
Experimental Characteristics Study of Data Storage Formats for Data Marts Development within Data Lakes



Abstract
1. Introduction
2. Related Works
3. Storage Formats Overview
4. Experiment
- -
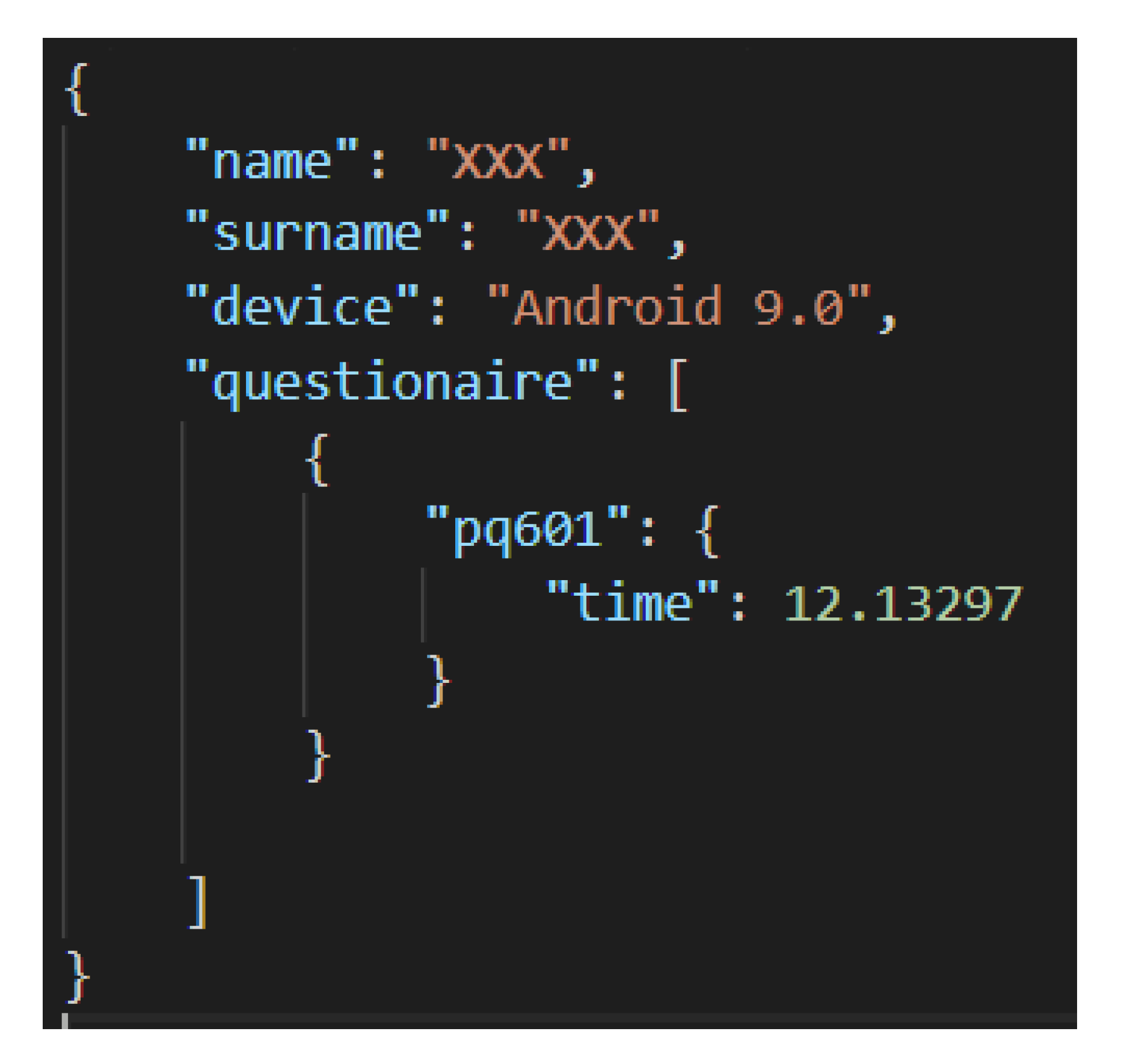
- name and surname of the test taker;
- -
- the device platform from which the test was passed (commonly, it is information about the operating system installed on the device)—this information can help in understanding which type of device (PC, mobile, old platforms) is used to improve the support of such operating systems;
- -
- an array of test completion information for each question. The most interesting information for this study from the array is the time the test taker spent on each question.
5. Results
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Alasta, A.F.; Enaba, M.A. Data warehouse on Manpower Employment for Decision Support System. Int. J. Comput. Commun. Instrum. Eng. 2014, 1, 48–53. [Google Scholar]
- Chong, D.; Shi, H. Big data analytics: A literature review. J. Manag. Anal. 2015, 2, 175–201. [Google Scholar] [CrossRef]
- Yang, C.; Huang, Q.; Li, Z.; Liu, K.; Hu, F. Big Data and cloud computing: Innovation opportunities and challenges. Int. J. Digit. Earth 2017, 10, 13–53. [Google Scholar] [CrossRef]
- Cappa, F.; Oriani, R.; Peruffo, E.; McCarthy, I.P. Big Data for Creating and Capturing Value in the Digitalized Environment: Unpacking the Effects of Volume, Variety and Veracity on Firm Performance. J. Prod. Innov. Manag. 2020. [Google Scholar] [CrossRef]
- Khine, P.P.; Wang, Z.S. Data Lake: A new ideology in big data era. ITM Web Conf. 2018, 17. [Google Scholar] [CrossRef]
- Tomashevskaya, V.S.; Yakovlev, D.A. Research of unstructured data interpretation problems. Russ. Technol. J. 2021, 9, 7–17. [Google Scholar] [CrossRef]
- Ghezzi, C. Designing data marts for data warehouses. ACM Trans. Softw. Eng. Methodol. 2001, 10, 452–483. [Google Scholar] [CrossRef]
- O’Driscoll, A.; Belogrudov, V.; Carroll, J.; Kropp, K.; Walsh, P.; Ghazal, P.; Sleator, R.D. HBLAST: Parallelised sequence Similarity—A Hadoop MapReducable basic local alignment search tool. J. Biomed. Inf. 2015, 54, 58–64. [Google Scholar] [CrossRef]
- HDFS. 2020 HDFS Architecture Guide. Available online: https://hadoop.apache.org/docs/r1.2.1/hdfs_design.html (accessed on 24 July 2021).
- Introducing JSON. Available online: https://www.json.org/json-en.html (accessed on 22 August 2021).
- Super CSV. What is CSV? Available online: http://super-csv.github.io/super-csv/csv_specification.html (accessed on 22 August 2021).
- Apache. Parquet Official Documentation 2018. Available online: https://parquet.apache.org/documen-tation/latest/ (accessed on 24 July 2021).
- Apache. Avro Specification 2012. Available online: http://avro.apache.org/docs/current/spec.html (accessed on 24 July 2021).
- ORC. ORC Specification 2020. Available online: https://orc.apache.org/specification/ORCv1/ (accessed on 24 July 2021).
- Nikulchev, E.; Ilin, D.; Silaeva, A.; Kolyasnikov, P.; Belov, V.; Runtov, A.; Pushkin, P.; Laptev, N.; Alexeenko, A.; Magomedov, S.; et al. Digital Psychological Platform for Mass Web-Surveys. Data 2020, 5, 95. [Google Scholar] [CrossRef]
- Rasheed, Y.; Qutqut, M.H.; Almasalha, F. Overview of the Current Status of NoSQL Database. Int. J. Comput. Sci. Netw. Secur. 2019, 19, 47–53. [Google Scholar]
- Ali, W.; Shafique, M.U.; Majeed, M.A.; Raza, A. Comparison between SQL and NoSQL Databases and Their Relationship with Big Data Analytics. Asian J. Res. Comput. Sci. 2019, 4, 1–10. [Google Scholar] [CrossRef]
- Bicevska, Z.; Oditis, I. Towards NoSQL-based Data Warehouse Solutions. Procedia Comput. Sci. 2017, 104, 104–111. [Google Scholar] [CrossRef]
- Hamoud, A.K.; Ulkareem, M.A.; Hussain, H.N.; Mohammed, Z.A.; Salih, G.M. Improve HR Decision-Making Based On Data Mart and OLAP. J. Phys. Conf. Ser. 2020, 1530, 012058. [Google Scholar] [CrossRef]
- Wang, X.; Xie, Z. The Case for Alternative Web Archival Formats to Expedite the Data-To-Insight Cycle. In Proceedings of the ACM/IEEE Joint Conference on Digital Libraries, Virtual Event, China, 1–5 August 2020; pp. 177–186. [Google Scholar]
- Ahmed, S.; Ali, M.U.; Ferzund, J.; Sarwar, M.A.; Rehman, A.; Mehmood, A. Modern Data Formats for Big Bioinformatics Data Analytics. Int. J. Adv. Comput. Sci. Appl. 2017, 8. [Google Scholar] [CrossRef]
- Ramírez, A.; Parejo, J.A.; Romero, J.R.; Segura, S.; Ruiz-Cortés, A. Evolutionary composition of QoS-aware web services: A many-objective perspective. Expert Syst. Appl. 2017, 72, 357–370. [Google Scholar] [CrossRef]
- Plase, D.; Niedrite, L.; Taranovs, R. A Comparison of HDFS Compact Data Formats: Avro Versus Parquet. Moksl. Liet. Ateitis 2017, 9, 267–276. [Google Scholar] [CrossRef][Green Version]
- Raevich, A.; Dobronets, B.; Popova, O.; Raevich, K. Conceptual model of operational-analytical data marts for big data processing. E3S Web Conf 2020, 149. [Google Scholar] [CrossRef]
- McCarthy, S. Reusing Dynamic Data Marts for Query Management in an on-Demand ETL Architecture. Ph.D. Thesis, Dublin City University, Dublin, Ireland, 2021. [Google Scholar]
- Huh, J.H.; Seo, K. Design and test bed experiments of server operation system using virtualization technology. Hum. Cent. Comput. Inf. Sci. 2016, 6, 1. [Google Scholar] [CrossRef]
- Yang, Q.; Ge, M.; Helfert, M. Developing Reliable Taxonomic Features for Data Warehouse Architectures. In Proceedings of the IEEE 22nd Conference on Business Informatics (CBI), Antwerp, Belgium, 22–24 June 2020; pp. 241–249. [Google Scholar] [CrossRef]
- Nikulchev, E.; Ilin, D.; Gusev, A. Technology Stack Selection Model for Software Design of Digital Platforms. Mathematics 2021, 9, 308. [Google Scholar] [CrossRef]
- Oussous, A.; Benjelloun, F.-Z.; Lahcen, A.A.; Belfkih, S. NoSQL databases for big data. Int. J. Big Data Intell. 2017, 4, 171–185. [Google Scholar] [CrossRef]
- Salloum, S.; Dautov, R.; Chen, X.; Peng, P.X.; Huang, J.Z. Big data analytics on Apache Spark. Int. J. Data Sci. Anal. 2016, 1, 145–164. [Google Scholar] [CrossRef]
- Apache. Hive Official Documentation 2014. Available online: https://hive.apache.org/ (accessed on 24 July 2021).
- Belov, V.; Tatarintsev, A.; Nikulchev, E. Choosing a Data Storage Format in the Apache Hadoop System Based on Experimental Evaluation Using Apache Spark. Symmetry 2021, 13, 195. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Configuration Item | Characteristics |
|---|---|
| Nodes count | 3 |
| Replication factor | 2 |
| Hadoop Distributive | Cloudera v. 4.2 |
| Nodes Characteristics | |
| Processor | Intel Core i7 2 Cores |
| RAM | 4 GB |
| OS | Debian 9 |
| Platform | Java Virtual Machine |
| Programming language | Java v.1.8 |
| Framework | Apache Spark v. 2.4 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Belov, V.; Kosenkov, A.N.; Nikulchev, E. Experimental Characteristics Study of Data Storage Formats for Data Marts Development within Data Lakes. Appl. Sci. 2021, 11, 8651. https://doi.org/10.3390/app11188651
Belov V, Kosenkov AN, Nikulchev E. Experimental Characteristics Study of Data Storage Formats for Data Marts Development within Data Lakes. Applied Sciences. 2021; 11(18):8651. https://doi.org/10.3390/app11188651
Chicago/Turabian StyleBelov, Vladimir, Alexander N. Kosenkov, and Evgeny Nikulchev. 2021. "Experimental Characteristics Study of Data Storage Formats for Data Marts Development within Data Lakes" Applied Sciences 11, no. 18: 8651. https://doi.org/10.3390/app11188651
APA StyleBelov, V., Kosenkov, A. N., & Nikulchev, E. (2021). Experimental Characteristics Study of Data Storage Formats for Data Marts Development within Data Lakes. Applied Sciences, 11(18), 8651. https://doi.org/10.3390/app11188651