
Domain Adaptation Network with Double Adversarial Mechanism for Intelligent Fault Diagnosis




Abstract
:1. Introduction
- (1)
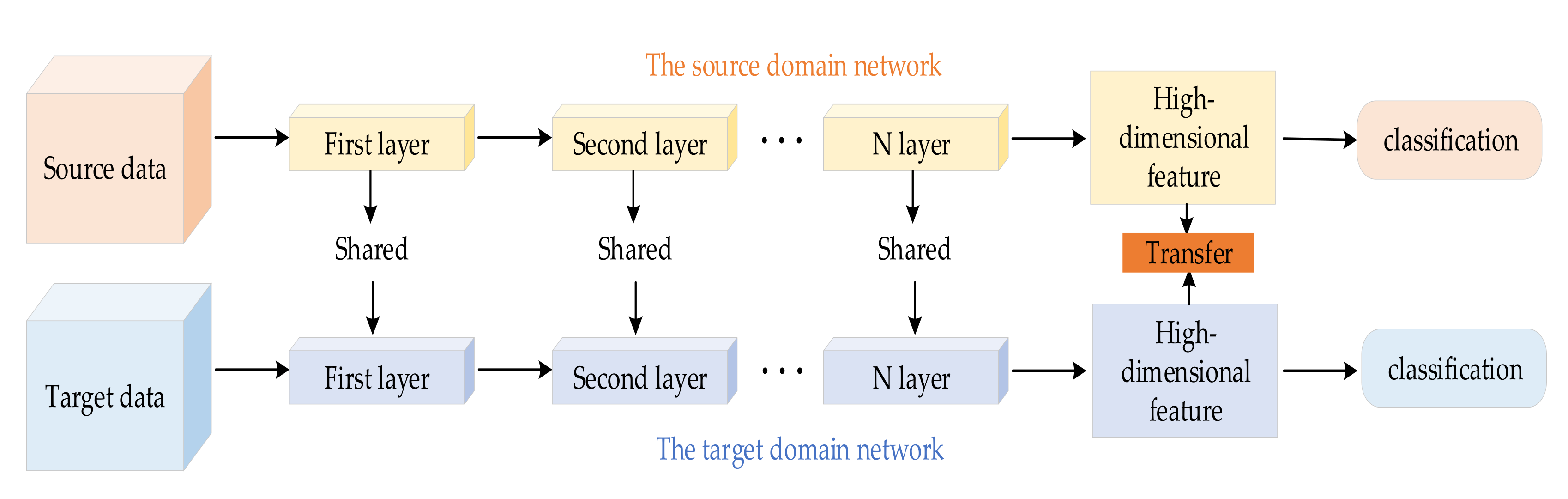
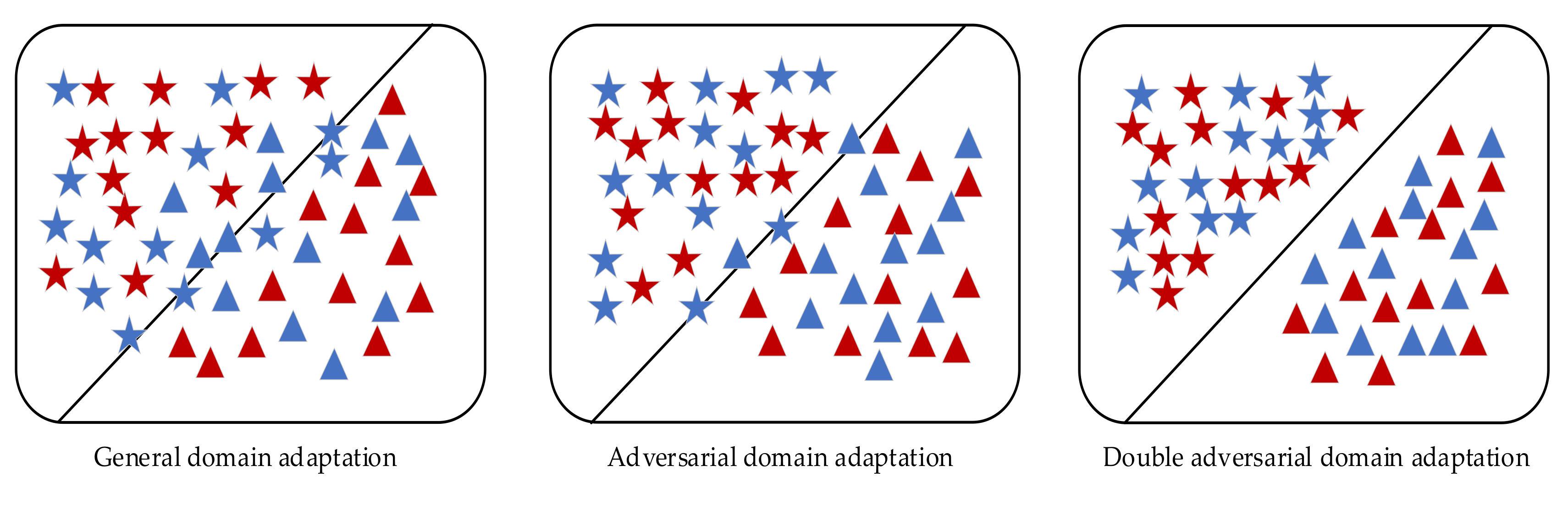
- In this paper, a new fault diagnosis method is proposed, which adopts a double adversarial mechanism to realize domain-level alignment and class-level alignment at the same time.
- (2)
- The proposed method is a novel domain adaptation method to solve the problem that distribution of training data and test data is not the same in a real state. Therefore, the unlabeled target domain samples are the same as the labeled source domain samples, which can be correctly distinguished.
- (3)
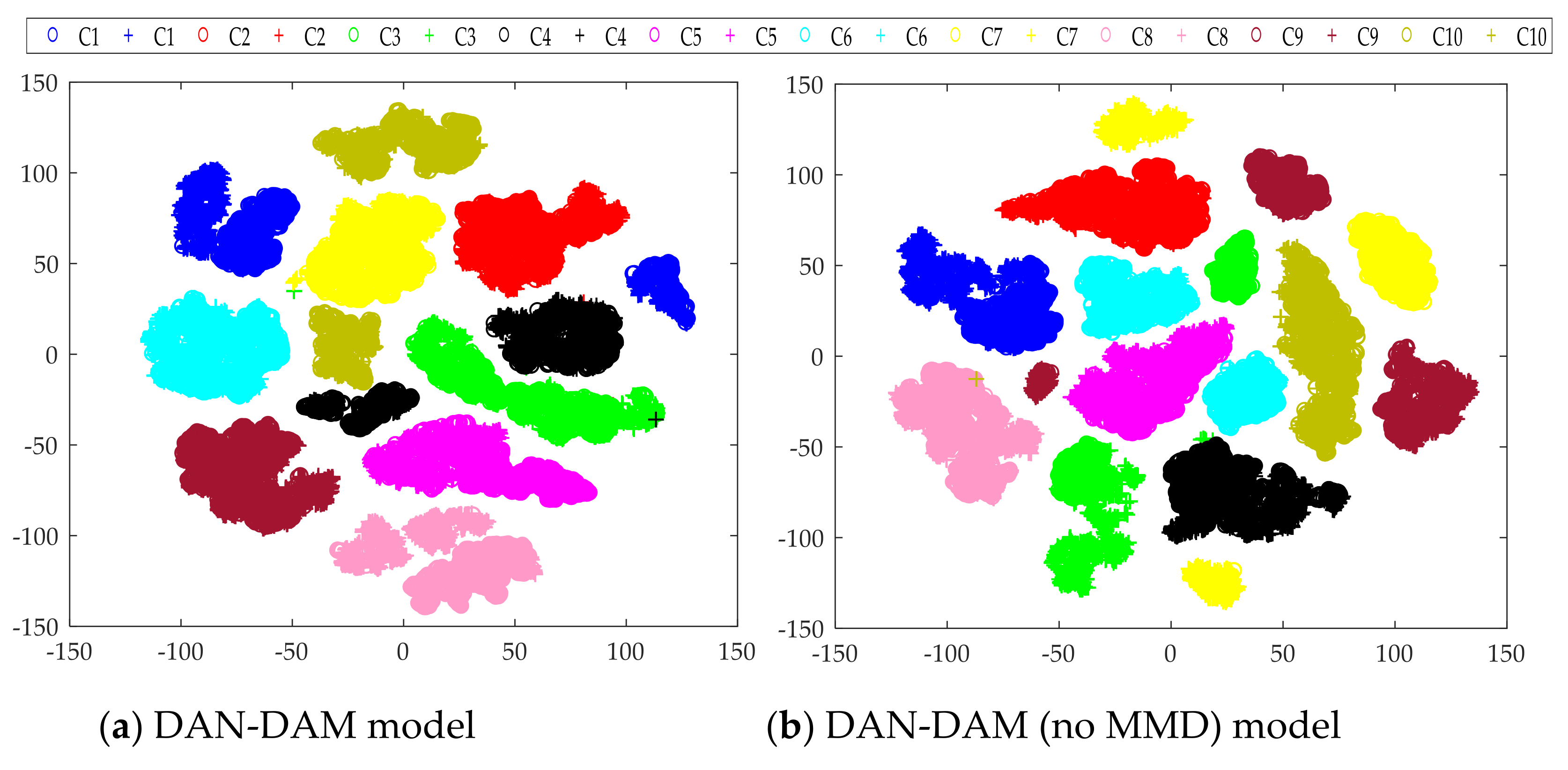
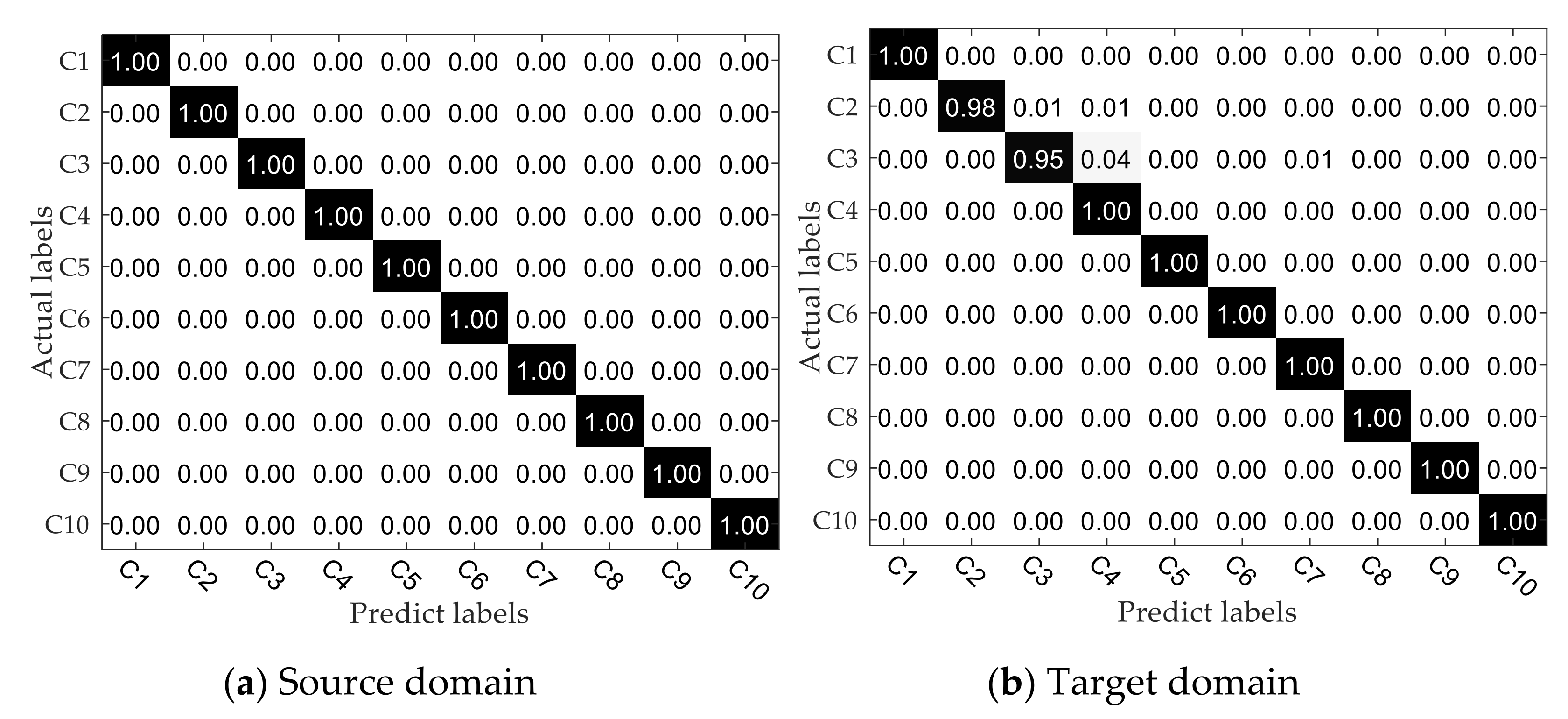
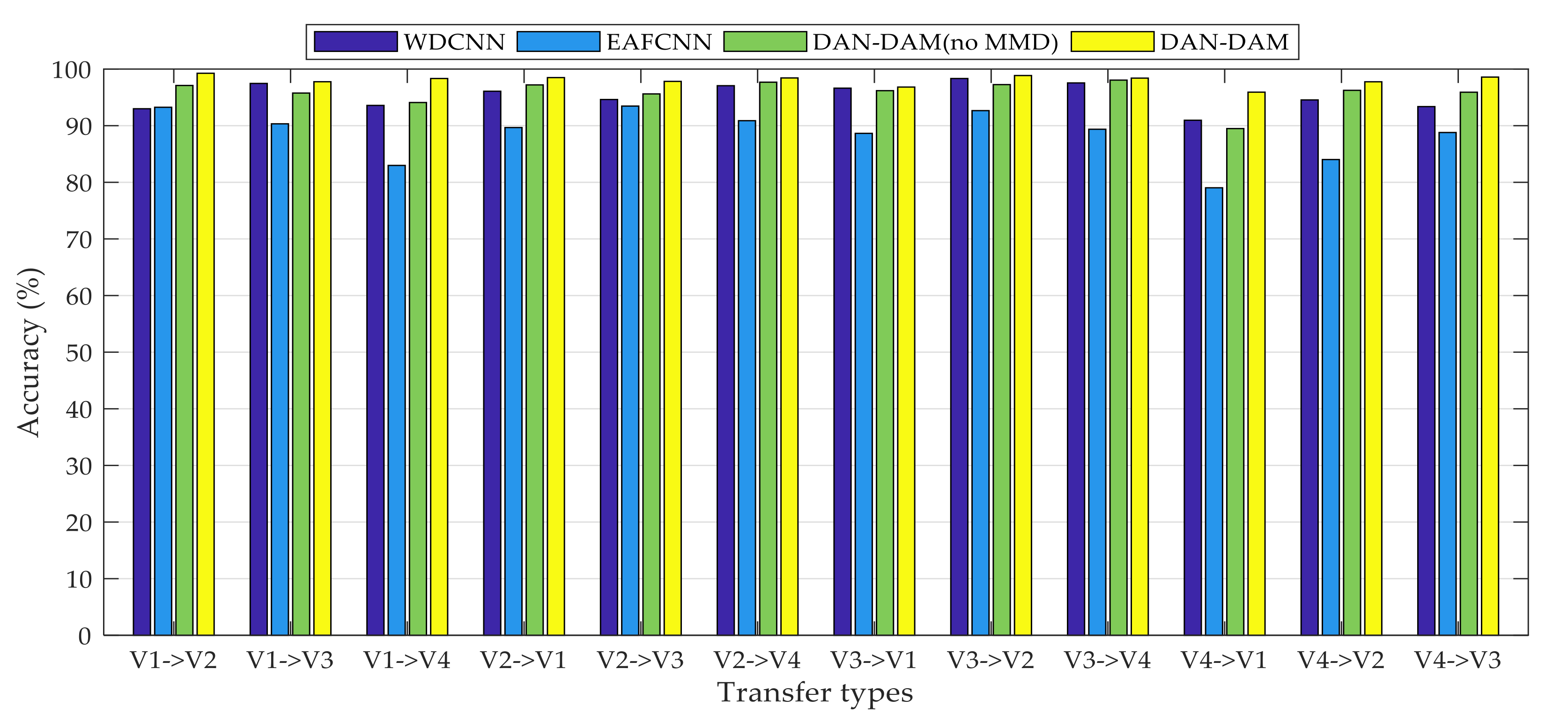
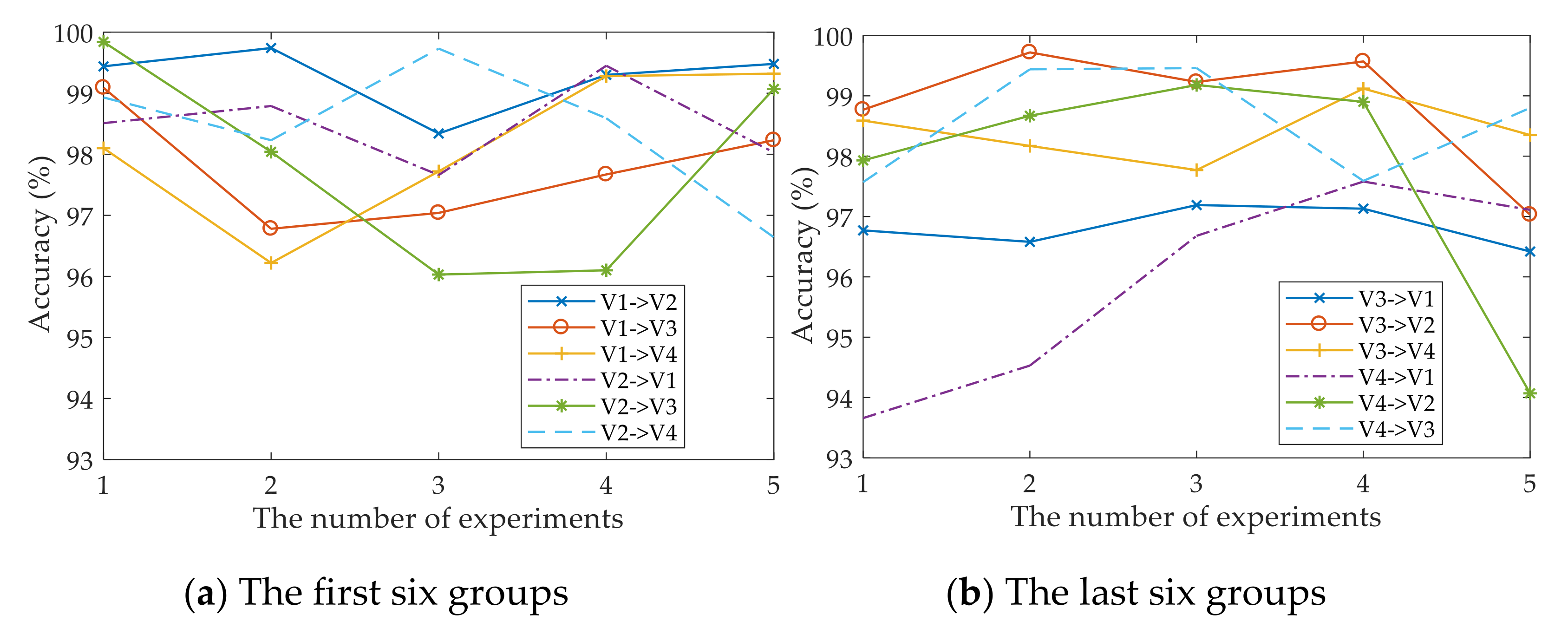
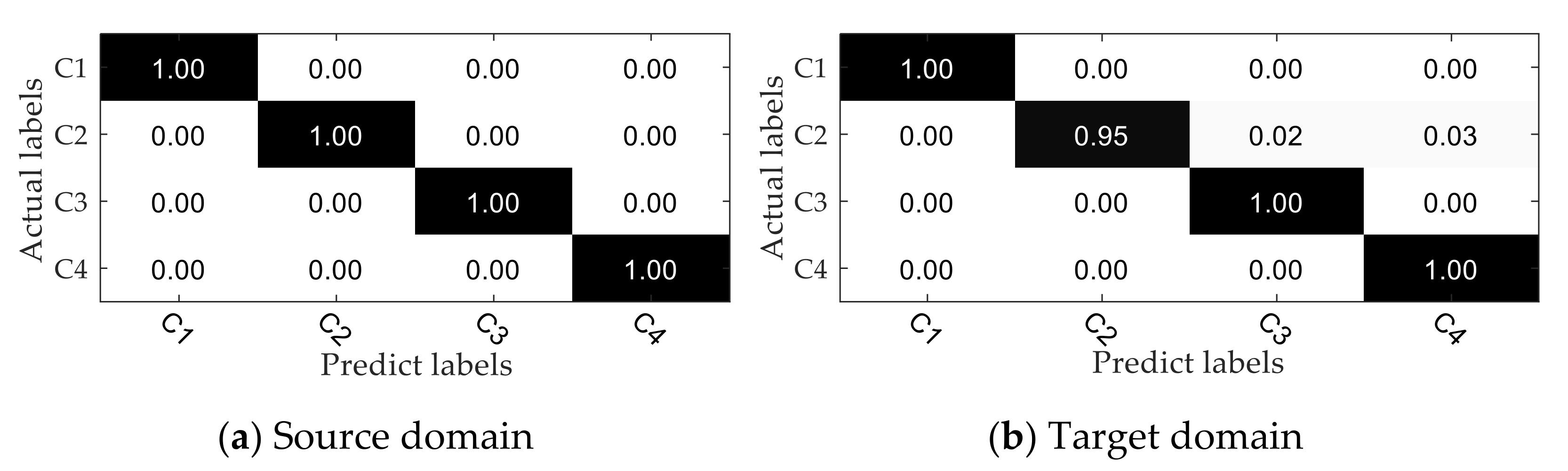
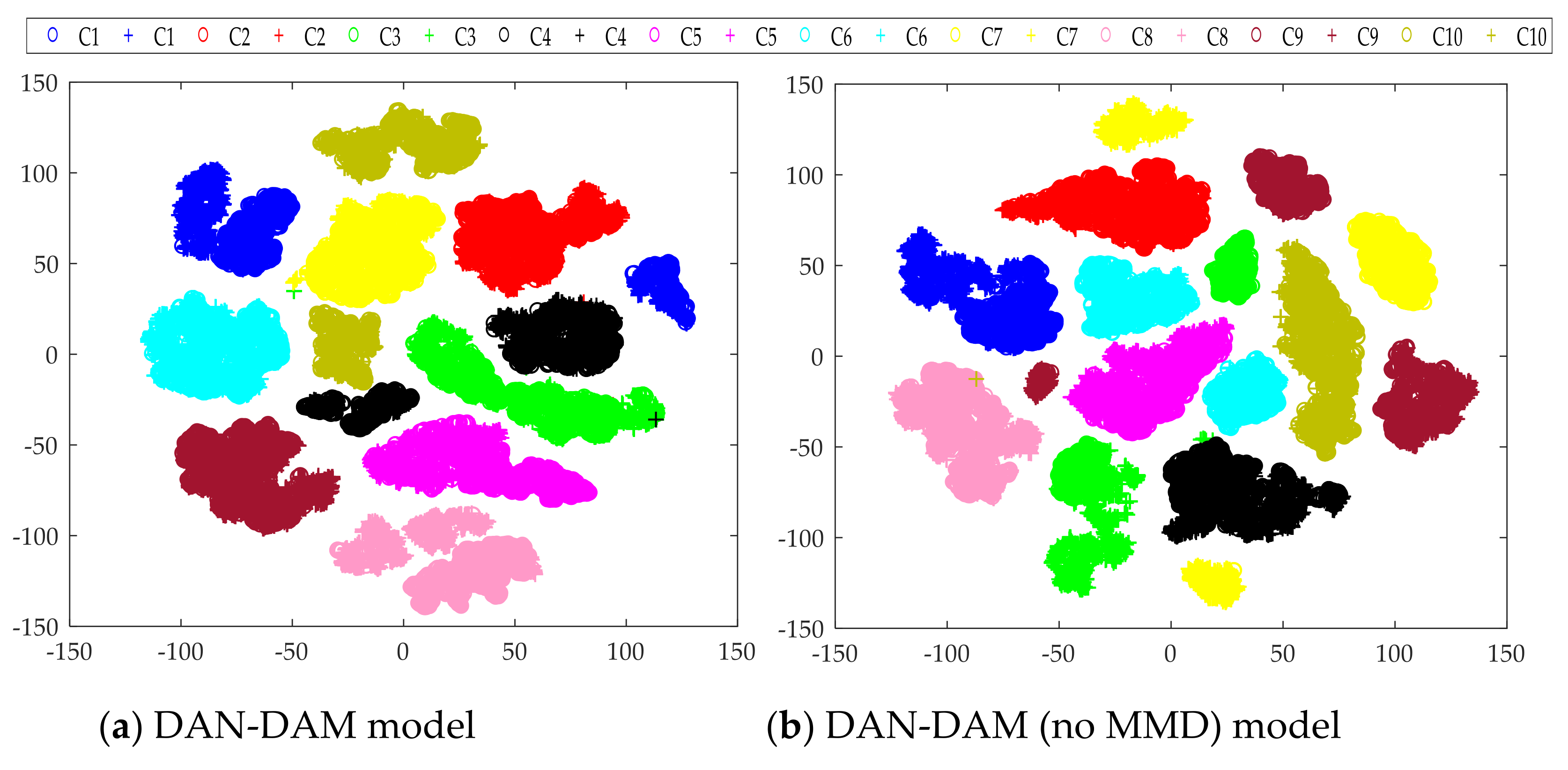
- The proposed method was verified by multi-group transfer experiments and compared with other mainstream intelligent fault diagnosis methods. It can be seen from the experimental results that the DAN-DAM model has a better diagnostic effect for the domain shift samples and the diagnostic accuracy is generally higher than other mainstream diagnostic methods, which more strongly proves the superiority of the DAN-DAM model.
2. Theoretical Background
2.1. Convolutional Neural Network
2.2. Domain Adaptation
2.3. Maximum Mean Discrepancy
2.4. Wasserstein Distance
3. Proposed Method
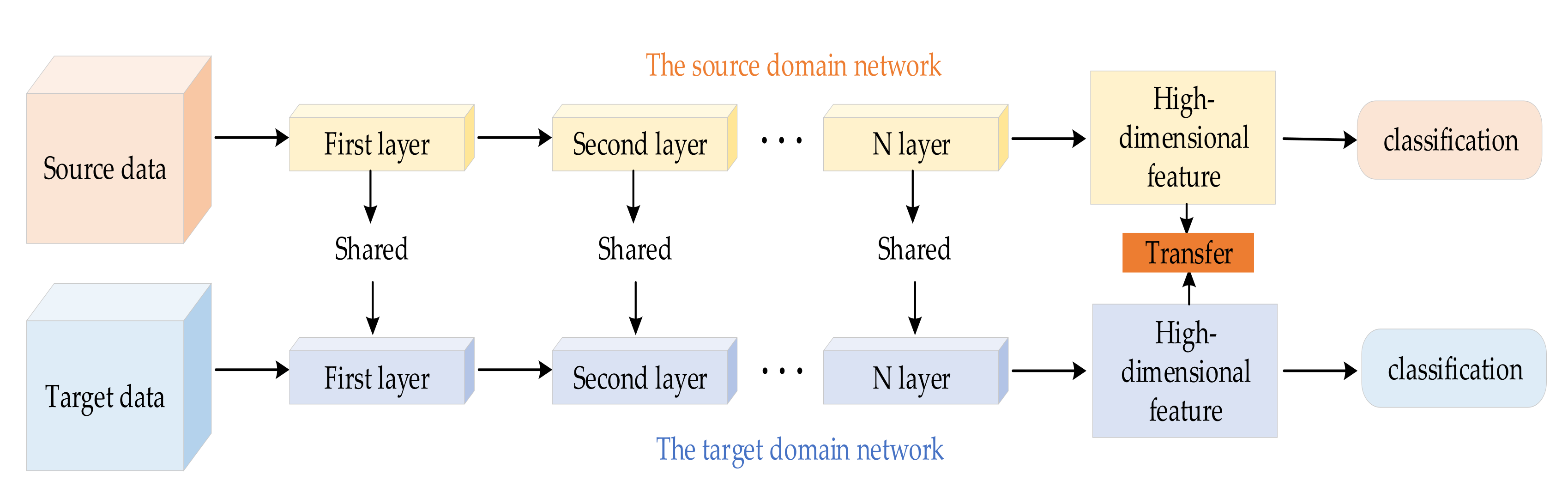
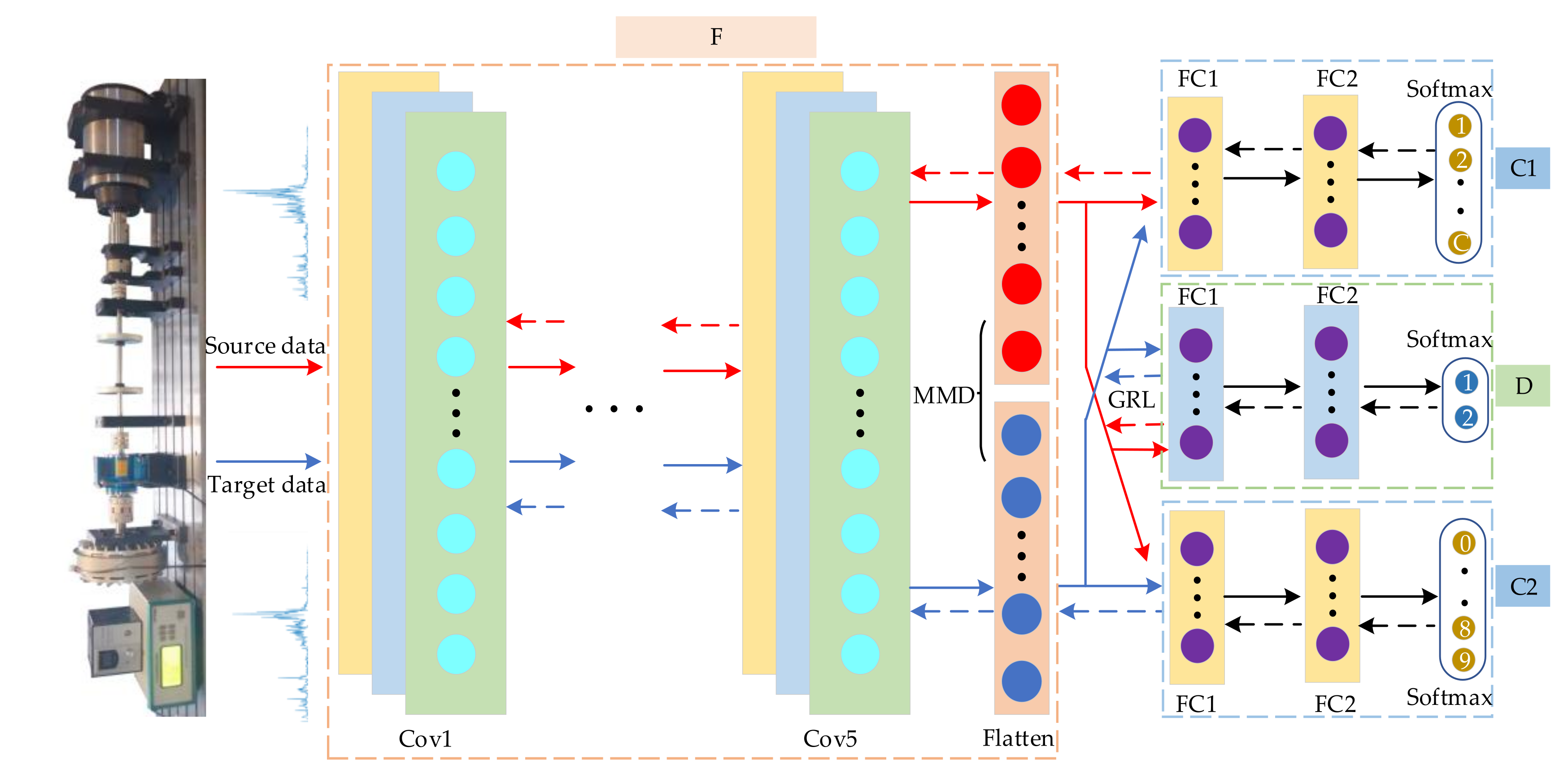
3.1. Feature Extractor
3.2. Domain Discriminator
3.3. Maximum Classifier Discrepancy
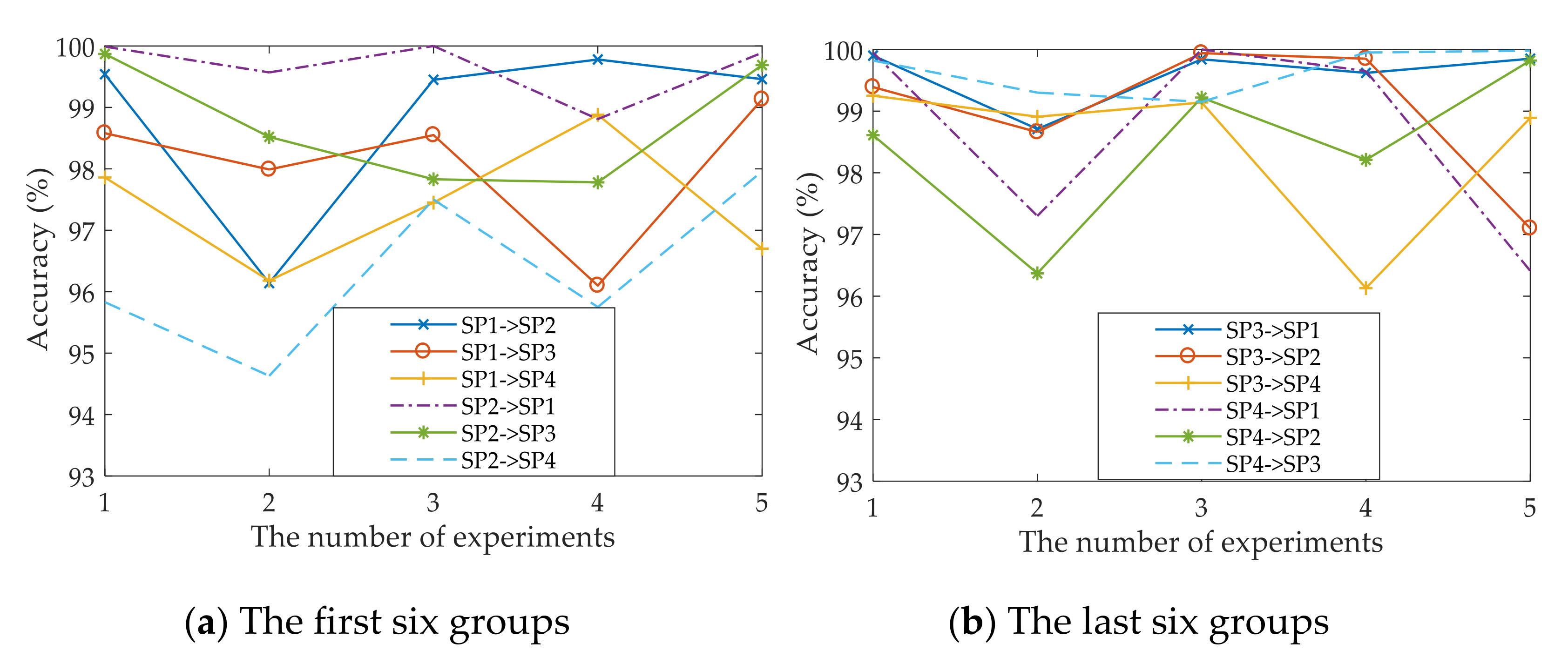
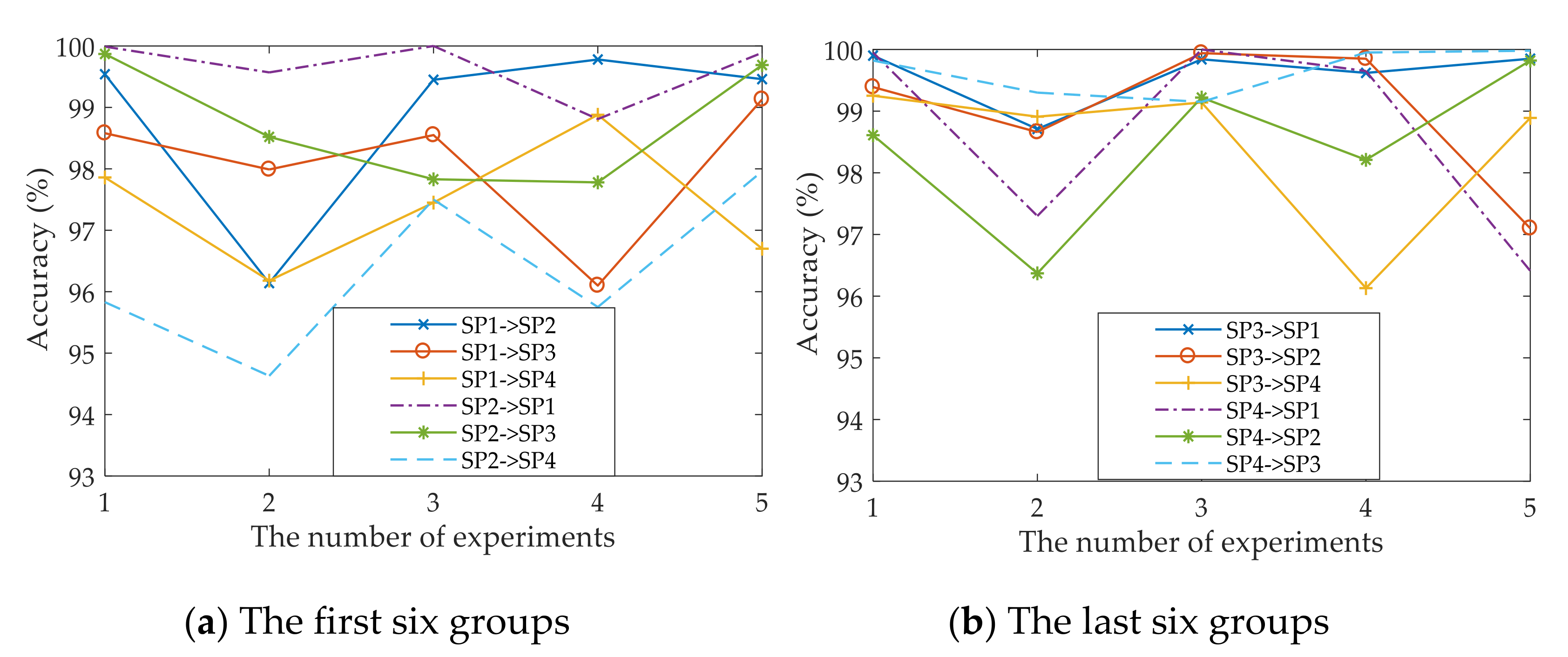
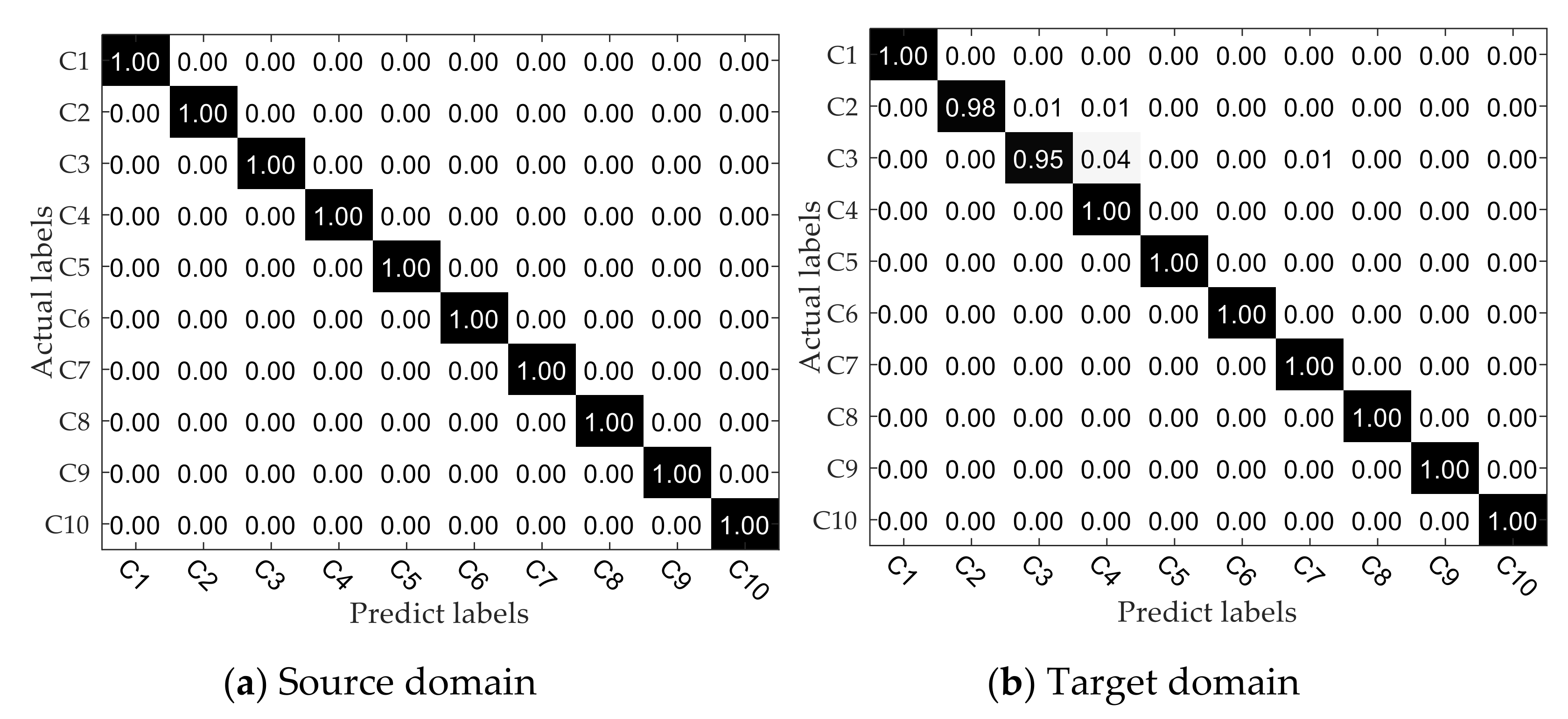
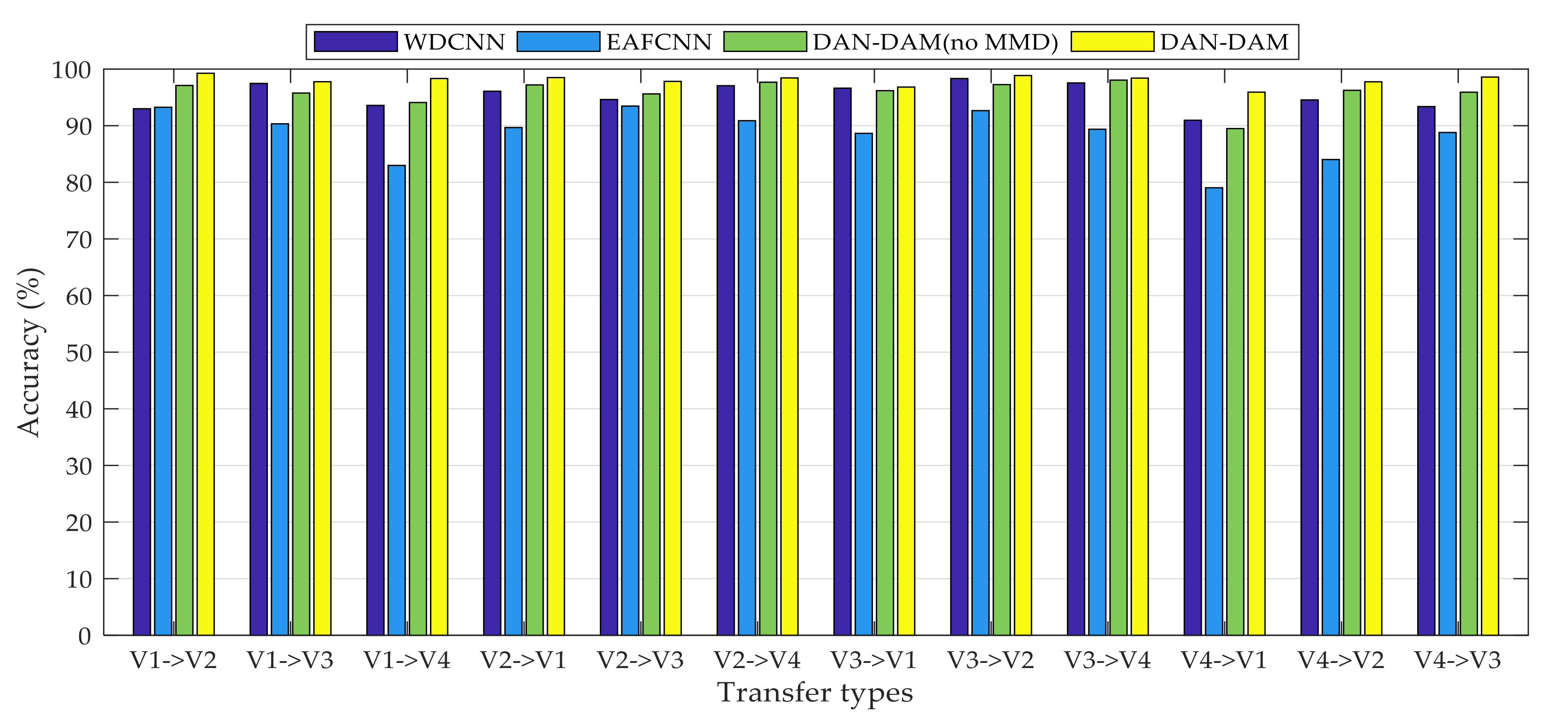
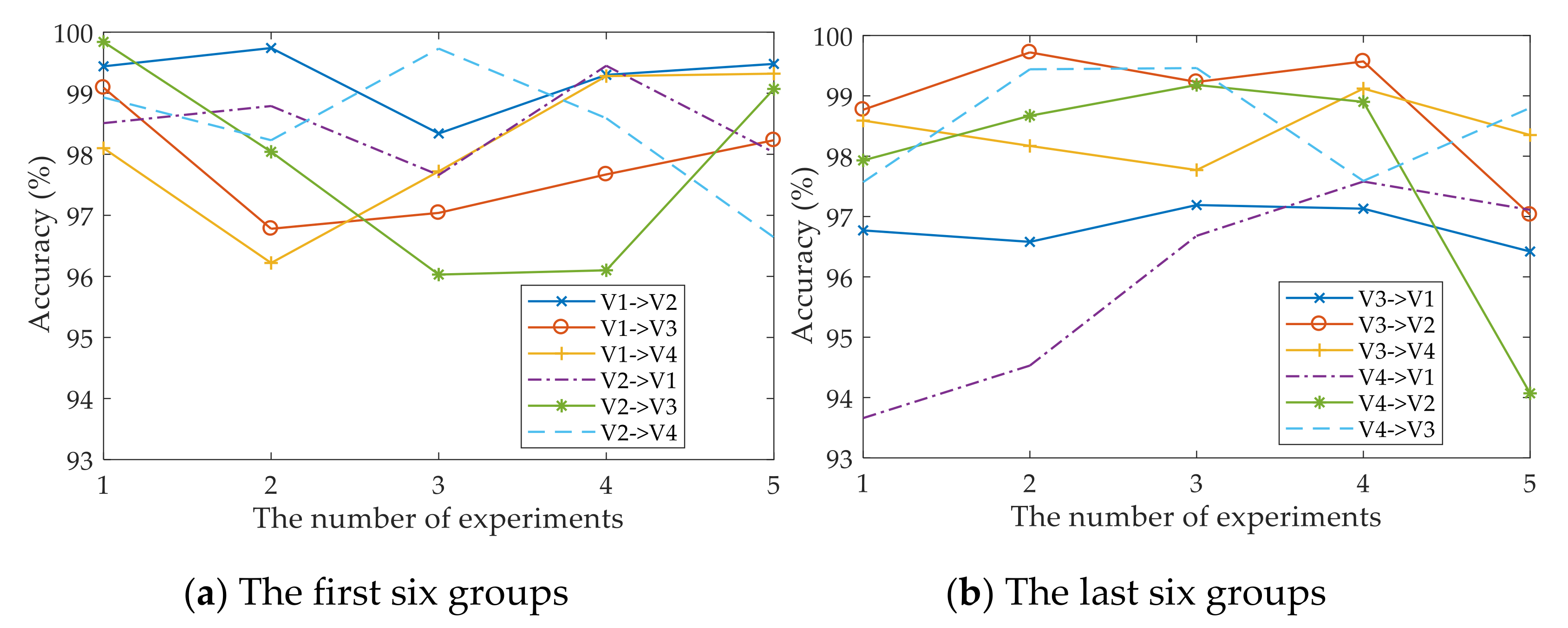
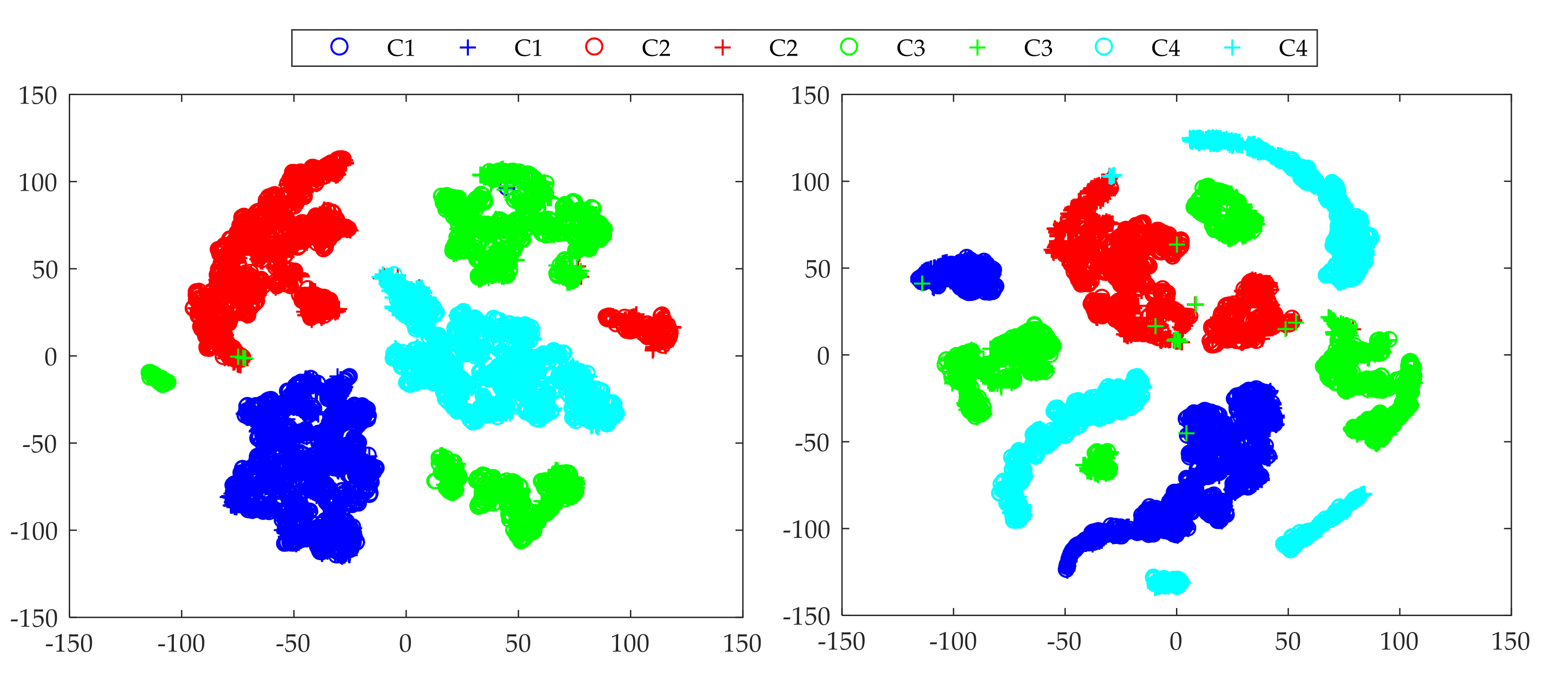
4. Experimental Setup and Results
4.1. Open Datasets
4.2. Private Datasets
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- An, Z.; Li, S.; Wang, J.; Xin, Y.; Xu, K. Generalization of deep neural network for bearing fault diagnosis under different working conditions using multiple kernel method. Neurocomputing 2019, 352, 42–53. [Google Scholar] [CrossRef]
- Zhang, J.; Zhang, Q.; He, X.; Sun, G.; Zhou, D. Compound-Fault Diagnosis of Rotating Machinery: A Fused Imbalance Learning Method. IEEE Trans. Control. Syst. Technol. 2021, 29, 1462–1474. [Google Scholar] [CrossRef]
- Yang, B.; Lei, Y.; Jia, F.; Xing, S. An intelligent fault diagnosis approach based on transfer learning from laboratory bearings to locomotive bearings. Mech. Syst. Signal Process. 2019, 122, 692–706. [Google Scholar] [CrossRef]
- Yang, C.; Zhou, K.; Liu, J. SuperGraph: Spatial-temporal graph-based feature extraction for rotating machinery diagnosis. IEEE Trans. Ind. Electron. 2021, PP, 1. [Google Scholar] [CrossRef]
- Berghout, T.; Benbouzid, M.; Mouss, L.H. Leveraging Label Information in a Knowledge-Driven Approach for Roll-ing-Element Bearings Remaining Useful Life Prediction. Energies 2021, 14, 2163. [Google Scholar] [CrossRef]
- Li, T.; Kou, Z.; Wu, J.; Yahya, W.; Villecco, F. Multipoint Optimal Minimum Entropy Deconvolution Adjusted for Automatic Fault Diagnosis of Hoist Bearing. Shock. Vib. 2021, 2021, 1–15. [Google Scholar] [CrossRef]
- Habbouche, H.; Amirat, Y.; Benkedjouh, T.; Benbouzid, M. Bearing Fault Event-Triggered Diagnosis using a Variational Mode Decomposition-based Machine Learning Approach. IEEE Trans. Energy Convers. 2021, PP, 1. [Google Scholar] [CrossRef]
- Khamoudj, C.E.; Tayeb, F.B.-S.; Benatchba, K.; Benbouzid, M.; Djaafri, A. A Learning Variable Neighborhood Search Approach for Induction Machines Bearing Failures Detection and Diagnosis. Energies 2020, 13, 2953. [Google Scholar] [CrossRef]
- Bazan, G.; Goedtel, A.; Duque-Perez, O.; Morinigo-Sotelo, D. Multi-Fault Diagnosis in Three-Phase Induction Motors Using Data Optimization and Machine Learning Techniques. Electronics 2021, 10, 1462. [Google Scholar] [CrossRef]
- Rauber, T.W.; Loca, A.L.D.S.; Boldt, F.D.A.; Rodrigues, A.L.; Varejão, F.M. An experimental methodology to evaluate machine learning methods for fault diagnosis based on vibration signals. Expert Syst. Appl. 2021, 167, 114022. [Google Scholar] [CrossRef]
- Tao, H.; Wang, P.; Chen, Y.; Stojanovic, V.; Yang, H. An unsupervised fault diagnosis method for rolling bearing using STFT and generative neural networks. J. Frankl. Inst. 2020, 357, 7286–7307. [Google Scholar] [CrossRef]
- Xu, X.; Zhao, Z.; Xu, X.; Yang, J.; Chang, L.; Yan, X.; Wang, G. Machine learning-based wear fault diagnosis for marine diesel engine by fusing multiple data-driven models. Knowledge-Based Syst. 2020, 190, 105324. [Google Scholar] [CrossRef]
- Cheng, Y.; Lin, M.; Wu, J.; Zhu, H.; Shao, X. Intelligent fault diagnosis of rotating machinery based on continuous wavelet transform-local binary convolutional neural network. Knowledge-Based Syst. 2021, 216, 106796. [Google Scholar] [CrossRef]
- Zhao, X.; Jia, M.; Liu, Z. Semisupervised Deep Sparse Auto-Encoder with Local and Nonlocal Information for Intelligent Fault Diagnosis of Rotating Machinery. IEEE Trans. Instrum. Meas. 2021, 70, 1–13. [Google Scholar] [CrossRef]
- Cheng, C.; Liu, W.; Wang, W.; Pecht, M. A novel deep neural network based on an unsupervised feature learning method for rotating machinery fault diagnosis. Meas. Sci. Technol. 2021, 32, 095013. [Google Scholar] [CrossRef]
- Gai, J.; Shen, J.; Wang, H.; Hu, Y. A Parameter-Optimized DBN Using GOA and Its Application in Fault Diagnosis of Gearbox. Shock. Vib. 2020, 2020, 1–11. [Google Scholar] [CrossRef]
- Jiang, W.; Wang, C.; Zou, J.; Zhang, S. Application of Deep Learning in Fault Diagnosis of Rotating Machinery. Processes 2021, 9, 919. [Google Scholar] [CrossRef]
- Kolar, D.; Lisjak, D.; Pająk, M.; Gudlin, M. Intelligent Fault Diagnosis of Rotary Machinery by Convolutional Neural Network with Automatic Hyper-Parameters Tuning Using Bayesian Optimization. Sensors 2021, 21, 2411. [Google Scholar] [CrossRef]
- Pan, S.J.; Yang, Q. A Survey on Transfer Learning. IEEE Trans. Knowl. Data Eng. 2010, 22, 1345–1359. [Google Scholar] [CrossRef]
- Xiao, D.; Qin, C.; Yu, H.; Huang, Y.; Liu, C.; Zhang, J. Unsupervised machine fault diagnosis for noisy domain adaptation using marginal denoising autoencoder based on acoustic signals. Measurement 2021, 176, 109186. [Google Scholar] [CrossRef]
- Lu, W.; Liang, B.; Cheng, Y.; Meng, D.; Yang, J.; Zhang, T. Deep Model Based Domain Adaptation for Fault Diagnosis. IEEE Trans. Ind. Electron. 2017, 64, 2296–2305. [Google Scholar] [CrossRef]
- Li, X.; Jia, X.; Zhang, W.; Ma, H.; Luo, Z.; Li, X. Intelligent cross-machine fault diagnosis approach with deep auto-encoder and domain adaptation. Neurocomputing 2020, 383, 235–247. [Google Scholar] [CrossRef]
- Singh, J.; Azamfar, M.; Ainapure, A.N.; Lee, J. Deep learning-based cross-domain adaptation for gearbox fault diagnosis under variable speed conditions. Meas. Sci. Technol. 2019, 31, 055601. [Google Scholar] [CrossRef]
- Xu, K.; Li, S.; Jiang, X.; Lu, J.; Yu, T.; Li, R. A novel transfer diagnosis method under unbalanced sample based on discrete-peak joint attention enhancement mechanism. Knowl. -Based Syst. 2021, 212, 106645. [Google Scholar] [CrossRef]
- Lee, K.; Han, S.; Pham, V.; Cho, S.; Choi, H.-J.; Lee, J.; Noh, I.; Lee, S. Multi-Objective Instance Weighting-Based Deep Transfer Learning Network for Intelligent Fault Diagnosis. Appl. Sci. 2021, 11, 2370. [Google Scholar] [CrossRef]
- Xu, K.; Li, S.; Jiang, X.; An, Z.; Wang, J.; Yu, T. A renewable fusion fault diagnosis network for the variable speed conditions under unbalanced samples. Neurocomputing 2020, 379, 12–29. [Google Scholar] [CrossRef]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative Adversarial Networks. Commun. Acm 2020, 63, 139–144. [Google Scholar] [CrossRef]
- Zhang, W.; Li, X.; Jia, X.; Ma, H.; Luo, Z.; Li, X. Machinery fault diagnosis with imbalanced data using deep generative adversarial networks. Measurement 2020, 152, 107377. [Google Scholar] [CrossRef]
- Zheng, T.; Song, L.; Wang, J.; Teng, W.; Xu, X.; Ma, C. Data synthesis using dual discriminator conditional generative adversarial networks for imbalanced fault diagnosis of rolling bearings. Measurement 2020, 158, 107741. [Google Scholar] [CrossRef]
- Liu, S.; Jiang, H.; Wu, Z.; Li, X. Rolling bearing fault diagnosis using variational autoencoding generative adversarial networks with deep regret analysis. Measurement 2021, 168, 108371. [Google Scholar] [CrossRef]
- Kwon, H.; Kim, Y.; Yoon, H.; Choi, D. CAPTCHA Image Generation Systems Using Generative Adversarial Networks. IEICE Trans. Inf. Syst. 2018, E101.D, 543–546. [Google Scholar] [CrossRef] [Green Version]
- Saito, K.; Watanabe, K.; Ushiku, Y.; Harada, T. Maximum Classifier Discrepancy for Unsupervised Domain Adaptation. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 3723–3732. [Google Scholar]
- Wu, Z.; Jiang, H.; Lu, T.; Zhao, K. A deep transfer maximum classifier discrepancy method for rolling bearing fault diagnosis under few labeled data. Knowl. -Based Syst. 2020, 196, 105814. [Google Scholar] [CrossRef]
- Li, R.; Li, S.; Xu, K.; Lu, J.; Teng, G.; Du, J. Deep domain adaptation with adversarial idea and coral alignment for transfer fault diagnosis of rolling bearing. Meas. Sci. Technol. 2021, 32, 094009. [Google Scholar] [CrossRef]
- Guo, L.; Lei, Y.; Xing, S.; Yan, T.; Li, N. Deep Convolutional Transfer Learning Network: A New Method for Intelligent Fault Diagnosis of Machines with Unlabeled Data. IEEE Trans. Ind. Electron. 2019, 66, 7316–7325. [Google Scholar] [CrossRef]
- Zhang, J.; Zhou, W.; Chen, X.; Yao, W.; Cao, L. Multi-Source Selective Transfer Framework in Multi-Objective Optimization Problems. IEEE Trans. Evol. Comput. 2019, 24, 1. [Google Scholar] [CrossRef]
- Ganin, Y.; Lempitsky, V. Unsupervised domain adaptation by backpropagation. International conference on machine learning. PMLR 2015, 37, 1180–1189. [Google Scholar]
- Xu, K.; Li, S.; Li, R.; Lu, J.; Zeng, M.; Li, X.; Du, J.; Wang, Y. Cross-domain intelligent diagnostic network based on enhanced attention features and characteristics visualization. Meas. Sci. Technol. 2021, 32, 114009. [Google Scholar] [CrossRef]
- Poria, S.; Cambria, E.; Gelbukh, A. Aspect extraction for opinion mining with a deep convolutional neural network. Knowl. -Based Syst. 2016, 108, 42–49. [Google Scholar] [CrossRef]
- Smith, W.; Randall, R. Rolling element bearing diagnostics using the Case Western Reserve University data: A benchmark study. Mech. Syst. Signal. Process. 2015, 64–65, 100–131. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
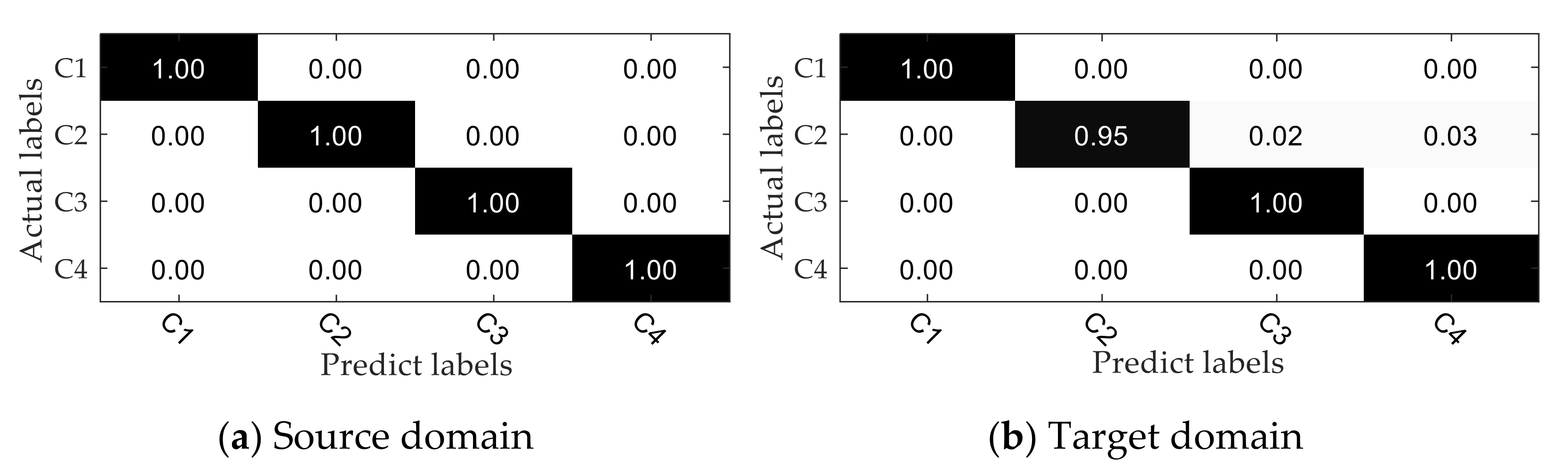{kind=link}
| Module | Layer | Kernel Size | Stride | Channel | Pad | BN | Note |
|---|---|---|---|---|---|---|---|
| Feature extractor F | Conv-Pool1 | 64 × 1/2 × 1 | 15 × 1/2 × 1 | 16 | Same | Yes | SELU |
| Conv-Pool2 | 32 × 1/2 × 1 | 9 × 1/2 × 1 | 32 | Same | Yes | SELU | |
| Conv-Pool3 | 16 × 1/2 × 1 | 9 × 1/2 × 1 | 64 | Same | Yes | SELU | |
| Conv-Pool4 | 3 × 1/2 × 1 | 3 × 1/2 × 1 | 64 | Same | Yes | SELU | |
| Conv-Pool5 | 3 × 1/1 × 1 | 1 × 1/1 × 1 | 64 | Same | Yes | SELU | |
| Label classifier1 C1 | FC1 | 64 × 100 | / | / | / | / | SELU Dropout 0.5 |
| FC2 | 100 × 10 | / | 1 | / | / | / | |
| Softmax | 10 | / | 1 | / | / | / | |
| Label classifier2 C2 | FC1 | 64 × 120 | / | / | / | / | SELU Dropout 0.5 |
| FC2 | 120 × 10 | / | 1 | / | / | / | |
| Softmax | 10 | / | 1 | / | / | / | |
| Domain discriminator D | FC1 | 64 × 32 | / | / | / | / | SELU Dropout 0.5 |
| FC2 | 32 × 2 | / | 1 | / | / | / | |
| Softmax | 2 | / | 1 | / | / | / |
| Fault Location | Normal | Fault in Roller | Fault in Inner Race | Fault in Outer Race | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Severity (mil) | 0 | 7 | 14 | 21 | 7 | 14 | 21 | 7 | 14 | 21 |
| Fault abbreviation | N | RF1 | RF2 | RF3 | IF1 | IF2 | IF3 | OF1 | OF2 | OF3 |
| Category labels | C1 | C2 | C3 | C4 | C5 | C6 | C7 | C8 | C9 | C10 |
| Source Domain | Models | Target Domain | |||
|---|---|---|---|---|---|
| SP1 | SP2 | SP3 | SP4 | ||
| SP1 | WDCNN | - | 85.02% | 83.05% | 85.78% |
| EAFCNN | 95.18% | 86.73% | 82.93% | ||
| DAN-DAM (no MMD) | 96.17% | 94.38% | 86.58% | ||
| DAN-DAM (ours) | 98.88% | 98.07% | 97.41% | ||
| SP2 | WDCNN | 90.22% | - | 76.81% | 72.21% |
| EAFCNN | 95.03% | 96.82% | 96.22% | ||
| DAN-DAM (no MMD) | 95.26% | 96.22% | 95.02% | ||
| DAN-DAM (ours) | 99.65% | 98.74% | 96.33% | ||
| SP3 | WDCNN | 83.69% | 88.98% | - | 83.88% |
| EAFCNN | 97.38% | 98.78% | 97.08% | ||
| DAN-DAM (no MMD) | 95.28% | 95.21% | 95.71% | ||
| DAN-DAM (ours) | 99.58% | 98.99% | 98.46% | ||
| SP4 | WDCNN | 91.10% | 84.41% | 86.68% | - |
| EAFCNN | 85.45% | 98.01% | 94.25% | ||
| DAN-DAM (no MMD) | 93.74% | 95.43% | 98.53% | ||
| DAN-DAM (ours) | 98.66% | 98.45% | 99.64% | ||
| Fault Location | Normal | Fault in Roller | Fault in Inner Race | Fault in Outer Race |
|---|---|---|---|---|
| Severity (mm) | 0 | 0.5 | 0.5 | 0.5 |
| Fault abbreviation | N | RF1 | IF1 | OF1 |
| Category labels | C1 | C2 | C3 | C4 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xu, K.; Li, S.; Li, R.; Lu, J.; Li, X.; Zeng, M. Domain Adaptation Network with Double Adversarial Mechanism for Intelligent Fault Diagnosis. Appl. Sci. 2021, 11, 7983. https://doi.org/10.3390/app11177983
Xu K, Li S, Li R, Lu J, Li X, Zeng M. Domain Adaptation Network with Double Adversarial Mechanism for Intelligent Fault Diagnosis. Applied Sciences. 2021; 11(17):7983. https://doi.org/10.3390/app11177983
Chicago/Turabian StyleXu, Kun, Shunming Li, Ranran Li, Jiantao Lu, Xianglian Li, and Mengjie Zeng. 2021. "Domain Adaptation Network with Double Adversarial Mechanism for Intelligent Fault Diagnosis" Applied Sciences 11, no. 17: 7983. https://doi.org/10.3390/app11177983
APA StyleXu, K., Li, S., Li, R., Lu, J., Li, X., & Zeng, M. (2021). Domain Adaptation Network with Double Adversarial Mechanism for Intelligent Fault Diagnosis. Applied Sciences, 11(17), 7983. https://doi.org/10.3390/app11177983