Deep Learning-Based Computer-Aided Diagnosis System for Gastroscopy Image Classification Using Synthetic Data


Abstract
1. Introduction
2. Materials and Methods
2.1. Dataset
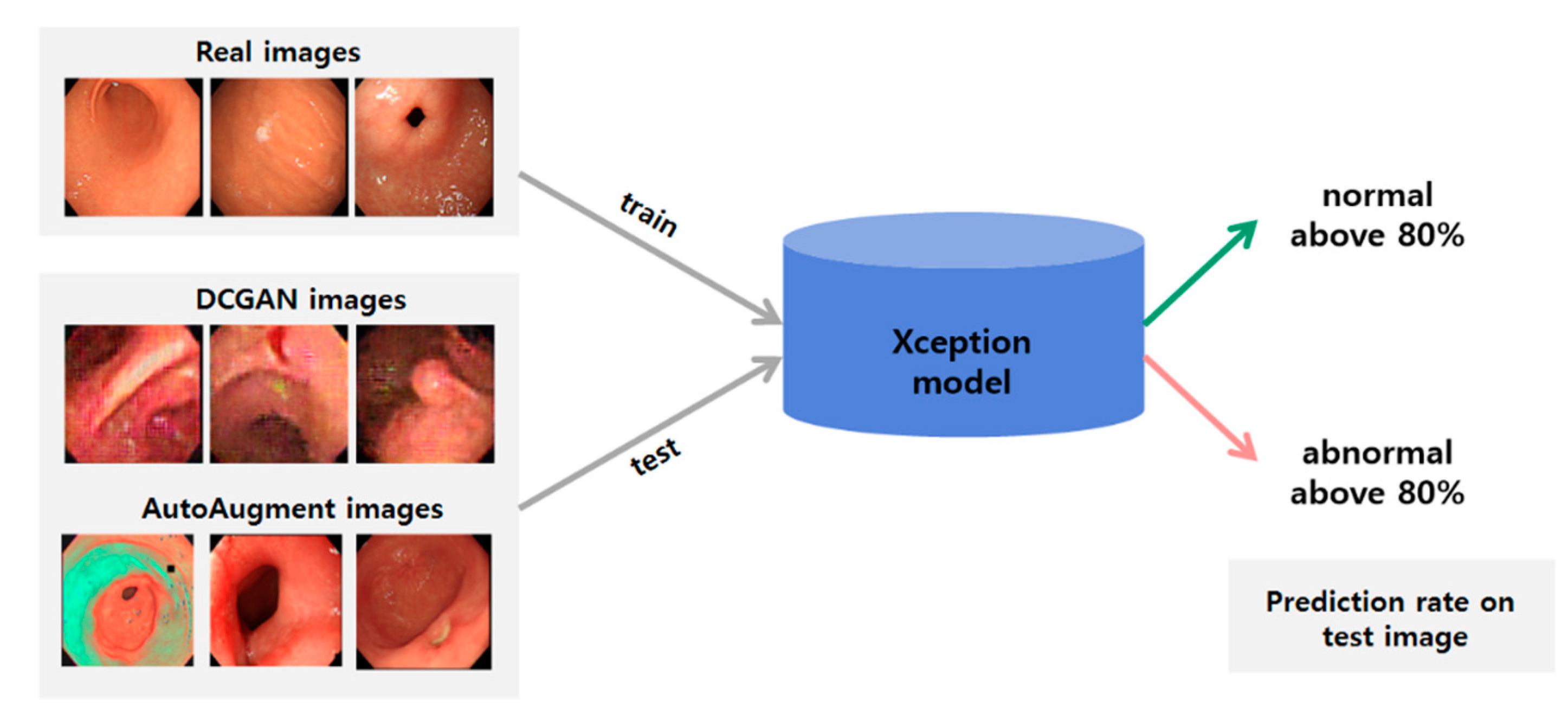
2.2. Classification Method
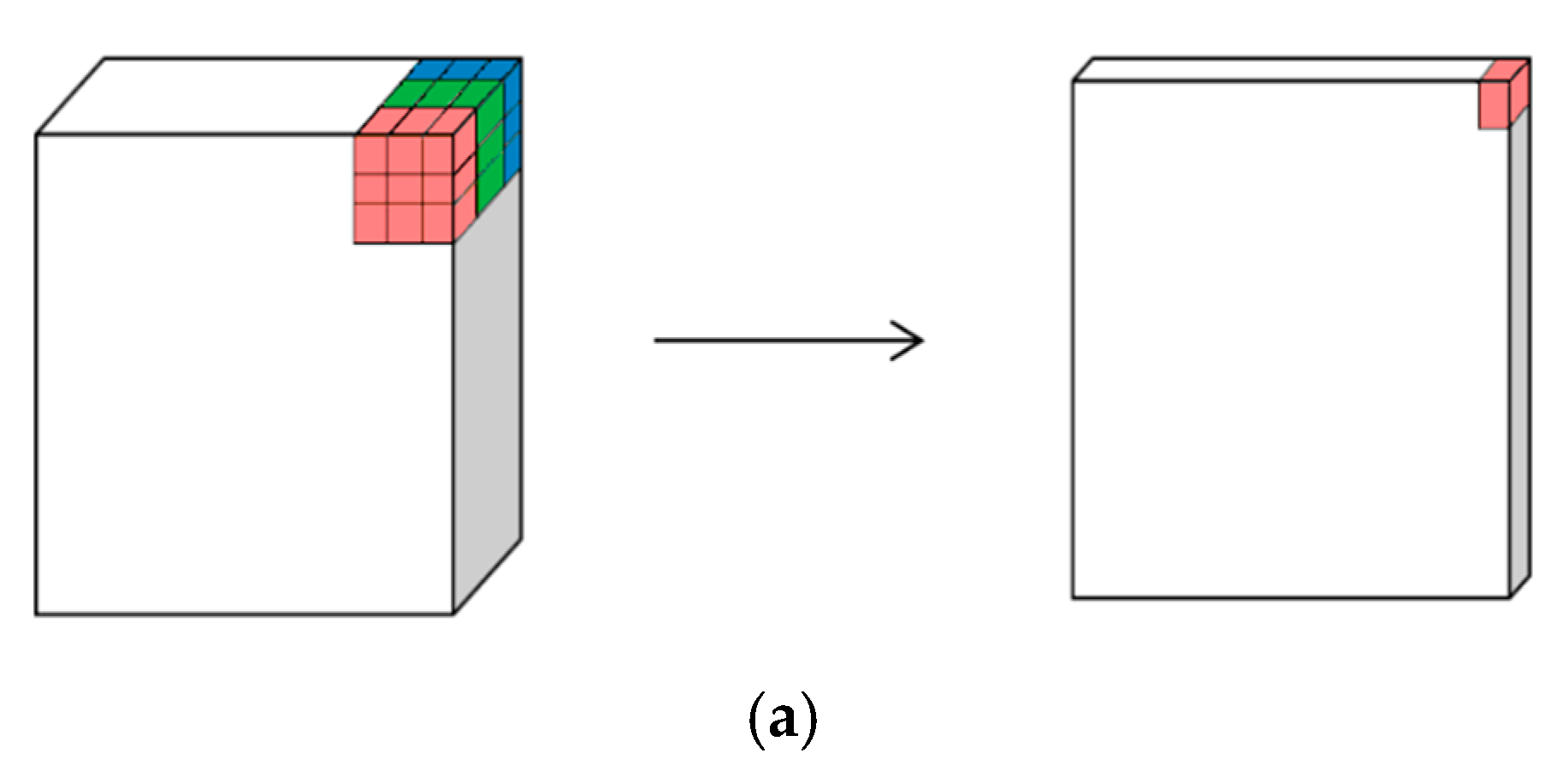
2.3. Generating Synthetic Gastroscopy Images
2.3.1. DCGAN
2.3.2. AutoAugment
2.4. Image Quality Measurement Method
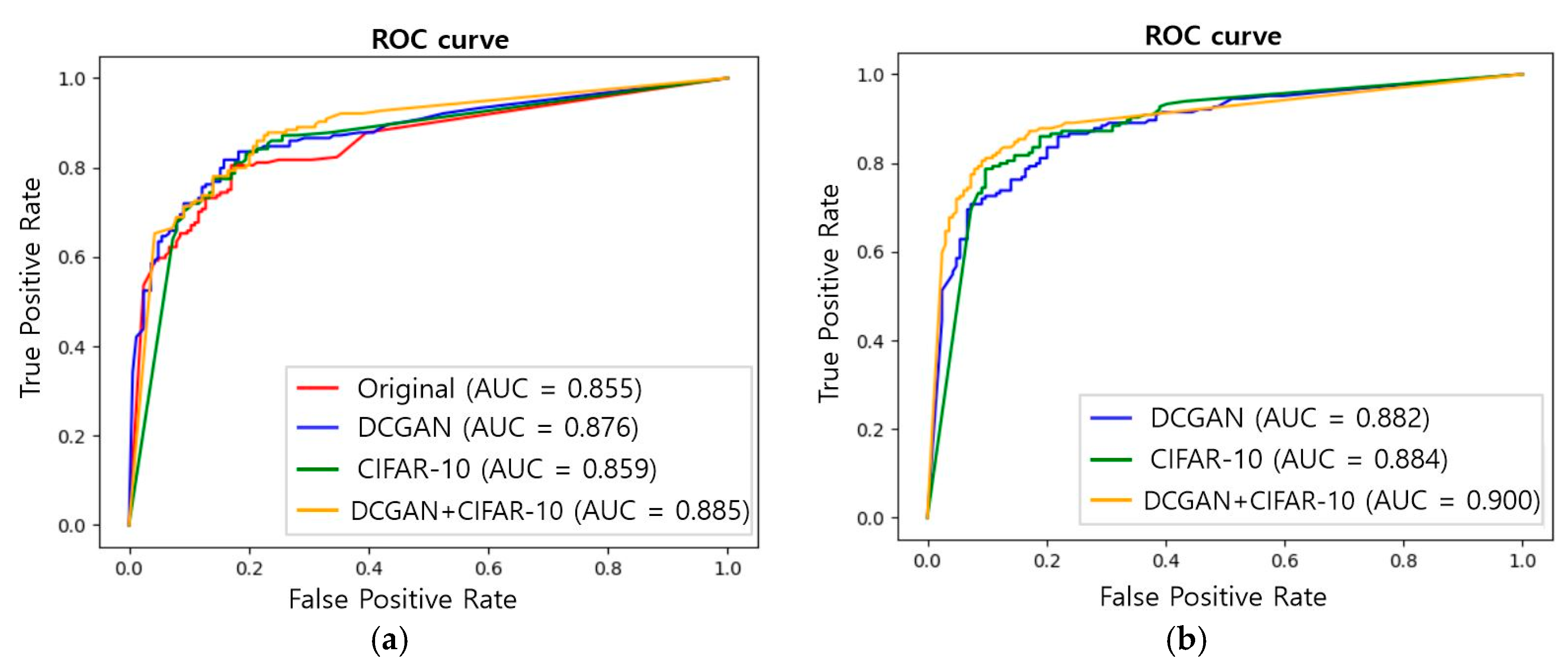
3. Results
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Ethical Approval
References
- Bray, F.; Ferlay, J.; Soerjomataram, I.; Siegel, R.L.; Torre, L.A.; Jemal, A. Global cancer statistics 2018: GLOBOCAN estimates of incidence and mortality worldwide for 36 cancers in 185 countries. CA Cancer J. Clin. 2008, 68, 394–424. [Google Scholar] [CrossRef] [PubMed]
- Lim, E.-K.; Kim, K.-H.; Kim, K.-B. Endoscopic image analysis system for early gastric cancer. In Proceedings of the Korean Intelligent Systems Society, Seoul, Korea, 29 April–30 April 2005; Volume 15, pp. 255–260. [Google Scholar]
- Rolnick, D.; Veit, A.; Belongie, S.; Shavit, N. Deep learning is robust to massive label noise. arXiv 2017, arXiv:1705.10694. [Google Scholar]
- Frid-Adar, M.; Diamant, I.; Klang, E.; Amitai, M.; Goldberger, J.; Greenspan, H. GAN-based synthetic medical image augmentation for increased CNN performance in liver lesion classification. Neurocomputing 2018, 321, 321–331. [Google Scholar] [CrossRef]
- Zafar, K.; Gilani, S.O.; Waris, A.; Ahmed, A.; Jamil, M.; Khan, M.N.; Sohail Kashif, A. Skin Lesion Segmentation from Dermoscopic Images Using Convolutional Neural Network. Sensors 2020, 20, 1601. [Google Scholar] [CrossRef]
- Shin, H.-C.; Tenenholtz, N.A.; Rogers, J.K.; Schwarz, C.G.; Senjem, M.L.; Gunter, J.L.; Andriole, K.; Michalski, M. Medical image synthesis for data augmentation and anonymization using generative adversarial networks. In International Workshop on Simulation and Synthesis in Medical Imaging; Springer: Granada, Spain, 2018; pp. 1–11. [Google Scholar]
- Dai, W.; Dong, N.; Wang, Z.; Liang, X.; Zhang, H.; Xing, E.P. Scan: Structure correcting adversarial network for organ segmentation in chest x-Rays. In Deep Learning in Medical Image Analysis and Multimodal Learning for Clinical Decision Support; Springer: Berlin/Heidelberg, Germany, 2018; pp. 263–273. [Google Scholar]
- Zhao, D.; Zhu, D.; Lu, J.; Luo, Y.; Zhang, G. Synthetic medical images using F&BGAN for improved lung nodules classification by multi-scale VGG16. Symmetry 2018, 10, 519. [Google Scholar]
- Gomes Ataide, E.J.; Ponugoti, N.; Illanes, A.; Schenke, S.; Kreissl, M.; Friebe, M. Thyroid Nodule Classification for Physician Decision Support Using Machine Learning-Evaluated Geometric and Morphological Features. Sensors 2020, 20, 6110. [Google Scholar] [CrossRef] [PubMed]
- Lyu, J.; Bi, X.; Ling, S.H. Multi-Level Cross Residual Network for Lung Nodule Classification. Sensors 2020, 20, 2837. [Google Scholar] [CrossRef] [PubMed]
- Asperti, A.; Mastronardo, C. The effectiveness of data augmentation for detection of gastrointestinal diseases from endoscopical images. arXiv 2017, arXiv:1712.03689. [Google Scholar]
- Togo, R.; Ogawa, T.; Haseyama, M. Synthetic gastritis image generation via loss function-based conditional pggan. IEEE Access 2019, 7, 87448–87457. [Google Scholar] [CrossRef]
- Nguyen, D.T.; Lee, M.B.; Pham, T.D.; Batchuluun, G.; Arsalan, M.; Park, K.R. Enhanced Image-Based Endoscopic Pathological Site Classification Using an Ensemble of Deep Learning Models. Sensors 2020, 20, 5982. [Google Scholar] [CrossRef] [PubMed]
- Chollet, F. Xception: Deep learning with depthwise separable convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21 July–26 July 2017; pp. 1251–1258. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. Adv. Neural Inf. Process. Syst. 2014, 27, 2672–2680. [Google Scholar]
- Radford, A.; Metz, L.; Chintala, S. Unsupervised representation learning with deep convolutional generative adversarial networks. arXiv 2015, arXiv:1511.06434. [Google Scholar]
- Cubuk, E.D.; Zoph, B.; Mane, D.; Vasudevan, V.; Le, Q.V. Autoaugment: Learning augmentation policies from data. arXiv 2018, arXiv:1805.09501. [Google Scholar]
- Barratt, S.; Sharma, R. A note on the inception score. arXiv 2018, arXiv:1801.01973. [Google Scholar]
- Shmelkov, K.; Schmid, C.; Alahari, K. How good is my GAN? In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 213–229. [Google Scholar]
- Shin, S.-A.; Kim, D.-H.; Cho, H.-C. Deep Learning Based Gastric Lesion Classification System Using Data Augmentation. Trans. Korean Inst. Electr. Eng. 2020, 69, 1033–1039. [Google Scholar]
- Yun, J.P.; Shin, W.C.; Koo, G.; Kim, M.S.; Lee, C.; Lee, S.J. Automated defect inspection system for metal surfaces based on deep learning and data augmentation. J. Manuf. Syst. 2020, 55, 317–324. [Google Scholar] [CrossRef]
- Kusrini, K.; Suputa, S.; Setyanto, A.; Agastya, I.M.A.; Priantoro, H.; Chandramouli, K.; Izquierdo, E. Data augmentation for automated pest classification in Mango farms. Comput. Electron. Agric. 2020, 179, 105842. [Google Scholar] [CrossRef]
- Wang, J.; Wu, Z.; Li, F.; Zhang, J. A Data Augmentation Approach to Distracted Driving Detection. Future Internet 2021, 13, 1. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Normal | Abnormal | ||
|---|---|---|---|
| Training dataset | Original | 655 | 655 |
| Synthetic | 11,944 | 11,944 | |
| Test dataset | 164 | 164 | |
| Total | 12,763 | 12,763 | |
| Accuracy | Precision | Recall | F1 Score | |
|---|---|---|---|---|
| Original | 0.796 | 0.839 | 0.732 | 0.782 |
| DCGAN | 0.811 (0.814) | 0.823 (0.825) | 0.793 (0.774) | 0.807 (0.804) |
| CIFAR-10 | 0.832 (0.805) | 0.819 (0.825) | 0.854 (0.774) | 0.836 (0.799) |
| DCGAN+CIFAR-10 | 0.851 (0.820) | 0.896 (0.800) | 0.793 (0.854) | 0.841 (0.826) |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kim, Y.-j.; Cho, H.C.; Cho, H.-c. Deep Learning-Based Computer-Aided Diagnosis System for Gastroscopy Image Classification Using Synthetic Data. Appl. Sci. 2021, 11, 760. https://doi.org/10.3390/app11020760
Kim Y-j, Cho HC, Cho H-c. Deep Learning-Based Computer-Aided Diagnosis System for Gastroscopy Image Classification Using Synthetic Data. Applied Sciences. 2021; 11(2):760. https://doi.org/10.3390/app11020760
Chicago/Turabian StyleKim, Yun-ji, Hyun Chin Cho, and Hyun-chong Cho. 2021. "Deep Learning-Based Computer-Aided Diagnosis System for Gastroscopy Image Classification Using Synthetic Data" Applied Sciences 11, no. 2: 760. https://doi.org/10.3390/app11020760
APA StyleKim, Y.-j., Cho, H. C., & Cho, H.-c. (2021). Deep Learning-Based Computer-Aided Diagnosis System for Gastroscopy Image Classification Using Synthetic Data. Applied Sciences, 11(2), 760. https://doi.org/10.3390/app11020760