
HybridTabNet: Towards Better Table Detection in Scanned Document Images


 ,
,  ,
, 
Abstract
:1. Introduction
- We propose HybridTabNet, a novel table detection system by incorporating deformable convolutions in the backbone network of an instance segmentation-based Hybrid Task Cascade (HTC) network.
- During our exhaustive evaluation, we accomplish state-of-the-art performance on five well-recognized publicly available datasets for table detection in scanned document images.
- We present the superiority of the proposed method by reporting results with a leave-one-out scheme on several table detection datasets. The employed strategy sets a new direction, indicating the generalization capabilities of the proposed method.
2. Related Work
2.1. Rule-Based Approaches
2.2. Learning-Based Approaches
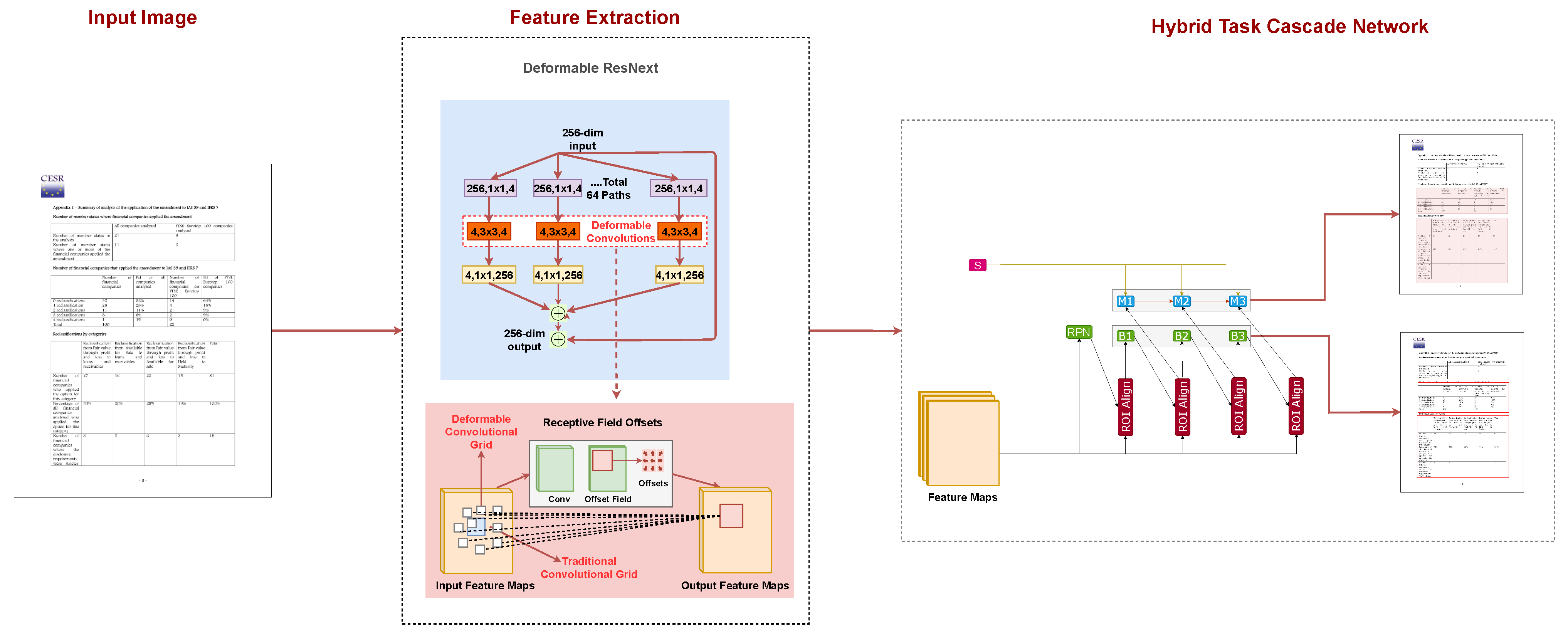
3. Method
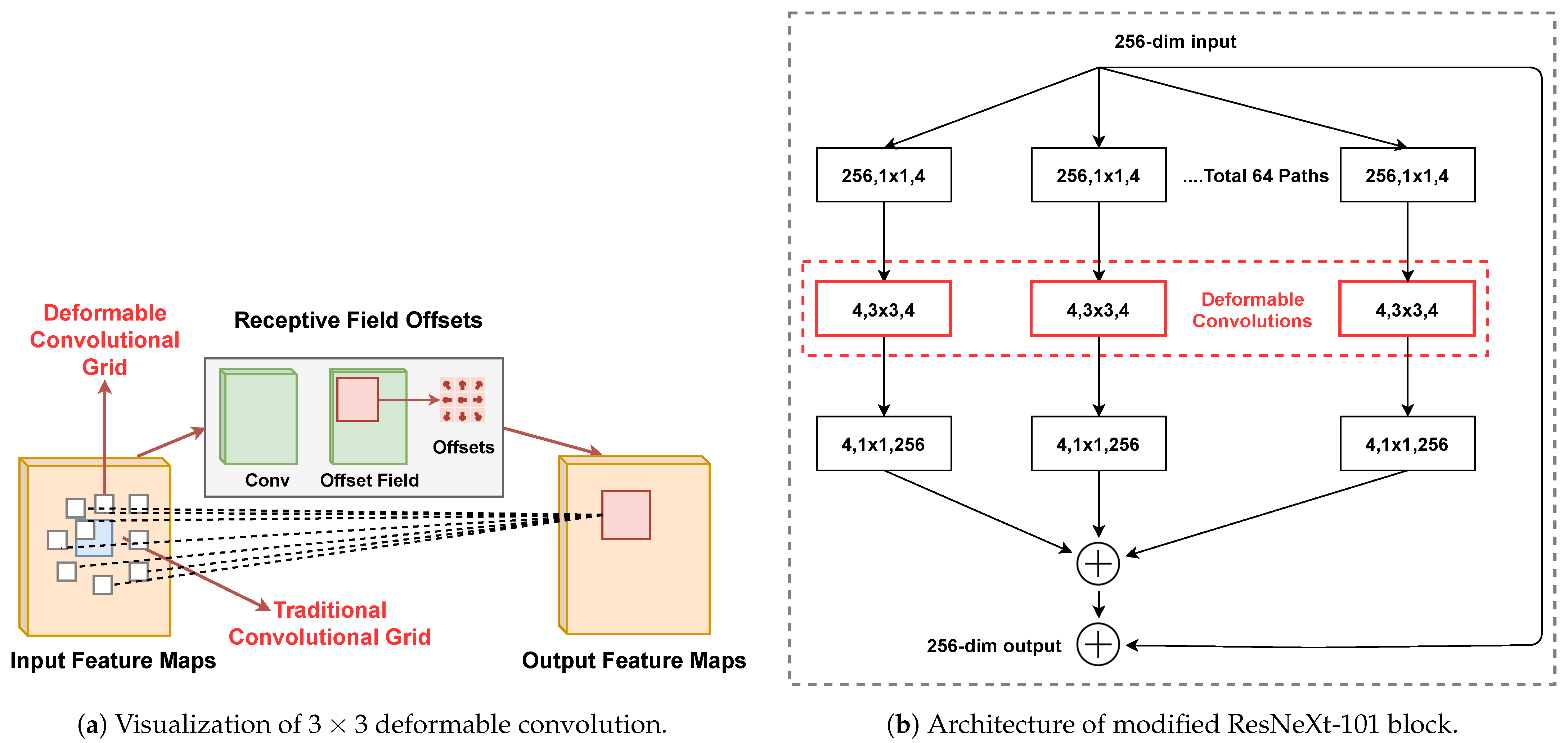
3.1. Deformable Convolution
3.2. ResNeXt-101
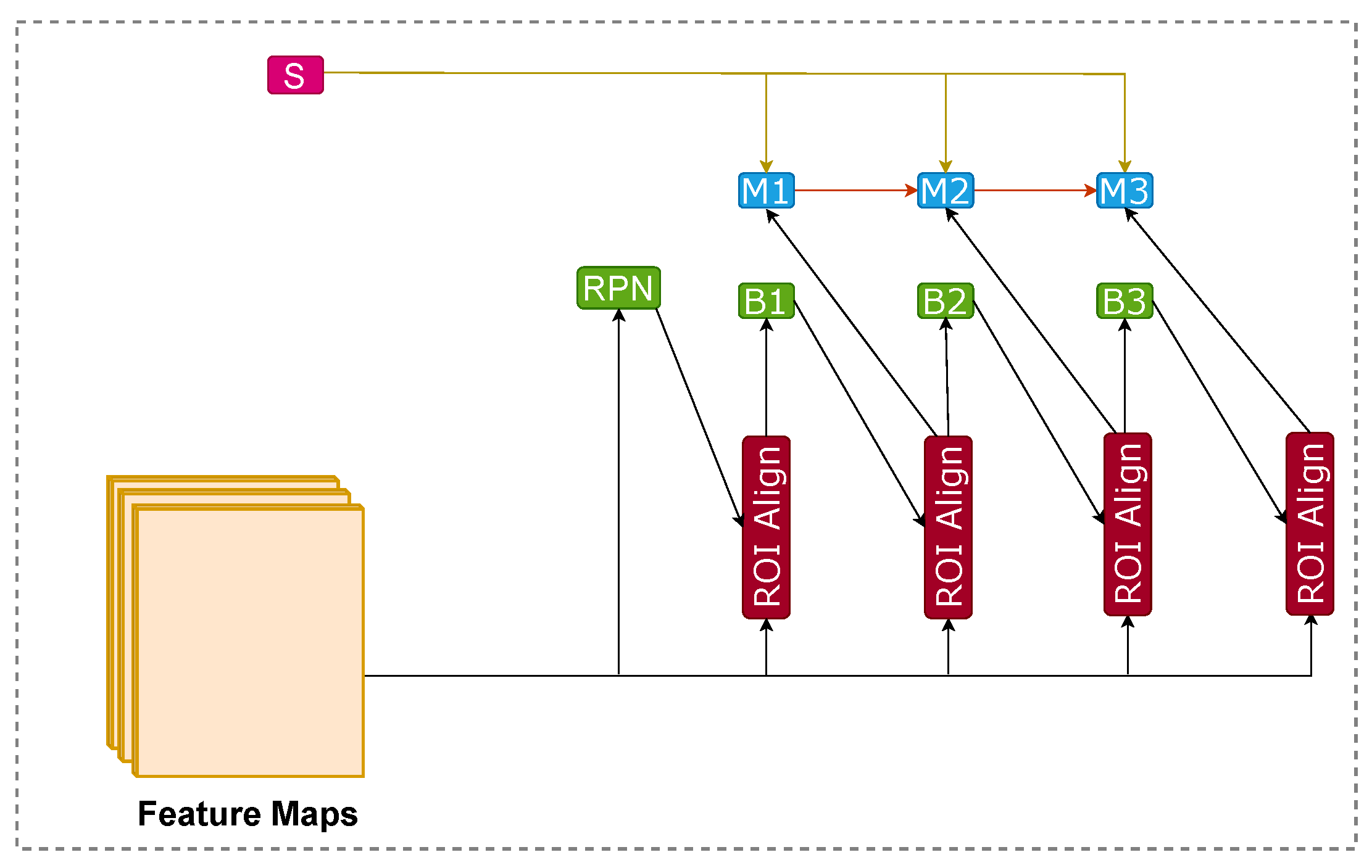
3.3. Hybrid Task Cascade
4. Datasets
4.1. ICDAR-13
4.2. ICDAR-17 POD
4.3. ICDAR-19
4.4. Marmot
4.5. UNLV
4.6. TableBank
5. Evaluation Metrics
5.1. Intersection of Union
5.2. Precision
5.3. Recall
5.4. F1-Score
5.5. Weighted-Average
6. Experiments and Results
6.1. ICDAR-19
6.2. ICDAR-17 POD
6.3. TableBank
6.4. Marmot
6.5. UNLV
6.6. Comparison with State-of-the-Art Approaches
6.6.1. ICDAR-19
6.6.2. ICDAR-17
6.6.3. ICDAR-13
6.6.4. TableBank
6.6.5. Marmot
6.6.6. UNLV
6.7. Leave-One-Out Evaluation
7. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Gao, L.; Yi, X.; Jiang, Z.; Hao, L.; Tang, Z. ICDAR2017 competition on page object detection. In Proceedings of the 2017 14th IAPR International Conference on Document Analysis and Recognition (ICDAR), Kyoto, Japan, 9–15 November 2017; Volume 1, pp. 1417–1422. [Google Scholar]
- Zhao, Z.; Jiang, M.; Guo, S.; Wang, Z.; Chao, F.; Tan, K.C. Improving deep learning based optical character recognition via neural architecture search. In Proceedings of the 2020 IEEE Congress on Evolutionary Computation (CEC), Glasgow, UK, 19–24 July 2020; pp. 1–7. [Google Scholar]
- Hashmi, K.A.; Ponnappa, R.B.; Bukhari, S.S.; Jenckel, M.; Dengel, A. Feedback Learning: Automating the Process of Correcting and Completing the Extracted Information. In Proceedings of the 2019 International Conference on Document Analysis and Recognition Workshops (ICDARW), Sydney, Australia, 22–25 September 2019; Volume 5, pp. 116–121. [Google Scholar]
- Van Strien, D.; Beelen, K.; Ardanuy, M.C.; Hosseini, K.; McGillivray, B.; Colavizza, G. Assessing the Impact of OCR Quality on Downstream NLP Tasks. In Proceedings of the International Conference on Agents and Artificial Intelligence ICAART (1), Valletta, Malta, 22–24 February 2020; pp. 484–496. [Google Scholar]
- Bhatt, J.; Hashmi, K.A.; Afzal, M.Z.; Stricker, D. A Survey of Graphical Page Object Detection with Deep Neural Networks. Appl. Sci. 2021, 11, 5344. [Google Scholar] [CrossRef]
- Schreiber, S.; Agne, S.; Wolf, I.; Dengel, A.; Ahmed, S. Deepdesrt: Deep learning for detection and structure recognition of tables in document images. In Proceedings of the 2017 14th IAPR International Conference on Document Analysis and Recognition (ICDAR), Kyoto, Japan, 9–15 November 2017; Volume 1, pp. 1162–1167. [Google Scholar]
- Siddiqui, S.A.; Malik, M.I.; Agne, S.; Dengel, A.; Ahmed, S. Decnt: Deep deformable cnn for table detection. IEEE Access 2018, 6, 74151–74161. [Google Scholar] [CrossRef]
- Prasad, D.; Gadpal, A.; Kapadni, K.; Visave, M.; Sultanpure, K. CascadeTabNet: An approach for end to end table detection and structure recognition from image-based documents. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 14–19 June 2020; pp. 572–573. [Google Scholar]
- Agarwal, M.; Mondal, A.; Jawahar, C. CDeC-Net: Composite Deformable Cascade Network for Table Detection in Document Images. arXiv 2020, arXiv:2008.10831. [Google Scholar]
- Huang, Y.; Yan, Q.; Li, Y.; Chen, Y.; Wang, X.; Gao, L.; Tang, Z. A YOLO-based table detection method. In Proceedings of the 2019 International Conference on Document Analysis and Recognition (ICDAR), Sydney, Australia, 20–25 September 2019; pp. 813–818. [Google Scholar]
- Gilani, A.; Qasim, S.R.; Malik, I.; Shafait, F. Table detection using deep learning. In Proceedings of the 2017 14th IAPR International Conference on Document Analysis and Recognition (ICDAR), Kyoto, Japan, 9–15 November 2017; Volume 1, pp. 771–776. [Google Scholar]
- Saha, R.; Mondal, A.; Jawahar, C. Graphical object detection in document images. In Proceedings of the 2019 International Conference on Document Analysis and Recognition (ICDAR), Sydney, Australia, 20–25 September 2019; pp. 51–58. [Google Scholar]
- Coüasnon, B.; Lemaitre, A. Recognition of Tables and Forms; HAL: Lyon, France, 2014. [Google Scholar]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. arXiv 2015, arXiv:1506.01497. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Cai, Z.; Vasconcelos, N. Cascade r-cnn: Delving into high quality object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6154–6162. [Google Scholar]
- Paliwal, S.S.; Vishwanath, D.; Rahul, R.; Sharma, M.; Vig, L. Tablenet: Deep learning model for end-to-end table detection and tabular data extraction from scanned document images. In Proceedings of the 2019 International Conference on Document Analysis and Recognition (ICDAR), Sydney, Australia, 20–25 September 2019; pp. 128–133. [Google Scholar]
- Hashmi, K.A.; Stricker, D.; Liwicki, M.; Afzal, M.N.; Afzal, M.Z. Guided Table Structure Recognition through Anchor Optimization. arXiv 2021, arXiv:2104.10538. [Google Scholar]
- Chen, K.; Pang, J.; Wang, J.; Xiong, Y.; Li, X.; Sun, S.; Feng, W.; Liu, Z.; Shi, J.; Ouyang, W.; et al. Hybrid Task Cascade for instance segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 4974–4983. [Google Scholar]
- Dai, J.; Qi, H.; Xiong, Y.; Li, Y.; Zhang, G.; Hu, H.; Wei, Y. Deformable Convolutional Networks. arXiv 2017, arXiv:1703.06211. [Google Scholar]
- Itonori, K. Table structure recognition based on textblock arrangement and ruled line position. In Proceedings of the 2nd International Conference on Document Analysis and Recognition (ICDAR’93), Tsukuba, Japan, 20–22 October 1993; pp. 765–768. [Google Scholar]
- Tupaj, S.; Shi, Z.; Chang, C.H.; Alam, H. Extracting Tabular Information from Text Files; EECS Department, Tufts University: Medford, FL, USA, 1996. [Google Scholar]
- Chandran, S.; Kasturi, R. Structural recognition of tabulated data. In Proceedings of the 2nd International Conference on Document Analysis and Recognition (ICDAR’93), Sukuba, Japan, 20–22 October 1993; pp. 516–519. [Google Scholar]
- Hirayama, Y. A method for table structure analysis using DP matching. In Proceedings of the 3rd International Conference on Document Analysis and Recognition, Montreal, QC, Canada, 14–16 August 1995; Volume 2, pp. 583–586. [Google Scholar]
- Green, E.; Krishnamoorthy, M. Recognition of tables using table grammars. In Proceedings of the Fourth Annual Symposium on Document Analysis and Information Retrieval, Las Vegas, NV, USA, 24–26 April 1995; pp. 261–278. [Google Scholar]
- Kieninger, T.G. Table structure recognition based on robust block segmentation. In Document Recognition V. International Society for Optics and Photonics; SPIE Proceedings: San Jose, CA, USA, 1998; Volume 3305, pp. 22–32. [Google Scholar]
- Casado-García, Á.; Domínguez, C.; Heras, J.; Mata, E.; Pascual, V. The benefits of close-domain fine-tuning for table detection in document images. In International Workshop on Document Analysis Systems; Springer: Berlin/Heidelberg, Germany, 2020; pp. 199–215. [Google Scholar]
- Sun, N.; Zhu, Y.; Hu, X. Faster R-CNN based table detection combining corner locating. In Proceedings of the 2019 International Conference on Document Analysis and Recognition (ICDAR), Sydney, Australia, 20–25 September 2019; pp. 1314–1319. [Google Scholar]
- Vo, N.D.; Nguyen, K.; Nguyen, T.V.; Nguyen, K. Ensemble of deep object detectors for page object detection. In Proceedings of the 12th International Conference on Ubiquitous Information Management and Communication, Langkawi, Malaysia, 5–7 January 2018; pp. 1–6. [Google Scholar]
- Mondal, A.; Lipps, P.; Jawahar, C. IIIT-AR-13K: A new dataset for graphical object detection in documents. In International Workshop on Document Analysis Systems; Springer: Berlin/Heidelberg, Germany, 2020; pp. 216–230. [Google Scholar]
- Hashmi, K.A.; Liwicki, M.; Stricker, D.; Afzal, M.A.; Afzal, M.A.; Afzal, M.Z. Current Status and Performance Analysis of Table Recognition in Document Images with Deep Neural Networks. IEEE Access 2021, 9, 87663–87685. [Google Scholar] [CrossRef]
- Pyreddy, P.; Croft, W.B. Tintin: A system for retrieval in text tables. In Proceedings of the Second ACM International Conference on Digital Libraries, Philadelphia, PA, USA, 23–26 July 1997; pp. 193–200. [Google Scholar]
- Pivk, A.; Cimiano, P.; Sure, Y.; Gams, M.; Rajkovič, V.; Studer, R. Transforming arbitrary tables into logical form with TARTAR. Data Knowl. Eng. 2007, 60, 567–595. [Google Scholar] [CrossRef]
- Hu, J.; Kashi, R.S.; Lopresti, D.P.; Wilfong, G. Medium-independent table detection. In Document Recognition and Retrieval VII. International Society for Optics and Photonics; Proc. SPIE; International Society for Optics and Photonics: San Jose, CA, USA, 1999; Volume 3967, pp. 291–302. [Google Scholar]
- Zanibbi, R.; Blostein, D.; Cordy, J.R. A survey of table recognition. Doc. Anal. Recognit. 2004, 7, 1–16. [Google Scholar] [CrossRef]
- e Silva, A.C.; Jorge, A.M.; Torgo, L. Design of an end-to-end method to extract information from tables. Int. J. Doc. Anal. Recognit. 2006, 8, 144–171. [Google Scholar] [CrossRef]
- Khusro, S.; Latif, A.; Ullah, I. On methods and tools of table detection, extraction and annotation in PDF documents. J. Inf. Sci. 2015, 41, 41–57. [Google Scholar] [CrossRef]
- Embley, D.W.; Hurst, M.; Lopresti, D.; Nagy, G. Table-processing paradigms: A research survey. Int. J. Doc. Anal. Recognit. (IJDAR) 2006, 8, 66–86. [Google Scholar] [CrossRef]
- Kieninger, T.; Dengel, A. The t-recs table recognition and analysis system. In International Workshop on Document Analysis Systems; Springer: Berlin/Heidelberg, Germany, 1998; pp. 255–270. [Google Scholar]
- Oro, E.; Ruffolo, M. TREX: An approach for recognizing and extracting tables from PDF documents. In Proceedings of the 2009 10th International Conference on Document Analysis and Recognition, Barcelona, Spain, 26–29 July 2009; pp. 906–910. [Google Scholar]
- Fan, M.; Kim, D.S. Detecting table region in PDF documents using distant supervision. arXiv 2015, arXiv:1506.08891. [Google Scholar]
- Cesarini, F.; Marinai, S.; Sarti, L.; Soda, G. Trainable table location in document images. Object Recognit. Support. User Interact. Service Rob. 2002, 3, 236–240. [Google Scholar]
- e Silva, A.C. Learning rich hidden markov models in document analysis: Table location. In Proceedings of the 2009 10th International Conference on Document Analysis and Recognition, Barcelona, Spain, 26–29 July 2009; pp. 843–847. [Google Scholar]
- Silva, A. Parts That Add up to a Whole: A Framework for the Analysis of Tables; Edinburgh University: Edinburgh, UK, 2010. [Google Scholar]
- Kasar, T.; Barlas, P.; Adam, S.; Chatelain, C.; Paquet, T. Learning to detect tables in scanned document images using line information. In Proceedings of the 2013 12th International Conference on Document Analysis and Recognition, Washington, DC, USA, 25–28 August 2013; pp. 1185–1189. [Google Scholar]
- Hao, L.; Gao, L.; Yi, X.; Tang, Z. A table detection method for pdf documents based on convolutional neural networks. In Proceedings of the 2016 12th IAPR Workshop on Document Analysis Systems (DAS), Santorini, Greece, 11–14 April 2016; pp. 287–292. [Google Scholar]
- Zeiler, M.D.; Fergus, R. Visualizing and understanding convolutional networks. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2014; pp. 818–833. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Zhong, X.; Tang, J.; Yepes, A.J. Publaynet: Largest dataset ever for document layout analysis. In Proceedings of the 2019 International Conference on Document Analysis and Recognition (ICDAR), Sydney, Australia, 20–25 September 2019; pp. 1015–1022. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multibox detector. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2016; pp. 21–37. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Xie, S.; Girshick, R.; Dollár, P.; Tu, Z.; He, K. Aggregated Residual Transformations for Deep Neural Networks. arXiv 2016, arXiv:1611.05431. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 25, 1097–1105. [Google Scholar] [CrossRef]
- Zhao, Z.Q.; Zheng, P.; Xu, S.T.; Wu, X. Object Detection with Deep Learning: A Review. arXiv 2019, arXiv:1807.05511. [Google Scholar] [CrossRef] [Green Version]
- Jiao, L.; Zhang, F.; Liu, F.; Yang, S.; Li, L.; Feng, Z.; Qu, R. A Survey of Deep Learning-Based Object Detection. IEEE Access 2019, 7, 128837–128868. [Google Scholar] [CrossRef]
- Minaee, S.; Boykov, Y.; Porikli, F.; Plaza, A.; Kehtarnavaz, N.; Terzopoulos, D. Image Segmentation Using Deep Learning: A Survey. arXiv 2020, arXiv:2001.05566. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. arXiv 2015, arXiv:1512.03385. [Google Scholar]
- Nasr, G.E.; Badr, E.; Joun, C. Cross entropy error function in neural networks: Forecasting gasoline demand. In Proceedings of the FLAIRS Conference, Pensacola Beach, FL, USA, 16–18 May 2002; pp. 381–384. [Google Scholar]
- Ruby, U.; Yendapalli, V. Binary cross entropy with deep learning technique for image classification. Int. J. Adv. Trends Comput. Sci. Eng. 2020, 9. [Google Scholar] [CrossRef]
- Göbel, M.; Hassan, T.; Oro, E.; Orsi, G. ICDAR 2013 table competition. In Proceedings of the 2013 12th International Conference on Document Analysis and Recognition, Washington, DC, USA, 25–28 August 2013; pp. 1449–1453. [Google Scholar]
- Gao, L.; Huang, Y.; Déjean, H.; Meunier, J.L.; Yan, Q.; Fang, Y.; Kleber, F.; Lang, E. ICDAR 2019 competition on table detection and recognition (cTDaR). In Proceedings of the 2019 International Conference on Document Analysis and Recognition (ICDAR), Sydney, Australia, 20–25 September 2019; pp. 1510–1515. [Google Scholar]
- Li, M.; Cui, L.; Huang, S.; Wei, F.; Zhou, M.; Li, Z. Tablebank: Table benchmark for image-based table detection and recognition. In Proceedings of the 12th Language Resources and Evaluation Conference, Marseille, France, 11–16 May 2020; pp. 1918–1925. [Google Scholar]
- Fang, J.; Tao, X.; Tang, Z.; Qiu, R.; Liu, Y. Dataset, ground-truth and performance metrics for table detection evaluation. In Proceedings of the 2012 10th IAPR International Workshop on Document Analysis Systems, Gold Coast, Australia, 27–29 March 2012; pp. 445–449. [Google Scholar]
- Yu, J.; Jiang, Y.; Wang, Z.; Cao, Z.; Huang, T. Unitbox: An advanced object detection network. In Proceedings of the 24th ACM international conference on Multimedia, Amsterdam, The Netherlands, 15–19 October 2016; pp. 516–520. [Google Scholar]
- Rezatofighi, H.; Tsoi, N.; Gwak, J.; Sadeghian, A.; Reid, I.; Savarese, S. Generalized intersection over union: A metric and a loss for bounding box regression. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 658–666. [Google Scholar]
- Chen, K.; Wang, J.; Pang, J.; Cao, Y.; Xiong, Y.; Li, X.; Sun, S.; Feng, W.; Liu, Z.; Xu, J.; et al. MMDetection: Open MMLab Detection Toolbox and Benchmark. arXiv 2019, arXiv:1906.07155. [Google Scholar]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. PyTorch: An Imperative Style, High-Performance Deep Learning Library. In Advances in Neural Information Processing Systems 32; Wallach, H., Larochelle, H., Beygelzimer, A., d’Alché-Buc, F., Fox, E., Garnett, R., Eds.; Curran Associates, Inc.: Vancouver, BC, Canada, 2019; pp. 8024–8035. [Google Scholar]
- Lin, T.Y.; Maire, M.; Belongie, S.; Bourdev, L.; Girshick, R.; Hays, J.; Perona, P.; Ramanan, D.; Zitnick, C.L.; Dollár, P. Microsoft COCO: Common Objects in Context. arXiv 2014, arXiv:1405.03129. [Google Scholar]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. arXiv 2017, arXiv:1612.03144. [Google Scholar]
- Shahab, A.; Shafait, F.; Kieninger, T.; Dengel, A. An open approach towards the benchmarking of table structure recognition systems. In Proceedings of the 9th IAPR International Workshop on Document Analysis Systems, Boston, MA, USA, 9–11 June 2010; pp. 113–120. [Google Scholar]
- Zhu, X.; Hu, H.; Lin, S.; Dai, J. Deformable convnets v2: More deformable, better results. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 9308–9316. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Backbone | IOU Threshold | Precision | Recall | F1-Score |
|---|---|---|---|---|
| ResNeXt-101 | 0.5 | 0.954 | 0.953 | 0.953 |
| 0.6 | 0.937 | 0.948 | 0.942 | |
| 0.7 | 0.927 | 0.948 | 0.933 | |
| 0.8 | 0.920 | 0.9331 | 0.927 | |
| 0.9 | 0.895 | 0.905 | 0.901 | |
| W.Avg | 0.923 | 0.934 | 0.928 | |
| ResNet-50 | 0.5 | 0.928 | 0.920 | 0.924 |
| 0.6 | 0.905 | 0.922 | 0.913 | |
| 0.7 | 0.894 | 0.910 | 0.902 | |
| 0.8 | 0.879 | 0.895 | 0.887 | |
| 0.9 | 0.831 | 0.846 | 0.838 | |
| W.Avg | 0.881 | 0.894 | 0.887 |
| Model | IOU Threshold | Precision | Recall | F1-Score |
|---|---|---|---|---|
| HybridTabNet | 0.5 | 0.882 | 0.997 | 0.936 |
| 0.6 | 0.882 | 0.997 | 0.936 | |
| 0.7 | 0.882 | 0.997 | 0.936 | |
| 0.8 | 0.879 | 0.994 | 0.933 | |
| 0.9 | 0.870 | 0.983 | 0.926 | |
| W.Avg | 0.878 | 0.993 | 0.932 |
| Dataset | IOU Threshold | Precision | Recall | F1-Score |
|---|---|---|---|---|
| Latex | 0.5 | 0.977 | 0.983 | 0.980 |
| 0.6 | 0.977 | 0.982 | 0.979 | |
| 0.7 | 0.975 | 0.980 | 0.978 | |
| 0.8 | 0.969 | 0.974 | 0.971 | |
| 0.9 | 0.932 | 0.937 | 0.934 | |
| W.Avg | 0.963 | 0.968 | 0.966 | |
| Word | 0.5 | 0.955 | 0.985 | 0.970 |
| 0.6 | 0.953 | 0.982 | 0.967 | |
| 0.7 | 0.951 | 0.980 | 0.965 | |
| 0.8 | 0.950 | 0.978 | 0.964 | |
| 0.9 | 0.948 | 0.977 | 0.962 | |
| W.Avg | 0.950 | 0.979 | 0.965 | |
| Both | 0.5 | 0.963 | 0.986 | 0.974 |
| 0.6 | 0.961 | 0.984 | 0.972 | |
| 0.7 | 0.959 | 0.982 | 0.970 | |
| 0.8 | 0.955 | 0.978 | 0.967 | |
| 0.9 | 0.938 | 0.960 | 0.949 | |
| W.Avg | 0.953 | 0.976 | 0.965 |
| IOU Threshold | Precision | Recall | F1-Score |
|---|---|---|---|
| 0.5 | 0.962 | 0.961 | 0.956 |
| 0.6 | 0.952 | 0.955 | 0.953 |
| 0.7 | 0.947 | 0.950 | 0.948 |
| 0.8 | 0.934 | 0.938 | 0.936 |
| 0.9 | 0.900 | 0.903 | 0.901 |
| W.Avg | 0.935 | 0.937 | 0.935 |
| IOU Threshold | Precision | Recall | F1-Score |
|---|---|---|---|
| 0.5 | 0.926 | 0.962 | 0.944 |
| 0.6 | 0.914 | 0.949 | 0.931 |
| 0.7 | 0.914 | 0.949 | 0.931 |
| 0.8 | 0.902 | 0.936 | 0.919 |
| 0.9 | 0.792 | 0.822 | 0.807 |
| W.Avg | 0.882 | 0.915 | 0.898 |
| Dataset | Method | IOU | W.Avg | ||||
|---|---|---|---|---|---|---|---|
| 0.5 | 0.6 | 0.7 | 0.8 | 0.9 | |||
| ICDAR-2019-TrackA-Modern | TableRadar [63] | – | 0.969 | 0.957 | 0.951 | 0.897 | 0.940 |
| NLPR-PAL [63] | – | 0.979 | 0.966 | 0.939 | 0.850 | 0.927 | |
| Cascade-TabNet [8] | – | 0.943 | 0.934 | 0.925 | 0.901 | 0.901 | |
| Ours | 0.953 | 0.942 | 0.933 | 0.927 | 0.901 | 0.928 | |
| ICDAR-2017-POD | Fast Detectors [1] | – | 0.921 | – | 0.896 | – | – |
| PAL [1] | – | 0.960 | – | 0.951 | – | – | |
| GOD [12] | – | 0.971 | – | 0.968 | – | – | |
| DeCNT [7] | – | 0.968 | – | 0.952 | – | – | |
| Ours | 0.936 | 0.936 | 0.936 | 0.933 | 0.923 | 0.932 | |
| ICDAR-2013 | Cascade-TabNet [8] | 1.0 | – | – | – | – | – |
| Ours | 1.0 | – | – | – | – | – | |
| TableBank (Latex) | Cascade-TabNet [8] | 0.966 | – | – | – | – | – |
| Ours | 0.980 | 0.980 | 0.978 | 0.971 | 0.934 | 0.9661 | |
| TableBank (Word) | Cascade-TabNet [8] | 0.949 | – | – | – | – | – |
| Ours | 0.970 | 0.967 | 0.965 | 0.964 | 0.962 | 0.965 | |
| TableBank (Both) | Cascade-TabNet [8] | 0.943 | – | – | – | – | – |
| Ours | 0.974 | 0.972 | 0.970 | 0.967 | 0.949 | 0.965 | |
| Marmot | DeCNT [7] | 0.895 | – | – | – | – | – |
| CDeC-Net [9] | 0.952 | – | – | 0.840 | 0.769 | – | |
| Ours | 0.956 | 0.953 | 0.948 | 0.936 | 0.901 | 0.935 | |
| UNLV | GOD [12] | 0.928 | – | – | – | – | – |
| CDeC-Net [9] | 0.938 | 0.883 | – | – | – | – | |
| Ours | 0.944 | 0.931 | 0.931 | 0.919 | 0.807 | 0.898 | |
| Train Dataset | Test Dataset | IOU | W.Avg | ||||
|---|---|---|---|---|---|---|---|
| 0.5 | 0.6 | 0.7 | 0.8 | 0.9 | |||
| UNLV + ICDAR-2013 + TableBank (Both) + Marmot + ICDAR-2017-POD | ICDAR-2019-Modern | 0.823 | 0.808 | 0.787 | 0.767 | 0.706 | 0.770 |
| ICDAR-2019-TrackA-Modern + UNLV + TableBank (Both) + Marmot + ICDAR-2013 | ICDAR-2017-POD | 0.895 | 0.890 | 0.884 | 0.846 | 0.813 | 0.860 |
| ICDAR-2019-TrackA-Modern + UNLV + TableBank (Both) + Marmot + ICDAR-2017-POD | ICDAR-2013 | 0.825 | 0.825 | 0.788 | 0.767 | 0.619 | 0.751 |
| ICDAR-2019-TrackA-Modern + UNLV + TableBank (Word) + Marmot + ICDAR-2017-POD + ICDAR-2013 | TableBank(Latex) | 0.951 | 0.947 | 0.944 | 0.933 | 0.866 | 0.923 |
| ICDAR-2019-TrackA-Modern + UNLV + TableBank (Latex) + Marmot + ICDAR-2017-POD + ICDAR-2013 | TableBank(Word) | 0.932 | 0.926 | 0.922 | 0.917 | 0.906 | 0.919 |
| ICDAR-2019-TrackA-Modern + UNLV + Marmot + ICDAR-2017-POD + ICDAR-2013 | TableBank(Both) | 0.949 | 0.943 | 0.940 | 0.932 | 0.886 | 0.926 |
| ICDAR-2019-TrackA-Modern + UNLV + TableBank (Both) + UNLV + ICDAR-2017-POD | Marmot | 0.962 | 0.960 | 0.956 | 0.949 | 0.929 | 0.949 |
| ICDAR-2017-POD + Marmot + TableBank (Both) + ICDAR-2013 + ICDAR-2019-TrackA-Modern | UNLV | 0.808 | 0.787 | 0.766 | 0.711 | 0.503 | 0.898 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Nazir, D.; Hashmi, K.A.; Pagani, A.; Liwicki, M.; Stricker, D.; Afzal, M.Z. HybridTabNet: Towards Better Table Detection in Scanned Document Images. Appl. Sci. 2021, 11, 8396. https://doi.org/10.3390/app11188396
Nazir D, Hashmi KA, Pagani A, Liwicki M, Stricker D, Afzal MZ. HybridTabNet: Towards Better Table Detection in Scanned Document Images. Applied Sciences. 2021; 11(18):8396. https://doi.org/10.3390/app11188396
Chicago/Turabian StyleNazir, Danish, Khurram Azeem Hashmi, Alain Pagani, Marcus Liwicki, Didier Stricker, and Muhammad Zeshan Afzal. 2021. "HybridTabNet: Towards Better Table Detection in Scanned Document Images" Applied Sciences 11, no. 18: 8396. https://doi.org/10.3390/app11188396
APA StyleNazir, D., Hashmi, K. A., Pagani, A., Liwicki, M., Stricker, D., & Afzal, M. Z. (2021). HybridTabNet: Towards Better Table Detection in Scanned Document Images. Applied Sciences, 11(18), 8396. https://doi.org/10.3390/app11188396