2.1. Machine Learning Algorithms
The goal of ML is to construct a model for making predictions [
22]. There are two essential parts to constructing a model: (1) the Machine Learning Algorithm (MLA) [
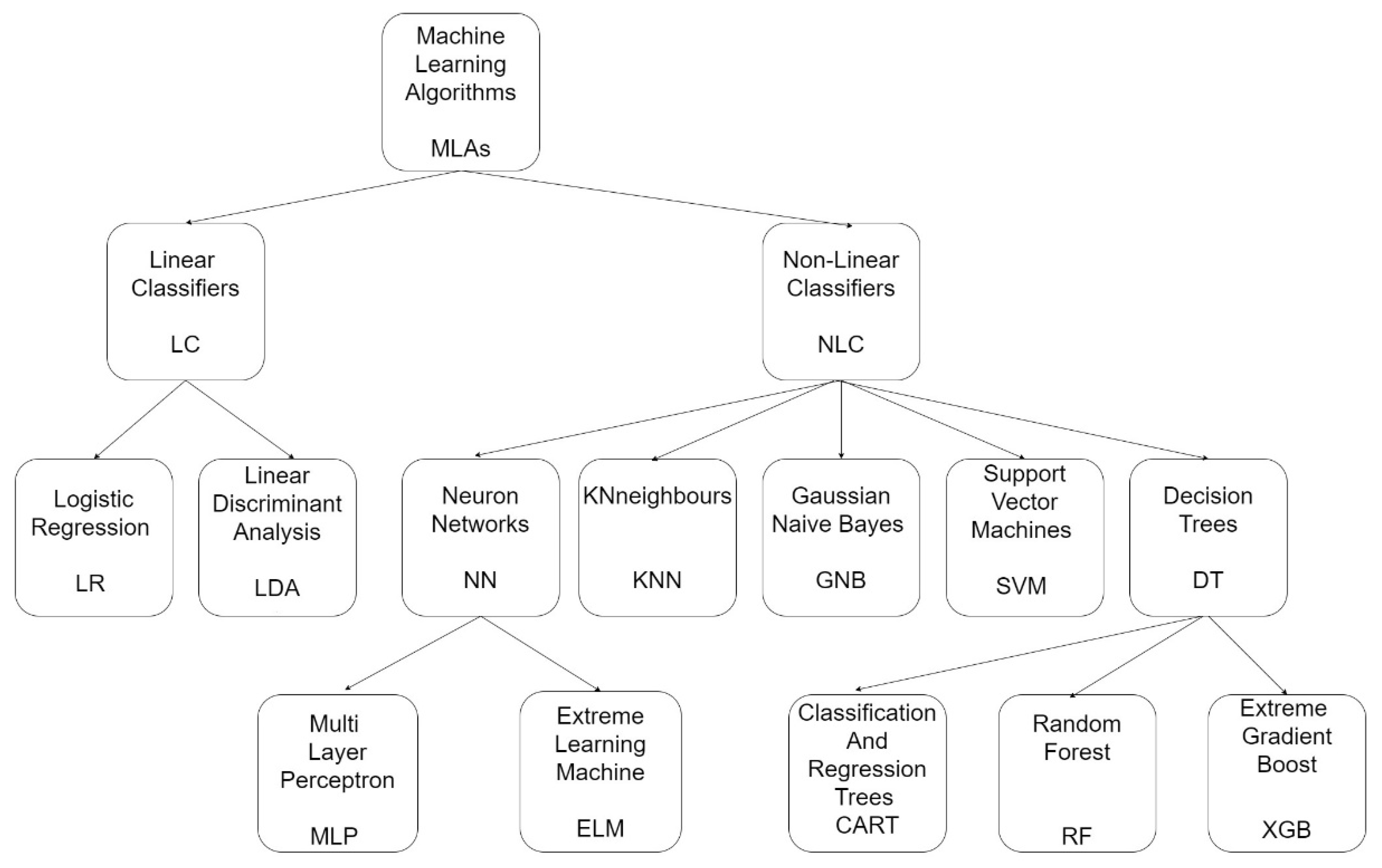
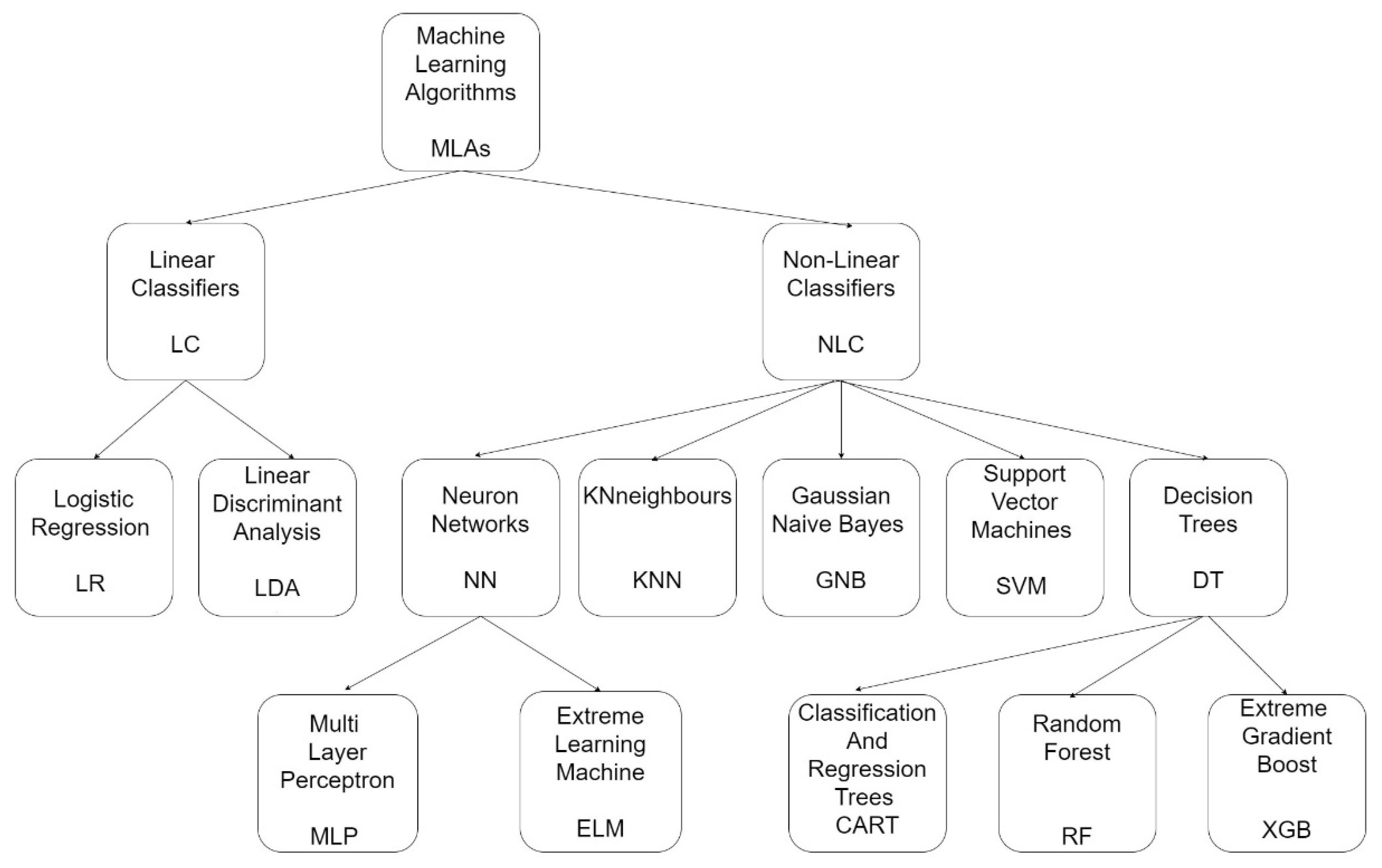
23] and (2) the data. A wide variety of MLAs have been developed since the 1960s, and their improvement has never ceased. The choice of the best-performing algorithm is determined heuristically for a given problem. The best learning algorithm is considered to be the one that has low bias and accurately relates the input to the output values, achieving low variance, meaning that it can successfully predict the same result using different datasets. The latter is also called generalization. Ten MLAs, both linear and non-linear, were used in this study (
Figure 3).
Of the linear algorithms, Logistic Regression (LR) [
24] and Linear Discriminant Analysis (LDA) [
25] were used. The non-linear algorithms tested were k-Nearest Neighbor (kNN) [
26], Gaussian Naive Bayes (GNB) [
27], and Support Vector Machine (SVM) [
28]. Furthermore, Multi-Layer Perceptron (MLP) [
29,
30] and Extreme Learning Machine (ELM) [
31,
32] belonging to the Neural Network Group were evaluated. Finally, decision trees were tested, namely Classification and Regression Trees (CART) [
33], Random Forest (RF) [
34,
35,
36], and Extreme Gradient Boost (XGB) [
37,
38].
2.1.1. Logistic Regression
The LR algorithm [
24] is an extension of the linear regression algorithm [
39], where the goal is to find the ‘line of best fit’ in order to map the relationship between the dependent variable and the independent variables. The LR algorithm predicts whether something belongs to a class or not, i.e., if it is true or false. LR is mainly used for binary classification but can be extended for multiclass classification. In our case, Multinomial Logistic Regression was used.
2.1.2. Linear Discriminant Analysis
LDA is a supervised algorithm which reduces dimensionality. LDA is a two-class classifier but can be generalized for multi-class problems. The linear discriminants are the axes, which maximize the distances of multiple classes [
25].
2.1.3. k-Nearest Neighbor
In the kNN classifier [
26], the distances of the sample points are calculated from a random central point, and each data point is grouped according to this distance. It is regarded as one of the simplest MLAs. The k parameter indicates the number of points that will be taken into account. Larger values create high bias and should be avoided. Another parameter to be selected is the way the distance is computed. Some options are: (1) Euclidean distance, (2) Manhattan distance, and (3) Minkowski distance.
2.1.4. Gaussian Naïve Bayes
The GNB is a probabilistic non-parametric classifier and, as the name implies, is based on Bayes’ theorem [
27].
2.1.5. Support Vector Machine
SVM is a supervised classification technique and was initially developed for binary classification problems. The main idea is that input vectors are mapped in a non-linear way to a very high-dimension feature space. A linear decision surface is constructed in this feature space. When a dataset consisting of three features is trained by an SVM, each point is plotted in the three-dimensional space. The algorithm’s goal is to classify the points by applying three planes. In the case of n features, the points are projected in an n-dimensional space, which cannot be visualized. The algorithm’s goal is to classify the objects by dividing the n-dimensional space with the use of what is known as hyperplanes. Predictions are achieved by projecting new points in these divisions [
28].
2.1.6. Multi-Layer Perceptron
An MLP is a type of feedforward Artificial Neural Network (ANN). ANNs are based on the assumption that the way the human brain operates can be mimicked artificially by creating artificial neurons named perceptrons [
30]. This is achieved by providing input and output data to the algorithm, which tries, by changing the weights of its neurons, to create a function that successfully maps the relationship between the input and the output data. In the case of the MLP, at least three layers are required: the input layer, the hidden layer, and the output layer. Each node is a neuron that uses a non-linear activation function. In this way, the MLP can classify separable non-linear data [
29].
2.1.7. Extreme Learning Machine
ELMs are essentially neural networks with only one hidden layer. According to the original authors [
32], this algorithm performs faster than MLPs with good generalization. In an ELM, the hidden nodes’ learning parameters, such as the input weight and biases, are randomly assigned and, according to the author, no tuning is needed. Furthermore, the output weights are determined by a simple inverse operation [
31]. The only parameter tuned is the number of neurons in the hidden layer.
2.1.8. Classification and Regression Trees
When CART is used, classification of the samples is achieved by the binary partitioning of a feature [
33]. It is not only the ease and robustness of construction that make CART a very attractive classifier. The big advantage is the possibility of interpreting the classification, which is either difficult or not possible at all with the aforementioned classifiers. Another advantage is the ability of classification trees to handle missing data. The disadvantage, however, is the overfitting problem. The tree created works well with the data used to create it but does not perform that well with new data. This is also called low bias–high variance. No parameters are set in this algorithm.
2.1.9. Random Forest
To deal with the overfitting problem of CART, the ensemble classifier RF was developed [
35,
36]. The main idea is to use many trees instead of one. The trees are built by using randomly selected subsets of the original data. The only constraint is that all the vectors must have the same dimensions. This is called bootstrapping. The results obtained from each tree are then put to a vote. The aggregate is the final result. This technique is known as bagging (from bootstrap aggregation) [
34]. The split at each node is made by randomly selecting a subset of features. As the number of trees grows, better generalization is achieved. The parameters that can be set are: (1) the number of trees, (2) the number of features used to make the split at each node, and (3) the function used to measure the effectiveness of the split.
2.1.10. Extreme Gradient Boost
XGB is the latest classifier in the evolution of tree-based classifiers. It introduced tree gradient boosting [
38]. Furthermore, XGB can handle sparse data [
37]. According to the authors, XGB runs 10 times faster than other solutions.
2.2. Data Preparation
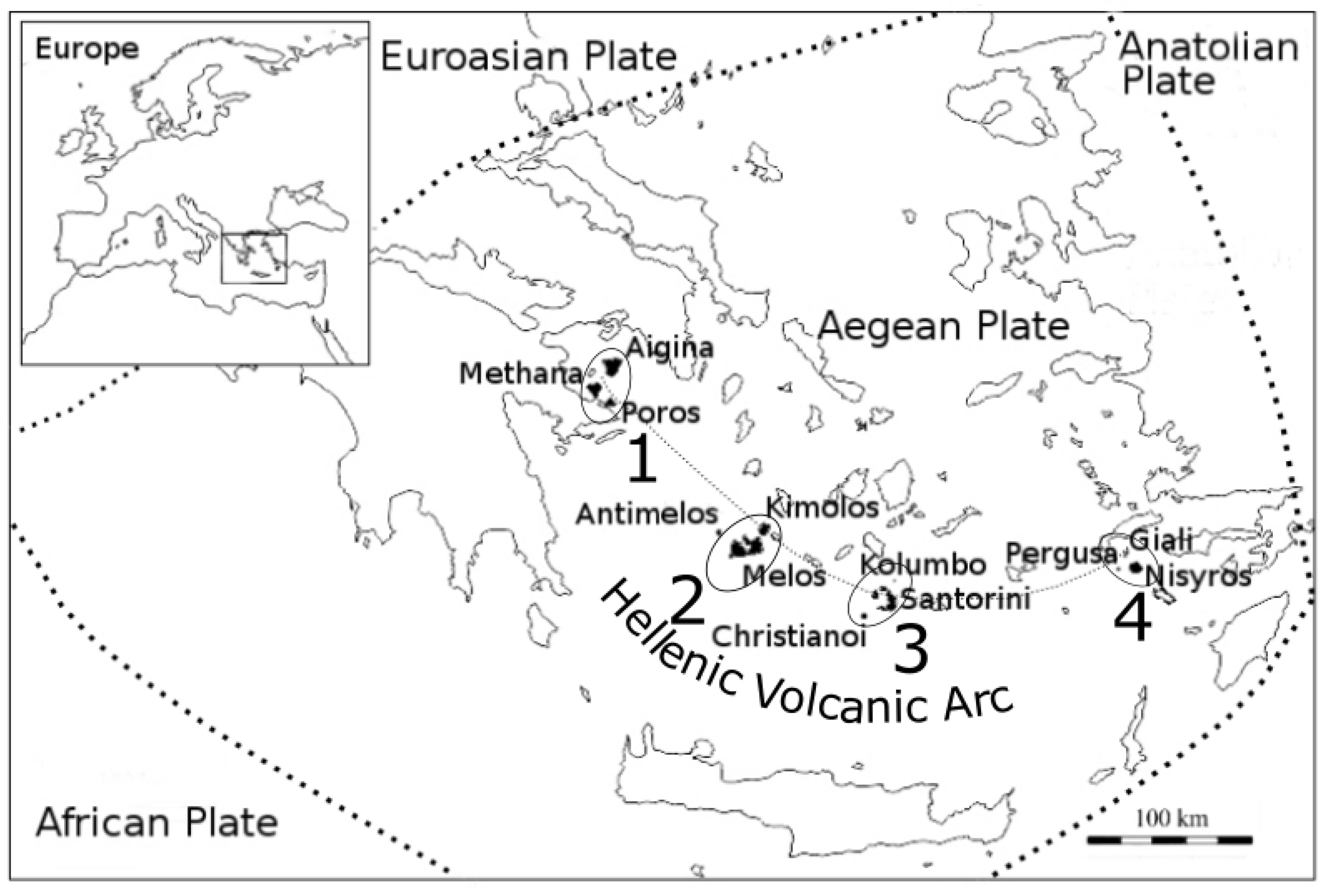
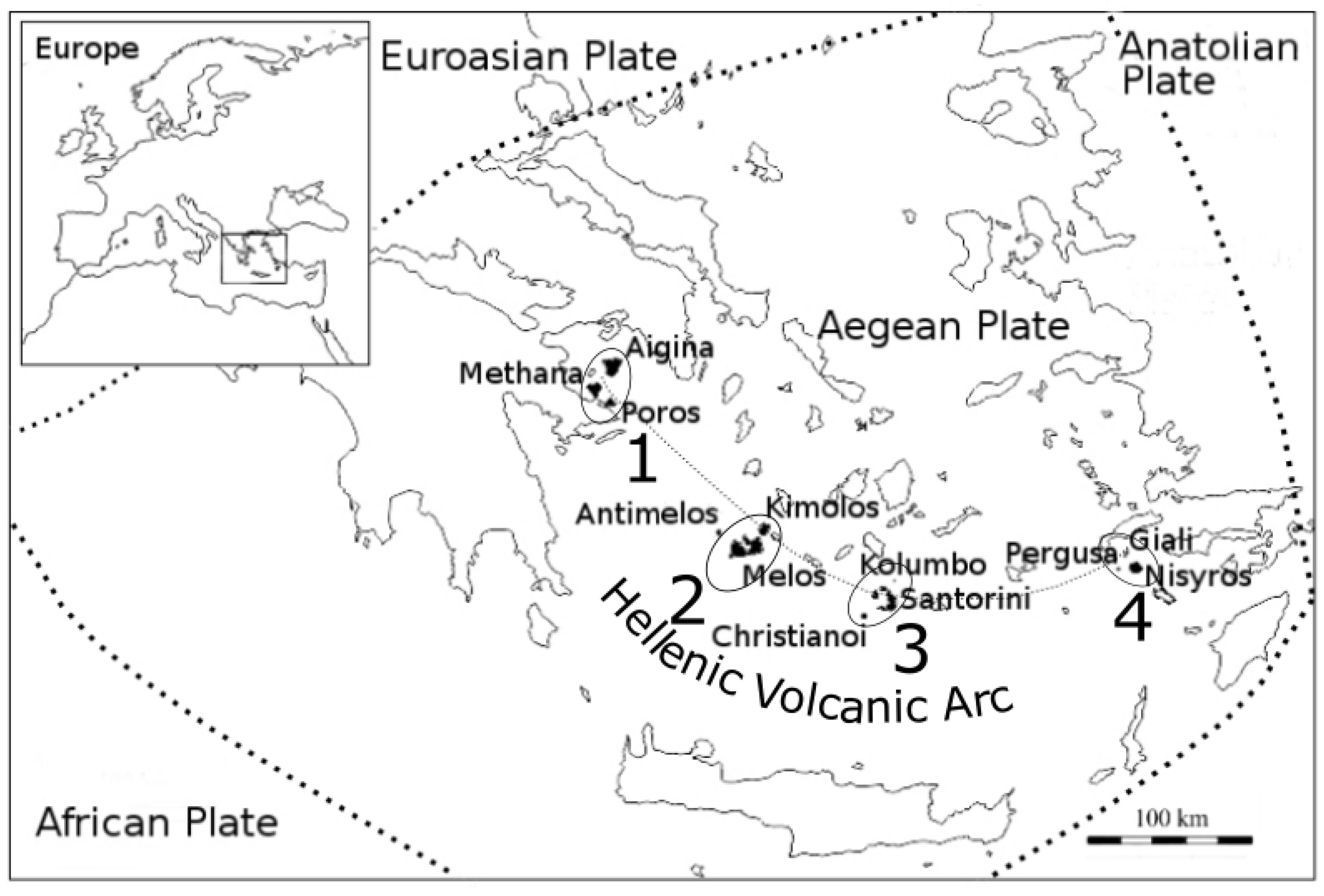
A collection of volcanic rock geochemical data, covering the active volcanic regions (4) of the HVA and most non-active pre-Pliocene volcanic regions (32) of Greece, was retrieved from the GEOROC database [
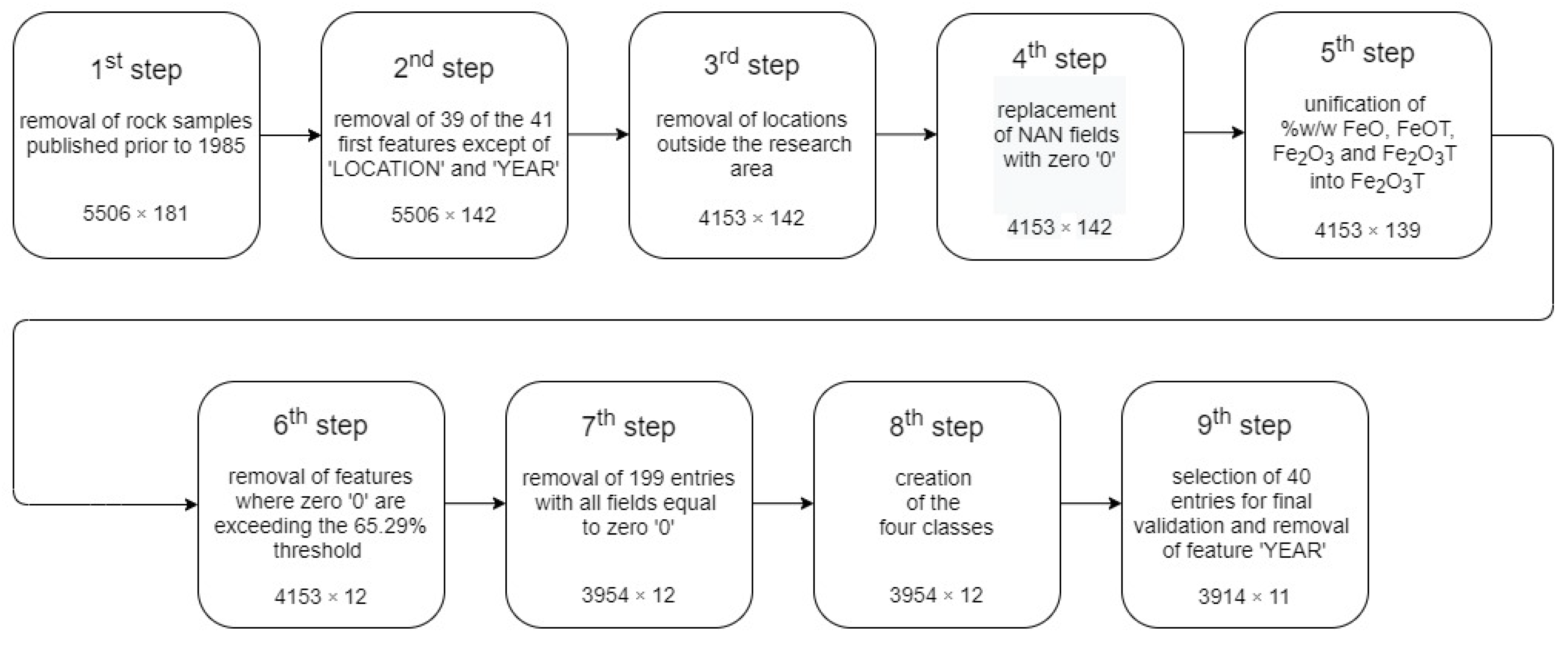
10]. The initial dataset provided consists of 6229 entries containing 181 features. The first 41 features are descriptive and cover general information about the rock samples. Most notable is the year of publication of the rock sample data and the sampling location. Initially, data reduction was performed using the Python libraries Pandas [
40] and Numpy [
41] in nine sequential steps (
Figure 4). In the first step, all rock sample entries published before 1985 [
12] were deleted because analytical methods—the way the chemical composition was analyzed—prior to this year are considered unreliable. This resulted in a new data matrix with the dimensions of 5506 × 181. In the second step, 39 of the first 41 features were deleted. The ‘LOCATION’ feature was preserved, as it was essential for creating the classes in the eighth step. The ‘CITATION’ feature was used to select the validation data in the ninth step. In this way, the data matrix was reduced to 5506 × 142. The first feature represents the location and the second represents the scientific paper where the sample’s chemical composition was published, while the other 140 features contain the geochemical data of the rock samples. The chemical composition is expressed was the mass fraction (wt%) of the major elements, trace elements in parts per million (ppm) or parts per billion (ppb), and isotopes as ratios. In the third step, locations outside the research area were deleted, resulting in a 4153 × 142 data matrix.
Moreover, in the initial dataset, many NAN fields were present, which could be computed by the MLAs; therefore, in the fourth step, these were replaced with zeroes and, consequently, no data matrix dimension change occurred.
The chemical compositions provided by GEOROC were determined using the XRF method. Depending on the methodology used, the iron oxides’ mass fraction (wt%) was provided either in FeO, FeOT, Fe2O3, or Fe2O3T. Thus, in the fifth step, to calculate the mass fraction uniformly, these four features were unified into one (Fe2O3T) through the following procedure: all oxides measured as FeOT were transformed to Fe2O3T by first multiplying the wt% of FeOT’s chemical composition by 1.1111. The chemical composition of FeO was multiplied by 1.1111 to obtain its chemical composition in Fe2O3, then, this value was added to the initial value of Fe2O3, resulting in the Fe2O3T. In this way, the table’s new dimensions were 4153 × 139.
In the sixth step, features where zeroes represented more than 65.29% (this value corresponds to the oxide P
2O
5) were deleted. This was necessary, as features beyond this threshold had zero values higher than 90%, making them useless for the training process of a ML model. This produced a 4153 × 12 data matrix. In the seventh stage, 199 entries had to be deleted as all 10 of their geochemical data fields were equal to zero. The emerging new data matrix’s dimensions were 3954 × 12. In the eighth step, the classes were prepared based on the four volcanic groups of the HVA [
1,
2]. Methana along with Aigina and Paros were labeled as Class 1. Melos together with Antimelos and Kimolos were labeled as Class 2. Santorini with Christianoi and Kolumbo were labeled as Class 3, and finally, Nisyros with Giali, and Pergoussa were labeled as Class 4.
In the final ninth step, 40 entries were randomly handpicked from the dataset to compile the validation dataset. This was done with the following constrains: 10 samples from each class, with each sample from a different publication and year. Furthermore, the ‘CITATION’ feature was removed, as it was no longer needed. This resulted in a 3914 × 11 matrix dimension for the final dataset.
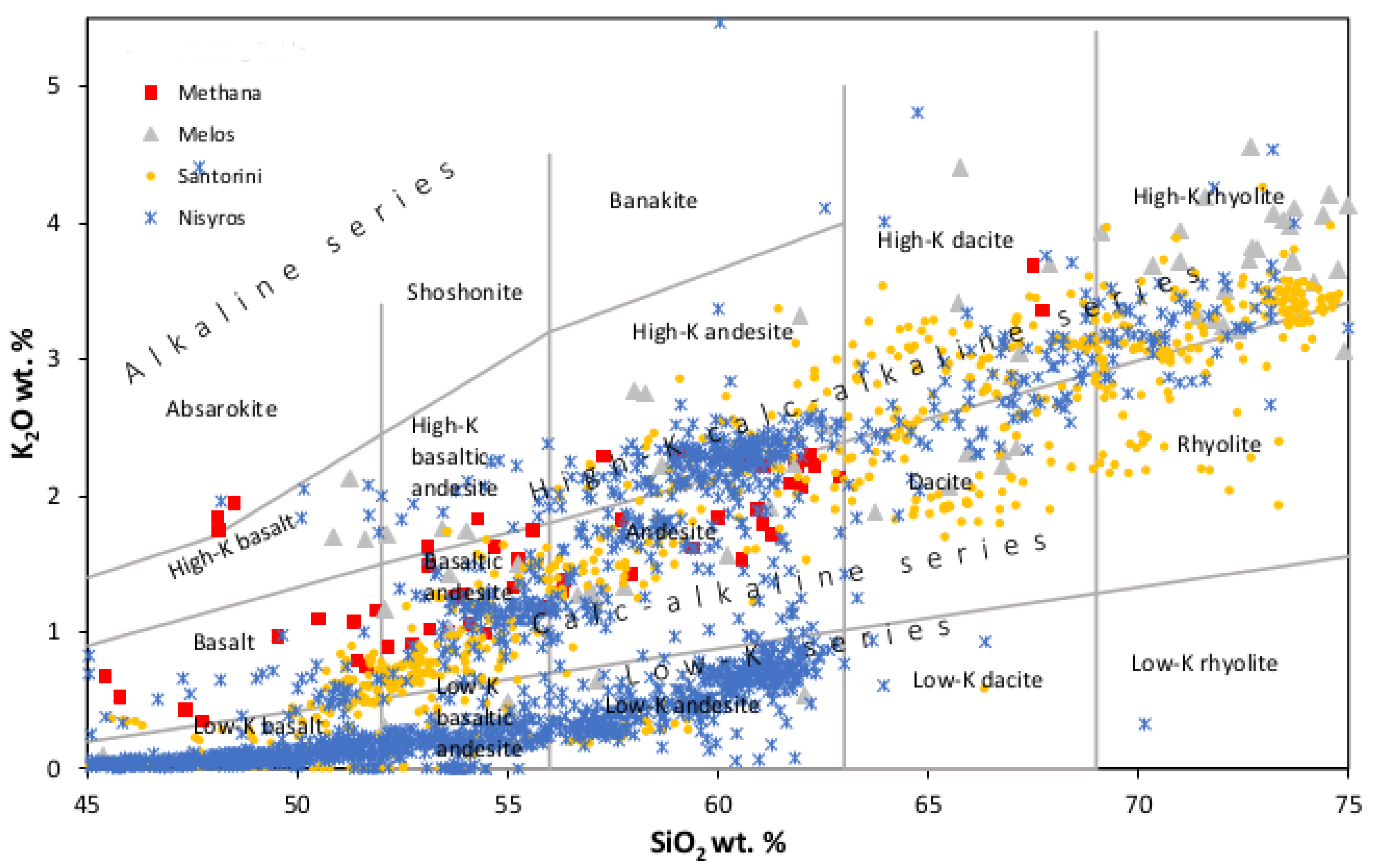
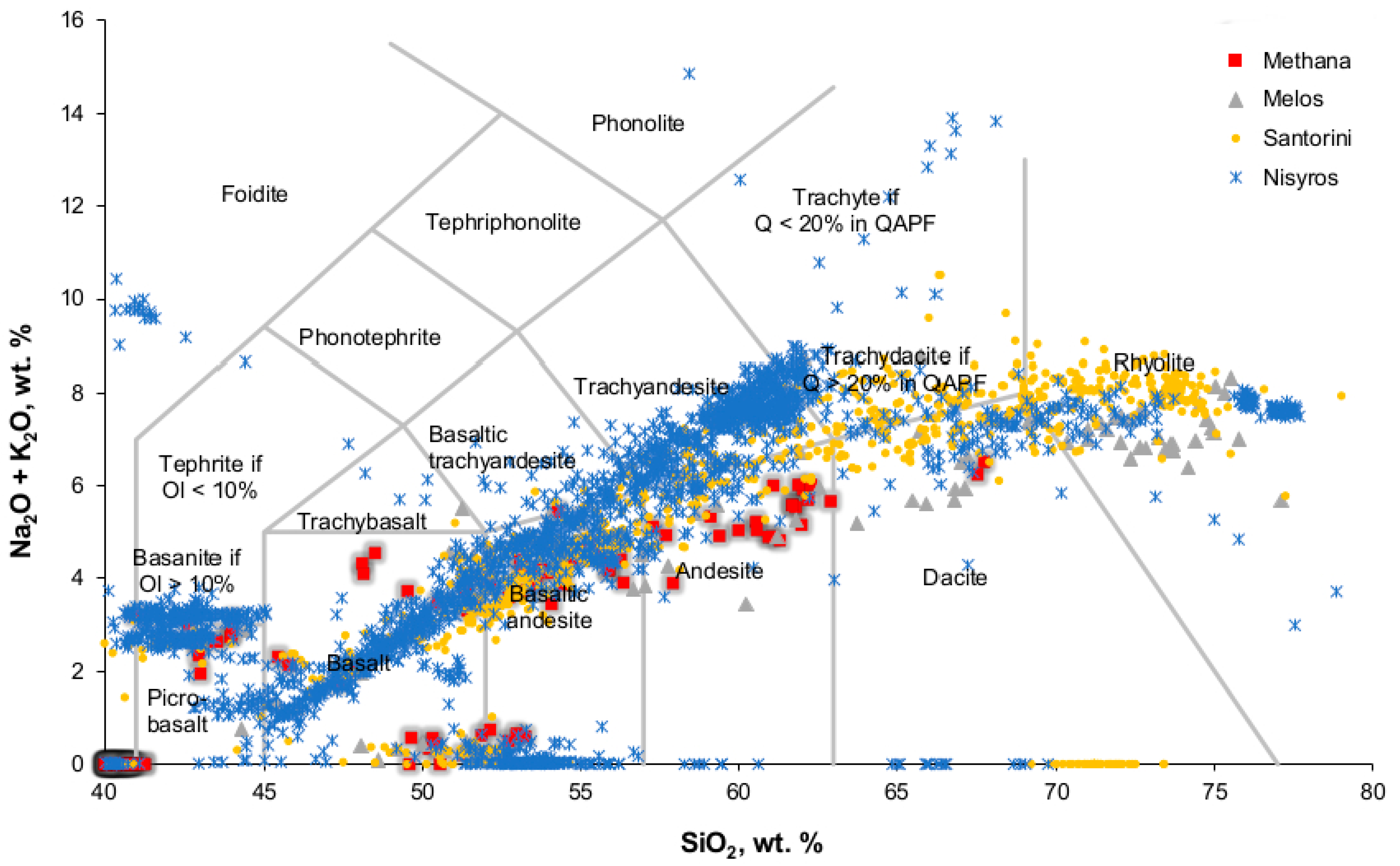
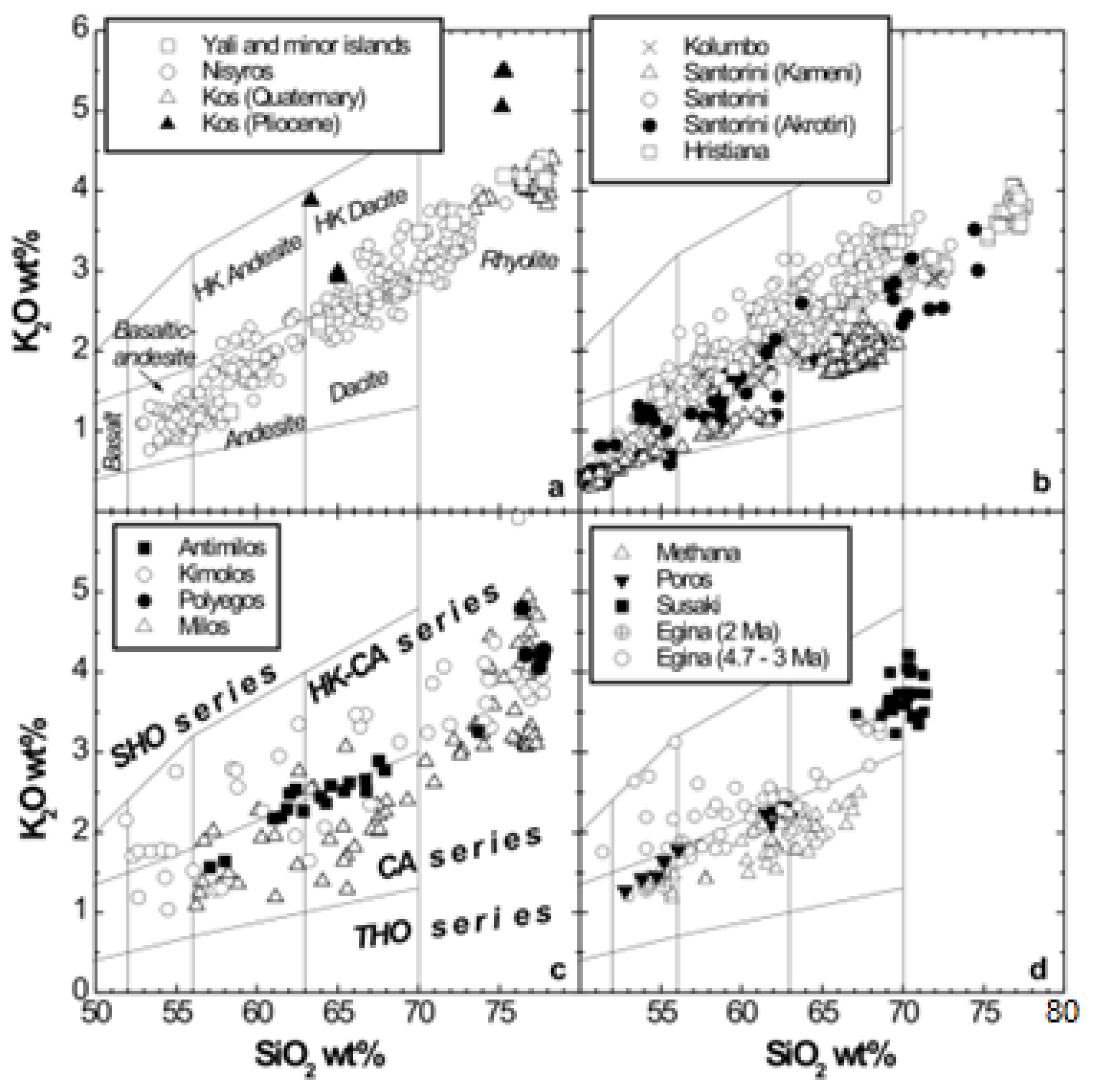
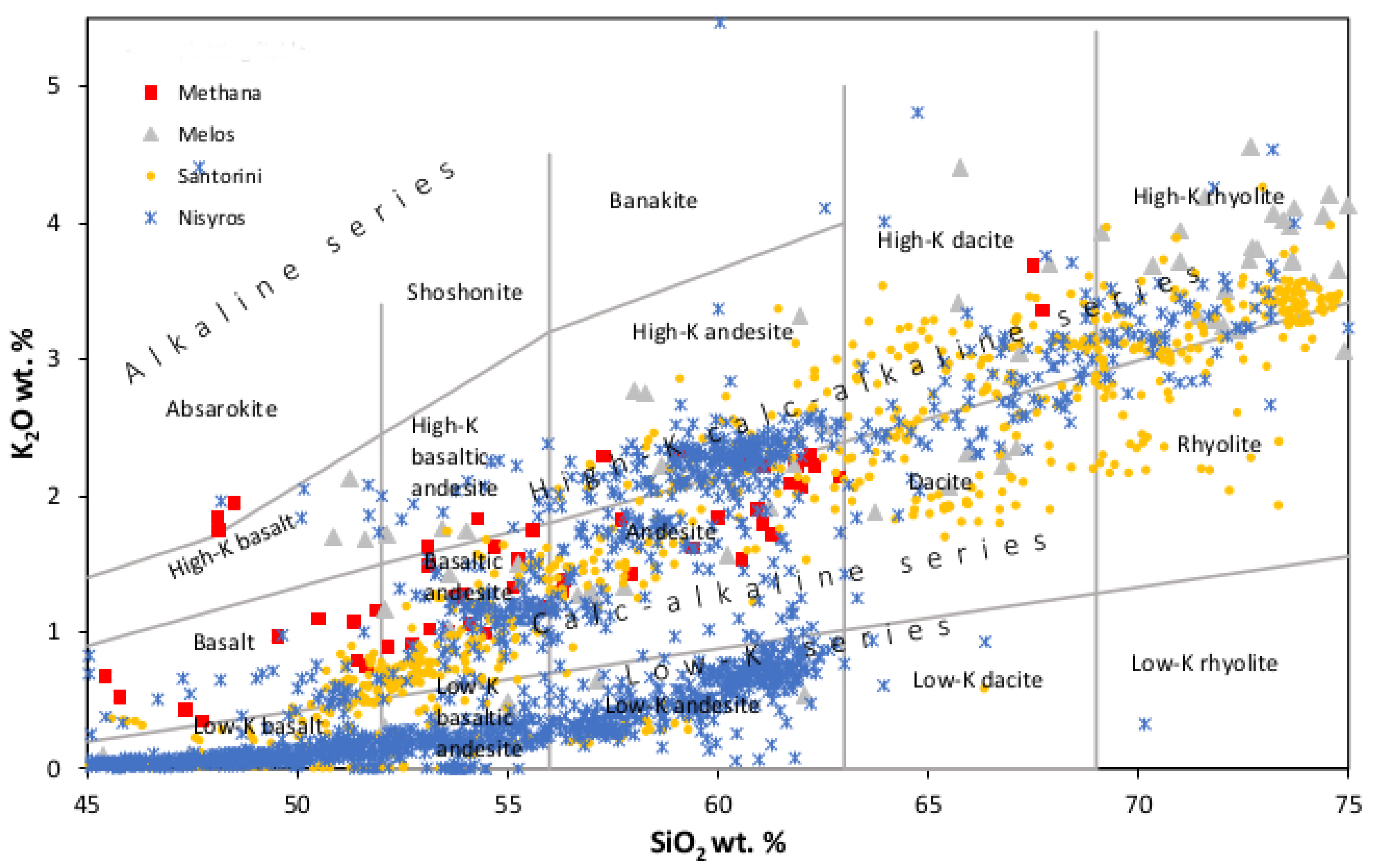
Following data reduction, six datasets (All datasets are available upon request) were created. The initial dataset was labeled Dataset 1 and consisted of 3914 entries and 11 features. The first 10 features were the geochemical data of the major elements and the last was the class. A snapshot of Dataset 1, the initial dataset, is shown in
Table 1. These 3914 data samples were used to plot SiO
2 vs. K
2O [
42] (
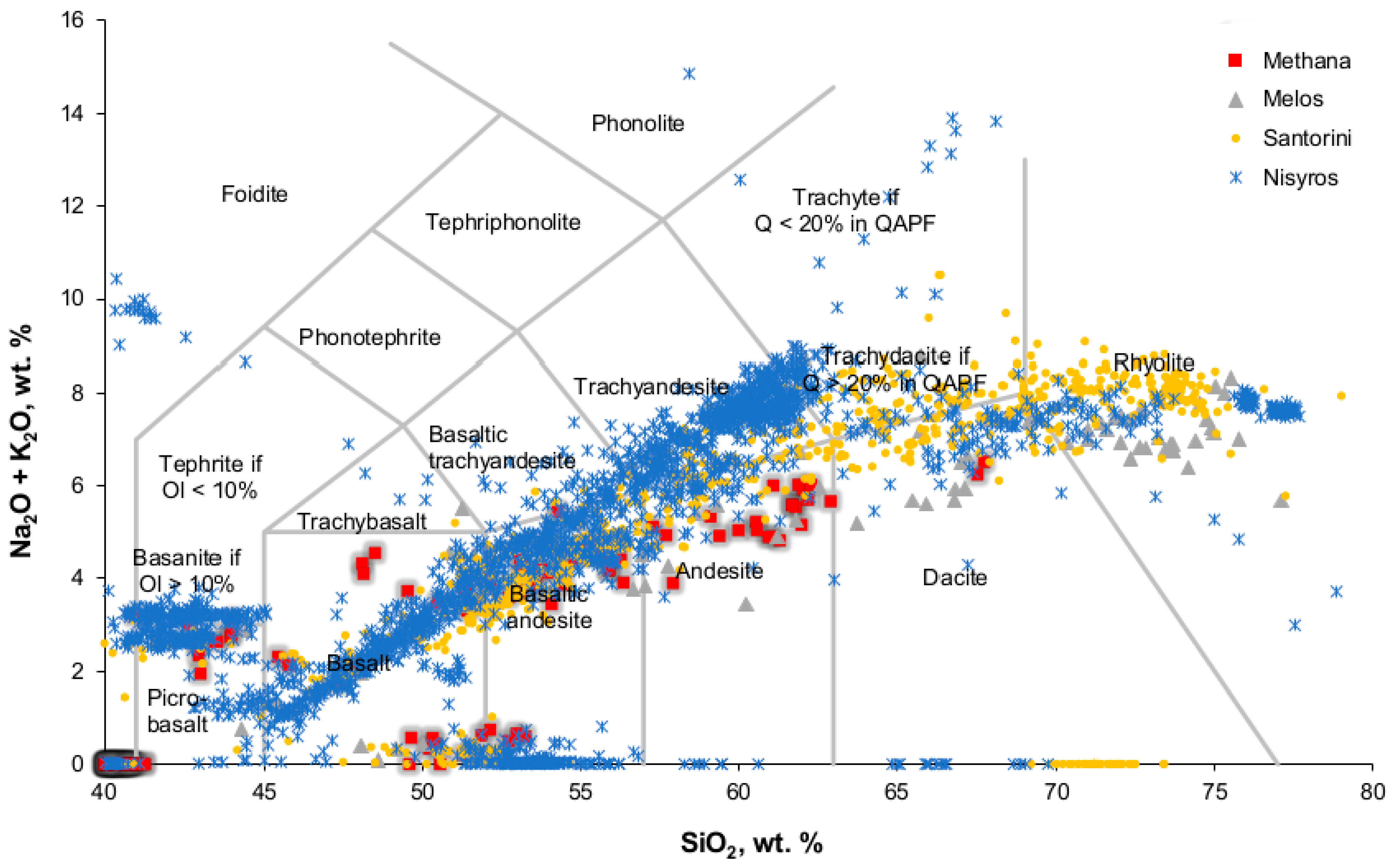
Figure 5) and SiO
2 vs. Na
2O + K
2O [
43] (
Figure 6) to check if the four volcanic regions could be discriminated by the use of this bigger dataset. The diagrams show that this was not the case, as major overlapping of the sample points was present. In Dataset 2, the zeroes were replaced by the mean value. In Dataset 3, the zeroes were replaced by the median. Datasets 4–6 were created from Datasets 1–3 correspondingly by deleting the outliers. The outliers were removed by using the stats class of the Scipy library and the Numpy library. The number of entries of each class in every dataset is shown in
Table 2. The basic statistic data of Datasets 1–6 are presented in
Table 3,
Table 4,
Table 5,
Table 6,
Table 7 and
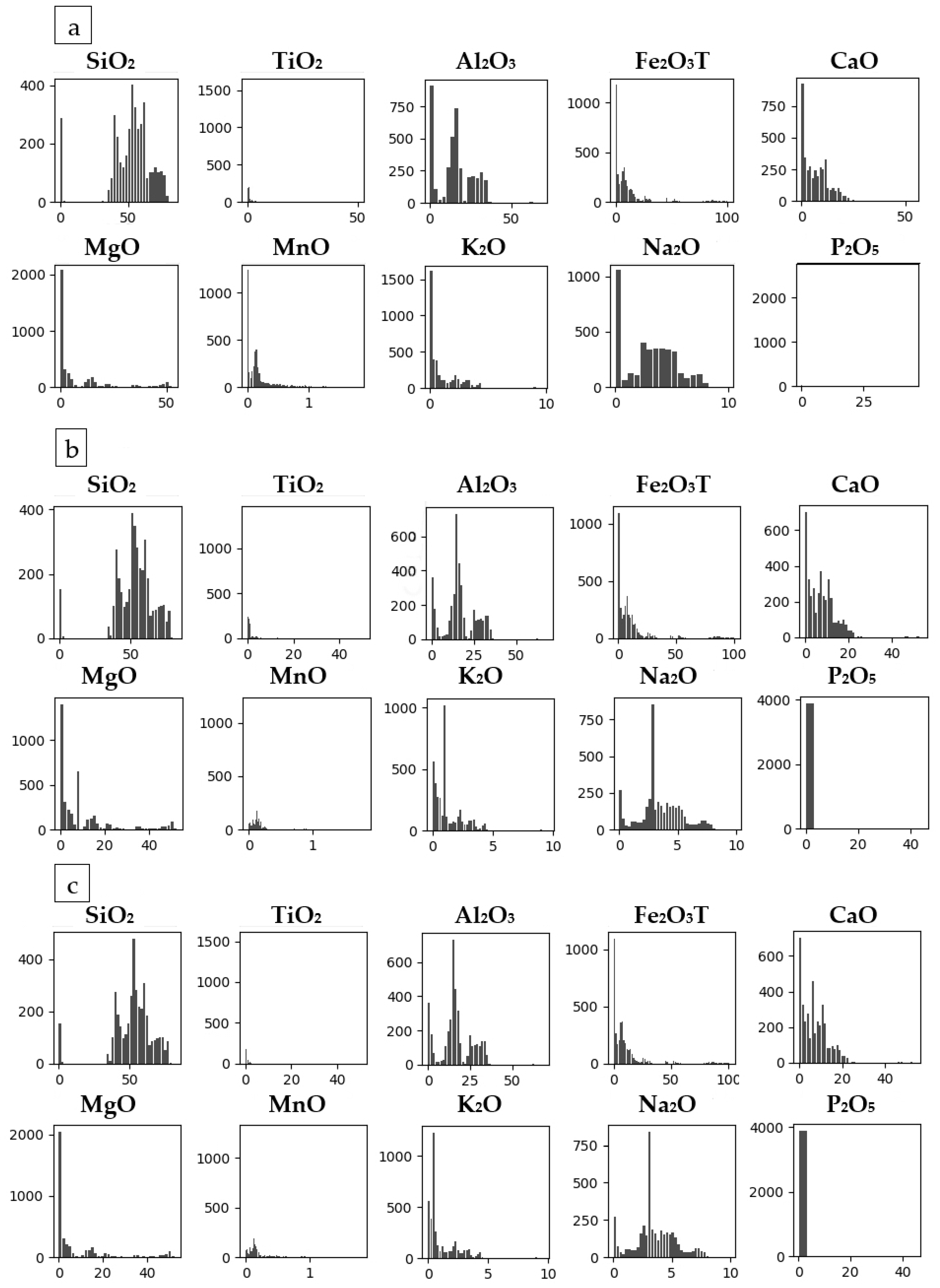
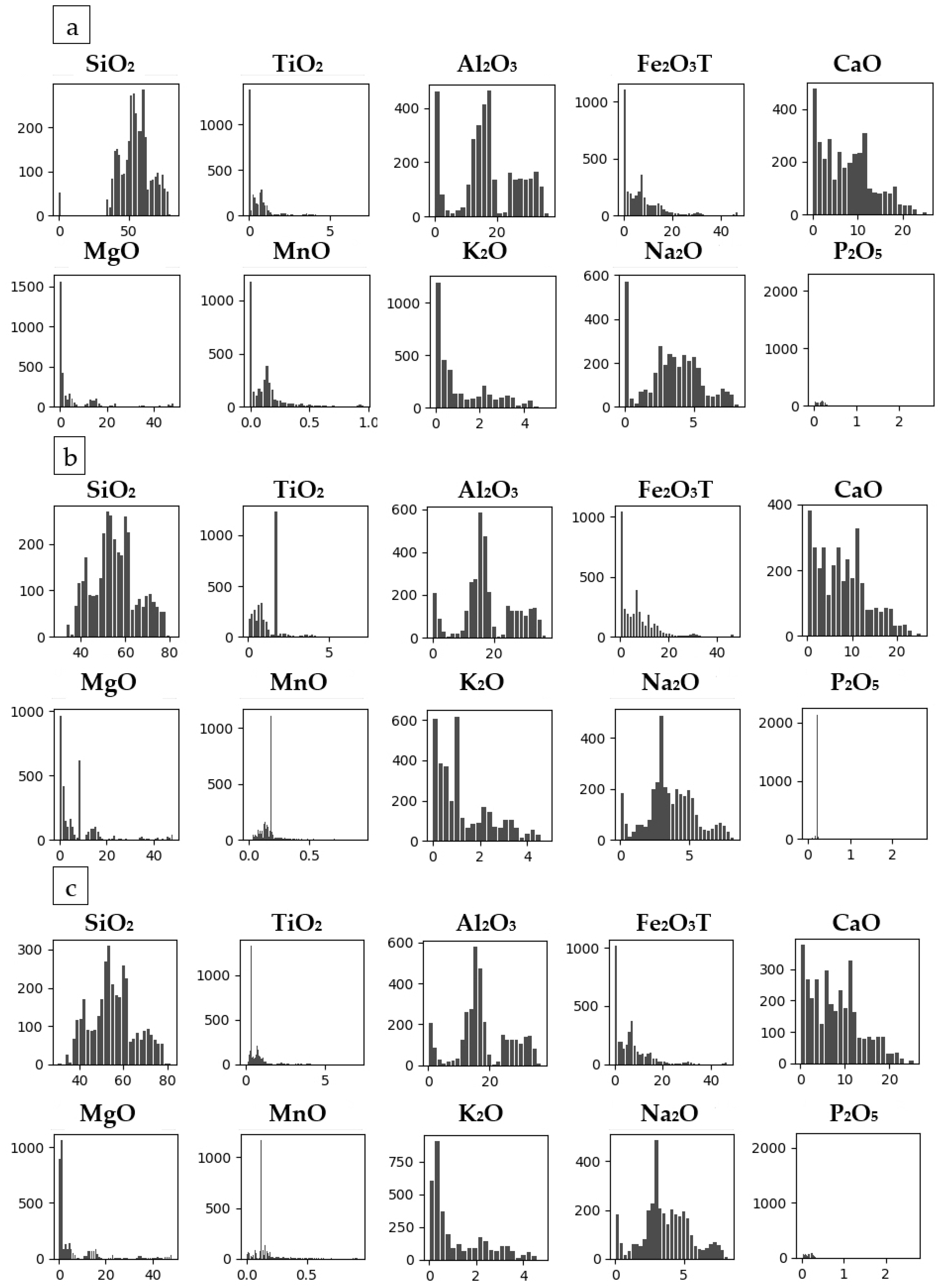
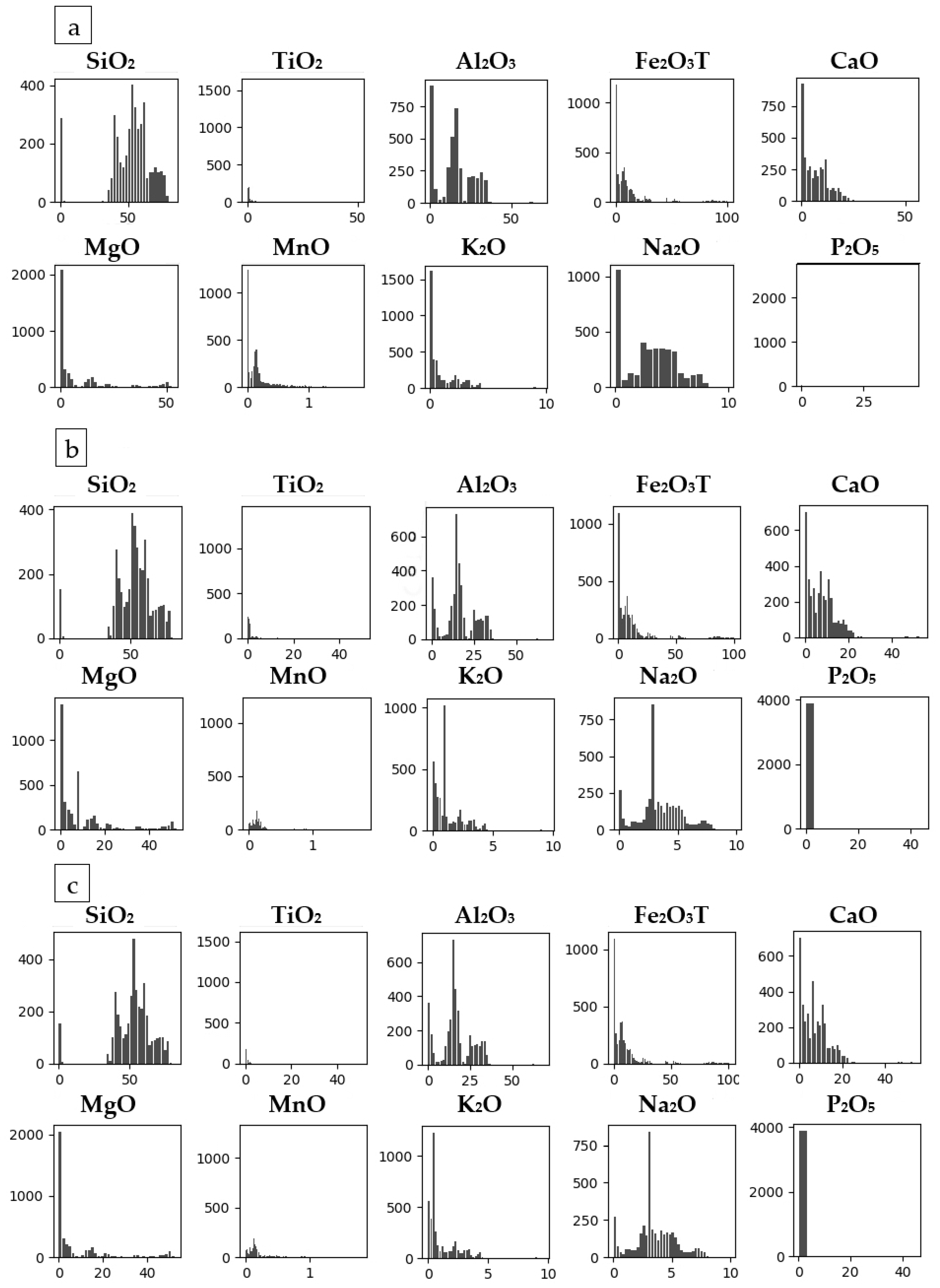
Table 8. The histograms of Datasets 1–3 with outliers are depicted in
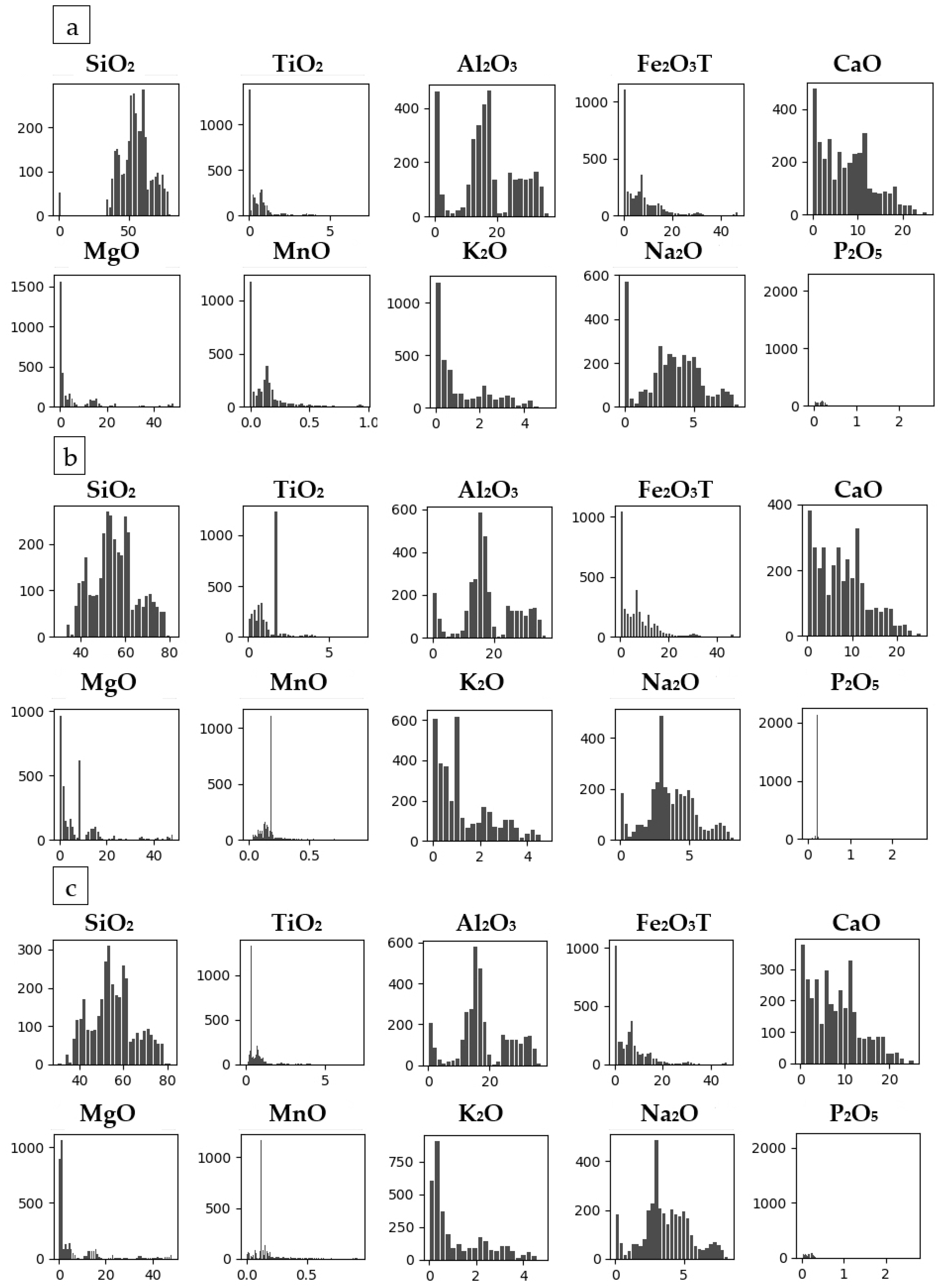
Figure 7. The histograms of Datasets 4–6 with the outliers removed are depicted in
Figure 8. The histogram of Dataset 5 shows the best distribution of the data.
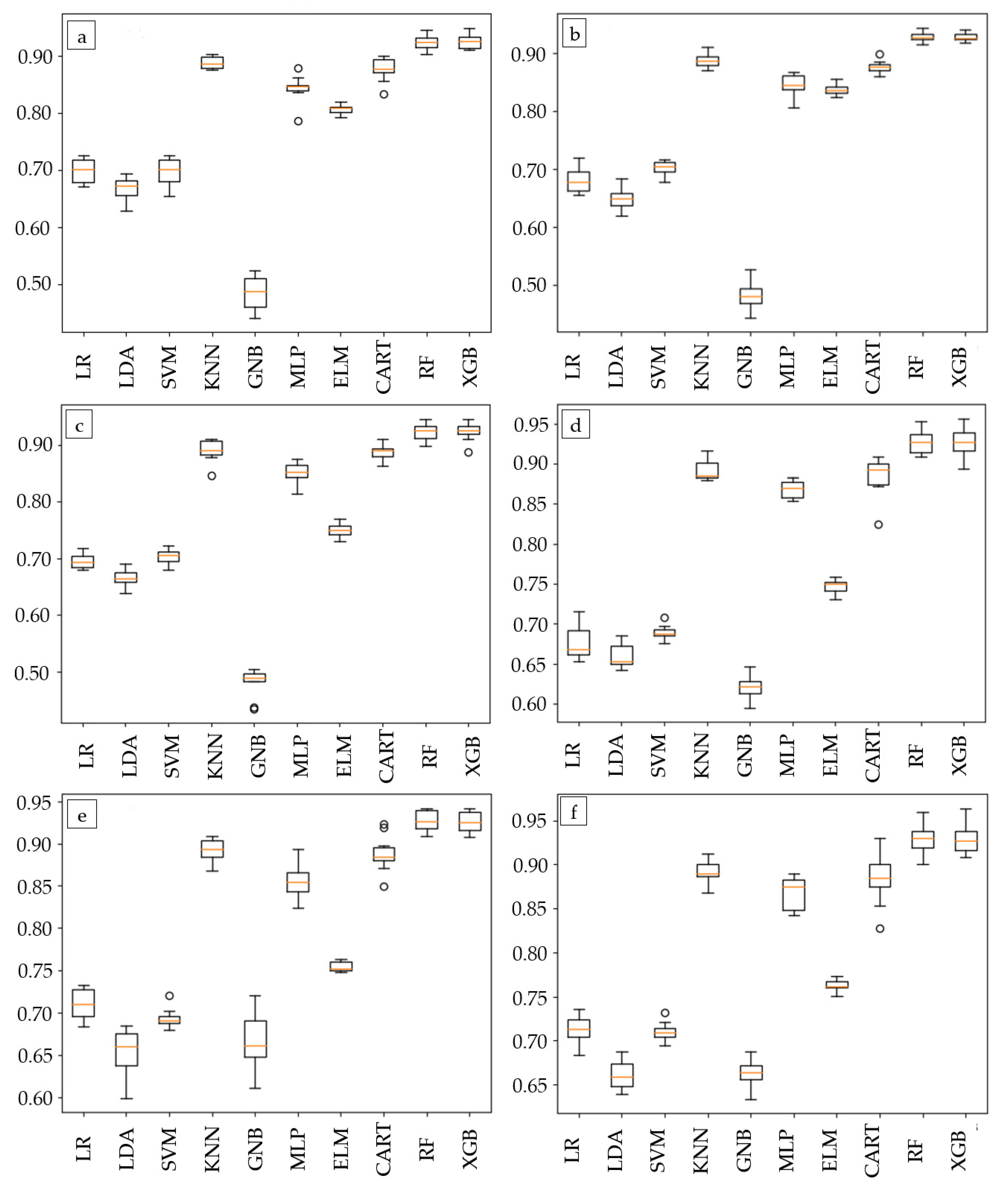
2.3. Simulations
The training of the models was implemented using Python 3.8 (Guido van Rossum, The Hague, The Netherlands) [
44] joint with Scikit-learn (David Cournapeau, Paris, France) [
45], the xGboost wrapper for Scikit-learn(
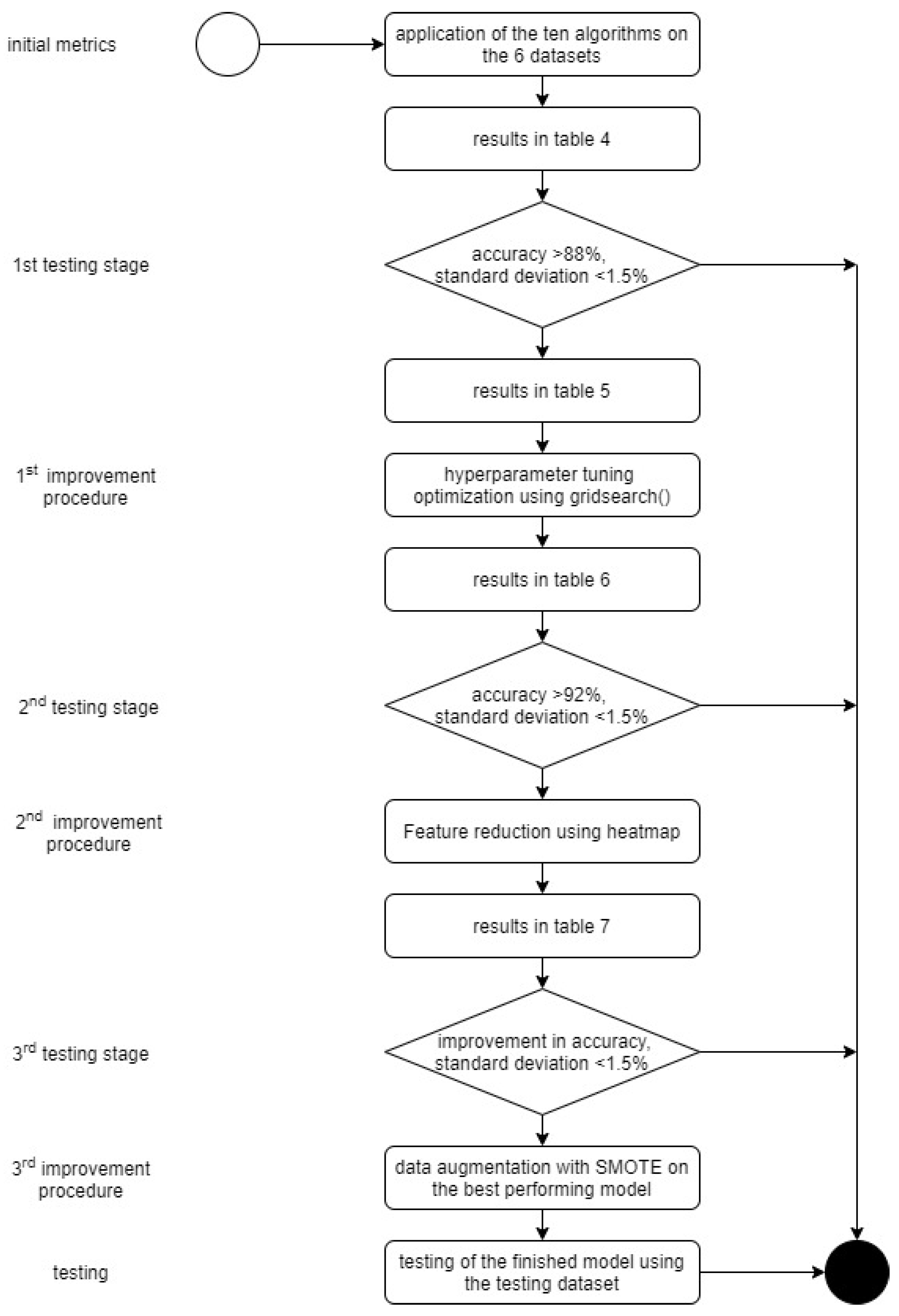
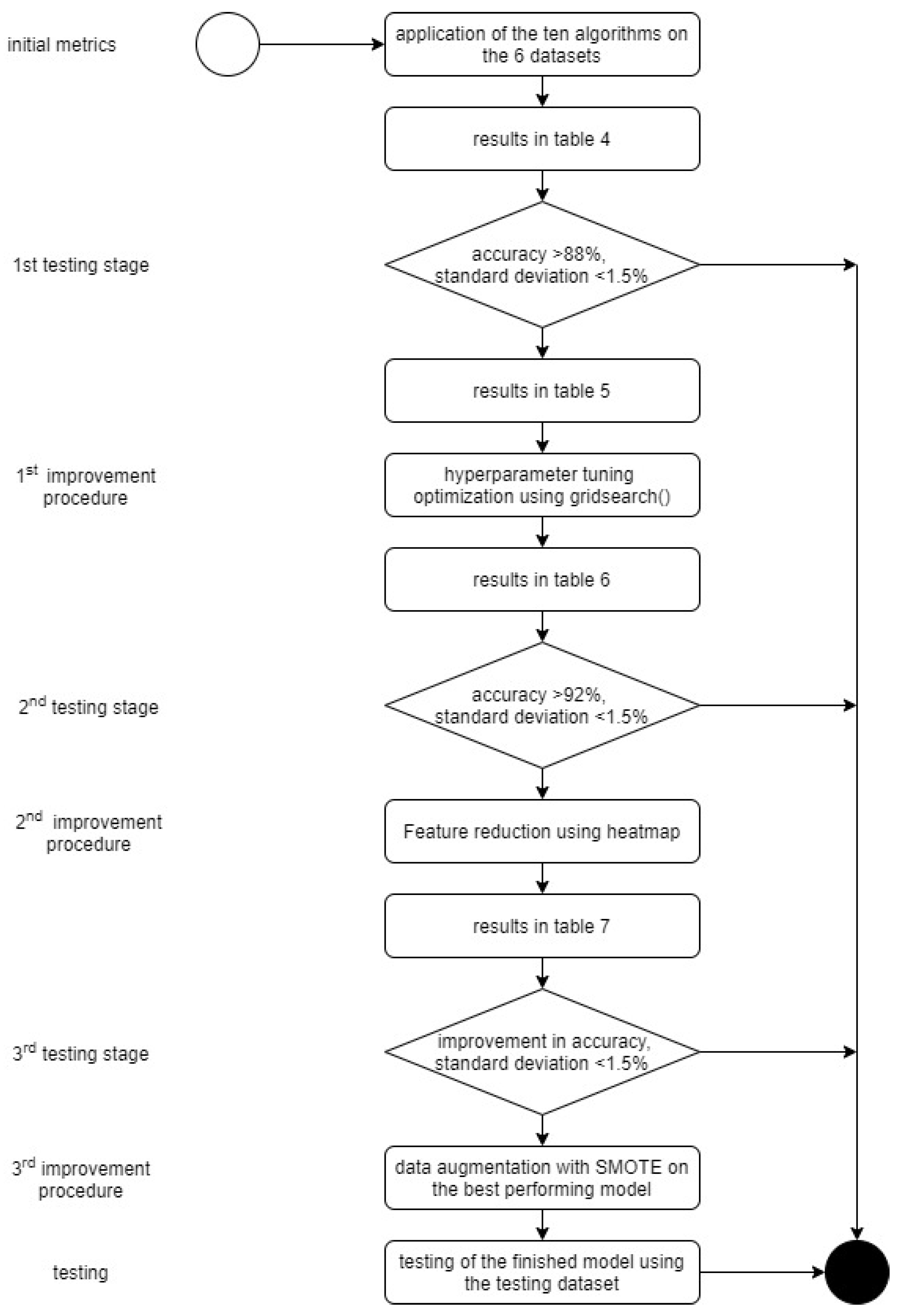
https://xgboost.readthedocs.io/, accessed on 30 June 2021) and elm.ELM Kernel (Augusto Almeida, Brazil). The goal was to create the most accurate model, with the smallest standard deviation and the least computing time, by using one out of the 10 MLAs and one of the six datasets. Training of the model was conducted on a Windows 10 System with an Intel Core 2 Quad Q8400 CPU and 8 GB of RAM. Tenfold cross-validation was applied (i.e., the original sample was randomly partitioned into 10 equal size subsamples). The datasets were split randomly into 70% training data and 30% testing data. In this way, the experiments were repeated 10 times by using 10 different versions of the dataset. Finally, three stages of testing and three improvement procedures were applied (
Figure 9).
The initial metrics were computed by using the six datasets on the 10 algorithms with their default parameters.
The threshold values for the first testing stage were an accuracy of >88% and a standard deviation of <1.5%. In the following initial improvement procedure, a grid search was applied to the MLAs of the models passing the first testing stage to optimize the selected model’s algorithms.
The second testing stage had a threshold accuracy of >92% and the standard deviation remained at <1.5%. The models outperforming all the others were then put into the second improvement procedure, where feature reduction was applied using the results of a heatmap.
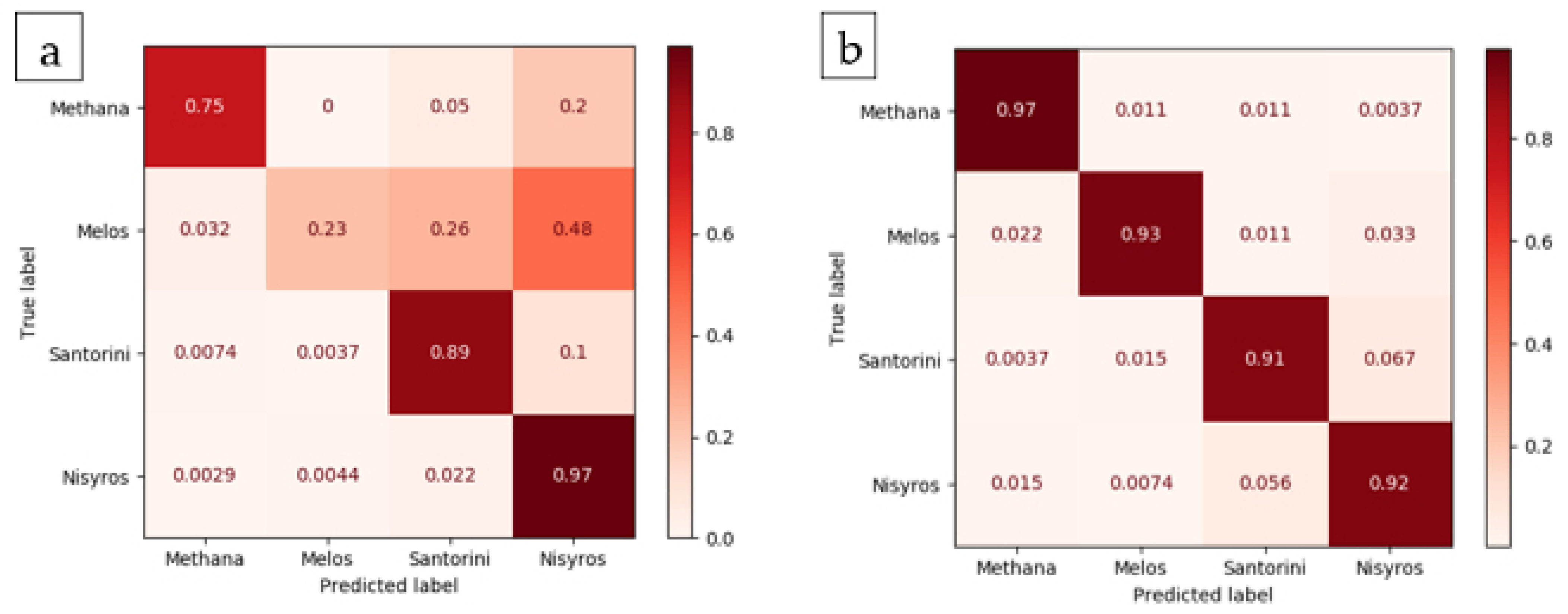
In the third testing stage, the goal was to improve accuracy by keeping the standard deviation of <1.50%. Following this, a confusion matrix [
46] was compiled for the best-performing model. This revealed that a third improvement procedure was necessary to augment the data. Namely, the Synthetic Minority Over-sampling Technique (SMOTE) [
47] was applied to the best-performing model’s dataset. Finally, the best-performing model was tested using the testing data, i.e., the 40 entries left out of the training and validation.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}