Integrating Dilated Convolution into DenseLSTM for Audio Source Separation

Abstract
1. Introduction
2. Related Works
3. Proposed Architecture
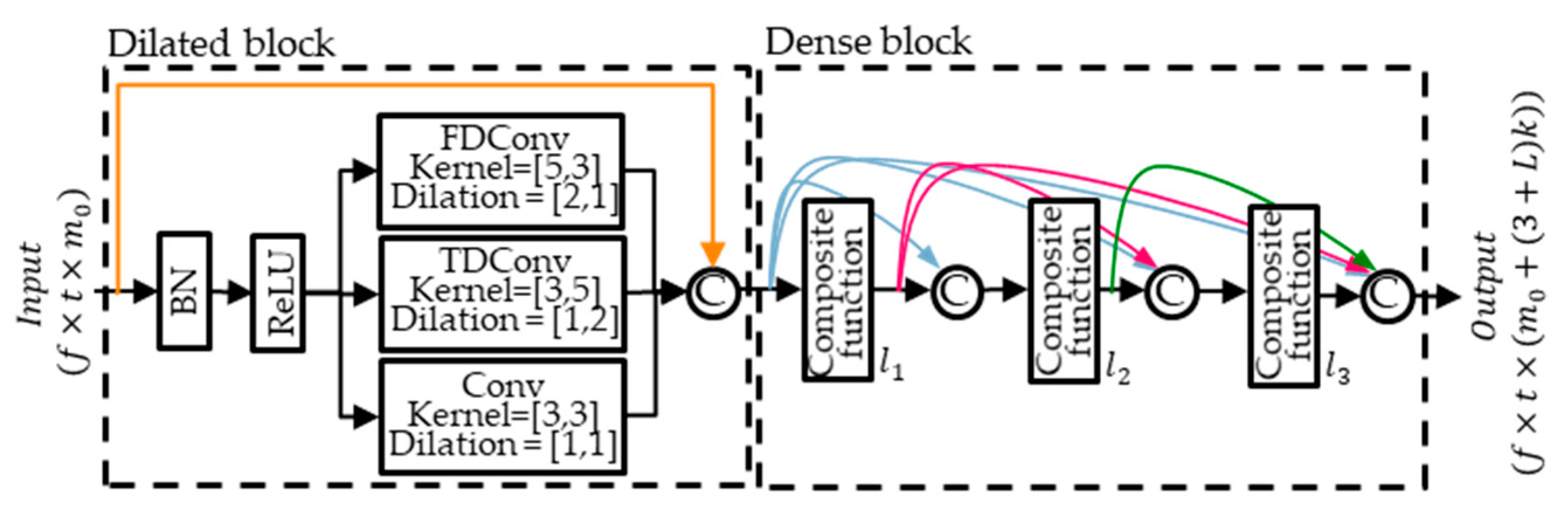
3.1. DenseNet and Dilated Dense Block
3.2. Multi-Scale Dilated Time-Frequency DenseLSTM
3.3. Multi-Scale Multi-Band Dilated Time-Frequency DenseLSTM
4. Experiments
4.1. Speech Experiment
4.1.1. Dataset for Speech Experiment
4.1.2. Setup for Speech Experiment
4.1.3. Experimental Results of the Subjective Quality Measure for Speech Enhancement
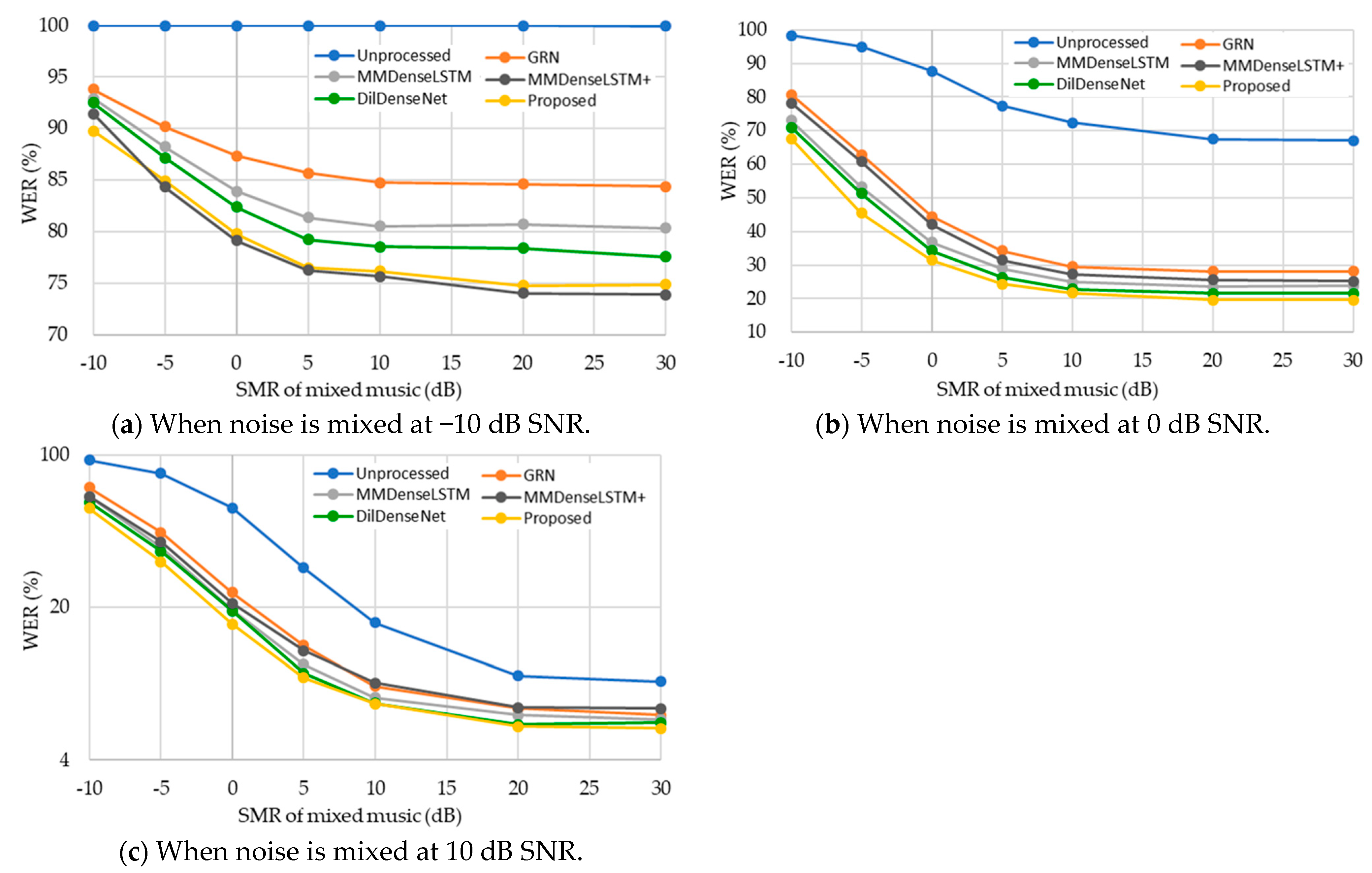
4.1.4. Experimental Results of the Objective Measures for Speech Enhancement and Recognition
4.2. Music Experiment
4.2.1. Dataset for Music Experiment
4.2.2. Setup for Music Experiment
4.2.3. Experimental Results for Music Signal Separation and Identification
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Bregman, A.S. Auditory Scene Analysis: The Perceptual Organization of Sound; The MIT Press: Cambridge, MA, USA, 1990. [Google Scholar]
- Hirsch, H.G.; Ehrlicher, C. Noise estimation techniques for robust speech recognition. In Proceedings of the IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP), Detroit, MI, USA, 9–12 May 1995; Volume 1, pp. 153–156. [Google Scholar]
- Zhang, H.; Liu, C.; Inoue, N.; Shinoda, K. Multi-task autoencoder for noise-robust speech recognition. In Proceedings of the IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018; pp. 5599–5603. [Google Scholar]
- Lee, D.D.; Seung, H.S. Learning the parts of objects by non-negative matrix factorization. Nature 1999, 401, 788–791. [Google Scholar] [CrossRef]
- Fan, H.T.; Hung, J.; Lu, X.; Wang, S.S.; Tsao, Y. Speech enhancement using segmental nonnegative matrix factorization. In Proceedings of the IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP), Florence, Italy, 4–9 May 2014; pp. 4483–4487. [Google Scholar]
- Sprechmann, P.; Bronstein, A.M.; Sapiro, G. Supervised non-Euclidean sparse NMF via bilevel optimization with applications to speech enhancement. In Proceedings of the Joint Workshop on Hands-free Speech Communication and Microphone Arrays (HSCMA), Nancy, France, 12–14 May 2014; pp. 11–15. [Google Scholar]
- Vincent, E.; Bertin, N.; Gribonval, R.; Bimbot, F. From blind to guided audio source separation: How models and side information can improve the separation of sound. IEEE Signal Process. Mag. 2014, 31, 107–115. [Google Scholar] [CrossRef]
- Wang, Y.; Wang, D. Towards scaling up classification-based speech separation. IEEE Trans. Audio Speech Lang. Process. 2013, 21, 1381–1390. [Google Scholar]
- Xu, Y.; Du, J.; Dai, L.-R.; Lee, C.-H. An experimental study on speech enhancement based on deep neural networks. IEEE Signal Process. Lett. 2014, 21, 65–68. [Google Scholar] [CrossRef]
- Kang, T.G.; Kwon, K.; Shin, J.W.; Kim, N.S. NMF-based target source separation using deep neural network. IEEE Signal Process. Lett. 2015, 22, 229–233. [Google Scholar] [CrossRef]
- Grais, E.; Sen, M.; Erdogan, H. Deep neural networks for single channel source separation. In Proceedings of the IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP), Florence, Italy, 4–9 May 2014; pp. 3734–3738. [Google Scholar]
- Nugraha, A.A.; Liutkus, A.; Vincent, E. Multichannel music separation with deep neural networks. In Proceedings of the European Signal Processing Conference (EUSIPCO), Budapest, Hungary, 29 August–2 September 2015; pp. 1748–1752. [Google Scholar]
- Uhlich, S.; Giron, F.; Mitsufuji, Y. Deep neural network based instrument extraction from music. In Proceedings of the IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP), Brisbane, Australia, 19–24 April 2015; pp. 2135–2139. [Google Scholar]
- Le Roux, J.; Hershey, J.; Weninger, F. Deep NMF for speech separation. In Proceedings of the IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP), Brisbane, Australia, 19–24 April 2015; pp. 66–70. [Google Scholar]
- Hsu, K.Y.; Li, H.Y.; Psaltis, D. Holographic implementation of a fully connected neural network. Proc. IEEE 1990, 78, 1637–1645. [Google Scholar] [CrossRef]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]
- Werbos, P.J. Backpropagation through time: What it does and how to do it. Proc. IEEE 1990, 78, 1550–1560. [Google Scholar] [CrossRef]
- Chen, J.; Wang, D. Long short-term memory for speaker generalization in supervised speech separation. J. Acoust. Soc. Am. 2017, 141, 4705–4714. [Google Scholar] [CrossRef]
- Weninger, F.; Eyben, F.; Schuller, B. Single-channel speech separation with memory-enhanced recurrent neural networks. In Proceedings of the IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP), Florence, Italy, 4–9 May 2014; pp. 3709–3713. [Google Scholar]
- Fu, S.-W.; Tsao, Y.; Lu, X. SNR-aware convolutional neural network modeling for speech enhancement. In Proceedings of the INTERSPEECH, San Francisco, CA, USA, 8–12 September 2016; pp. 3768–3772. [Google Scholar]
- Kounovsky, T.; Malek, J. Single channel speech enhancement using convolutional neural network. In Proceedings of the IEEE International Workshop of Electronics, Control, Measurement, Signals and their Application to Mechatronics (ECMSM), San Sebastian, Spain, 24–26 May 2017; pp. 1–5. [Google Scholar]
- Uhlich, S.; Porcu, M.; Giron, F.; Enenkl, M.; Kemp, T.; Takahashi, N.; Mitsufuji, Y. Improving music source separation based on deep neural networks through data augmentation and network blending. In Proceedings of the IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP), New Orleans, LA, USA, 5–9 March 2017; pp. 261–265. [Google Scholar]
- Jansson, A.; Humphrey, E.; Montecchio, N.; Bittner, R.; Kumar, A.; Weyde, T. Singing voice separation with deep U-Net convolutional networks. In Proceedings of the International Society for Music Information Retrieval Conference (ISMIR), Montreal, QC, Canada, 4–8 November 2017; pp. 745–751. [Google Scholar]
- Park, S.; Kim, T.; Lee, K.; Kwak, N. Music source separation using stacked hourglass networks. In Proceedings of the International Society for Music Information Retrieval Conference (ISMIR), Paris, France, 23–27 September 2018; pp. 289–296. [Google Scholar]
- Takahashi, N.; Mitsufuji, Y. Multi-scale multi-band DenseNets for audio source separation. In Proceedings of the IEEE Workshop on Applications of Signal Processing to Audio and Acoustics (WASPAA), New Paltz, NY, USA, 15–18 October 2017; pp. 21–25. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Graves, A.; Schmidhuber, J. Framewise phoneme classification with bidirectional LSTM networks. In Proceedings of the IEEE International Joint Conference on Neural Networks, Montreal, QC, Canada, 31 July–4 August 2005; Volume 4, pp. 2047–2052. [Google Scholar]
- Shi, B.; Bai, X.; Yao, C. An end-to-end trainable neural network for image-based sequence recognition and its application to scene text recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 2298–2304. [Google Scholar] [CrossRef]
- Li, A.; Yuan, M.; Zheng, C.; Li, X. Speech enhancement using progressive learning-based convolutional recurrent neural network. Appl. Acoust. 2020, 166, 107347. [Google Scholar] [CrossRef]
- Chakrabarty, S.; Habets, E.A.P. Time–frequency masking based online multi-channel speech enhancement with convolutional recurrent neural networks. IEEE J. Sel. Top. Signal Process. 2019, 13, 787–799. [Google Scholar] [CrossRef]
- Takahashi, N.; Goswami, N.; Mitsufuji, Y. MMDenseLSTM: An efficient combination of convolutional and recurrent neural networks for audio source separation. In Proceedings of the International Workshop on Acoustic Signal Enhancement (IWAENC), Tokyo, Japan, 17–20 September 2018; pp. 106–110. [Google Scholar]
- Hubel, D.H.; Wiesel, T.N. Receptive fields, binocular interaction and functional architecture in the cat’s visual cortex. J. Physiol. 1962, 160, 106–154. [Google Scholar] [CrossRef]
- Heo, W.-H.; Kim, H.; Kwon, O.-W. Source separation using dilated time-frequency DenseNet for music identification in broadcast contents. Appl. Sci. 2020, 10, 1727. [Google Scholar] [CrossRef]
- Yu, F.; Koltun, V. Multi-scale context aggregation by dilated convolutions. In Proceedings of the International Conference on Learning Representations (ICLR), San Juan, PR, USA, 2–4 May 2016. [Google Scholar]
- Tan, K.; Chen, J.; Wang, D. Gated residual networks with dilated convolutions for monaural speech enhancement. IEEE Trans. Audio Speech Lang. Process. 2019, 27, 189–198. [Google Scholar] [CrossRef]
- Huang, G.; Liu, Z.; Weinberger, K.Q.; Maaten, L. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 24–30 June 2017; pp. 4700–4708. [Google Scholar]
- Stoller, D.; Ewert, S.; Dixon, S. Wave-U-Net: A multi-scale neural network for end-to-end audio source separation. arXiv 2018, arXiv:1806.03185. [Google Scholar]
- Luo, Y.; Mesgarani, N. Conv-TasNet: Surpassing ideal time–frequency magnitude masking for speech separation. IEEE/ACM Trans. Audio Speech Lang. Process. 2019, 27, 1256–1266. [Google Scholar] [CrossRef]
- Ciaburro, G. Sound event detection in underground parking garage using convolutional neural network. Big Data Cogn. Comput. 2020, 4, 20. [Google Scholar] [CrossRef]
- Ciaburro, G.; Iannace, G. Improving smart cities safety using sound events detection based on deep neural network algorithms. Informatics 2020, 7, 23. [Google Scholar] [CrossRef]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In Proceedings of the International Conference on Machine Learning (ICML), Lille, France, 6–11 July 2015; pp. 448–456. [Google Scholar]
- Glorot, X.; Bordes, A.; Bengio, Y. Deep sparse rectifier neural networks. In Proceedings of the International Conference on Artificial Intelligence and Statistics (AISTATS), Fort Lauderdale, FL, USA, 11–13 April 2011; pp. 315–323. [Google Scholar]
- Xu, Y.; Du, J.; Huang, Z.; Dai, L.-R.; Lee, C.-H. Multi-objective learning and mask-based post-processing for deep neural network based speech enhancement. In Proceedings of the INTERSPEECH, Dresden, Germany, 6–10 September 2015; pp. 1508–1512. [Google Scholar]
- Piczak, K.J. ESC: Dataset for environmental sound classification. In Proceedings of the ACM International Conference on Multimedia, New York, NY, USA, 12–16 October 2015; pp. 1015–1018. [Google Scholar]
- Varga, A.; Steeneken, H.J.M. Assessment for automatic speech recognition: II. NOISEX-92: A database and an experiment to study the effect of additive noise on speech recognition systems. Speech Commun. 1993, 12, 247–251. [Google Scholar] [CrossRef]
- CSR-II (WSJ1) Complete. Available online: https://catalog.ldc.upenn.edu/LDC94S13A (accessed on 23 July 2020).
- The MUSDB18 Corpus for Music Separation. Available online: https://doi.org/10.5281/zenodo.1117372 (accessed on 28 August 2020).
- Kingma, D.; Ba, J. Adam: A method for Stochastic Optimization. In Proceedings of the International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Vincent, E.; Gribonval, R.; Fevotte, C. Performance measurement in blind audio source separation. IEEE Trans. Audio Speech Lang. Process. 2006, 14, 1462–1469. [Google Scholar] [CrossRef]
- Rix, A.; Beerends, J.; Hollier, M.; Hekstra, A. Perceptual evaluation of speech quality (PESQ)-a new method for speech quality assessment of telephone networks and codecs. In Proceedings of the IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP), Salt Lake City, UT, USA, 7–11 May 2001; pp. 749–752. [Google Scholar]
- Taal, C.; Hendriks, R.; Heusdens, R.; Jensen, J. An algorithm for intelligibility prediction of time-frequency weighted noisy speech. IEEE Trans. Audio Speech Lang. Process. 2011, 19, 2125–2136. [Google Scholar] [CrossRef]
- Ma, J.; Hu, Y.; Loizou, P.C. Objective measures for predicting speech intelligibility in noisy conditions based on new band-importance functions. J. Acoust. Soc. Am. 2009, 125, 3387–3405. [Google Scholar] [CrossRef]
- Kates, J.M.; Arehart, K.H. Coherence and the speech intelligibility index. J. Acoust. Soc. Am. 2005, 117, 2224–2237. [Google Scholar] [CrossRef]
- Povey, D.; Ghoshal, A.; Boulianne, G.; Burget, L.; Glembek, O.; Goel, N.; Hannemann, M.; Motlicek, P.; Qian, Y.; Schwarz, P.; et al. The Kaldi speech recognition toolkit. In Proceedings of the IEEE Workshop on Automatic Speech Recognition and Understanding (ASRU), Waikoloa, HI, USA, 11–15 December 2011. [Google Scholar]
- Pirhosseinloo, S.; Brumberg, J.S. Monaural speech enhancement with dilated convolutions. In Proceedings of the INTERSPEECH, Graz, Austria, 15–19 September 2019; pp. 3143–3147. [Google Scholar]
- Wang, P.; Wang, D. Enhanced spectral features for distortion-independent acoustic modeling. In Proceedings of the INTERSPEECH, Graz, Austria, 15–19 September 2019; pp. 476–480. [Google Scholar]
- Choi, H.S.; Kim, J.H.; Huh, J.; Kim, A.; Ha, J.W.; Lee, K. Phase-aware speech enhancement with deep complex u-net. In Proceedings of the International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Gillick, L.; Cox, S.J. Some statistical issues in the comparison of speech recognition algorithms. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Glasgow, UK, 23–26 May 1989; pp. 532–535. [Google Scholar]
- Wang, A. An industrial strength audio search algorithm. In Proceedings of the International Society for Music Information Retrieval Conference (ISMIR), Baltimore, MD, USA, 26–30 October 2003; pp. 7–13. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Low (15, 5, 0.095) | Middle (4, 4, 0.25) | High (2, 1, 0.4) | Full (7, -, 0.2) | ||
|---|---|---|---|---|---|
| Layer | |||||
| Conv | 1, 32 | 1, 32 | 1, 32 | 1, 32 | |
| DDB and CP1 | 1, 13 | 1, 15 | 1, 16 | 1, 14 | |
| DS1 | 1/2, 13 | 1/2, 15 | 1/2, 16 | 1/2, 14 | |
| DDB and CP2 | 1/2, 11 | 1/2, 10 | 1/2, 9 | 1/2, 11 | |
| DS2 | 1/4, 11 | 1/4, 10 | 1/4, 9 | 1/4, 11 | |
| DDB and CP3 | 1/4, 11 | 1/4, 9 | 1/4, 7 (8) | 1/4, 12 | |
| DS3 | 1/8, 11 | 1/8, 9 | - | 1/8, 12 | |
| DDB and CP4 | 1/8, 12 (128) | 1/8, 10 (32) | - | 1/8, 13 | |
| DS4 | - | - | - | 1/16, 13 | |
| DDB and CP5 | - | - | - | 1/16, 14 (128) | |
| US4 and CC4 | - | - | - | 1/8, 27 | |
| DDB and CP6 | - | - | - | 1/8, 16 | |
| US3 and CC3 | 1/4, 23 | 1/4, 19 | - | 1/4, 28 | |
| DDB and CP7 | 1/4, 12 | 1/4, 11 | - | 1/4, 15 | |
| US2 and CC2 | 1/2, 23 | 1/2, 21 | 1/2, 16 | 1/2, 26 | |
| DDB and CP8 | 1/2, 13 (128) | 1/2, 12 | 1/2, 9 | 1/2, 14 (128) | |
| US1 and CC1 | 1, 26 | 1, 27 | 1, 25 | 1, 28 | |
| DDB and CP9 | 1, 13 | 1, 13 | 1, 13 | 1, 14 | |
| Concatenation | 1, 27 | ||||
| DDB and CP10 | (Parameter: = 12, = 3, = 0.2) 1, 19 | ||||
| Conv | 1, 1 | ||||
| DB | Noise | Music | Speech | ||
|---|---|---|---|---|---|
| 115 Noise | ESC-50 | NOISEX-92 | MUSDB | WSJ1 | |
| Training | 2.3 h (165 types) | Not used | 5 h (86 songs) | 30 h (57 utterances 284 speakers) | |
| Validation | 30 min (165 types) | Not used | 1 h (14 songs) | 5 h (35 utterances 60 speakers) | |
| Test | Not used | 18 min (6 types) | 3.5 h (50 songs) | 30 min (284 utterances 10 speakers) | |
| Remark | Used for training and validation | Used for test | Different song for each dataset | Independent speaker for each dataset | |
| Environment | Hard | Medium | Easy | Total | |
|---|---|---|---|---|---|
| Model Comparison | |||||
| Proposed > DilDenseNet | 0.60 () | 0.60 () | 0.59 () | 0.60 () | |
| Proposed > MMDenseLSTM | 0.61 () | 0.67 () | 0.62 () | 0.63 () | |
| Proposed > GRN | 0.89 () | 0.79 () | 0.71 () | 0.80 () | |
| DilDenseNet > MMDenseLSTM | 0.57 (n.s.) | 0.51 (n.s.) | 0.42 (n.s.) | 0.50 (n.s.) | |
| DilDenseNet > GRN | 0.79 () | 0.79 () | 0.68 () | 0.76 () | |
| MMDenseLSTM > GRN | 0.88 () | 0.82 () | 0.88 () | 0.86 () | |
| Architecture | |
|---|---|
| GRN | 3.11 |
| MMDenseLSTM | 0.98 |
| MMDenseLSTM+ | 1.51 |
| DilDenseNet | 0.47 |
| Proposed | 1.49 |
| SNR | −10 | 0 | 10 | |
|---|---|---|---|---|
| Architecture | ||||
| GRN | 87.26 | 44.04 | 24.89 | |
| MMDenseLSTM | 84.01 | 37.79 | 21.91 | |
| MMDenseLSTM+ | 79.24 | 41.51 | 23.01 | |
| DilDenseNet | 82.26 | 35.54 | 20.77 | |
| Proposed | 79.55 | 32.83 | 19.20 | |
| DB | Music | Speech | Remark |
|---|---|---|---|
| Training | extracted 1 sample in each song (1673 songs, 5 h 30 min) | 1673 samples (5 h 30 min) | Used for the training and validation of the separation model |
| Validation | extracted 1 sample in each song (150 songs, 30 min) | 150 samples (30 min) | |
| Test | extracted 2 samples in each song (7295 songs, 48 h) | 1823 samples (6 h) | Used for measuring the separation and identification performances |
| All | 9118 songs | 3646 samples |
| Architecture | 0 dB MSR | −10 dB MSR | ||
|---|---|---|---|---|
| Median SDR | Mean SDR | Median SDR | Mean SDR | |
| U-Net | 6.24 | 6.19 | 3.18 | 3.11 |
| Wave-U-Net | 6.33 | 6.22 | 2.97 | 2.86 |
| MDenseNet | 6.98 | 6.86 | 3.84 | 3.67 |
| MMDenseNet | 7.15 | 7.10 | 4.04 | 3.91 |
| MMDenseLSTM | 7.40 | 7.38 | 4.13 | 4.05 |
| DilDenseNet | 7.72 | 7.63 | 4.44 | 4.32 |
| Proposed | 7.69 | 7.65 | 4.54 | 4.40 |
| Architecture | 0 dB MSR | −10 dB MSR | ||
|---|---|---|---|---|
| MI Accuracy | MI Accuracy | |||
| Unprocessed | 43.38 | 20.2 | 4.59 | 11.8 |
| U-Net | 42.33 | 16.0 | 19.38 | 11.8 |
| Wave-U-Net | 54.77 | 19.1 | 26.89 | 12.4 |
| MDenseNet | 52.57 | 19.1 | 28.44 | 13.2 |
| MMDenseNet | 49.66 | 17.4 | 26.67 | 12.3 |
| MMDenseLSTM | 67.94 | 22.0 | 44.96 | 14.9 |
| DilDenseNet | 71.91 | 23.8 | 48.03 | 15.5 |
| Proposed | 73.35 | 25.0 | 50.75 | 16.1 |
| Oracle | 95.92 | 72.6 | 95.92 | 72.6 |
| Architecture | 0 dB MSR | −10 dB MSR | ||
|---|---|---|---|---|
| Unprocessed | 32.0 | 2.9 | 27.0 | 1.6 |
| U-Net | 29.7 | 2.1 | 25.1 | 1.6 |
| Wave-U-Net | 33.7 | 2.6 | 30.4 | 1.7 |
| MDenseNet | 25.7 | 2.6 | 21.6 | 1.8 |
| MMDenseNet | 23.7 | 2.0 | 20.1 | 1.5 |
| MMDenseLSTM | 31.0 | 2.9 | 26.4 | 1.9 |
| DilDenseNet | 30.3 | 3.1 | 25.8 | 2.0 |
| Proposed | 30.7 | 3.3 | 26.6 | 2.1 |
| Oracle | 33.6 | 9.5 | 33.6 | 9.5 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Heo, W.-H.; Kim, H.; Kwon, O.-W. Integrating Dilated Convolution into DenseLSTM for Audio Source Separation. Appl. Sci. 2021, 11, 789. https://doi.org/10.3390/app11020789
Heo W-H, Kim H, Kwon O-W. Integrating Dilated Convolution into DenseLSTM for Audio Source Separation. Applied Sciences. 2021; 11(2):789. https://doi.org/10.3390/app11020789
Chicago/Turabian StyleHeo, Woon-Haeng, Hyemi Kim, and Oh-Wook Kwon. 2021. "Integrating Dilated Convolution into DenseLSTM for Audio Source Separation" Applied Sciences 11, no. 2: 789. https://doi.org/10.3390/app11020789
APA StyleHeo, W.-H., Kim, H., & Kwon, O.-W. (2021). Integrating Dilated Convolution into DenseLSTM for Audio Source Separation. Applied Sciences, 11(2), 789. https://doi.org/10.3390/app11020789