
A Survey on Recent Named Entity Recognition and Relationship Extraction Techniques on Clinical Texts

 ,
,
Abstract
:1. Introduction
2. Background
2.1. Machine Learning
- Supervised Learning: With these algorithms, the training data are given ground-truth labels, which can be used for learning the underlying patterns in the dataset. Classification and regression algorithms are most commonly used, including Naive Bayes [8], Support Vector Machines (SVM) [9], and Decision Trees [10].
- Semi-Supervised Learning: Here, only some of the training data is labeled, putting these solutions in a space somewhere between fully supervised and unsupervised learning. Text classification [13] is one of the most common applications for semi-supervised learning.
- Reinforcement Learning: Using a reward system, a reinforcement learning agent optimizes future returns based on prior results. This iterative, continuous learning process mirrors how humans learn from their experiences when interacting with an environment. Deep Adversarial Networks [14] and Q-Learning [15] are well known reinforcement learning algorithms.
2.2. Neural Networks
2.3. Common Evaluation Metrics
- True Positive (TP): A perfect match between the entity obtained by NER system and the ground truth.
- False Positive (FP): Entity detected by the NER system but not present in the ground truth.
- False Negative (FN): Entity not detected by the NER system but present in the ground truth.
- True Negative (TN): No match between the entity obtained by NER system and the ground truth.
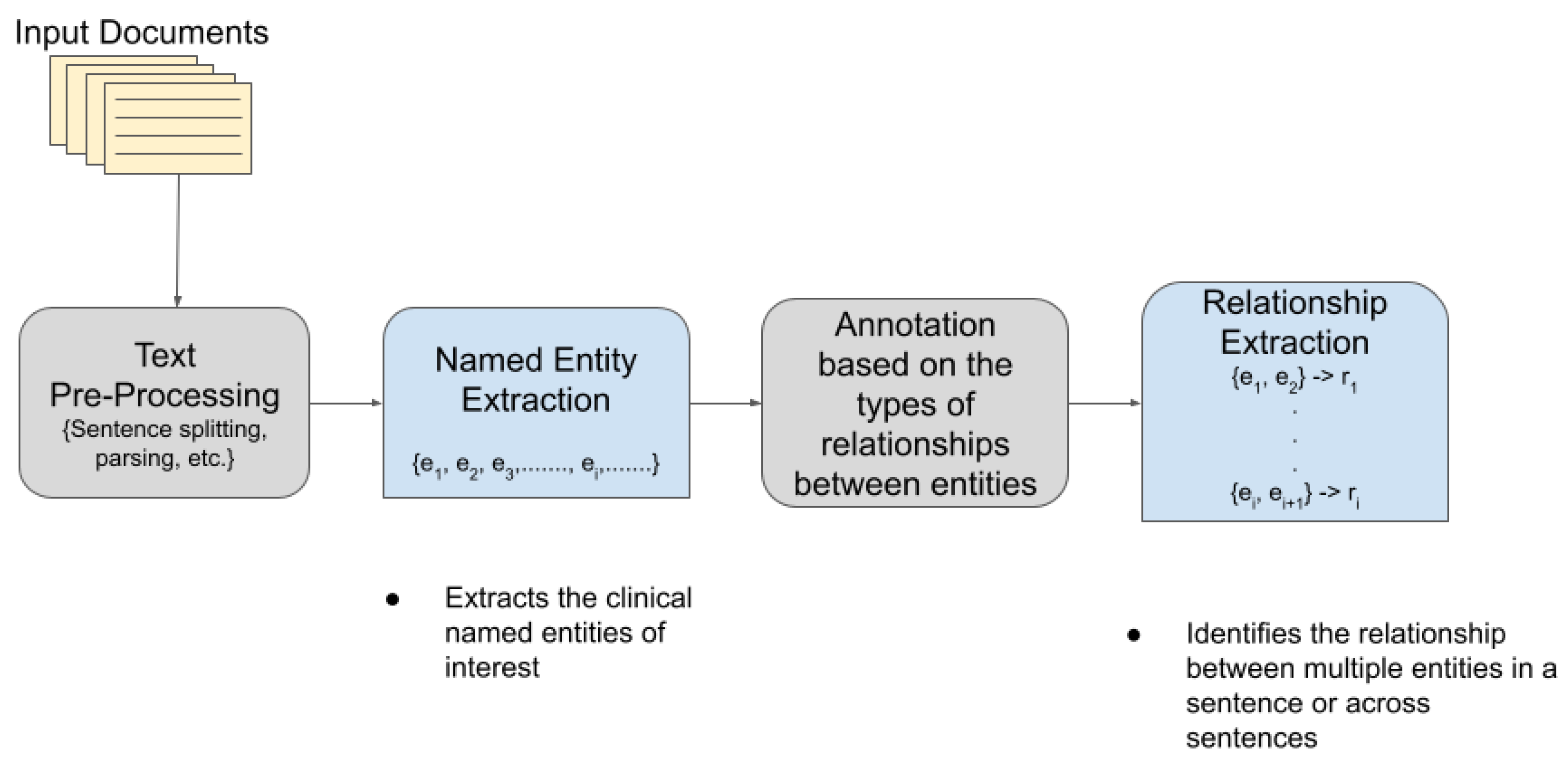
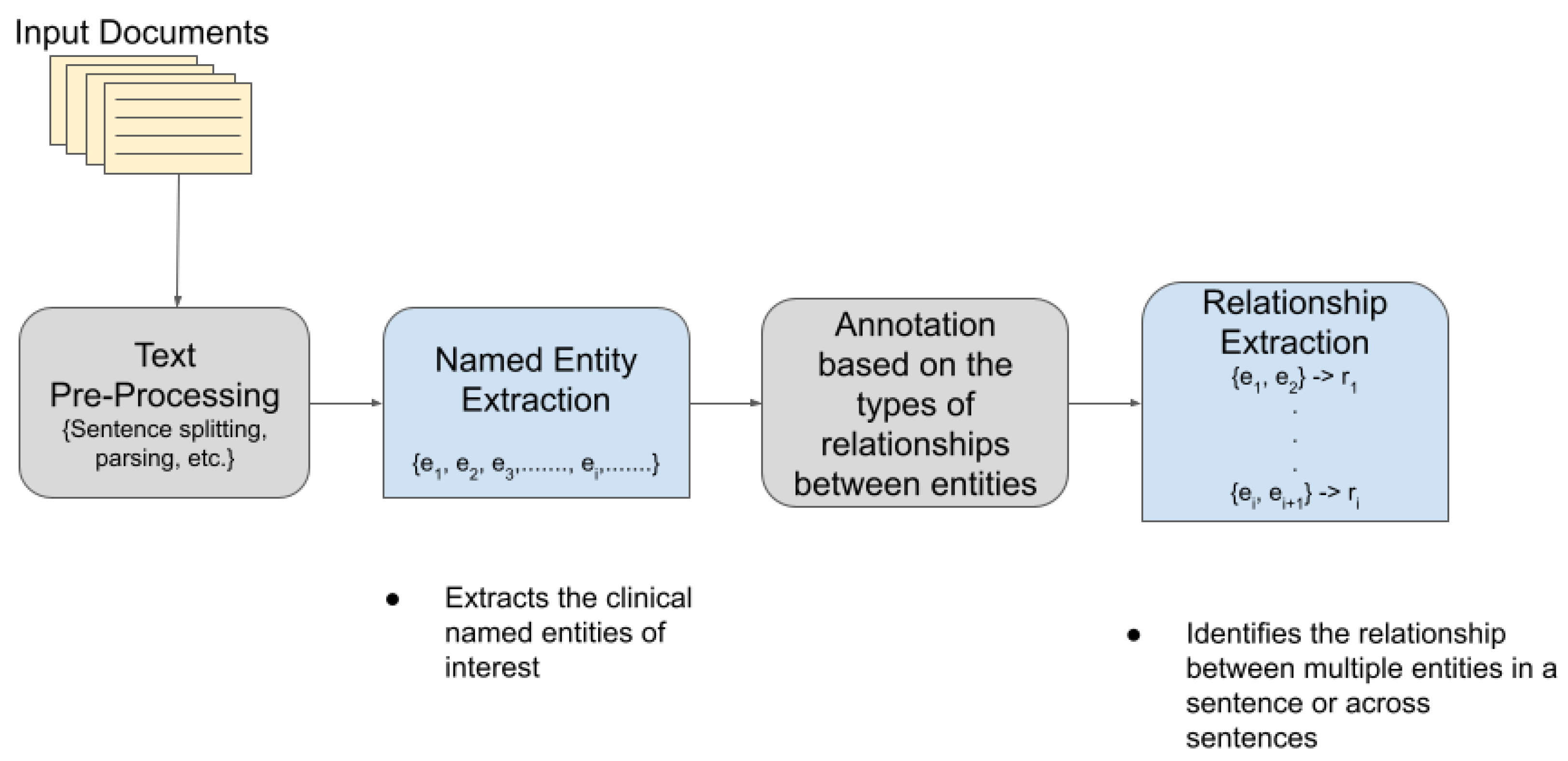
2.4. Named Entity Recognition
2.5. Relationship Extraction
2.6. Motivation
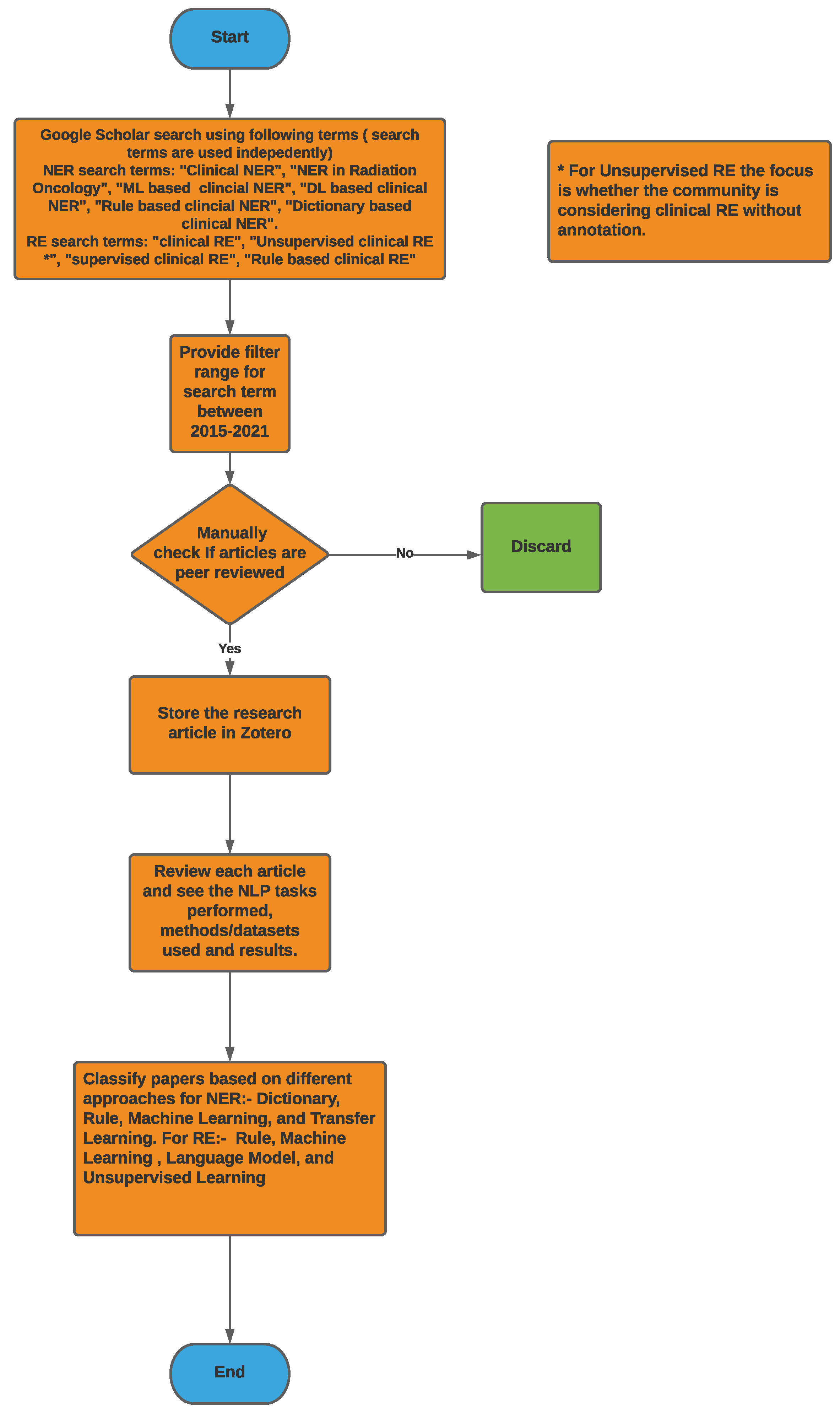
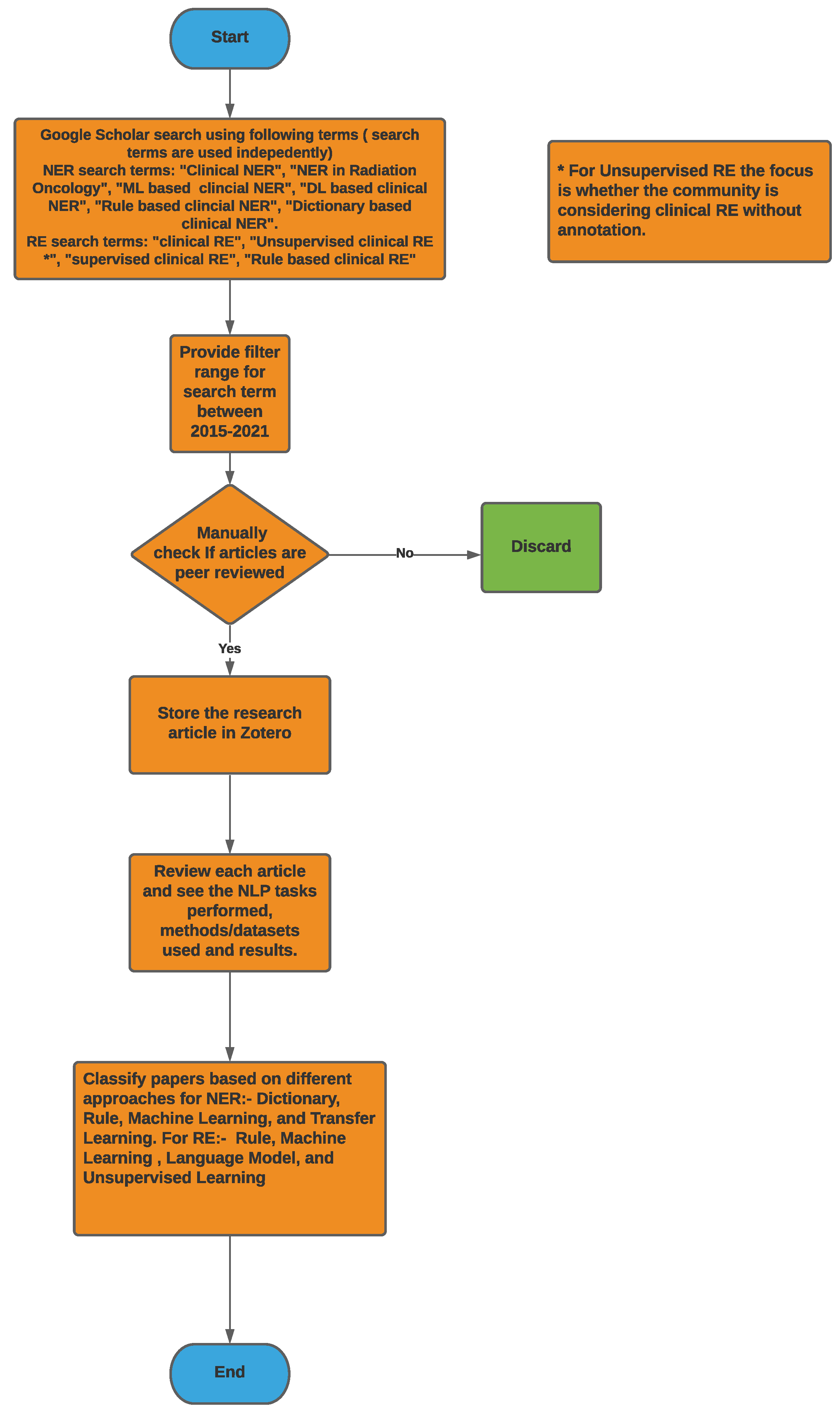
3. Methodology
4. NLP Competitions and Datasets for Clinical Text
4.1. Competitions
- 2010 i2b2/VA Challenge on Concepts, Assertions, and Relations in Clinical Text [38]: In this competition, 16 teams participated in the relationship extraction task that showed that rule-based methods can be augmented with machine learning-based methods. SVM-based supervised learning algorithm performed the best with an F1-score of 0.737 [39].
- 2011 Evaluating the state-of-the-art in co-reference resolution for electronic medical records [40]: In this competition, 20 teams participated and rule-based and machine learning-based approaches performed best, with an augmentation of the external knowledge sources (coreference clues) from the document structure. The best results on the co-reference resolution on the ODIE corpus with the ground truth concept mentions and the ODIE clinical records were provided by Glinos et al. [41], with an F1-score of 0.827. The best results on both the i2b2 and the i2b2/UPMC data were provided by Xu et al. [42], with F1-scores of 0.915 and 0.913, respectively.
- Evaluating temporal relations in clinical text, 2012 i2b2 Challenge [43]: 18 teams participated in this challenge, where for the temporal relations task, the participants first determined the event pairs and temporal relations exhibiting temporal expressions and then identified the temporal relation between them. This competition also showed that hybrid approaches based on machine learning and heuristics performed the best for the relationship classification. Rule-based pair selection with CRF and SVM by Vanderbilt University provided the best results here (F1-score: 0.69).
- 2018 n2c2 shared task on adverse drug events and medication extraction in electronic health records [44]: a total of 21 teams participated in the relationship classification task on adverse drug events (ADEs) and medication. Team UTHealth/Dalian (UTH) [45] designed a BiLSTM–CRF-based joint relation extraction system that performed the best (F1-score: 0.9630).
4.2. Datasets
- MADE1.0 Data set: This dataset consists of 1092 medical notes from 21 randomly selected cancer patients’ EHR notes at the University of Massachusetts Memorial Hospital.
- FoodBase Corpus: It consists of 1000 recipes annotated with food concepts. The recipes were collected from a popular recipe sharing social network. This is the first annotated corpora with food entities and was used by Popovski et al. [48] to compare food-based NER methods and to extract food entities from dietary records for individuals that were written in an unstructured text format.
- Swedish and Spanish Clinical Corpora [49]: This dataset consists of annotated corpora clinical texts extracted from EHRs; the Spanish dataset consists of annotated entities for disease and drugs, while the Swedish dataset has entities annotated for body parts, disorder, and findings. This dataset is mostly used for training and validation for NER on Swedish and Spanish clinical text.
- i2b2 2010 dataset [38]: This dataset includes discharge data summaries from Partners Healthcare, Beth Israel Deaconess Medical center, and University of Pittsburgh (also contributed progress reports). It consists of 394 training, 477 test, and 877 unannotated reports. All of the information are de-identified and released for challenge. These datasets are used for training and validation in many of the NER models used for clinical text.
- MIMIC-III Clinical Database [50]: This is a large and freely available dataset consisting of de-identified clinical data of more than 40,000 patients who stayed at the Beth Israel Deaconess Medical Center between 2001 and 2012. This dataset also consists of free-text notes, besides also providing a demo dataset with information for 100 patients.
- Shared Annotated Resources (shARe) Corpus [37]: This dataset consists of a corpus annotated with disease/disorder in clinical text.
- 1.
- 2010 i2b2/VA Challenge on Concepts, Assertions, and Relations in Clinical Text [38]: A wide variety of relations were identified as follows:
- Medical problem–treatment relations:
- -
- TrIP indicates that treatment improves medical problems, such as hypertension being controlled by hydrochlorothiazide.
- -
- TrWP indicates that treatment worsens medical conditions, such as the tumor growing despite the available chemotherapeutic regimen.
- -
- TrCP indicates that treatment causes medical problems, such as Bactrium possibly being a cause of abnormalities.
- -
- TrAP indicates that treatment is administered for medical problems, e.g., periodic Lasix treatment preventing congestive heart failure.
- -
- TrNAP indicates that treatment is not administered because of medical problems e.g., Relafen being contraindicated because of ulcers.
- -
- Others that do not fit into medical problem–treatment relations.
- Medical problem–test relations:
- -
- TeRP indicates that the test reveals medical problems, such as an MRI revealing a C5-6 disc herniation.
- -
- TeCP indicates that the test was conducted to investigate a medical problem, such as a VQ scan being performed to investigate a pulmonary embolus.
- -
- Others that do not fit into medical–test relations.
- Medical problem–medical problem relations:
- -
- PIP indicates any kind of medical problem such as a C5–6 disc herniation with cord compression.
- -
- Other relations with respect to medical problems that do not fit into the PIP relationship.
- 2.
- 2011 Evaluating the state-of-the-art in coreference resolution for electronic medical records [40]: The data for this challenge was similar to the 2010 i2b2/VA challenge as the dataset contained two separate corpora, i.e., the i2b2/VA corpus and the Ontology Development and Information Extraction (ODIE) corpus, which contained de-identified clinical reports, pathology reports, etc.
- 3.
- Evaluating temporal relations in clinical text, 2012 i2b2 Challenge [43]: The temporal relations or links in the dataset indicate how two events or two time expressions or an event and a time expression is related to each other. The possible links annotated in the dataset were BEFORE, AFTER, SIMULTANEOUS, OVERLAP, BEGUN_BY, ENDED_BY, DURING, and BEFORE_OVERLAP.Ex: OVERLAP -> She denies any fever or chills.Ex: ENDED_BY -> His nasogastric tube was discontinued on 05-26-98.
- 4.
- 2018 n2c2 shared a task on adverse drug events and medication extraction in electronic health records [44]: The different relations identified between two entities in this case are either of the following types: Strength–Drug, Form–Drug, Dosage–Drug, Frequency–Drug, Route–Drug, Duration–Drug, Reason–Drug, and ADE–Drug.
5. Discussion on Clinical Named Entity Recognition
- Physical Exam: This section can have both structured and unstructured information such as toxicity and review of systems, where we try to store information such as dizziness, cough, and rectal bleeding.
- Past Medical History: This has all of the allergy information, medications, prior military service, prior surgery information, and prior diseases for patients and is mostly stored as unstructured free text.
- Oncologic History: This includes all of the prior oncologic information in unstructured format and varies based on the types of cancer.
- Diagnostic Test: Various tests may be performed on patients and vary based on cancer types. They are mostly in structured format; however, some tests may be specific to patients that can be documented and stored in unstructured free text format such as Bone Scan and CT Pelvis.
5.1. Challenges in Clinical NER
- Nested Entities and Ambiguity: Most clinical terms are often confusing as there is no common ontology. Physicians often use abbreviations or acronyms, which makes it very difficult to standardize clinical text. In the radiation oncology domain, a common challenge is that physicians dictate their clinical assessment based on the style they were trained in and it varies significantly for different types of cancers, which makes it very difficult to develop a standard NER model for processing radiation oncology notes that cater to all of the different types.
- Meaning of Context: The clinical terms used can have different meanings, which vary based on the context. Although this problem mostly applies to non-clinical notes, for clinical NER, this becomes more challenging as the model should understand the complete clinical context along with the entity. A common issue is negative medical findings, where text is written in such a manner that it reports findings in a negative context; however, the NER considers that as a positive.
5.2. Clinical NER Methods
- Dictionary-Based Approach: In this approach, a predefined set of named entities are defined that are later used as a lookup while parsing the clinical text for entities. For example, Savova et al. [46] used a dictionary-based approach to detect NERs from clinical text using their NLP toolkit.
- Rule-Based Approach: Here, the rules/entities are predefined by domain experts. Most of the rules are handcrafted and are used to detect entities in a specific text. The limitation of this approach is generalizability or extensibility, as most of them are applicable to the domain they were defined in. This approach certainly requires a lot of effort where experts spend time defining the entities, and then, it is used as a lookup while parsing the clinical notes.
- Machine Learning-Based Approach: The purpose of this approach is to completely automate the NER process. Commonly used ML algorithms such as Random Forest (RE), Support Vector Machines (SVMs), and Neural Networks (NN) are used to learn the pattern (entities and boundaries) using the training set. Once the training is over, the model can classify the clinical text into predefined classes. This approach is garnering much attention due to recent advancements in ML and the easy availability of computational resources. The majority of the articles collected for this survey used this approach.
- Conditional Random Field (CRF)-Based Approach: The CRF approaches fall under the ML category and mostly solve a label sequencing problem, where for a given input sequence , CRF tries to find the best label sequence . At first, the entities are annotated with tags; in general, the BIO (Beginning, Inside, and Outside of Entity) schema is used for annotation, where each word is assigned to a label. The input for CRF models is mostly designed by humans and represented as a bag-of-words style vector. Wu et al. [4] introduced seven tags and three CRF baselines using different features. All of the commonly used CRF-based implementations in clinical NER can be found in the CRF++ package. In Table A1 and Table A2, we observe that there are many models using CRFs for NER with good accuracy.
- Deep Learning-Based Methods: This is similar to the CRF label sequencing problem using the BIO schema, where the input is a raw sequence of words. An added layer performs the word embedding by converting words into densely valued vectors. In the training phase, it learns the dependencies and features to determine entities. Deep learning methods are very popular for clinical NER as they achieve state-of-the-art results and can also detect hidden features automatically. The first neural network architecture for NER was proposed by Collobert et al. [19], with a convolution layer, several standard layers, and a non-linear layer. This architecture achieved state-of-the-art performance in clinical NER. Details on the CNN model for clinical NER can be found in [17]. New studies have recently shown that RNNs (Recurrent Neural Networks) perform much better than CNNs and are capable of capturing long-term dependencies for sequence data. Lample et al. [55] introduced Long Short-Term Memory (LSTM), a popular implementation of RNN architecture, for this problem. Wu et al. [4] evaluated the performance of CNNs, RNNs, and CRFs with different features and concluded that the RNN implementation outperformed the other two.
- Hybrid Approaches: here, any of the above approaches are combined and then used to determine entities.
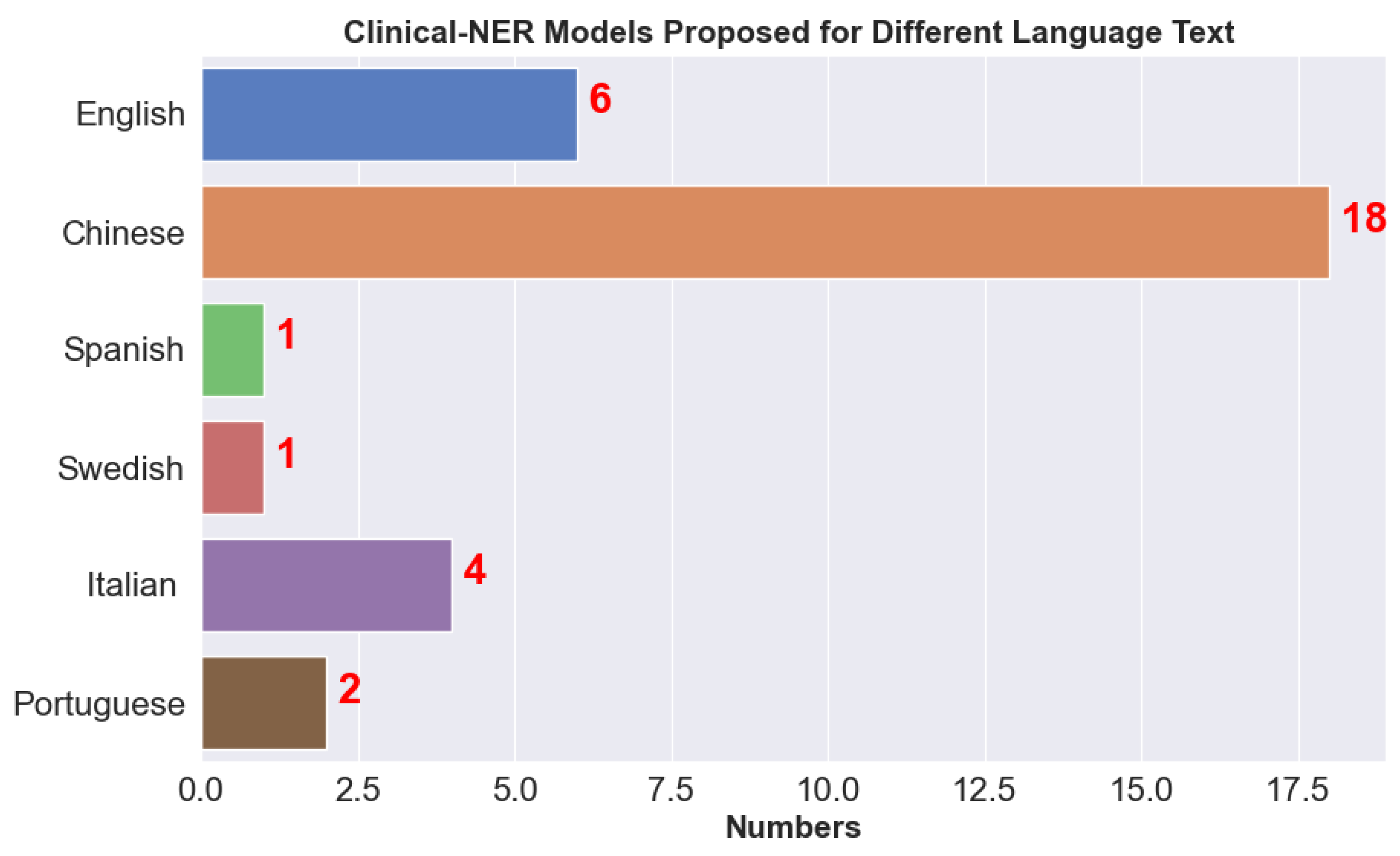
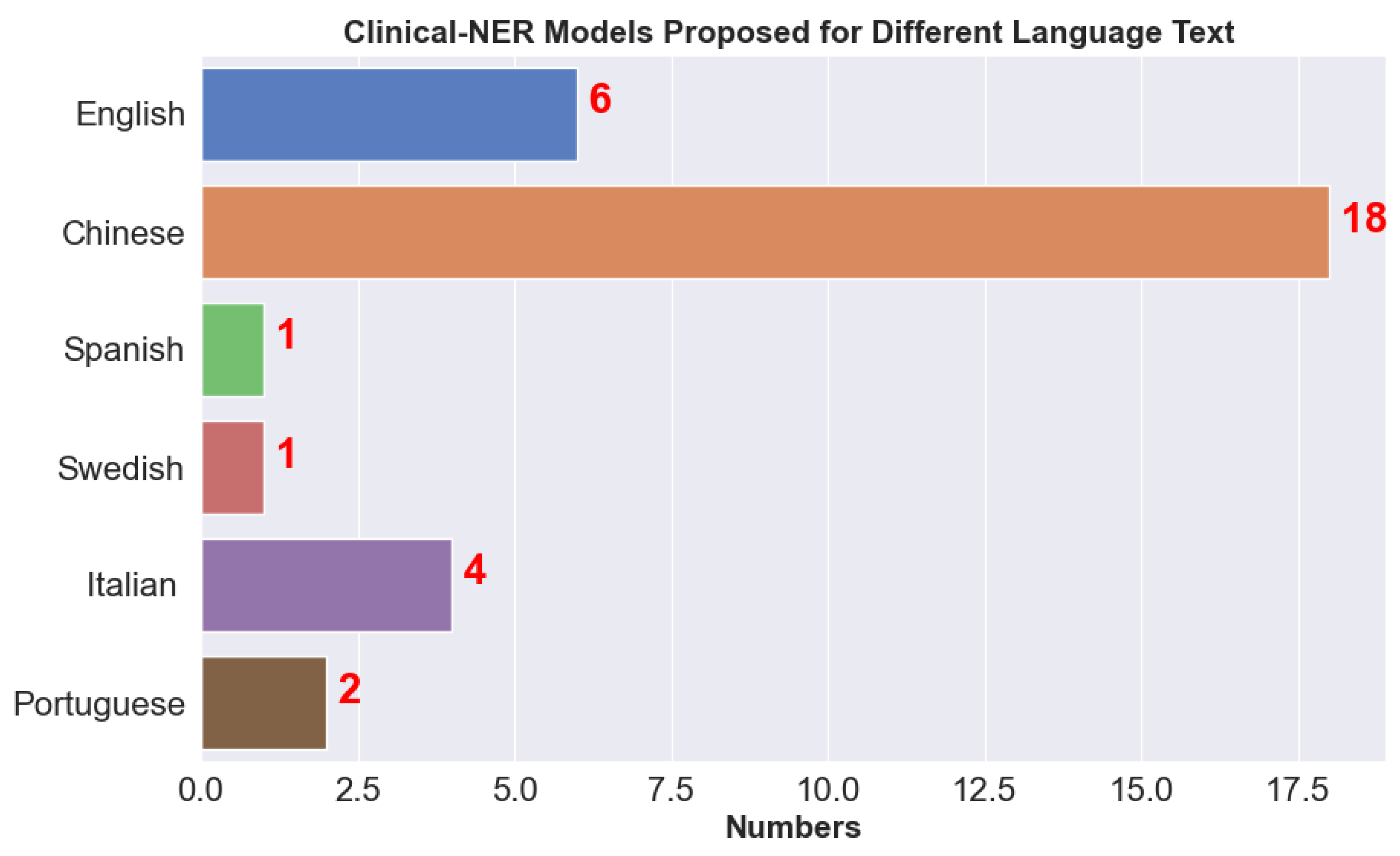
5.3. Clinical NER Models
- Savova et al. [46] proposed a dictionary look up algorithm, where each named entity is mapped to a terminology. The dictionary was constructed using the terms from UMLS, SNOMED CT, and RxNORM. This implementation also involves a parser in which the output is used further to search for noun phrases. The limitation of this implementation is that it fails to resolve ambiguities while working with results from multiple terms in the same text. They datasets for NER are derived from Mayo clinic EMR. For exact and overlapping matches F1-score reported were 0.715 and 0.824 respectively.
- Skeppstedt et al. [56] used CRF model and a rule-based approach to detect NER on Swedish health records and identified four entities: Drug, Finding, Disorder, and Body structure. They also compared it on English clinical text. They reported precision and recall for all of their findings: 0.88 and 0.82 for body structure, 0.80 and 0.82 for disorders, 0.72 and 0.65 for findings, and 0.95 and 0.83 for pharmaceutical drugs.
- Chen et al. [57] developed a rule-based NER system that was designed to detect patients for clinical trial. They used the n2c2-1 challenge dataset for training and achieved an F1-score of 0.90.
- Eftimov et al. [48] developed a rule-based approach to detect extraction of food, nutrient, and dietary recommendations from text. They discussed four methods FoodIE, NCBO, NCBO (OntoFood), and NCBO(FoodON). Based on their comparison, they identified that FoodIE performs well. Their model was trained on the FoodBase Corpus and was able to identify entities from dietary recommendation.
- Xu et al. [58] developed a joint model based on which CRF performs word segmentation and NER. Generally, both systems are developed independently, but the joint model used to detect Chinese discharge summaries performed well. There was no score reported in this publication; they only reported that the joint model performance is better when they compared it with the two individual tasks.
- Magge et al. [59] developed an NLP pipeline, which processed clinical notes and performed NER using bi-directional LSTM coupled with CRF in the output layer. They used 1092 notes from 21 cancer patients, from which 800 notes were used for NER training. They reported NER precision, recall, F1-score for the entities individually and reported a macro-averaged F1-score of 0.81.
- Nayel et al. [60] proposed a novel ensemble approach using the strength of one approach to overcome the weakness of other approaches. In their proposed two-stage approach, the first step is to identify base classifiers using SVM, while in the second phase, they combined the outputs of base classifiers based on voting. They used the i2b2 dataset and reported an F1-score of 0.77.
- Wu et al. [4] performed a comparison study between two well-known deep learning architectures, CNN and RNN, with three other implementations: CRFs and two state-of-the-art NER systems from the i2b2 2010 competition to extract components from clinical text. The comparison created a new state-of-the art performance for the RNN model and achieved an F1-score of 85.94%.
- Wang et al. [61] proposed a model to study symptoms from Chinese clinical text. They performed an extensive set of experiments and compared CRF with HMM and MEMM for detecting symptoms. They also used label sequencing and the CRF approach outperformed the other methods.
- Yadav et al. [17] provided a comprehensive survey of deep neural architectures for NER and compared it with other approaches including supervised and semi-supervised learning algorithms. Their experiments showed good performance when they include neural networks, and they claim that integrating neural networks with earlier work on NER can help obtain better results.
- Vunikili et al. [51] used Bidirectional Encoder Representations from Transformers (BERT) [62] and Spanish BERT (BETO) [63] for transfer learning. This model is used to extract tumor information from clinical reports written in Spanish. They reported an F1-score of 73.4%.Jiang et al. [64] developed ML-based approaches to extract entities such as discharge summaries, medical problems, tests, and treatment from the clinical text. They used a dataset comprising 349 annotated notes for training and evaluated their model on 477 annotated notes to extract entities. They reported an F1-score of 0.83 for concept extraction.
- Yang et al. [65] proposed a deep learning model to extract family history, and they compared LSTM, BERT, and ensemble models using a majority voting.
5.4. Clinical NER Evaluation Metrics
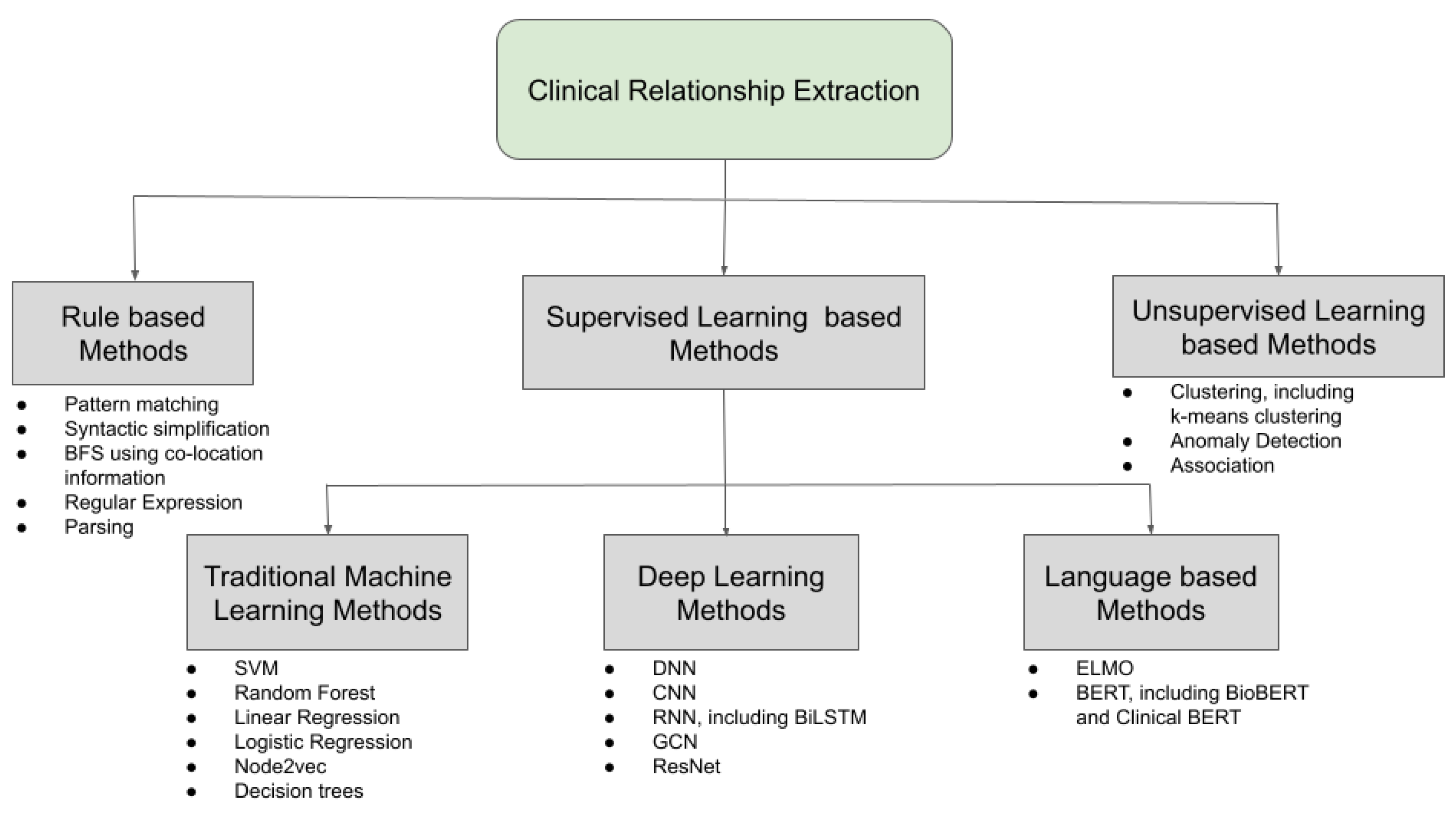
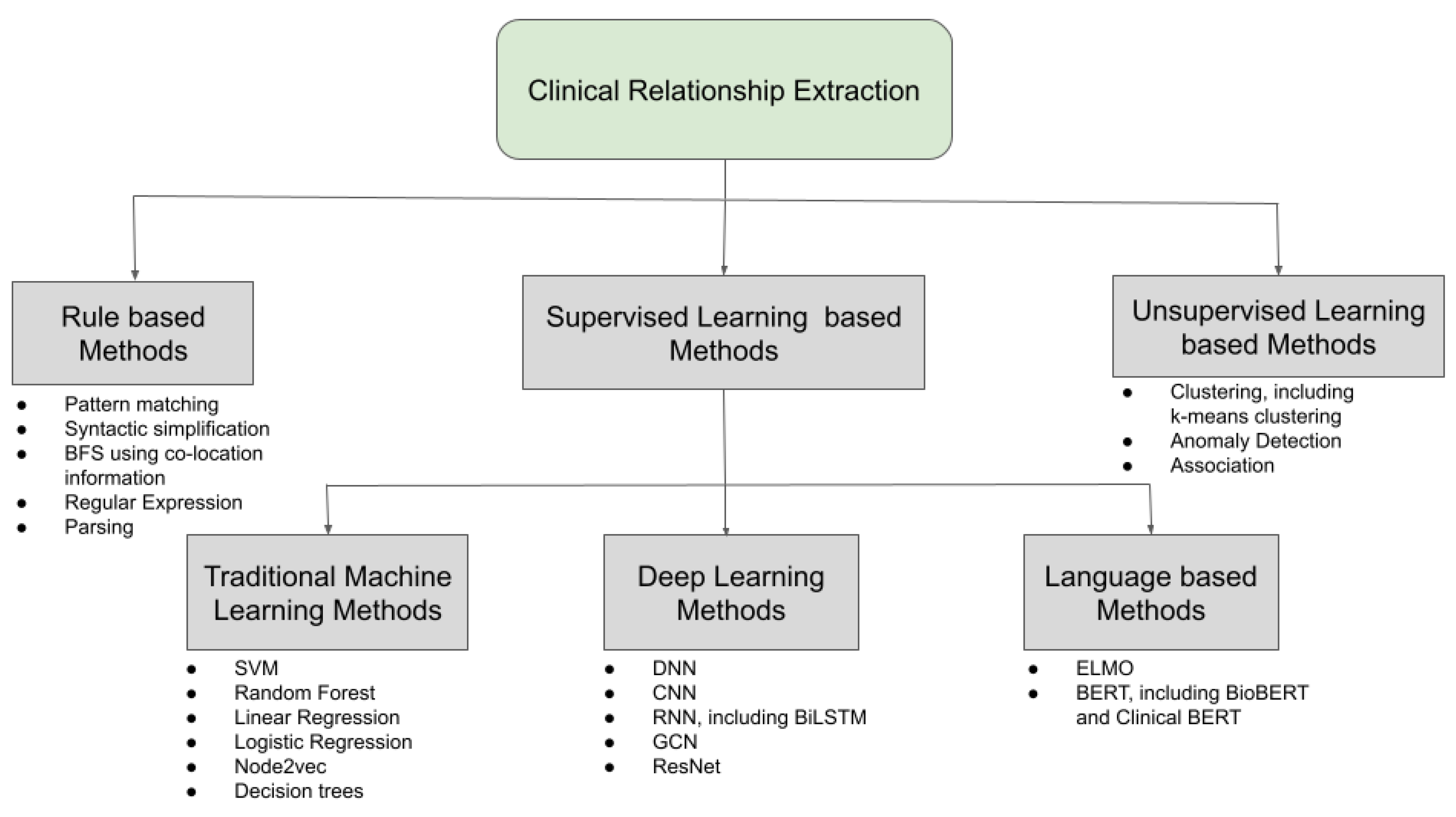
6. Discussion on Clinical Relationship Extraction
6.1. Feature Generation
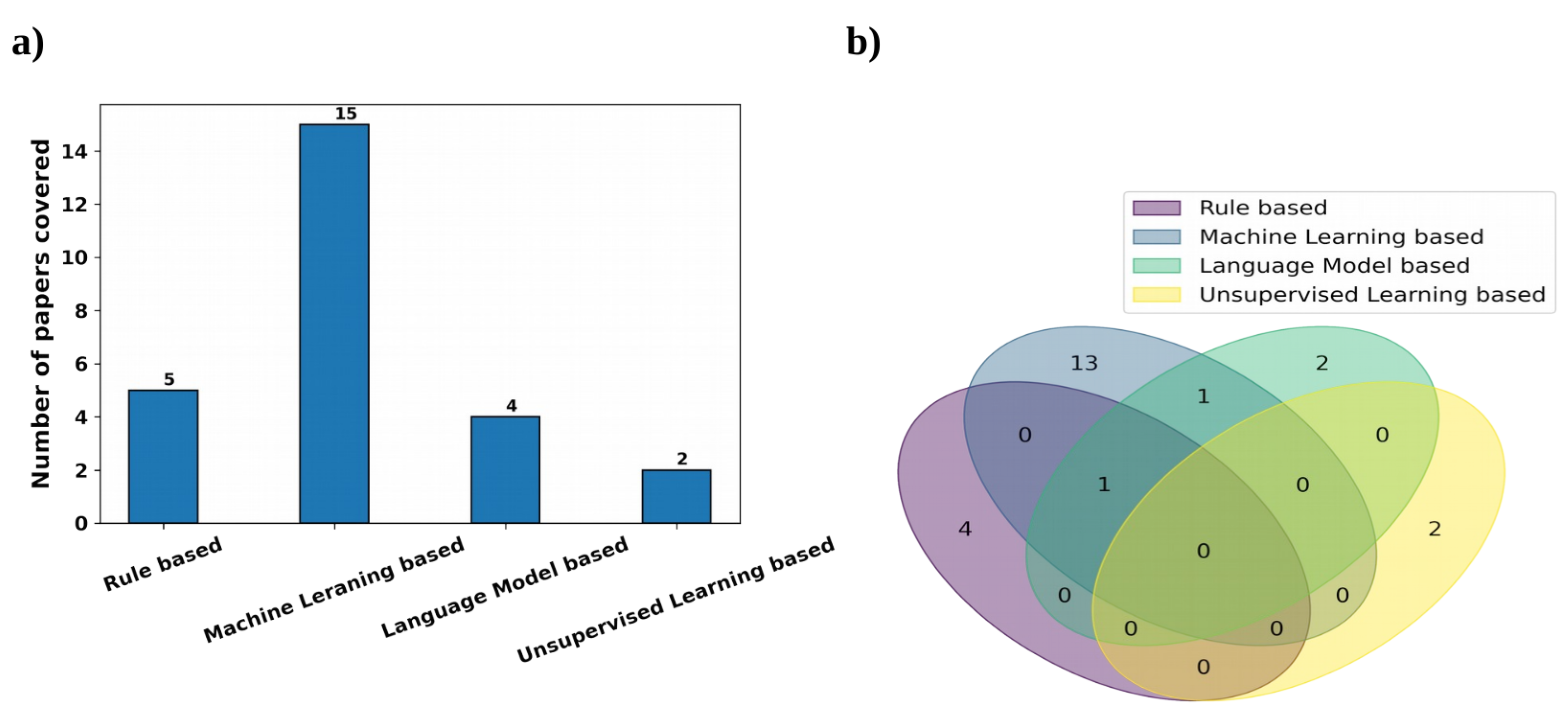
6.2. Rule-Based Methods
6.3. Supervised Learning Methods
6.3.1. Traditional Machine Learning and Deep Learning-Based Methods
6.3.2. Language Model-Based Methods
6.4. Unsupervised Learning Methods
7. Trends and Future Research Directions
8. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| IDC | International Data Corporation |
| TM | Text Mining |
| NLP | Natural Language Processing |
| NE | Named Entity |
| NER | Named Entity Recognition |
| RE | Relationship Extraction |
| ML | Machine Learning |
| AI | Artificial Intelligence |
| EHR | Electronic Health Record |
| WEKA | Waikato Environment for Knowledge Analysis |
| CLAMP | Clinical Language Annotation, Modeling, and Processing |
| AWS | Amazon Web Services |
| EU | European Union |
| HIPAA | Health Insurance Portability and Accountability Act |
| n2c2 | National NLP Clinical Challenges |
| i2b2 | Informatics for Integrating Biology and the Bedside |
| NIH | National Institutes of Health |
| NCBC | National Centers for Biomedical Computing |
| EMR | Electronic Medical Record |
| SVM | Support Vector Machine |
| RF | Random Forest |
| NN | Neural Network |
| CRF | Conditional Random Field |
| ME | Maximum Entropy |
| BERT | Bidirectional Encoder Representations from Transformers |
| BETO | SPanish BERT |
| BIO | Beginning, Inside, Outside of Entity |
| POS | Parts of Speech |
| BFS | Breadth First Search |
| CNN | Convolutional Neural Network |
| RNN | Recurrent Neural Network |
| LSTM | Long Short Term Memory |
| GCN | Graph Convolutional Network |
| CDT | Concept Dependency Tree |
| GNN | Graph Neural Network |
| TP | True Positive |
| TN | True Negative |
| FP | False Positive |
| FN | False Negative |
| ROC | Receiver Operator Characteristic |
| AUC | Area Under the Curve |
| ODIE | Ontology Development and Information Extraction |
| ADE | Adverse Drug Events |
| PHI | Personal Health Information |
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Publication | Task | Methods | Performance |
|---|---|---|---|
| Savova et al. [46] | Extraction of entities from EMR using NLP tools | Dictionary look-up algorithm | Conducted multiple performance evaluation on different NLP tasks; for NER, the F1-scores reported were 0.71 (exact match) and 0.82 (overlapping matches). |
| Skeppstedt et al. [56] | Detecting disorders, findings, and body structures from Swedish clinical text | Rule-based and CRF approach | Precision and recall for detecting body structure are 0.88 and 0.82, respectively, while for disorder, they were reported as 0.72 and 0.65; for finding, they are 0.72 and 0.65; and for drug, they are 0.95 and 0.83 |
| Chen et al. [57] | Detecting patients who are qualified for clinical trial | Rule-Based approach using knowledge input defined by lexical, syntactic, or meta-level tasks | F1-score reported was 0.90 |
| Eftimov et al. [48] | Extraction of food entity, nutrient entity, and quantity/unit from dietary recommendations | Rule-based approach | TP for food, nutrient, and quantity was reported as 538, 557, and 86. FN for food, nutrient, and quantity was reported as 25, 17, 11. FP for food, nutrient, and quantity was reported as 5, 2, and none. |
| Xu et al. [58] | Combined Segmentation and NER on Chinese text | CRF using three features | 96% F1-score was recorded as the best performance; the authors also provided a comparison between individual, incremental, and joint models. |
| Magge et al. [59] | Identification of specific entities from clinical notes such as drug, dose, and route; a total of nine terms were used for identification | Machine; earning-based approach: bidirectional LSTM-CRF | F1-score average for all nine terms is 0.81; they used the standard gold annotated dataset available at the University of Massachusetts comprising about 1092 medical notes. Around 800 notes were used for training, 76 was for validation, and the rest was used for testing. |
| Publication | Task | Methods | Performance |
|---|---|---|---|
| Nayel et al. [60] | Detection of annotated data from clinical text | Designed an ensemble approach which combined the results of base classifiers and used SVM for learning base classifiers | The proposed ensemble learning model reported an F1-score of 77%. |
| Wu et al. [4] | Concept extraction from clinical text by using and comparing CNN and RNN | Deep learning-based approach | RNN model performed better when compared with CNN and achieved an F1-score of 86%. |
| Wang et al. [61] | Studying symptoms and parthenogenesis in Chinese EHR | ML-based approach used CRF, SVM, and Maximum Entropy (ME) | Among all three methods applied, CRF outperformed the others. |
| Yadav et al. [17] | Advancement and improvement in NER from deep learning models | ML-based approach but focus was more on using deep learning | Better performance reported using deep learning compared with other supervised and semi-supervised learning algorithms. |
| Vunikili et al. [51] | NER on Spanish Clinical Text to extract tumor morphology | Transfer learning using BERT and BETO | 73% F1-score was reported without any features. |
| Jiang et al. [64] | Extraction of clinical entities from 349 clinical annotated notes with different features | ML-based approach (SVM and CRF) | CRF outperformed SVM and their hybrid system achieved an F1-score of 0.84 for concept extraction and 0.93 for assertion classification. |
| Yang et al. [65] | Extraction of family history from clinical narratives | Deep learning-based models such as LSTM, BERT, and ensemble models using majority voting strategy | Micro-averaged F1-score of 0.7944 for concept extraction. |
| Publication | Task | Methods | Performance |
|---|---|---|---|
| Segura-Bedmar et al. (2011) [84] | Drug–disease interaction extraction from clinical texts | Linguistic hybrid rule-based method using shallow parsing, syntactic simplification, and pattern matching | Did not perform well with an average precision and a very low recall |
| Xu et al. (2011) [85] | Clinical RE on 2010 i2b2 dataset | Combination of Rule-based and ML methods | Model performed decently with a micro-average F1-score of 0.7326 |
| Li et al. (2015) [86] | Automated extraction of medication discrepancy | Matching of drug names with their attributes from a prescription list and confirming it by means of co-location information | Performed well in identifying the medical discrepancies |
| Veena et al. (2021) [87] | RE between different clinical words | Path similarity analysis on the terms extracted by scraping and POS tagging | Successfully converted the data into a classified form |
| Mahendran et al. (2021) [70] | Adverse drug event extraction on 2018 n2c2 dataset | BFS based on the co-location information between the drug and the non-drug entity types | Left-only rule-based approach (macro-average F1-score: 0.83) performed the best amongst other rule-based models |
| Publication | Task | Methods | Performance |
|---|---|---|---|
| Roberts et al. (2011) [39] | 2010 i2b2/VA challenge on concepts, assertions, and relations in clinical text [38] | SVM-based supervised learning algorithm | Best performance with an F1-score of 0.737 |
| Sahu et al. (2016) [76] | Clinical RE on 2010 i2b2 dataset | Domain invariant CNN on multiple features | Decent performance: filter combination of [4, 6] performed the best (F1-score: 0.7116) amongst CNNs |
| Singhal et al. (2016) [79] | Disease-mutation RE on biomedical texts | C4.5 decision trees on various features | State-of-the art performance thus far; F1-score of 0.880 and 0.845 on prostate and lung disease mutations |
| Lv et al. (2016) [95] | Clinical RE on 2010 i2b2 dataset | Deep autoencoder-based model and sparse deep autoencoder-based model | Sparse deep autoencoder-based model performed better with an F1-score above 80% |
| Lin et al. (2017) [80] | Disorder Recognition in the 2013 CLEF task-1 dataset | multi-label structured SVM | Improved Performance: F1-score: 0.7343, i.e., 0.1428 more than the baseline BIOHD1234 scheme. |
| Mondal et al. (2017) [73] | Clinical RE based on the categories of medical concepts | Feature-oriented SVM-based supervised learning | Better performance (F1-score: 0.86) than the rule-based approach (F1-score: 0.79) |
| Kim et al. (2018) [72] | Clinical RE for biological pathway | Node2vec to learn the features from texts in networks | Best performance for type 2 diabetes pathway |
| Munkhdalai et al. (2018) [96] | Clinical RE towards drug surveillance | SVM model and a deep learning-based LSTM model | SVM performed better (89.1% F1-score) than all of the LSTM models |
| Li et al. (2019) [97] | Clinical RE on 2010 i2b2 dataset | NNs to model the shortest dependency path between entities and sentences | Resulted in an improved performance with an F1-score of 74.34% |
| Minard et al. (2019) [81] | Clinical RE on 2010 i2b2 dataset | Multi-class SVM | Poor performance (F1-score: 0.70) compared with the previous models |
| Christopoulou et al. (2020) [79] | Extraction of the adverse drug events and medications relations | An ensemble deep learning method | Achieved a micro-averaged F1-score of 0.9472 and 0.8765 for RE and end-to-end RE, respectively |
| Hasan et al. (2020) [82] | Clinical RE on 2010 i2b2 dataset | Deep learning methods such as CNN, GCN, GCN-CDT, ResNet, and BiLSTM | BiLSTM performed the best with a nine-class F1-score of 0.8808 and a six-class F1-score of 0.8894 |
| Mahendran et al. (2021) [70] | Adverse drug event extraction on 2018 n2c2 dataset | Sentence-CNN and segment-CNN | The CNN models did not perform better (micro-average F1-score: 0.78 and macro-average F1-score: 0.77) than the other models mentioned |
| Publication | Task | Methods | Performance |
|---|---|---|---|
| Lin et al. (2019) [77] | Temporal RE in clinical domain | Pretrained domain-specific as well as fine-tuned BERT | State-of-the art performance; 0.684 F1-score for in-domain texts and 0.565 F1-score for cross-domain texts |
| Alimova et al. (2020) [83] | Drug–disease RE from biomedical and clinical texts | BERT, BioBERT and Clinical BERT and Random Forest | The BERT models performed much better on the MADE corpus |
| Wei et al. (2020) [100] | RE on two clinical corpus: 2018 n2c2 dataset and 2010 i2b2 dataset | Fine-tuned and feature-combined BERT along with some deep learning methods | MIMIC fine-tuned BERT performed the best: F1-score of 0.9409 and 0.7679 on the n2c2 and the i2b2 datasets, respectively |
| Mahendran et al. (2021) [70] | Adverse drug event extraction on 2018 n2c2 dataset | BERT (cased and uncased), BioBERT, and Clinical BERT along with other methods | All of the BERT models performed the best, with a micro-averaged F1-score of 0.94 and a macro-averaged F1-score of 0.93 |
| Publication | Task | Methods | Performance |
|---|---|---|---|
| Quan et al. (2014) [101] | Protein–protein interactions and gene–suicide association extraction | Clustering based on dependency and phased structure parsing | Performed moderately but the proposed semi-supervised model surpassed its performance |
| Alicante et al. (2016) [102] | Domain-relevant entities and RE from Italian clinical records | Model Based, K-Means, and Hierarchical Clustering for pattern discovery | Promising performance to introduce a semi-automatic relation labelling |
References
- Gantz, J.; Reinsel, D. The digital universe in 2020: Big data, bigger digital shadows, and biggest growth in the far east. IDC IView IDC Anal. Future 2012, 2007, 1–16. [Google Scholar]
- Tan, A.H. Text mining: The state of the art and the challenges. In Proceedings of the Pakdd 1999 Workshop on Knowledge Disocovery from Advanced Databases, Bejing, China, 26–28 April 1999; Volume 8, pp. 65–70. [Google Scholar]
- Kong, H.J. Managing unstructured big data in healthcare system. Healthc. Inform. Res. 2019, 25, 1–2. [Google Scholar] [CrossRef] [PubMed]
- Wu, Y.; Jiang, M.; Xu, J.; Zhi, D.; Xu, H. Clinical Named Entity Recognition Using Deep Learning Models. AMIA Annu. Symp. Proc. 2017, 2017, 1812–1819. [Google Scholar]
- Hall, M.; Frank, E.; Holmes, G.; Pfahringer, B.; Reutemann, P.; Witten, I.H. The WEKA Data Mining Software: An Update. SIGKDD Explor. Newsl. 2009, 11, 10–18. [Google Scholar] [CrossRef]
- Soysal, E.; Wang, J.; Jiang, M.; Wu, Y.; Pakhomov, S.; Liu, H.; Xu, H. CLAMP—A toolkit for efficiently building customized clinical natural language processing pipelines. J. Am. Med. Inform. Assoc. 2017, 25, 331–336. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Bhatia, P.; Celikkaya, B.; Khalilia, M.; Senthivel, S. Comprehend Medical: A Named Entity Recognition and Relationship Extraction Web Service. In Proceedings of the 2019 18th IEEE International Conference on Machine Learning and Applications (ICMLA), Boca Raton, FL, USA, 16–19 December 2019; pp. 1844–1851. [Google Scholar] [CrossRef] [Green Version]
- Rish, I. An empirical study of the naive Bayes classifier. In Proceedings of the IJCAI 2001 Workshop on Empirical Methods in Artificial Intelligence, Seattle, WA, USA, 4–6 August 2001. [Google Scholar]
- Vishwanathan, S.; Murty, M.N. SSVM: A simple SVM algorithm. In Proceedings of the 2002 International Joint Conference on Neural Networks, IJCNN’02 (Cat. No. 02CH37290), Honolulu, HI, USA, 12–17 May 2002; Volume 3, pp. 2393–2398. [Google Scholar]
- Quinlan, J.R. Induction of decision trees. Mach. Learn. 1986, 1, 81–106. [Google Scholar] [CrossRef] [Green Version]
- Hartigan, J.A.; Wong, M.A. Algorithm AS 136: A k-means clustering algorithm. J. R. Stat. Society. Ser. C (Appl. Stat.) 1979, 28, 100–108. [Google Scholar] [CrossRef]
- Schubert, E.; Sander, J.; Ester, M.; Kriegel, H.P.; Xu, X. DBSCAN revisited, revisited: Why and how you should (still) use DBSCAN. ACM Trans. Database Syst. (TODS) 2017, 42, 1–21. [Google Scholar] [CrossRef]
- Aggarwal, C.C.; Zhai, C. A survey of text classification algorithms. In Mining Text Data; Springer: Boston, MA, USA, 2012; pp. 163–222. [Google Scholar]
- Derr, T.; Karimi, H.; Liu, X.; Xu, J.; Tang, J. Deep Adversarial Network Alignment. arXiv 2019, arXiv:cs.SI/1902.10307. [Google Scholar]
- Watkins, C.J.; Dayan, P. Q-learning. Mach. Learn. 1992, 8, 279–292. [Google Scholar] [CrossRef]
- Abiodun, O.I.; Jantan, A.; Omolara, A.E.; Dada, K.V.; Mohamed, N.A.; Arshad, H. State-of-the-art in artificial neural network applications: A survey. Heliyon 2018, 4, e00938. [Google Scholar] [CrossRef] [Green Version]
- Yadav, V.; Bethard, S. A survey on recent advances in named entity recognition from deep learning models. arXiv 2019, arXiv:1910.11470. [Google Scholar]
- Grishman, R.; Sundheim, B. Message understanding conference-6: A brief history. In Proceedings of the 1995 International Conference on Computational Linguistics (COLING), Copenhagen, Denmark, 5–9 August 1995. [Google Scholar]
- Collobert, R.; Weston, J.; Bottou, L.; Karlen, M.; Kavukcuoglu, K.; Kuksa, P. Natural language processing (almost) from scratch. J. Mach. Learn. Res. 2011, 12, 2493–2537. [Google Scholar]
- Bach, N.; Badaskar, S. A review of relation extraction. Lit. Rev. Lang. Stat. II 2007, 2, 1–15. [Google Scholar]
- Brin, S. Extracting Patterns and Relations from the World Wide Web. In The World Wide Web and Databases, Proceedings of the International Workshop WebDB’98, Valencia, Spain, 27–28 March 1998; Atzeni, P., Mendelzon, A., Mecca, G., Eds.; Springer: Berlin/Heidelberg, Germany, 1999; pp. 172–183. [Google Scholar]
- Agichtein, E.; Gravano, L. Snowball: Extracting Relations from Large Plain-Text Collections. In Proceedings of the Fifth ACM Conference on Digital Libraries (DL’00), San Antonio, TX, USA, 2–7 June 2000; Association for Computing Machinery: New York, NY, USA, 2000; pp. 85–94. [Google Scholar] [CrossRef]
- Culotta, A.; Sorensen, J. Dependency Tree Kernels for Relation Extraction. In Proceedings of the 42nd Annual Meeting of the Association for Computational Linguistics (ACL-04), Barcelona, Spain, 21–26 July 2004; pp. 423–429. [Google Scholar] [CrossRef] [Green Version]
- Bunescu, R.C.; Mooney, R.J. A Shortest Path Dependency Kernel for Relation Extraction. In Proceedings of the HLT/EMNLP, Vancouver, BC, Canada, 6–8 October 2005; pp. 724–731. [Google Scholar]
- Bunescu, R.C.; Mooney, R.J. Subsequence Kernels for Relation Extraction. In Proceedings of the 18th International Conference on Neural Information Processing Systems (NIPS’05), Vancouver, BC, Canada, 5–8 December 2005; MIT Press: Cambridge, MA, USA, 2005; pp. 171–178. [Google Scholar]
- Culotta, A.; McCallum, A.; Betz, J. Integrating Probabilistic Extraction Models and Data Mining to Discover Relations and Patterns in Text. In Proceedings of the HLT-NAACL, New York, NY, USA, 4–9 June 2006. [Google Scholar]
- Allahyari, M.; Pouriyeh, S.; Assefi, M.; Safaei, S.; Trippe, E.D.; Gutierrez, J.B.; Kochut, K. A Brief Survey of Text Mining: Classification, Clustering and Extraction Techniques. arXiv 2017, arXiv:cs.CL/1707.02919. [Google Scholar]
- Hedderich, M.A.; Lange, L.; Adel, H.; Strötgen, J.; Klakow, D. A survey on recent approaches for natural language processing in low-resource scenarios. arXiv 2020, arXiv:2010.12309. [Google Scholar]
- Stubbs, A.; Uzuner, Ö. Annotating longitudinal clinical narratives for de-identification: The 2014 i2b2/UTHealth corpus. J. Biomed. Inform. 2015, 58, S20–S29. [Google Scholar] [CrossRef]
- Stubbs, A.; Kotfila, C.; Xu, H.; Uzuner, Ö. Identifying risk factors for heart disease over time: Overview of 2014 i2b2/UTHealth shared task Track 2. J. Biomed. Inform. 2015, 58, S67–S77. [Google Scholar] [CrossRef]
- Stubbs, A.; Filannino, M.; Uzuner, Ö. De-identification of psychiatric intake records: Overview of 2016 CEGS N-GRID Shared Tasks Track 1. J. Biomed. Inform. 2017, 75, S4–S18. [Google Scholar] [CrossRef]
- Goto, I.; Chow, K.P.; Lu, B.; Sumita, E.; Tsou, B.K. Overview of the Patent Machine Translation Task at the NTCIR-10 Workshop. In Proceedings of the NTCIR, Tokyo, Japan, 18–21 June 2013. [Google Scholar]
- Coffman, A.; Wharton, N. Clinical Natural Language Processing: Auto-Assigning ICD-9 Codes. Overview of the Computational Medicine Center’s. 2007. Available online: https://courses.ischool.berkeley.edu/i256/f09/Final%20Projects%20write-ups/coffman_wharton_project_final.pdf (accessed on 2 September 2012).
- Jagannatha, A.; Liu, F.; Liu, W.; Yu, H. Overview of the first natural language processing challenge for extracting medication, indication, and adverse drug events from electronic health record notes (MADE 1.0). Drug Saf. 2019, 42, 99–111. [Google Scholar] [CrossRef]
- Liu, F.; Jagannatha, A.; Yu, H. Towards Drug Safety Surveillance and Pharmacovigilance: Current Progress in Detecting Medication and Adverse Drug Events from Electronic Health Records. Drug Saf. 2019, 42, 95–97. [Google Scholar] [CrossRef] [Green Version]
- Pradhan, S.; Chapman, W.; Man, S.; Savova, G. Semeval-2014 task 7: Analysis of clinical text. In Proceedings of the 8th International Workshop on Semantic Evaluation (SemEval 2014), Dublin, Ireland, 23–24 August 2014. [Google Scholar]
- Pradhan, S.; Elhadad, N.; South, B.R.; Martinez, D.; Christensen, L.; Vogel, A.; Suominen, H.; Chapman, W.W.; Savova, G. Evaluating the state of the art in disorder recognition and normalization of the clinical narrative. J. Am. Med. Inform. Assoc. 2015, 22, 143–154. [Google Scholar] [CrossRef] [Green Version]
- Uzuner, Ö.; South, B.R.; Shen, S.; DuVall, S.L. 2010 i2b2/VA challenge on concepts, assertions, and relations in clinical text. J. Am. Med. Inform. Assoc. 2011, 18, 552–556. [Google Scholar] [CrossRef] [Green Version]
- Roberts, K.; Rink, B.; Harabagiu, S. Extraction of medical concepts, assertions, and relations from discharge summaries for the fourth i2b2/VA shared task. In Proceedings of the 2010 i2b2/VA Workshop on Challenges in Natural Language Processing for Clinical Data, Washington, DC, USA, 12–13 November 2010. [Google Scholar]
- Uzuner, O.; Bodnari, A.; Shen, S.; Forbush, T.; Pestian, J.; South, B.R. Evaluating the state of the art in coreference resolution for electronic medical records. J. Am. Med. Inform. Assoc. 2012, 19, 786–791. [Google Scholar] [CrossRef] [Green Version]
- Glinos, D. A search based method for clinical text coreference resolution. In Proceedings of the 2011 i2b2/VA/Cincinnati Workshop on Challenges in Natural Language Processing for Clinical Data, Washington, DC, USA, 21–22 October 2011. [Google Scholar]
- Xu, Y.; Liu, J.; Wu, J. EHUATUO: A mention-pair coreference system by exploiting document intrinsic latent structures and world knowledge in discharge summaries: 2011 i2b2 challenge. In Proceedings of the 2011 i2b2/VA/Cincinnati Workshop on Challenges in Natural Language Processing for Clinical Data, Washington, DC, USA, 21–22 October 2011. [Google Scholar]
- Sun, W.; Rumshisky, A.; Uzuner, O. Evaluating temporal relations in clinical text: 2012 i2b2 Challenge. J. Am. Med. Inform. Assoc. 2013, 20, 806–813. [Google Scholar] [CrossRef] [Green Version]
- Henry, S.; Buchan, K.; Filannino, M.; Stubbs, A.; Uzuner, O. 2018 n2c2 shared task on adverse drug events and medication extraction in electronic health records. J. Am. Med. Inform. Assoc. 2019, 27, 3–12. [Google Scholar] [CrossRef]
- Xu, J.; Lee, H.J.; Ji, Z.; Wang, J.; Wei, Q.; Xu, H. UTH_CCB System for Adverse Drug Reaction Extraction from Drug Labels at TAC-ADR 2017; TAC: Gaithersburg, MD, USA, 2017. [Google Scholar]
- Savova, G.K.; Masanz, J.J.; Ogren, P.V.; Zheng, J.; Sohn, S.; Kipper-Schuler, K.C.; Chute, C.G. Mayo clinical Text Analysis and Knowledge Extraction System (cTAKES): Architecture, component evaluation and applications. J. Am. Med. Inform. Assoc. 2010, 17, 507–513. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Olson, J.E.; Ryu, E.; Johnson, K.J.; Koenig, B.A.; Maschke, K.J.; Morrisette, J.A.; Liebow, M.; Takahashi, P.Y.; Fredericksen, Z.S.; Sharma, R.G.; et al. The Mayo Clinic Biobank: A building block for individualized medicine. Mayo Clin. Proc. 2013, 88, 952–962. [Google Scholar] [CrossRef] [Green Version]
- Popovski, G.; Seljak, B.K.; Eftimov, T. A survey of named-entity recognition methods for food information extraction. IEEE Access 2020, 8, 31586–31594. [Google Scholar] [CrossRef]
- Weegar, R.; Pérez, A.; Casillas, A.; Oronoz, M. Recent advances in Swedish and Spanish medical entity recognition in clinical texts using deep neural approaches. BMC Med. Inform. Decis. Mak. 2019, 19, 274. [Google Scholar] [CrossRef] [Green Version]
- Johnson, A.E.; Pollard, T.J.; Shen, L.; Li-Wei, H.L.; Feng, M.; Ghassemi, M.; Moody, B.; Szolovits, P.; Celi, L.A.; Mark, R.G. MIMIC-III, a freely accessible critical care database. Sci. Data 2016, 3, 1–9. [Google Scholar] [CrossRef] [Green Version]
- Vunikili, R.; SH, N.; Marica, G.; Farri, O. Clinical NER using Spanish BERT Embeddings. In Proceedings of the Iberian Languages Evaluation Forum (IberLEF 2020), Malaga, Spain, 23 September 2020. [Google Scholar]
- Catelli, R.; Gargiulo, F.; Casola, V.; De Pietro, G.; Fujita, H.; Esposito, M. Crosslingual named entity recognition for clinical de-identification applied to a COVID-19 Italian data set. Appl. Soft Comput. 2020, 97, 106779. [Google Scholar] [CrossRef]
- Nalluri, J.; Kapoor, R.; Sleeman, W.; Soni, P.; Ghosh, P.; Khajamoinuddin, S.; Hagan, M.; Palta, J. Health Information and Gateway Exchange (HINGE): Big Data Curation Tool for Radiation Oncology. Int. J. Radiat. Oncol. Biol. Phys. 2019, 105, E132. [Google Scholar] [CrossRef]
- Kapoor, R.; Sleeman, W.C., IV; Nalluri, J.J.; Turner, P.; Bose, P.; Cherevko, A.; Srinivasan, S.; Syed, K.; Ghosh, P.; Hagan, M.; et al. Automated data abstraction for quality surveillance and outcome assessment in radiation oncology. J. Appl. Clin. Med. Phys. 2021, 22, 177–187. [Google Scholar] [CrossRef] [PubMed]
- Lample, G.; Ballesteros, M.; Subramanian, S.; Kawakami, K.; Dyer, C. Neural architectures for named entity recognition. arXiv 2016, arXiv:1603.01360. [Google Scholar]
- Skeppstedt, M.; Kvist, M.; Dalianis, H. Rule-based Entity Recognition and Coverage of SNOMED CT in Swedish Clinical Text. In Proceedings of the LREC, Istanbul, Turkey, 23–25 May 2012; pp. 1250–1257. [Google Scholar]
- Chen, L.; Gu, Y.; Ji, X.; Lou, C.; Sun, Z.; Li, H.; Gao, Y.; Huang, Y. Clinical trial cohort selection based on multi-level rule-based natural language processing system. J. Am. Med. Inform. Assoc. 2019, 26, 1218–1226. Available online: https://academic.oup.com/jamia/article-pdf/26/11/1218/36089031/ocz109.pdf (accessed on 13 July 2019). [CrossRef]
- Xu, Y.; Wang, Y.; Liu, T.; Liu, J.; Fan, Y.; Qian, Y.; Tsujii, J.; Chang, E.I. Joint segmentation and named entity recognition using dual decomposition in Chinese discharge summaries. J. Am. Med. Inform. Assoc. 2014, 21, e84–e92. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Magge, A.; Scotch, M.; Gonzalez-Hernandez, G. Clinical NER and relation extraction using bi-char-LSTMs and random forest classifiers. In Proceedings of the International Workshop on Medication and Adverse Drug Event Detection, Virtual, 4 May 2018; pp. 25–30. [Google Scholar]
- Nayel, H.; Shashirekha, H. Improving NER for clinical texts by ensemble approach using segment representations. In Proceedings of the 14th International Conference on Natural Language Processing (ICON-2017), Kolkata, India, 18–21 December 2017; pp. 197–204. [Google Scholar]
- Wang, Y.; Yu, Z.; Chen, L.; Chen, Y.; Liu, Y.; Hu, X.; Jiang, Y. Supervised methods for symptom name recognition in free-text clinical records of traditional Chinese medicine: An empirical study. J. Biomed. Inform. 2014, 47, 91–104. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Canete, J.; Chaperon, G.; Fuentes, R.; Pérez, J. Spanish pre-trained bert model and evaluation data. In Proceedings of the PML4DC, ICLR 2020, Addis Aboba, Ethiopia, 26 April 2020. [Google Scholar]
- Jiang, M.; Chen, Y.; Liu, M.; Rosenbloom, S.T.; Mani, S.; Denny, J.C.; Xu, H. A study of machine-learning-based approaches to extract clinical entities and their assertions from discharge summaries. J. Am. Med. Inform. Assoc. 2011, 18, 601–606. [Google Scholar] [CrossRef]
- Yang, X.; Zhang, H.; He, X.; Bian, J.; Wu, Y. Extracting Family History of Patients From Clinical Narratives: Exploring an End-to-End Solution With Deep Learning Models. JMIR Med. Inform. 2020, 8, e22982. [Google Scholar] [CrossRef]
- Hsu, T.C.; Feldt, L.S. The effect of limitations on the number of criterion score values on the significance level of the F-test. Am. Educ. Res. J. 1969, 6, 515–527. [Google Scholar]
- Branco, P.; Torgo, L.; Ribeiro, R.P. Relevance-based evaluation metrics for multi-class imbalanced domains. In Proceedings of the Pacific-Asia Conference on Knowledge Discovery and Data Mining, Jeju, Korea, 23–26 May 2017; Springer: Cham, Switzerland, 2017; pp. 698–710. [Google Scholar]
- Law, V.; Knox, C.; Djoumbou, Y.; Jewison, T.; Guo, A.C.; Liu, Y.; Maciejewski, A.; Arndt, D.; Wilson, M.; Neveu, V.; et al. DrugBank 4.0: Shedding new light on drug metabolism. Nucleic Acids Res. 2013, 42, D1091–D1097. Available online: https://academic.oup.com/nar/article-pdf/42/D1/D1091/3559045/gkt1068.pdf (accessed on 13 July 2019). [CrossRef] [PubMed] [Green Version]
- Hebbring, S.J. The challenges, advantages and future of phenome-wide association studies. Immunology 2014, 141, 157–165. Available online: https://onlinelibrary.wiley.com/doi/pdf/10.1111/imm.12195 (accessed on 13 July 2019). [CrossRef] [PubMed]
- Mahendran, D.; McInnes, B.T. Extracting Adverse Drug Events from Clinical Notes. arXiv 2021, arXiv:cs.CL/2104.10791. [Google Scholar]
- Sarker, A.; Gonzalez, G. Portable automatic text classification for adverse drug reaction detection via multi-corpus training. J. Biomed. Inform. 2015, 53, 196–207. [Google Scholar] [CrossRef] [Green Version]
- Kim, M. Relation extraction for biological pathway construction using node2vec. BMC Bioinform. 2018, 19, 206. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Mondal, A.; Das, D.; Bandyopadhyay, S. Relationship Extraction based on Category of Medical Concepts from Lexical Contexts. In Proceedings of the 14th International Conference on Natural Language Processing (ICON-2017), Kolkata, India, 18–21 December 2017; NLP Association of India: Kolkata, India, 2017; pp. 212–219. [Google Scholar]
- Singhal, A.; Simmons, M.; Lu, Z. Text mining for precision medicine: Automating disease-mutation relationship extraction from biomedical literature. J. Am. Med. Inform. Assoc. 2016, 23, 766–772. [Google Scholar] [CrossRef] [Green Version]
- Lim, C.G.; Choi, H.J. Temporal Relationship Extraction for Natural Language Texts by Using Deep Bidirectional Language Model. In Proceedings of the 2020 IEEE International Conference on Big Data and Smart Computing (BigComp), Busan, Korea, 19–22 February 2020; pp. 555–557. [Google Scholar] [CrossRef]
- Sahu, S.K.; Anand, A.; Oruganty, K.; Gattu, M. Relation extraction from clinical texts using domain invariant convolutional neural network. arXiv 2016, arXiv:cs.CL/1606.09370. [Google Scholar]
- Lin, C.; Miller, T.; Dligach, D.; Bethard, S.; Savova, G. A BERT-based universal model for both within-and cross-sentence clinical temporal relation extraction. In Proceedings of the 2nd Clinical Natural Language Processing Workshop, Minneapolis, MN, USA, 7 June 2019; pp. 65–71. [Google Scholar]
- Swampillai, K.; Stevenson, M. Extracting relations within and across sentences. In Proceedings of the International Conference Recent Advances in Natural Language Processing 2011, Hissar, Bulgaria, 12–14 September 2011; pp. 25–32. [Google Scholar]
- Christopoulou, F.; Tran, T.T.; Sahu, S.K.; Miwa, M.; Ananiadou, S. Adverse drug events and medication relation extraction in electronic health records with ensemble deep learning methods. J. Am. Med. Inform. Assoc. 2019, 27, 39–46. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Lin, W.; Ji, D.; Lu, Y. Disorder recognition in clinical texts using multi-label structured SVM. BMC Bioinform. 2017, 18, 75. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Minard, A.L.; Ligozat, A.L.; Grau, B. Multi-class SVM for relation extraction from clinical reports. In Proceedings of the Recent Advances in Natural Language Processing, Varna, Bulgaria, 2–4 September 2011. [Google Scholar]
- Hasan, F.; Roy, A.; Pan, S. Integrating Text Embedding with Traditional NLP Features for Clinical Relation Extraction. In Proceedings of the 2020 IEEE 32nd International Conference on Tools with Artificial Intelligence (ICTAI), Baltimore, MD, USA, 9–11 November 2020; pp. 418–425. [Google Scholar] [CrossRef]
- Alimova, I.; Tutubalina, E. Multiple features for clinical relation extraction: A machine learning approach. J. Biomed. Inform. 2020, 103, 103382. [Google Scholar] [CrossRef]
- Segura-Bedmar, I.; Martínez, P.; de Pablo-Sánchez, C. A linguistic rule-based approach to extract drug-drug interactions from pharmacological documents. BMC Bioinform. 2011, 12, S1. [Google Scholar] [CrossRef] [Green Version]
- Xu, Y.; Hong, K.; Tsujii, J.; Chang, E.I.C. Feature engineering combined with machine learning and rule-based methods for structured information extraction from narrative clinical discharge summaries. J. Am. Med. Inform. Assoc. 2012, 19, 824–832. [Google Scholar] [CrossRef] [Green Version]
- Li, Q.; Spooner, S.A.; Kaiser, M.; Lingren, N.; Robbins, J.; Lingren, T.; Tang, H.; Solti, I.; Ni, Y. An end-to-end hybrid algorithm for automated medication discrepancy detection. BMC Med. Inform. Decis. Mak. 2015, 15, 37. [Google Scholar] [CrossRef] [Green Version]
- Veena, G.; Hemanth, R.; Hareesh, J. Relation Extraction in Clinical Text using NLP Based Regular Expressions. In Proceedings of the 2019 2nd International Conference on Intelligent Computing, Instrumentation and Control Technologies (ICICICT), Kannur, India, 5–6 July 2019; Volume 1, pp. 1278–1282. [Google Scholar] [CrossRef]
- Russell, S.; Norvig, P. Artificial Intelligence: A Modern Approach; Prentice Hall: Hoboken, NJ, USA, 2002. [Google Scholar]
- Janiesch, C.; Zschech, P.; Heinrich, K. Machine learning and deep learning. Electron. Mark. 2021. [Google Scholar] [CrossRef]
- Bose, P.; Sleeman, W.C.; Syed, K.; Hagan, M.; Palta, J.; Kapoor, R.; Ghosh, P. Deep Neural Network Models to Automate Incident Triage in the Radiation Oncology Incident Learning System. In Proceedings of the 12th ACM International Conference on Bioinformatics, Computational Biology and Health Informatics (BCB’21), Gainesville, FL, USA, 1–4 August 2021; Association for Computing Machinery: New York, NY, USA, 2021. [Google Scholar] [CrossRef]
- Watson, D.S.; Krutzinna, J.; Bruce, I.N.; Griffiths, C.E.; McInnes, I.B.; Barnes, M.R.; Floridi, L. Clinical applications of machine learning algorithms: Beyond the black box. BMJ 2019, 364, l886. [Google Scholar] [CrossRef] [Green Version]
- Weng, S.F.; Reps, J.; Kai, J.; Garibaldi, J.M.; Qureshi, N. Can machine-learning improve cardiovascular risk prediction using routine clinical data? PLoS ONE 2017, 12, e0174944. [Google Scholar] [CrossRef] [Green Version]
- Sleeman, W.; Bose, P.; Ghosh, P.; Palta, J.; Kapoor, R. Using CNNs to Extract Standard Structure Names While Learning Radiomic Features. In Medical Physics; Wiley: Hoboken, NJ, USA, 2021; Volume 48. [Google Scholar]
- Bose, P.; Sleeman, W.; Srinivasan, S.; Palta, J.; Kapoor, R.; Ghosh, P. Integrated Structure Name Mapping with CNN. In Medical Physics; Wiley: Hoboken, NJ, USA, 2021; Volume 48. [Google Scholar]
- Lv, X.; Guan, Y.; Yang, J.; Wu, J. Clinical relation extraction with deep learning. Int. J. Hybrid Inf. Technol. 2016, 9, 237–248. [Google Scholar] [CrossRef] [Green Version]
- Munkhdalai, T.; Liu, F.; Yu, H. Clinical Relation Extraction Toward Drug Safety Surveillance Using Electronic Health Record Narratives: Classical Learning Versus Deep Learning. JMIR Public Health Surveill. 2018, 4, e29. [Google Scholar] [CrossRef]
- Li, Z.; Yang, Z.; Shen, C.; Xu, J.; Zhang, Y.; Xu, H. Integrating shortest dependency path and sentence sequence into a deep learning framework for relation extraction in clinical text. BMC Med. Inf. Decis. Mak. 2019, 19, 22. [Google Scholar] [CrossRef]
- Lee, J.; Yoon, W.; Kim, S.; Kim, D.; Kim, S.; So, C.H.; Kang, J. BioBERT: A pre-trained biomedical language representation model for biomedical text mining. Bioinformatics 2019, 36, 1234–1240. [Google Scholar] [CrossRef]
- Alsentzer, E.; Murphy, J.R.; Boag, W.; Weng, W.H.; Jin, D.; Naumann, T.; McDermott, M.B.A. Publicly Available Clinical BERT Embeddings. arXiv 2019, arXiv:cs.CL/1904.03323. [Google Scholar]
- Wei, Q.; Ji, Z.; Si, Y.; Du, J.; Wang, J.; Tiryaki, F.; Wu, S.; Tao, C.; Roberts, K.; Xu, H. Relation Extraction from Clinical Narratives Using Pre-trained Language Models. AMIA Annu. Symp. Proc. 2020, 2019, 1236–1245. [Google Scholar]
- Quan, C.; Wang, M.; Ren, F. An Unsupervised Text Mining Method for Relation Extraction from Biomedical Literature. PLoS ONE 2014, 9, e102039. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Alicante, A.; Corazza, A.; Isgrò, F.; Silvestri, S. Unsupervised entity and relation extraction from clinical records in Italian. Comput. Biol. Med. 2016, 72, 263–275. [Google Scholar] [CrossRef] [PubMed]
- Hand, D.J.; Christen, P.; Kirielle, N. F*: An interpretable transformation of the F-measure. Mach. Learn. 2021, 110, 451–456. [Google Scholar] [CrossRef]
- Aggarwal, A.; Mittal, M.; Battineni, G. Generative adversarial network: An overview of theory and applications. Int. J. Inf. Manag. Data Insights 2021, 1, 100004. [Google Scholar]
- Isaac, A.; Schlobach, S.; Matthezing, H.; Zinn, C. Integrated access to cultural heritage resources through representation and alignment of controlled vocabularies. Libr. Rev. 2008, 57, 187–199. [Google Scholar] [CrossRef]
- Van Hooland, S.; Verborgh, R.; De Wilde, M.; Hercher, J.; Mannens, E.; Van de Walle, R. Evaluating the success of vocabulary reconciliation for cultural heritage collections. J. Am. Soc. Inf. Sci. Technol. 2013, 64, 464–479. [Google Scholar] [CrossRef] [Green Version]

Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bose, P.; Srinivasan, S.; Sleeman, W.C., IV; Palta, J.; Kapoor, R.; Ghosh, P. A Survey on Recent Named Entity Recognition and Relationship Extraction Techniques on Clinical Texts. Appl. Sci. 2021, 11, 8319. https://doi.org/10.3390/app11188319
Bose P, Srinivasan S, Sleeman WC IV, Palta J, Kapoor R, Ghosh P. A Survey on Recent Named Entity Recognition and Relationship Extraction Techniques on Clinical Texts. Applied Sciences. 2021; 11(18):8319. https://doi.org/10.3390/app11188319
Chicago/Turabian StyleBose, Priyankar, Sriram Srinivasan, William C. Sleeman, IV, Jatinder Palta, Rishabh Kapoor, and Preetam Ghosh. 2021. "A Survey on Recent Named Entity Recognition and Relationship Extraction Techniques on Clinical Texts" Applied Sciences 11, no. 18: 8319. https://doi.org/10.3390/app11188319
APA StyleBose, P., Srinivasan, S., Sleeman, W. C., IV, Palta, J., Kapoor, R., & Ghosh, P. (2021). A Survey on Recent Named Entity Recognition and Relationship Extraction Techniques on Clinical Texts. Applied Sciences, 11(18), 8319. https://doi.org/10.3390/app11188319