1. Introduction
With the increase in the use of various media, such as social media and the Internet of Things, large amounts of real-time stream data are generated in various forms. In a sensor network, real-time stream data are used to detect equipment malfunction and monitor maloperation [
1,
2]. A system that identifies equipment malfunction or maloperation is unable to serve its objective if it fails to assess scenarios and provide appropriate notifications, and therefore, real-time big data processing technology is required for responding within the time defined by users [
3,
4]. Stream processing platforms are commonly used for real-time stream processing of big data, such as Spark, Storm, and Flink [
5,
6,
7]. These platforms consistently perform stream processing by operating Java Virtual Machines (JVM) once, thus solving the problem of re-operating JVMs in Hadoop [
8,
9]. Moreover, in order to solve the response problem, intermediate results of the processing are maintained in the memory for minimizing disk I/O. In particular, the main objective of Storm is real-time stream processing, different from Spark and Flink, which aim at both stream and batch processing. Therefore, this study focuses on Storm, which can efficiently perform stream processing of big data. Storm has the advantages of high data processing speed, scalability, fault tolerance, reliability, and low operation difficulty [
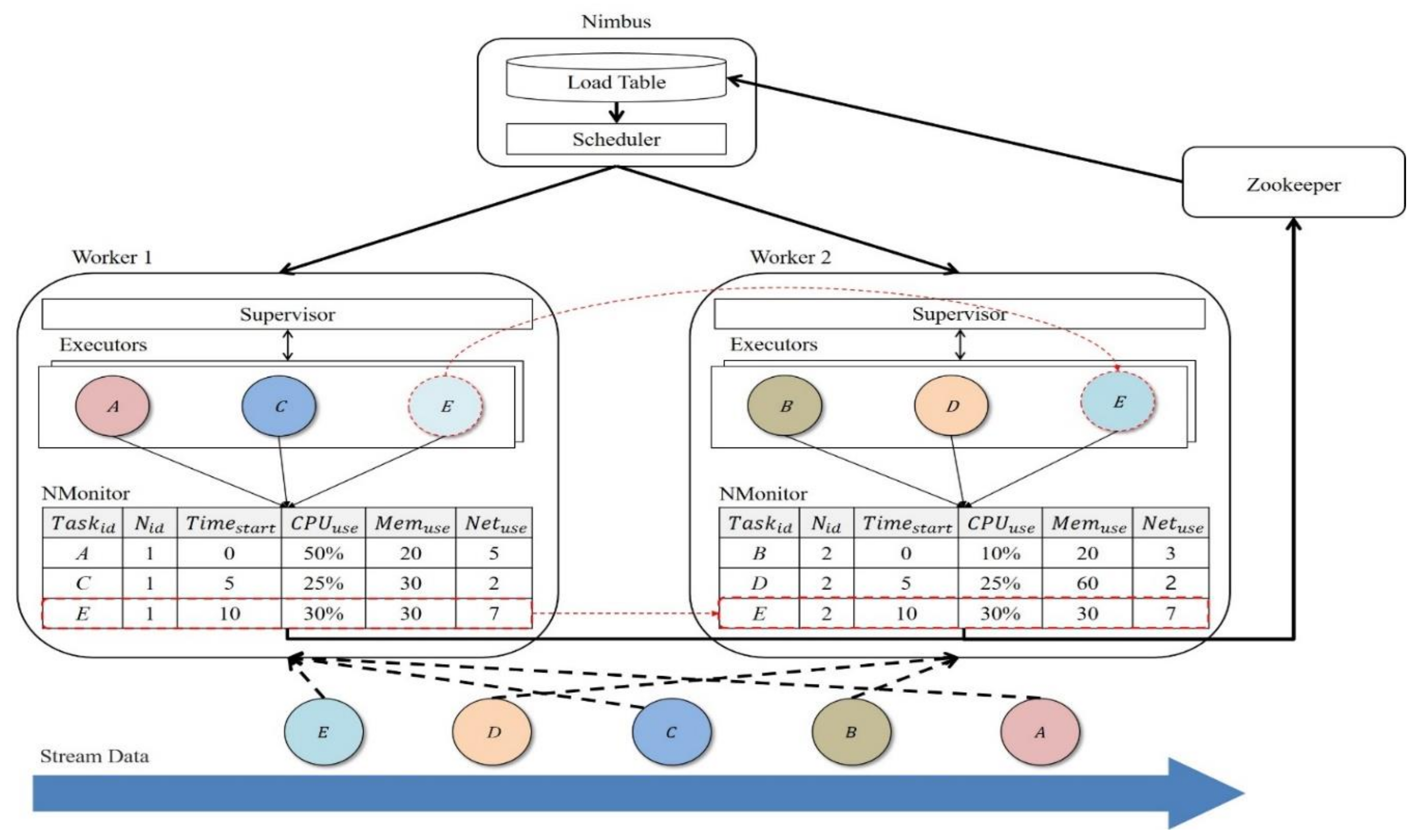
7]. In Storm, Nimbus, which is the master node, delivers the data to the supervisor of a worker node, which is a slave, for stream processing data input in real time. During this process, tasks are distributed by round-robin fashion. However, the input tasks may have varying degrees of computational complexity, which may apply loads on a particular worker node. A delay may occur in real-time processing if the loads on the worker nodes are not considered.
Various studies have been conducted for resolving this problem [
10,
11,
12,
13,
14,
15,
16,
17,
18,
19,
20,
21]. In some study, simply calculating the traffic cannot solve the problem of load imbalance on worker nodes. In addition, only an environment in which the expected task processing time does not fluctuate significantly was considered by including simple queries, such as data search. Therefore, scenarios in which complex operation queries are requested need to be considered in addition to simple search queries. Some studies cannot deal with real-time tasks given a specific deadline.
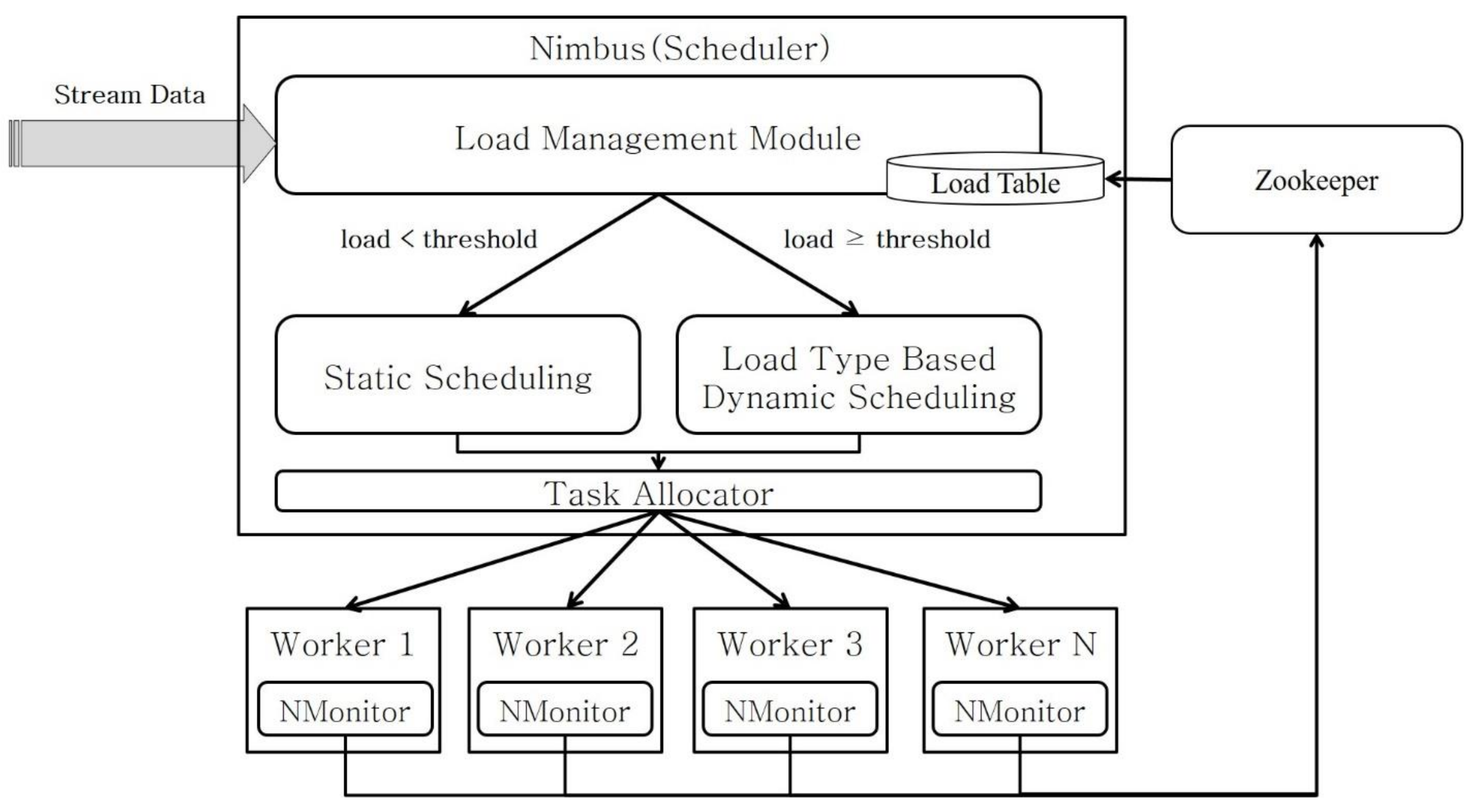
This study proposes a dynamic task scheduling scheme in which task deadlines and the node resources in Storm are considered. The proposed scheme manages the states of the worker nodes to assess the cause of the loads on them and performs dynamic scheduling based on the load type. For performing dynamic scheduling, the priority of task is determined based on the deadline information and their processing costs. For load balancing, tasks with higher priorities are redistributed over the relatively lower loaded nodes. For performing dynamic task scheduling in heterogeneous cluster environments with different performance levels, the performance of each worker node is recorded, and tasks with higher priorities are assigned to the worker nodes with better performance, to complete tasks within the given deadline. Consequently, the proposed method distributes loads on the worker nodes to prevent bottleneck in real-time processing. This study has the following contributions:
Dynamic scheduling based on the cluster status: Cluster worker nodes may have varying performance depending on the operation scenario. Each worker node has a different task throughput; thus, a worker node with a higher throughput must process a larger number of tasks. In this study, dynamic scheduling for task distribution is performed by considering the diversity in the performance of cluster worker nodes.
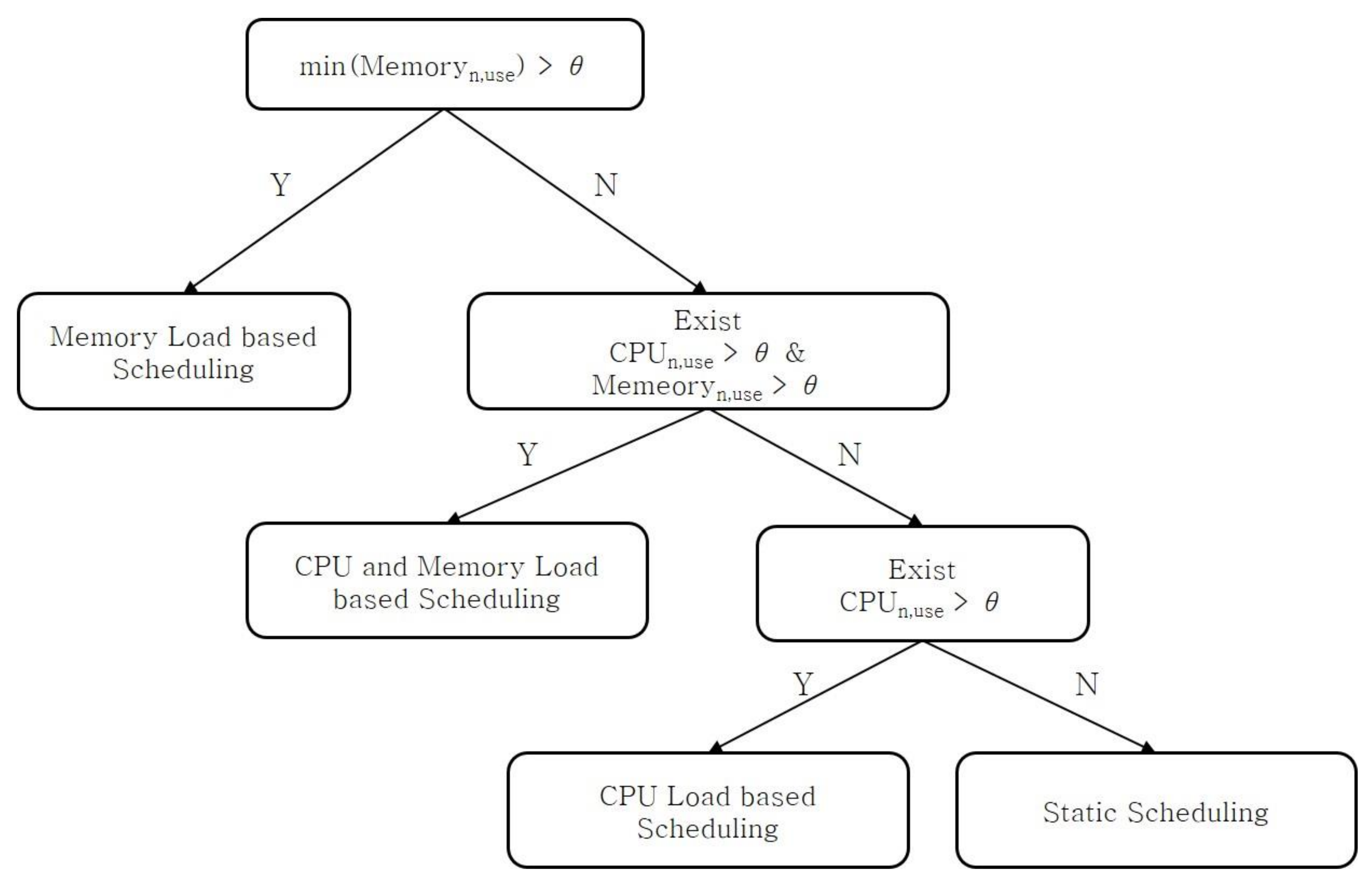
Dynamic scheduling considering the load type: The load types of a worker node are classified in this study as CPU, memory, or CPU and memory loads based on the number of resources used. The number of resources used per task is monitored, and dynamic scheduling is performed to redistribute the tasks based on the defined load types.
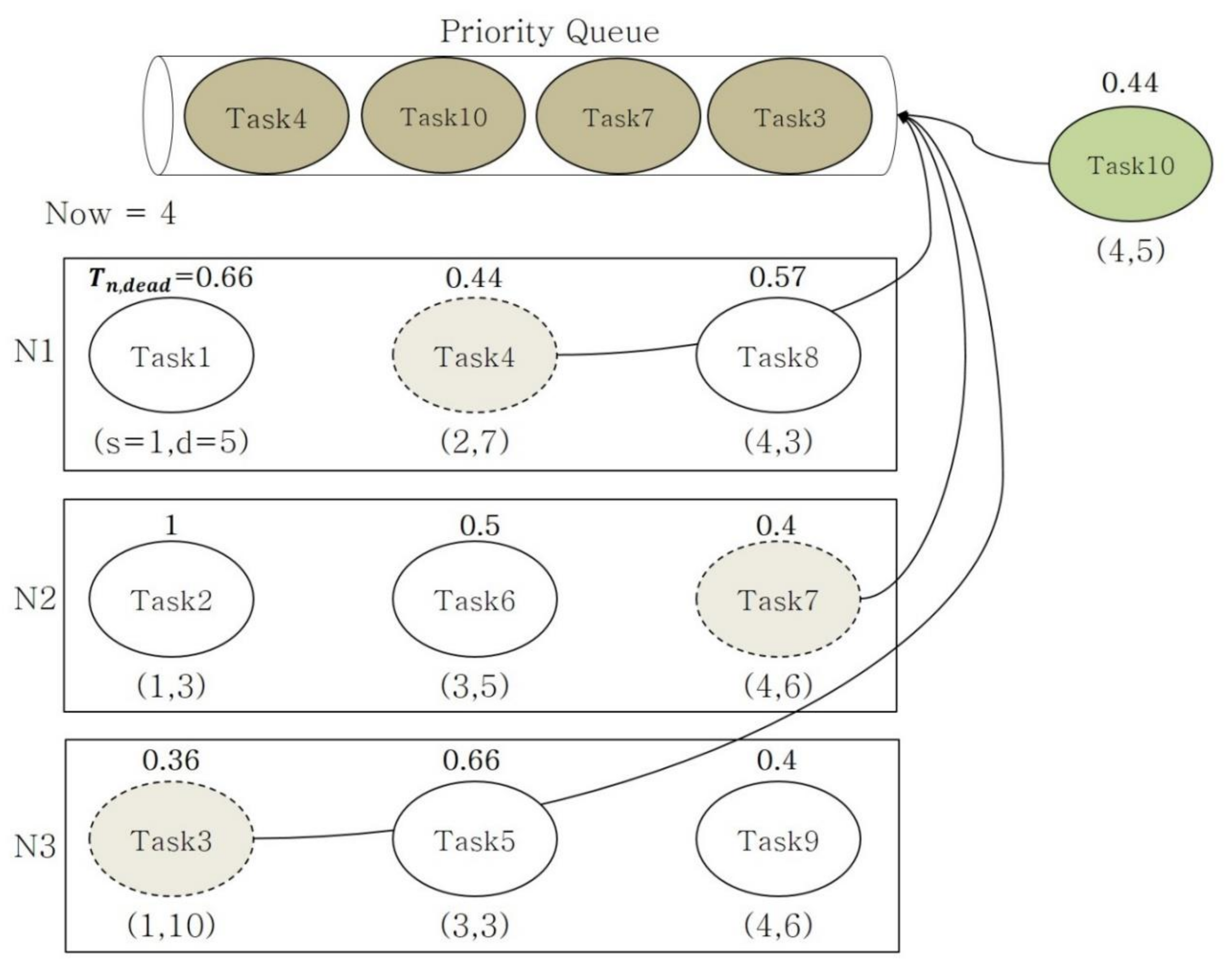
Dynamic scheduling considering the task deadline: If a task is not processed within a deadline during real-time stream processing, the processing result becomes insignificant. In this study, dynamic scheduling is performed by considering the deadline for each task based on the loads generated during the stream processing.
The remainder of this paper is organized as follows.
Section 2 explains the characteristics and problems of conventional scheduling schemes.
Section 3 describes the dynamic task scheduling proposed in this paper. In
Section 4, the excellence of the proposed scheme is proved by presenting the comparison of the performances of conventional schemes and the stream processing scheme proposed in this paper. The conclusions and directions for future research are provided in
Section 5.
2. Related Work
The round-robin scheduler provided by default in Storm has the advantage of simple implementation; however, it causes an excessive number of tasks to be allocated to low-performance worker nodes because the performance of the worker nodes and a distributed environment with various performance are not considered. In this case, response delay and task loss occur during real-time stream processing of data, which causes failure in task completion within the deadline. For resolving these issues, various scheduling schemes have been examined in which the loads on the worker nodes in a real-time stream environment are considered [
10,
11,
12,
13,
14,
15,
16,
17,
18,
19,
20,
21].
A study [
10] proposed a task scheduling scheme for distributing tasks by predicting the processing times of the tasks based on the performance of the worker nodes for rapid search performance. The tasks that require longer processing time than expected are redistributed to standardize the processing times of the worker nodes. However, the study aimed to perform relatively simple tasks, such as search, and thus, an environment in which complex tasks, such as the k-means algorithm, are simultaneously input must be considered.
T-Storm is a task scheduling scheme in which the traffic between the worker nodes and between the processes is considered [
11]. The data on the CPU usage and traffic between the worker nodes and between the processes measured by load monitors are stored in a database. Subsequently, a scheduler in the master sequentially distributes the tasks starting with those with the lowest traffic between the worker nodes and between the processes based on the data stored in the database.
R-Storm is a task scheduling scheme in which the resources of the worker nodes and the expected processing costs of the tasks are considered [
12]. R-Storm distributes the tasks to the most suitable worker nodes by comparing the CPU usage, memory, and network costs of the worker nodes with the corresponding expected values to be used by the tasks. After presenting the expected usage of the resources by the tasks and the free resources (CPU, memory, and network cost) of the worker nodes as three-dimensional dots, each task is allocated to the worker nodes, starting with the closest node based on the three-dimensional distance. Accordingly, the task processing efficiency is improved by selecting the most appropriate worker node for the expected processing costs.
A study [
13] proposed static and dynamic task scheduling schemes based on the CPU usage and network bandwidths of the worker nodes. The default task allocation in [
13] was static allocation, which was based on the network bandwidth and the transmission amount of a tuple. Subsequently, dynamic scheduling is proceeded at certain intervals (5 min). Dynamic scheduling identifies load occurrence when the CPU usage of a worker node exceeds the threshold. Subsequently, the task at the loaded worker node is migrated to a worker node that is unloaded by considering the CPU usage and the network costs. Accordingly, dynamic scheduling is performed based on the loads on the worker nodes. However, important resources for processing tasks, such as memory usage, were not considered, and dynamic scheduling also fails to consider the task deadline; therefore, it is incapable of processing urgent tasks.
Studies [
14,
15] proposed a scheduling scheme which includes the topology of Storm in addition to network traffic and worker nodes’ resources which were considered in T-Storm and R-Storm. A study [
14] proposed a task scheduling scheme based on the topology and resources for a heterogeneous cluster environment. Based on the topology information of Storm, the amounts of communications within a group and between groups are defined to be used for task allocation. Similar to [
14], a study [
15] also proposed a task scheduling scheme based on the Storm topology, resources of worker nodes, and network traffic. In this study, the amount of communication between worker nodes is calculated by monitoring and plotted as a graph. The graph generated based on the amount of communication between worker nodes is converted into a spanning tree to perform tree partitioning using the information on the resources of worker nodes. A scheduling scheme for allocating tasks based on the information on the resources of worker nodes and partitioning is proposed.
A study [
16] proposed mechanisms to dynamically enact the rescheduling and migration of tasks in a streaming dataflow from one set of virtual machines to another reliably and rapidly. They proposed two task migration strategies such as Drain-Checkpoint-Restore(DCR) and Capture-Checkpoint-Resume(CCR) in Storm by using Redis that is a distributed key/value store. The migration strategies allow a running streaming dataflow to migrate without any loss of in-flight messages or their internal tasks states, while reducing the time to recover and stabilize.
A study [
17] proposed a dynamic scheduling algorithm to maximize the throughput of a heterogeneous distributed cluster environment. It considers cluster characteristics and the topology job and node attributes such as the computational complexities, data size, node processing powers, and link transfer bandwidths. They utilize the dynamic programming technique to identify and minimize the potential computational or communicational bottlenecks.
A study [
18] proposed a thread-level non-stop task migration scheme called N-Storm that performs online task migrations in Storm without killing existing Executors or starting new Executors. N-Storm adds a key/value store on each worker node to make works be aware of the changes during task scheduling. Each worker in the same worker node can communicate with the supervisor through the key/value store. N-Storm performs thread-level task migrations that improve the performance of task migration. Furthermore, they proposed several optimization schemes of N-Storm to get efficiency for multiple tasks migrations.
A study [
19] modeled the elasticity problem for data stream processing as an integer linear programming problem, which is used to optimize different quality of service metrics such as the response time, the tuple processing time, the tuple transmission time, and the application downtime. They proposed a general formulation of the reconfiguration costs caused by operator migration and scaling in terms of application downtime. It implemented the proposed mechanisms on Apache Storm.
A study [
20] proposed a dynamic scheduler that can redistribute the migrated tasks in a fair and fast way based on their previous work [
21]. They perform the dynamic scheduling by estimating the load of the nodes to handle task migrations when the system parameters change such as the number of tasks and configuration of executors or nodes. It treats all the required operations (tuple transfer, tuple processing, and tuple packing) in a pipeline fashion based on their previous study [
21] in order to reduce the overall processing time.
Studies [
12,
14,
15,
16,
17,
18,
19,
20,
21] proposed task scheduling schemes based on various resources of worker nodes. T-Storm performs scheduling only based on traffic information, and thus, cannot solve the problem of load imbalance in worker nodes; it also entails delays in certain tasks if dynamic scheduling is not performed, as in [
12]. Therefore, a task redistribution policy is needed based on real-time loads. Loads can be defined in various ways depending on the task type and the free resources of worker nodes. Task redistribution can be efficiently conducted if the policy varies with the load type. Finally, task deadlines may be differently defined based on the stream input time and type. Therefore, a measure in which task deadlines are also considered in dynamic scheduling is needed.
4. Performance Evaluation
For verifying the excellence of the proposed dynamic task scheduling scheme, its processing speed was measured under each load condition, and the performance was evaluated for task scheduling proposed using R-Storm [
12] and J. Fan [
13]. The two existing methods we have chosen for performance evaluation are the most appropriate for performance comparison with the proposed method as they perform scheduling with only collectable memory usage, CPU, and network traffic information. The performance evaluation parameters are listed in
Table 3. The environment consists of one master and ten worker nodes, in which the data processing speeds for complex and simple queries as well as the task delay of each worker node are evaluated. The threshold for determining a load is set as 80%.
Table 4 summarizes the types of data and queries used in the performance evaluation. The dataset used in the performance evaluation includes text files of 1 GB and 2 GB sizes consisting of English letters and of the same size consisting of random numbers. The performance evaluation data were transmitted in real time to construct a stream environment. Accordingly, the word count corresponding to a simple query and the k-means algorithm, which corresponds to a complex query, are processed [
22]. The k-means algorithm is an algorithm for grouping data into
k number of clusters, where the distribution of the distances from each cluster is minimized. The factors that significantly influence the computational complexity of the k-means algorithm are Euclidean space
d and the number of clusters
k. Even if the number of clusters is small, finding the optimal solution of the k-means algorithm in general Euclidean space
d is NP-hard [
23,
24]. Finding the optimal solution of
k number of clusters even in a low-dimensional Euclidean space is also NP-hard [
25]. Therefore, the task complexity in the k-means algorithm is high because a heuristic technique is used. The processing speeds of the tasks and the real-time processing rates are comparatively analyzed by classifying the tasks into simple and complex tasks.
When processing real-time stream data, the task processing speed and the delay time vary with the load. Therefore, they must be examined with respect to the query of the proposed scheme. First, the speed of processing the tasks based on the worker node load and the rate of processing the tasks within the deadline are examined; subsequently, the performance is evaluated by comparing to previously proposed schemes. Text files of size 1 GB consisting of English alphabets and random numbers, respectively, are used.
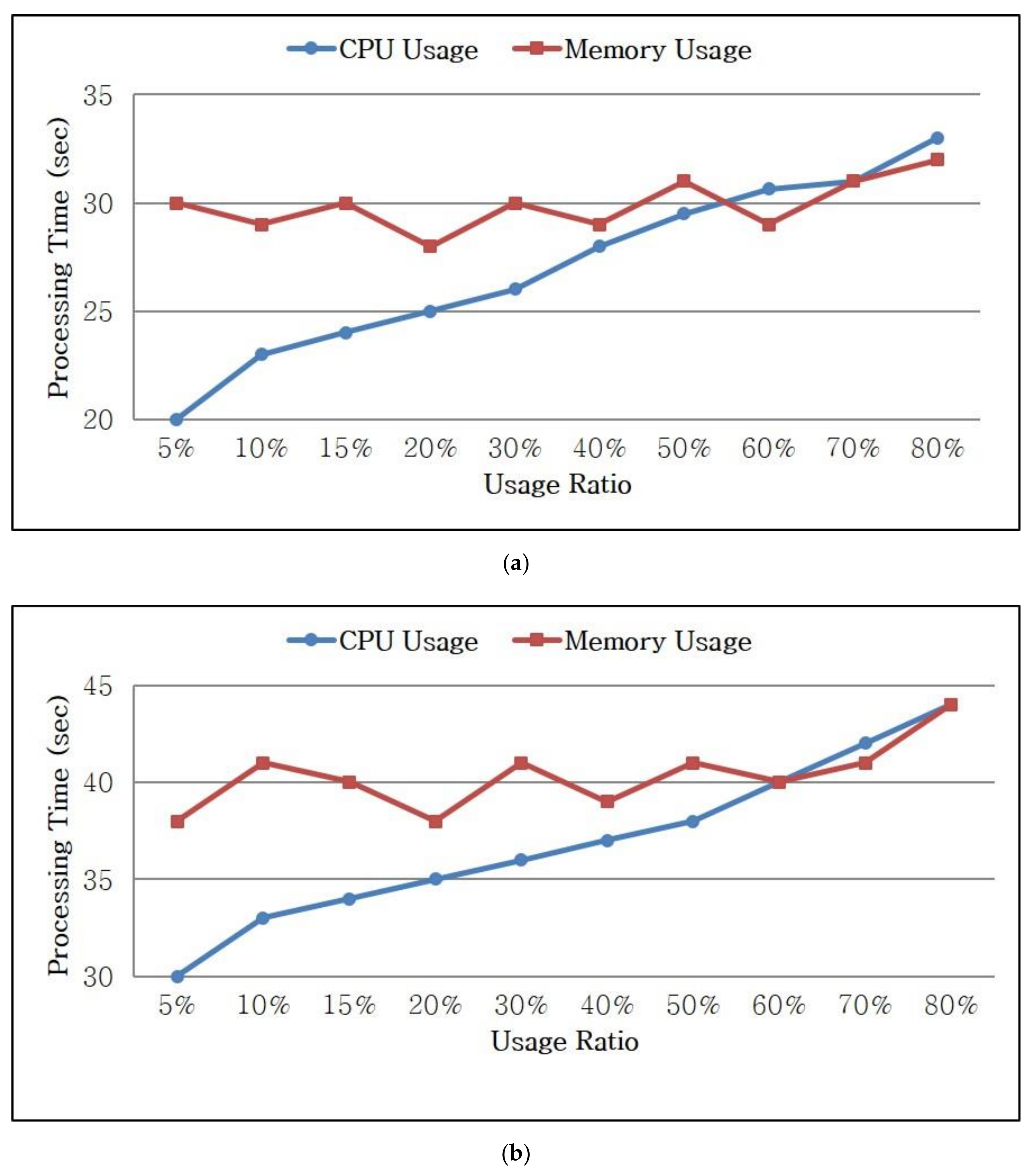
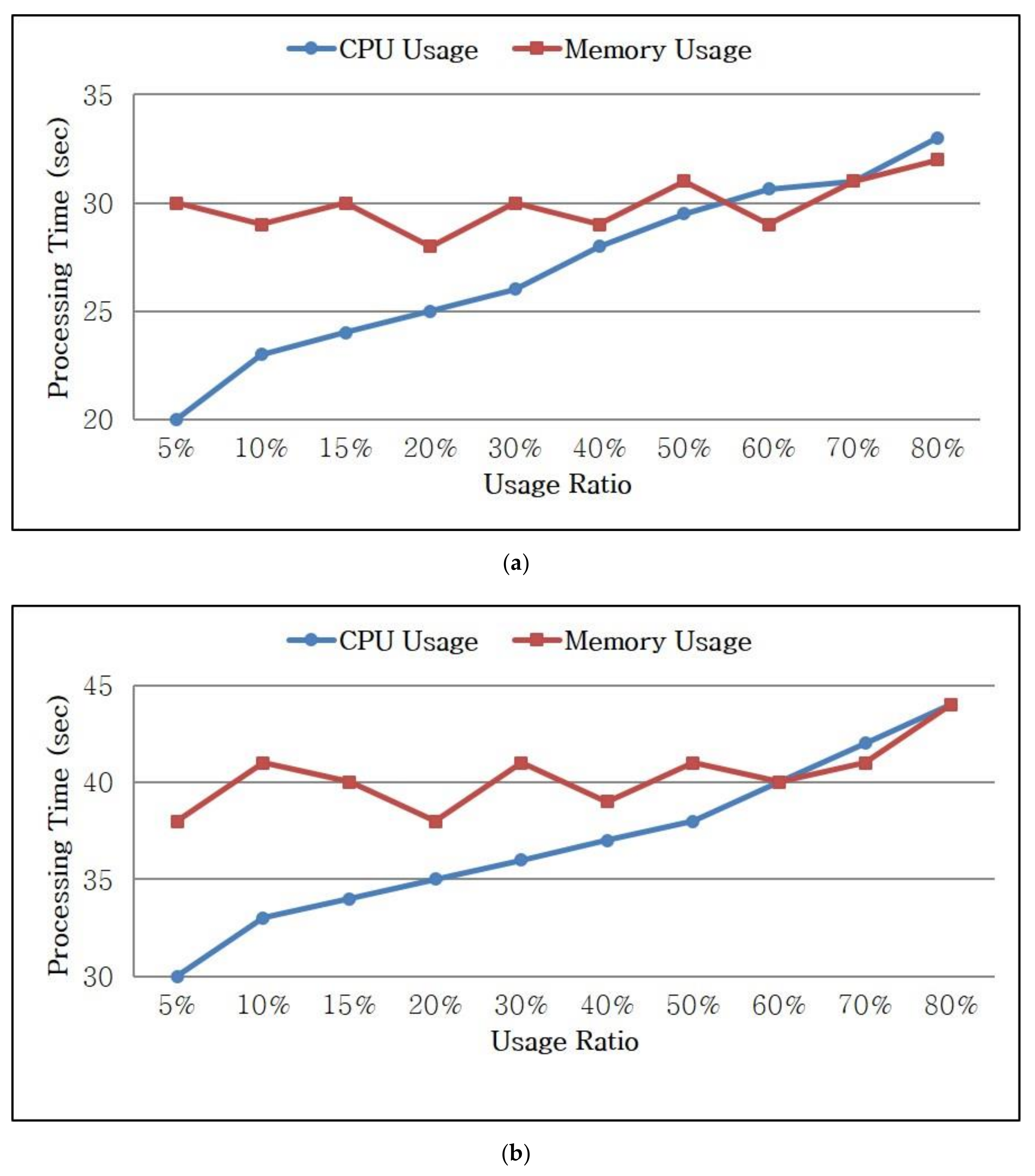
Figure 7 illustrates the processing times of the proposed scheme for queries with respect to the CPU and memory usage.
Figure 7a shows the processing time for a simple query, such as word count, and
Figure 7b shows that for a complex query, such as k-means clustering. The processing times of the tasks varied based on the CPU usage, whereas no significant changes were observed with respect to the memory usage.
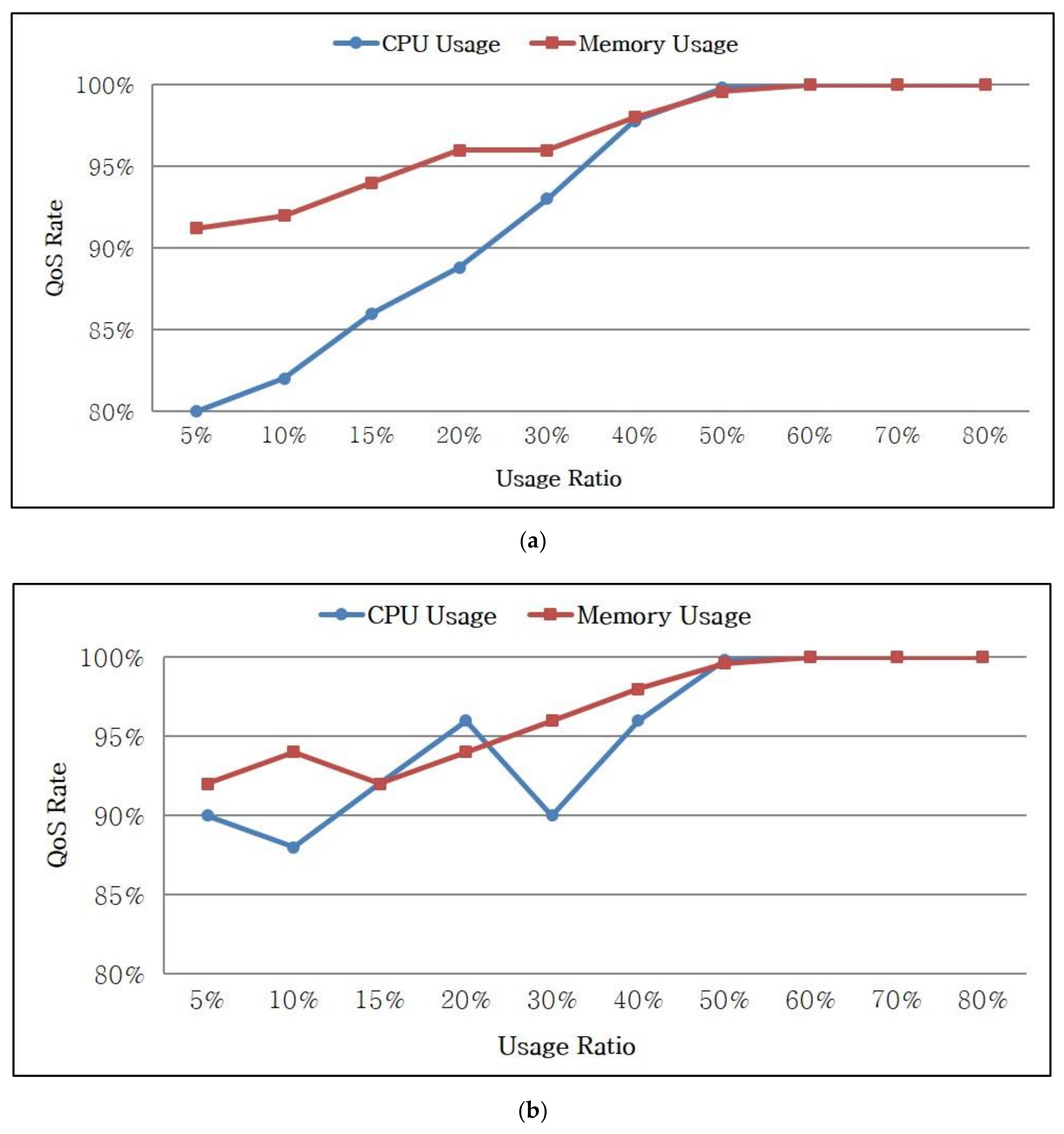
In addition, the quality of service (QoS) rate is examined for evaluating the performance. The QoS rate refers to the ration of the processed time to the deadline. For example, a QoS rate of 80% indicates that the task was completed within 80% of the deadline. This rate can be used to examine whether a task can be completed within a deadline.
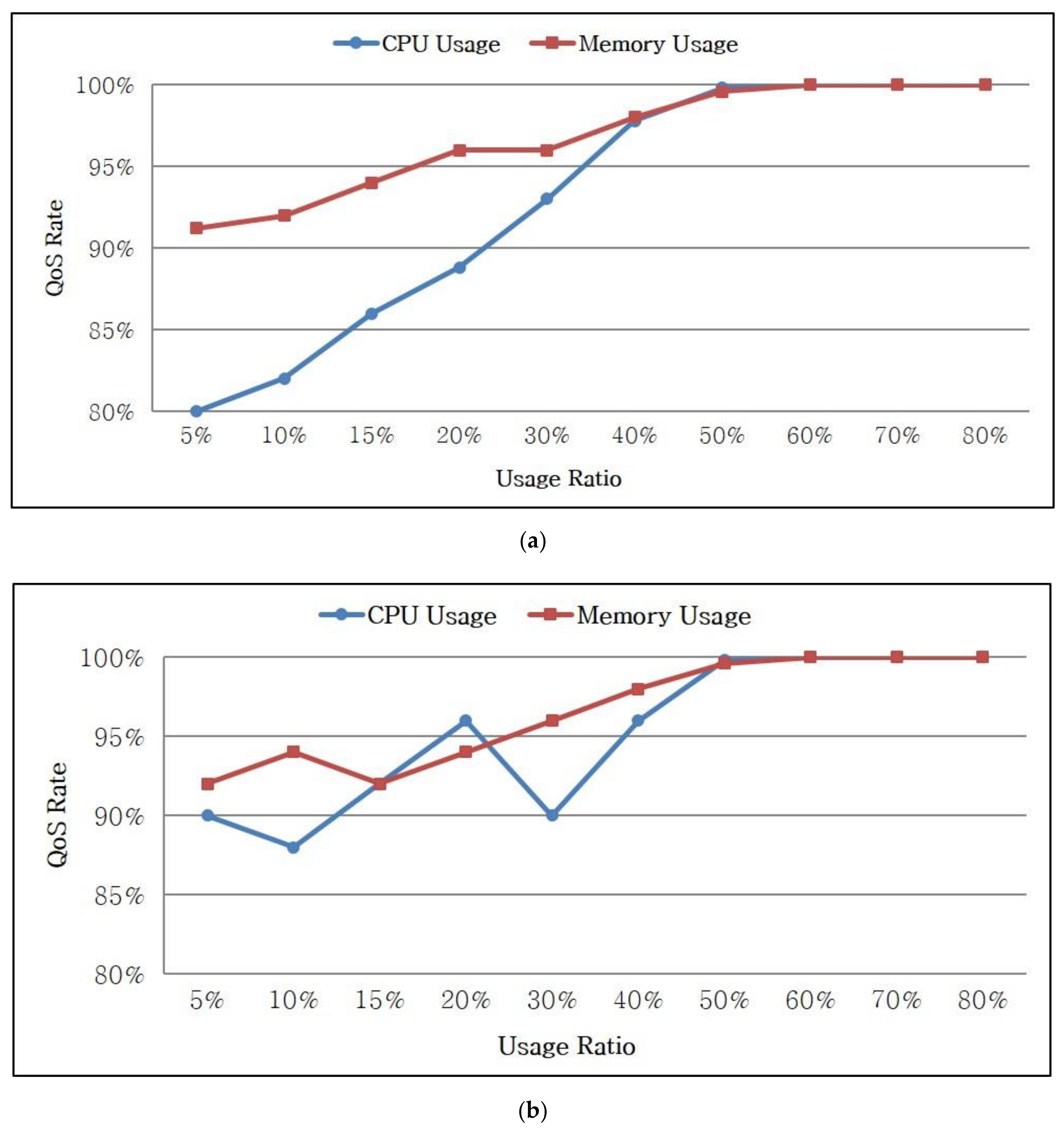
Figure 8 illustrates the QoS rates based on the query types.
Figure 8a shows the QoS rate for a simple query. When the CPU usage is 20%, the tasks are processed within 90% of the deadline because the number of tasks is small. When the CPU usage is increased to 50–80% during real-time stream processing, the usage also increases but all the tasks are processed within the deadline.
Figure 8b shows the QoS rate for a complex query. Similar to a simple query, the tasks are processed within 95% of the deadline if the usage is not high. Similarly, the proposed dynamic scheduling considering deadlines is valid because all tasks are processed within the deadline.
The proposed scheme is compared with existing scheduling schemes to verify the excellence of the former. The processing times are compared based on real-time data of various sizes and combination of queries (simple query + complex query). The conventional scheme, R-Storm, and the dynamic scheduling scheme proposed by Fan, adaptive scheduler, are comparatively evaluated.
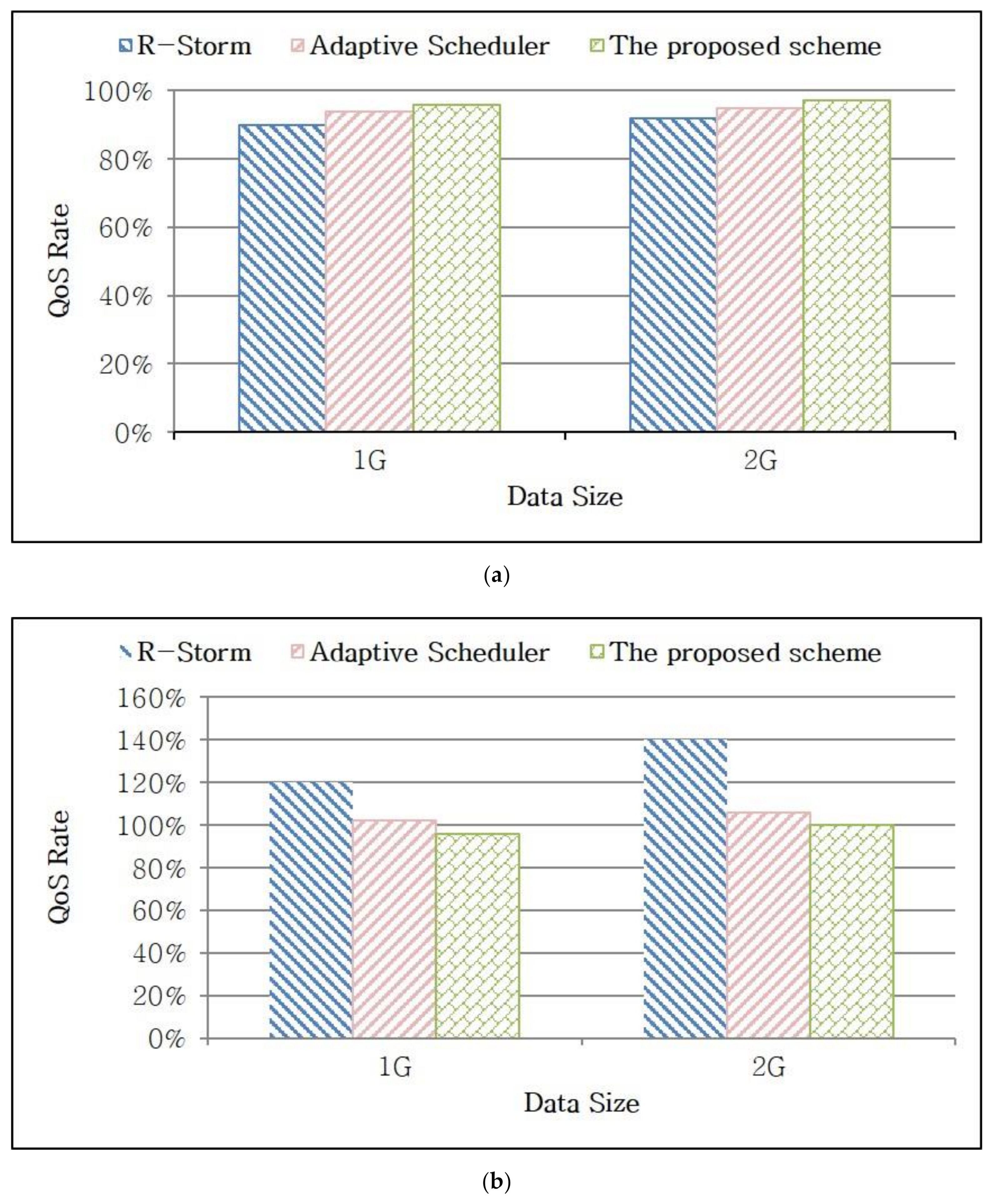
Figure 9 shows the performance evaluation based on the data size and the query. Word count and k-means clustering were performed using text files of 1 GB and 2 GB consisting of English alphabets and random numbers separately. R-Storm has the highest task processing time and increases the processing costs of the worker nodes owing to its computational complexity. The adaptive scheduler scheme and the proposed dynamic scheduling scheme process real-time data within 45 s for the 2 GB data. The proposed scheme reduces the processing time by 11–15% on average by performing a scheduling in which the task deadline and various loads are considered.
In addition, the QoS rates of the tasks were examined. In
Figure 10a, the average QoS rate of each worker node when processing a simple query is shown. The QoS rate is within 100% when the data size is small, thus indicating that all tasks are processed within the deadline. The proposed scheme has a relatively long delay time for a simple query. However, as shown in
Figure 10b, the QoS rates of all conventional schemes exceed 100% for a complex query, thus having a delay in the tasks. This delay is caused by failing to consider the task deadline. The proposed scheme does not pass the deadline regardless of the data size because the deadline as well as CPU and memory usage of the worker nodes were considered, and exhibits a 9–11% improved performance compared to the existing schemes.
5. Conclusions
In this paper, we have proposed a dynamic task scheduling scheme in which task deadline and node resources in Storm are considered. The proposed scheme considers the CPU usage, free memory size, and network load to calculate the load of each worker node and redistributes the tasks by assigning priorities based on the task deadline and the available resources. In this study, the loads were categorized into three types—CPU, memory, and CPU and memory loads—and dynamic task scheduling was performed with respect to the load type. Moreover, the throughput of each worker node was calculated by considering the state of a heterogeneous cluster, and the tasks with closer deadlines were distributed to the worker nodes with good performance to improve the QoS. The proposed scheme exhibited an approximately 15% more outstanding performance in terms of processing a complex query compared to existing schemes. Furthermore, both simple and complex queries were processed without passing the deadline in real-time processing. In future research, we will perform additional performance evaluations with the most recent existing dynamic task scheduling scheme. In addition, static task allocation and simple query processing performance will be improved by applying machine learning techniques.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}