components are calculated to select the components that meet the conditions. Finally, the number of principal components is determined based on the actual requirements.
The method and process using the
CPVs as the basis for selecting the principal components are as follows: First, the corresponding initial data samples are calculated and processed to obtain the covariance matrix. Subsequently, the corresponding eigenvectors are sorted in descending order of the corresponding eigenvalues, and finally, the number of principal components that meets the requirements is selected. The variance contribution rate of a single principal component is
where
represents the percent variance of the
r-th principal component.
The
CPV calculation method of the first
s principal components is as follows:
where
P is the total number of eigenvectors.
The CPV size is typically set based on the operating states of the system when using the KPCA method to analyze and calculate the data information. Among the current KPCA methods, CPV is the most extensively used for selecting the number of principal components, and it is relatively easy to implement. In general, to simplify the number of variables in the original sample, reduce the complexity of the data structure, and simultaneously maximize the retention of most useful information in the original sample, the CPV is generally set as at least 85%.
3. Principle of JITL Method
The principle of the JITL method is “similar input data produce similar output data.” Its basic workflow is to store a large amount of sample information in the sample data memory. Based on the actual input data, data similar to the input sample data are found in the sample data storage, and subsequently the corresponding output data of the input data are obtained from the sample data information.
For a nonlinear mapping of multiple inputs and single output,
, it is assumed that the input and output data of the system (i.e.,
, where
V is the number of training samples) can be measured. Moreover, the input and output data have the following functional relationship:
where
represents the input sample data and
T is the dimension of the input sample data. The output sample data are
.
is an independent random variable with a zero mean and a variance of
.
The JITL method establishes a model in a certain space by recursion to predict the output. The input and output relationship of the established model is described as follows:
where
represents the sub-model parameters. Combined with a historical database, mapping in the local space is established to obtain the model output value,
. Therefore, the predicted output problem can be solved using an optimal solution, and the formula is as follows:
where
is the local space consisting of
k sample data near
.
is the mapping relationship between input data
and output data
.
is the weight corresponding to the
q-th historical sample data, which represents the weight of the influence of the
q-th sample data contained in the local sample space on the model output.
The selection of the local space has a significant influence on the accuracy of the sub-models. For the input data,
, the selected local space is used to select the appropriate historical data. These historical data consist of
k samples that are most similar to the input data,
. To select historical data similar to the input vector,
, some scholars have proposed k-NN, k-surrounding neighbors, k-bipartite neighbors, and other methods to screen the modeling data. However, these methods mainly refer to the Euclidean distance as the basis for modeling, which is insufficient for fully exploring the internal relationships among the input and nearest data. In [
45], the k-VNN method was proposed, which considers both the Euclidean distance and angle relationship between two vectors. Therefore, the k-VNN method is used as the neighborhood selection criterion in this study.
As we all know, k-VNN considers both the Euclidean distance and angle relationship between two vectors, while k-NN mainly refers to the Euclidean distance as the basis for modeling, which is insufficient for fully exploring the internal relationships among the input and nearest data. Therefore, sample selection method based on k-VNN of the RUL prediction method can significantly improve the prediction accuracy of the RUL prediction model.
Assuming that the data in the historical database are
and the input data of the model are denoted by
; the Euclidean distance,
; and the two vector angles,
, between the input data,
, and the historical data,
, can be expressed as
When constructing the neighborhood, , of the input vector, , the relationship between the Euclidean distance and the angle of the data information, and , are comprehensively considered.
When the angle between and is large (i.e., ), it is considered that the information vector of the sample data deviates from the current input vector, , and does not meet the requirements of the local modeling of the system. Therefore, the sample data information should not be used to construct the modeling neighborhood. When the angle between and is small (i.e., ), it is considered that the information vector of the sample data is close to the current input vector, , and meets the requirements of the local modeling of the system. Therefore, the sample data information is used to construct the modeling neighborhood.
The neighborhood selection criterion,
, of input vector is constructed as follows:
where
is the weight factor and
. Because
and
,
.
Equation (20) indicates that
considers not only the Euclidean distance of the vectors but also the angle information between the vectors. Considering the Euclidean distance and the angle information, the similarity between vectors
and
can be more comprehensively reflected. Two similar vectors imply large neighborhood selection criteria
. This indicates that the historical data,
, have a significant influence on the sub-model (i.e., the weight coefficient,
, is large). Therefore, the following is set:
that is,
It is considered that in the neighborhood of the input vector,
, the local model of the system can be represented by a linear polynomial. First, it is necessary to provide the range size of the neighborhood,
k, of the current input vector,
;
indicates that the number of vectors required for the local modeling of the current input vector,
, is at least
and at most
.
is taken as a criterion for selecting samples, and the current input vector,
, is used to construct their neighborhood,
. Because a large
implies high similarity degree between the vectors, the descending order arrangement method is adopted to construct the neighborhood as follows:
Therefore, the problem of solving Equation (18) is transformed into an optimal selection problem of neighborhood
k. To improve the prediction speed of the system, the recursive least square algorithm [
46] is used to calculate parameter
of the sub-models.
where
,
is a diagonal matrix,
is the error between the predicted value and the actual value of the
k-th historical data during the establishment of the sub-model, and
is the pre-set error correction coefficient.
To examine the advantages and disadvantages of the model over time, the cross-validation calculation method is selected to calculate the “leave-one-out error” [
47] of the model. Specifically, first, one sample is removed from all the samples, subsequently the remaining samples are used for modeling, and finally, the removed sample is used to check the current model. Based on the local model,
, and the matrix,
, the “leave-one-out error” value [
48] of the current model is obtained as follows:
Because there are a total of
k samples in the model, there are
k values of the “leave-one-out error” as follows:
Using the mathematical calculation method of mean square error, the following is obtained:
Thus, the range size of the optimal neighborhood,
k, can be obtained using the following formula:
In this case, is the optimal model of the system in the neighborhood of .
When constructing the neighborhood of the input vector,
, we can follow the standard formula in Equation (20), that is, the sample constructed in the neighborhood is sorted in descending order based on the magnitude of the similarity coefficient. Arrangement of the data information in the latter part has an adverse effect on the establishment of the JITL model. Therefore, when a partial model of the system is obtained using the recursive algorithm, the termination condition [
49] of the recursive algorithm can be expressed by Equation (29);
The above formula suggests that the accuracy of the local model has a tendency to “deteriorate” when the recursive solution is used with the sample at k + 1. Therefore, in the following modeling process, when the accuracy obtained using the samples with serial numbers after k + 1 becomes increasingly worsened, the iteration should be terminated.
The specific steps to establish the improved JITL model are as follows [
50]:
The input and output history database, , is built. All data contained in the database should cover the actual operating states that may occur in the industrial field maximally.
The range of k in the neighborhood of input data is determined (i.e., ). The neighborhood, , of is constructed using the k-VNN method and arrange in descending order.
The parameters in the recursive algorithm are initialized as follows: and .
Samples are added from the neighborhood set in order, and the model, , is obtained using Equation (24) by an iterative calculation.
Based on Equations (26) and (27), the “leave-one-out error” and mean square error of the model can be calculated. If Equation (29) is satisfied, the model is output based on step 6; otherwise, k = k + 1 is set and step 4 is conducted for iterative calculation until Equation (29) is satisfied.
, and the output of the model is obtained as follows: .
5. RUL Prediction Method of Hydraulic Pump Based on KPCA and JITL
When repairing and maintaining mechanical equipment, if the maintenance personnel can timely and accurately determine their RUL, a scientific and appropriate maintenance plan can be formulated, and the property losses and casualties caused by their untimely maintenance can be avoided. Therefore, it is extremely essential to predict the RUL of mechanical equipment on time and accurately. As the core of a hydraulic system, it is highly important to predict the RUL and manage the health of a hydraulic pump. Therefore, an RUL prediction method of a hydraulic pump based on KPCA and JITL is proposed in this paper.
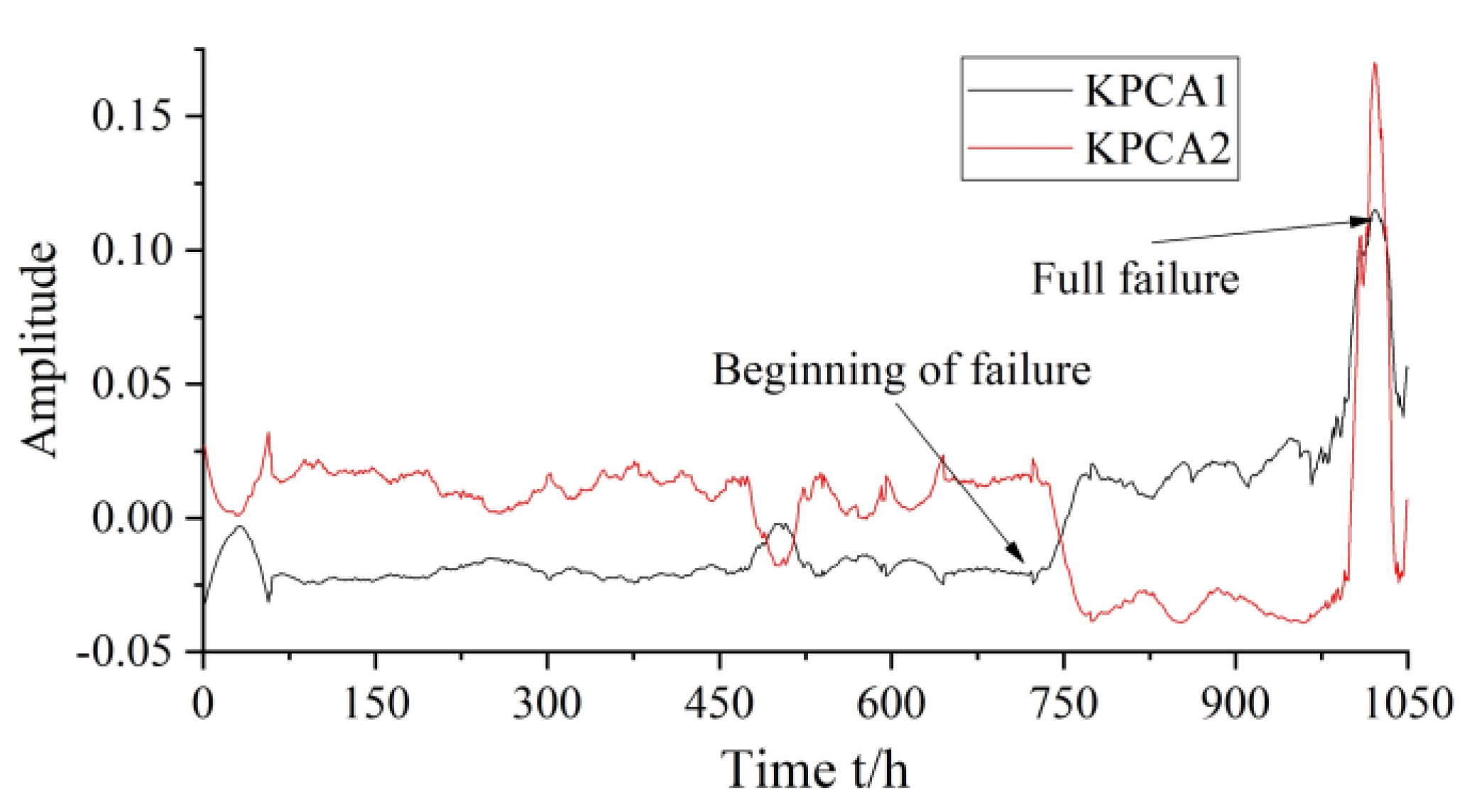
The KPCA method was used to perform the weighted fusion calculation of the selected characteristic parameters, and the first and second principal components were extracted as the evaluation indices representing the performance degradation of a gear pump. Subsequently, the RUL prediction model of a hydraulic pump based on KPCA and JITL was established using the RUL prediction method of JITL based on k-VNN.
The KPCA method was used to analyze the time- and frequency-domain characteristic parameters of the gear pump pressure signals. Based on
Table 5, when the kernel parameter is
, the
CPVs of the first and second principal components of the four gear pumps exceed 90%. Therefore, in this study, the first and second principal components of tested gear pump 1–3 were selected as the training samples in the modeling. Moreover, the data of tested gear pump 4 were chosen as the test samples to verify the accuracy of the model.
As aforedescribed, the selected minimum neighborhood,
, and the weight factor,
, in the JITL method have different effects on the predicted results. Among them, the maximum relative error (MRE) is listed in
Table 6.
It can be observed from
Table 6 that when the minimum neighborhood,
, is set as 2, 3, 4, and 5, respectively, the weight factors,
, are 0.9 and 1.0; the corresponding MREs are smaller than the other MREs. To further optimize the values of the above parameters, the average relative errors (AREs) of the predicted results were compared, and the results are tabulated in
Table 7.
Based on
Table 7, when minimum neighborhood
and weight factor
, the corresponding ARE is minimum. Therefore, in this study, parameters
and
of the model established are 5 and 1.0, respectively. The model was established based on the life-cycle test data of gear pumps 1–3. The prediction results of the RUL of gear pump 4 obtained using the model are shown in
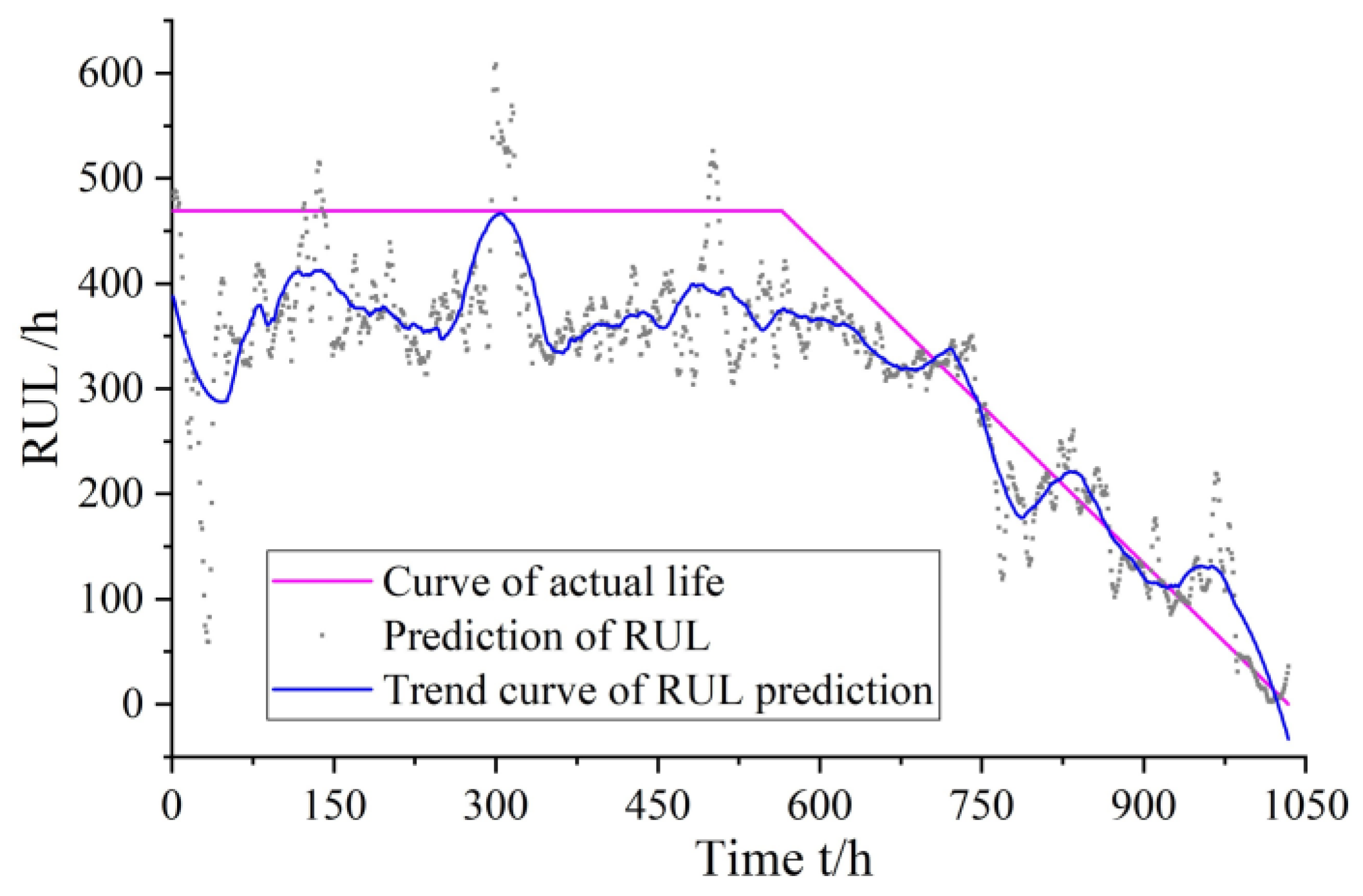
Figure 11.
As can be seen from
Figure 11, the gear pump is in a healthy state in the initial operating state without any mechanical failure; therefore, its life is not changed significantly. Over time, when the gear pump has operated for approximately 700 h, its RUL begins to decrease gradually. The predicted values of the RUL basically coincides with the real values.
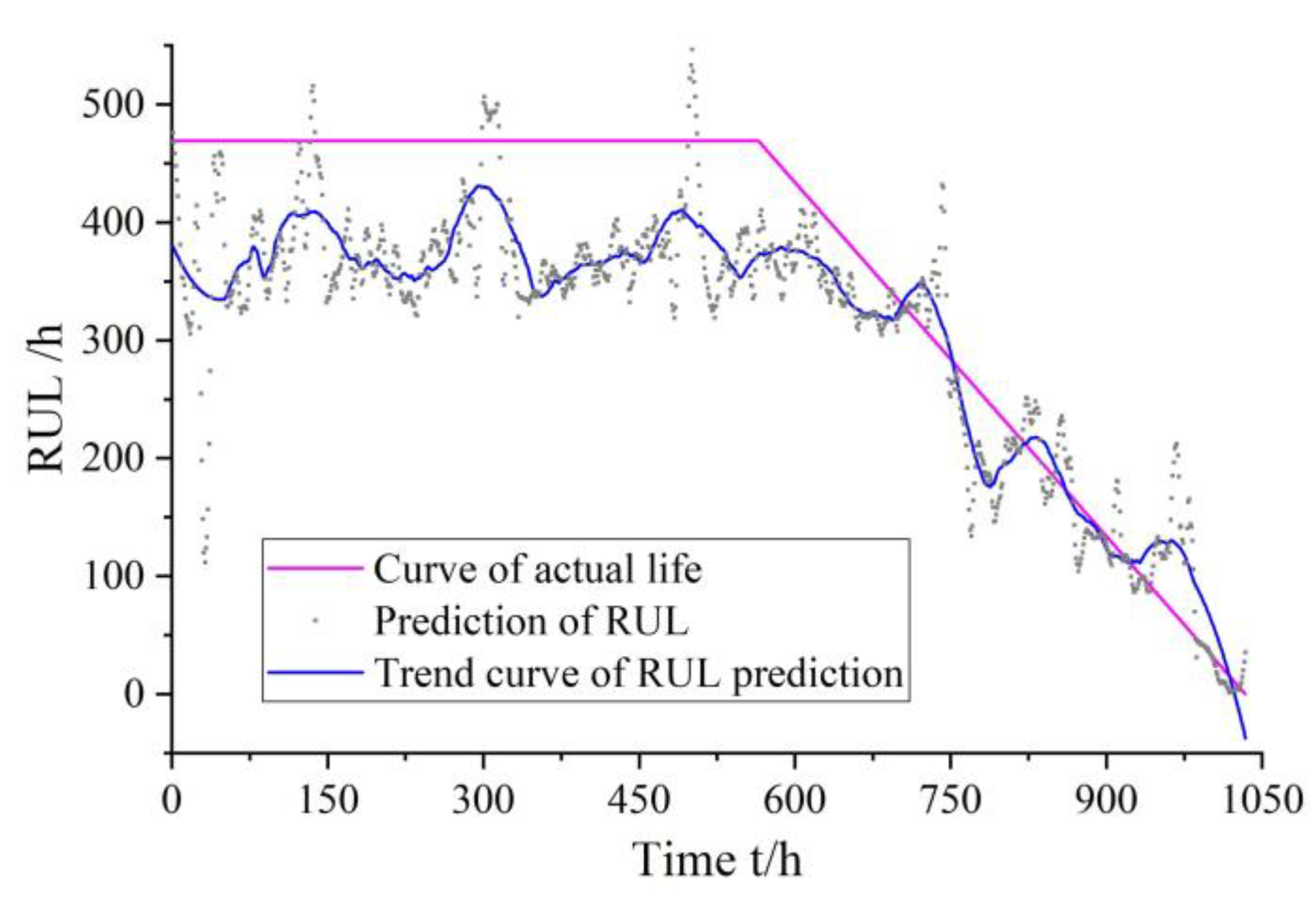
To illustrate the RUL prediction efficiency of the JITL method proposed in this paper, the results are compared with those of the traditional JITL method based on k-NN, which are shown in
Figure 12.
Table 8 compares the MREs and AREs of both methods.
Table 8 indicates that both MRE and ARE of the gear pump RUL prediction method proposed in this paper are better than those of the traditional k-NN-based RUL prediction algorithm. The k-VNN method considers both the Euclidean distance and angle relationship between two vectors, while k-NN mainly refers to the Euclidean distance as the basis for modeling, which is insufficient for fully exploring the internal relationships among the input and nearest data. Therefore, sample selection method based on k-VNN of the RUL prediction method significantly improved the prediction accuracy of the RUL prediction model. This shows that the RUL prediction model based on KPCA and JITL proposed in this paper has higher prediction accuracy than the traditional RUL prediction model based on k-NN.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}