
Further Improvement on Two-Way Cooperative Collaborative Filtering Approaches for the Binary Market Basket Data


Abstract
:1. Introduction
2. Existing CF Approaches
2.1. One-Way Pearson Correlation-Based Approaches
2.2. One-Way RF Regression Approaches
2.3. One-Way PCA+LR Approaches
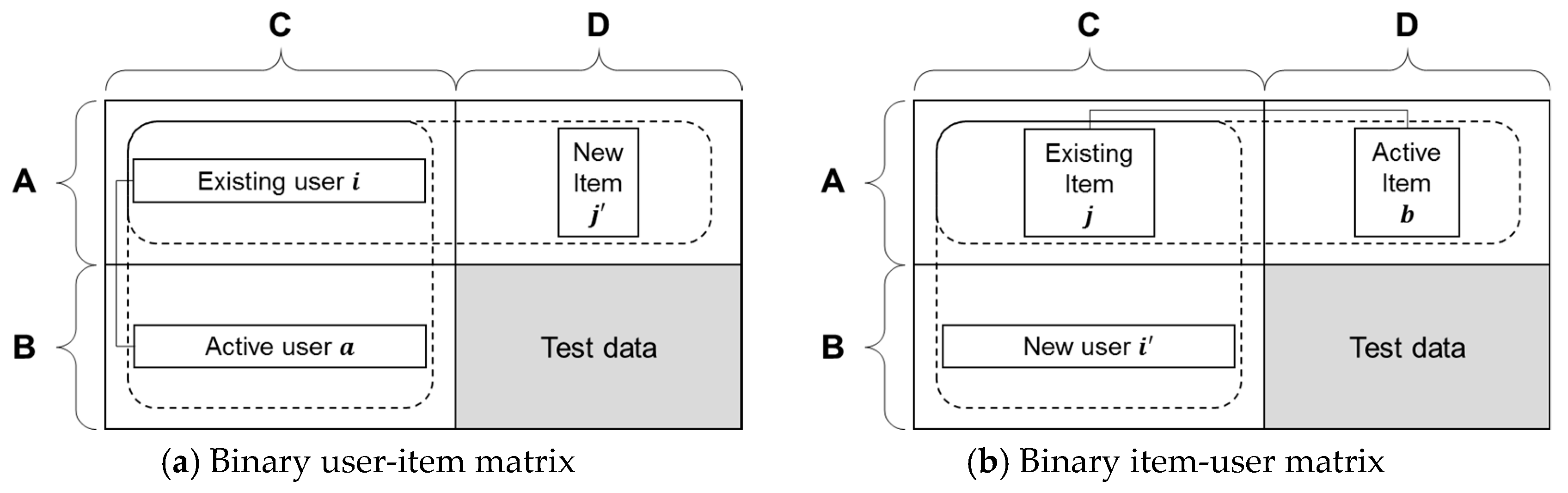
2.4. Two-Way Logistic Regression Approach (PCA+LR Two-Way 1)
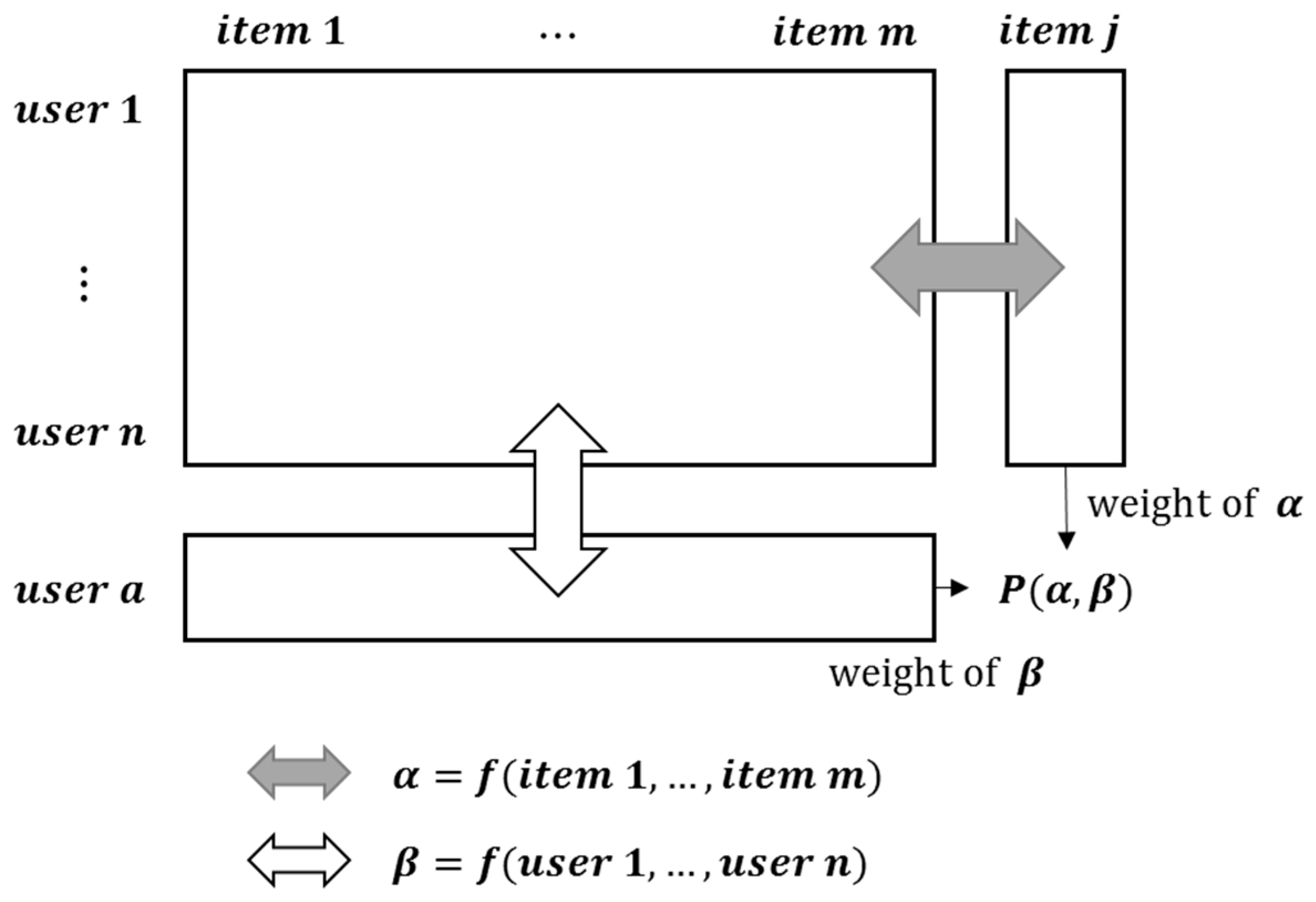
3. Proposed Two-Way Cooperative CF Approaches
3.1. Improved Two-Way Logistic Regression Approach (PCA+LR Two-Way 2)
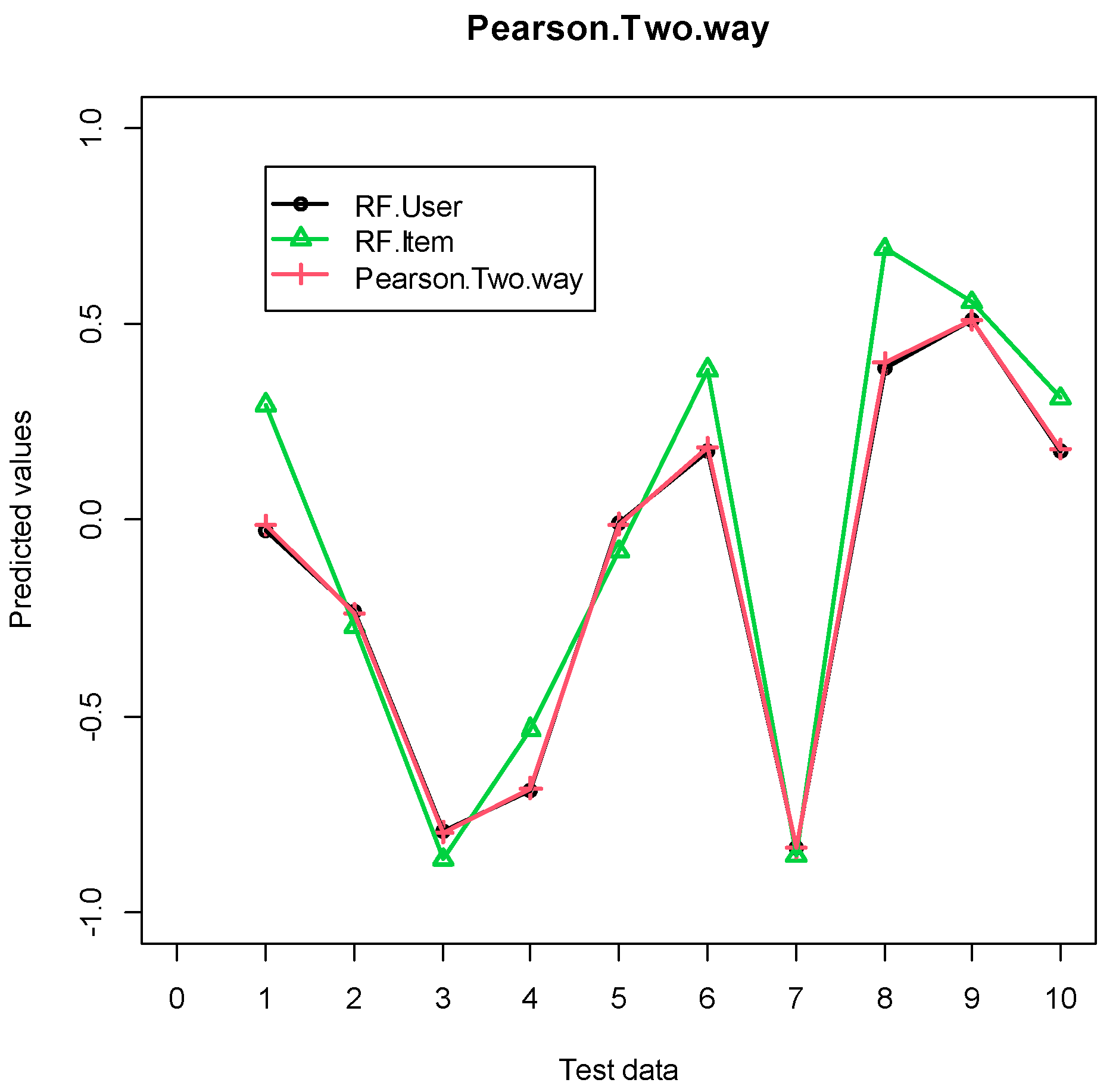
3.2. Pearson Correlation-Based Score
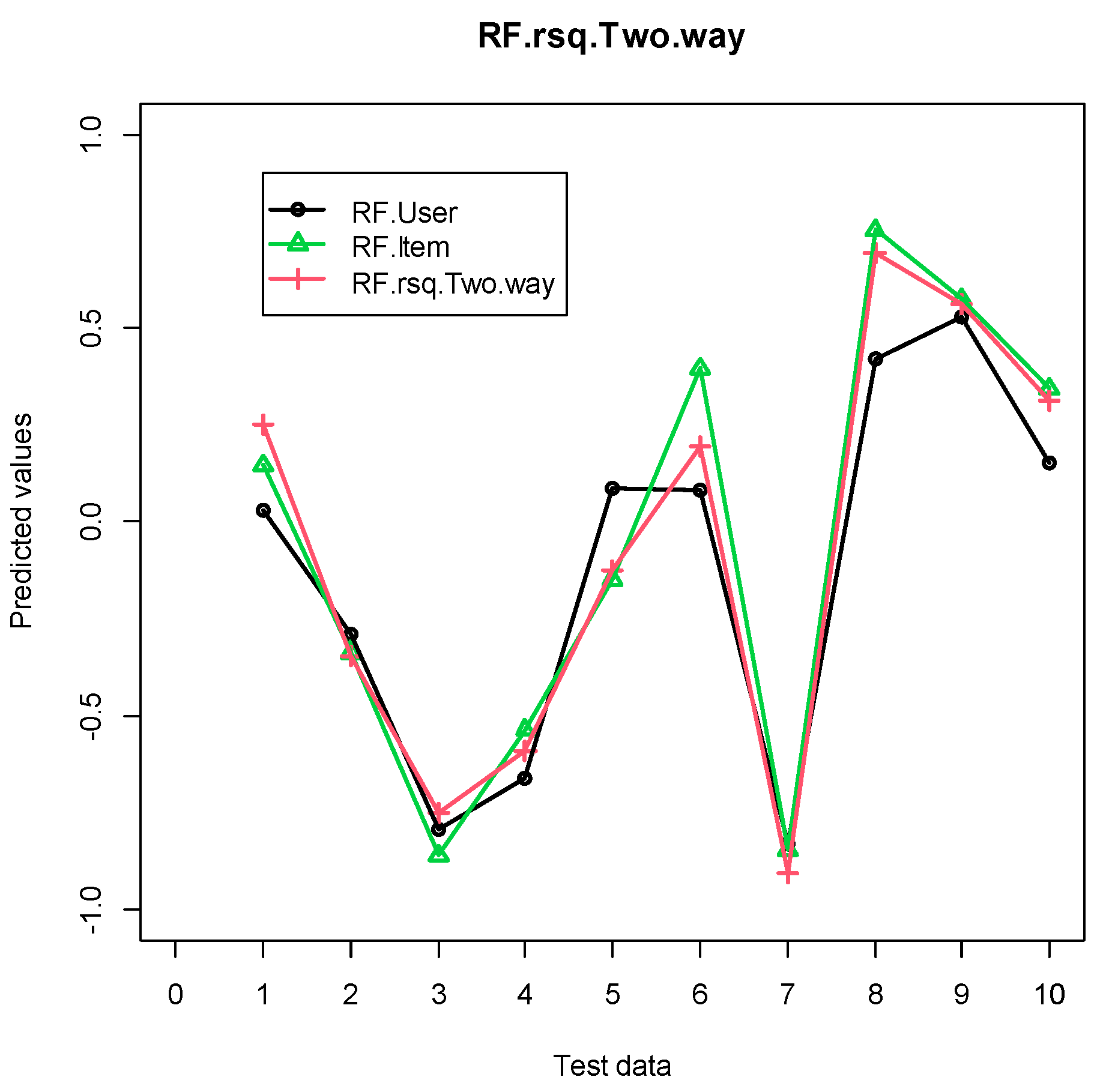
3.3. RF R-Square-Based Score and RF Pearson Correlation-Based Score
3.4. Scheme for RF R-Square-Based Score
3.5. Computational Complexity Analysis
4. Numerical Experiments
4.1. Experimental Settings
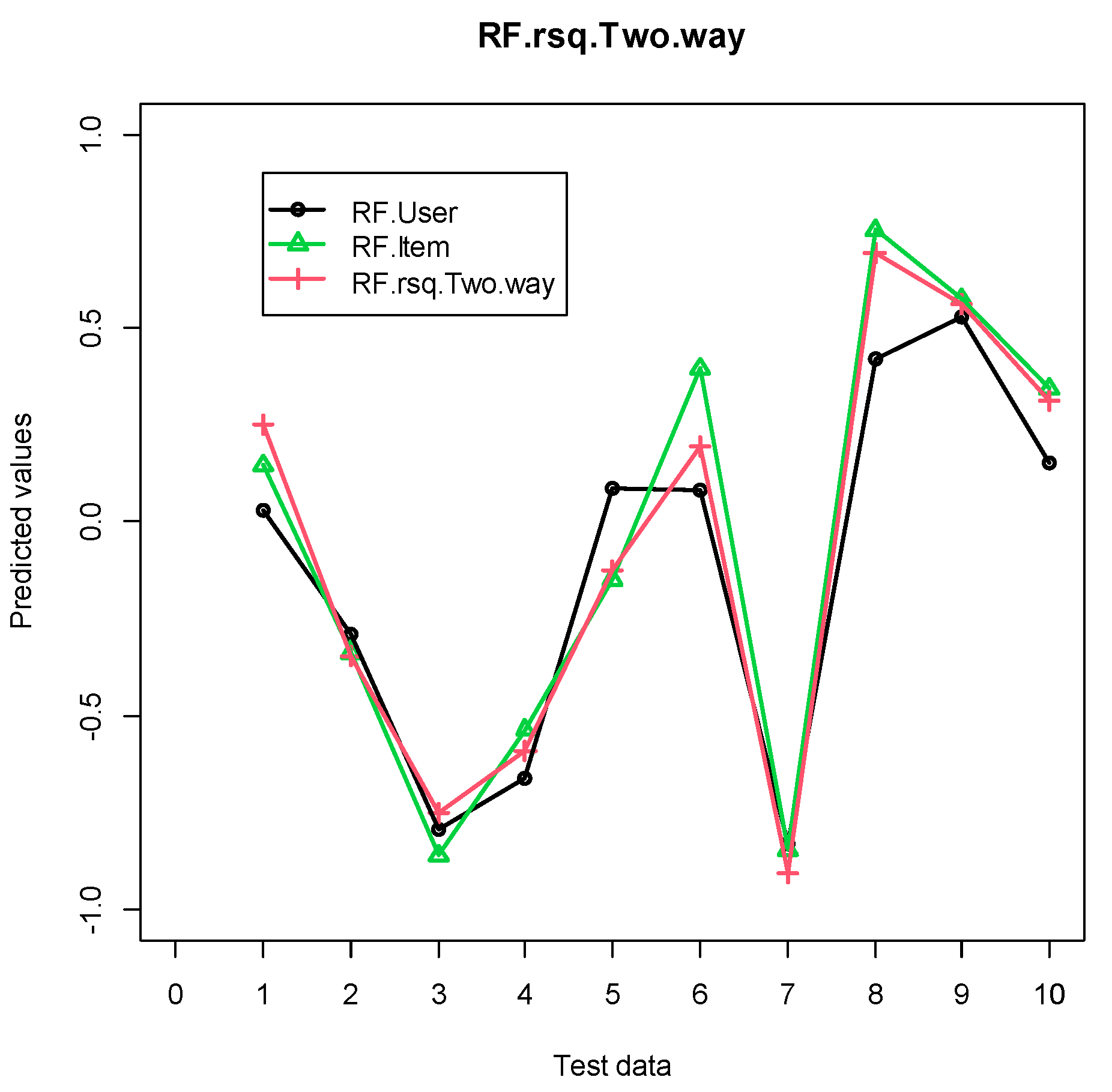
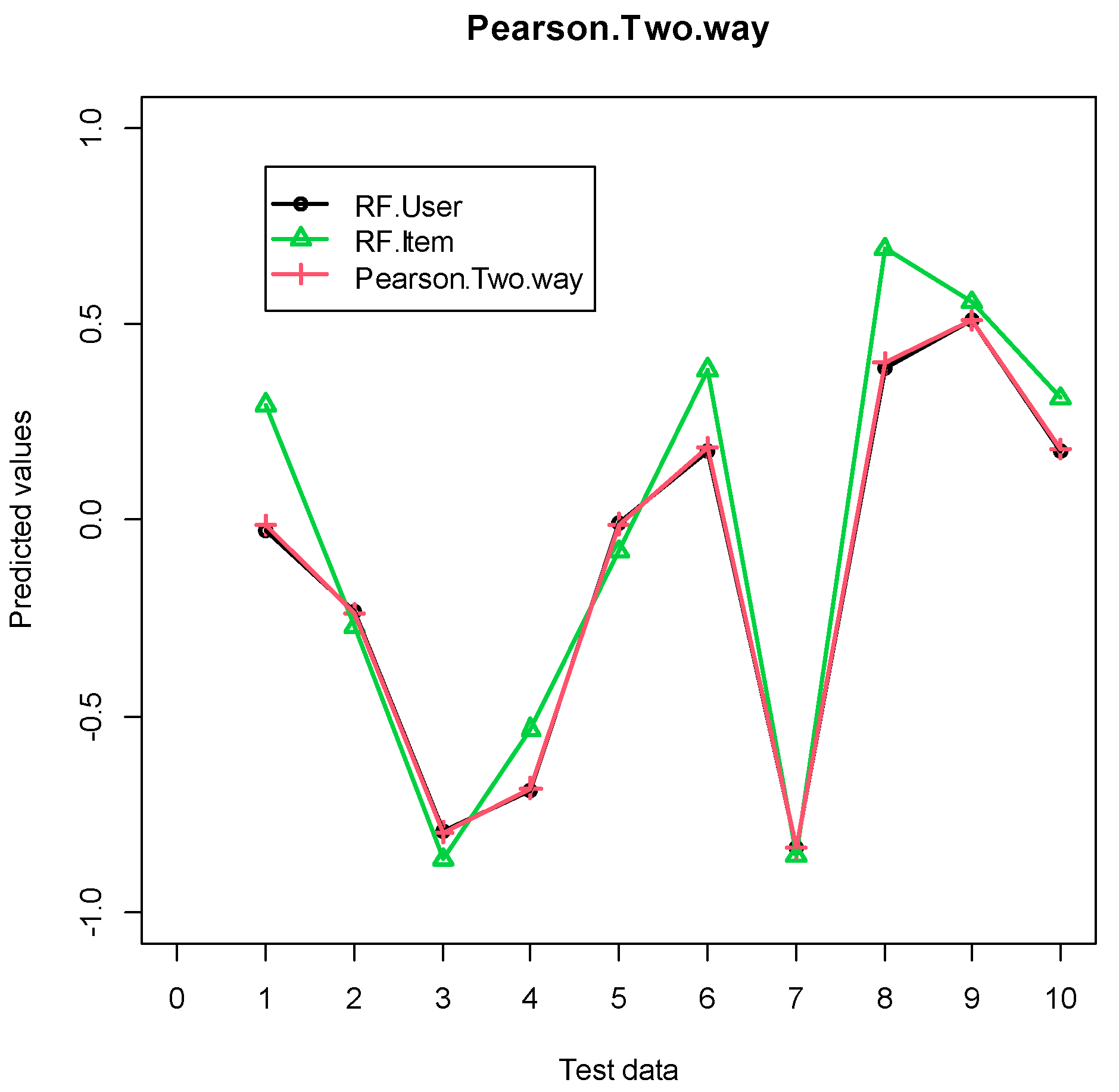
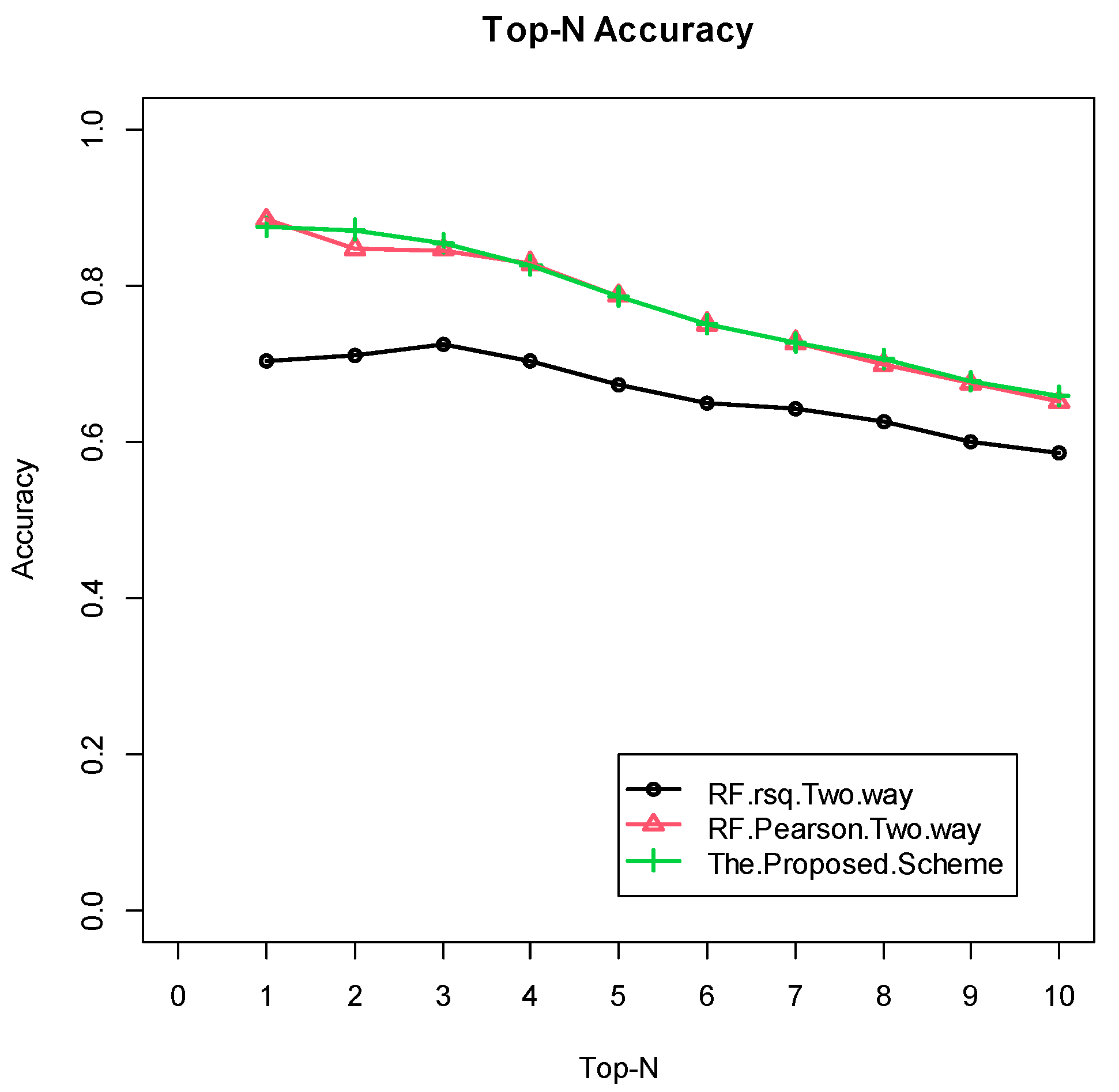
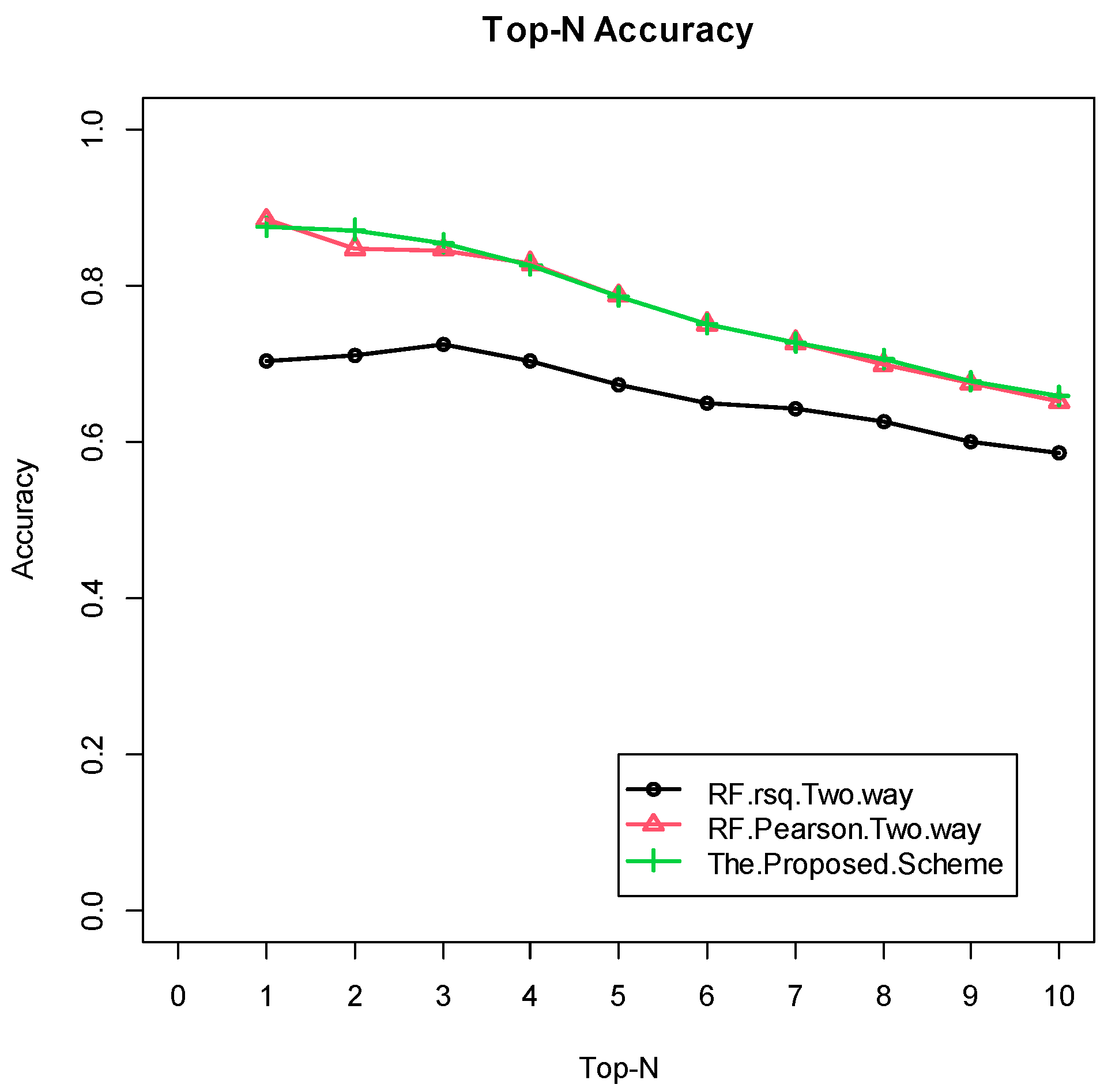
4.2. Experimental Results
4.2.1. Grocery Dataset
4.2.2. Eachmovie Dataset
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Su, X.; Khoshgoftaar, T.M. A Survey of Collaborative Filtering Techniques. Adv. Artif. Intell. 2009, 2009, 421425. [Google Scholar] [CrossRef]
- Park, D.H.; Kim, H.K.; Choi, I.Y.; Kim, J.K. A research. Expert Syst. Appl. 2012, 39, 10059–10072. [Google Scholar] [CrossRef]
- Ahn, H.J. A new similarity measure for collaborative filtering to alleviate the new user cold-starting problem. Inf. Sci. 2008, 178, 37–51. [Google Scholar] [CrossRef]
- Schein, A.; Popescul, A.; Ungar, L.H. Methods and metrics for cold-start recommendations. In Proceedings of the 25th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, Tampere, Finland, 11–15 August 2002; pp. 253–260. [Google Scholar]
- Park, S.T.; Chu, W. Pairwise preference regression for cold-start recommendation. In Proceedings of the third ACM Conference on Recommender Systems (RecSys2009), New York, NY, USA, 22–25 October 2009; pp. 21–28. [Google Scholar]
- Chen, C.C.; Wan, Y.-H.; Chung, M.-C.; Sun, Y.-C. An effective recommendation method for cold start new users using trust and distrust networks. Inf. Sci. 2013, 224, 19–36. [Google Scholar] [CrossRef]
- Lika, B.; Kolomvatsos, K.; Hadjiefthymiades, S. Facing the cold start problem in recommender systems. Expert Syst. Appl. 2013, 41, 2065–2073. [Google Scholar] [CrossRef]
- Liu, H.; Hu, Z.; Mian, A.; Tian, H.; Zhu, X. A new user similarity model to improve the accuracy of collaborative filtering. Knowl. -Based Syst. 2014, 56, 156–166. [Google Scholar] [CrossRef] [Green Version]
- Son, L.H. Dealing with the new user cold-start problem in recommender systems: A comparative review. Inf. Syst. 2016, 58, 87–104. [Google Scholar] [CrossRef]
- JBreese, S.; Heckerman, D.; Kadie, C. Empirical Analysis of Predictive Algorithms for Collaborative Filtering; Technical Report MSR-TR-98-12; Microsoft Research: Redmond, WA, USA, 1998. [Google Scholar]
- Choi, K.; Suh, Y. A new similarity function for selecting neighbors for each target item in collaborative filtering. Knowl.-Based Syst. 2013, 37, 146–153. [Google Scholar] [CrossRef]
- Goldberg, D.; Nichols, D.; Oki, B.M.; Terry, D. Using collaborative filtering to weave an information tapestry. Commun. ACM 1992, 35, 61–70. [Google Scholar] [CrossRef]
- Leung, C.W.-K.; Chan, S.C.-F.; Chung, F.-L. An empirical study of a cross-level association rule mining approach to cold-start recommendations. Knowl.-Based Syst. 2008, 21, 515–529. [Google Scholar] [CrossRef]
- Tsai, C.-F.; Hung, C. Cluster ensembles in collaborative filtering recommendation. Appl. Soft Comput. 2011, 12, 1417–1425. [Google Scholar] [CrossRef]
- Stai, E.; Kafetzoglou, S.; Tsiropoulou, E.E.; Papavassiliou, S. A holistic approach for personalization, relevance feedback & recommendation in enriched multimedia content. Multimed. Tools Appl. 2018, 77, 283–326. [Google Scholar]
- Burke, R. Hybrid Recommender Systems: Survey and Experiments. User Model. User-Adapt. Interact. 2002, 12, 331–370. [Google Scholar] [CrossRef]
- Thai, M.T.; Wu, W.; Xiong, H. Big Data in Complex and Social Networks; CRC Press: Boca Raton, FL, USA, 2016. [Google Scholar]
- Mild, A.; Reutterer, T. An improved collaborative filtering approach for predicting cross-category purchases based on binary market basket data. J. Retail. Consum. Serv. 2003, 10, 123–133. [Google Scholar] [CrossRef] [Green Version]
- Mild, A.; Reutterer, T. Collaborative Filtering Methods for Binary Market Basket Data Analysis. In International Computer Science Conference on Active Media Technology; Springer: Berlin/Heidelberg, Germany, 2001; Volume 2252, pp. 302–313. [Google Scholar] [CrossRef]
- Hwang, W.Y. Variable Selection for Collaborative Filtering with the Market Basket Data. Int. Trans. Oper. Res. 2020, 27, 3167–3177. [Google Scholar] [CrossRef]
- Hwang, W.-Y. Assessing new correlation-based collaborative filtering approaches for binary market basket data. Electron. Commer. Res. Appl. 2018, 29, 12–18. [Google Scholar] [CrossRef]
- Lee, J.; Jun, C.-H.; Kim, S. Classification-based collaborative filtering using market basket data. Expert Syst. Appl. 2005, 29, 700–704. [Google Scholar] [CrossRef]
- Hwang, W.-Y.; Jun, C.-H. Supervised Learning-Based Collaborative Filtering Using Market Basket Data for the Cold-Start Problem. Ind. Eng. Manag. Syst. 2014, 13, 421–431. [Google Scholar] [CrossRef] [Green Version]
- Lee, J.-S.; Olafsson, S. Two-way cooperative prediction for collaborative filtering recommendations. Expert Syst. Appl. 2009, 36, 5353–5361. [Google Scholar] [CrossRef]
- Hahsler, M.; Hornik, K.; Reutterer, T. Implications of Probabilistic Data Modeling for Mining Association Rules. In From Data and Information Analysis to Knowledge Engineering; Springer: Berlin/Heidelberg, Germany, 2006; pp. 598–605. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Symbol | Description |
|---|---|
| number of users | |
| number of items | |
| similarity between users and | |
| similarity between items and | |
| , | predicted scores by user-based and item-based CFs |
| predicted scores by regression | |
| Pearson correlation-based score | |
| RF R-square-based score | |
| RF Pearson correlation-based score |
| Classification Error | Precision | Recall | F1 Score | |
|---|---|---|---|---|
| PCA+LR item modeling | 0.173 | |||
| PCA+LR user modeling | 0.120 | |||
| PCA+LR two-way 1 | NA | NA | NA | NA |
| PCA+LR two-way 2 | NA | NA | NA | NA |
| User-based CF | 0.050 | |||
| Item-based CF | 0.110 | |||
| Pearson correlation-based score | 0.099 | |||
| RF item modeling | 0.087 | |||
| RF user modeling | 0.087 | |||
| RF R-square-based score | 0.099 | |||
| RF Pearson correlation-based score | 0.153 |
| N | PCA+LR User | PCA+LR Item | PCA+LR Two-Way 1 | Pearson User | Pearson Item | Pearson Score | RF User | RF Item | RF rsq Score |
|---|---|---|---|---|---|---|---|---|---|
| 1 | 0.926 | 0.926 | 0.917 | 0.893 | 0.843 | 0.884 | 0.926 | 0.934 | 0.934 |
| 2 | 0.905 | 0.921 | 0.917 | 0.868 | 0.855 | 0.872 | 0.921 | 0.917 | 0.913 |
| 3 | 0.909 | 0.917 | 0.912 | 0.862 | 0.857 | 0.871 | 0.917 | 0.904 | 0.909 |
| 4 | 0.899 | 0.907 | 0.899 | 0.847 | 0.855 | 0.853 | 0.897 | 0.895 | 0.903 |
| 5 | 0.891 | 0.893 | 0.891 | 0.812 | 0.833 | 0.823 | 0.873 | 0.881 | 0.893 |
| 6 | 0.858 | 0.855 | 0.854 | 0.788 | 0.807 | 0.803 | 0.850 | 0.864 | 0.869 |
| 7 | 0.837 | 0.832 | 0.835 | 0.769 | 0.782 | 0.775 | 0.829 | 0.836 | 0.837 |
| 8 | 0.807 | 0.802 | 0.808 | 0.738 | 0.754 | 0.750 | 0.813 | 0.813 | 0.817 |
| 9 | 0.778 | 0.775 | 0.786 | 0.717 | 0.731 | 0.731 | 0.778 | 0.789 | 0.793 |
| 10 | 0.751 | 0.752 | 0.757 | 0.704 | 0.696 | 0.711 | 0.754 | 0.759 | 0.771 |
| Avg. | 0.856 | 0.858 | 0.858 | 0.800 | 0.801 | 0.807 | 0.856 | 0.859 | 0.864 |
| N | PCA+LR User | PCA+LR Item | PCA+LR Two-Way 1 | Pearson User | Pearson ITEM | Pearson Score | RF User | RF Item | RF rsq Score |
|---|---|---|---|---|---|---|---|---|---|
| 1 | 0.940 | 0.940 | 0.920 | 0.880 | 0.780 | 0.920 | 0.900 | 0.920 | 0.920 |
| 2 | 0.900 | 0.880 | 0.910 | 0.870 | 0.790 | 0.870 | 0.850 | 0.900 | 0.900 |
| 3 | 0.867 | 0.860 | 0.860 | 0.873 | 0.727 | 0.873 | 0.867 | 0.893 | 0.893 |
| 4 | 0.860 | 0.855 | 0.850 | 0.875 | 0.730 | 0.875 | 0.820 | 0.860 | 0.865 |
| 5 | 0.840 | 0.828 | 0.844 | 0.832 | 0.708 | 0.840 | 0.800 | 0.836 | 0.836 |
| 6 | 0.803 | 0.793 | 0.797 | 0.777 | 0.683 | 0.790 | 0.770 | 0.800 | 0.800 |
| 7 | 0.766 | 0.746 | 0.754 | 0.740 | 0.660 | 0.740 | 0.734 | 0.763 | 0.777 |
| 8 | 0.735 | 0.705 | 0.715 | 0.705 | 0.633 | 0.710 | 0.703 | 0.725 | 0.743 |
| 9 | 0.691 | 0.678 | 0.693 | 0.689 | 0.611 | 0.687 | 0.678 | 0.696 | 0.708 |
| 10 | 0.660 | 0.662 | 0.672 | 0.670 | 0.592 | 0.664 | 0.654 | 0.684 | 0.674 |
| Avg. | 0.806 | 0.795 | 0.802 | 0.791 | 0.691 | 0.797 | 0.778 | 0.808 | 0.812 |
| N | PCA+LR User | PCA+LR Item | PCA+LR 2-Way 1 | PCA+LR 2-Way 2 | Pearson User | Pearson Item | Pearson Score | RF User | RF Item | RF rsq Score | RF Pearson Score |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 0.49 | 0.67 | 0.49 | 0.54 | 0.71 | 0.41 | 0.30 | 0.66 | 0.63 | 0.57 | 0.79 |
| 2 | 0.47 | 0.66 | 0.40 | 0.48 | 0.73 | 0.38 | 0.24 | 0.71 | 0.71 | 0.59 | 0.71 |
| 3 | 0.42 | 0.62 | 0.37 | 0.44 | 0.68 | 0.39 | 0.27 | 0.66 | 0.65 | 0.56 | 0.65 |
| 4 | 0.43 | 0.56 | 0.38 | 0.45 | 0.63 | 0.38 | 0.26 | 0.61 | 0.61 | 0.53 | 0.62 |
| 5 | 0.42 | 0.55 | 0.36 | 0.42 | 0.60 | 0.37 | 0.24 | 0.58 | 0.58 | 0.53 | 0.60 |
| 6 | 0.42 | 0.53 | 0.35 | 0.42 | 0.56 | 0.36 | 0.23 | 0.57 | 0.56 | 0.53 | 0.57 |
| 7 | 0.44 | 0.52 | 0.36 | 0.44 | 0.54 | 0.35 | 0.25 | 0.54 | 0.54 | 0.50 | 0.54 |
| 8 | 0.43 | 0.50 | 0.35 | 0.43 | 0.51 | 0.34 | 0.23 | 0.52 | 0.52 | 0.49 | 0.53 |
| 9 | 0.42 | 0.49 | 0.34 | 0.42 | 0.50 | 0.34 | 0.23 | 0.49 | 0.50 | 0.48 | 0.52 |
| 10 | 0.41 | 0.47 | 0.34 | 0.41 | 0.49 | 0.33 | 0.23 | 0.48 | 0.47 | 0.47 | 0.50 |
| Avg. | 0.44 | 0.56 | 0.37 | 0.45 | 0.60 | 0.36 | 0.25 | 0.58 | 0.58 | 0.53 | 0.60 |
| N | PCA +LR User | PCA +LR Item | PCA +LR 2-Way 1 | PCA +LR 2-Way 2 | Pearson User | Pearson Item | Pearson Score | RF User | RF Item | RF rsq 2-Way | RF Pearson Score |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 0.76 | 0.87 | NA | 0.69 | 0.84 | 0.68 | 0.85 | 0.86 | 0.88 | 0.70 | 0.88 |
| 2 | 0.73 | 0.87 | NA | 0.74 | 0.84 | 0.63 | 0.83 | 0.84 | 0.86 | 0.71 | 0.85 |
| 3 | 0.71 | 0.85 | NA | 0.74 | 0.82 | 0.62 | 0.82 | 0.83 | 0.84 | 0.73 | 0.85 |
| 4 | 0.67 | 0.84 | NA | 0.74 | 0.81 | 0.62 | 0.80 | 0.81 | 0.81 | 0.70 | 0.83 |
| 5 | 0.64 | 0.82 | NA | 0.71 | 0.77 | 0.62 | 0.77 | 0.76 | 0.79 | 0.67 | 0.79 |
| 6 | 0.61 | 0.78 | NA | 0.69 | 0.75 | 0.61 | 0.74 | 0.74 | 0.76 | 0.65 | 0.75 |
| 7 | 0.59 | 0.75 | NA | 0.67 | 0.71 | 0.59 | 0.71 | 0.70 | 0.73 | 0.64 | 0.73 |
| 8 | 0.57 | 0.71 | NA | 0.64 | 0.68 | 0.57 | 0.68 | 0.68 | 0.70 | 0.63 | 0.70 |
| 9 | 0.56 | 0.69 | NA | 0.62 | 0.66 | 0.56 | 0.66 | 0.65 | 0.68 | 0.60 | 0.68 |
| 10 | 0.55 | 0.67 | NA | 0.61 | 0.64 | 0.54 | 0.64 | 0.63 | 0.65 | 0.59 | 0.65 |
| Avg. | 0.64 | 0.79 | NA | 0.69 | 0.75 | 0.60 | 0.75 | 0.75 | 0.77 | 0.66 | 0.77 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hwang, W.-Y.; Lee, J.-S. Further Improvement on Two-Way Cooperative Collaborative Filtering Approaches for the Binary Market Basket Data. Appl. Sci. 2021, 11, 8977. https://doi.org/10.3390/app11198977
Hwang W-Y, Lee J-S. Further Improvement on Two-Way Cooperative Collaborative Filtering Approaches for the Binary Market Basket Data. Applied Sciences. 2021; 11(19):8977. https://doi.org/10.3390/app11198977
Chicago/Turabian StyleHwang, Wook-Yeon, and Jong-Seok Lee. 2021. "Further Improvement on Two-Way Cooperative Collaborative Filtering Approaches for the Binary Market Basket Data" Applied Sciences 11, no. 19: 8977. https://doi.org/10.3390/app11198977
APA StyleHwang, W.-Y., & Lee, J.-S. (2021). Further Improvement on Two-Way Cooperative Collaborative Filtering Approaches for the Binary Market Basket Data. Applied Sciences, 11(19), 8977. https://doi.org/10.3390/app11198977