
A Corpus-Based Study of Linguistic Deception in Spanish

Abstract
:Featured Application
Abstract
1. Introduction
2. Automated Deception Detection
2.1. Essentials of Linguistic Deception Detection
2.2. The Role of Linguistic Variables in the Computational Analysis of Deception
3. Description and Explanation of the Most Significant Methodologies
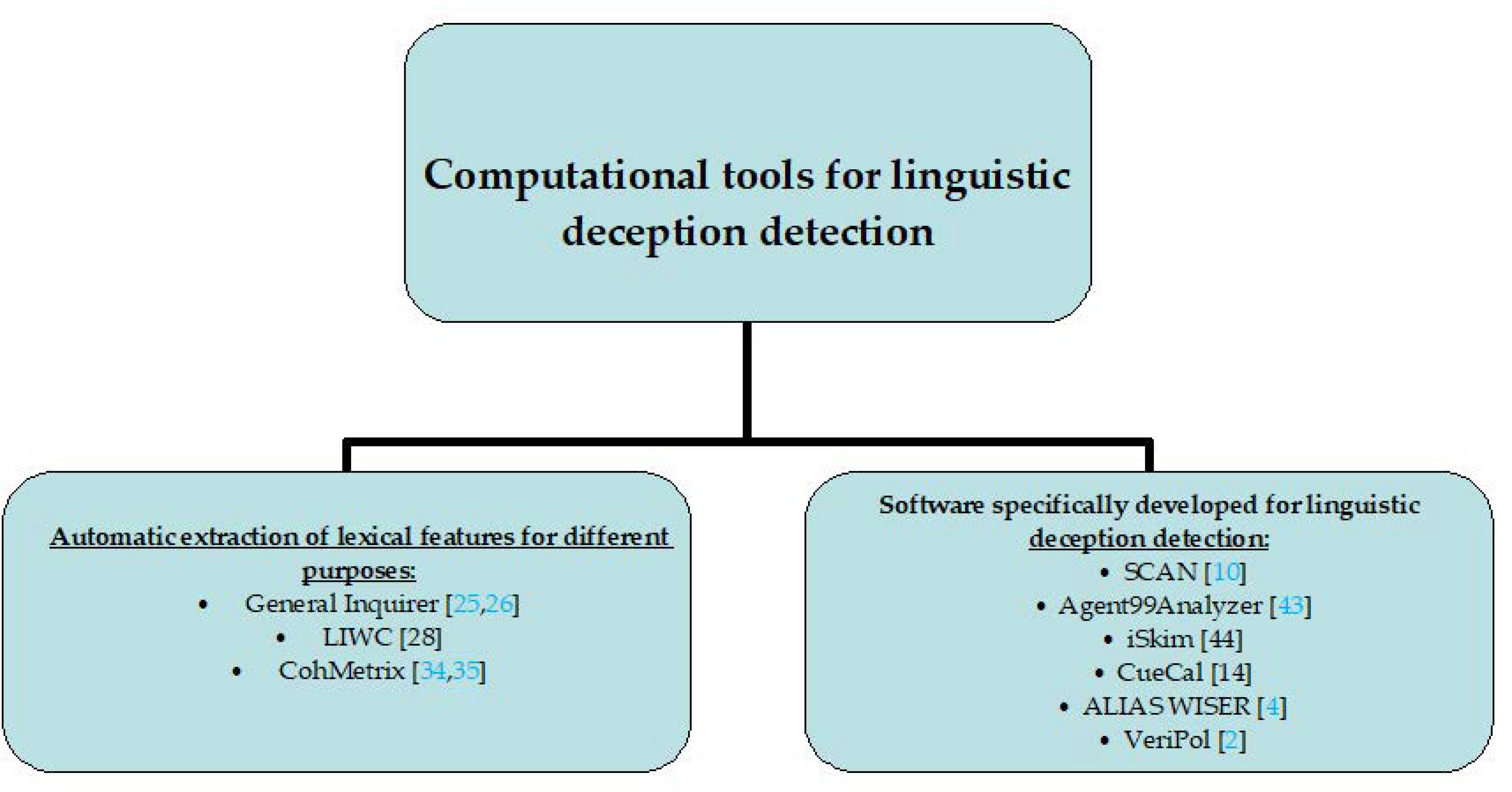
3.1. Automatic Extraction of Linguistic Features Applied to Detecting Deception
3.2. Software Developed for the Computational Classification of Written Statements as True or False
4. Materials and Methods
4.1. Contextualizing the Study
- (1)
- Regarding the variables for analysis, a fifth dimension is added to the original LIWC set, comprising some stylometric variables which have proved useful in other NLP tasks [49] (described in depth in Section 4.3.2).
- (2)
- Statistical tests are applied to the individual categories instead of the ML algorithms usually employed for automatic deception detection. Specifically, a discriminant function analysis and several logistic regressions is performed so as to assess the discriminant power of the independent variables individually, instead of testing the dimensions as a whole (described in detail in Section 4.4). This rule-based feature extraction is chosen to make the classifier more describable.
4.2. Research Question
4.3. Methodology
4.3.1. Nature of the Study
4.3.2. Variables
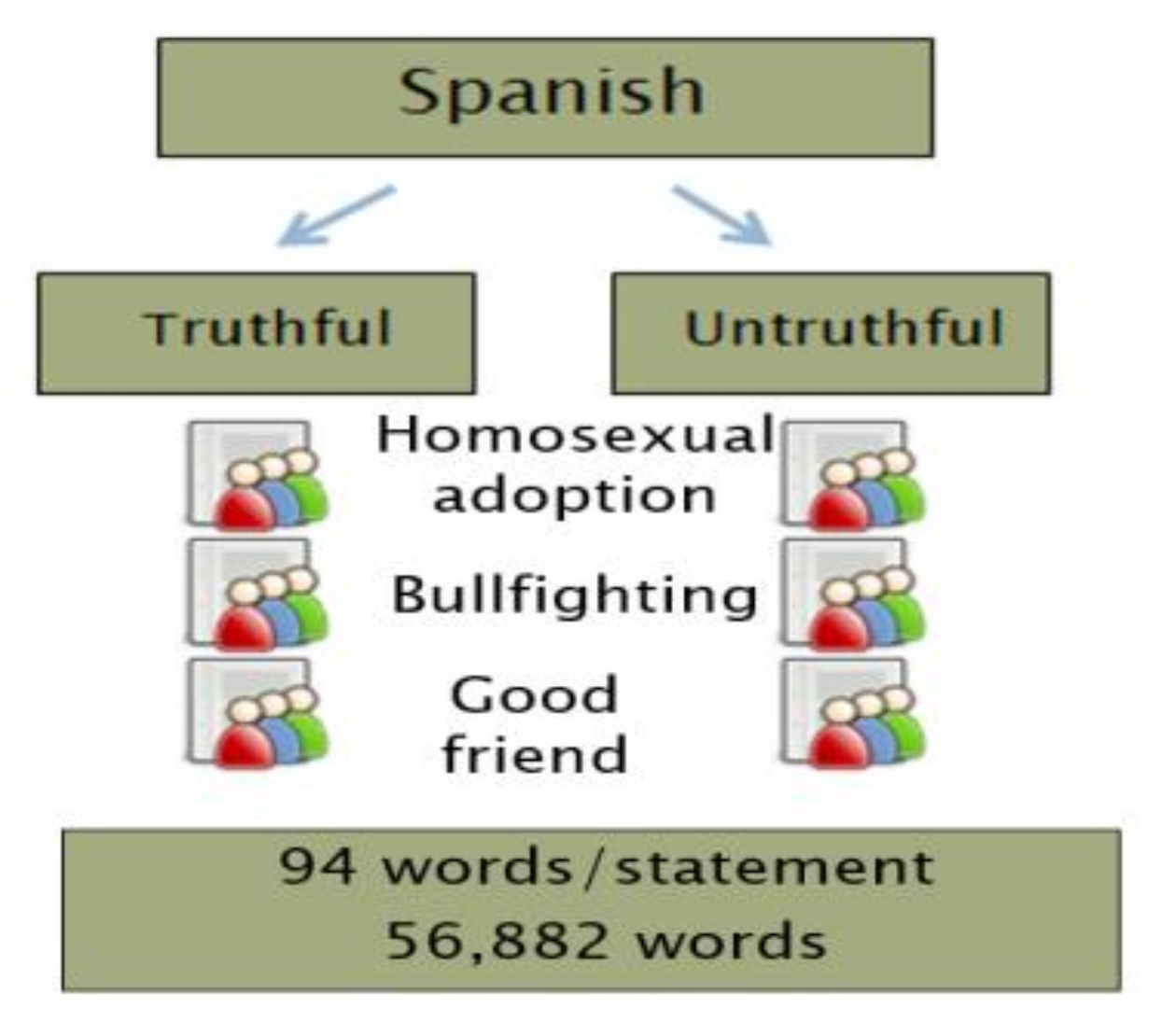
4.3.3. Corpus Description
4.4. Data Analysis
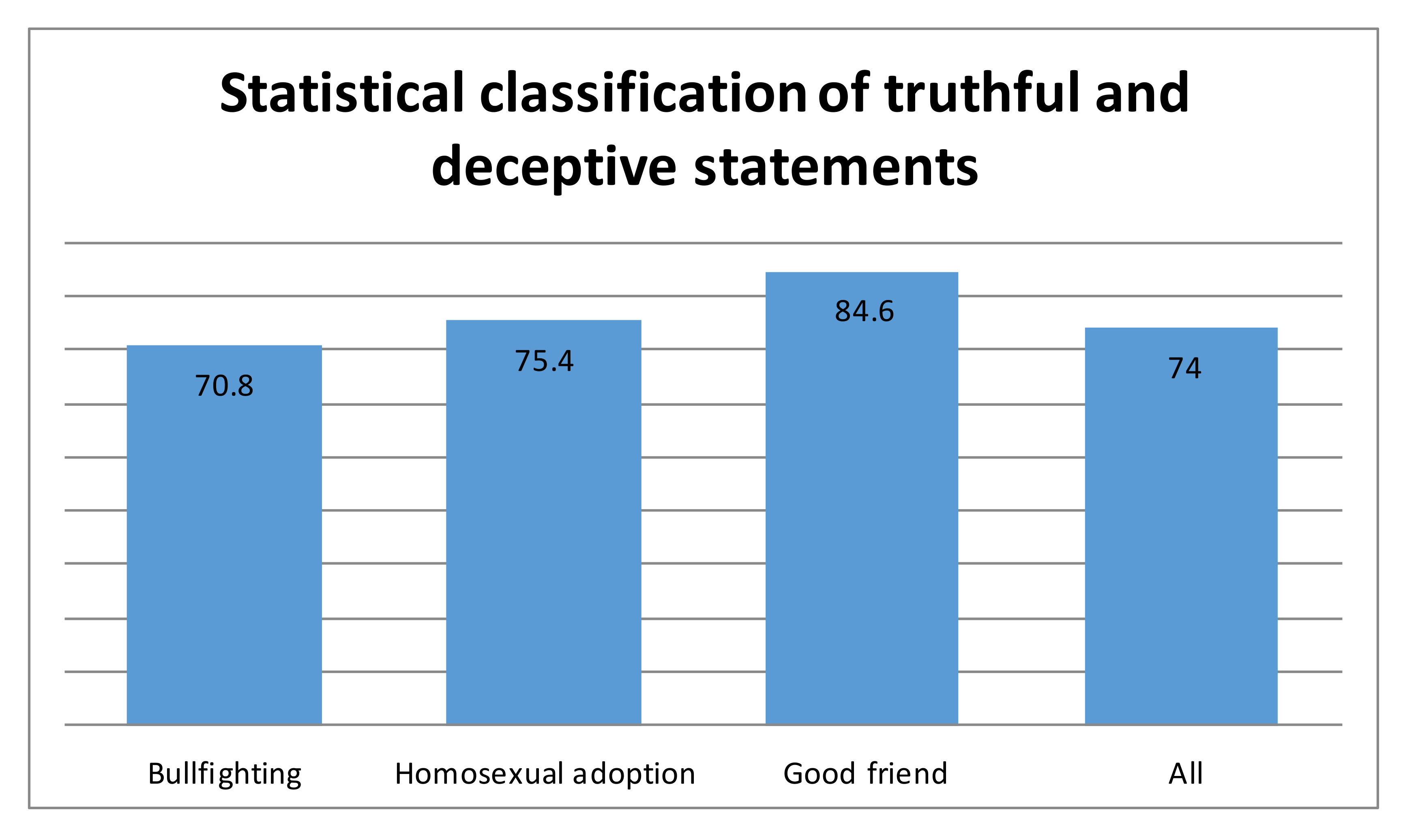
5. Results and Discussion
Qualitative Evaluation
6. Conclusions and Suggestions for Further Research
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
| I. Linguistic dimensions | ||
| TOTAL PRONOUNS | Total 1st person | 1st person singular |
| 1st person plural | ||
| Total 2nd person | - | |
| Total 3rd person | - | |
| II. Psychological processes | ||
| AFFECTIVE OR EMOTIONAL PROCESSES | Positive emotions | Positive feelings |
| Optimism and energy | ||
| Negative emotions | Anxiety or fear | |
| Anger | ||
| Sadness or depression | ||
| COGNITIVE PROCESSES | Causation | - |
| Insight | - | |
| Discrepancy | - | |
| Inhibition | - | |
| Tentative | - | |
| Certainty | - | |
| SENSORY AND PERCEPTUAL PROCESSES | Seeing | - |
| Hearing | - | |
| Feeling | - | |
| SOCIAL PROCESSES | Communication | - |
| Other references to people | 1st person plural | |
| Total 2nd person | ||
| Total 3rd person | ||
| Friends | - | |
| Family | - | |
| Humans | - | |
| III. Relativity | ||
| TIME | Past tense verb | - |
| Present tense verb | - | |
| Future tense verb | - | |
| SPACE | Up | - |
| Down | - | |
| Inclusive | - | |
| Exclusive | - | |
| IV. Personal concerns | ||
| OCCUPATION | School | - |
| Job or work | - | |
| Achievement | - | |
| LEISURE ACTIVITY | Home | - |
| Sports | - | |
| Television and movies | - | |
| Music | - | |
| Money and financial issues | - | |
| METAPHYSICAL ISSUES | Religion | - |
| Death and dying | - | |
| PHYSICAL STATES AND FUNCTIONS | Body states, symptoms | - |
| Sex and sexuality | - | |
| Eating, drinking, dieting | - | |
| Sleeping, dreaming | - | |
| Grooming | - | |
| Swearing | - | |
Appendix B
| Variables | Class |
|---|---|
| Word count | LIWC |
| Words per sentence | LIWC |
| Words longer than 6 letters | LIWC |
| Period | LIWC |
| Comma | LIWC |
| Colon | LIWC |
| Semicolon | LIWC |
| Sentences ending with ‘?’ | LIWC |
| Exclamation | LIWC |
| Dash | LIWC |
| Quote | LIWC |
| Apostrophe | LIWC |
| Parenthesis | LIWC |
| Other punctuation | LIWC |
| 1st person singular | LIWC |
| 1st person plural | LIWC |
| 2nd person | LIWC |
| 3rd person | LIWC |
| Negations | LIWC |
| Assents | LIWC |
| Articles | LIWC |
| Prepositions | LIWC |
| Numbers | LIWC |
| Positive feelings | LIWC |
| Optimism and energy | LIWC |
| Anxiety or fear | LIWC |
| Anger | LIWC |
| Sadness or depression | LIWC |
| Causation | LIWC |
| Insight | LIWC |
| Discrepancy | LIWC |
| Inhibition | LIWC |
| Tentative | LIWC |
| Certainty | LIWC |
| Seeing | LIWC |
| Hearing | LIWC |
| Feeling | LIWC |
| Communication | LIWC |
| Friends | LIWC |
| Family | LIWC |
| Humans | LIWC |
| Past tense verb | LIWC |
| Present tense verb | LIWC |
| Future tense verb | LIWC |
| Up | LIWC |
| Down | LIWC |
| Inclusive | LIWC |
| Exclusive | LIWC |
| Motion | LIWC |
| School | LIWC |
| Job or work | LIWC |
| Achievement | LIWC |
| Home | LIWC |
| Sports | LIWC |
| Television and movies | LIWC |
| Music | LIWC |
| Money and financial issues | LIWC |
| Religion | LIWC |
| Death and dying | LIWC |
| Body states, symptoms | LIWC |
| Sex and sexuality | LIWC |
| Eating, drinking, dieting | LIWC |
| Sleeping, dreaming | LIWC |
| Grooming | LIWC |
| Swearing | LIWC |
| Standardized type/token ratio | Styl. |
| Mean word length | Styl. |
| Sentences/WC | Styl. |
| 1-letter words/WC | Styl. |
| 2-letter words/WC | Styl. |
| 3-letter words/WC | Styl. |
| 4-letter words/WC | Styl. |
| 5-letter words/WC | Styl. |
| 6-letter words/WC | Styl. |
| 7-letter words/WC | Styl. |
| Complex words/WC | Styl. |
Appendix C
| TRUTH | LIE |
|---|---|
| HOMOSEXUAL ADOPTION | |
| Para mí no está clara la repercusión que tendría sobre los niños el hecho de que las parejas homosexuales adopten. Sería necesario un estudio previo de las posibles consecuencias o secuelas psicológicas, o de la ausencia de ellas, en el mejor de los casos. | La familia es y ha sido siempre la formada por un hombre y una mujer. No debemos cambiar esto, pues es un claro síntoma de la degeneración de la sociedad. Hemos de defender las tradiciones que llevan funcionando bien durante miles de años. |
| Translation into English: | Translation into English: |
| It is not clear to me what the repercussions would be for children if homosexual couples were to adopt. A prior study of the possible psychological consequences or sequelae, or the absence of them at best, would be necessary. | The family is and has always been the one formed by a man and a woman. We must not change this, as it is a clear symptom of the degeneration of society. We must defend the traditions that have been working well for thousands of years. |
| BULLFIGHTING | |
| Es una salvajada. Regodearse en el sufrimiento de un animal, disfrutar viendo cómo realiza sus últimos movimientos, agotado y herido. ¿Cómo puede ser un arte esto? Sin duda hay muchas personas que están familiarizadas con las corridas de toros.Es para ellos una situación normal. | Los espectáculos relacionados con los toros son una tradición antiquísima y un arte. Es más, los toros de lidia se pasan la vida al aire libre y son bien mimados por sus criadores, disfrutando así de una vida muchísimo mejor que la que se les ofrece a los animales de granja. |
| Translation into English: | Translation into English: |
| It is a savagery. To wallow in the suffering of an animal, to enjoy watching it make its last movements, exhausted and wounded. How can this be art? Undoubtedly, there are many people who are familiar with bullfighting. For them, it is a normal situation. | Bullfighting shows are an ancient tradition and an art. Moreover, fighting bulls spend their lives outdoors and are well pampered by their breeders, enjoying a much better life than that offered to farm animals. |
| GOOD FRIEND | |
| Cuando conocí a José María pensé que era uno más, que incluso no nos podríamos llevar bien. Qué equivocación más grande, ¡y qué afortunada! Es hoy uno de mis mejores amigos, que me encontré de casualidad en una de mis muchas andanzas por el mundo. | Sergio es un chaval inteligente, que sabe lo que quiere. Es realmente una buena persona, con la que puedes contar para todo. Su principal cualidad es su simpatía y amabilidad con todos, no importa que no te conozca de nada, siempre te da una oportunidad. |
| Translation into English: | Translation into English: |
| When I first met José María I thought he was just another guy, and that we might not even get along. What a big mistake, and how fortunate! Today he is one of my best friends, whom I met by chance in one of my many wanderings around the world. | Sergio is an intelligent guy, who knows what he wants. He is a really good person, you can count on him for everything. His main quality is his sympathy and kindness with everyone, it doesn’t matter if he doesn’t know you at all, he always gives you a chance. |
| TRUTH | LIE |
|---|---|
| HOMOSEXUAL ADOPTION | |
| Yo pienso que es un tema muy delicado y tal vez ahora mismo los hijos de parejas homosexuales podrían ser discriminados en el colegio, tendrá que cambiar la sociedad poco a poco pero aun así pienso que es importante tener un referente masculino y otro femenino en la educación de un niño. | Me gustaría decir estoy cansado de las discriminaciones que sufren las parejas homosexuales en la sociedad hoy en día. Son parejas como cualquier otra y sienten lo mismo que las demás. Por lo tanto pienso que sería correcto que pudieran adoptar ya que querrían a su hijo de la misma manera que las parejas heterosexuales. El respeto a los demás y la tolerancia es uno de los valores centrales de la educación en una familia. |
| Translation into English: | Translation into English: |
| I think it is a very delicate issue and maybe right now the homosexual couples’ children could be discriminated at school; society will have to change little by little, but I still think it is important to have a male and female reference in the education of a child. | I would like to say that I am tired of the discrimination that homosexual couples suffer in today’s society. They are couples like any other and feel the same as others. Therefore, I think it would be right for them to be able to adopt since they would love their child in the same way as heterosexual couples. Respect for others and tolerance is one of the core educational values in a family. |
| BULLFIGHTING | |
| El animal agoniza en una sopa de sangre, siente miedo, dolor, angustia, desesperación. No tiene posibilidades reales de defenderse, no tiene noción de lo que sucede a su alrededor, no tiene capacidad de razonar y por ende, de imaginarse cuándo cesarán todas esas desagradables sensaciones. El toro no lucha por su vida. Es sometido a una serie de torturas sistemáticas que lo humillan, lo denigran y lo hacen padecer infinito dolor. | Los toros y las corridas como acto o evento social me parece algo que está hace muchísimos años y da de comer a muchísimas familias, a pesar que dicen que es cruento, piensen que si se quitaran las corridas mucha gente quedaría en paro y lo más señalado es que nos comeríamos los toros igualmente, así que no es interesante el acabar con la famosa fiesta taurina y algo más, ¿toda la carne que comemos todos que pasa?¿Es sintética? |
| Translation into English: | Translation into English: |
| The animal dies in a soup of blood, feels fear, pain, anguish, despair. It has no real possibility of defending itself, it has no notion of what is happening around it, it has no capacity to reason and, therefore, to imagine when all these unpleasant sensations will cease. The bull does not fight for its life. It is subjected to a series of systematic tortures that humiliate it, denigrate it and make it suffer from infinite pain. | Bullfighting as a social act or event seems to me something that has been around for many years and feeds many families, even though they say it is cruel; think that if bullfighting were banned, many people would be unemployed, and the most important issue is that we would eat bulls anyway, so it is not interesting to ban the famous bullfighting tradition, and something else: What happens with the meat that we all eat? Is it synthetic? |
| GOOD FRIEND | |
| Mi mejor amigo es la persona con la que paso prácticamente todo mi tiempo libre. Es la persona con la que siempre puedo contar, sea cual sea el problema que tenga. Siempre solemos tener los mismos gustos y aficiones. Nos conocemos desde el colegio y a pesar de los años siempre hemos mantenido una amistad, aunque durante los dos últimos años está siendo mi prioridad.Espero que no se acabe nunca. | Mi amigo X es una de esas personas con las que siempre te lo pasas bien, tiene una gran capacidad para hacerte sentir bien y que eres especial. Es una persona muy sociable y abierta con todo el mundo.Aunque si hay una cualidad que lo distingue es su fidelidad y confianza. |
| Translation into English: | Translation into English: |
| My best friend is the person I spend practically all my free time with. He is the person I can always count on, no matter what problem I have. We always tend to have the same tastes and hobbies. We have known each other since school and, despite the years, we have always maintained a friendship, although for the last two years he has been my priority. I hope it never ends. | My friend X is one of those people with whom you always have a good time, he has a great ability to make you feel good and feel that you are special. He is a very sociable and open person with everyone. Although if there is one quality that distinguishes him it is his loyalty and trust. |
References
- Ott, M.; Choi, Y.; Cardie, C.; Hancock, J.T. Finding deceptive opinion spam by any stretch of the imagination. In Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies, Portland, OR, USA, 19–24 June 2011; pp. 309–319. [Google Scholar]
- Quijano-Sánchez, L.; Liberatore, F.; Camacho-Collados, J.; Camacho-Collados, M. Applying automatic text-based detection of deceptive language to police reports: Extracting behavioral patterns from a multi-step classification model to understand how we lie to the police. Knowl. Based Syst. 2018, 149, 155–168. [Google Scholar] [CrossRef] [Green Version]
- Vogler, N.; Pearl, L. Using linguistically defined specific details to detect deception across domains. Nat. Lang. Eng. 2019, 26, 349–373. [Google Scholar] [CrossRef] [Green Version]
- Chaski, C.E.; Almela, A.; Holness, G.; Barksdale, L. WISER: Automatically Classifying Written Statements as True or False. Oral communication presented. In Proceedings of the American Academy of Forensic Sciences 67th Annual Scientific Meeting, Orlando, FL, USA, 16–21 February 2015; pp. 576–577. [Google Scholar]
- Picornell, I. Cues to Deception in a Textual Narrative Context: Lying in Written Witness Statements. Ph.D. Dissertation, Aston University, Birmingham, UK, 2012. [Google Scholar]
- Meibauer, J. (Ed.) The Oxford Handbook of Lying; Oxford University Press: Oxford, UK, 2018. [Google Scholar]
- Markowitz, D.M.; Hancock, J.T. Deception and Language: The Contextual organization of Language and Deception (CoLD) framework. In The Palgrave Handbook of Deceptive Communication; Docan-Morgan, T., Ed.; Palgrave Macmillan: New York, NY, USA, 2019; pp. 193–212. [Google Scholar]
- Bull, R.; Cook, C.; Hatcher, R.; Woodhams, J.; Bilby, C.; Grant, T. Criminal Psychology: A Beginner’s Guide; Oneworld Publications: Oxford, UK, 2006. [Google Scholar]
- Sporer, S.L.; Manzanero, A.L.; Masip, J. Optimizing CBCA and RM research: Recommendations for analyzing and reporting data on content cues to deception. Psychol. Crime Law 2020, 27, 1–39. [Google Scholar] [CrossRef]
- Fitzpatrick, E.; Bachenko, J. Detecting Deception across Linguistically Diverse Text Types. In Proceedings of the Linguistic Society of America Annual Meeting, Boston, MA, USA, 3–6 January 2013. [Google Scholar]
- Chaski, C.E. Author Identification in the Forensic Setting. In The Oxford Handbook of Language and Law; Solan, L.M., Tiersma, P.M., Eds.; Oxford University Press: Oxford, UK, 2012. [Google Scholar]
- Chaski, C.E. Empirical Evaluations of Language-based Author Identification Techniques. Forensic Linguist. 2001, 8, 1–66. [Google Scholar] [CrossRef] [Green Version]
- Chaski, C.E. Best Practices and Admissibility of Forensic Author Identification. J. Law Policy 2013, 21, 233. [Google Scholar]
- Zhou, L.; Burgoon, J.K.; Nunamaker, J.F.; Twitchell, D. Automating linguistics-based cues for detecting deception in text-based asynchronous computer-mediated communications. Group Decis. Negot. 2004, 13, 81–106. [Google Scholar] [CrossRef]
- Mihalcea, R.; Strapparava, C. The lie detector: Explorations in the automatic recognition of deceptive language. In Proceedings of the ACL-IJCNLP 2009 Conference Short Papers, Association for Computational Linguistics, Singapore, 4 August 2009; pp. 309–312. [Google Scholar]
- Newman, M.; Pennebaker, J.; Berry, D.; Richards, J. Lying words: Predicting deception from linguistic styles. Personal. Soc. Psychol. Bull. 2003, 29, 665–675. [Google Scholar] [CrossRef]
- Almela, Á.; Alcaraz-Mármol, G.; Cantos, P.Y. Analysing deception in a psychopath’s speech: A quantitative approach. DELTA Doc. Estud. Lingüíst. Teór. Apl. 2015, 31, 559–572. [Google Scholar] [CrossRef]
- Fornaciari, T.; Poesio, M. Automatic deception detection in Italian court cases. Artif. Intell. Law 2013, 21, 303–340. [Google Scholar] [CrossRef]
- Feng, S.; Banerjee, R.; Choi, Y. Syntactic stylometry for deception detection. In Proceedings of the 50th Annual Meeting of the Association for Computational Linguistics, Association for Computational Linguistics, Jeju Island, Korea, 8–14 July 2012; pp. 171–175. [Google Scholar]
- Pérez-Rosas, V.; Mihalcea, R. Experiments in open domain deception detection. In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, Association for Computational Linguistics, Lisbon, Portugal, 17–21 September 2015; pp. 1120–1125. [Google Scholar]
- Yancheva, M.; Rudzicz, F. Automatic detection of deception in child-produced speech using syntactic complexity features. In Proceedings of the 51st Annual Meeting of the Association for Computational Linguistics, Association for Computational Linguistics, Stroudsburg, PA, USA, 4–9 August 2013; pp. 944–953. [Google Scholar]
- Almela, A.; Valencia-García, R.; Cantos, P. Seeing through Deception: A Computational Approach to Deceit Detection in Spanish Written Communication. In Proceedings of the Workshop on Computational Approaches to Deception Detection, Association for Computational Linguistics, Avignon, France, 23 April 2012; pp. 15–22. [Google Scholar]
- Rubin, V.L.; Vashchilko, T. Identification of truth and deception in text: Application of vector space model to rhetorical structure theory. In Proceedings of the Workshop on Computational Approaches to Deception Detection, Association for Computational Linguistics, Avignon, France, 23 April 2012; pp. 97–106. [Google Scholar]
- Hauch, V.; Blandón-Gitlin, I.; Masip, J.; Sporer, S.L. Are Computers Effective Lie Detectors? A Meta-Analysis of Linguistic Cues to Deception. Personal. Soc. Psychol. Rev. 2015, 19, 307–342. [Google Scholar] [CrossRef]
- Stone, P.J.; Bales, R.F.; Namenwirth, J.Z.; Ogilvie, D.M. The general inquirer: A computer system for content analysis and retrieval based on the sentence as a unit of information. Behav. Sci. 1962, 7, 484–494. [Google Scholar] [CrossRef]
- Stone, P.J.; Dunphy, D.; Smith, M.S.; Ogilvie, D.M. The General Inquirer: A Computer Approach to Content Analysis; MIT Press: Cambridge, MA, USA, 1966. [Google Scholar]
- Knapp, M.L.; Hart, R.P.; Dennis, H.S. An exploration of deception as a communication construct. Hum. Commun. Res. 1974, 1, 15–29. [Google Scholar] [CrossRef]
- Pennebaker, J.W.; Francis, M.E.; Booth, R.J. Linguistic Inquiry and Word Count; Erlbaum Publishers: Mahwah, NJ, USA, 2001. [Google Scholar]
- Pennebaker, J.W.; Graybeal, A. Patterns of natural language use: Disclosure, personality, and social integration. Curr. Dir. Psychol. Sci. 2001, 10, 90–93. [Google Scholar] [CrossRef]
- Ramírez-Esparza, N.; Pennebaker, J.W.; García, F.A.; Suriá, R. La psicología del uso de las palabras: Un programa de computadora que analiza textos en español. Rev. Mex. Psicol. 2007, 24, 85–99. [Google Scholar]
- Hunt, D.; Brookes, G. Corpus, Discourse and Mental Health; Bloomsbury Publishing: London, UK, 2020. [Google Scholar]
- Salas-Zárate, M.P.; López-López, E.; Valencia-García, R.; Aussenac-Gilles, N.; Almela, A.; Alor-Hernández, G. A study on LIWC categories for opinion mining in Spanish reviews. J. Inf. Sci. 2014, 40, 749–760. [Google Scholar] [CrossRef] [Green Version]
- Almela, A.; Alcaraz-Mármol, G.; Garcia, A.; Pallejá-López, C. Developing and Analyzing a Spanish Corpus for Forensic Purposes. LESLI Linguist. Evid. Secur. Law Intell. 2019, 3, 1–13. [Google Scholar] [CrossRef]
- Graesser, A.C.; McNamara, D.S.; Louwerse, M.M.; Cai, Z. Coh-Metrix: Analysis of text on cohesion and language. Behav. Res. Methods Instrum. Comput. 2004, 36, 193–202. [Google Scholar] [CrossRef] [Green Version]
- McNamara, D.S.; Graesser, A.C.; McCarthy, P.M.; Cai, Z. Automated Evaluation of Text and Discourse with Coh-Metrix; Cambridge University Press: Cambridge, MA, USA, 2014. [Google Scholar]
- Bedwell, J.S.; Gallagher, S.; Whitten, S.N.; Fiore, S.M. Linguistic correlates of self in deceptive oral autobiographical narratives. Conscious. Cogn. 2011, 20, 547–555. [Google Scholar] [CrossRef]
- Sapir, A. Scientific Content Analysis (SCAN); Laboratory of Scientific Investigation: Phoenix, AZ, USA, 1987. [Google Scholar]
- Lesce, T. SCAN: Deception Detection by Scientific Content Analysis. Law Order 1990, 38, 8. Available online: http://www.lsiscan.com/id37.htm (accessed on 25 November 2020).
- McClish, M. I Know You Are Lying. Detecting Deception through Statement Analysis; The Marpa Group, Inc.: Winterville, GA, USA, 2001. [Google Scholar]
- Fitzpatrick, E.; Bachenko, J.; Fornaciari, T. Automatic Detection of Verbal Deception; Morgan and Claypool Publishers: Williston, VT, USA, 2015. [Google Scholar] [CrossRef]
- Adams, S.H.; Jarvis, J.P. Indicators of veracity and deception: An analysis of written statements made to police. Speech Lang. Law 2006, 13, 1–22. [Google Scholar] [CrossRef]
- Kang, S.M.; Lee, H. Detecting deception by analyzing written statements in Korean. Linguist. Evid. Secur. Law Intell. 2014, 2, 1–10. [Google Scholar] [CrossRef]
- Fuller, C.M.; Biros, D.P.; Burgoon, J.K.; Adkins, M.; Twitchell, D.P. An analysis of text-based deception detection tools. In Proceedings of the 12th Americas Conference on Information Systems, Acapulco, Mexico, 4–6 August 2006; pp. 3465–3472. [Google Scholar]
- Zhou, L.; Booker, Q.E.; Zhang, D. ROD: Towards rapid ontology development for underdeveloped domains. In Proceedings of the 35th Hawaii International Conference on System Sciences, Honolulu, HI, USA, 10 January 2002; pp. 957–965. [Google Scholar] [CrossRef]
- Derrick, D.; Meservy, T.; Burgoon, J.; Nunamaker, J. An experimental agent for detecting deceit in chat-based communication. In Proceedings of the Rapid Screening Technologies, Deception Detection and Credibility Assessment Symposium; Jensen, M., Meservy, T., Burgoon, J., Nunamaker, J., Eds.; Grand Wailea: Maui, HI, USA, 2012; pp. 1–21. [Google Scholar] [CrossRef]
- Chaski, C.E.; Barksdale, L.; Reddington, M.M. Collecting Forensic Linguistic Data: Police and Investigative Sources of Data for Deception Detection Research. In Proceedings of the Linguistic Society of America Annual Meeting, Minneapolis, MN, USA, 2–5 January 2014. [Google Scholar]
- Harris, Z. Distributional Structure. Word 1954, 10, 146–162. [Google Scholar] [CrossRef]
- Salton, G.; McGill, M. Introduction to Modern Information Retrieval; McGraw-Hill: New York, NY, USA, 1983. [Google Scholar]
- Cantos, P.; Almela, A. Readability indices for the assessment of textbooks: A feasibility study in the context of EFL. Vigo Int. J. Appl. Linguist. 2019, 16, 31–52. [Google Scholar] [CrossRef] [Green Version]
- Shadish, W.R.; Cook, T.D.; Campbell, D.T. Experimental and Quasi-Experimental Designs for Generalized Causal Inference; Houghton Mifflin Company: Boston, MA, USA, 2002. [Google Scholar]
- Chipere, N.; Malvern, D.; Richards, B.J. Using a corpus of children’s writing to test a solution to the sample size problem affecting Type-Token Ratios. In Corpora and Language Learners; Aston, G., Bernardini, S., Stewart, D., Eds.; John Benjamins: Amsterdam, The Netherlands, 2004; pp. 139–147. [Google Scholar]
- Kline, P. A Handbook of Test Construction; Methuen: New York, NY, USA, 1986. [Google Scholar]
- Berber-Sardinha, T.; Veirano, M. (Eds.) Multidimensional Analysis; Bloomsbury Publishing: London, UK, 2019. [Google Scholar]
- Cantos, P. Statistical Methods in Language and Linguistic Research; Equinox: London, UK, 2013. [Google Scholar]
- Tabachnick, B.G.; Fidell, L.S. Using Multivariate Statistics, New International Edition, 6th ed.; Pearson Education Limited: Harlow, UK, 2013. [Google Scholar]
- Molinaro, A.M.; Simon, R.; Pfeiffer, R.M. Prediction error estimation: A comparison of resampling methods. Bioinformatics 2005, 21, 3301–3307. [Google Scholar] [CrossRef] [Green Version]
- Kohavi, R. A study of cross–validation and bootstrap for accuracy estimation and model selection. In Proceedings of the Fourteenth International Joint Conference on Artificial Intelligence; Morgan Kaufmann: San Mateo, CA, USA, 1995; pp. 1137–1143. [Google Scholar]
- DePaulo, B.M.; Lindsay, J.J.; Malone, B.E.; Muhlenbruck, L.; Charlton, K.; Cooper, H. Cues to deception. Psychol. Bull. 2003, 129, 74–118. [Google Scholar] [CrossRef]
- Masip, J.; Bethencourt, M.; Lucas, G.; Sánchez-San Segundo, M.; Herrero, C. Deception detection from written accounts. Scand. J. Psychol. 2012, 53, 103–111. [Google Scholar] [CrossRef]
- Burgoon, J.K.; Blair, J.P.; Qin, T.; Nunamaker, J.F. Detecting deception through linguistic analysis. Intell. Secur. Inform. 2003, 2665, 91–101. [Google Scholar] [CrossRef]
- Vivancos-Vicente, P.J.; García-Díaz, J.A.; Almela, A.; Molina, F.; Castejón-Garrido, J.A.; Valencia-García, R. Transcripción, indexación y análisis automático de declaraciones judiciales a partir de representaciones fonéticas y técnicas de lingüística forense. Proces. Leng. Nat. 2020, 65, 109–112. [Google Scholar]
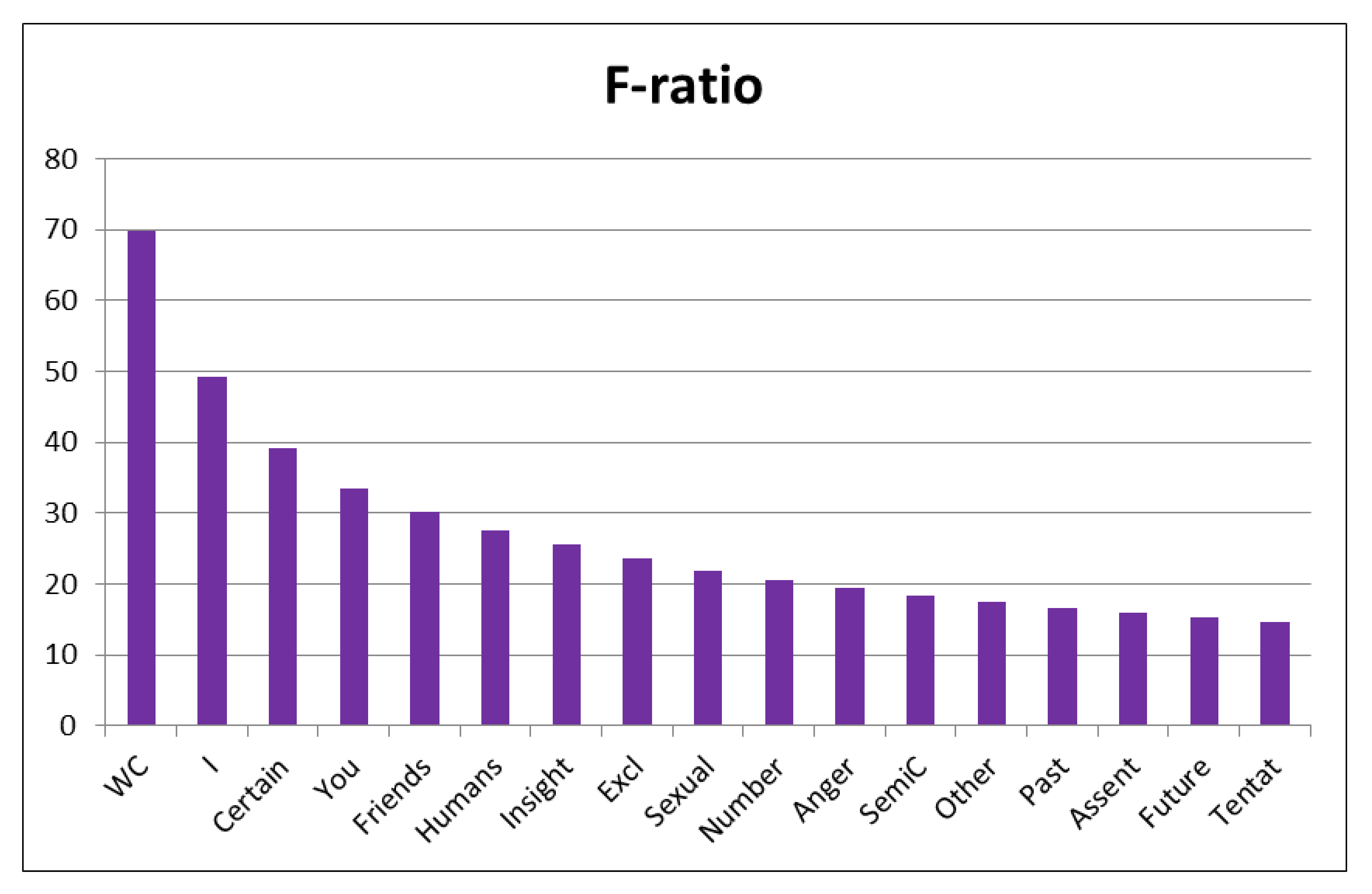
| Predictors | LIWC Abbreviation | Examples | F | Sig. |
|---|---|---|---|---|
| Word count | WC | - | 69.812 | 0.000 |
| 1st person singular | I | I, my, me | 49.259 | 0.000 |
| Certainty | Certain | always, never | 39.199 | 0.000 |
| Total second person | You | you, you’ll | 33.516 | 0.000 |
| Friends | Friends | pal, buddy, coworker | 30.167 | 0.000 |
| Humans | Humans | boy, woman, group | 27.682 | 0.000 |
| Insight | Insight | think, know, consider | 25.708 | 0.000 |
| Exclusive | Excl | but, except, without | 23.601 | 0.000 |
| Sex and sexuality | Sexual | lust, penis, suck | 21.871 | 0.000 |
| Numbers | Number | one, thirty, million | 20.568 | 0.000 |
| Anger | Anger | hate, kill, pissed | 19.397 | 0.000 |
| Semicolon | SemiC | - | 18.329 | 0.000 |
| Total third person | Other | she, their, them | 17.495 | 0.000 |
| Past tense verb | Past | walked, were, had | 16.643 | 0.000 |
| Assents | Assent | yes, OK, mmhmm | 15.909 | 0.000 |
| Future tense verb | Future | will, might, shall | 15.239 | 0.000 |
| Tentative | Tentat | maybe, perhaps, guess | 14.709 | 0.000 |
| Deception | Predicted Group Membership | Total | |||
|---|---|---|---|---|---|
| No | Yes | 1 | |||
| Original a | Count | No | 233 | 67 | 300 |
| Yes | 75 | 225 | 300 | ||
| % | No | 77.7 | 22.3 | 100.0 | |
| Yes | 25.0 | 75.0 | 100.0 | ||
| Cross-validated b | Count | No | 227 | 73 | 300 |
| Yes | 83 | 217 | 300 | ||
| % | No | 75.7 | 24.3 | 100.0 | |
| Yes | 27.7 | 72.3 | 100.0 | ||
| Bullfighting | Homosexual Adoption | Friend | All | |
|---|---|---|---|---|
| WC | T | T | T | T |
| 1st p. sing. | T | T | T | T |
| 2nd p. | U | U | ||
| 3rd p. | U | U | ||
| Semicolon | T | |||
| Number | T | T | ||
| Anxiety | T | |||
| Insight | T | |||
| Sadness | T | |||
| Friends | T | T | ||
| Humans | U | U | ||
| Posfeel | T | |||
| Certainty | U | U | ||
| Achievement | U | |||
| Inhibition | T | |||
| Assent | U | |||
| Tentative | T | |||
| Future | T | |||
| Past | T | |||
| Inclusive | U | |||
| Exclusive | T | T | ||
| Sexuality | T | |||
| Motion | U |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Almela, Á. A Corpus-Based Study of Linguistic Deception in Spanish. Appl. Sci. 2021, 11, 8817. https://doi.org/10.3390/app11198817
Almela Á. A Corpus-Based Study of Linguistic Deception in Spanish. Applied Sciences. 2021; 11(19):8817. https://doi.org/10.3390/app11198817
Chicago/Turabian StyleAlmela, Ángela. 2021. "A Corpus-Based Study of Linguistic Deception in Spanish" Applied Sciences 11, no. 19: 8817. https://doi.org/10.3390/app11198817
APA StyleAlmela, Á. (2021). A Corpus-Based Study of Linguistic Deception in Spanish. Applied Sciences, 11(19), 8817. https://doi.org/10.3390/app11198817