
Reusing Monolingual Pre-Trained Models by Cross-Connecting Seq2seq Models for Machine Translation


Abstract
:1. Introduction
2. Related Work
2.1. Unsupervised Pre-Training
2.2. Reusing Pre-Trained Models
2.3. Multilingual Language Models
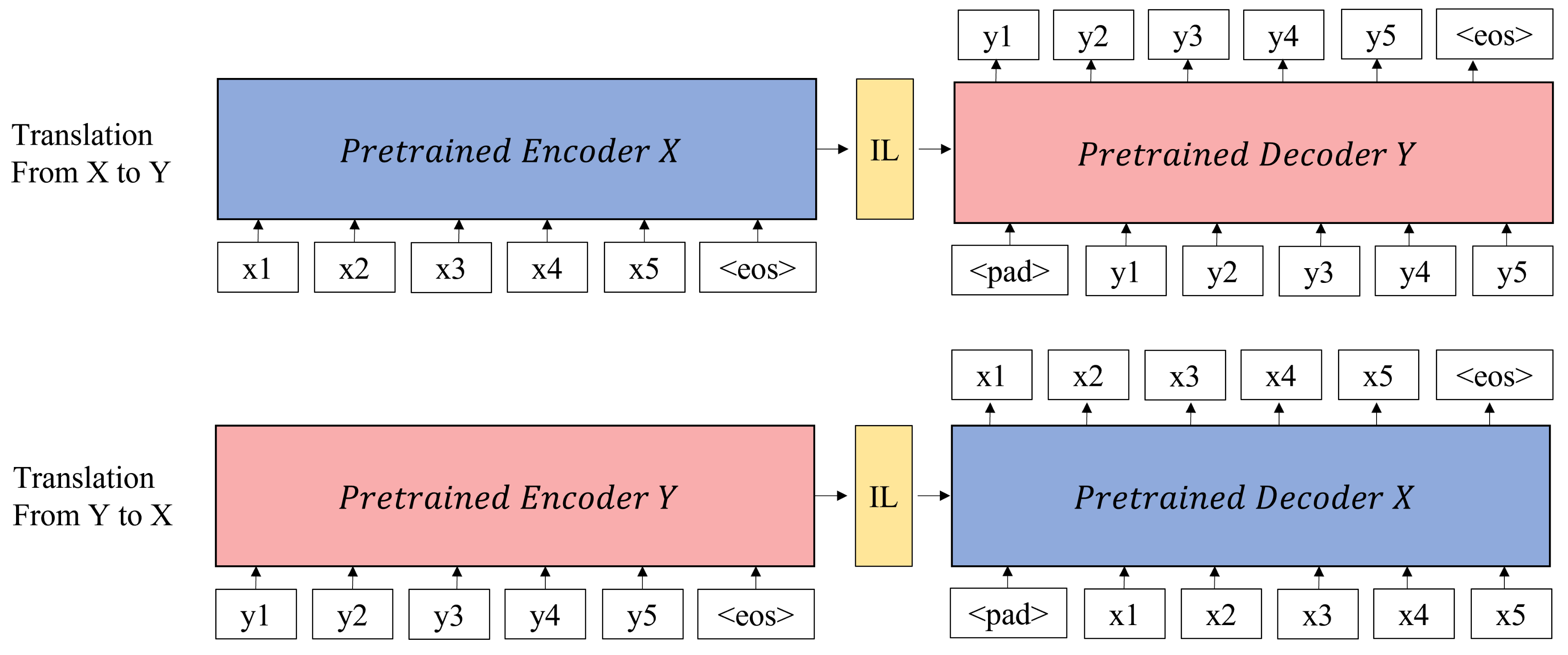
3. Method
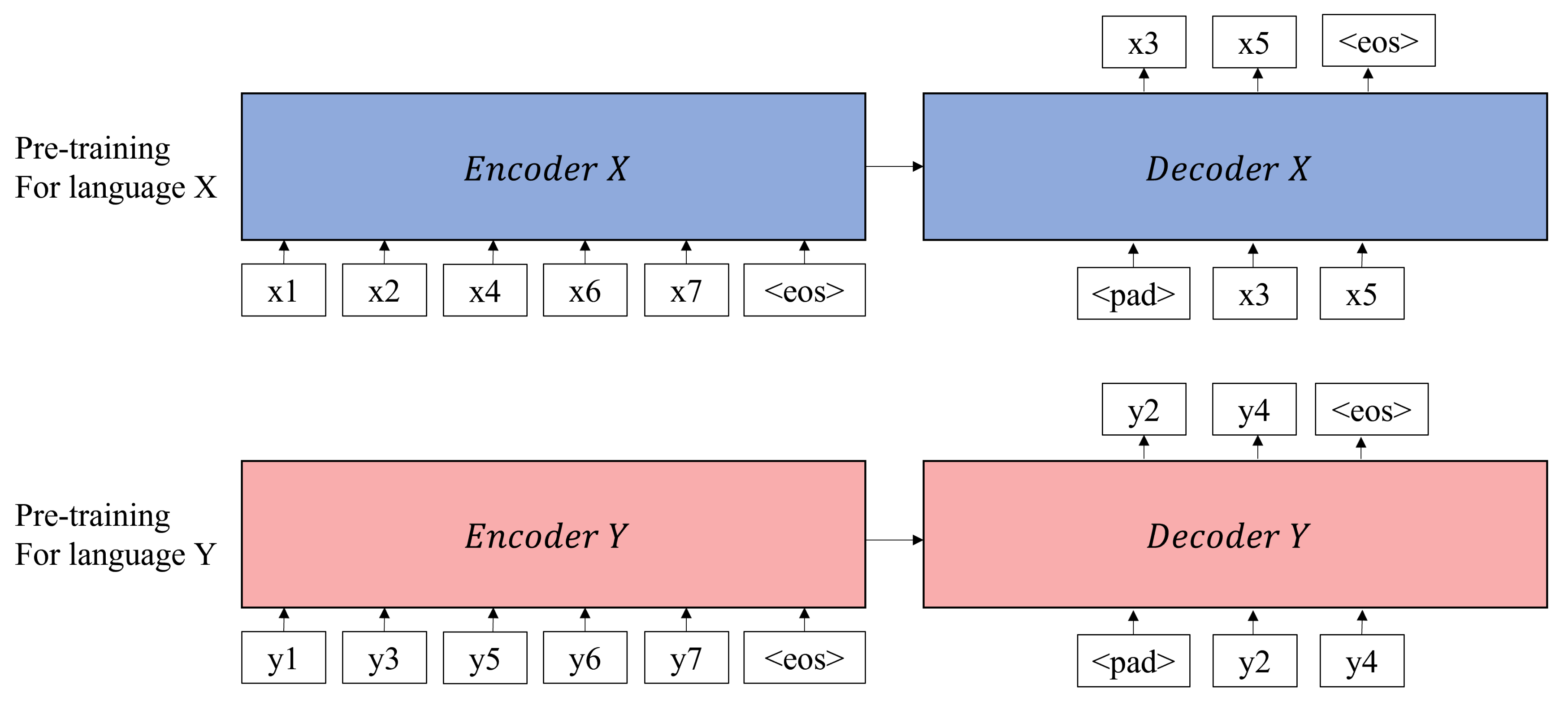
3.1. Monolingual Unsupervised Pre-Training
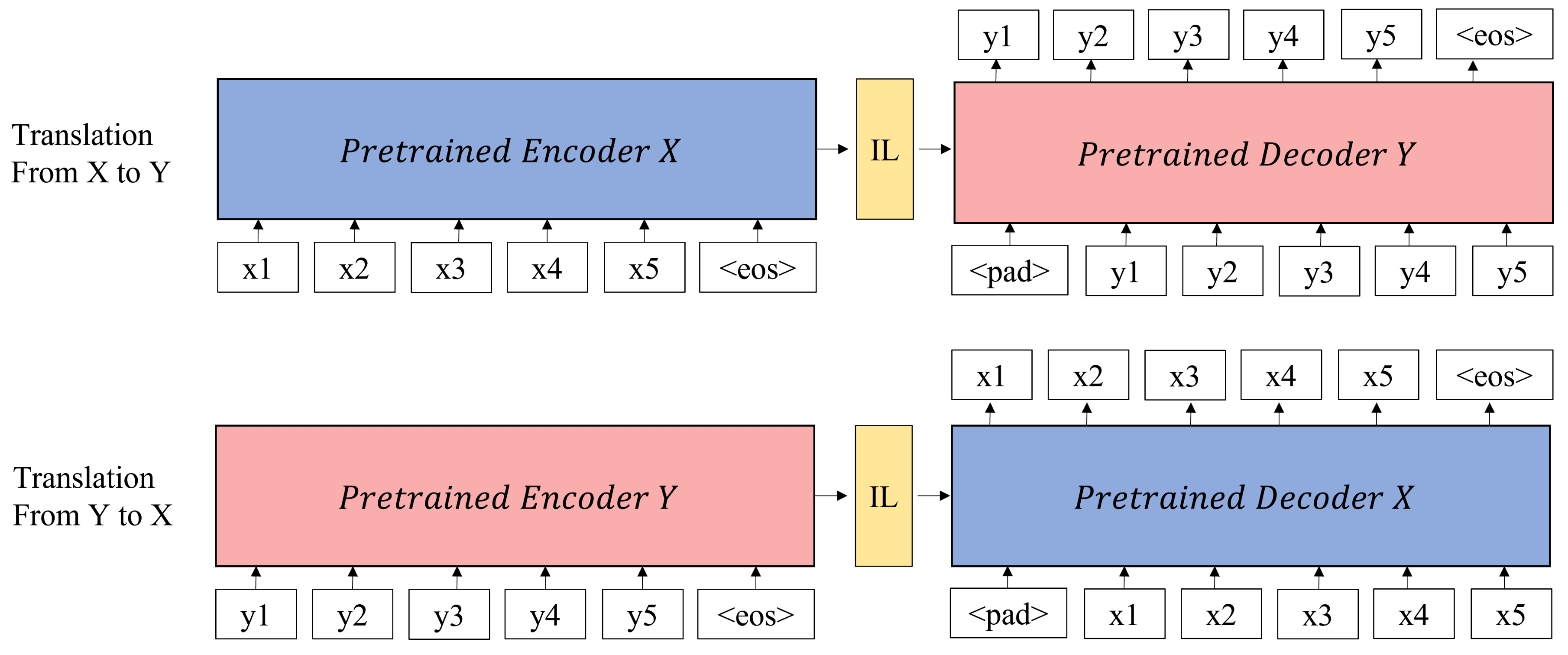
3.2. Cross-Connection and Fine-Tuning
3.3. Intermediate Layer
4. Experiment
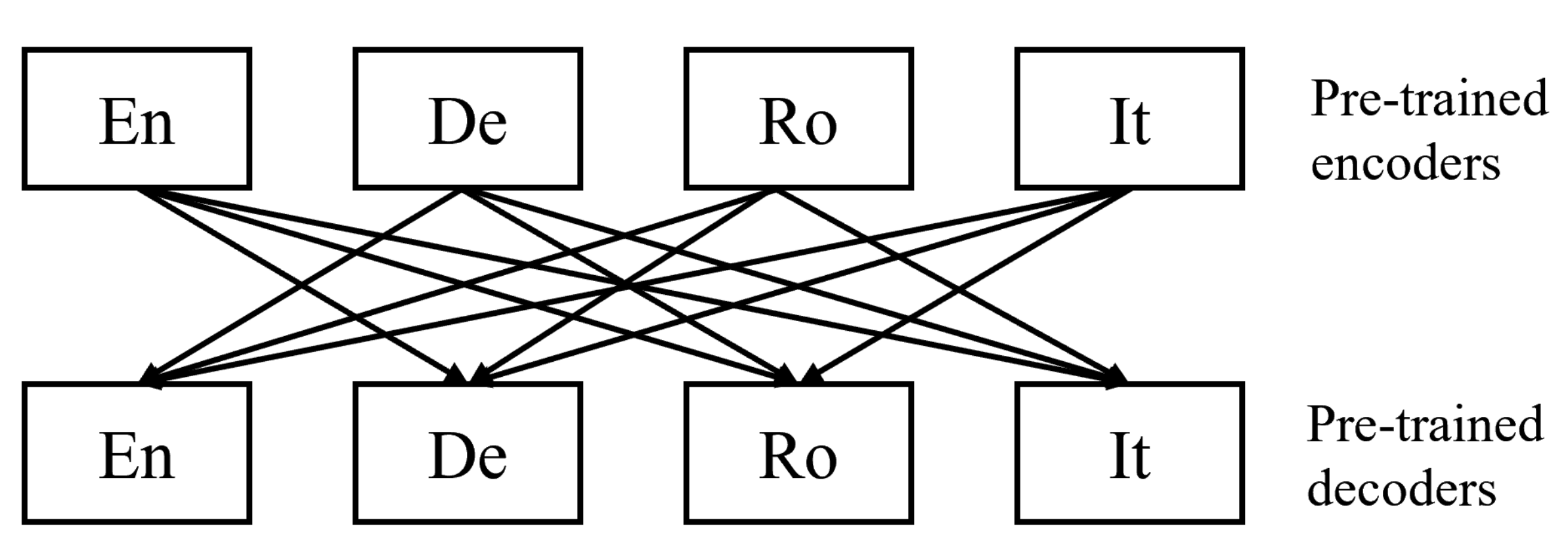
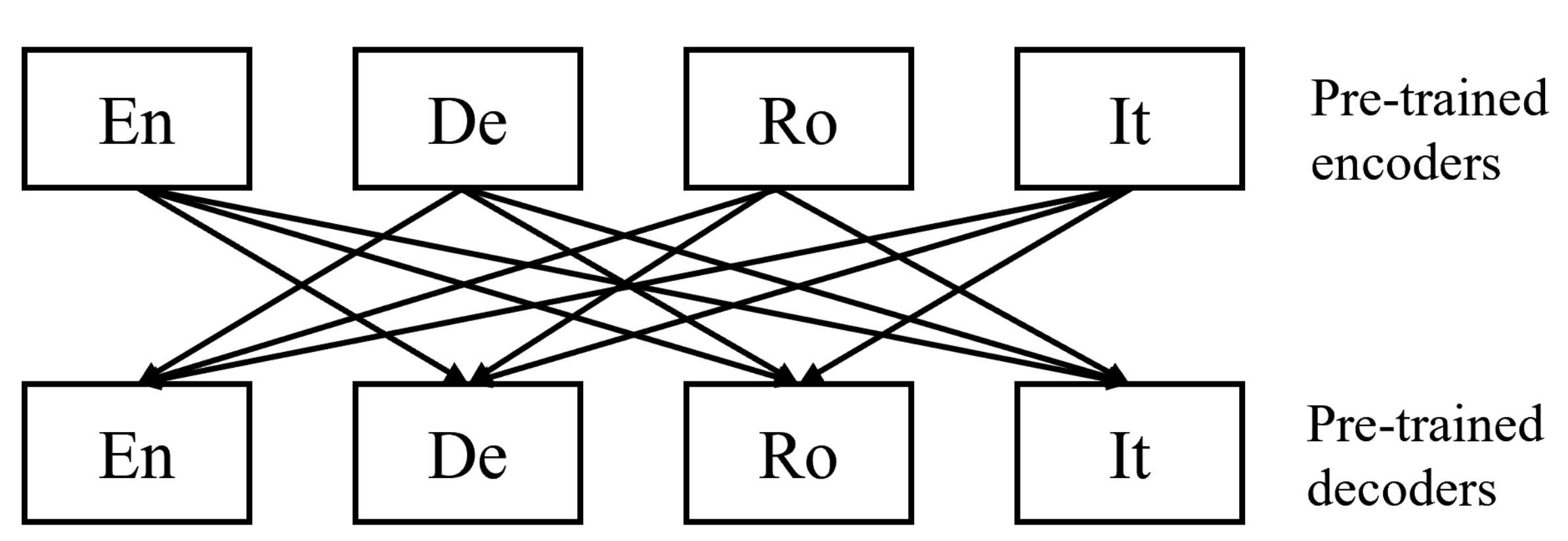
4.1. Architecture and Datasets
4.2. Training and Decoding
4.3. Models
- Random a randomly initialized baseline without pre-training.
- Cross-connected Our cross-connected models that the encoder is pre-trained with source language and the decoder is pre-trained with target language.
- Cross-connected + IL Our cross-connected models with the additional intermediate layer.
- ENC2ENC It is possible to use the pre-trained encoder weights to initialize the decoder such as BERT2BERT from [30], because the encoder and decoder of the Transformer are implemented in the same architecture except for the cross-attention of the decoder. We compare this scenario with our cross-connected method to see the effect of the pre-trained decoder. We initialize the encoder with the source language encoder weights, and we initialize the decoder with the target language encoder weights. In this case, the cross-attention of the decoder is initialized randomly.
4.4. Results
4.5. Ablation Study
4.5.1. Intermediate Layer
4.5.2. Initialization of Decoder Cross-Attention
4.5.3. Importance of Each Module
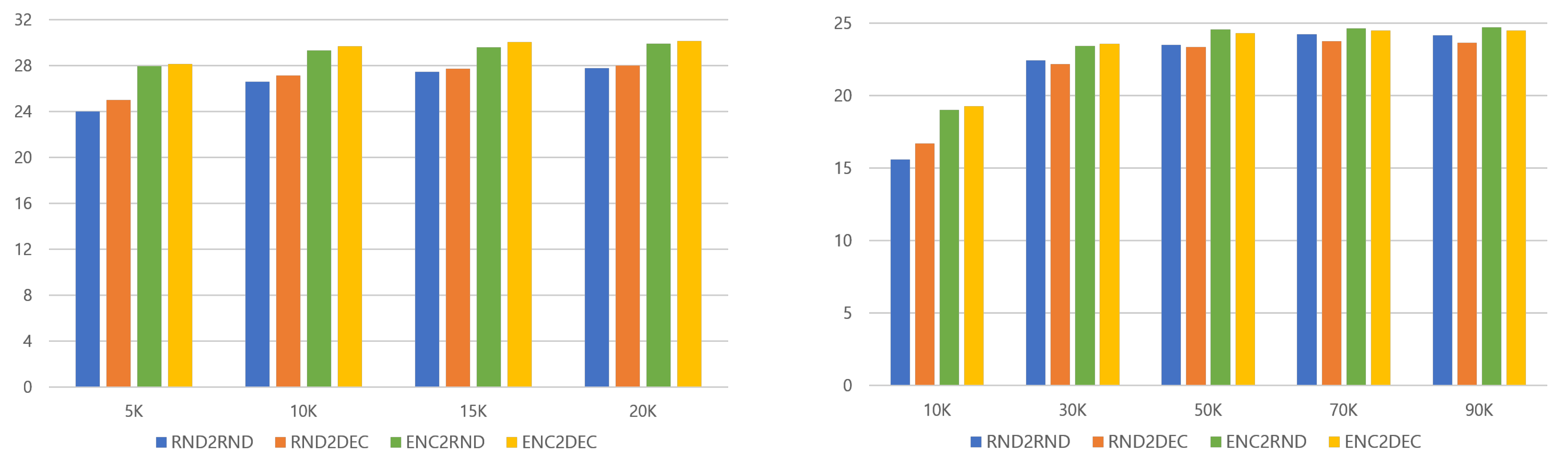
4.5.4. Low-Resource and Mid-Resource
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Liu, Y.; Gu, J.; Goyal, N.; Li, X.; Edunov, S.; Ghazvininejad, M.; Lewis, M.; Zettlemoyer, L. Multilingual denoising pre-training for neural machine translation. Trans. Assoc. Comput. Linguist. 2020, 8, 726–742. [Google Scholar] [CrossRef]
- Conneau, A.; Khandelwal, K.; Goyal, N.; Chaudhary, V.; Wenzek, G.; Guzmán, F.; Grave, E.; Ott, M.; Zettlemoyer, L.; Stoyanov, V. Unsupervised cross-lingual representation learning at scale. arXiv 2019, arXiv:1911.02116. [Google Scholar]
- Xue, L.; Constant, N.; Roberts, A.; Kale, M.; Al-Rfou, R.; Siddhant, A.; Barua, A.; Raffel, C. mT5: A massively multilingual pre-trained text-to-text transformer. arXiv 2020, arXiv:2010.11934. [Google Scholar]
- Carmo, D.; Piau, M.; Campiotti, I.; Nogueira, R.; Lotufo, R. PTT5: Pretraining and validating the T5 model on Brazilian Portuguese data. arXiv 2020, arXiv:2008.09144. [Google Scholar]
- de Vries, W.; van Cranenburgh, A.; Bisazza, A.; Caselli, T.; van Noord, G.; Nissim, M. Bertje: A dutch bert model. arXiv 2019, arXiv:1912.09582. [Google Scholar]
- Delobelle, P.; Winters, T.; Berendt, B. Robbert: A dutch roberta-based language model. arXiv 2020, arXiv:2001.06286. [Google Scholar]
- Dumitrescu, S.D.; Avram, A.M.; Pyysalo, S. The birth of Romanian BERT. arXiv 2020, arXiv:2009.08712. [Google Scholar]
- Kuratov, Y.; Arkhipov, M. Adaptation of deep bidirectional multilingual transformers for russian language. arXiv 2019, arXiv:1905.07213. [Google Scholar]
- Martin, L.; Muller, B.; Suárez, P.J.O.; Dupont, Y.; Romary, L.; de La Clergerie, É.V.; Seddah, D.; Sagot, B. Camembert: A tasty french language model. arXiv 2019, arXiv:1911.03894. [Google Scholar]
- Le, H.; Vial, L.; Frej, J.; Segonne, V.; Coavoux, M.; Lecouteux, B.; Allauzen, A.; Crabbé, B.; Besacier, L.; Schwab, D. Flaubert: Unsupervised language model pre-training for french. arXiv 2019, arXiv:1912.05372. [Google Scholar]
- Louis, A. BelGPT-2: A GPT-2 Model Pre-Trained on French Corpora. 2020. Available online: https://github.com/antoiloui/belgpt2 (accessed on 14 August 2021).
- Polignano, M.; Basile, P.; De Gemmis, M.; Semeraro, G.; Basile, V. Alberto: Italian BERT language understanding model for NLP challenging tasks based on tweets. In Proceedings of the 6th Italian Conference on Computational Linguistics, CLiC-it 2019, Bari, Italy, 13–15 November 2019; Volume 2481, pp. 1–6. [Google Scholar]
- De Mattei, L.; Cafagna, M.; Dell’Orletta, F.; Nissim, M.; Guerini, M. Geppetto carves italian into a language model. arXiv 2020, arXiv:2004.14253. [Google Scholar]
- Souza, F.; Nogueira, R.; Lotufo, R. Portuguese named entity recognition using BERT-CRF. arXiv 2019, arXiv:1909.10649. [Google Scholar]
- Cho, K.; Van Merriënboer, B.; Gulcehre, C.; Bahdanau, D.; Bougares, F.; Schwenk, H.; Bengio, Y. Learning phrase representations using RNN encoder-decoder for statistical machine translation. arXiv 2014, arXiv:1406.1078. [Google Scholar]
- Lample, G.; Conneau, A. Cross-lingual language model pretraining. arXiv 2019, arXiv:1901.07291. [Google Scholar]
- Radford, A.; Narasimhan, K.; Salimans, T.; Sutskever, I. Improving Language Understanding by Generative Pre-Training; 2018. Available online: https://www.cs.ubc.ca/~amuham01/LING530/papers/radford2018improving.pdf (accessed on 14 August 2021).
- Tang, Y.; Tran, C.; Li, X.; Chen, P.J.; Goyal, N.; Chaudhary, V.; Gu, J.; Fan, A. Multilingual translation with extensible multilingual pretraining and finetuning. arXiv 2020, arXiv:2008.00401. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is all you need. arXiv 2017, arXiv:1706.03762. [Google Scholar]
- Peters, M.E.; Neumann, M.; Iyyer, M.; Gardner, M.; Clark, C.; Lee, K.; Zettlemoyer, L. Deep contextualized word representations. arXiv 2018, arXiv:1802.05365. [Google Scholar]
- Liu, Y.; Ott, M.; Goyal, N.; Du, J.; Joshi, M.; Chen, D.; Levy, O.; Lewis, M.; Zettlemoyer, L.; Stoyanov, V. Roberta: A robustly optimized bert pretraining approach. arXiv 2019, arXiv:1907.11692. [Google Scholar]
- Joshi, M.; Chen, D.; Liu, Y.; Weld, D.S.; Zettlemoyer, L.; Levy, O. Spanbert: Improving pre-training by representing and predicting spans. Trans. Assoc. Comput. Linguist. 2020, 8, 64–77. [Google Scholar] [CrossRef]
- Song, K.; Tan, X.; Qin, T.; Lu, J.; Liu, T.Y. Mass: Masked sequence to sequence pre-training for language generation. arXiv 2019, arXiv:1905.02450. [Google Scholar]
- Lewis, M.; Liu, Y.; Goyal, N.; Ghazvininejad, M.; Mohamed, A.; Levy, O.; Stoyanov, V.; Zettlemoyer, L. Bart: Denoising sequence-to-sequence pre-training for natural language generation, translation, and comprehension. arXiv 2019, arXiv:1910.13461. [Google Scholar]
- Dong, L.; Yang, N.; Wang, W.; Wei, F.; Liu, X.; Wang, Y.; Gao, J.; Zhou, M.; Hon, H.W. Unified language model pre-training for natural language understanding and generation. arXiv 2019, arXiv:1905.03197. [Google Scholar]
- Bao, H.; Dong, L.; Wei, F.; Wang, W.; Yang, N.; Liu, X.; Wang, Y.; Gao, J.; Piao, S.; Zhou, M. Unilmv2: Pseudo-masked language models for unified language model pre-training. In Proceedings of the International Conference on Machine Learning, PMLR 2020, Virtual, 13–18 July 2020; pp. 642–652. [Google Scholar]
- Raffel, C.; Shazeer, N.; Roberts, A.; Lee, K.; Narang, S.; Matena, M.; Zhou, Y.; Li, W.; Liu, P.J. Exploring the limits of transfer learning with a unified text-to-text transformer. arXiv 2019, arXiv:1910.10683. [Google Scholar]
- Baziotis, C.; Titov, I.; Birch, A.; Haddow, B. Exploring Unsupervised Pretraining Objectives for Machine Translation. In Findings of the Association for Computational Linguistics, Proceedings of the ACL-IJCNLP 2021, Online, 1–6 August 2021; Association for Computational Linguistics: Stroudsburg, PA, USA, 2021; pp. 2956–2971. [Google Scholar] [CrossRef]
- Rothe, S.; Narayan, S.; Severyn, A. Leveraging pre-trained checkpoints for sequence generation tasks. Trans. Assoc. Comput. Linguist. 2020, 8, 264–280. [Google Scholar] [CrossRef]
- Zhu, J.; Xia, Y.; Wu, L.; He, D.; Qin, T.; Zhou, W.; Li, H.; Liu, T.Y. Incorporating bert into neural machine translation. arXiv 2020, arXiv:2002.06823. [Google Scholar]
- Yang, J.; Wang, M.; Zhou, H.; Zhao, C.; Zhang, W.; Yu, Y.; Li, L. Towards making the most of bert in neural machine translation. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 9378–9385. [Google Scholar]
- Imamura, K.; Sumita, E. Recycling a pre-trained BERT encoder for neural machine translation. In Proceedings of the 3rd Workshop on Neural Generation and Translation, Hong Kong, China, 4 November 2019; pp. 23–31. [Google Scholar]
- Clinchant, S.; Jung, K.W.; Nikoulina, V. On the use of bert for neural machine translation. arXiv 2019, arXiv:1909.12744. [Google Scholar]
- Vázquez, R.; Celikkanat, H.; Creutz, M.; Tiedemann, J. On the differences between BERT and MT encoder spaces and how to address them in translation tasks. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing: Student Research Workshop, Online, 5–6 August 2021; Association for Computational Linguistics: Stroudsburg, PA, USA, 2021; pp. 337–347. [Google Scholar] [CrossRef]
- Yoo, J.; Eom, H.; Choi, Y.S. Image-To-Image Translation Using a Cross-Domain Auto-Encoder and Decoder. Appl. Sci. 2019, 9, 4780. [Google Scholar] [CrossRef] [Green Version]
- Firat, O.; Cho, K.; Bengio, Y. Multi-way, multilingual neural machine translation with a shared attention mechanism. arXiv 2016, arXiv:1601.01073. [Google Scholar]
- Aharoni, R.; Johnson, M.; Firat, O. Massively multilingual neural machine translation. arXiv 2019, arXiv:1903.00089. [Google Scholar]
- Lu, Y.; Keung, P.; Ladhak, F.; Bhardwaj, V.; Zhang, S.; Sun, J. A neural interlingua for multilingual machine translation. arXiv 2018, arXiv:1804.08198. [Google Scholar]
- Lewis, M.; Ghazvininejad, M.; Ghosh, G.; Aghajanyan, A.; Wang, S.; Zettlemoyer, L. Pre-training via paraphrasing. arXiv 2020, arXiv:2006.15020. [Google Scholar]
- Chi, Z.; Dong, L.; Ma, S.; Mao, S.H.X.L.; Huang, H.; Wei, F. mT6: Multilingual Pretrained Text-to-Text Transformer with Translation Pairs. arXiv 2021, arXiv:2104.08692. [Google Scholar]
- Artetxe, M.; Ruder, S.; Yogatama, D. On the cross-lingual transferability of monolingual representations. arXiv 2019, arXiv:1910.11856. [Google Scholar]
- Yu, H.; Chen, C.; Du, X.; Li, Y.; Rashwan, A.; Hou, L.; Jin, P.; Yang, F.; Liu, F.; Kim, J.; et al. TensorFlow Model Garden. 2020. Available online: https://github.com/tensorflow/models (accessed on 14 August 2021).
- Bojar, O.r.; Chatterjee, R.; Federmann, C.; Graham, Y.; Haddow, B.; Huang, S.; Huck, M.; Koehn, P.; Liu, Q.; Logacheva, V.; et al. Findings of the 2017 Conference on Machine Translation (WMT17). In Proceedings of the Second Conference on Machine Translation, Volume 2: Shared Task Papers, Copenhagen, Denmark, 7–11 September 2017; Association for Computational Linguistics: Copenhagen, Denmark, 2017; pp. 169–214. [Google Scholar]
- ParaCrawl. 2018. Available online: https://paracrawl.eu/ (accessed on 14 August 2021).
- Bojar, O.r.; Chatterjee, R.; Federmann, C.; Graham, Y.; Haddow, B.; Huck, M.; Jimeno Yepes, A.; Koehn, P.; Logacheva, V.; Monz, C.; et al. Findings of the 2016 Conference on Machine Translation. In Proceedings of the First Conference on Machine Translation, Berlin, Germany, 11–12 August 2016; Association for Computational Linguistics: Berlin, Germany, 2016; pp. 131–198. [Google Scholar]
- Cettolo, M.; Girardi, C.; Federico, M. Wit3: Web inventory of transcribed and translated talks. In Proceedings of the 16th Conference of European Association for Machine Translation, Trento, Italy, 28–30 May 2012; pp. 261–268. [Google Scholar]
- Ott, M.; Edunov, S.; Baevski, A.; Fan, A.; Gross, S.; Ng, N.; Grangier, D.; Auli, M. fairseq: A Fast, Extensible Toolkit for Sequence Modeling. In Proceedings of the NAACL-HLT 2019: Demonstrations, Minneapolis, MN, USA, 2–7 June 2019. [Google Scholar]
- Wu, Y.; Schuster, M.; Chen, Z.; Le, Q.V.; Norouzi, M.; Macherey, W.; Krikun, M.; Cao, Y.; Gao, Q.; Macherey, K.; et al. Google’s neural machine translation system: Bridging the gap between human and machine translation. arXiv 2016, arXiv:1609.08144. [Google Scholar]
- Papineni, K.; Roukos, S.; Ward, T.; Zhu, W.J. Bleu: A method for automatic evaluation of machine translation. In Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics, Philadephia, PA, USA, 7–12 July 2002; pp. 311–318. [Google Scholar]
- Dalvi, F.; Durrani, N.; Sajjad, H.; Belinkov, Y.; Vogel, S. Understanding and Improving Morphological Learning in the Neural Machine Translation Decoder. In Proceedings of the Eighth International Joint Conference on Natural Language Processing (Volume 1: Long Papers), Taipei, Taiwan, 27 November–1 December 2017; Asian Federation of Natural Language Processing: Taipei, Taiwan, 2017; pp. 142–151. [Google Scholar]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Pre-training | WMT17 | ParaCrawl | ||||
| En | De | Ro | It | |||
| 639 | 714 | 264 | 1667 | |||
| Fine-tuning | IWSLT14 | IWSLT17 | ||||
| En-De | En-Ro | En-It | It-Ro | It-De | De-Ro | |
| 29.6 | 30.3 | 30.5 | 44.7 | 45.6 | 44.3 | |
| Model | En-De | De-En | En-Ro | Ro-En | En-It | It-En |
|---|---|---|---|---|---|---|
| Random (Baseline) | 26.11 | 33.83 | 27.49 | 37.47 | 29.10 | 31.44 |
| ENC2ENC | 28.36 | 37.16 | 29.31 | 39.06 | 31.18 | 34.22 |
| Cross-connected | 29.06 | 37.75 | 30.04 | 39.73 | 32.17 | 35.05 |
| Cross-connected + IL | 29.63 | 38.10 | 30.64 | 40.39 | 32.29 | 35.47 |
| Model | It-Ro | Ro-It | It-De | De-It | De-Ro | Ro-De |
| Random | 21.73 | 22.27 | 18.91 | 19.70 | 18.37 | 19.50 |
| ENC2ENC | 22.58 | 23.64 | 20.74 | 22.17 | 20.94 | 20.53 |
| Cross-connected | 22.36 | 23.91 | 21.53 | 22.65 | 20.98 | 21.20 |
| Cross-connected + IL | 23.03 | 24.33 | 22.04 | 23.32 | 21.26 | 21.71 |
| Model | En-De | De-En | En-Ro | Ro-En | En-It | It-En |
|---|---|---|---|---|---|---|
| No intermediate layer | 29.06 | 37.75 | 30.04 | 39.73 | 32.17 | 35.05 |
| 2FFN (filter size = 2048) | 29.43 | 38.08 | 30.31 | 40.01 | 31.80 | 35.14 |
| Encoder Sublayer (filter size = 2048) | 29.55 | 38.00 | 30.64 | 40.02 | 32.06 | 35.20 |
| 2FFN (filter size = 1024) | 29.20 | 38.01 | 30.29 | 40.39 | 32.09 | 35.22 |
| 1FFN (filter size = 2048) | 29.37 | 38.10 | 30.23 | 40.21 | 32.29 | 35.45 |
| 1FFN (filter size = 1024) | 29.57 | 37.91 | 30.37 | 40.20 | 32.08 | 35.23 |
| Self-Attention | 29.33 | 38.03 | 30.45 | 40.14 | 32.01 | 35.17 |
| 1FFN (filter size = 768) | 29.63 | 38.01 | 30.27 | 40.20 | 32.02 | 35.44 |
| 1FFN (filter size = 512) | 29.52 | 37.94 | 30.28 | 40.27 | 32.09 | 35.47 |
| Dense (size = 512) | 29.18 | 37.77 | 30.01 | 40.20 | 32.08 | 35.06 |
| Model | It-Ro | Ro-It | It-De | De-It | De-Ro | Ro-De |
| No intermediate layer | 22.36 | 23.91 | 21.53 | 22.65 | 20.98 | 21.20 |
| 2FFN (filter size = 2048) | 22.61 | 23.94 | 21.62 | 23.19 | 21.18 | 21.71 |
| Encoder Sublayer (filter size = 2048) | 22.72 | 23.92 | 21.46 | 23.32 | 20.69 | 21.44 |
| 2FFN (filter size = 1024) | 22.95 | 24.26 | 21.29 | 23.05 | 21.03 | 21.32 |
| 1FFN (filter size = 2048) | 22.96 | 23.50 | 21.41 | 23.17 | 20.58 | 21.19 |
| 1FFN (filter size = 1024) | 22.42 | 24.16 | 21.69 | 23.16 | 21.05 | 20.93 |
| Self-Attention | 22.39 | 24.07 | 21.64 | 22.96 | 20.68 | 21.03 |
| 1FFN (filter size = 768) | 23.03 | 23.74 | 21.90 | 23.01 | 21.00 | 21.03 |
| 1FFN (filter size = 512) | 22.08 | 24.11 | 22.04 | 23.28 | 21.26 | 21.14 |
| Dense (size = 512) | 22.24 | 24.33 | 21.80 | 22.89 | 21.02 | 21.42 |
| Model | En-De | De-En | En-Ro | Ro-En | En-It | It-En |
|---|---|---|---|---|---|---|
| RND2RND (baseline) | 26.11 | 33.83 | 27.49 | 37.47 | 29.10 | 31.44 |
| ENC2DEC+IL | 29.63 | 38.10 | 30.64 | 40.39 | 32.29 | 35.47 |
| ENC2DEC+IL (Random Cross-attention) | 29.24 | 37.90 | 30.14 | 39.72 | 31.81 | 35.03 |
| ENC2ENC+IL | 28.68 | 37.19 | 29.73 | 38.98 | 31.34 | 34.22 |
| Model | It-Ro | Ro-It | It-De | De-It | De-Ro | Ro-De |
| RND2RND (baseline) | 21.73 | 22.27 | 18.91 | 19.70 | 18.37 | 19.50 |
| ENC2DEC+IL | 23.03 | 24.33 | 22.04 | 23.32 | 21.26 | 21.71 |
| ENC2DEC+IL (Random Cross-attention) | 22.65 | 23.84 | 21.32 | 22.71 | 20.91 | 21.14 |
| ENC2ENC+IL | 22.71 | 23.43 | 20.33 | 22.01 | 20.80 | 20.76 |
| Model | En-De | De-En | En-Ro | Ro-En | En-It | It-En |
|---|---|---|---|---|---|---|
| RND2RND (baseline) | 26.11 | 33.83 | 27.49 | 37.47 | 29.10 | 31.44 |
| ENC2RND | 28.35 | 36.63 | 29.63 | 39.22 | 30.66 | 33.80 |
| RND2DEC | 27.13 | 34.88 | 28.01 | 37.86 | 29.81 | 32.10 |
| ENC2DEC | 29.06 | 37.75 | 30.04 | 39.73 | 32.17 | 35.05 |
| Model | It-Ro | Ro-It | It-De | De-It | De-Ro | Ro-De |
| RND2RND (baseline) | 21.73 | 22.27 | 18.91 | 19.70 | 18.37 | 19.50 |
| ENC2RND | 22.69 | 23.14 | 20.64 | 22.58 | 20.43 | 20.85 |
| RND2DEC | 20.59 | 22.27 | 19.40 | 19.96 | 18.94 | 20.24 |
| ENC2DEC | 22.36 | 23.91 | 21.53 | 22.65 | 20.98 | 21.20 |
| Models | IWSLT14 | WMT16 |
|---|---|---|
| RND2RND (baseline) | 27.49 | 23.89 |
| ENC2DEC | 30.04 | 24.51 |
| ENC2RND | 29.63 | 24.77 |
| RND2DEC | 28.01 | 23.73 |
| RND2ENC | 27.41 | 24.03 |
| ENC2ENC | 29.31 | 24.68 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Oh, J.; Choi, Y.-S. Reusing Monolingual Pre-Trained Models by Cross-Connecting Seq2seq Models for Machine Translation. Appl. Sci. 2021, 11, 8737. https://doi.org/10.3390/app11188737
Oh J, Choi Y-S. Reusing Monolingual Pre-Trained Models by Cross-Connecting Seq2seq Models for Machine Translation. Applied Sciences. 2021; 11(18):8737. https://doi.org/10.3390/app11188737
Chicago/Turabian StyleOh, Jiun, and Yong-Suk Choi. 2021. "Reusing Monolingual Pre-Trained Models by Cross-Connecting Seq2seq Models for Machine Translation" Applied Sciences 11, no. 18: 8737. https://doi.org/10.3390/app11188737
APA StyleOh, J., & Choi, Y.-S. (2021). Reusing Monolingual Pre-Trained Models by Cross-Connecting Seq2seq Models for Machine Translation. Applied Sciences, 11(18), 8737. https://doi.org/10.3390/app11188737