
Vision-Based Robotic Arm Control Algorithm Using Deep Reinforcement Learning for Autonomous Objects Grasping



Abstract
:1. Introduction
- We suggest using YOLOv5 for more precise object position after its detection;
- We use backward projection for the extraction of the object’s 3D position;
- We apply IK to compute the angles of the joints at the detected position;
- We employ the DDPG algorithm to teach the arm to autonomously reach the wanted object;
- Our method outperforms the state-of-the-art approaches by reaching the goal after only 400 episodes with accuracy.
2. Overview of Reinforcement Learning
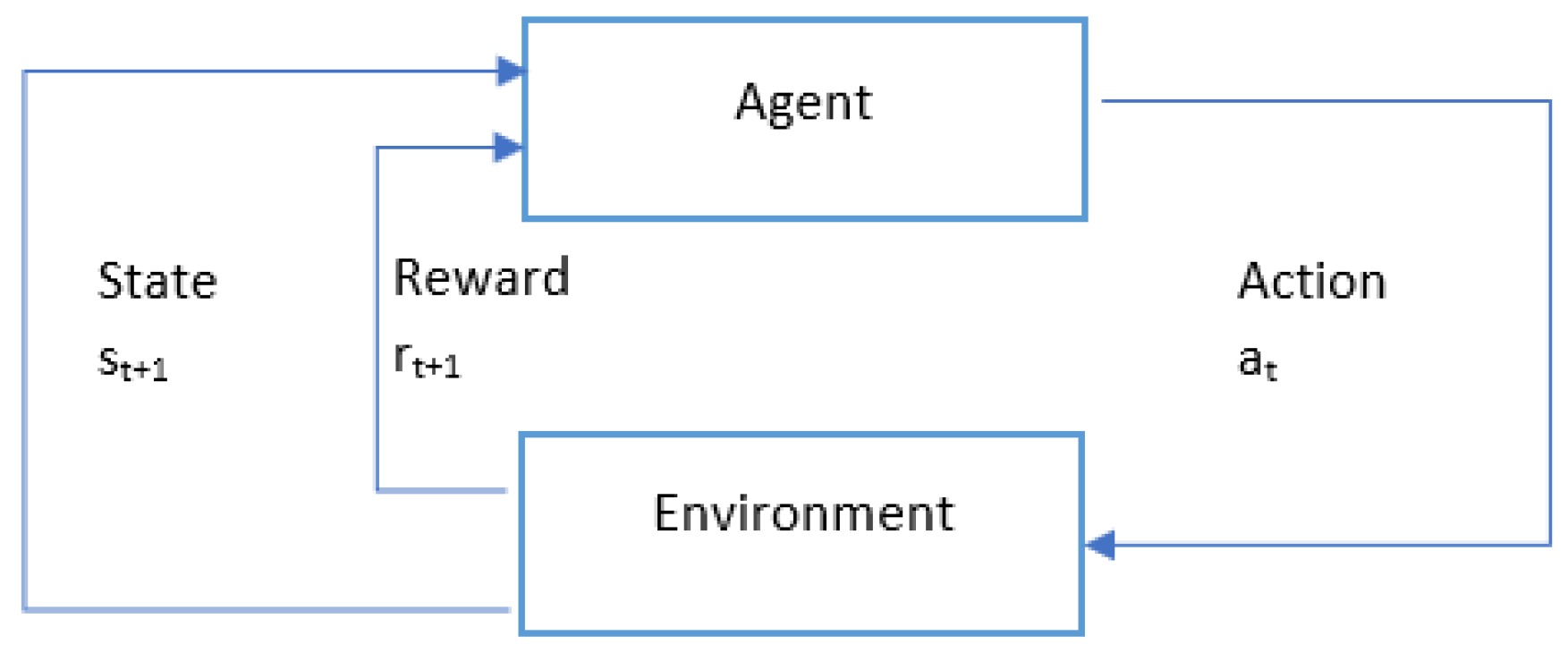
2.1. Reinforcement Learning
2.1.1. Q-Learning
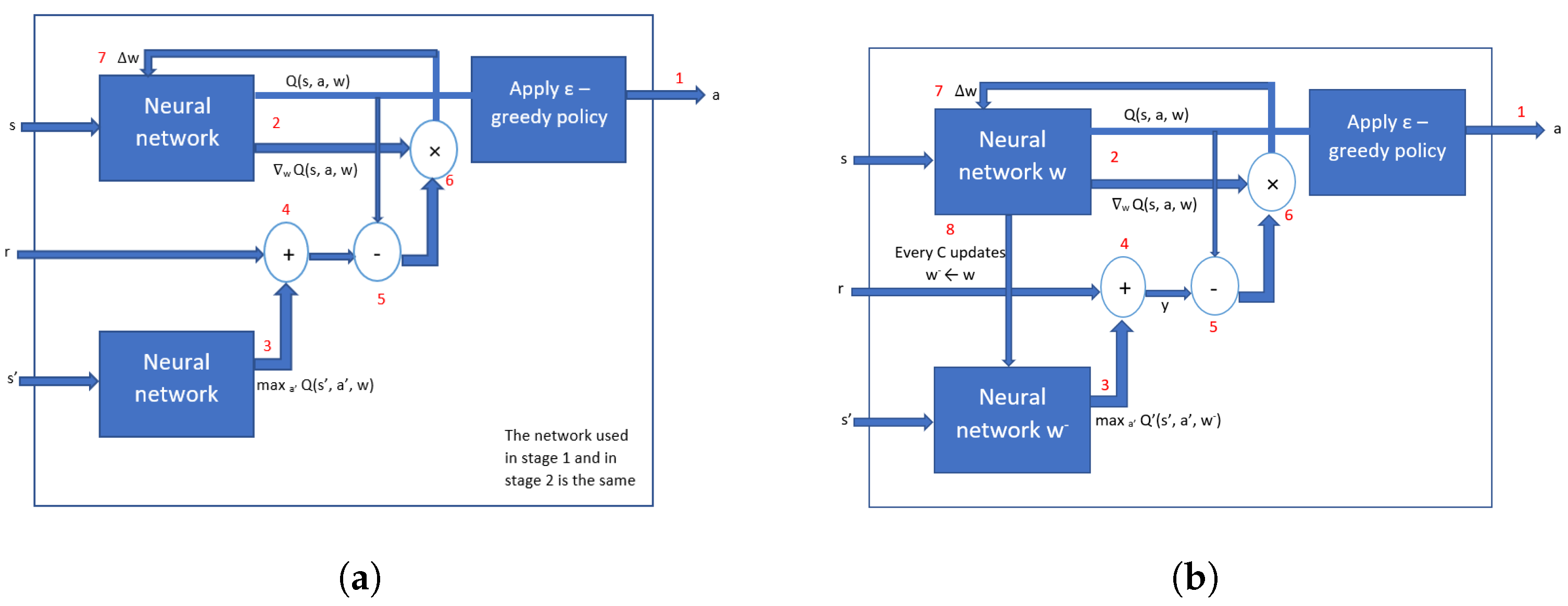
2.1.2. Deep Q-Learning (DQL)
2.1.3. Deep Deterministic Policy Gradient
3. Literature Review
3.1. Reinforcement Learning
3.2. Grasp Task
3.3. Object Detection
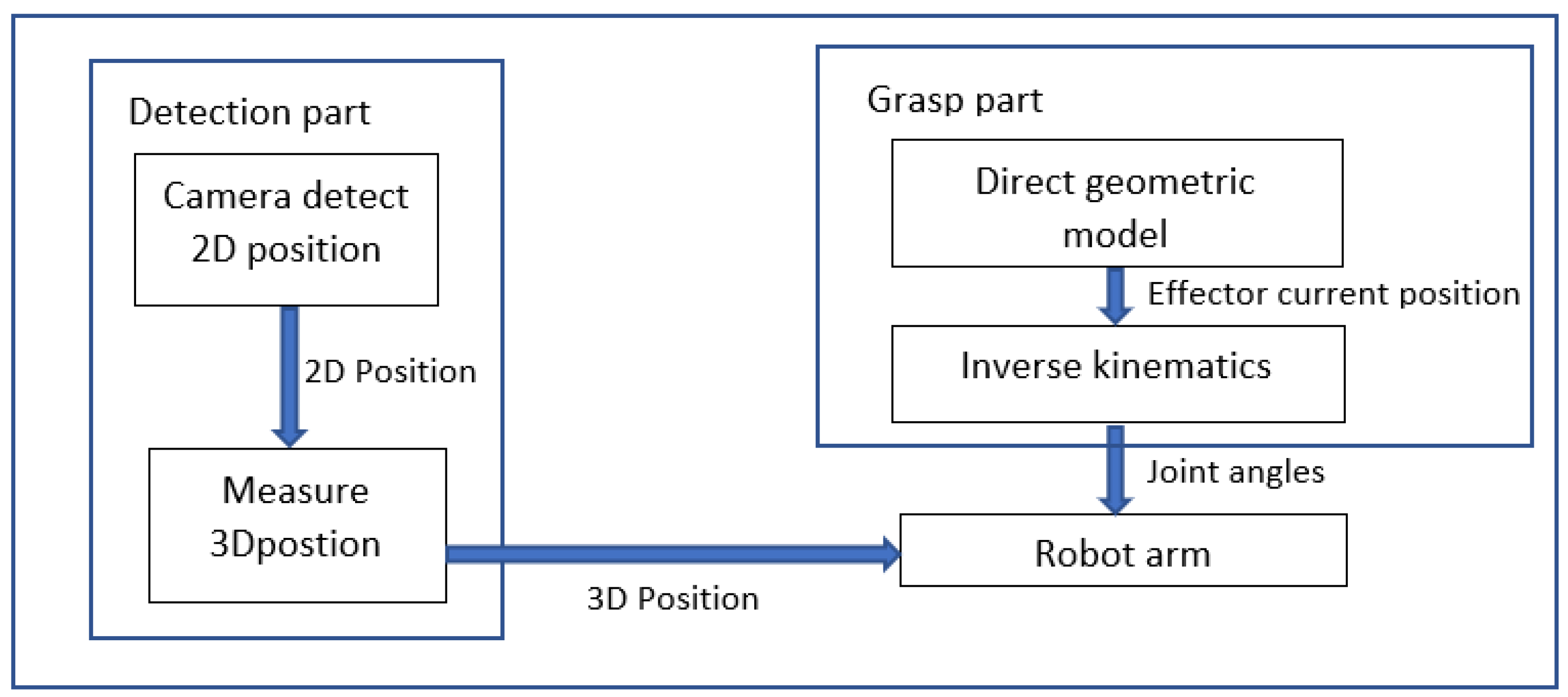
4. Methodology
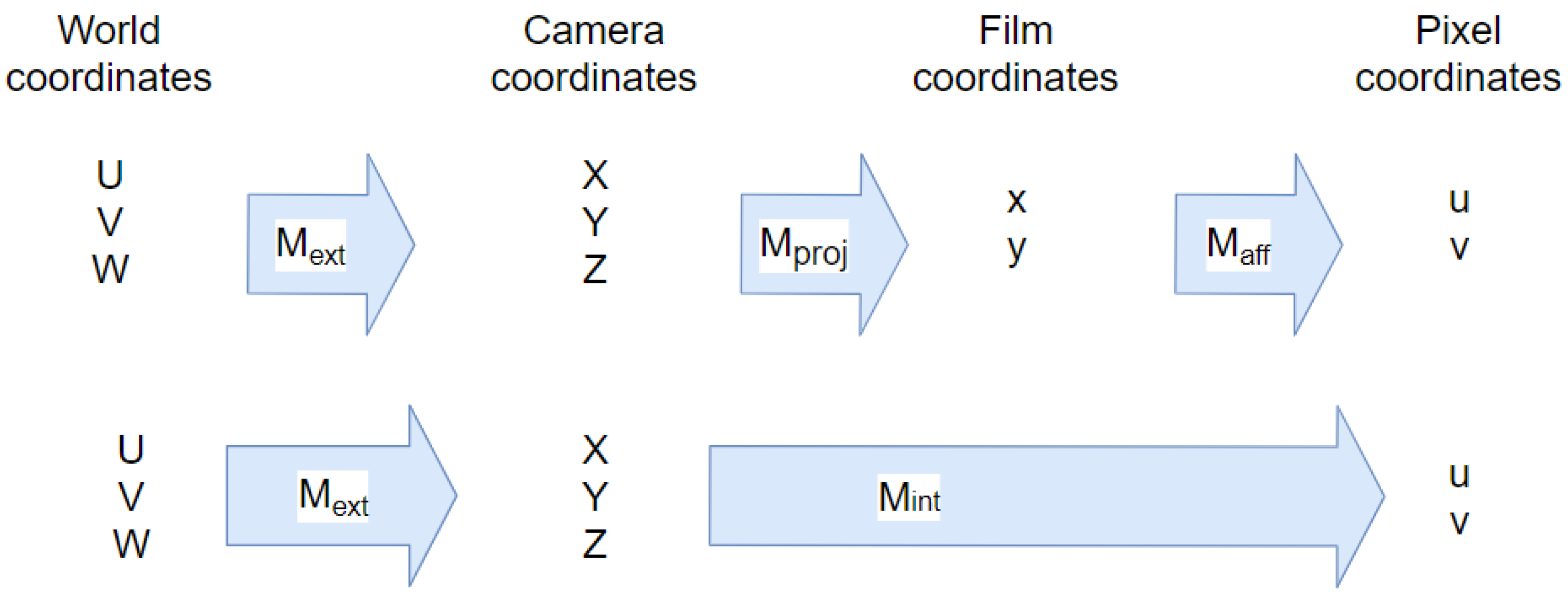
4.1. Object Pose Detection Method
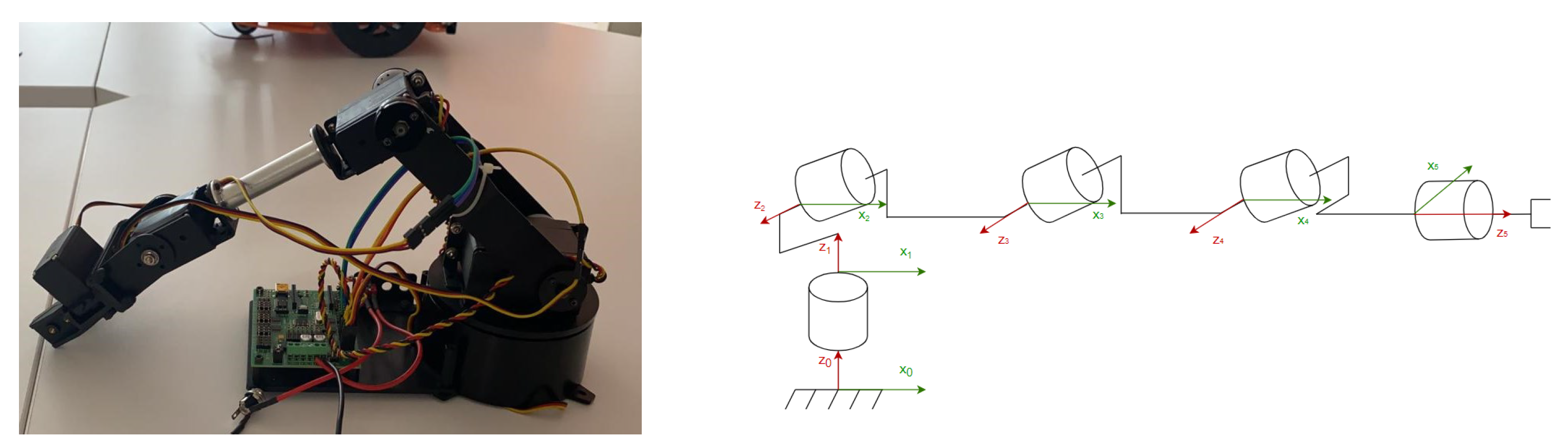
4.2. Kinematic Modeling and Inverse Kinematics
- Direct Geometric Model
- : the distance from to measured along ;
- : the twist angle between and measured about ;
- : the offset distance from to measured along ;
- : the angle between and measured about .
- Inverse kinematics
5. Experiments
5.1. Setup and Environment
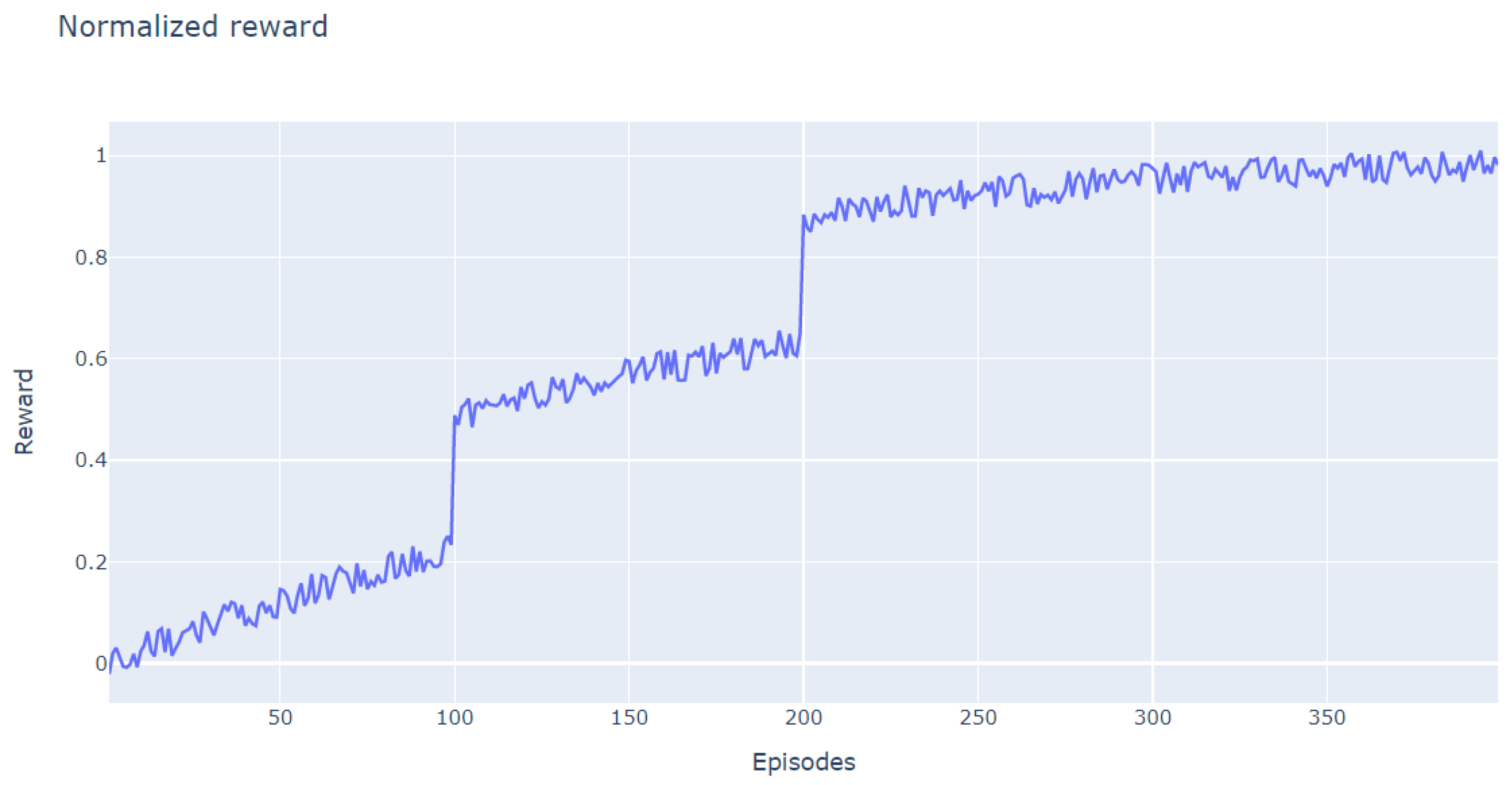
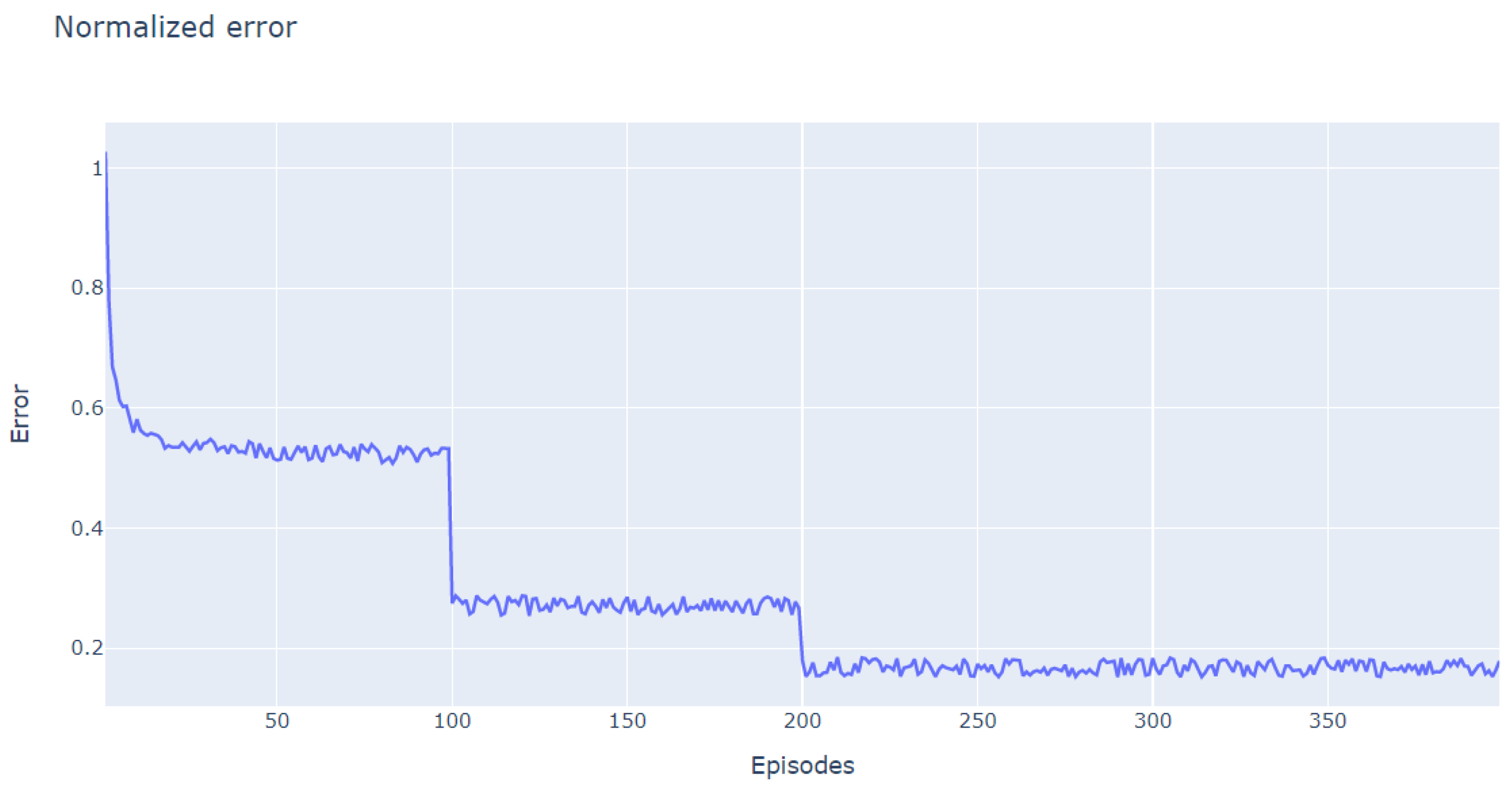
5.2. Implementation and Results
| Algorithm 1: DDPG algorithm for inverse kinematics learning |
 |
5.3. Visualization and Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Danielczuk, M.; Mahler, J.; Correa, C.; Goldberg, K. Linear Push Policies to Increase Grasp Access for Robot Bin Picking. In Proceedings of the IEEE 14th International Conference on Automation Science and Engineering (CASE), Munich, Germany, 20–24 August 2018; pp. 1249–1256. [Google Scholar] [CrossRef]
- Nam, C.; Lee, S.; Lee, J.; Cheong, S.H.; Kim, D.H.; Kim, C.; Kim, I.; Park, S.K. A Software Architecture for Service Robots Manipulating Objects in Human Environments. IEEE Access 2020, 8, 117900–117920. [Google Scholar] [CrossRef]
- Phaniteja, S.; Dewangan, P.; Guhan, P.; Sarkar, A.; Krishna, K.M. A deep reinforcement learning approach for dynamically stable inverse kinematics of humanoid robots. In Proceedings of the IEEE International Conference on Robotics and Biomimetics (ROBIO), Macau, Macao, 5–8 December 2017; pp. 1818–1823. [Google Scholar] [CrossRef] [Green Version]
- Vincze, M. Learn, Detect, and Grasp Objects in Real-World Settings; Springer: Berlin/Heidelberg, Germany, 2020; p. 7. [Google Scholar]
- Morrison, D.; Corke, P.; Leitner, J. Learning robust, real-time, reactive robotic grasping. Int. J. Robot. Res. 2019, 19. [Google Scholar] [CrossRef]
- Du, G.; Wang, K.; Lian, S.; Zhao, K. Vision-based Robotic Grasping From Object Localization, Object Pose Estimation to Grasp Estimation for Parallel Grippers: A Review. arXiv 2020, arXiv:1905.06658. [Google Scholar] [CrossRef]
- Xiao, T.; Jang, E.; Kalashnikov, D.; Levine, S.; Ibarz, J.; Hausman, K.; Herzog, A. Thinking While Moving: Deep Reinforcement Learning with Concurrent Control. arXiv 2020, arXiv:2004.06089. [Google Scholar]
- Ficuciello, F. Hand-arm autonomous grasping: Synergistic motions to enhance the learning process. Intell. Serv. Robot. 2019, 12, 17–25. [Google Scholar] [CrossRef]
- Von Oehsen, T.; Fabisch, A.; Kumar, S.; Kirchner, E.F. Comparison of Distal Teacher Learning with Numerical and Analytical Methods to Solve Inverse Kinematics for Rigid-Body Mechanisms. arXiv 2020, arXiv:2003.00225. [Google Scholar]
- Nian, R.; Liu, J.; Huang, E.B. A review On reinforcement learning: Introduction and applications in industrial process control. Comput. Chem. Eng. 2020, 139, 106886. [Google Scholar] [CrossRef]
- Nguyen, H. Review of Deep Reinforcement Learning for Robot Manipulation. In Proceedings of the 2019 Third IEEE International Conference on Robotic Computing (IRC), Naples, Italy, 25–27 February 2019; pp. 590–595. [Google Scholar] [CrossRef]
- Quillen, D.; Jang, E.; Nachum, O.; Finn, C.; Ibarz, J.; Levine, S. Deep Reinforcement Learning for Vision-Based Robotic Grasping: A Simulated Comparative Evaluation of Off-Policy Methods. In Proceedings of the 2018 IEEE International Conference on Robotics and Automation (ICRA), Brisbane, QLD, Australia, 21–25 May 2018; p. 8. [Google Scholar]
- Mohammed, M.Q.; Chung, K.L.; Chyi, C.S. Review of Deep Reinforcement Learning-Based Object Grasping: Techniques, Open Challenges and Recommendations. IEEE Access 2020, 8, 178450–178481. [Google Scholar] [CrossRef]
- Aitygulov, E.E. The Use of Reinforcement Learning in the Task of Moving Objects with the Robotic Arm. In Proceedings of the Artificial Intelligence 5th RAAI Summer School, Dolgoprudny, Russia, 4–7 July 2019. [Google Scholar]
- Franceschetti, A.; Tosello, E.; Castaman, N.; Ghidoni, S. Robotic Arm Control and Task Training through Deep Reinforcement Learning. arXiv 2020, arXiv:2005.02632. [Google Scholar]
- Guo, Z.; Huang, J. A Reinforcement Learning Approach for Inverse Kinematics of Arm Robot. In Proceedings of the 2019 The 4th International Conference on Robotics, Control and Automation, Guangzhou, China, 26–28 July 2019; p. 5. [Google Scholar]
- Joshi, S.; Kumra, S.; Sahin, F. Robotic Grasping using Deep Reinforcement Learning. In Proceedings of the 2020 IEEE 16th International Conference on Automation Science and Engineering (CASE), Hong Kong, China, 20–21 August 2020; pp. 1461–1466. [Google Scholar] [CrossRef]
- Zeng, A.; Song, S.; Welker, S.; Lee, J.; Rodriguez, A.; Funkhouser, T.A. Learning Synergies between Pushing and Grasping with Self-supervised Deep Reinforcement Learning. In Proceedings of the 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Madrid, Spain, 1–5 October 2018; p. 8. [Google Scholar]
- Kalashnikov, D. Scalable Deep Reinforcement Learning for Vision-Based Robotic Manipulation. Available online: http://proceedings.mlr.press/v87/kalashnikov18a.html (accessed on 17 August 2021).
- Liu, C.; Gao, J.; Bi, Y.; Shi, X.; Tian, D. A Multitasking-Oriented Robot Arm Motion Planning Scheme Based on Deep Reinforcement Learning and Twin Synchro-Control. Sensors 2020, 20, 3515. [Google Scholar] [CrossRef] [PubMed]
- Kerzel, M.; Mohammadi, H.B.; Zamani, M.A.; Wermter, S. Accelerating Deep Continuous Reinforcement Learning through Task Simplification. In Proceedings of the 2018 International Joint Conference on Neural Networks (IJCNN), Rio de Janeiro, Brazil, 8–13 July 2018; pp. 1–6. [Google Scholar] [CrossRef]
- Lin, M.; Shan, L.; Zhang, Y. Research on robot arm control based on Unity3D machine learning. J. Phys. 2020, 1633, 012007. [Google Scholar] [CrossRef]
- Zhang, L.; Zhang, H.; Yang, H.; Bian, G.B.; Wu, W. Multi-Target Detection and Grasping Control for Humanoid Robot NAO. Int. J. Adapt. Control. Signal Process. 2019, 33, 1225–1237. [Google Scholar] [CrossRef]
- Onishi, Y. An Automated Fruit Harvesting Robot by Using Deep Learning. Robomech J. 2019, 6, 1–8. [Google Scholar] [CrossRef] [Green Version]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar] [CrossRef] [Green Version]
- Ahmad, T.; Ma, Y.; Yahya, M.; Ahmad, B.; Nazir, S.; Haq, A.U. Object Detection through Modified YOLO Neural Network. Sci. Program. 2020, 2020, 1–10. [Google Scholar] [CrossRef]
- Sang, J.; Wu, Z.; Guo, P.; Hu, H.; Xiang, H.; Zhang, Q.; Cai, B. An Improved YOLOv2 for Vehicle Detection. Sensors 2018, 18, 4272. [Google Scholar] [CrossRef] [Green Version]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. YOLOv4: Optimal Speed and Accuracy of Object Detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Kasper-Eulaers, M.; Hahn, N.; Berger, S.; Sebulonsen, T.; Myrland, Ø.; Kummervold, P.E. Short Communication: Detecting Heavy Goods Vehicles in Rest Areas in Winter Conditions Using YOLOv5. Algorithms 2021, 14, 114. [Google Scholar] [CrossRef]
- Akkar, H.A.R.; A-Amir, A.N. Kinematics Analysis and Modeling of 6 Degree of Freedom Robotic Arm from DFROBOT on Labview. Res. J. Appl. Sci. Eng. Technol. 2016, 13, 69–575. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Link | i | mm | Degree | mm | Degree |
|---|---|---|---|---|---|
| 0-1 | 1 | 0 | 0 | ||
| 1-2 | 2 | 0 | 0 | ||
| 2-3 | 3 | 0 | 0 | ||
| 3-4 | 4 | 0 | 0 | ||
| 4-5 | 5 | 0 |
| Accuracy | 100 Episodes | 200 Episodes | 300 Episodes | 400 Episodes |
|---|---|---|---|---|
| Min | 3% | 24% | 63% | 93% |
| Max | 22% | 61% | 89% | 98% |
| Mean | 76% |
| Accuracy | 2700 Episodes | 3000 Episodes | 3900 Episodes | 9900 Episodes |
|---|---|---|---|---|
| Min | 80% | 76% | 88% | 87% |
| Max | 84% | 83% | 89% | 93% |
| Mean | 88.66% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sekkat, H.; Tigani, S.; Saadane, R.; Chehri, A. Vision-Based Robotic Arm Control Algorithm Using Deep Reinforcement Learning for Autonomous Objects Grasping. Appl. Sci. 2021, 11, 7917. https://doi.org/10.3390/app11177917
Sekkat H, Tigani S, Saadane R, Chehri A. Vision-Based Robotic Arm Control Algorithm Using Deep Reinforcement Learning for Autonomous Objects Grasping. Applied Sciences. 2021; 11(17):7917. https://doi.org/10.3390/app11177917
Chicago/Turabian StyleSekkat, Hiba, Smail Tigani, Rachid Saadane, and Abdellah Chehri. 2021. "Vision-Based Robotic Arm Control Algorithm Using Deep Reinforcement Learning for Autonomous Objects Grasping" Applied Sciences 11, no. 17: 7917. https://doi.org/10.3390/app11177917
APA StyleSekkat, H., Tigani, S., Saadane, R., & Chehri, A. (2021). Vision-Based Robotic Arm Control Algorithm Using Deep Reinforcement Learning for Autonomous Objects Grasping. Applied Sciences, 11(17), 7917. https://doi.org/10.3390/app11177917