1. Introduction
Recently, neural networks have shown great success in a wide range of tasks, such as achieving superhuman performance in the game of Go [
1] and Atari games [
2,
3], photo-realistic image synthesis [
4], and many natural language processing applications [
5,
6,
7,
8,
9]. One of the key factors behind these achievements is the huge amount of trainable parameters in the model. For instance, the PG-GAN model [
10], which is capable of generating high resolution, photo-realistic faces, has about 46 M parameters. Another example is BERT [
6], which is a model with around 340 M trainable parameters. At the time of its release, it achieved state-of-the-art performance in eleven natural language processing tasks.
Since the size of deep neural network models keeps getting larger, it is natural to suspect that not all of the parameters might be necessary to show that level of performance. Indeed, research has shown that features and parameters of a neural network tend to have redundancy [
11,
12,
13]. By analyzing the cause of these redundancies, methods that encourage the model to better utilize its full capacity can be developed. Dropout [
14] is one of the most successful and widely used examples, where the coadaptation of neurons was suggested as the cause of redundancy.
In this paper, we provide a theoretical and empirical analysis on a type of network redundancy, which we call the redundancy in the rank of parameters. It is based on a linear algebraic interpretation of parameter matrices, which suggests that the rank of it can be lower than the upper bound. Based on this hypothesis, we propose a novel regularization method that can not only improve the training dynamics of a neural network but also reduce the size of it. This regularization-by-pruning approach consists of a loss function that aims at making the parameter rank deficient, and a dynamic low-rank approximation method that gradually shrinks the size of this parameter by closing the gap between the actual rank and its upper bound.
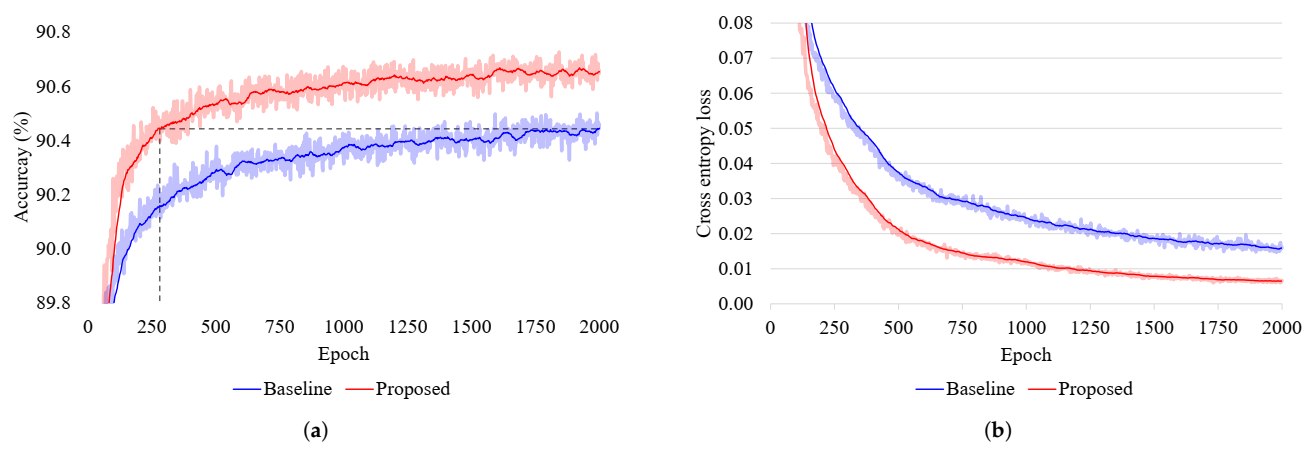
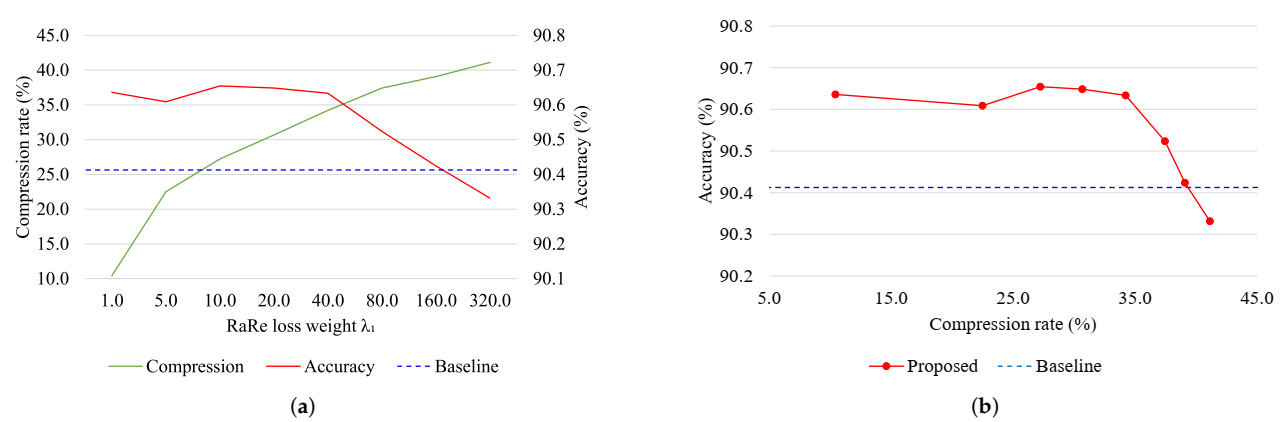
Empirically evaluating this method on an image classification task, we observe that the proposed method leads to a statistically significant accuracy gain of 0.21% and reduces the required number of gradient updates to train the model by a factor of 7. Furthermore, this approach provides the side benefit of reducing 30.65% of the free parameters in the model. Given that these improvements are built on top of other regularization methods such as Dropout, this approach is orthogonal to many other regularization studies and could be used in conjunction with them.
The contributions of this paper can be summarized as follows: (i) We provide theoretical background and analysis regarding this novel type of redundancy, found in the rank of neural network parameters. (ii) We propose a loss function that localizes and identifies redundant parts of a network, in a way that the parameters become rank deficient. (iii) We propose a dynamic low-rank approximation method that lowers the upper bound of the rank of a parameter, by gradually reducing its size. (iv) We provide empirical results that verify our theoretical analysis and claims.
2. Related Work
Many studies have shown that deep neural networks have a lot of redundancy in their parameterization and proposed ways to make better use of the redundant parameters. In the work of Ayinde et al. [
15], a measure was proposed to quantify network redundancy, and various architectural choices in designing neural networks were tested using this measure. It is shown that not only the depth and width of the network but also the choice of activation function and initialization method can affect redundancy. Dropout [
14] is a widely used regularization method that reduces redundancy by discouraging coadaptation of neurons. Cogswell et al. [
16] suggested that the covariance between the activations of a layer is the result of redundancy and designed a loss function that penalizes this. Their method has shown to be effective at reducing overfitting. In Minimum Hyperspherical Energy (MHE) regularization [
17], a method that promotes angular diversity of neurons was proposed and was shown to be a strong regularization method. Our method largely falls into this line of work, where the goal is to regularize the network by minimizing redundancy. Unlike the other methods, however, the proposed method has the benefit of reducing the number of trainable parameters.
Low-rank approximation aims to speed up and/or decrease storage footprint of a neural network by representing a parameter tensor with a multiplication of two or more smaller tensors. The work of Sainath et al. [
18] was one of the first works to investigate the effectiveness of low-rank matrix factorization in deep neural networks. They used low-rank factorization to compress the final layer of deep neural networks and showed that training speed can be greatly improved with the cost of no or marginal performance lost. In the works of Howard et al. [
19] and Kim et al. [
20], factorization methods were applied to popular image recognition models to reduce the storage and computation cost, so that they can be ported to mobile devices. GroupReduce [
21] is a block-wise low-rank approximation method that utilizes statistical property of word embedding and softmax layers. Since most of the trainable parameters resides in these two matrices, their method has shown great success in compressing large neural language models. In [
22], low-rank approximation is utilized to predict the sparsity of the activation in feed-forward neural networks and perform conditional computation to speed up the calculation. The works in [
23,
24] focused on automatically finding the optimal rank while compressing the kernel of convolutional neural networks via decomposition. DeepTwist [
25] proposes to inject noise that simulates weight decomposition during training to mitigate the performance drop caused by the actual decomposition in CNNs. Our work also takes the form of low-rank approximation but with two distinctive properties. First, it does not operate on a trained network and instead can be used during the initial task-specific training. Second, the rank of the factorized matrices does not need to be specified in our approach and is automatically discovered in the process of parameter optimization.
Network pruning is an active research area where the goal is to identify and remove redundant parts of a model. The key to a successful pruning algorithm is an effective method to localize and/or identify the redundant parts of a model. Early works in this literature and some extensions used the Hessian of the loss to determine and remove redundant parts of a neural network [
26,
27,
28]. In [
29] applies L2 regularization on the parameters during training and prunes connections with magnitudes below a certain threshold to acquire a sparsified network. This network is then retrained to recover the performance loss. In [
11] combines this approach with quantization and Huffman coding to greatly reduce the storage requirement of image recognition models without loss of accuracy. In [
30] further extends this work by allowing the threshold parameter to be differentiable so that it can be learned via backpropagation. CLIP-Q [
31] performs magnitude-based pruning and quantization in parallel to minimize the side effects of the latter. In [
32] also explores magnitude-based pruning but includes a wider range of models and tasks such as LSTMs, language modeling, and neural machine translation. ThiNet [
33] greedily removes convolutional filters that has the least contribution to the output of each layer. Some approaches targeted characteristics with more practical implications, such as FLOPs, required for an inference step instead of the number of trainable parameters as the pruning criteria [
34,
35]. However, pruning processes tend to act adversarially against the model’s performance and require a fine-tuning step to recover the loss [
36]. On the other hand, our method works as a regularizer which leads to better accuracy without the requirement of postpruning fine-tuning step.
3. Redundancy in the Rank of Parameters
A neural network layer can be seen as a mapping from one (input) feature space to another (output) feature space. This can be accomplished by combining several transformations. The most typical setting is to map the input feature space to an intermediate space via an affine or linear transformation and map this space to the output feature space with a nonlinearity. This not only applies to fully-connected networks and LSTMs but also to CNNs since in practice convolution operation is reduced to a batch matrix multiplication for efficiency [
37]. We will later discuss how this setting can be extended to other neural architectures.
Let
and
be some elements in the input and output feature space of a fully-connected layer, respectively, and
and
be the trainable parameters of it. Then, the mapping from
to
using this layer is computed by
where
is an element-wise nonlinearity such as the rectifier or sigmoid. Here,
in (
1) can be interpreted as the coordinates of a point in the Cartesian coordinate system, given
as the affine coordinates over the affine frame with origin
and basis
(assuming
has full rank). Thus, the intermediate feature space is a linear subspace of
where its dimension is the rank of
(i.e., the column space of
).
The key idea is that if
is rank-deficient, the same mapping can be represented with a smaller
, where
denotes the maximal linearly independent subset of matrix
. However, for fully-connected layers in modern neural architectures,
n and
m are often in the order of hundreds or thousands [
7,
38]. In such a high dimension, a set of vectors is almost always linearly independent, especially when they are randomly initialized and optimized towards a certain objective. We argue that even in such a case,
can be
almost linearly dependent, where some vectors in
can be defined as a linear combination of the other vectors with a small error.
More formally, let
be a vector that satisfies
where
denotes the zero vector.
is said to be linearly dependent if such
exists. We propose to introduce a slack variable
such that
Then, we can find the maximal linearly pseudoindependent subset of a matrix under the condition given by (
4). We denote this subset by
. The amount of difference that occurs when representing the column space of
using
can be controlled by introducing a condition on the slack variable
, such as
. If the rank of
is smaller than
, which is the upper bound of the rank of
, we can get a lossy mapping from the input feature space to the output feature space with less free parameters. In such case, it can be said that there is redundancy in the rank of
. This implies that there are always at least
linearly dependent vectors along the longer axis, and a square matrix is likely to have the least redundancy in its rank.
When is represented with , its outputs will lie in a lower-dimensional subspace of the original space, spanned by . However, the dimensionality of the feature space (i.e., outputs of ) can be higher than this subspace due to the nonlinear activation function . This suggests that the null space of still could grant some expressive power to this layer.
To close the gap between the upper bound of a parameter and its rank, one can lower the upper bound by shrinking the size of this parameter. By doing so, the same function of this neural network can be approximated with fewer trainable parameters, which leads to a more compact parameter search space.
Another important aspect of the aforementioned interpretation, based on affine frame, is that the input feature space’s entanglement is related to the orthogonality of the basis. Feature space correlation occurs when some change along one basis vector has an effect in the direction of other basis vectors. More formally, let be two basis vectors, and be their coordinates. Then, the change along the direction of introduced by is given by —the orthogonal projection of onto a straight line parallel to . Based on this observation, the feature space could be decorrelated by orthogonalizing the basis, but we leave this to a future work.
4. Proposed Method
In this section, we propose a novel method to manipulate the affine frame, based on the theoretical analysis in the previous section. Reducing the size of a neural network parameter based on its rank requires two steps. First, the parameter needs to be made rank deficient, while identifying the linearly dependent vectors in it. Second, we need to find a factorization of this parameter that approximates the original function, by fusing the linearly dependent vectors together.
4.1. Making a Matrix Rank Deficient
We need to find
that satisfies (
4), which in turn identifies vectors that can be represented with a linear combination of the other vectors. However, (
4) has infinitely many solutions since for any
that satisfies (
4),
where
also satisfies it. Furthermore, without explicit control on the interdependence between vectors of
, there is no mean to impose any bounds in
. To alleviate this issue, we propose a novel objective function that encourages a matrix to be rank deficient.
A matrix is rank deficient when there are linearly dependent vectors, and the most simple form of linear dependence is . This means that and are parallel or opposite to each other. Therefore, an objective function that encourages vectors to be this way can make the matrix rank deficient. Among the family of trigonometric functions, the value of sine function gets closer to zero when the angle between two vectors approach either or . Based on this fact, we build our objective function upon the pairwise squared sine values of a matrix.
Another important factor to consider is the task-specific training objective of the network. When the neural network is optimized for a task, the process can be seen as finding the set of basis vectors of the affine frame that would lead to a desirable feature space transformation. However, minimizing the pairwise squared sine values of a matrix could push these basis vectors to other directions, which in turn can act adversarially against the model’s primary training objective. Our preliminary experiments also supports this hypothesis, where naively minimizing the pairwise squared sine value led to unstable training and inferior performance.
To avoid this side-effect, we design the objective function so that it first chooses a pair of vectors that is the closest to being parallel or opposite, and pushes it further towards this direction. More formally, for a matrix
, we propose RaRe (Rank Reducing) loss which is defined as follows:
where
denotes the
ith column of
. Since this loss function affects only a single pair of vectors, it can only reduce the rank of a matrix by 1. This, however, is not a problem since this pair will be merged into a single vector using the method described in the following subsection. An alternative formulation which reduces the squared sine value of
k pairs instead of one is possible but performed worse than the proposed form in our preliminary experiments.
4.2. Dynamic Low-Rank Approximation
When a pair of linearly dependent vectors in a matrix is identified, the size of this matrix can be reduced by removing one of the vectors and representing it using the other one. Given the network layer described by (
1) and the columns
as the linearly dependent pair in
, we can create an equivalent function as follows:
This can be easily proved by setting
. Since the transformation from
to
can be implemented with a matrix multiplication, the problem becomes finding the matrices
,
for the original matrix
, such that
where
. This can be accomplished by initializing
with an identity matrix, and setting the
jth row as the weighted sum of the
ith and
jth row as follows:
Then, (
10) can be rewritten as:
The reduction process in (
8), (
9), (
11), and (
12) can be repeatedly applied whenever a linearly dependent pair of columns is identified.
Similarly, it is possible to fuse pairs of linearly dependent rows. Once linearly dependent rows has been identified after minimizing
, these rows can be fused by introducing a matrix
that satisfies
where
. The process of finding
and
is almost identical to (
9) and (
11), except the column operations become row operations and vice versa. When reducing both rows and columns, the vector fusing process along one axis can alter the pairwise angular distances along the other axis. The
r and
s terms in (
9) and (
11) are introduced to prevent this issue.
When fusing two vectors with this method, one must choose the vector that is merged to the other one. Since s is always greater than 1, the remaining vector’s magnitude increases. If we choose to keep the vector with greater magnitude, it is more likely to be kept after successive merges and become extremely large. This led to unstable training, so we choose to keep the shorter vector. Even with this precaution, the average magnitude of the vectors tends to increase after multiple merges. Therefore, we utilize L2 weight decay to counter this effect.
Another factor to consider when shrinking the weight parameter is the choice of axis to reduce. Since the upper bound of a matrix’s rank is , the longer axis is likely to have more redundancy. This hypothesis was supported by preliminary experiments, and we design this method to reduce along the longer axis only, keeping its shape close to a square.
Theoretically, this is not an approximation method, since it produces an equivalent function given that the merged pair of vectors are parallel or opposite to each other. However, in practice we find it neither necessary nor efficient to impose such a strict condition. Thus, we approximate the original function by allowing a slight angle between the two vectors. More formally, we fuse
and
if
. However, even with a very strict value of
, large error could be introduced since large difference in a single dimension would be amortized when calculating the cosine distance in a very high dimensional space. Therefore, we propose to use the Euclidean distance between the two vectors when their magnitudes are equalized, which is calculated as follows:
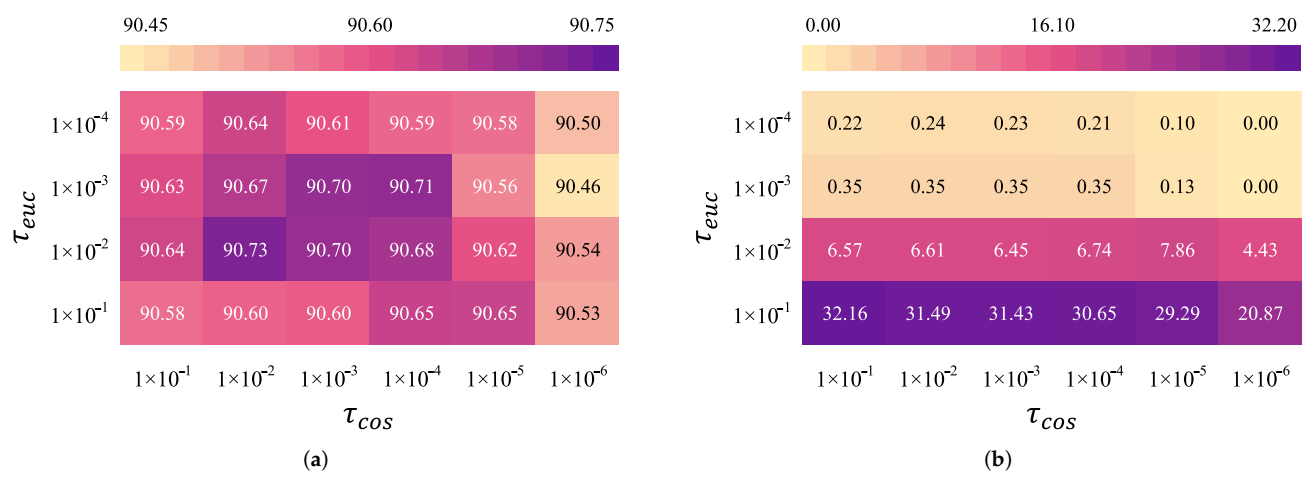
Then we fuse and if and . The value of and can be used to control how aggressively this method reduces the size of a matrix.
4.3. Feature Space Reduction
Even though the feature space could have higher dimensionality than the outputs’ lower-dimensional subspace spanned by
, the feature space can have redundancy in its dimensionality as well. This is due to the fact that many widely-used nonlinear activation functions such as the rectifier or the leaky rectifier are linear almost everywhere. For example, when the rectifier nonlinearity is used, two or more output coordinates in the feature space originated from a fused, single column of
have linear relationship when they are expected to have the same sign. By exploiting this fact, we reduce the feature space’s dimensionality by fusing these linear coordinates into one coordinate. Since this is not an approximation method, the feature space reduction is a lossless process. When the feature space is reduced, the drop rate of Dropout should be modified to compensate the change, and we linearly decay the rate
r as follows:
where
n is the current dimensionality of the feature space, and
are the initial values of
, respectively.
4.4. Comparison with Low-Rank Approximation
This method can be seen as a form of low-rank approximation. However, there are a few key improvements in this method. First, this process is
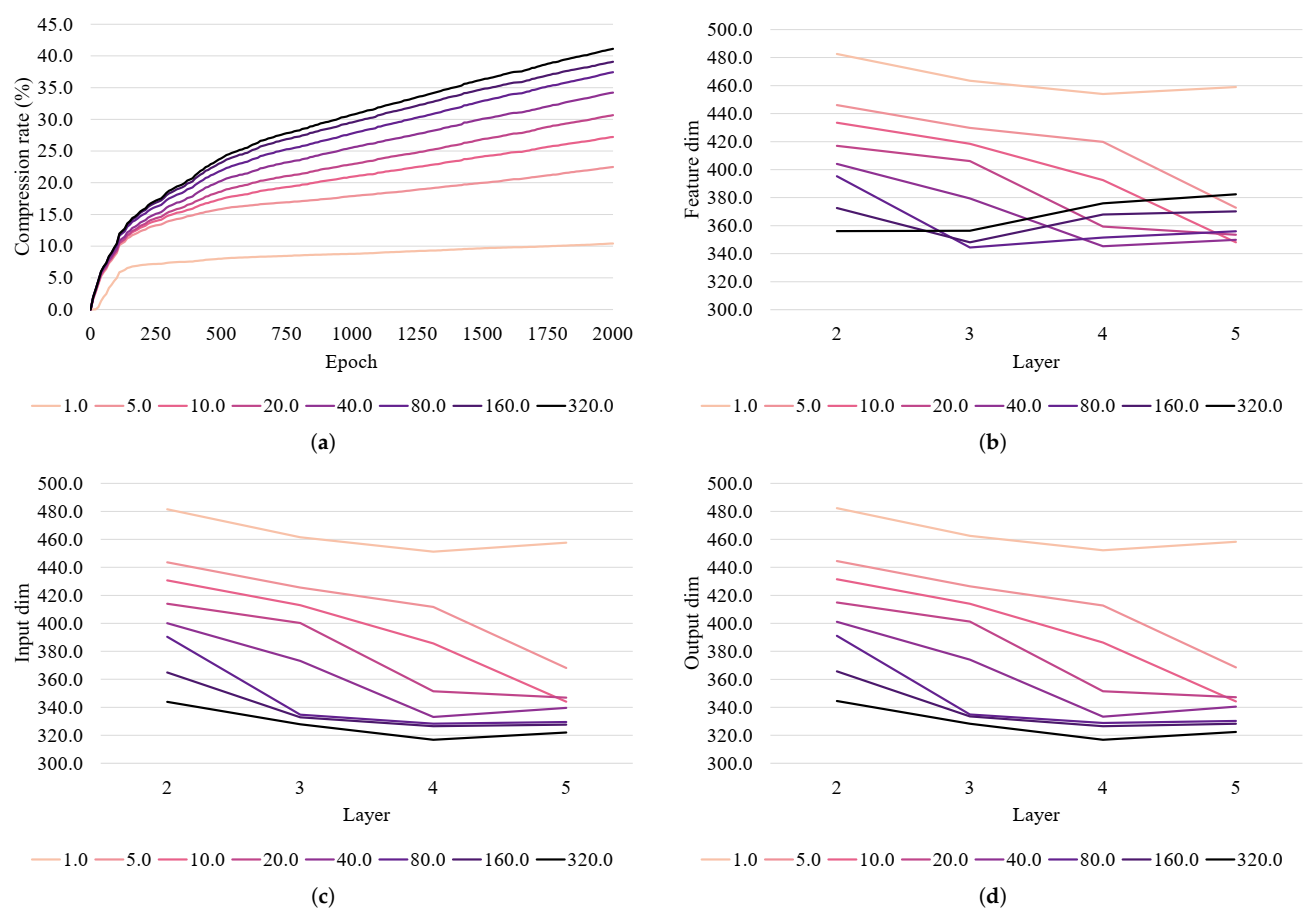
dynamic, in the sense that the desired rank of the matrix does not need to be predefined. As shown in the experiments section, this leads to different sizes in each layer, allowing the model to have more trainable parameters where needed and to remove parameters that do not affect performance. Similar observations has been made in the automatic structured pruning literature [
36,
39,
40]. Second, in the factorized form
, only
is trainable, while
and
are nontrainable, sparse matrices with only
m and
n nonzero elements, respectively. This always shrinks the size of the gradient-based parameter search space, which makes the optimization process more efficient and effective. On the contrary, in the case of factorizations where all factorized matrices are trainable, the number of free parameters increases unless
and
becomes small enough to satisfy
. Third, while most previous low-rank approximation methods focus on factorizing the parameter matrices after the task-specific training is finished, our method is most effective when its applied simultaneously with the training, since it is beneficial to the optimization process. Last but not least, the matrix reduction is a deterministic process that does not require an iterative method.
4.5. Input and Classification Layer
Unlike the hidden layers, the input and classification layers of a neural network serve special purposes and need to be treated differently. The input layer converts the input feature into a dense vector representation. If the size of an input dimension is reduced, part of the input feature is lost, which can lead to degeneration of the performance. In order to prevent this, we do not fuse any columns of the input layer’s parameter.
The classification layer refers to the layer that converts the output feature into logits, which is typically the last layer of a discriminative model. While hidden layers can be seen as functions that map one feature space to another, a classification layer evaluates how close the final output feature is to each class vector [
17,
41]. Therefore, when two class vectors (i.e., rows) of the classification layer’s parameter get fused, the model loses the ability to distinguish these two classes. Hence, we do not merge any rows in the parameter of the classification layer.
4.6. Frobenius Normalization
Even though the proposed method is orthogonal and can be used with many normalization techniques such as Layer Normalization [
42] or Batch Normalization [
43], methods that alter the pairwise angular distances between rows or columns could lead to unwanted behavior. Weight Normalization [
44] is an example of this case, since the magnitude-decoupling process along one axis of a matrix would alter the pairwise angular distances along the other axis. To alleviate this problem, we propose to use another form of reparameterization called Frobenius Normalization. As its name suggests, the Frobenius norm of a matrix is decoupled via a single trainable scalar, as follows:
where
k is the initial Frobenius norm of
, and
g is the trainable scalar that controls the norm of
, relative to
k. Empirically, we find this normalization method to accelerate parameter reduction and stabilize training.
4.7. Training Process
Applying the proposed method to a neural network is simple and straightforward. The detailed training process is shown in Algorithm 1. Given a network with
N weight matrices
, each matrix should be replaced with the initial factorized form
, where
is initialized with the values of
, and
,
are initialized with an identity matrix. Then the total RaRe loss for this network is calculated as follows:
| Algorithm 1: Training a neural network with Dynamic Low-Rank Approximation. |
 |
The weighting term
is introduced to encourage more reduction in larger parameters. As mentioned in the earlier section, the L2 decay loss is calculated as follows:
These two loss functions are optimized in conjunction with the task specific loss
:
After each parameter update, the pair of vectors that satisfies (
13) is merged using the method described by (
8), (
9), (
11).
Here, we assume that
is optimized using a gradient-based method, which requires
to be differentiable w.r.t. the input of the neural network in use. However, this requirement puts minimal restrictions on the type of neural network that can be used, since the use of differentiable neural architecture and loss function (e.g., cross-entropy loss) is the de facto standard in current practice. This setting also mitigates the convergence issue that the nonconvexity of
might carry. It has been suggested that gradient descent is reasonably effective at optimizing nonconvex functions [
45,
46], and in some cases the benefits of using nonconvex functions outweigh the absence of convergence guarantee [
47]. The empirical results of this study also suggest that
, despite its nonconvexity, improves the stability of the training process (
Section 5.2).
4.8. Extending to Other Neural Architectures
So far, we have elaborated our claim and analysis based on the fully-connected network architecture, centered on the parameter matrix. However, the proposed method is independent from most architectural choices such as activation function, batch normalization, and layer normalization. This makes it straightforward to apply this method to architectures that build upon parameter matrices, such as Transformer [
7] or Long-Short Term Memory (LSTM) [
48].
For other architectures, the concept of rows and columns in the parameter matrix can be generalized using the affine frame interpretation. A column can be seen as the set of elements in a parameter that share the same affine coordinate, and a row is the set of elements that contribute to the same coordinate in the intermediate feature space (i.e., the output space of (
1)). In the case of Convolutional Neural Networks (CNN), the weight parameter (i.e., kernel) is typically a 4-dimensional tensor with shape
, where
are the kernel’s height, width, number of input channels, number of output channels, respectively. Here, a column has the shape of
and a row has the shape of
. Hence, it would be possible to extend this work to reduce the size of a convolution kernel, but we leave this to a future work.
6. Conclusions and Future Directions
In this paper, we have provided theoretical and empirical analysis about a novel type of redundancy that can exist in the rank of neural network parameters. Since the actual rank of a parameter can be lower than the upper bound imposed by its size, closing this gap can lead to better training dynamics and fewer trainable parameters. Based on this analysis, we proposed a regularization-by-pruning method that has the side benefit of reducing the size of parameters. This has two parts, where the first part is a loss functions that makes the parameter rank deficient, and the second part is a dynamic low-rank approximation method that reduces the size of this parameter. Empirical analysis of this method shows that it can surpass the baseline accuracy with 7.1 times less training steps and provides an average of 2.09% relative error reduction, on top of Dropout. Furthermore, the proposed model has 30.65% less trainable parameters.
As for future research directions, we plan to investigate deeper about the characteristics of the affine frame of neural networks. Extending the proposed method to other architectures such as CNN and analyzing the effectiveness would be an important step as well. In addition, investigating this method’s pruning effect and combining it with other pruning methods can lead to smaller models, which is essential for resource-limited environments such as mobile devices.







{kind=link}
{kind=link}
{kind=link}
{kind=link}