
Algorithmic Music for Therapy: Effectiveness and Perspectives


 ,
,  ,
, 
Abstract
:1. Introduction
2. Materials and Methods
2.1. Phase 1
2.2. Phase 2
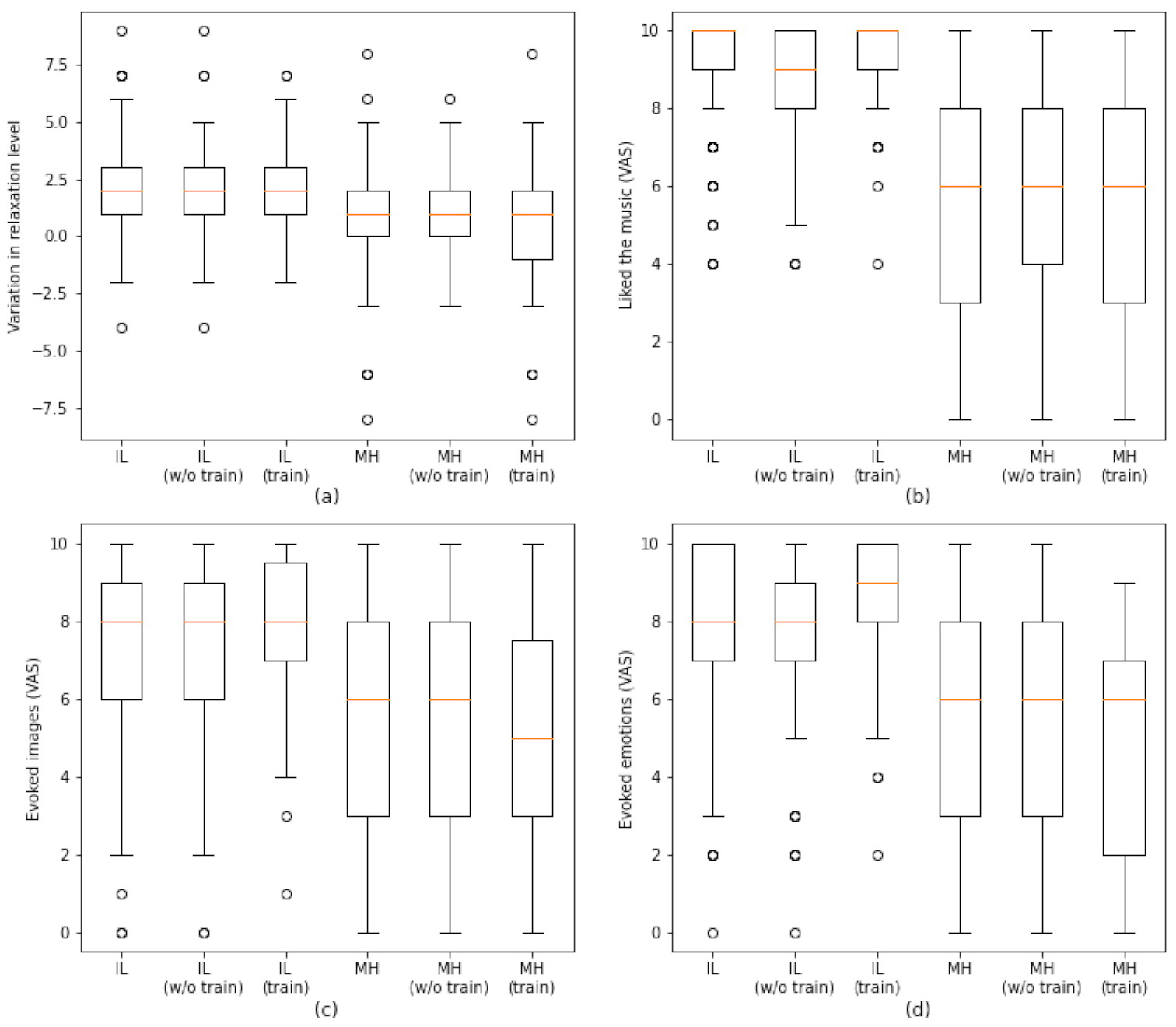
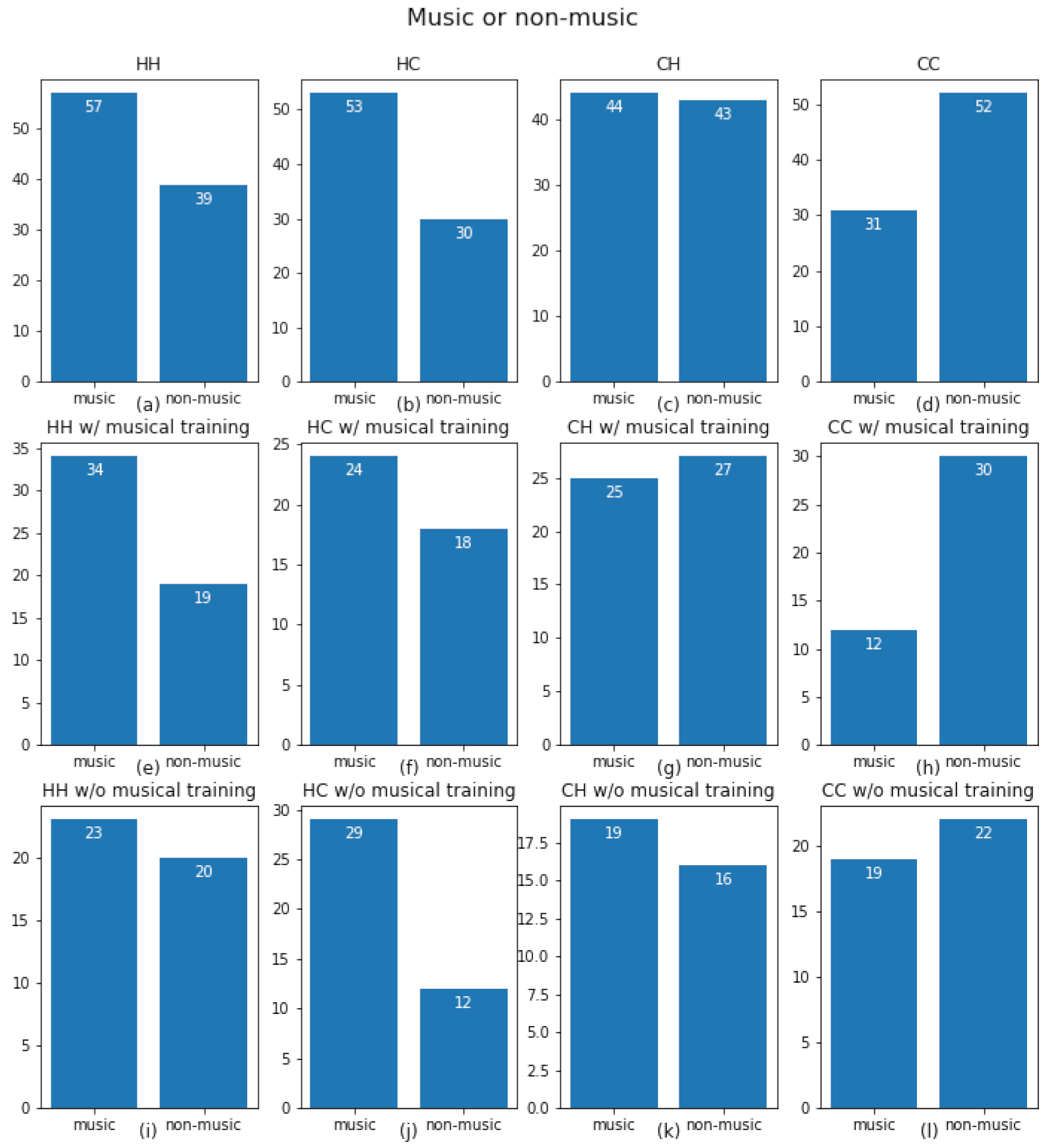
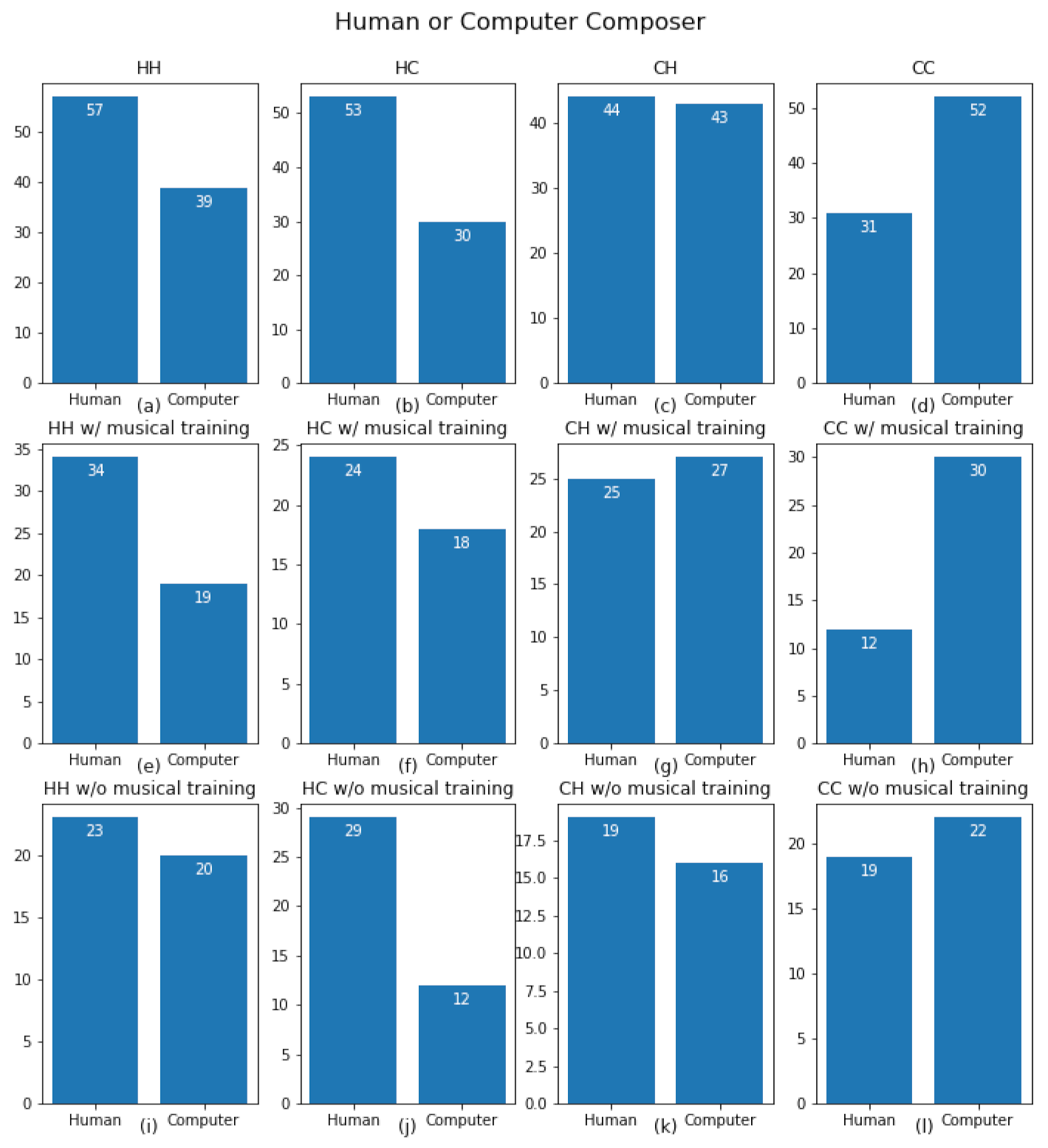
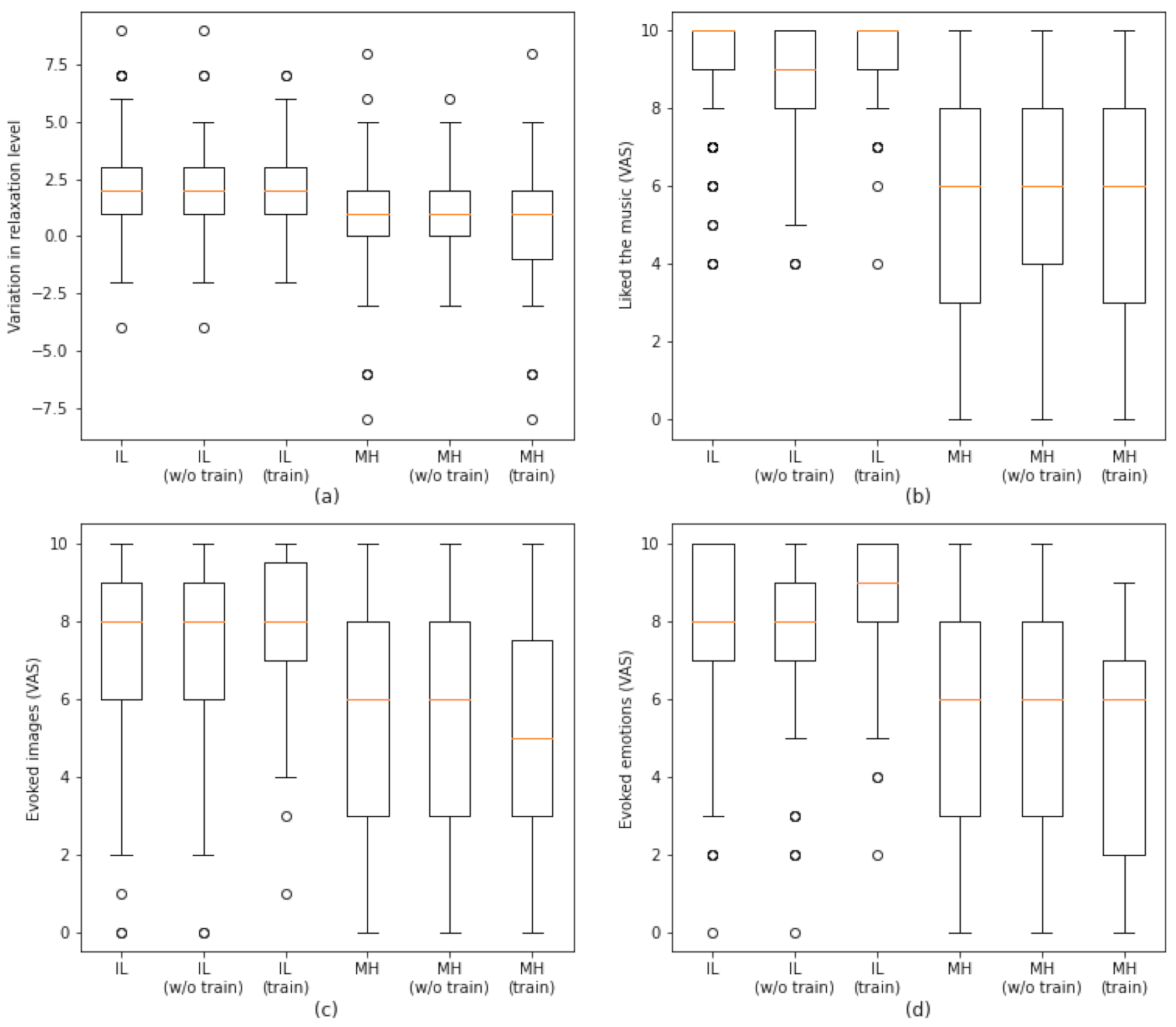
3. Results
3.1. Phase 1
3.2. Phase 2
4. Discussion
4.1. Phase 1
4.2. Phase 2
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Raglio, A. When music becomes music therapy. Psychiatry Clin. Neurosci. 2011, 65, 682–683. [Google Scholar] [CrossRef] [PubMed]
- Gold, C.; Solli, H.P.; Krüger, V.; Lie, S.A. Dose–response relationship in music therapy for people with serious mental disorders: Systematic review and meta-analysis. Clin. Psychol. Rev. 2009, 29, 193–207. [Google Scholar] [CrossRef] [PubMed]
- Raglio, A. More music, more health! J. Public Health 2020. [Google Scholar] [CrossRef]
- Raglio, A.; Oasi, O. Music and health: What interventions for what results? Front. Psychol. 2015, 6, 230. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Koelsch, S. A neuroscientific perspective on music therapy. Ann. N. Y. Acad. Sci. 2009, 1169, 374–384. [Google Scholar] [CrossRef] [PubMed]
- Raglio, A. Music and neurorehabilitation: Yes, we can! Funct. Neurol. 2018, 33, 173–174. [Google Scholar] [PubMed]
- Scholz, D.S.; Rohde, S.; Nikmaram, N.; Brückner, H.P.; Großbach, M.; Rollnik, J.D.; Altenmüller, E.O. Sonification of arm movements in stroke rehabilitation—A novel approach in neurologic music therapy. Front. Neurol. 2016, 7, 106. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Altenmüller, E.; Schlaug, G. Apollo’s gift: New aspects of neurologic music therapy. Prog. Brain Res. 2015, 217, 237–252. [Google Scholar]
- Thaut, M.; Hoemberg, V. Handbook of Neurologic Music Therapy; Oxford University Press: Oxford, UK, 2014. [Google Scholar]
- Sihvonen, A.J.; Särkämö, T.; Leo, V.; Tervaniemi, M.; Altenmüller, E.; Soinila, S. Music-based interventions in neurological rehabilitation. Lancet Neurol. 2017, 16, 648–660. [Google Scholar] [CrossRef] [Green Version]
- Simon, H.B. Music as medicine. Am. J. Med. 2015, 128, 208–210. [Google Scholar] [CrossRef]
- Chanda, M.L.; Levitin, D.J. The neurochemistry of music. Trends Cogn. Sci. 2013, 17, 179–193. [Google Scholar] [CrossRef] [Green Version]
- Boso, M.; Politi, P.; Barale, F.; Emanuele, E. Neurophysiology and neurobiology of the musical experience. Funct. Neurol. 2006, 21, 187. [Google Scholar]
- Lee, J.H. The effects of music on pain: A meta-analysis. J. Music. Ther. 2016, 53, 430–477. [Google Scholar] [CrossRef]
- Linnemann, A.; Kappert, M.B.; Fischer, S.; Doerr, J.M.; Strahler, J.; Nater, U.M. The effects of music listening on pain and stress in the daily life of patients with fibromyalgia syndrome. Front. Hum. Neurosci. 2015, 9, 434. [Google Scholar] [CrossRef] [Green Version]
- Bradt, J.; Dileo, C.; Magill, L.; Teague, A. Music interventions for improving psychological and physical outcomes in cancer patients. Cochrane Database Syst. Rev. 2016, 8. [Google Scholar] [CrossRef]
- Raglio, A. Therapeutic use of music in hospitals: A possible intervention model. Am. J. Med. Qual. 2019, 34, 618–620. [Google Scholar] [CrossRef]
- Hole, J.; Hirsch, M.; Ball, E.; Meads, C. Music as an aid for postoperative recovery in adults: A systematic review and meta-analysis. Lancet 2015, 386, 1659–1671. [Google Scholar] [CrossRef]
- Gaviola, M.A.; Inder, K.J.; Dilworth, S.; Holliday, E.G.; Higgins, I. Impact of individualised music listening intervention on persons with dementia: A systematic review of randomised controlled trials. Australas. J. Ageing 2020, 39, 10–20. [Google Scholar] [CrossRef]
- Raglio, A.; Attardo, L.; Gontero, G.; Rollino, S.; Groppo, E.; Granieri, E. Effects of music and music therapy on mood in neurological patients. World J. Psychiatry 2015, 5, 68. [Google Scholar] [CrossRef]
- Gerdner, L.A. Individualized music for dementia: Evolution and application of evidence-based protocol. World J. Psychiatry 2012, 2, 26. [Google Scholar] [CrossRef]
- Särkämö, T.; Tervaniemi, M.; Laitinen, S.; Forsblom, A.; Soinila, S.; Mikkonen, M.; Autti, T.; Silvennoinen, H.M.; Erkkilä, J.; Laine, M.; et al. Music listening enhances cognitive recovery and mood after middle cerebral artery stroke. Brain 2008, 131, 866–876. [Google Scholar] [CrossRef] [Green Version]
- Lopez-Rincon, O.; Starostenko, O.; Ayala-San Martín, G. Algoritmic music composition based on artificial intelligence: A survey. In Proceedings of the 2018 IEEE International Conference on Electronics, Communications and Computers (CONIELECOMP), Cholula, Mexico, 21–23 February 2018; pp. 187–193. [Google Scholar]
- Liu, C.H.; Ting, C.K. Computational intelligence in music composition: A survey. IEEE Trans. Emerg. Top. Comput. Intell. 2016, 1, 2–15. [Google Scholar] [CrossRef]
- De Prisco, R.; Zaccagnino, G.; Zaccagnino, R. EvoComposer: An Evolutionary Algorithm for 4-Voice Music Compositions. Evol. Comput. 2020, 28, 489–530. [Google Scholar] [CrossRef]
- Wiggins, G.A. Computer models of musical creativity: A review of computer models of musical creativity by David Cope. Lit. Linguist. Comput. 2008, 23, 109–116. [Google Scholar] [CrossRef] [Green Version]
- Raglio, A.; Bellandi, D.; Gianotti, M.; Zanacchi, E.; Gnesi, M.; Monti, M.; Montomoli, C.; Vico, F.; Imbriani, C.; Giorgi, I.; et al. Daily music listening to reduce work-related stress: A randomized controlled pilot trial. J. Public Health 2020, 42, e81–e87. [Google Scholar] [CrossRef]
- Raglio, A. What Happens When Algorithmic Music Meets Pain Medicine. Pain Med. 2020, 21, 3736–3737. [Google Scholar]
- Raglio, A.; Vico, F. Music and technology: The curative algorithm. Front. Psychol. 2017, 8, 2055. [Google Scholar] [CrossRef] [Green Version]
- Requena, G.; Sánchez, C.; Corzo-Higueras, J.L.; Reyes-Alvarado, S.; Rivas-Ruiz, F.; Vico, F.; Raglio, A. Melomics music medicine (M3) to lessen pain perception during pediatric prick test procedure. Pediatr. Allergy Immunol. 2014, 25, 721–724. [Google Scholar] [CrossRef] [PubMed]
- Zatorre, R.J. Why Do We Love Music? In Cerebrum: The Dana Forum on Brain Science; Dana Foundation: New York, NY, USA, 2018; Volume 2018. [Google Scholar]
- Holbrook, M.B.; Schindler, R.M. Some exploratory findings on the development of musical tastes. J. Consum. Res. 1989, 16, 119–124. [Google Scholar] [CrossRef]
- Way, S.F.; Gil, S.; Anderson, I.; Clauset, A. Environmental changes and the dynamics of musical identity. In Proceedings of the International AAAI Conference on Web and Social Media, Munich, Germany, 11–14 June 2019; Volume 13, pp. 527–536. [Google Scholar]
- Martin-Saavedra, J.S.; Vergara-Mendez, L.D.; Pradilla, I.; Velez-van Meerbeke, A.; Talero-Gutierrez, C. Standardizing music characteristics for the management of pain: A systematic review and meta-analysis of clinical trials. Complement. Ther. Med. 2018, 41, 81–89. [Google Scholar] [CrossRef]
- Guétin, S.; Giniès, P.; Siou, D.K.A.; Picot, M.C.; Pommié, C.; Guldner, E.; Gosp, A.M.; Ostyn, K.; Coudeyre, E.; Touchon, J. The effects of music intervention in the management of chronic pain: A single-blind, randomized, controlled trial. Clin. J. Pain 2012, 28, 329–337. [Google Scholar] [CrossRef] [PubMed]
- Raglio, A.; Imbriani, M.; Imbriani, C.; Baiardi, P.; Manzoni, S.; Gianotti, M.; Castelli, M.; Vanneschi, L.; Vico, F.; Manzoni, L. Machine learning techniques to predict the effectiveness of music therapy: A randomized controlled trial. Comput. Methods Programs Biomed. 2020, 185, 105160. [Google Scholar] [CrossRef] [PubMed]
- Sheskin, D.J. Handbook of Parametric and Nonparametric Statistical Procedures; CRC Press: Boca Raton, FL, USA, 2020. [Google Scholar]
- Kirke, A.; Miranda, E.R. A survey of computer systems for expressive music performance. ACM Comput. Surv. CSUR 2009, 42, 1–41. [Google Scholar] [CrossRef]
- Blood, A.J.; Zatorre, R.J. Intensely pleasurable responses to music correlate with activity in brain regions implicated in reward and emotion. Proc. Natl. Acad. Sci. USA 2001, 98, 11818–11823. [Google Scholar] [CrossRef] [Green Version]
- Salimpoor, V.N.; Benovoy, M.; Larcher, K.; Dagher, A.; Zatorre, R.J. Anatomically distinct dopamine release during anticipation and experience of peak emotion to music. Nat. Neurosci. 2011, 14, 257–262. [Google Scholar] [CrossRef]
- Salimpoor, V.N.; van den Bosch, I.; Kovacevic, N.; McIntosh, A.R.; Dagher, A.; Zatorre, R.J. Interactions between the nucleus accumbens and auditory cortices predict music reward value. Science 2013, 340, 216–219. [Google Scholar] [CrossRef]


{kind=link}
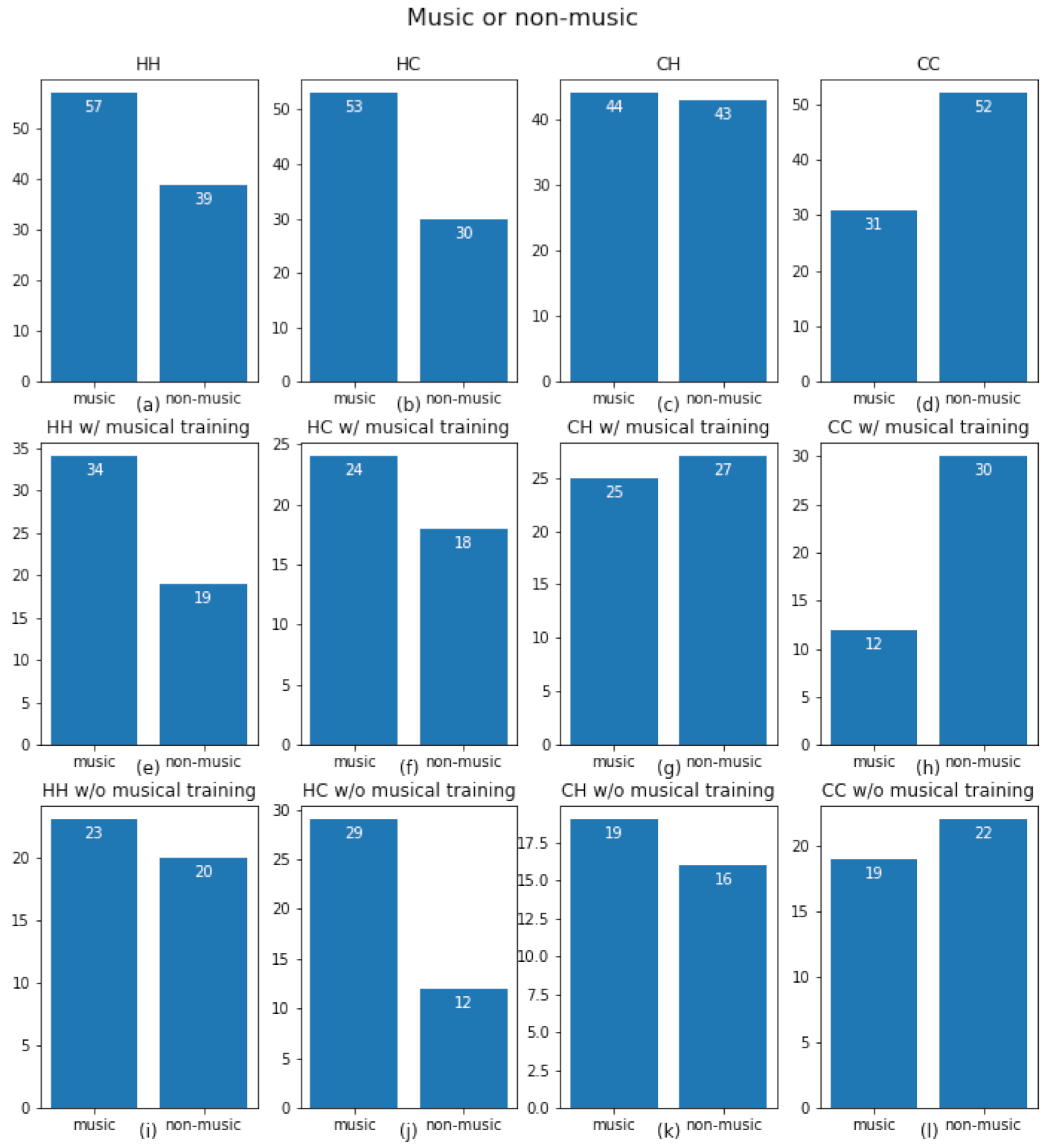{kind=link}
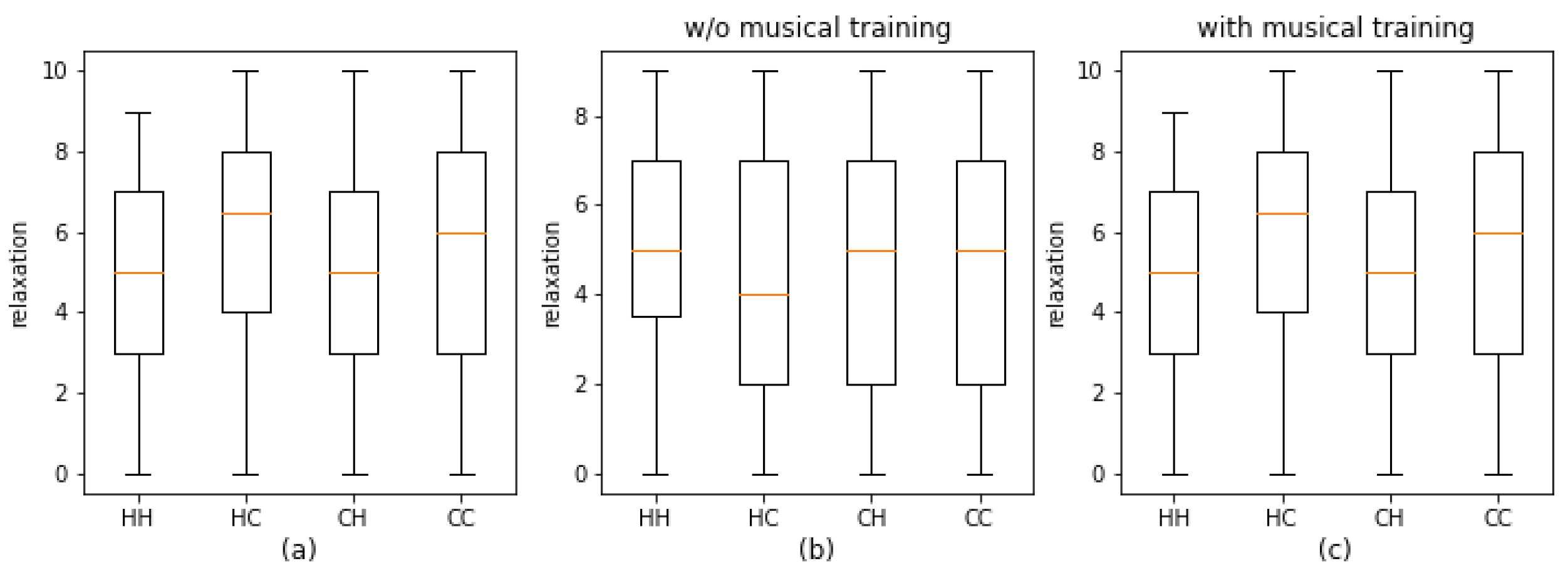{kind=link}
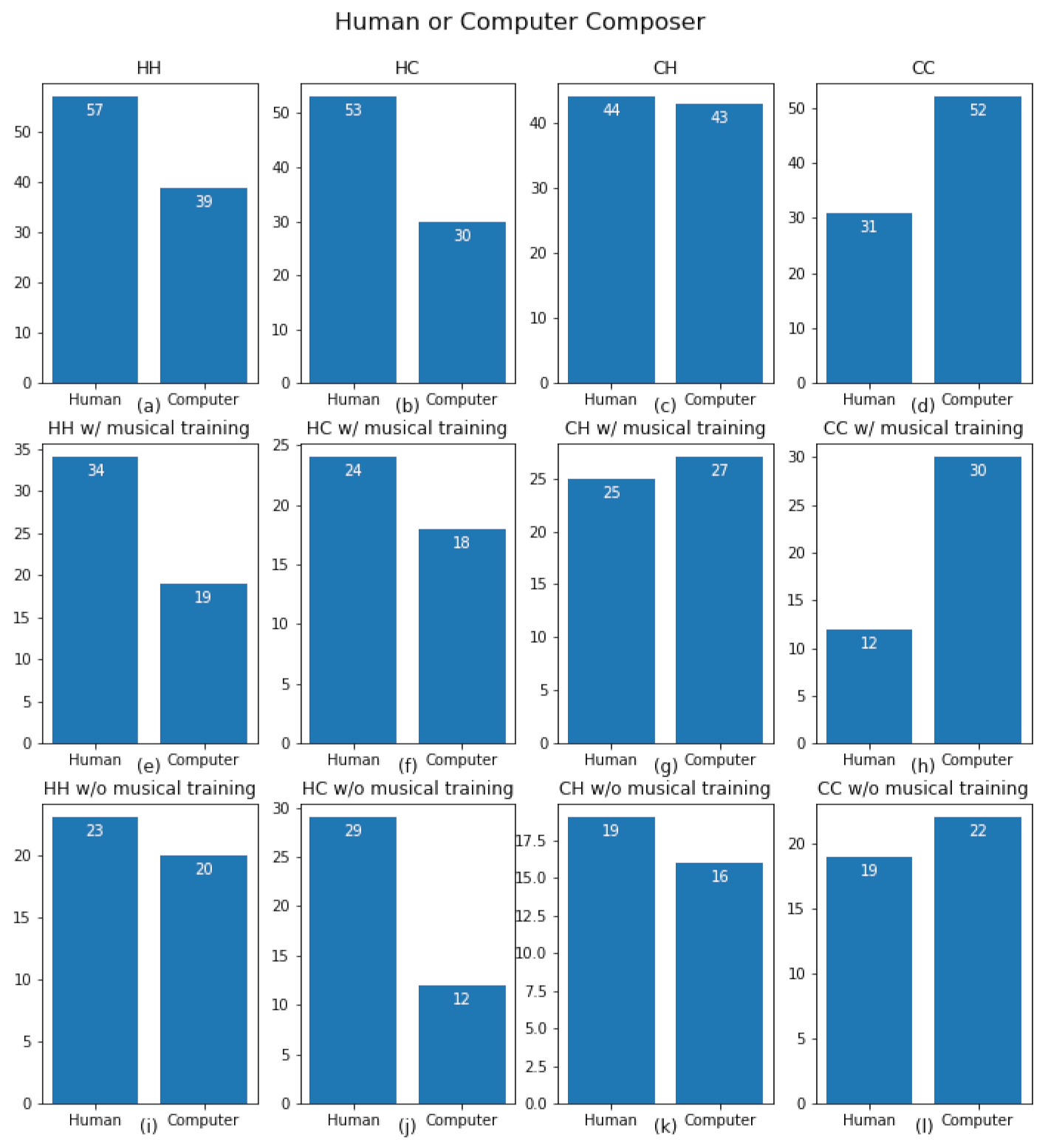{kind=link}
| Relaxation Levels | Liked the Music | Evoked Images | Evoked Emotions | |
|---|---|---|---|---|
| All subjects | 1.71 | 2.01 | 2.48 | 3.68 |
| Musical training | 2.07 | 1.80 | 1.19 | 1.07 |
| No musical training | 1.02 | 3.34 | 3.51 | 4.06 |
| All Subjects | ||||
|---|---|---|---|---|
| HH | HC | CH | CC | |
| HH | 1 | 0.28313 | 0.001 | 0.0003 |
| HC | 0.28313 | 1 | 0.05217 | 0.02241 |
| CH | 0.001 | 0.05217 | 1 | 0.79334 |
| CC | 0.0003 | 0.02241 | 0.79334 | 1 |
| With musical training | ||||
| HH | HC | CH | CC | |
| HH | 1 | 0.78885 | 0.00284 | 0.00909 |
| HC | 0.78885 | 1 | 0.03044 | 0.07029 |
| CH | 0.00284 | 0.03044 | 1 | 0.95809 |
| CC | 0.00909 | 0.07029 | 0.95809 | 1 |
| Without musical training | ||||
| HH | HC | CH | CC | |
| HH | 1 | 0.48585 | 0.1659 | 0.02745 |
| HC | 0.48585 | 1 | 0.68641 | 0.21269 |
| CH | 0.1659 | 0.68641 | 1 | 0.53559 |
| CC | 0.02745 | 0.21269 | 0.53559 | 1 |
| All Subjects | ||||
|---|---|---|---|---|
| HH | HC | CH | CC | |
| HH | 1 | 0.28313 | 0.001 | 0.0003 |
| HC | 0.28313 | 1 | 0.05217 | 0.02241 |
| CH | 0.001 | 0.05217 | 1 | 0.79334 |
| CC | 0.0003 | 0.02241 | 0.79334 | 1 |
| With musical training | ||||
| HH | HC | CH | CC | |
| HH | 1 | 0.78885 | 0.00284 | 0.00909 |
| HC | 0.78885 | 1 | 0.03044 | 0.07029 |
| CH | 0.00284 | 0.03044 | 1 | 0.95809 |
| CC | 0.00909 | 0.07029 | 0.95809 | 1 |
| Without musical training | ||||
| HH | HC | CH | CC | |
| HH | 1 | 0.48585 | 0.1659 | 0.02745 |
| HC | 0.48585 | 1 | 0.68641 | 0.21269 |
| CH | 0.1659 | 0.68641 | 1 | 0.53559 |
| CC | 0.02745 | 0.21269 | 0.53559 | 1 |
| All Subjects | ||||
|---|---|---|---|---|
| HH | HC | CH | CC | |
| HH | 1 | 0.64537 | 0.29525 | 0.00528 |
| HC | 0.64537 | 1 | 0.11102 | 0.00111 |
| CH | 0.29525 | 0.11102 | 1 | 0.11378 |
| CC | 0.00528 | 0.00111 | 0.11378 | 1 |
| With musical training | ||||
| HH | HC | CH | CC | |
| HH | 1 | 0.62849 | 0.14344 | 0.0012 |
| HC | 0.62849 | 1 | 0.50469 | 0.0153 |
| CH | 0.14344 | 0.50469 | 1 | 0.08687 |
| CC | 0.0012 | 0.0153 | 0.08687 | 1 |
| Without musical training | ||||
| HH | HC | CH | CC | |
| HH | 1 | 0.16093 | 0.8744 | 0.66243 |
| HC | 0.16093 | 1 | 0.21389 | 0.04366 |
| CH | 0.8744 | 0.21389 | 1 | 0.64532 |
| CC | 0.66243 | 0.04366 | 0.64532 | 1 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Raglio, A.; Baiardi, P.; Vizzari, G.; Imbriani, M.; Castelli, M.; Manzoni, S.; Vico, F.; Manzoni, L. Algorithmic Music for Therapy: Effectiveness and Perspectives. Appl. Sci. 2021, 11, 8833. https://doi.org/10.3390/app11198833
Raglio A, Baiardi P, Vizzari G, Imbriani M, Castelli M, Manzoni S, Vico F, Manzoni L. Algorithmic Music for Therapy: Effectiveness and Perspectives. Applied Sciences. 2021; 11(19):8833. https://doi.org/10.3390/app11198833
Chicago/Turabian StyleRaglio, Alfredo, Paola Baiardi, Giuseppe Vizzari, Marcello Imbriani, Mauro Castelli, Sara Manzoni, Francisco Vico, and Luca Manzoni. 2021. "Algorithmic Music for Therapy: Effectiveness and Perspectives" Applied Sciences 11, no. 19: 8833. https://doi.org/10.3390/app11198833
APA StyleRaglio, A., Baiardi, P., Vizzari, G., Imbriani, M., Castelli, M., Manzoni, S., Vico, F., & Manzoni, L. (2021). Algorithmic Music for Therapy: Effectiveness and Perspectives. Applied Sciences, 11(19), 8833. https://doi.org/10.3390/app11198833