
Context-Aware Bidirectional Neural Model for Sindhi Named Entity Recognition


Abstract
:1. Introduction
- Our main contribution is the design of a neural model for Sindhi NER by taking into account relations between the entity pairs. The proposed CaBiLSTM model learns the token-level structure of sentences to capture the dependency of a whole sentence. We combine self-attention into the BiLSTM encoder to deeply capture semantic information and lexical features to boost the model’s performance. The CaBiLSTM model relies on the contextual representations that include task-specific NE-based knowledge.
- To alleviate the low-resource problem for training neural models, we train word-level and character-level SdGloVe and SdfastText representations on the unlabeled corpus. To highlight the significance of the proposed model, we compare the neural baseline models with the proposed CaBiLSTM model while exploiting pretrained SdGloVe, SdfastText, and task-specific character-level and word-level representations.
- We investigate the performance gap between classical (pretrained) and task-specific contextual word representations in RNN variants of long short-term memory (LSTM), BiLSTM, and BiLSTM-CRF to predict and classify NEs in the SiNER dataset. Furthermore, we analyze the influence of dropout on the recurrent dimensions to mitigate the overfitting problem and evaluate the context window size (CWS) for selecting optimal hyperparameters. We attain new state-of-the-art results and outperform existing systems on the publicly available SiNER dataset.
2. Related Work
2.1. Sindhi Named Entity Recognition
2.2. Neural NER Approaches
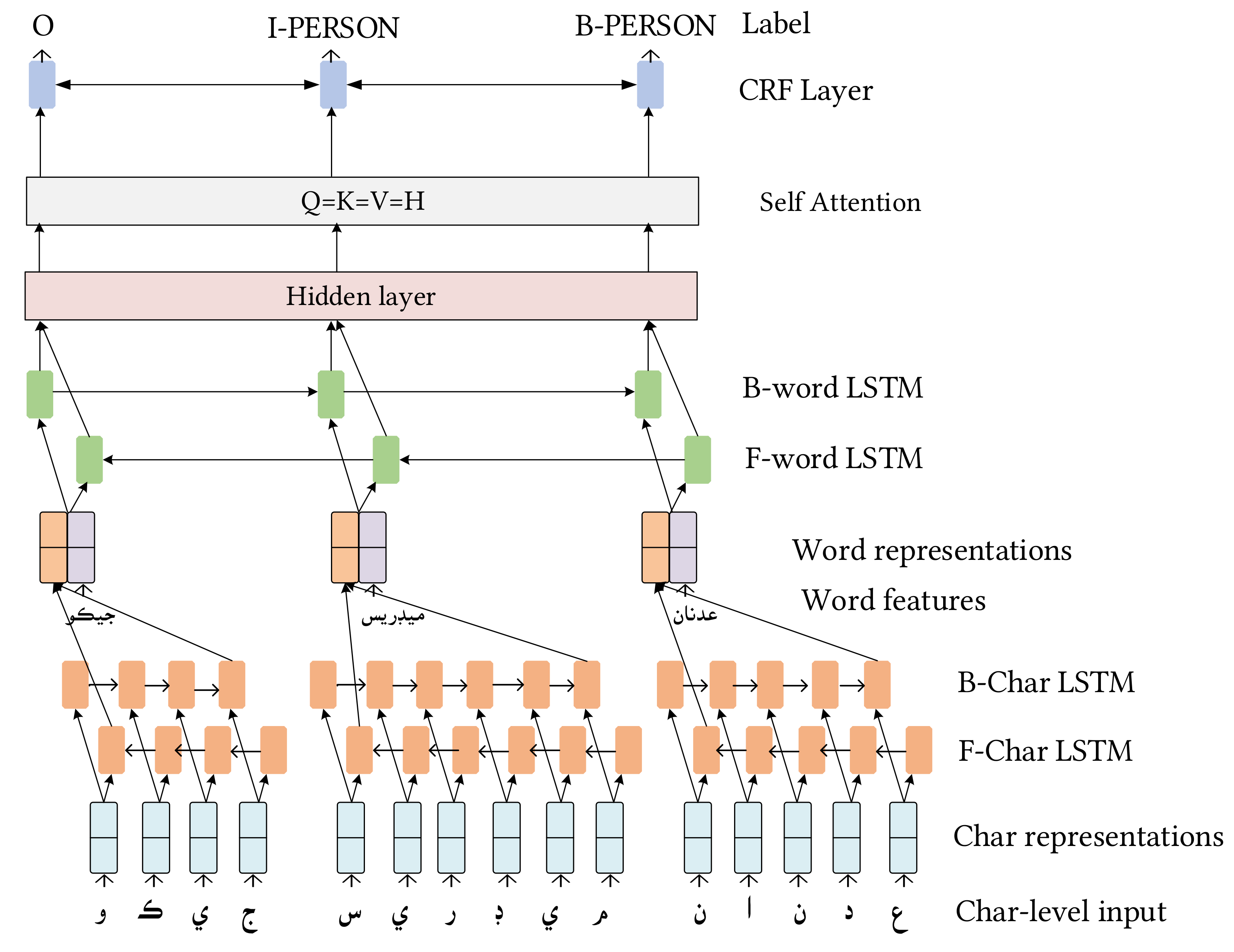
3. Methodology
3.1. Representation Learning
3.1.1. Uncontextualized Representation Learning
- GloVe: The well-known GloVe [25] model was developed at Stanford. The word representation can be derived by factorizing the log of the co-occurrence matrix by minimizing the cosine distance between words to ensure a high co-occurrence probability [42]. The resulting word representations show the linear substructure of the words in vector space.
- fastText: The fastText [26] model was open-sourced by Facebook. This sub-word model, based on the bag of n-gram characters, is dominant over the skip-gram model [43]. The vector representation is obtained by taking the sum of the vectors of the n-grams appearing in the word [28]. The underlying principle behind this method relies on the information encoding in sub-word representations [30].
3.1.2. Task-Specific Contextual Representation Learning
- Infrequent and OOV (unseen) words with low-quality representations can get extra information from character glyphs and morphemes.
- The character-based representations act as a highly generalized model of typical character-level patterns, allowing the word representations to act as a memory storing exceptions to these patterns.
3.2. Neural Baseline Models
- WLSTM: The unidirectional LSTM network [24] with forward hidden layers. The WSTM baseline model relies on word-level representation learning.
- WBiLSTM: The word-level BiLSTM network [24] with forward and backward . The combination of both and resulted in . The WBiLSTM baseline model is exploited using softmax, CRF, and self-attention on the pretrained SdGloVe, SdfastText, and task-oriented character-level and word-level representations.
- CBiLSTM: The character-level BiLSTM network [36] with forward and backward hidden LSTM layers, similar to WBiLSTM. The CBiLSTM baseline model is also exploited with softmax, CRF, and self-attention using SdGloVe, SdfastText, and task-oriented character-level and word-level representations.
3.3. The Proposed CaBiLSTM Model
3.4. Character-Level Bidirectional Encoder
3.5. Contextual Representation Layer
3.6. Bidirectional Network
3.7. Self-Attention Layer
3.8. Decoder
4. Experimental Setup
4.1. Dataset
4.2. Evaluation Metrics
4.3. Training Setup
4.3.1. Uncontextualized Representations
4.3.2. Training Neural Models
5. Results and Analysis
5.1. Baseline Results
5.2. Parameter Sensitivity
5.3. Final Results
5.4. Comparison with Existing Sindhi NER Systems
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Yadav, V.; Bethard, S. A survey on recent advances in named entity recognition from deep learning models. In Proceedings of the 27th International Conference on Computational Linguistics, Santa Fe, NM, USA, 20–26 August 2018; pp. 2145–2158. [Google Scholar]
- Jumani, A.K.; Memon, M.A.; Khoso, F.H.; Sanjrani, A.A.; Soomro, S. Named entity recognition system for Sindhi language. In Proceedings of the International Conference for Emerging Technologies in Computing, London, UK, 23–24 August 2018; Springer: Cham, Switzerland; pp. 237–246. [Google Scholar]
- Li, J.; Sun, A.; Han, J.; Li, C. A survey on deep learning for named entity recognition. IEEE Trans. Knowl. Data Eng. 2020. [Google Scholar] [CrossRef]
- Kanwal, S.; Malik, K.; Shahzad, K.; Aslam, F.; Nawaz, Z. Urdu named entity recognition: Corpus generation and deep learning applications. ACM Trans. Asian Low-Resour. Lang. Inf. Process. 2019, 19, 1–13. [Google Scholar] [CrossRef] [Green Version]
- Dias, M.; Boné, J.; Ferreira, J.C.; Ribeiro, R.; Maia, R. Named entity recognition for sensitive data discovery in Portuguese. Appl. Sci. 2020, 10, 2303. [Google Scholar] [CrossRef] [Green Version]
- Yamada, I.; Asai, A.; Shindo, H.; Takeda, H.; Matsumoto, Y. LUKE: Deep Contextualized Entity Representations with Entity-aware Self-attention. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), online, 16–20 November 2020; pp. 6442–6454. [Google Scholar]
- Tran, Q.H.; MacKinlay, A.; Yepes, A.J. Named entity recognition with stack residual LSTM and trainable bias decoding. In Proceedings of the Eighth International Joint Conference on Natural Language Processing, Taipei, Taiwan, 27 November–1 December 2017; pp. 566–575. [Google Scholar]
- Ma, X.; Hovy, E. End-to-end sequence labeling via bi-directional LSTM-CNNs-CRF. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics, Berlin, Germany, 7–12 August 2016; pp. 1064–1074. [Google Scholar]
- Lample, G.; Ballesteros, M.; Subramanian, S.; Kawakami, K.; Dyer, C. Neural architectures for named entity recognition. In Proceedings of the NAACL-HLT, San Diego, CA, USA, 12–17 June 2016; pp. 260–270. [Google Scholar]
- Dong, C.; Zhang, J.; Zong, C.; Hattori, M.; Di, H. Character-based LSTM-CRF with radical-level features for Chinese named entity recognition. In Natural Language Understanding and Intelligent Applications; Springer: Cham, Switzerland, 2 December 2016; pp. 239–250. [Google Scholar]
- Jia, Y.; Ma, X. Attention in character-Based BiLSTM-CRF for Chinese named entity recognition. In Proceedings of the 4th International Conference on Mathematics and Artificial Intelligence, Chegndu, China, 12–15 April 2019; pp. 1–4. [Google Scholar]
- Huang, C.; Chen, Y.; Liang, Q. Attention-based bidirectional long short-term memory networks for Chinese named entity recognition. In Proceedings of the 4th International Conference on Machine Learning Technologies, Nanchang, China, 21–23 June 2019; pp. 53–57. [Google Scholar]
- Misawa, S.; Taniguchi, M.; Miura, Y.; Ohkuma, T. Character-based bidirectional LSTM-CRF with words and characters for Japanese named entity recognition. In Proceedings of the First Workshop on Subword and Character Level Models in NLP, Copenhagen, Denmark, 7 September 2017; pp. 97–102. [Google Scholar]
- Mukund, S.; Srihari, R.; Peterson, E. An information-extraction system for Urdu—A resource-poor language. ACM Trans. Asian Lang. Inf. Process. 2010, 9, 1–43. [Google Scholar] [CrossRef] [Green Version]
- Li, F.; Wang, Z.; Hui, S.C.; Liao, L.; Song, D.; Xu, J. Effective Named Entity Recognition with Boundary-aware Bidirectional Neural Networks. In Proceedings of the Web Conference 2021, Ljubljana, Slovenia, 19–23 April 2021; pp. 1695–1703. [Google Scholar]
- Shah, D.N.; Bhadka, H. A survey on various approach used in named entity recognition for Indian languages. Int. J. Comput. Appl. 2017, 167, 11–18. [Google Scholar]
- Ali, W.; Kehar, A.; Shaikh, H. Towards Sindhi named entity recognition: Challenges and opportunities. In Proceedings of the 1st National Conference on Trends and Innovations in Information Technology, Nawabshah, Pakistan, 24–26 February 2016. [Google Scholar]
- Jamro, W.A. Sindhi language processing: A survey. In Proceedings of the International Conference on Innovations in Electrical Engineering and Computational Technologies (ICIEECT), Karachi, Pakistan, 5–7 April 2017; pp. 1–8. [Google Scholar]
- Motlani, R.; Tyers, F.; Sharma, D.M. A finite-state morphological analyser for Sindhi. In Proceedings of the Tenth International Conference on Language Resources and Evaluation (LREC’16), Portorož, Slovenia, 23–28 May 2016; pp. 2572–2577. [Google Scholar]
- Motlani, R. Developing language technology tools and resources for a resource-poor language: Sindhi. In Proceedings of the NAACL Student Research Workshop, San Diego, CA, USA, 12–17 June 2016; pp. 51–58. [Google Scholar]
- Ali, W.; Lu, J.; Xu, Z. SiNER: A large dataset for Sindhi named entity recognition. In Proceedings of the 12th Language Resources and Evaluation Conference, Marseille, France, 11–16 May 2020; pp. 2946–2954. [Google Scholar]
- Liu, M.; Zhang, Y.; Li, W.; Ji, D. Joint model of entity recognition and relation Extraction with Self-attention Mechanism. ACM Trans. Asian Low-Resour. Lang. Inf. Process. 2020, 19, 1–19. [Google Scholar] [CrossRef]
- Ronran, C.; Lee, S.; Jang, H.J. Delayed combination of feature embedding in bidirectional LSTM CRF for NER. Appl. Sci. 2020, 10, 7557. [Google Scholar] [CrossRef]
- Huang, Z.; Xu, W.; Yu, K. Bidirectional LSTM-CRF models for sequence tagging. arXiv 2015, arXiv:1508.01991. [Google Scholar]
- Pennington, J.; Socher, R.; Manning, C.D. Glove: Global vectors for word representation. In Proceedings of the Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; pp. 1532–1543. [Google Scholar]
- Bojanowski, P.; Grave, E.; Joulin, A.; Mikolov, T. Enriching word vectors with subword information. Trans. Assoc. Comput. Linguist. 2017, 5, 135–146. [Google Scholar] [CrossRef] [Green Version]
- Liu, Q.; Huang, H.Y.; Gao, Y.; Wei, X.; Tian, Y.; Liu, L. Task-oriented word embedding for text classification. In Proceedings of the 27th International Conference on Computational Linguistics COLING, Santa Fe, NM, USA, 20–26 August 2018; pp. 2023–2032. [Google Scholar]
- Grave, E.; Bojanowski, P.; Gupta, P.; Joulin, A.; Mikolov, T. Learning word vectors for 157 Languages. In Proceedings of the Language Resources and Evaluation Conference, Miyazaki, Japan, 7–12 May 2018. [Google Scholar]
- Liao, F.; Ma, L.; Pei, J.; Tan, L. Combined Self-Attention Mechanism for Chinese Named Entity Recognition in Military. Future Internet 2019, 11, 180. [Google Scholar] [CrossRef] [Green Version]
- Ali, W.; Kumar, J.; Lu, J.; Xu, Z. Word embedding based new corpus for low-resourced language: Sindhi. arXiv 2019, arXiv:1911.12579. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 5998–6008. [Google Scholar]
- Chiong, R.; Wei, W. Named entity recognition using hybrid machine learning approach. In Proceedings of the 2006 5th IEEE International Conference on Cognitive Informatics, Beijing, China, 17–19 July 2006; Volume 1, pp. 578–583. [Google Scholar]
- Hakro, M.A.; Lashari, I.A. Sindhi named entity recognition (SNER). Gov.-Annu. Res. J. Political Sci. 2017, 5, 143–154. [Google Scholar]
- Nawaz, D.; Awan, S.; Bhutto, Z.; Memon, M.; Hameed, M. Handling ambiguities in Sindhi named entity recognition (SNER). Sindh Univ. Res. J.-SURJ (Sci. Ser.) 2017, 49, 513–516. [Google Scholar] [CrossRef]
- Sang, E.T.K.; De Meulder, F. Introduction to the CoNLL-2003 shared task: Language-independent named entity recognition. In Proceedings of the Seventh Conference on Natural Language Learning at HLT-NAACL, Edmonton, AB, Canada, 31 May–1 June 2003; pp. 142–147. [Google Scholar]
- Kuru, O.; Can, O.A.; Yuret, D. Charner: Character-level named entity recognition. In Proceedings of the 26th International Conference on Computational Linguistics: Technical Papers, Osaka, Japan, 11–16 December 2016; pp. 911–921. [Google Scholar]
- Das, A.; Ganguly, D.; Garain, U. Named entity recognition with word embeddings and Wikipedia categories for a low-resource language. ACM Trans. Asian Low-Resour. Lang. Inf. Process. 2017, 16, 1–19. [Google Scholar] [CrossRef]
- Wang, X.; Jiang, Y.; Bach, N.; Wang, T.; Huang, Z.; Huang, F.; Tu, K. Improving Named Entity Recognition by External Context Retrieving and Cooperative Learning. arXiv 2021, arXiv:2105.03654. [Google Scholar]
- Dashtipour, K.; Gogate, M.; Adeel, A.; Algarafi, A.; Howard, N.; Hussain, A. Persian named entity recognition. In Proceedings of the 2017 IEEE 16th International Conference on Cognitive Informatics &Cognitive Computing (ICCI*CC), Oxford, UK, 26–28 July 2017; pp. 79–83. [Google Scholar]
- Luo, Y.; Xiao, F.; Zhao, H. Hierarchical contextualized representation for named entity recognition. In Proceedings of the AAAI Conference on Artificial Intelligence, The Tenth AAAI Symposium on Educational Advances in Artificial Intelligence, EAAI, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 8441–8448. [Google Scholar]
- Liu, L.; Shang, J.; Ren, X.; Xu, F.F.; Gui, H.; Peng, J.; Han, J. Empower sequence labeling with task-aware neural language model. In Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February2018; pp. 5253–5260. [Google Scholar]
- Yang, J.; Liu, Y.; Qian, M.; Guan, C.; Yuan, X. Information extraction from electronic medical records using multitask recurrent neural network with contextual word embedding. Appl. Sci. 2019, 9, 3658. [Google Scholar] [CrossRef] [Green Version]
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient estimation of word representations in vector space. arXiv 2013, arXiv:1301.3781. [Google Scholar]
- Zhang, M.; Yu, N.; Fu, G. A simple and effective neural model for joint word segmentation and POS tagging. IEEE/ACM Trans. Audio Speech Lang. Process. 2018, 26, 1528–1538. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Schuster, M.; Paliwal, K.K. Bidirectional recurrent neural networks. IEEE Trans. Signal Process. 1997, 45, 2673–2681. [Google Scholar] [CrossRef] [Green Version]
- Shen, T.; Zhou, T.; Long, G.; Jiang, J.; Zhang, C. Bi-directional block self-attention for fast and memory-efficient sequence modeling. In Proceedings of the International Conference on Representation Learning, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Shen, T.; Zhou, T.; Long, G.; Jiang, J.; Pan, S.; Zhang, C. DiSAN: Directional self-attention network for RNN/CNN-free language understanding. In Proceedings of the Association for the Advancement of Artificial Intelligence (AAAI), New Orleans, LA, USA, 2–7 February 2018; pp. 5446–5455. [Google Scholar]
- Zukov-Gregoric, A.; Bachrach, Y.; Minkovsky, P.; Coope, S.; Maksak, B. Neural named entity recognition using a self-attention mechanism. In Proceedings of the IEEE 29th International Conference on Tools with Artificial Intelligence (ICTAI), Boston, MA, USA, 6–8 November 2017; pp. 652–656. [Google Scholar]
- Lafferty, J.; McCallum, A.; Pereira, F.C. Conditional random fields: Probabilistic models for segmenting and labeling sequence data. In Proceedings of the Eighteenth International Conference on Machine Learning, San Francisco, CA, USA 28 June–1 July 2001; Volume 1, pp. 282–289. [Google Scholar]
- Sutton, C.; McCallum, A. An introduction to conditional random fields. Found. Trends® Mach. Learn. 2012, 4, 267–373. [Google Scholar] [CrossRef]
- Sang, E.F.; Veenstra, J. Representing text chunks. In Proceedings of the Ninth Conference on European Chapter of the Association for Computational Linguistics, Bergen, Norway, 8–12 June 1999; pp. 173–179. [Google Scholar]
- Viterbi, A. Error bounds for convolutional codes and an asymptotically optimum decoding algorithm. IEEE Trans. Inf. Theory 2006, 13, 260–269. [Google Scholar] [CrossRef] [Green Version]
- Abadi, M.; Barham, P.; Chen, J.; Chen, Z.; Davis, A.; Dean, J.; Devin, M.; Ghemawat, S.; Irving, G.; Isard, M.; et al. Tensorflow: A system for large-scale machine learning. In Proceedings of the 12th {USENIX} Symposium on Operating Systems Design and Implementation ({OSDI} 16), Savannah, GA, USA, 2–4 November 2016; pp. 265–283. [Google Scholar]
- Van Asch, V. Macro- and Micro-Averaged Evaluation Measures; CLiPS: Antwerpen, Belgium, 2013; Volume 49. [Google Scholar]
- Caruana, R.; Lawrence, S.; Giles, C. Overfitting in Neural Nets: Backpropagation, Conjugate Gradient, and Early Stopping. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, January 2000; Volume 13. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Gal, Y.; Ghahramani, Z. A theoretically grounded application of dropout in recurrent neural networks. In Proceedings of the Advances in Neural Information Processing Systems, Barcelona, Spain, 5–8 December 2016; pp. 1019–1027. [Google Scholar]
- Reimers, N.; Gurevych, I. Optimal hyperparameters for deep LSTM-networks for sequence labeling tasks. arXiv 2017, arXiv:1707.06799. [Google Scholar]
- Pascanu, R.; Mikolov, T.; Bengio, Y. On the difficulty of training recurrent neural networks. In Proceedings of the International Conference on Machine Learning, Atlanta, GA, USA, 16–21 June 2013; pp. 1310–1318. [Google Scholar]





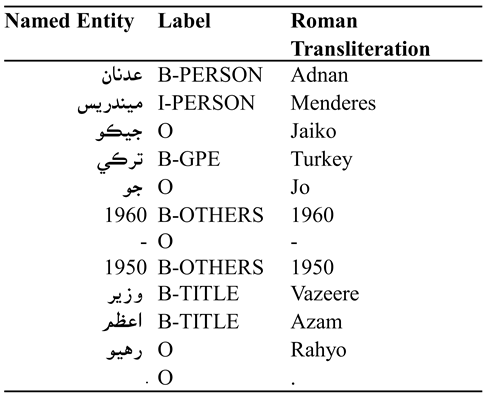
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Ambiguity | Description |
|---|---|
| Lack of capitalization | The capitalization rule in the English language is an important characteristic to enhance the performance of the NER system. However, there is no difference between NEs and plain text in Sindhi language. Thus, NER becomes challenging task. |
| Context sensitivity | 1. Due to change in the context, a token in a sentence that refers to an NE may change its type or may not remain an NE. Such as the name of a girl  (pronounced as Sindhu) is labeled as PERSON, whereas it also refers to the name of the river labeled as LOC (location) in the SiNER dataset. However, as a verb (pronounced as Sandhou), which means ’partition’, it does not belong to NE. (pronounced as Sindhu) is labeled as PERSON, whereas it also refers to the name of the river labeled as LOC (location) in the SiNER dataset. However, as a verb (pronounced as Sandhou), which means ’partition’, it does not belong to NE. |
2. Ambiguities in the person names are also common. An example of a person’s name (Wazeer-  ) is also tagged as the TITLE of a person because it also means minister. The name of a girl (Suhnhi- ) is also tagged as the TITLE of a person because it also means minister. The name of a girl (Suhnhi-  ) is also an adjective, which means beautiful. ) is also an adjective, which means beautiful. | |
3. The country name Syria (Shaam-  ) tagged as GPE (geopolitical entity) is also a name of person (Shaam- ) tagged as GPE (geopolitical entity) is also a name of person (Shaam-  ), and it also means evening. ), and it also means evening. | |
| Free word order | The sentence is normally written in subject-object-verb order, but all writers do not follow the same writing order. For example, the sentence “Wazeer drives a car" is translated as  (transliteration is Wazeer car halai tho), as well as (transliteration is Wazeer car halai tho), as well as  (transliteration is Car Wazeer halai tho). Such change in sentence order makes the identification of NEs more difficult. (transliteration is Car Wazeer halai tho). Such change in sentence order makes the identification of NEs more difficult. |
| Agglutinative and inflectional morphology | An NE may either change its type or even may not remain a name when connected with other words, which makes Sindhi NER a challenging task. For example, a person’s name (  -Mukhtiyar) does not remain an NE when combined with ‘khud’ forms ( -Mukhtiyar) does not remain an NE when combined with ‘khud’ forms (  khud-mukhtiyar), which means ‘autonomous’. khud-mukhtiyar), which means ‘autonomous’. |
| NE Type | Label | Train Set | Valid Set | Test Set |
|---|---|---|---|---|
| Person names | PERSON | 21,515 | 10,540 | 3478 |
| Title of a person | TITLE | 5122 | 4703 | 2009 |
| Organizations | ORG | 1943 | 1934 | 741 |
| Geopolitical Entities | GPE | 9652 | 4814 | 3041 |
| Locations | LOC | 4628 | 1085 | 360 |
| Nationalities | NORP | 4678 | 4210 | 2950 |
| Names of Buildings | FAC | 568 | 586 | 130 |
| Events, incidents | EVENT | 885 | 399 | 575 |
| Languages | LANGUAGE | 972 | 174 | 52 |
| Art work, title of books and songs | ART | 1172 | 276 | 67 |
| Miscellaneous | OTHERS | 16,297 | 6681 | 4601 |
| Model | Hyperparameter | Range |
|---|---|---|
| Representation learning | Epochs † | 100 |
| Learning rate † | 0.025 | |
| CWS† | 7 | |
| Pretrained word representations †d | 300 | |
| Task-specific word representations d | 300 | |
| CRL representations d | 300 | |
| Char representations †d | 64 | |
| minn Char count ‡ | 3 | |
| maxn Char count ‡ | 10 | |
| NS ‡ | 20 | |
| minw ‡ | 3 | |
| Neural models | Learning rate | 0.02 |
| Decay rate | 0.05 | |
| Gradient normalization | 0.82% | |
| h layers | 200 | |
| Dropout | 0.25 | |
| Batch size | 32 | |
| Epochs | 40 |
| Representation | Model | Variants | Precision% | Recall% | F1-Score% |
|---|---|---|---|---|---|
| SdGloVe | WLSTM | softmax | 84.41 | 84.85 | 84.73 |
| WBiLSTM | softmax | 86.33 | 85.76 | 85.92 | |
| CBiLSTM | softmax | 86.74 | 85.9 | 86.15 | |
| WBiLSTM | CRF | 87.19 | 86.39 | 86.79 | |
| CBiLSTM | CRF | 87.64 | 86.71 | 86.83 | |
| WBiLSTM | Attention, CRF | 86.59 | 87.46 | 87.32 | |
| CBiLSTM | Attention, CRF | 87.93 | 87.41 | 87.61 | |
| SdfastText | WLSTM | softmax | 85.23 | 85.94 | 85.24 |
| WBiLSTM | softmax | 87.62 | 86.34 | 86.58 | |
| CBiLSTM | softmax | 87.84 | 86.55 | 87.16 | |
| WBiLSTM | CRF | 87.69 | 87.8 | 87.63 | |
| CBiLSTM | CRF | 88.36 | 88.72 | 88.24 | |
| WBiLSTM | Attention, CRF | 88.89 | 88.53 | 88.79 | |
| CBiLSTM | Attention, CRF | 89.45 | 89.42 | 89.27 | |
| Task-specific | WLSTM | softmax | 86.48 | 86.63 | 85.82 |
| WBiLSTM | softmax | 87.61 | 86.28 | 86.9 | |
| CBiLSTM | softmax | 88.35 | 87.59 | 87.26 | |
| WBiLSTM | CRF | 88.62 | 88.91 | 88.58 | |
| CBiLSTM | CRF | 89.34 | 89.38 | 89.21 | |
| WBiLSTM | Attention, CRF | 89.45 | 89.29 | 89.42 | |
| CBiLSTM | Attention, CRF | 90.48 | 90.52 | 90.39 |
| CWS | No Dropout | Dropout = 0.25 | Dropout = 0.5 | ||||||
|---|---|---|---|---|---|---|---|---|---|
| P% | R% | F% | P% | R% | F% | P% | R% | F% | |
| 3 | 88.74 | 89.41 | 88.43 | 89.67 | 90.28 | 89.55 | 88.24 | 88.39 | 89.17 |
| 5 | 90.21 | 90.47 | 90.36 | 90.86 | 90.61 | 90.83 | 89.37 | 89.42 | 89.28 |
| 7 | 90.79 | 90.94 | 90.89 | 91.43 | 91.76 | 91.25 | 90.79 | 90.29 | 90.59 |
| 10 | 90.84 | 90.9 | 90.82 | 91.13 | 91.32 | 91.28 | 90.36 | 90.72 | 90.24 |
| Representation | Variants | Precision% | Recall% | F1-Score% |
|---|---|---|---|---|
| SdGloVe | No-attention | 87.92 | 88.27 | 88.16 |
| Attention | 88.37 | 89.25 | 88.79 | |
| SdfastText | No-attention | 89.74 | 90.18 | 89.76 |
| Attention | 90.27 | 90.64 | 90.11 | |
| CRL | No-attention | 90.58 | 90.86 | 90.82 |
| Attention | 91.43 | 91.76 | 91.25 |
| Paper | Model | Precision% | Recall% | F1-Score% |
|---|---|---|---|---|
| Existing work [21] | BiLSTM-CRF (GloVe) | 84.40 | 84.93 | 84.67 |
| BiLSTM-CRF (fastText) | 90.83 | 87.54 | 89.16 | |
| Our work | CaBiLSTM (SdGloVe) | 88.37 | 89.25 | 88.79 |
| CaBiLSTM (SdfastText) | 90.27 | 90.64 | 90.11 | |
| CaBiLSTM (CRL) | 90.43 | 91.76 | 91.25 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ali, W.; Kumar, J.; Xu, Z.; Kumar, R.; Ren, Y. Context-Aware Bidirectional Neural Model for Sindhi Named Entity Recognition. Appl. Sci. 2021, 11, 9038. https://doi.org/10.3390/app11199038
Ali W, Kumar J, Xu Z, Kumar R, Ren Y. Context-Aware Bidirectional Neural Model for Sindhi Named Entity Recognition. Applied Sciences. 2021; 11(19):9038. https://doi.org/10.3390/app11199038
Chicago/Turabian StyleAli, Wazir, Jay Kumar, Zenglin Xu, Rajesh Kumar, and Yazhou Ren. 2021. "Context-Aware Bidirectional Neural Model for Sindhi Named Entity Recognition" Applied Sciences 11, no. 19: 9038. https://doi.org/10.3390/app11199038
APA StyleAli, W., Kumar, J., Xu, Z., Kumar, R., & Ren, Y. (2021). Context-Aware Bidirectional Neural Model for Sindhi Named Entity Recognition. Applied Sciences, 11(19), 9038. https://doi.org/10.3390/app11199038