Deep-Learning-Based Pupil Center Detection and Tracking Technology for Visible-Light Wearable Gaze Tracking Devices




Abstract
1. Introduction
Related Works
- (1)
- By using a nearfield visible-light eye image dataset for training, the used deep-learning models achieved real-time and accurate detection of the pupil position at the visible-light mode.
- (2)
- The proposed design detects the position of the pupil’s object at any eyeball movement condition, which is more effective than the traditional image processing methods without deep-learning technologies at the near-eye visible-light mode.
- (3)
- The proposed pupil tracking technology can overcome efficiently the light and shadow interferences at the near-eye visible-light mode, and the detection accuracy of a pupil’s location is higher than that of previous wearable gaze tracking designs without using deep-learning technologies.
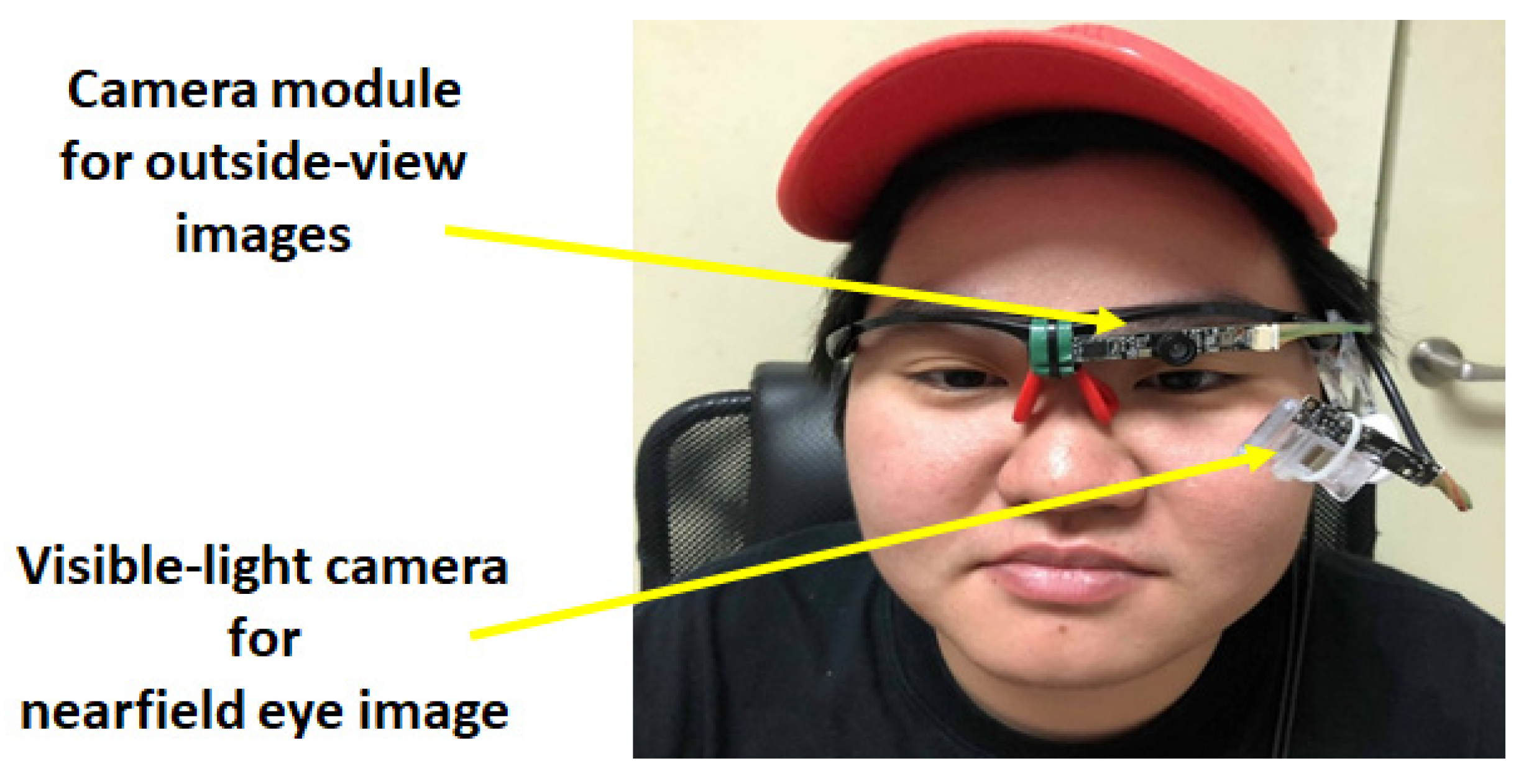
2. Background of Wearable Eye Tracker Design
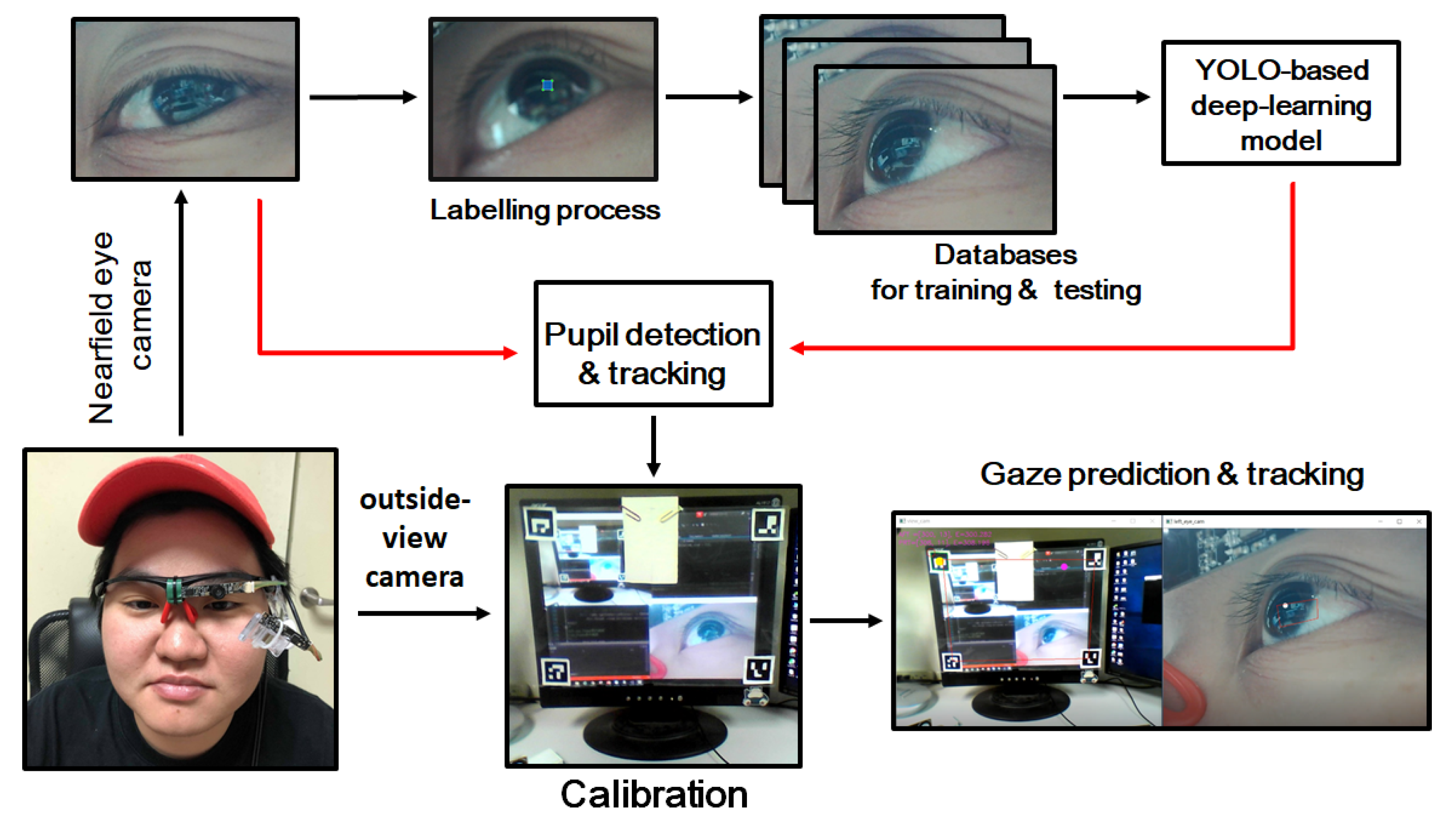
3. Proposed Methods
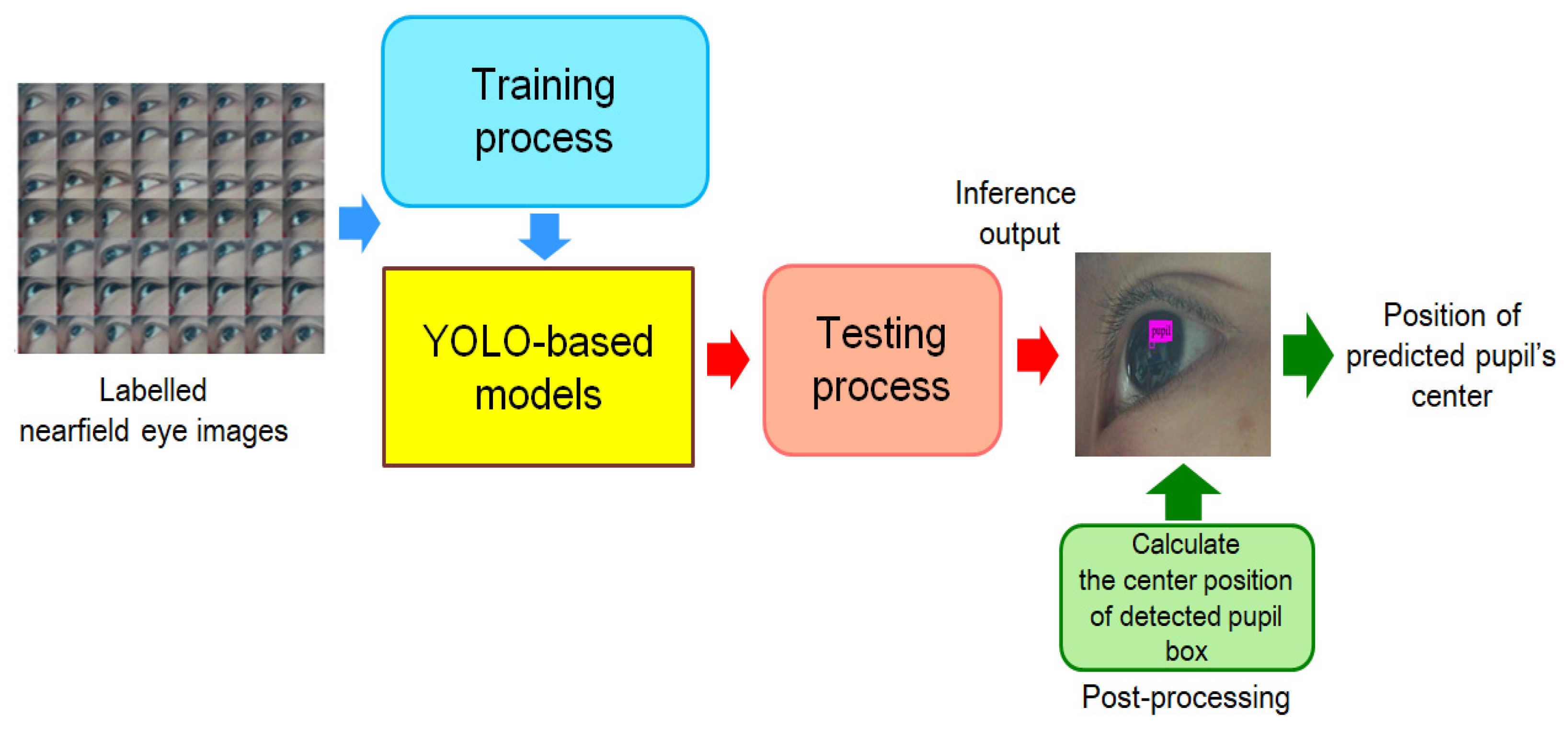
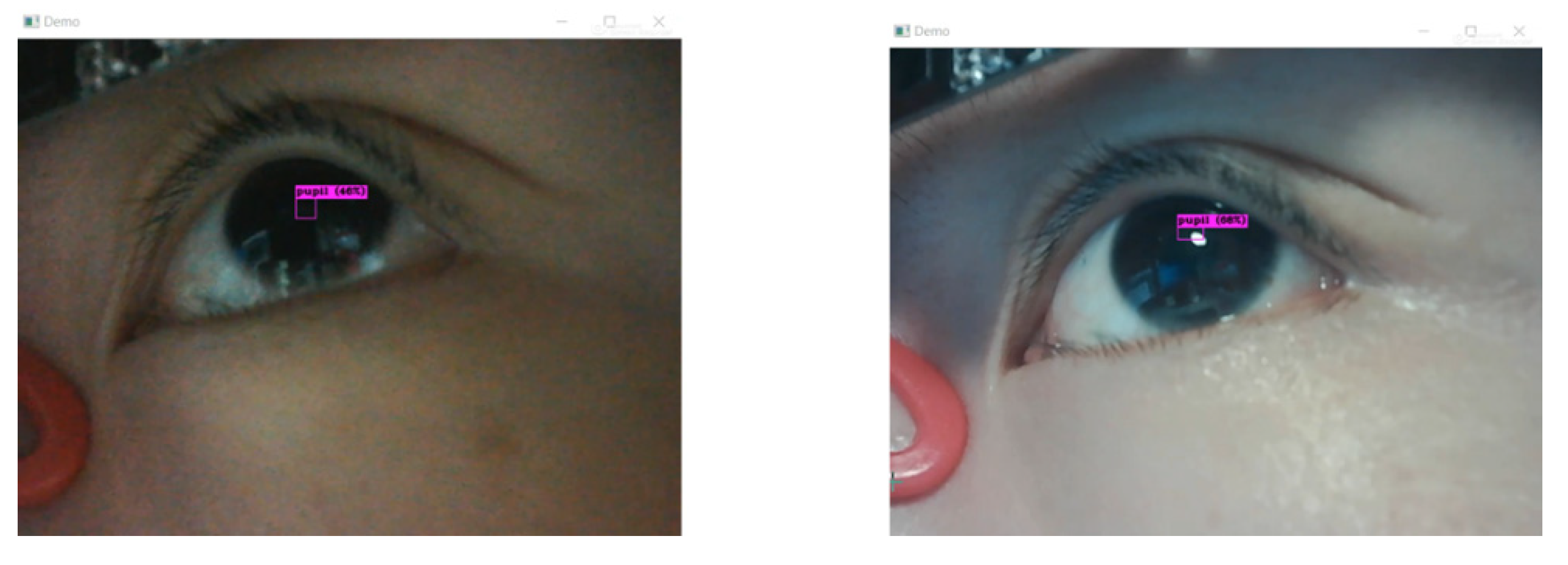
3.1. Pre-Processing for Pupil Center Estimation and Tracking
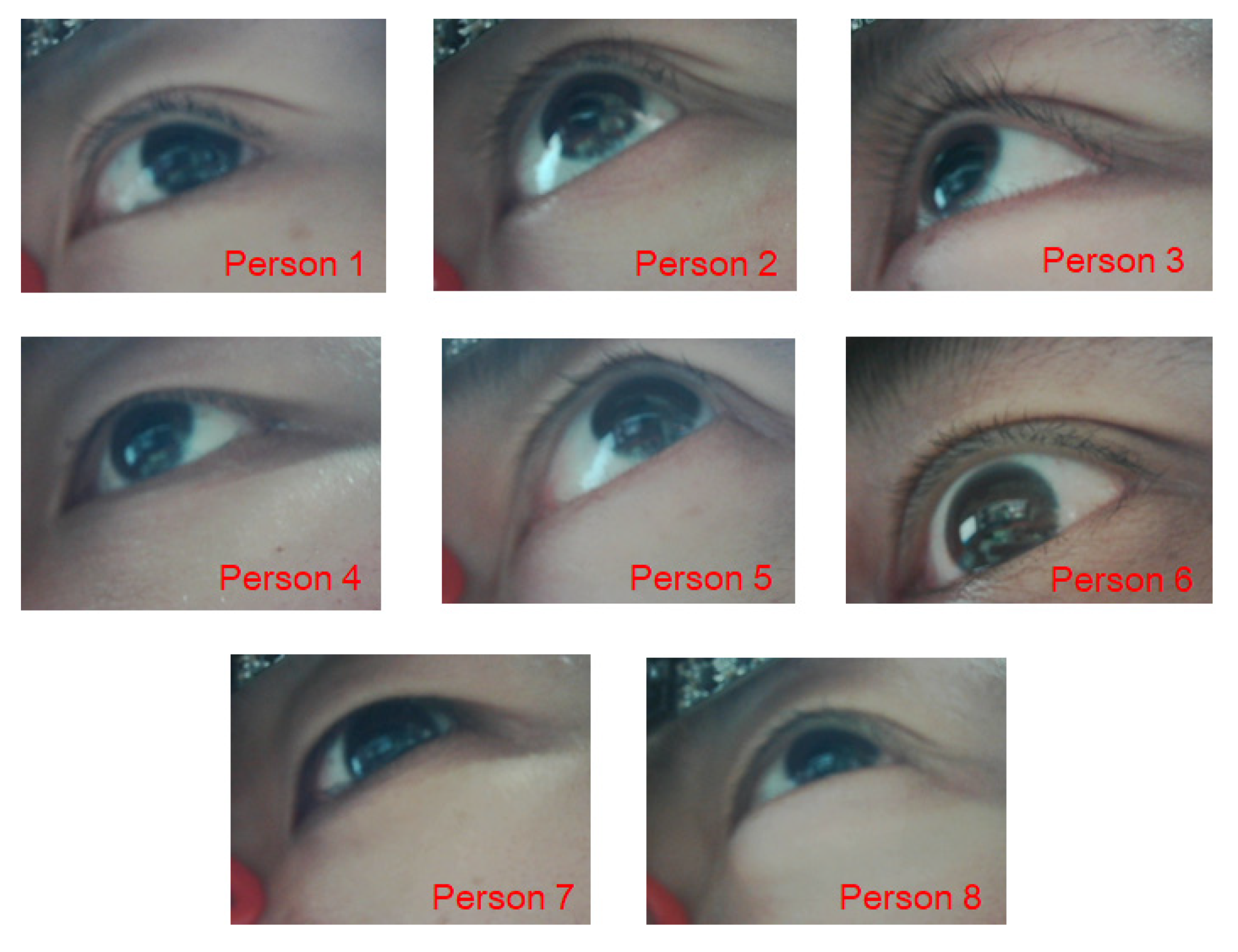
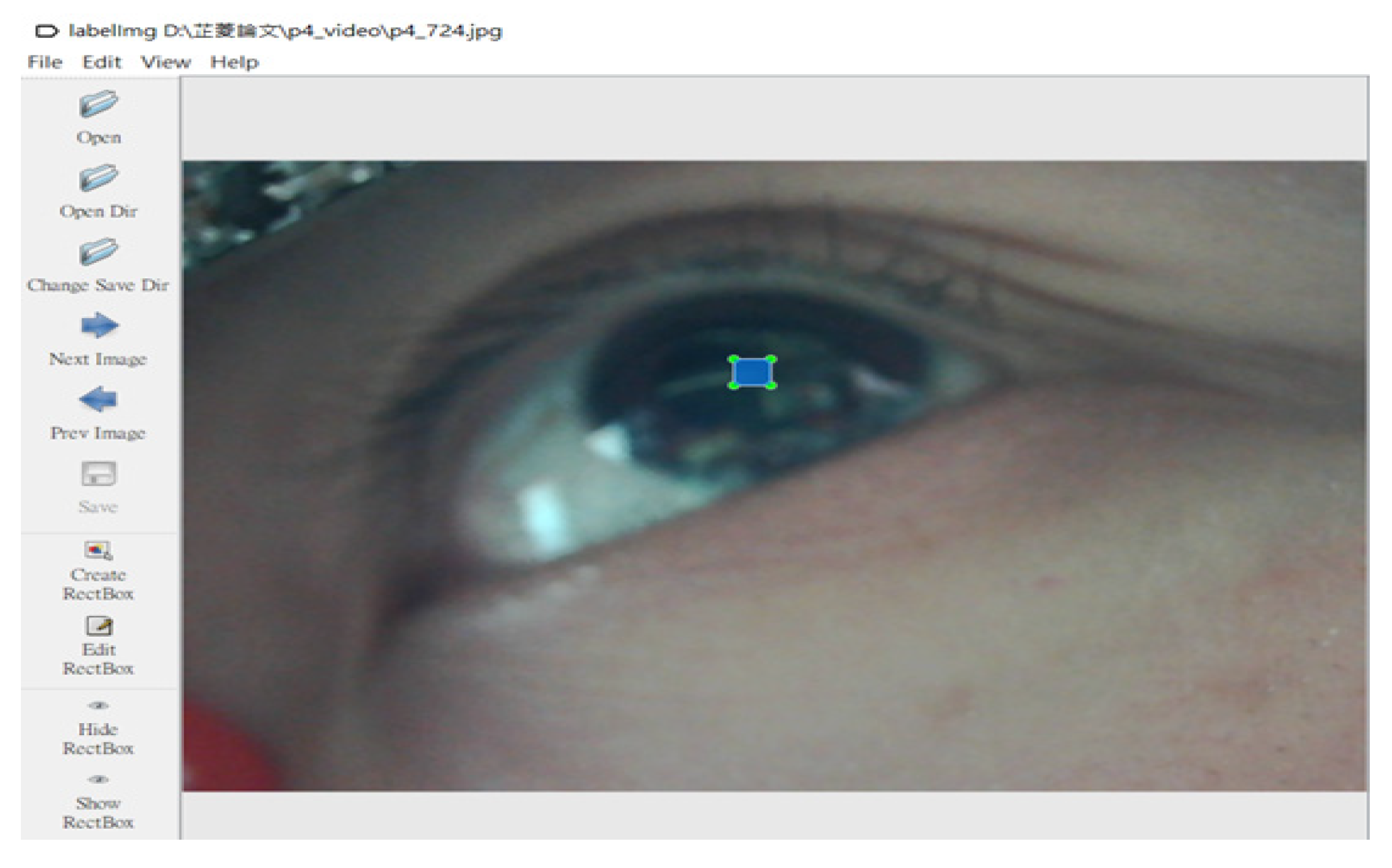
3.1.1. Generation of Training and Validation Datasets
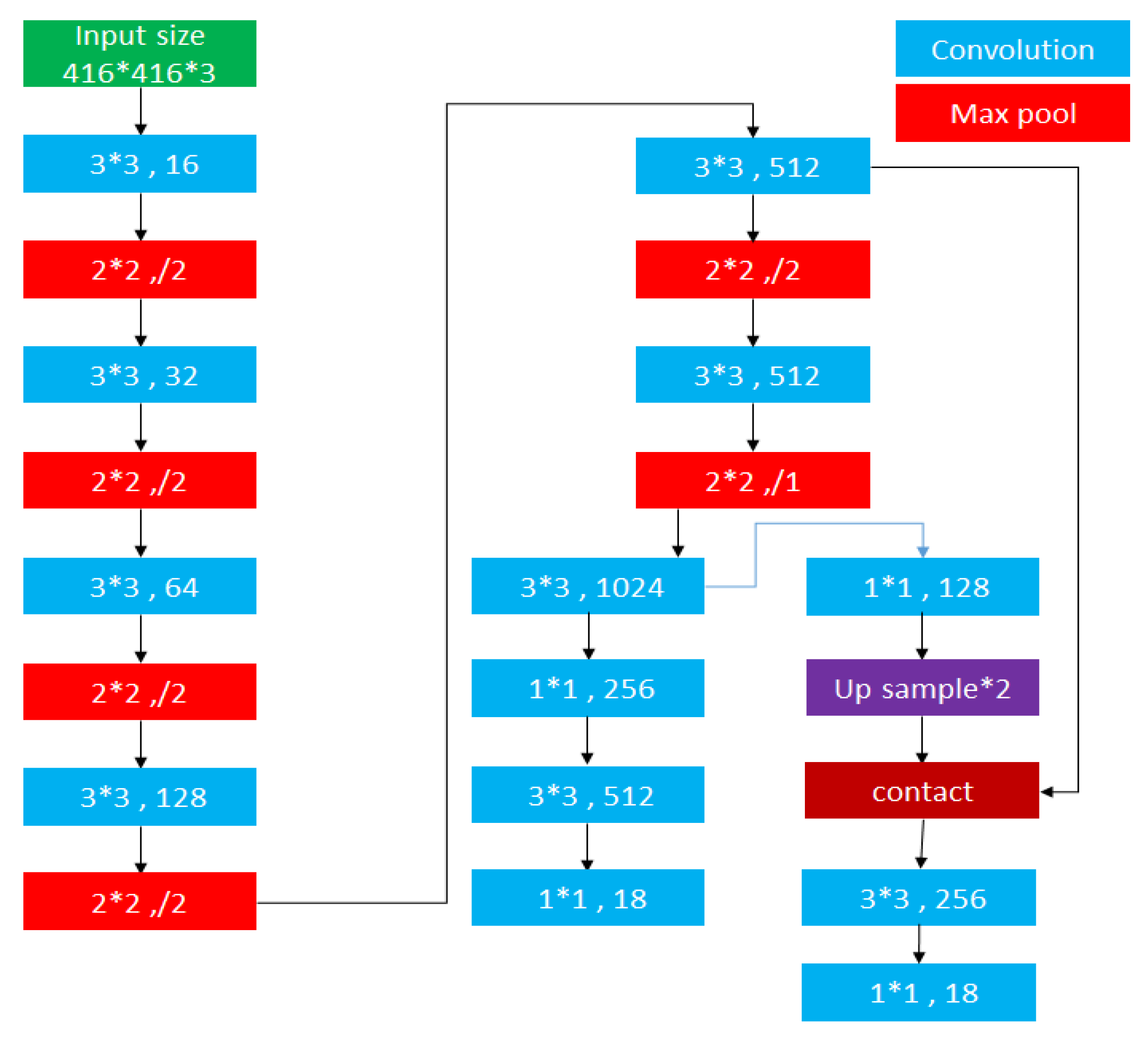
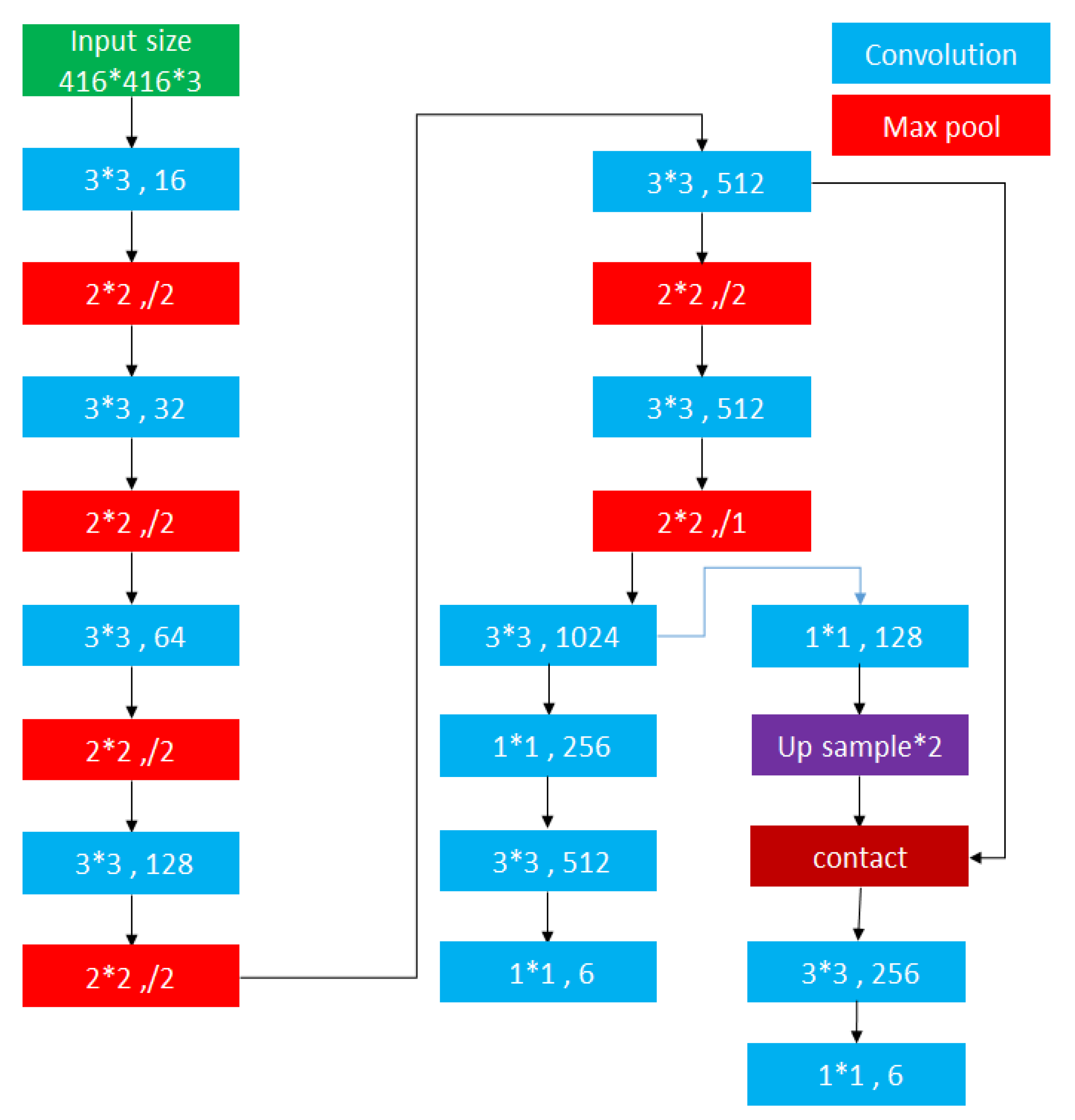
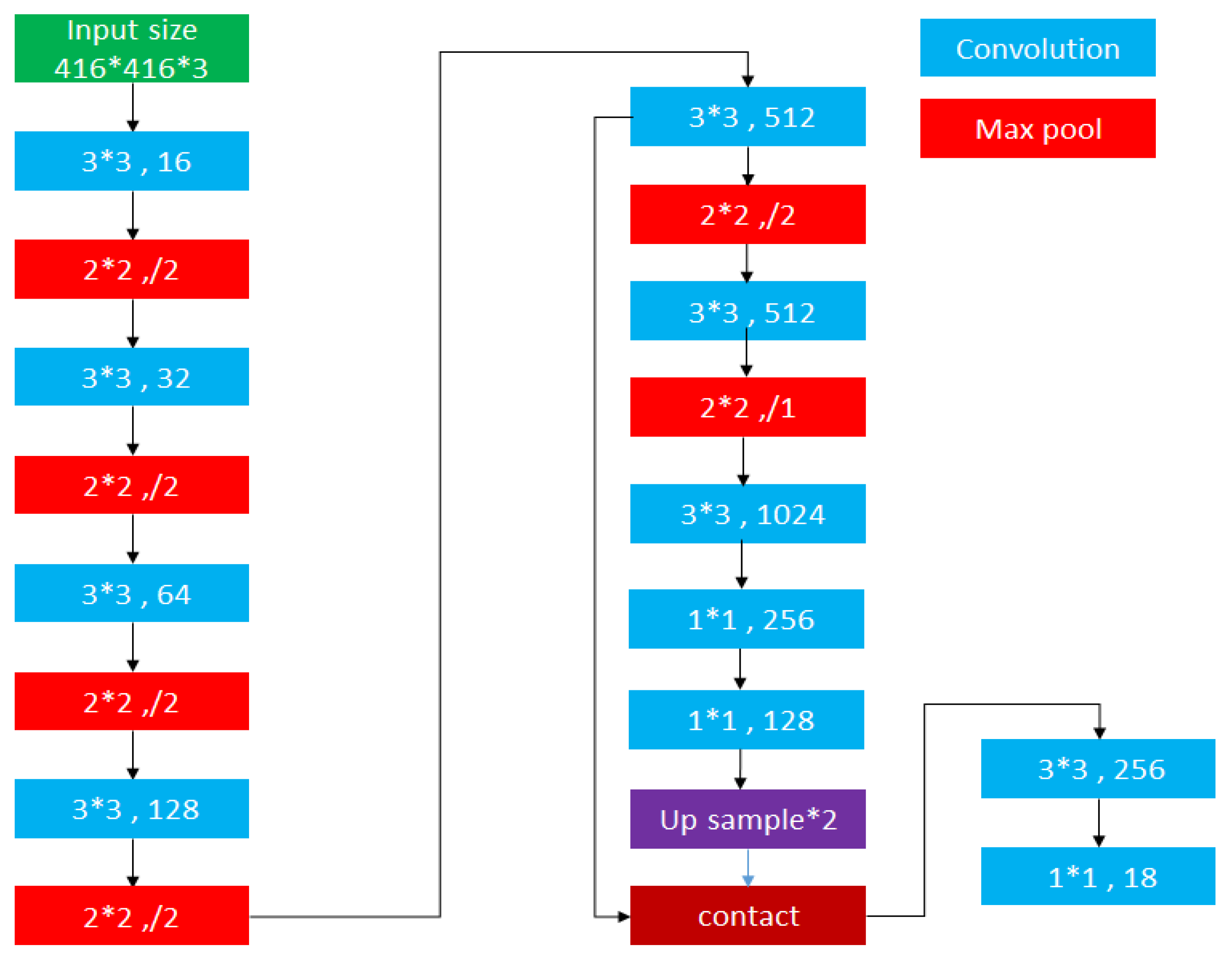
3.1.2. The Used YOLO-Based Models and Training/Validation Process
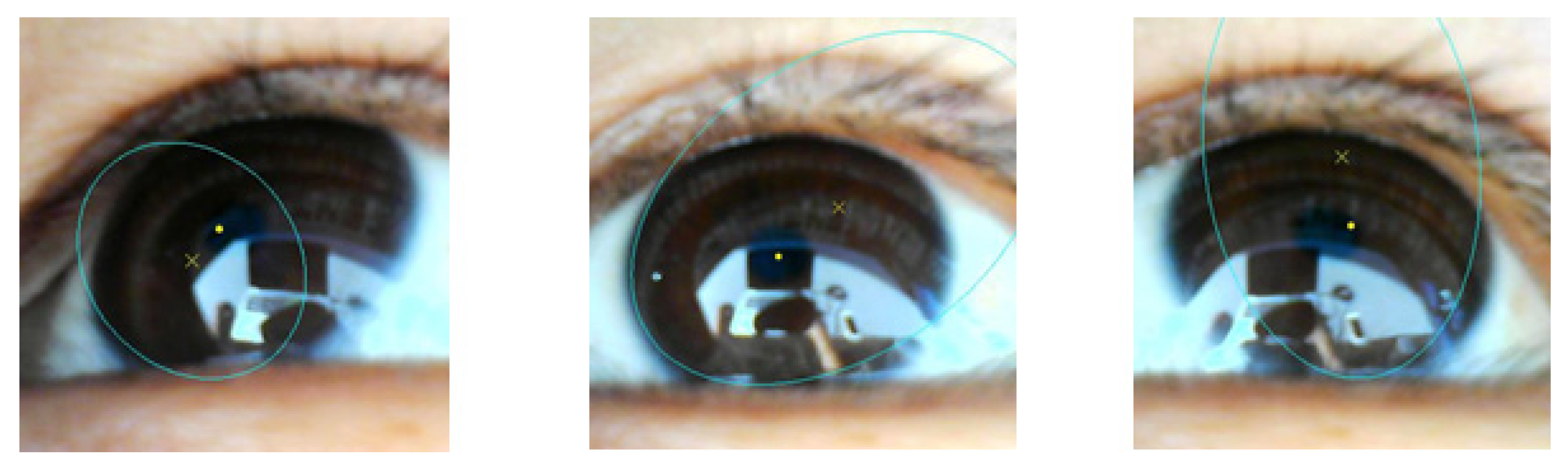
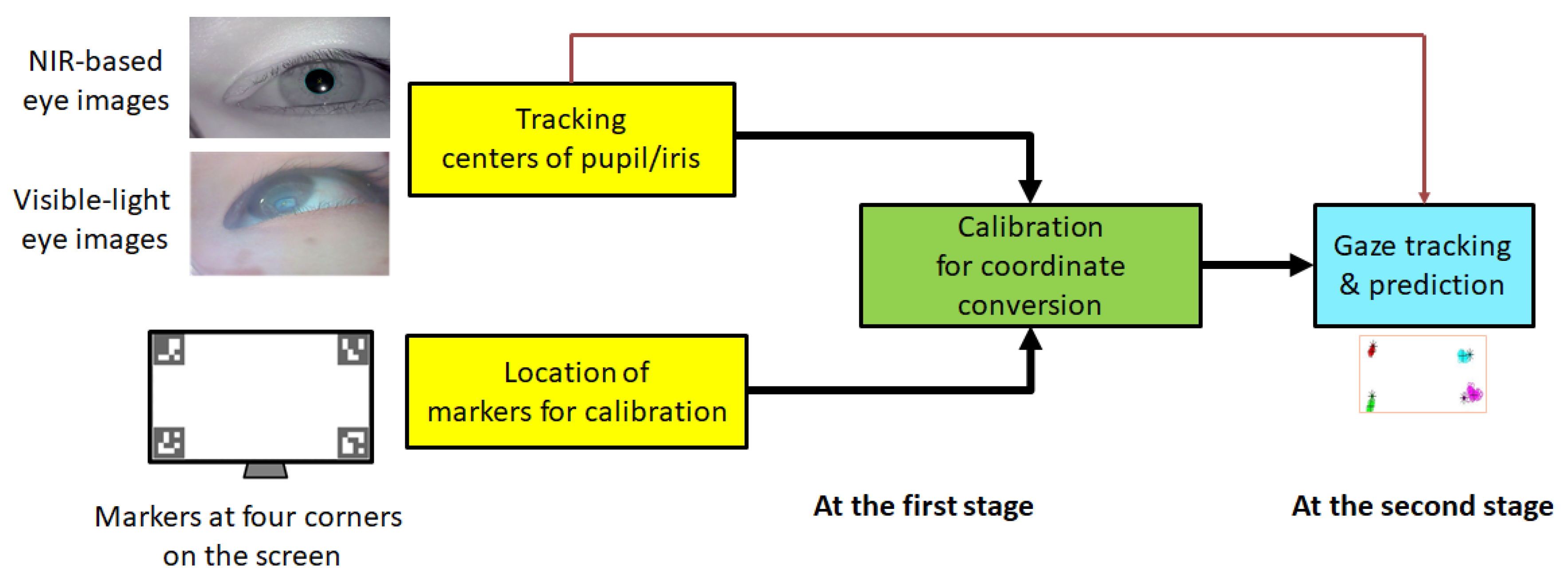
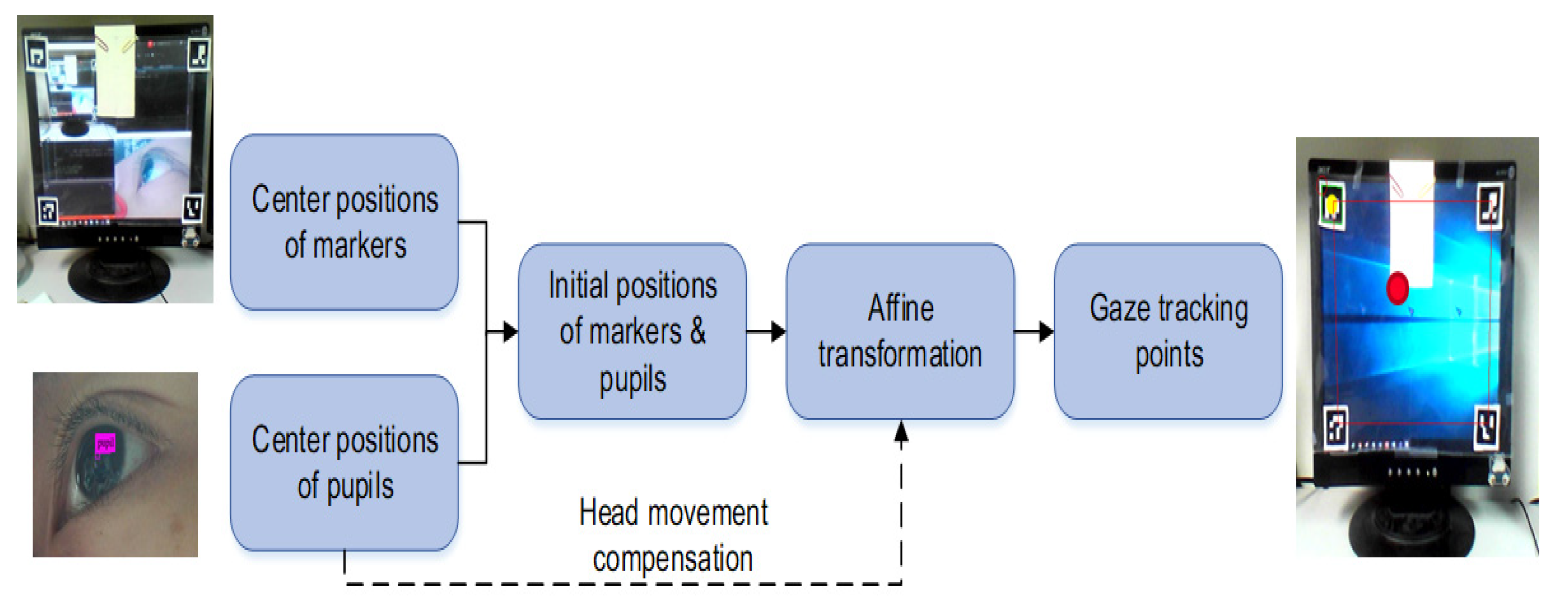
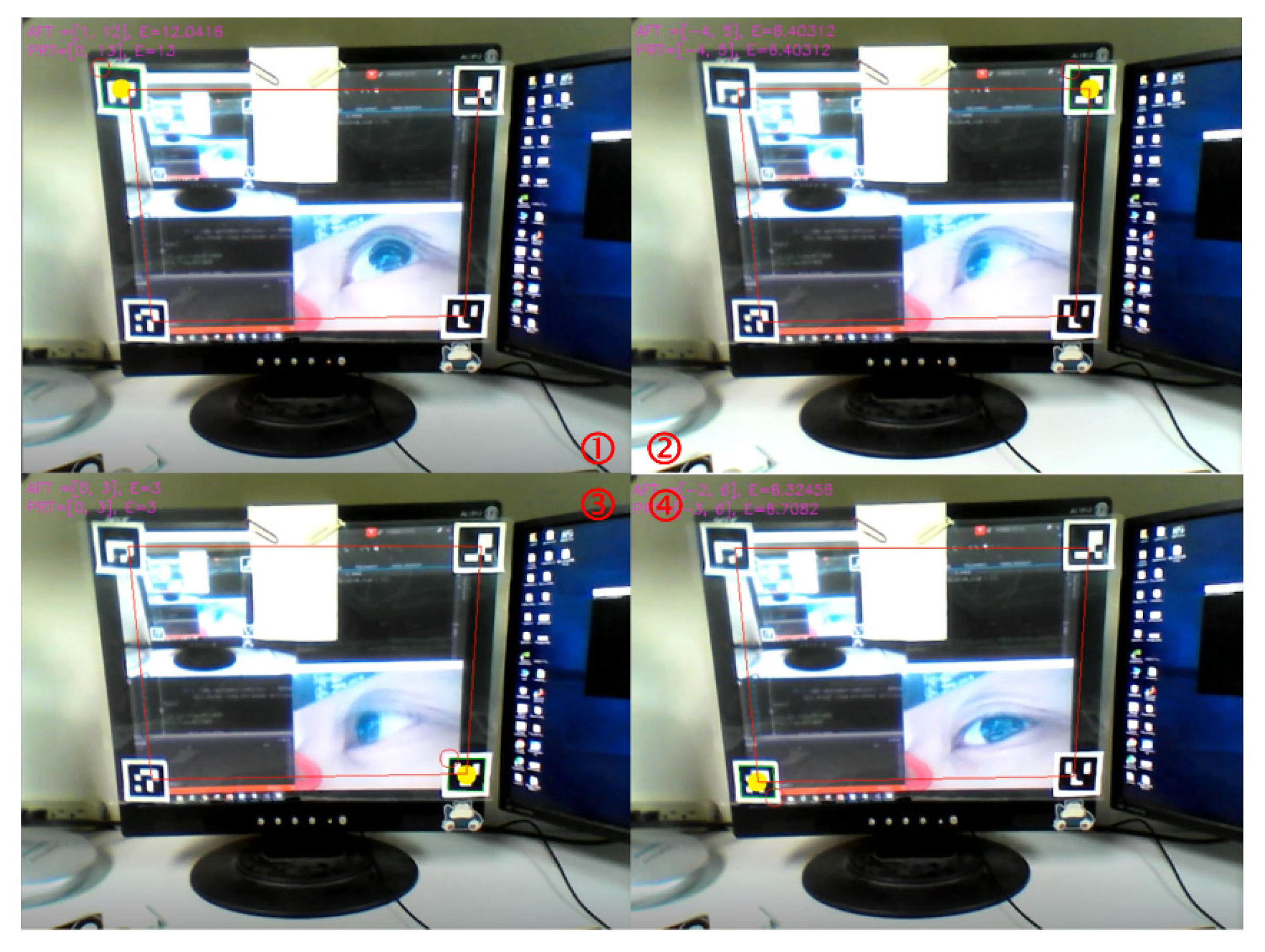
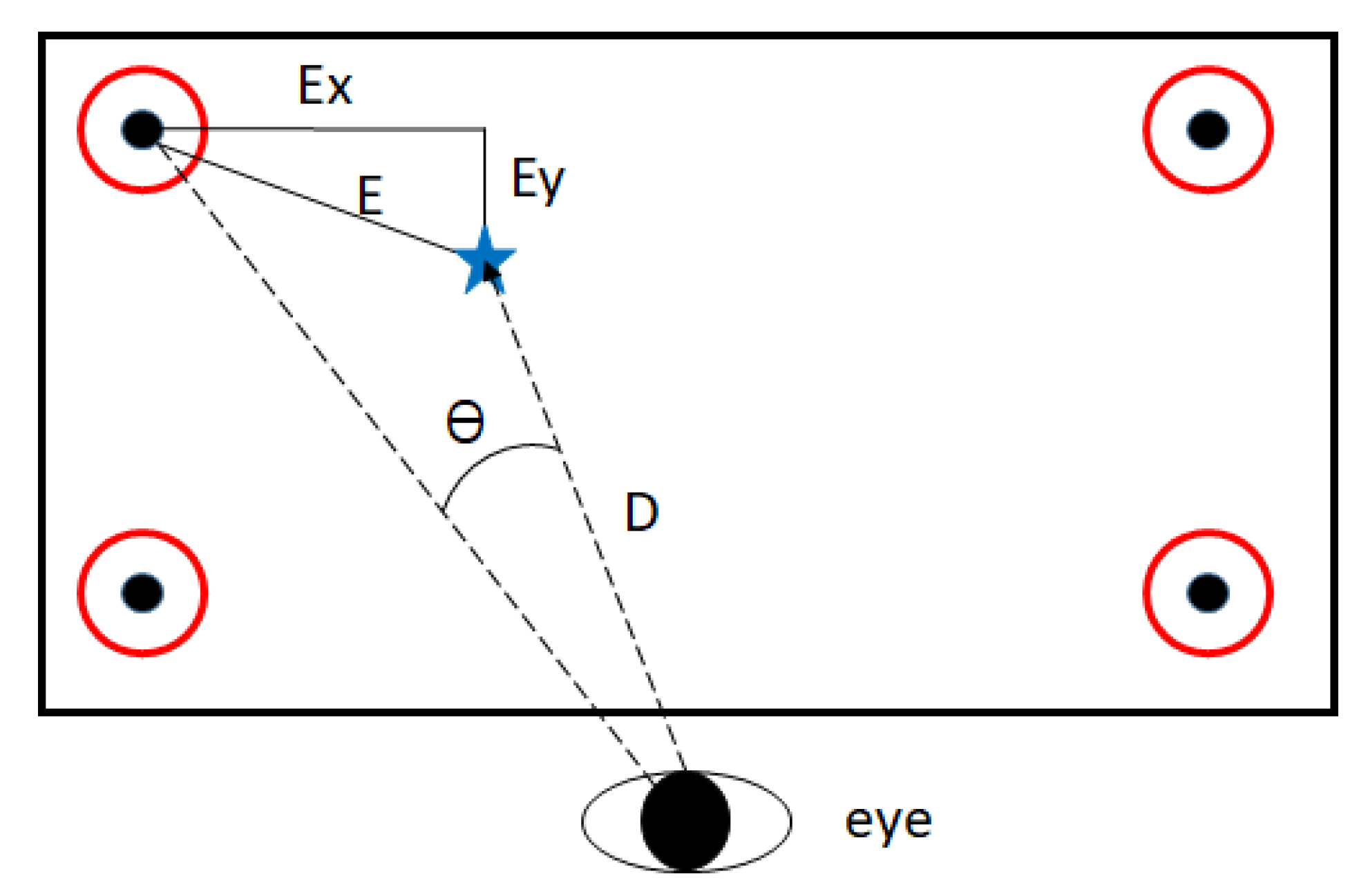
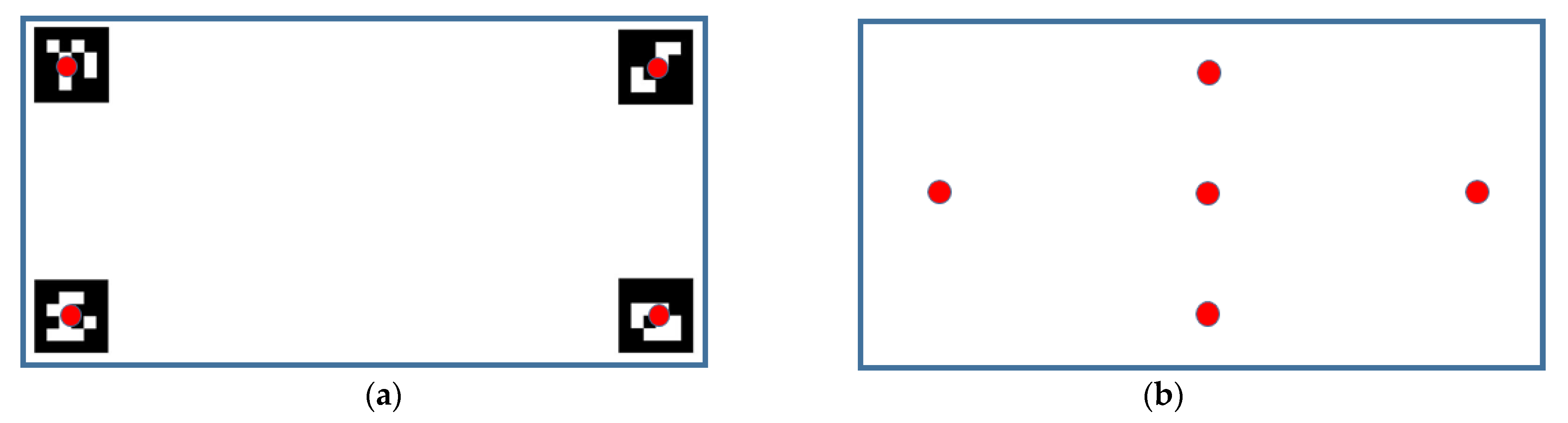
3.2. Calibration and Gaze Tracking Processes
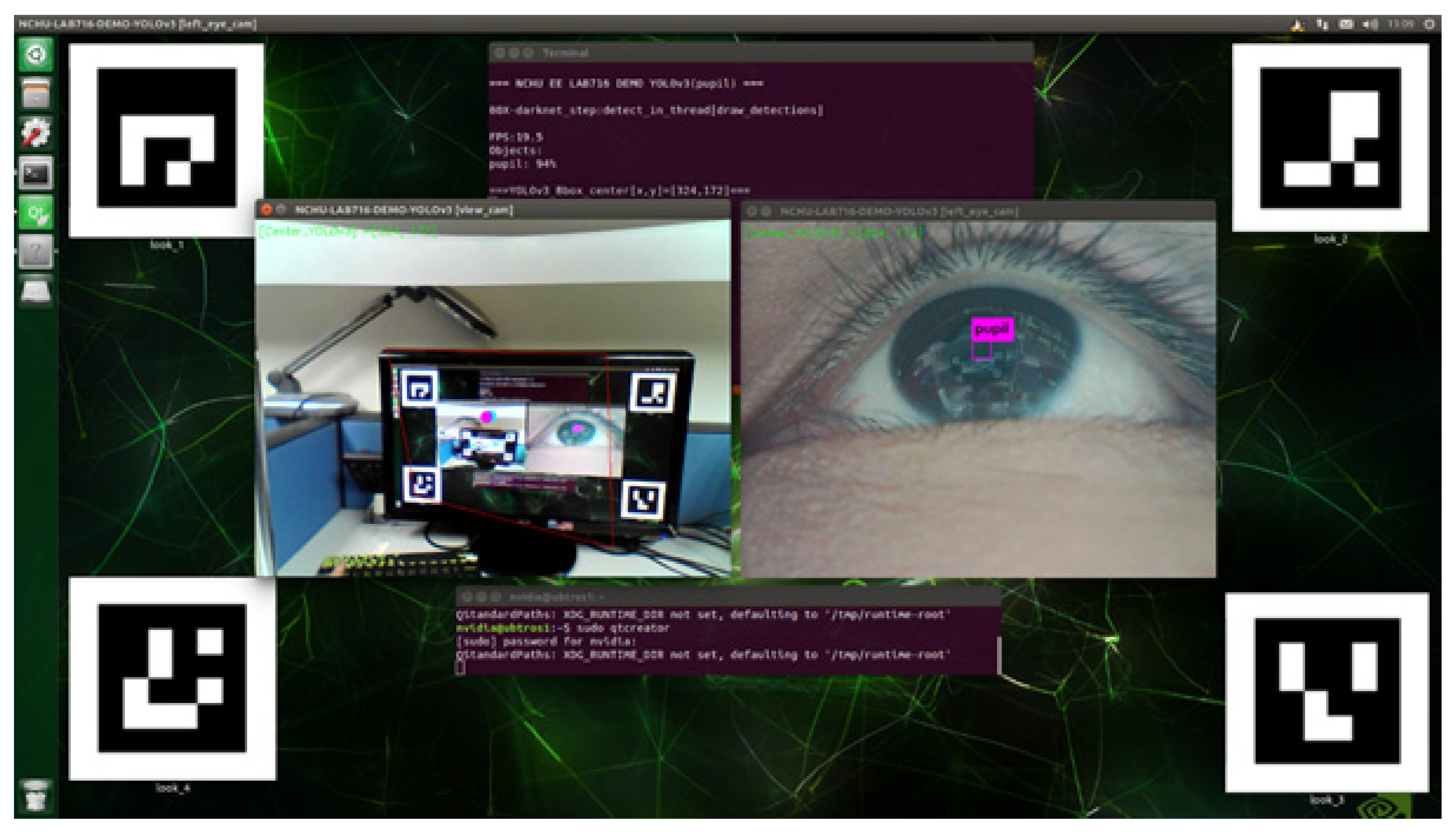
4. Experimental Results and Comparisons
5. Conclusions and Future Work
Author Contributions
Funding
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Chennamma, H.R.; Yuan, X. A Survey on Eye-Gaze Tracking Techniques. Indian J. Comput. Sci. Eng. (IJCSE) 2013, 4, 388–393. [Google Scholar]
- Li, D.; Babcock, J.; Parkhurst, D.J. OpenEyes: A Low-Cost Head-Mounted Eye-Tracking Solution. In Proceedings of the 2006 ACM Eye Tracking Research and Applications Symposium, San Diego, CA, USA, 27–29 March 2006; pp. 95–100. [Google Scholar]
- Fan, C.P. Design and Implementation of Wearable Gaze Tracking Device with Near-Infrared and Visible-Light Image Sensors. In Advances in Modern Sensors-Physics, Design, Simulation and Application; Sinha, G.R., Ed.; IOP Publishing: Bristol, UK, 2020; pp. 12.1–12.14. [Google Scholar]
- Katona, J.; Kovari, A.; Costescu, C.; Rosan, A.; Hathazi, A.; Heldal, I.; Helgesen, C.; Thill, S. The Examination Task of Source-code Debugging Using GP3 Eye Tracker. In Proceedings of the 10th International Conference on Cognitive Infocommunications (CogInfoCom), Naples, Italy, 23–25 October 2019; pp. 329–334. [Google Scholar]
- Katona, J.; Kovari, A.; Heldal, I.; Costescu, C.; Rosan, A.; Demeter, R.; Thill, S.; Stefanut, T. Using Eye-Tracking to Examine Query Syntax and Method Syntax Comprehension in LINQ. In Proceedings of the 11th International Conference on Cognitive Infocommunications (CogInfoCom), Mariehamn, Finland, 23–25 September 2020; pp. 437–444. [Google Scholar]
- Kővári, A.; Katona, J.; Costescu, C. Evaluation of Eye-Movement Metrics in a Software Debugging Task using GP3 Eye Tracker. Acta Polytech. Hung. 2020, 17, 57–76. [Google Scholar] [CrossRef]
- Świrski, L.; Bulling, A.; Dodgson, N. Robust Real-Time Pupil Tracking in Highly Off-Axis Images. In Proceedings of the ACM Proceedings of the Symposium on Eye Tracking Research and Applications, Santa Barbara, CA, USA, 28–30 March 2012; pp. 173–176. [Google Scholar]
- Chen, Y.; Su, J. Fast Eye Localization Based on a New Haar-like Feature. In Proceedings of the 10th World Congress on Intelligent Control and Automation (WCICA), Beijing, China, 6–8 July 2012; pp. 4825–4830. [Google Scholar]
- Ohno, T.; Mukawa, N.; Yoshikawa, A. FreeGaze: A Gaze Tracking System for Everyday Gaze Interaction. In Proceedings of the Eye Tracking Research Applications Symposium, New Orleans, LA, USA, 25–27 March 2002; pp. 125–132. [Google Scholar]
- Morimoto, C.H.; Mimica, M.R.M. Eye Gaze Tracking Techniques for Interactive applications. Comput. Vis. Image Underst. 2005, 98, 4–24. [Google Scholar] [CrossRef]
- Li, D.; Winfield, D.; Parkhurst, D.J. Starburst: A Hybrid Algorithm for Video-Based Eye Tracking Combining Feature-Based and Model-Based Approaches. In Proceedings of the IEEE Computer Vision and Pattern Recognition–Workshops, San Diego, CA, USA, 21–23 September 2005; pp. 1–8. [Google Scholar]
- Sugita, T.; Suzuki, S.; Kolodko, J.; Igarashi, H. Development of Head-Mounted Eye Tracking System achieving Environmental Recognition Ability. In Proceedings of the SICE Annual Conference, Takamatsu, Japan, 17–20 September 2007; pp. 1887–1891. [Google Scholar]
- Chen, S.; Julien, J.E. Efficient and Robust Pupil Size and Blink Estimation from Near-Field Video Sequences for Human-Machine Interaction. IEEE Trans. Cybern. 2014, 44, 2356–2367. [Google Scholar] [CrossRef] [PubMed]
- Zhang, X.; Sugano, Y.; Fritz, M.; Bulling, A. Appearance-Based Gaze Estimation in the Wild. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–10. [Google Scholar]
- Cheng, C.W.; Ou, W.L.; Fan, C.P. Fast Ellipse Fitting Based Pupil Tracking Design for Human-Computer Interaction Applications. In Proceedings of the IEEE International Conference on Consumer Electronics, Las Vegas, NV, USA, 7–11 January 2016; pp. 445–446. [Google Scholar]
- Wu, J.H.; Ou, W.L.; Fan, C.P. NIR-based Gaze Tracking with Fast Pupil Ellipse Fitting for Real-Time Wearable Eye Trackers. In Proceedings of the IEEE Conference on Dependable and Secure Computing, Taipei, Taiwan, 7–10 August 2017; pp. 93–97. [Google Scholar]
- Pires, B.R.; Hwangbo, M.; Devyver, M.; Kanade, T. Visible-Spectrum Gaze Tracking for Sports. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Portland, OR, USA, 23–28 June 2013; pp. 1005–1010. [Google Scholar]
- Kao, W.C.; Chang, W.T.; Wu, S.J.; Liu, C.H.; Yin, S.Y. High Speed Gaze Tracking with Visible Light. In Proceedings of the International Conference on System Science and Engineering (ICSSE), Budapest, Hungary, 4–6 July 2013; pp. 285–288. [Google Scholar]
- Wu, J.H.; Ou, W.L.; Fan, C.P. Fast Iris Ellipse Fitting Based Gaze Tracking with Visible Light for Real-Time Wearable Eye Trackers. In Proceedings of the 5th IEEE Global Conference on Consumer Electronics, Kyoto, Japan, 11–14 October 2016. [Google Scholar]
- Liu, T.L.; Fan, C.P. Visible-Light Based Gaze Tracking with Image Enhancement Pre-processing for Wearable Eye Trackers. In Proceedings of the 6th IEEE Global Conference on Consumer Electronics, Nagoya, Japan, 24–27 October 2017. [Google Scholar]
- Liu, T.L.; Fan, C.P. Visible-Light Wearable Eye Gaze Tracking by Gradients-Based Eye Center Location and Head Movement Compensation with IMU. In Proceedings of the International Conference on Consumer Electronics, Las Vegas, NV, USA, 12–14 January 2018; pp. 1–2. [Google Scholar]
- Sun, H.P.; Yang, C.H.; Lai, S.H. A Deep Learning Approach to Appearance-Based Gaze Estimation under Head Pose Variations. In Proceedings of the 4th IAPR Asian Conference on Pattern Recognition, Nanjing, China, 26–29 November 2017; pp. 935–940. [Google Scholar]
- Yin, Y.; Juan, C.; Chakraborty, J.; McGuire, M.P. Classification of Eye Tracking Data using a Convolutional Neural Network. In Proceedings of the 17th IEEE International Conference on Machine Learning and Applications, Orlando, FL, USA, 17–20 December 2018. [Google Scholar]
- Lemley, J.; Kar, A.; Drimbarean, A.; Corcoran, P. Efficient CNN Implementation for Eye-Gaze Estimation on Low-Power/Low-Quality Consumer Imaging Systems. arXiv 2018, arXiv:1806.10890v1. [Google Scholar]
- Ahmad, M.B.; Saifullah Raja, M.A.; Asif, M.W.; Khurshid, K. i-Riter: Machine Learning Based Novel Eye Tracking and Calibration. In Proceedings of the IEEE International Instrumentation and Measurement Technology Conference, Houston, TX, USA, 14–17 May 2018; 2018. [Google Scholar]
- Cha, X.; Yang, X.; Feng, Z.; Xu, T.; Fan, X.; Tian, J. Calibration-free gaze zone estimation using convolutional neural network. In Proceedings of the International Conference on Security, Pattern Analysis, and Cybernetics, Jinan, China, 14–17 December 2018; pp. 481–484. [Google Scholar]
- Stember, J.N.; Celik, H.; Krupinski, E.; Chang, P.D.; Mutasa, S.; Wood, B.J.; Lignelli, A.; Moonis, G.; Schwartz, L.H.; Jambawalikar, S.; et al. Eye Tracking for Deep Learning Segmentation Using Convolutional Neural Networks. J. Digit. Imaging 2019, 32, 597–604. [Google Scholar] [CrossRef] [PubMed]
- Yiu, Y.H.; Aboulatta, M.; Raiser, T.; Ophey, L.; Flanagin, V.L.; zu Eulenburg, P.; Ahmadi, S.A. DeepVOG: Open-Source Pupil Segmentation and Gaze Estimation in Neuroscience Using Deep Learning. J. Neurosci. Methods 2019, 324, 108307. [Google Scholar] [CrossRef] [PubMed]
- Zhang, X.; Sugano, Y.; Fritz, M.; Bulling, A. MPIIGaze: Real-World Dataset and Deep Appearance-Based Gaze Estimation. IEEE Tran. Pattern Anal. Mach. Intell. 2019, 41, 162–175. [Google Scholar] [CrossRef] [PubMed]
- Stavridis, K.; Psaltis, A.; Dimou, A.; Papadopoulos, G.T.; Daras, P. Deep Spatio-Temporal Modeling for Object-Level Gaze-Based Relevance Assessment. In Proceedings of the 27th European Signal Processing Conference (EUSIPCO), A Coruña, Spain, 2–6 September 2019. [Google Scholar]
- Liu, J.; Lee, B.S.F.; Rajan, D. Free-Head Appearance-Based Eye Gaze Estimation on Mobile Devices. In Proceedings of the International Conference on Artificial Intelligence in Information and Communication (ICAIIC), Okinawa, Japan, 11–13 February 2019; pp. 232–237. [Google Scholar]
- Lian, D.; Hu, L.; Luo, W.; Xu, Y.; Duan, L.; Yu, J.; Gao, S. Multiview Multitask Gaze Estimation with Deep Convolutional Neural Networks. IEEE Tran. Neural Netw. Learn. Syst. 2019, 30, 3010–3023. [Google Scholar] [CrossRef]
- Porta, S.; Bossavit, B.; Cabeza, R.; Larumbe-Bergera, A.; Garde, G.; Villanueva, A. U2Eyes: A binocular dataset for eye tracking and gaze estimation. In Proceedings of the IEEE/CVF International Conference on Computer Vision Workshop, Seoul, Korea, 27–28 October 2019; pp. 3660–3664. [Google Scholar]
- Li, W.Y.; Dong, Q.L.; Jia, H.; Zhao, S.; Wang, Y.C.; Xie, L.; Pan, Q.; Duan, F.; Liu, T.M. Training a Camera to Perform Long-Distance Eye Tracking by Another Eye-Tracker. IEEE Access 2019, 7, 155313–155324. [Google Scholar] [CrossRef]
- Rakhmatulina, I.; Duchowskim, A.T. Deep Neural Networks for Low-Cost Eye Tracking. In Proceedings of the 24th International Conference on Knowledge-Based and Intelligent Information & Engineering Systems, Procedia Computer Science, Verona, Italy, 16–18 September 2020; pp. 685–694. [Google Scholar]
- Brousseau, B.; Rose, J.; Eizenman, M. Hybrid Eye-Tracking on a Smartphone with CNN Feature Extraction and an Infrared 3D Model. Sensors 2020, 20, 543. [Google Scholar] [CrossRef]
- Kuo, T.L.; Fan, C.P. Design and Implementation of Deep Learning Based Pupil Tracking Technology for Application of Visible-Light Wearable Eye Tracker. In Proceedings of the IEEE International Conference on Consumer Electronics, Las Vegas, NV, USA, 4–6 January 2020; pp. 1–2. [Google Scholar]
- Joseph, R.; Farhadi, A. YOLOv3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Kocejko, T.; Bujnowski, A.; Rumiński, J.; Bylinska, E.; Wtorek, J. Head Movement Compensation Algorithm in Multidisplay Communication by Gaze. In Proceedings of the 7th International Conference on Human System Interactions (HSI), Costa da Caparica, Portugal, 16–18 June 2014; pp. 88–94. [Google Scholar]
- LabelImg: The graphical image annotation tool. Available online: https://github.com/tzutalin/labelImg (accessed on 26 November 2020).
- NVIDIA Jetson AGX Xavier. Available online: https://www.nvidia.com (accessed on 26 November 2020).


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Deep-learning-based Methods | Operational Mode/Setup | Dataset Used | Eye/Pupil Tracking Method | Gaze Estimation and Calibration Scheme |
|---|---|---|---|---|
| Sun et al. [22] | Visible-light mode /Non-Wearable | UT Multiview | Uses a facial landmarks-based design to locate eye regions | Multiple pose-based and VGG-like CNN models for gaze estimation |
| Lemley et al. [24] | Visible-light mode /Non-Wearable | MPII Gaze | The CNN-based eye detection | Joint eye-gaze CNN architecture with both eyes for gaze estimation |
| Cha et al. [26] | Visible-light mode /Non-Wearable | Self-made dataset | Uses the OpenCV method to extract the face region and eye region | GoogleNetV1 based gaze estimation |
| Zhang et al. [29] | Visible-light mode /Non-Wearable | MPII Gaze | Uses face alignment and 3D face model fitting to find eye zones | VGGNet-16-based GazeNet for gaze estimation |
| Lian et al. [32] | Visible-light mode /Non-Wearable | ShanghaiTechGaze and MPII Gaze | Uses the ResNet-34 model for eye features extraction | CNN-based multi-view and multi-task gaze estimation |
| Li et al. [34] | Visible-light mode /Non-Wearable | Self-made dataset | Uses the OpenFace CLM-framework/Face++/YOLOv3 to extract facial ROI and landmarks | Infrared-LED based calibration |
| Rakhmatulin et al. [35] | Visible-light mode /Non-Wearable | Self-made dataset | Uses YOLOv3 to detect the eyeball and eye’s corners | Infrared-LED based calibration |
| Brousseau et al. [36] | Infrared mode /Non-Wearable | Self-made dataset | Eye-Feature locator CNN model | 3D gaze-estimation model-based design |
| Yiu et al. [28] | Near-eye infrared mode /Wearable | German center for vertigo and balance disorders | Uses a fully convolutional neural network for pupil segmentation and uses ellipse fitting to locate the eye center | 3D eyeball model, marker, and projector-assisted-based calibration |
| Proposed design | Near-eye visible-light mode/Wearable | Self-made dataset | Uses the YOLOv3-tiny-based lite model to detect the pupil zone | Marker and affine transform-based calibration |
| Actual Values | |||
|---|---|---|---|
| Positives | Negatives | ||
| Predictive values | Positives | True Positives (TP) | False Positives (FP) |
| Negatives | False Negatives (FN) | True Negatives (TN) | |
| Model | Validation | Test | ||
|---|---|---|---|---|
| Precision | Recall | Precision | Recall | |
| YOLOv3-tiny (original) | 81.40% | 83% | 78.43% | 81% |
| YOLOv3-tiny (one anchor) | 80.19% | 84% | 80.50% | 83% |
| YOLOv3-tiny (one anchor/one way) | 79.79% | 82% | 76.82% | 81% |
| Methods | Ellipse Fitting Based Design [15] | Gradients-Based Design [21] | YOLOv3-Tiny (Original) |
|---|---|---|---|
| Average tracking errors (pixels) | Larger than 50 | 5.99 | 1.62 |
| Standard deviation (pixels) | 63.1 | N/A | 2.03 |
| Max/min errors (pixels) | 294/0 | 40/0 | 21/0 |
| Model | Mean Errors (Pixels) | Variance (Pixels) |
|---|---|---|
| YOLOv3-tiny (original) | 1.62 | 2.03 |
| YOLOv3-tiny (one anchor) | 1.58 | 1.87 |
| YOLOv3-tiny (one anchor/one way) | 1.46 | 1.75 |
| Model | Mean Errors (Pixels) | Variance (Pixels) |
|---|---|---|
| YOLOv3-tiny (original) | 4.11 | 2.31 |
| YOLOv3-tiny (one anchor) | 3.99 | 2.27 |
| YOLOv3-tiny (one anchor/one way) | 4.93 | 2.31 |
| Model | BFLOPS |
|---|---|
| YOLOv3-tiny (original) | 5.448 |
| YOLOv3-tiny (one anchor) | 5.441 |
| YOLOv3-tiny (one anchor/one way) | 5.042 |
| Model | Mean Gaze Tracking Errors, θ (Degrees) | Variance (Degrees) |
|---|---|---|
| YOLOv3-tiny (original) | 2.131 | 0.249 |
| YOLOv3-tiny (one anchor) | 2.22 | 0.227 |
| YOLOv3-tiny (one anchor/one way) | 2.959 | 0.384 |
| Model | Mean Gaze trAcking Errors, θ (Degrees) | Variance (Degrees) |
|---|---|---|
| YOLOv3-tiny (original) | 2.434 | 0.468 |
| YOLOv3-tiny (one anchor) | 2.57 | 0.268 |
| YOLOv3-tiny (one anchor/one way) | 3.523 | 0.359 |
| Deep-learning-based Methods | Operational Mode/Setup | Pupil Tracking Errors | Gaze Estimation Errors |
|---|---|---|---|
| Sun et al. [22] | Visible-light mode /Non-Wearable | N/A | Mean errors are less than 7.75 degrees |
| Lemley et al. [24] | Visible-light mode /Non-Wearable | N/A | Less than 3.64 degrees |
| Cha et al. [26] | Visible-light mode /Non-Wearable | N/A | Accuracy 92.4% by 9 gaze zones |
| Zhang et al. [29] | Visible-light mode /Non-Wearable | N/A | Mean errors are 10.8 degrees for cross-dataset /Less than 5.5 degrees for cross-person |
| Lian et al. [32] | Visible-light mode /Non-Wearable | N/A | Less than 5 degrees |
| Li et al. [34] | Visible-light mode /Non-Wearable | N/A | Less than 2 degrees at training mode /Less than 5 degrees at testing mode |
| Rakhmatulin et al. [35] | Visible-light mode /Non-Wearable | N/A | Less than 2 degrees |
| Brousseau et al. [36] | Infrared mode /Non-Wearable | Less than 6 pixels | Gaze-estimation bias is 0.72 degrees |
| Yiu et al. [28] | Near-eye infrared mode/Wearable | Median accuracy is 1.0 pixel | Less than 0.5 degrees |
| Proposed design | Near-eye visible-light mode/Wearable | Less than 5 pixels for the cross-person testing mode | Less than 2.9 degrees for the training mode /Less than 3.5 degrees for the testing mode |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ou, W.-L.; Kuo, T.-L.; Chang, C.-C.; Fan, C.-P. Deep-Learning-Based Pupil Center Detection and Tracking Technology for Visible-Light Wearable Gaze Tracking Devices. Appl. Sci. 2021, 11, 851. https://doi.org/10.3390/app11020851
Ou W-L, Kuo T-L, Chang C-C, Fan C-P. Deep-Learning-Based Pupil Center Detection and Tracking Technology for Visible-Light Wearable Gaze Tracking Devices. Applied Sciences. 2021; 11(2):851. https://doi.org/10.3390/app11020851
Chicago/Turabian StyleOu, Wei-Liang, Tzu-Ling Kuo, Chin-Chieh Chang, and Chih-Peng Fan. 2021. "Deep-Learning-Based Pupil Center Detection and Tracking Technology for Visible-Light Wearable Gaze Tracking Devices" Applied Sciences 11, no. 2: 851. https://doi.org/10.3390/app11020851
APA StyleOu, W.-L., Kuo, T.-L., Chang, C.-C., & Fan, C.-P. (2021). Deep-Learning-Based Pupil Center Detection and Tracking Technology for Visible-Light Wearable Gaze Tracking Devices. Applied Sciences, 11(2), 851. https://doi.org/10.3390/app11020851