
A Synthesized Study Based on Machine Learning Approaches for Rapid Classifying Earthquake Damage Grades to RC Buildings

 ,
,  ,
,  ,
,  ,
,  and
and
Abstract
1. Introduction
Background of Study
2. Background of the Selected Earthquakes
Choice of Building’s Damage Inducing Parameters
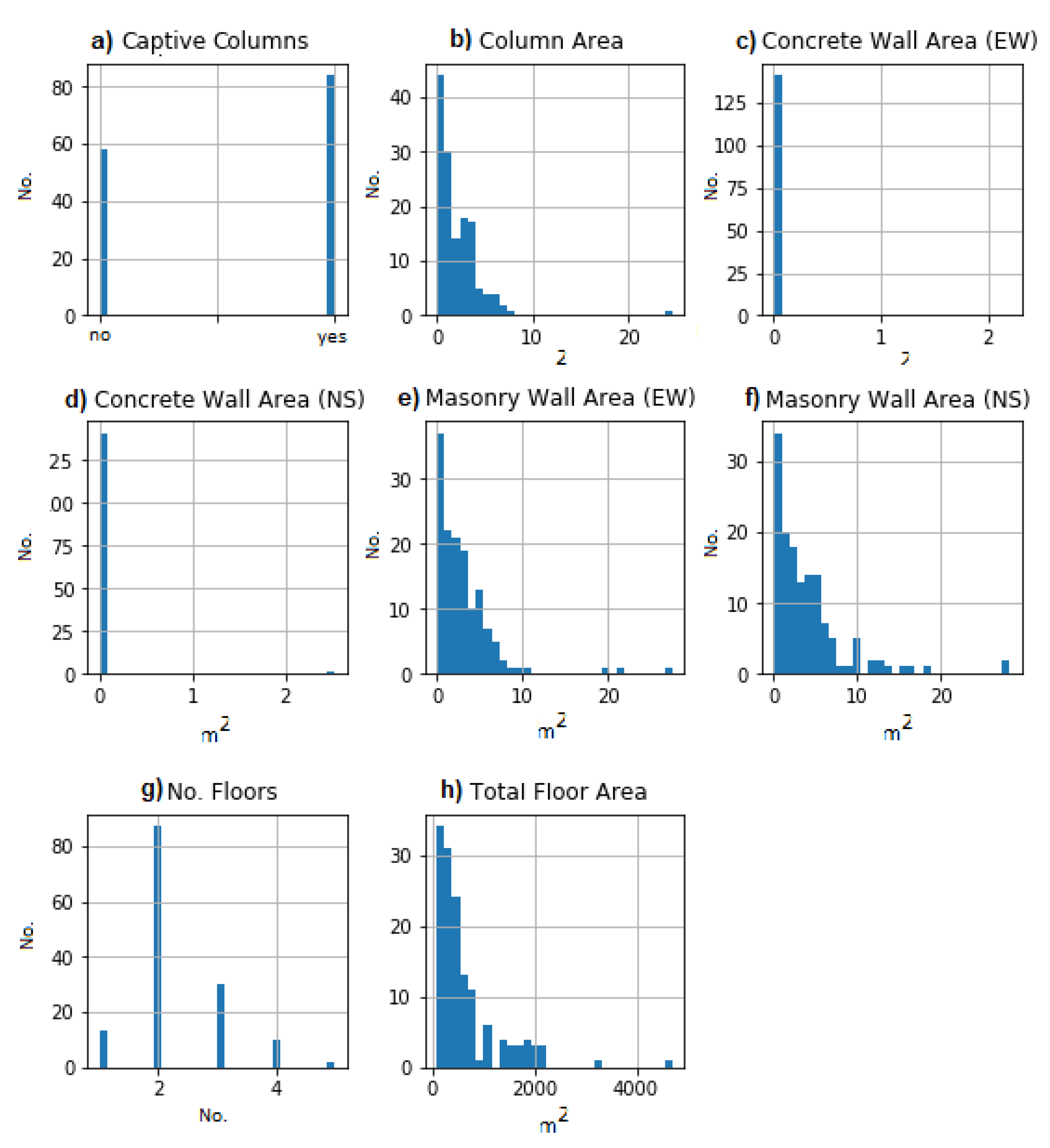
3. Input Data Interpretations
4. Supervised Learning as Statistical Analysis for RVS
4.1. Support Vector Machine
- Linear: ;
- Polynomial: ;
- Gaussian RBF: ;
- Sigmoid: ;
- K: kernel;
- d: degree of polynomial;
- a and b: vectors in the input space ∈;
- : mapping function;
- r: an independent parameter, such that r ≥ 0.
4.2. K-Nearest Neighbor
- Euclidean: ();
- Manhattan: ();
- Minkowski: (.
- is the ith value of and is the ith value of ,
- k is the number of nearest neighbors, and
- q is a positive value.
4.3. Bootstrap Aggregation/Bagging
4.4. Random Forest
4.5. Extra Tree
5. Data Analysis and Method Implementation
5.1. First Stage: Data Pre-Processing
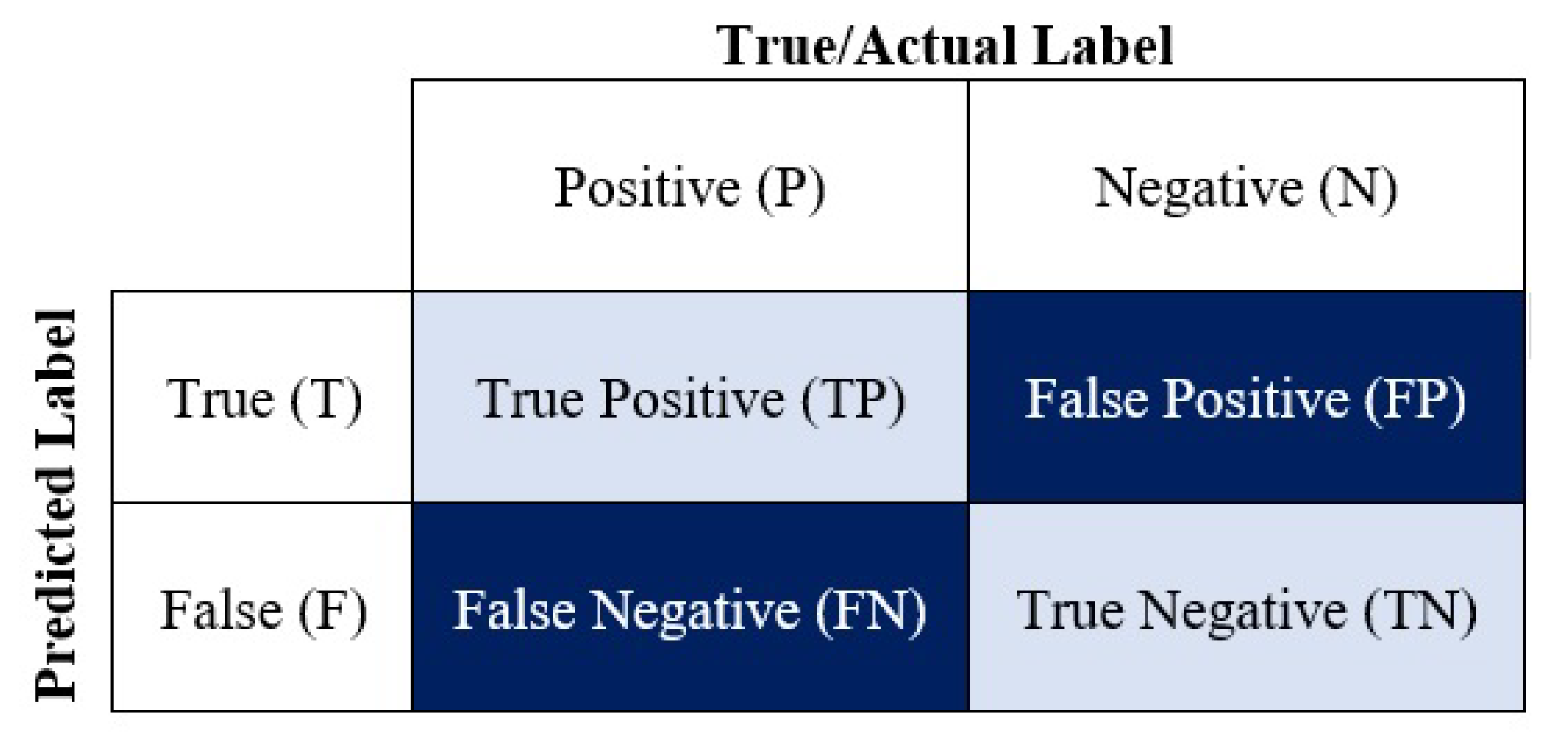
5.2. Second Stage: Model Evaluation
5.3. Third Stage: Model Selection and Visualization
5.4. Fourth Stage: Hyper-Parameter Optimization and Model Fitting
- Number of Trees: One of the critical hyperparameters for the ET classifier is the number of trees that the ensemble holds, represented by the argument “n_estimator” ExtraTreeClassifier. In general, the number of trees increases until the performance of the model stabilizes. A high number of trees may lead to overfitting and a slowing down of the learning process, but the unlikely ET algorithms approach appears to be immune to overfitting the training dataset given that the learning algorithm is stochastic.
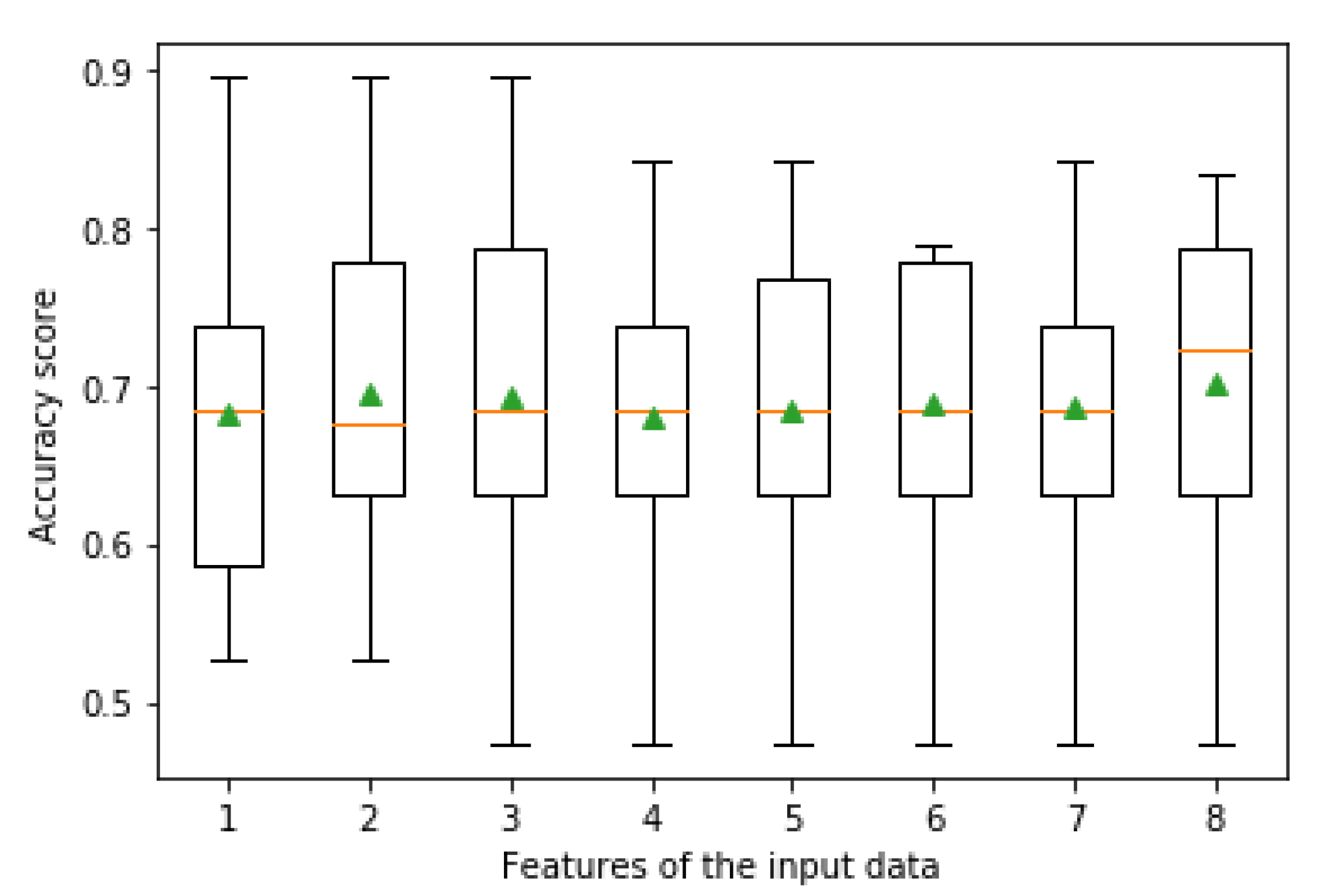
- Feature Selection: The number of randomly sampled features for each split point is perhaps an essential factor to tune for ET, but it is not sensitive to the use of any specific value. Argument “max_features” in the classifier is used to select the number of features. While selecting the features randomly, the generalization error can get influenced in two ways; first, when many features are selected, the strength of individual tree increases, second when very few features are selected, the correlation among the trees decreases, and overall the whole forest gets strengthened.
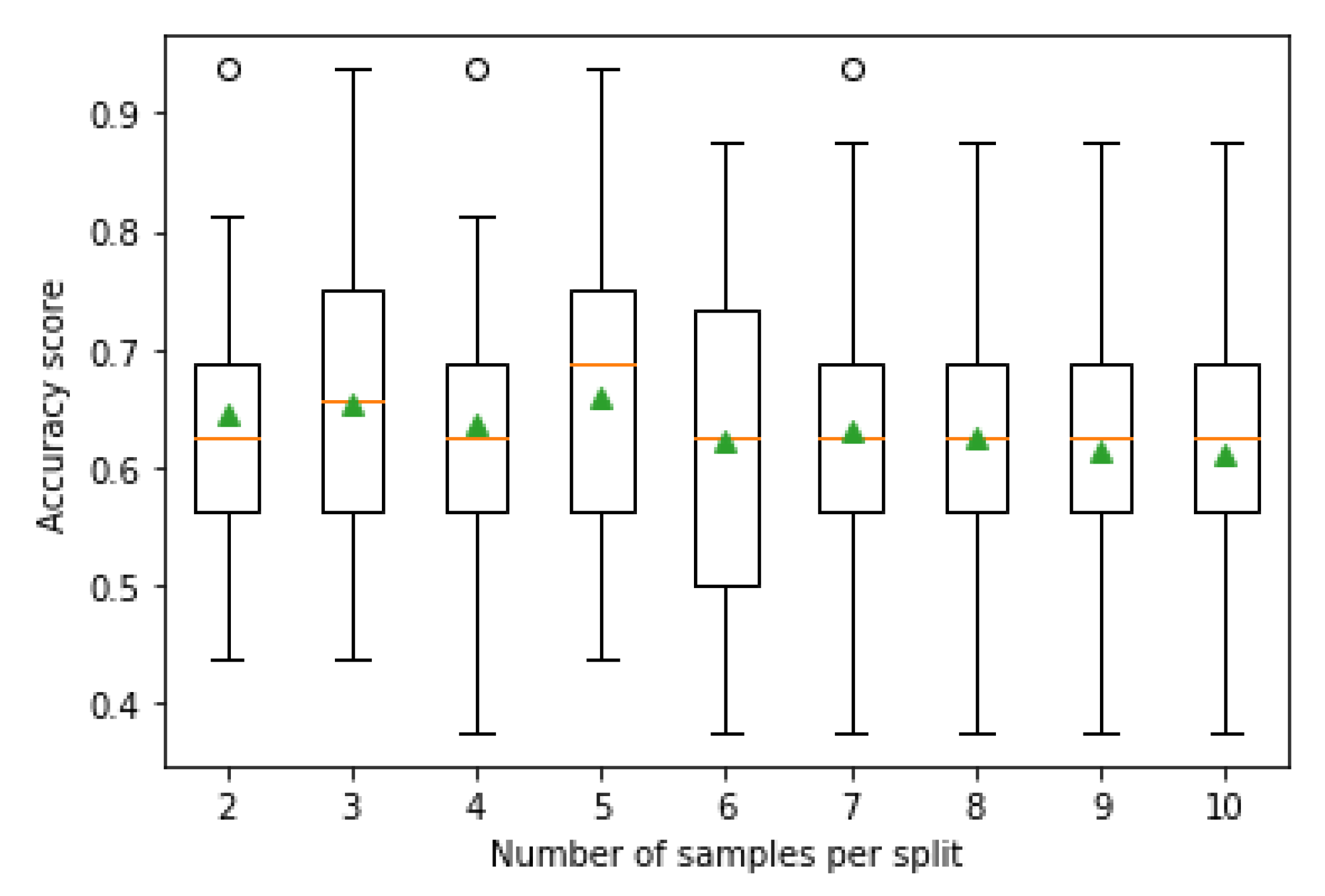
- Minimum Number of Samples per Split: The last hyperparameter for optimizing is the number of samples in a tree node before any split. The tree adds a new split that occurs when the number of samples divides equally or if the value exceeds. The argument “min_samples_split” represents the minimum number of samples required to split an internal node, and the default value is two samples. Smaller numbers of samples result in more splits and a more rooted, more specialized tree. In turn, this can mean a lower correlation between the predictions made by trees in the ensemble and potentially lift performance.
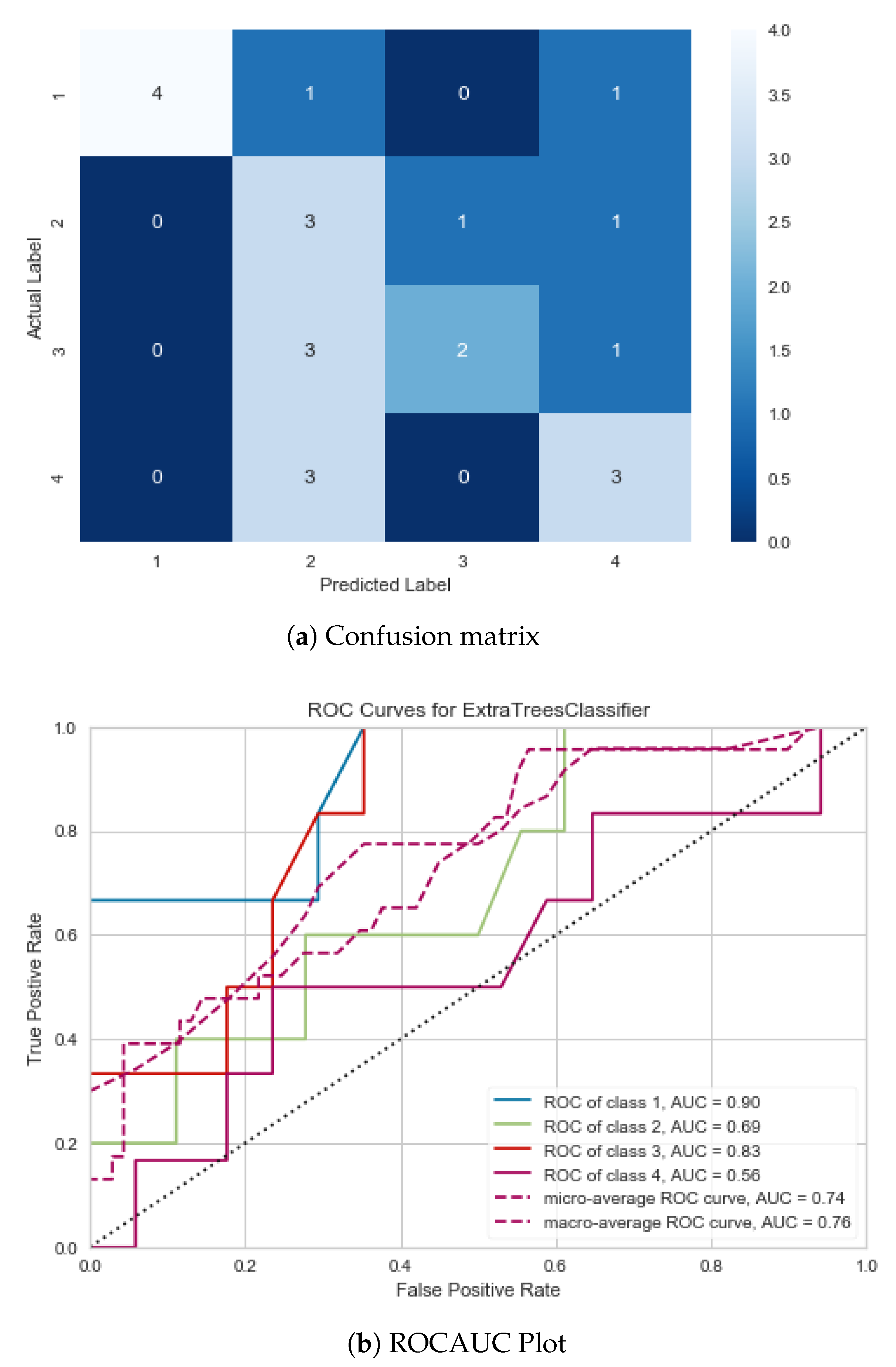
5.5. Results and Analysis
6. Discussion and Conclusions
6.1. Adequacy of ML Techniques
6.2. Applicability of ML-Based Methods to RVS Purposes
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| ACI | American Concrete Institute |
| ANN | Artificial Neural Network |
| AUC | Area under the Curve |
| ET | Extra Tree |
| ETE | Extra Tree Ensemble |
| ESPOL | Escuela Superior Politécnica del Litoral |
| FEMA | Federal Emergency Management Agency |
| KNN | K-Nearest Neighbor |
| MCE | Maximum Considered Earthquake |
| MM | Modified Mercalli |
| ML | Machine Learning |
| RC | Reinforced Concrete |
| RF | Random Forest |
| ROC | Receiver Operating Characteristics |
| RVS | Rapid Visual Screening |
| SVA | Seismic Vulnerability Assessment |
| SVM | Support Vector Machine |
References
- FEMA P-154. Rapid Visual Screening of Buildings for Potential Seismic Hazards: A Handbook, 3rd ed.; Homeland Security Department, Federal Emergency Management Agency: Washington, DC, USA, 2015. [Google Scholar]
- Harirchian, E.; Hosseini, S.E.A.; Jadhav, K.; Kumari, V.; Rasulzade, S.; Işık, E.; Wasif, M.; Lahmer, T. A review on application of soft computing techniques for the rapid visual safety evaluation and damage classification of existing buildings. J. Build. Eng. 2021, 43, 102536. [Google Scholar] [CrossRef]
- Yadollahi, M.; Adnan, A.; Mohamad zin, R. Seismic Vulnerability Functional Method for Rapid Visual Screening of Existing Buildings. Arch. Civ. Eng. 2012, 3, 363–377. [Google Scholar] [CrossRef][Green Version]
- Yang, Y.; Goettel, K.A. Enhanced Rapid Visual Screening (E-RVS) Method for Prioritization of Seismic Retrofits in Oregon; Oregon Department of Geology and Mineral Industries: Portland, OR, USA, 2007. [Google Scholar]
- Harirchian, E.; Jadhav, K.; Mohammad, K.; Aghakouchaki Hosseini, S.E.; Lahmer, T. A comparative study of MCDM methods integrated with rapid visual seismic vulnerability assessment of existing RC structures. Appl. Sci. 2020, 10, 6411. [Google Scholar] [CrossRef]
- Jain, S.; Mitra, K.; Kumar, M.; Shah, M. A proposed rapid visual screening procedure for seismic evaluation of RC-frame buildings in India. Earthq. Spectra 2010, 26, 709–729. [Google Scholar] [CrossRef]
- Chanu, N.; Nanda, R. A Proposed Rapid Visual Screening Procedure for Developing Countries. Int. J. Geotech. Earthq. Eng. 2018, 9, 38–45. [Google Scholar] [CrossRef]
- Sinha, R.; Goyal, A. A National Policy for Seismic Vulnerability Assessment of Buildings and Procedure for Rapid Visual Screening of Buildings for Potential Seismic Vulnerability; Report to Disaster Management Division; Ministry of Home Affairs, Government of India: Mumbai, India, 2004. [Google Scholar]
- Rai, D.C. Review of Documents on Seismic Evaluation of Existing Buildings; IIT Kanpur and Gujarat State Disaster Mitigation Authority: Gandhinagar, India, 2005; pp. 1–120. [Google Scholar]
- Mishra, S. Guide Book for Integrated Rapid Visual Screening of Buildings for Seismic Hazard; TARU Leading Edge Private Ltd.: New Delhi, India, 2014. [Google Scholar]
- Luca, F.; Verderame, G. Seismic Vulnerability Assessment: Reinforced Concrete Structures; Springer: Berlin/Heidelberg, Germany, 2014. [Google Scholar]
- Chanu, N.; Nanda, R. Rapid Visual Screening Procedure of Existing Building Based on Statistical Analysis. Int. J. Disaster Risk Reduct. 2018, 28, 720–730. [Google Scholar]
- Özhendekci, N.; Özhendekci, D. Rapid Seismic Vulnerability Assessment of Low- to Mid-Rise Reinforced Concrete Buildings Using Bingöl’s Regional Data. Earthq. Spectra 2012, 28, 1165–1187. [Google Scholar] [CrossRef]
- Harirchian, E.; Lahmer, T. Improved Rapid Assessment of Earthquake Hazard Safety of Structures via Artificial Neural Networks. In Proceedings of the 2020 5th International Conference on Civil Engineering and Materials Science (ICCEMS 2020), Singapore, 15–18 May 2020; IOP Publishing: Bristol, UK, 2020; Volume 897, p. 012014. [Google Scholar]
- Harirchian, E.; Lahmer, T.; Rasulzade, S. Earthquake Hazard Safety Assessment of Existing Buildings Using Optimized Multi-Layer Perceptron Neural Network. Energies 2020, 13, 2060. [Google Scholar] [CrossRef]
- Arslan, M.; Ceylan, M.; Koyuncu, T. An ANN approaches on estimating earthquake performances of existing RC buildings. Neural Netw. World 2012, 22, 443–458. [Google Scholar] [CrossRef]
- Roeslin, S.; Ma, Q.; Juárez-Garcia, H.; Gómez-Bernal, A.; Wicker, J.; Wotherspoon, L. A machine learning damage prediction model for the 2017 Puebla-Morelos, Mexico, earthquake. Earthq. Spectra 2020, 36, 314–339. [Google Scholar] [CrossRef]
- Mangalathu, S.; Sun, H.; Nweke, C.C.; Yi, Z.; Burton, H.V. Classifying earthquake damage to buildings using machine learning. Earthq. Spectra 2020, 36, 183–208. [Google Scholar] [CrossRef]
- Tesfamariam, S.; Liu, Z. Earthquake induced damage classification for reinforced concrete buildings. Struct. Saf. 2010, 32, 154–164. [Google Scholar] [CrossRef]
- Harirchian, E.; Kumari, V.; Jadhav, K.; Raj Das, R.; Rasulzade, S.; Lahmer, T. A machine learning framework for assessing seismic hazard safety of reinforced concrete buildings. Appl. Sci. 2020, 10, 7153. [Google Scholar] [CrossRef]
- Harirchian, E.; Harirchian, A. Earthquake Hazard Safety Assessment of Buildings via Smartphone App: An Introduction to the Prototype Features-30. In 30. Forum Bauinformatik: Von jungen Forschenden für junge Forschende: September 2018, Informatik im Bauwesen; Professur Informatik im Bauwesen, Bauhaus-Universität Weimar: Weimar, Germany, 2018; pp. 289–297. [Google Scholar]
- Yu, Q.; Wang, C.; McKenna, F.; Stella, X.Y.; Taciroglu, E.; Cetiner, B.; Law, K.H. Rapid visual screening of soft-story buildings from street view images using deep learning classification. Earthq. Eng. Eng. Vib. 2020, 19, 827–838. [Google Scholar] [CrossRef]
- Ketsap, A.; Hansapinyo, C.; Kronprasert, N.; Limkatanyu, S. Uncertainty and fuzzy decisions in earthquake risk evaluation of buildings. Eng. J. 2019, 23, 89–105. [Google Scholar] [CrossRef]
- Mandas, A.; Dritsos, S. Vulnerability assessment of RC structures using fuzzy logic. WIT Trans. Ecol. Environ. 2004, 77, 10. [Google Scholar]
- Tesfamariam, S.; Saatcioglu, M. Seismic vulnerability assessment of reinforced concrete buildings using hierarchical fuzzy rule base modeling. Earthq. Spectra 2010, 26, 235–256. [Google Scholar] [CrossRef]
- Şen, Z. Rapid visual earthquake hazard evaluation of existing buildings by fuzzy logic modeling. Expert Syst. Appl. 2010, 37, 5653–5660. [Google Scholar] [CrossRef]
- Harirchian, E.; Lahmer, T. Developing a hierarchical type-2 fuzzy logic model to improve rapid evaluation of earthquake hazard safety of existing buildings. In Structures; Elsevier: Edinburgh, UK, 2020; Volume 28, pp. 1384–1399. [Google Scholar]
- Harirchian, E.; Lahmer, T. Improved Rapid Visual Earthquake Hazard Safety Evaluation of Existing Buildings Using a Type-2 Fuzzy Logic Model. Appl. Sci. 2020, 10, 2375. [Google Scholar] [CrossRef]
- Sucuoglu, H.; Yazgan, U.; Yakut, A. A Screening Procedure for Seismic Risk Assessment in Urban Building Stocks. Earthq. Spectra 2007, 23, 441–458. [Google Scholar] [CrossRef]
- Morfidis, K.; Kostinakis, K. Seismic parameters’ combinations for the optimum prediction of the damage state of R/C buildings using neural networks. Adv. Eng. Softw. 2017, 106, 1–16. [Google Scholar] [CrossRef]
- Jain, S.; Mitra, K.; Kumar, M.; Shah, M. A Rapid Visual Seismic Assessment Procedure for RC Frame Buildings in India. In Proceedings of the 9th US National and 10th Canadian Conference on Earthquake Engineering, Toronto, ON, Canada, 29 July 2010. [Google Scholar]
- Aldemir, A.; Sahmaran, M. Rapid screening method for the determination of seismic vulnerability assessment of RC building stocks. Bull. Earthq. Eng. 2019, 18, 1401–1416. [Google Scholar]
- Askan, A.; Yucemen, M. Probabilistic methods for the estimation of potential seismic damage: Application to reinforced concrete buildings in Turkey. Struct. Saf. 2010, 32, 262–271. [Google Scholar] [CrossRef]
- Morfidis, K.; Kostinakis, K. Use of Artificial Neural Networks in the r/c Buildings’ Seismic Vulnerabilty Assessment: The Practical Point of View. In Proceedings of the 7th International Conference on Computational Methods in Structural Dynamics and Earthquake Engineering, Crete, Greece, 24–26 June 2019. [Google Scholar]
- Dritsos, S.; Moseley, V. A Fuzzy Logic Rapid Visual Screening Procedure to Identify Buildings at Seismic Risk; Beton-Und Stahlbetonbau: Ernst & Sohn Verlag für Architektur und Technische Wissenschaften GmbH & Co. KG: Berlin, Germany, 2013; pp. 136–143. Available online: https://www.researchgate.net/publication/295594396_A_fuzzy_logic_rapid_visual_screening_procedure_to_identify_buildings_at_seismic_risk (accessed on 30 June 2020).
- Sun, H.; Burton, H.V.; Huang, H. Machine learning applications for building structural design and performance assessment: State-of-the-art review. J. Build. Eng. 2020, 33, 101816. [Google Scholar] [CrossRef]
- Harirchian, E.; Lahmer, T.; Kumari, V.; Jadhav, K. Application of Support Vector Machine Modeling for the Rapid Seismic Hazard Safety Evaluation of Existing Buildings. Energies 2020, 13, 3340. [Google Scholar] [CrossRef]
- Zhang, Z.; Hsu, T.Y.; Wei, H.H.; Chen, J.H. Development of a Data-Mining Technique for Regional-Scale Evaluation of Building Seismic Vulnerability. Appl. Sci. 2019, 9, 1502. [Google Scholar] [CrossRef]
- Christine, C.A.; Chandima, H.; Santiago, P.; Lucas, L.; Chungwook, S.; Aishwarya, P.; Andres, B. A cyberplatform for sharing scientific research data at DataCenterHub. Comput. Sci. Eng. 2018, 20, 49. [Google Scholar]
- Sim, C.; Laughery, L.; Chiou, T.C.; Weng, P.W. 2017 Pohang Earthquake—Reinforced Concrete Building Damage Survey DEEDS; Purdue University Research Repository: Lafayette, IN, USA, 2018; Available online: https://datacenterhub.org/resources/14728 (accessed on 2 June 2020).
- Sim, C.; Villalobos, E.; Smith, J.P.; Rojas, P.; Pujol, S.; Puranam, A.Y.; Laughery, L.A. Performance of Low-Rise Reinforced Concrete Buildings in the 2016 Ecuador Earthquake, Purdue University Research Repository, United States. 2017. Available online: https://purr.purdue.edu/publications/2727/1 (accessed on 10 June 2020).
- NEES: The Haiti Earthquake Database; DEEDS, Purdue University Research Repository: Lafayette, IN, USA, 2017; Available online: https://datacenterhub.org/resources/263 (accessed on 2 June 2020).
- Shah, P.; Pujol, S.; Puranam, A.; Laughery, L. Database on Performance of Low-Rise Reinforced Concrete Buildings in the 2015 Nepal Earthquake; DEEDS, Purdue University Research Repository: Lafayette, IN, USA, 2015; Available online: https://datacenterhub.org/resources/238 (accessed on 10 June 2020).
- Toulkeridis, T.; Chunga, K.; Rentería, W.; Rodriguez, F.; Mato, F.; Nikolaou, S.; D’Howitt, M.C.; Besenzon, D.; Ruiz, H.; Parra, H.; et al. THE 7.8 M w EARTHQUAKE AND TSUNAMI OF 16 th April 2016 IN ECUADOR: Seismic Evaluation, Geological Field Survey and Economic Implications. Sci. Tsunami Hazards 2017, 36, 78–123. [Google Scholar]
- Vera-Grunauer, X. Geer-Atc Mw7.8 Ecuador 4/16/16 Earthquake Reconnaissance Part II: Selected Geotechnical Observations. In Proceedings of the 16th World Conference on Earthquake Engineering (WCEE), Santiago, Chile, 9–13 January 2017. [Google Scholar]
- O’Brien, P.; O’Brien, P.; Eberhard, M.; Haraldsson, O.; Irfanoglu, A.; Lattanzi, D.; Lauer, S.; Pujol, S. Measures of the Seismic Vulnerability of Reinforced Concrete Buildings in Haiti. Earthq. Spectra 2011, 27, S373–S386. [Google Scholar] [CrossRef]
- De León, R.O. Flexible soils amplified the damage in the 2010 Haiti earthquake. Earthq. Resist. Eng. Struct. IX 2013, 132, 433–444. [Google Scholar]
- U.S. Geological Survey (USGS) 2010; U.S. Geological Survey: Reston, VA, USA, 2010.
- Collins, B.D.; Jibson, R.W. Assessment of Existing and Potential Landslide Hazards Resulting from the April 25, 2015 Gorkha, Nepal Earthquake Sequence; Ver. 1.1, August 2015; U.S. Geological Survey Open-File Report 2015–1142; U.S. Geological Survey: Reston, VA, USA, 2015; 50p. [Google Scholar] [CrossRef]
- Tallett-Williams, S.; Gosh, B.; Wilkinson, S.; Fenton, C.; Burton, P.; Whitworth, M.; Datla, S.; Franco, G.; Trieu, A.; Dejong, M.; et al. Site amplification in the Kathmandu Valley during the 2015 M7. 6 Gorkha, Nepal earthquake. Bull. Earthq. Eng. 2016, 14, 3301–3315. [Google Scholar] [CrossRef]
- Işık, E.; Büyüksaraç, A.; Ekinci, Y.L.; Aydın, M.C.; Harirchian, E. The Effect of Site-Specific Design Spectrum on Earthquake-Building Parameters: A Case Study from the Marmara Region (NW Turkey). Appl. Sci. 2020, 10, 7247. [Google Scholar] [CrossRef]
- Grigoli, F.; Cesca, S.; Rinaldi, A.P.; Manconi, A.; Lopez-Comino, J.A.; Clinton, J.; Westaway, R.; Cauzzi, C.; Dahm, T.; Wiemer, S. The November 2017 Mw 5.5 Pohang earthquake: A possible case of induced seismicity in South Korea. Science 2018, 360, 1003–1006. [Google Scholar] [CrossRef] [PubMed]
- Kim, H.S.; Sun, C.G.; Cho, H.I. Geospatial assessment of the post-earthquake hazard of the 2017 Pohang earthquake considering seismic site effects. ISPRS Int. J. Geo-Inf. 2018, 7, 375. [Google Scholar] [CrossRef]
- Ademović, N.; Šipoš, T.K.; Hadzima-Nyarko, M. Rapid assessment of earthquake risk for Bosnia and Herzegovina. Bull. Earthq. Eng. 2020, 18, 1835–1863. [Google Scholar] [CrossRef]
- USGS. Earthquake Hazards Program, ShakeMap. Available online: https://earthquake.usgs.gov/data/shakemap (accessed on 2 May 2021).
- USGS. Earthquake Hazards Program, ShakeMap of Ecuador Earthquake 2016. Available online: https://earthquake.usgs.gov/earthquakes/eventpage/us20005j32/shakemap/intensity (accessed on 10 May 2021).
- USGS. Earthquake Hazards Program, ShakeMap of Haiti Earthquake 2010. Available online: https://earthquake.usgs.gov/earthquakes/eventpage/usp000h60h/shakemap/intensity (accessed on 16 May 2021).
- USGS. Earthquake Hazards Program, ShakeMap of Nepal Earthquake 2015. Available online: ttps://earthquake.usgs.gov/earthquakes/eventpage/us20002ejl/shakemap/intensity (accessed on 12 June 2021).
- USGS. Earthquake Hazards Program, ShakeMap of Pohang Earthquake 2017. Available online: https://earthquake.usgs.gov/earthquakes/eventpage/us2000bnrs/shakemap/intensity (accessed on 13 June 2021).
- Stone, H. Exposure and Vulnerability for Seismic Risk Evaluations. Ph.D. Thesis, UCL (University College London), London, UK, 2018. [Google Scholar]
- Harirchian, E.; Lahmer, T. Earthquake Hazard Safety Assessment of Buildings via Smartphone App: A Comparative Study. IOP Conf. Ser. Mater. Sci. Eng. 2019, 652, 012069. [Google Scholar] [CrossRef]
- Harirchian, E.; Jadhav, K.; Kumari, V.; Lahmer, T. ML-EHSAPP: A prototype for machine learning-based earthquake hazard safety assessment of structures by using a smartphone app. Eur. J. Environ. Civ. Eng. 2021, 25, 1–21. [Google Scholar] [CrossRef]
- Yakut, A.; Aydogan, V.; Ozcebe, G.; Yucemen, M. Preliminary Seismic Vulnerability Assessment of Existing Reinforced Concrete Buildings in Turkey. In Seismic Assessment and Rehabilitation of Existing Buildings; Springer: Dordrecht, The Netherlands, 2003; pp. 43–58. [Google Scholar]
- Hassan, A.F.; Sozen, M.A. Seismic vulnerability assessment of low-rise buildings in regions with infrequent earthquakes. ACI Struct. J. 1997, 94, 31–39. [Google Scholar]
- Caruana, R.; Niculescu-Mizil, A. An empirical comparison of supervised learning algorithms. In Proceedings of the 23rd International Conference on Machine Learning, Pittsburgh, PA, USA, 25–29 June 2006; pp. 161–168. [Google Scholar] [CrossRef]
- Géron, A. Hands-on Machine Learning with Scikit-Learn and TensorFlow: Concepts, Tools, and Techniques to Build Intelligent Systems O’Reilly Media; O’Reilly: Sebastopol, CA, USA, 2017. [Google Scholar]
- Vapnik, V.N.; Golowich, S.E. Support Vector Method for Function Estimation. U.S. Patent 6,269,323, 31 July 2001. [Google Scholar]
- Fix, E. Discriminatory Analysis. Nonparametric Discrimination: Consistency Properties. Int. Stat. Rev./Rev. Int. Stat. 1989, 57, 238–247. [Google Scholar] [CrossRef]
- Cover, T.; Hart, P. Nearest neighbor pattern classification. IEEE Trans. Inf. Theory 1967, 13, 21–27. [Google Scholar] [CrossRef]
- Breiman, L. Bagging predictors. Mach. Learn. 1996, 24, 123–140. [Google Scholar] [CrossRef]
- Geurts, P.; Ernst, D.; Wehenkel, L. Extremely randomized trees. Mach. Learn. 2006, 63, 3–42. [Google Scholar] [CrossRef]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Ho, T. Random decision forests. In Proceedings of the Third International Conference on Document Analysis and Recognition, ICDAR 1995, Montreal, QC, Canada, 14–16 August 1995; Volume 1, pp. 278–282. [Google Scholar]
- Ho, T.K. The random subspace method for constructing decision forests. IEEE Trans. Pattern Anal. Mach. Intell. 1998, 20, 832–844. [Google Scholar]
- Amit, Y.; Geman, D. Shape quantization and recognition with randomized trees. Neural Comput. 1997, 9, 1545–1588. [Google Scholar] [CrossRef]
- Fawagreh, K.; Gaber, M.M.; Elyan, E. Random forests: From early developments to recent advancements. Syst. Sci. Control Eng. Open Access J. 2014, 2, 602–609. [Google Scholar] [CrossRef]
- Webb, G.I. Multiboosting: A technique for combining boosting and wagging. Mach. Learn. 2000, 40, 159–196. [Google Scholar] [CrossRef]
- Breiman, L. Randomizing outputs to increase prediction accuracy. Mach. Learn. 2000, 40, 229–242. [Google Scholar] [CrossRef]
- Liaw, A.; Wiener, M. Classification and regression by randomForest. R News 2002, 2, 18–22. [Google Scholar]
- Chawla, N.V.; Bowyer, K.W.; Hall, L.O.; Kegelmeyer, W.P. SMOTE: Synthetic minority over-sampling technique. J. Artif. Intell. Res. 2002, 16, 321–357. [Google Scholar] [CrossRef]
- May, R.J.; Maier, H.R.; Dandy, G.C. Data splitting for artificial neural networks using SOM-based stratified sampling. Neural Netw. 2010, 23, 283–294. [Google Scholar] [CrossRef] [PubMed]
- Lewis, H.; Brown, M. A generalized confusion matrix for assessing area estimates from remotely sensed data. Int. J. Remote Sens. 2001, 22, 3223–3235. [Google Scholar] [CrossRef]
- Sun, Y.; Gong, H.; Li, Y.; Zhang, D. Hyperparameter Importance Analysis based on N-RReliefF Algorithm. Int. J. Comput. Commun. Control 2019, 14, 557–573. [Google Scholar] [CrossRef]




























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Variable | Parameter | Unit | Type |
|---|---|---|---|
| No. of story | N (1, 2, …) | Quantitative | |
| Total Floor Area | m | Quantitative | |
| Column Area | m | Quantitative | |
| Concrete Wall Area (Y) | m | Quantitative | |
| Concrete Wall Area (X) | m | Quantitative | |
| Masonry Wall Area (Y) | m | Quantitative | |
| Masonry Wall Area (X) | m | Quantitative | |
| Captive Columns | N (exist = yes = 1, absent = no = 0) | Dummy |
| Earthquake | No. of Buildings |
|---|---|
| Ecuador | 172 |
| Haiti | 145 |
| Nepal | 135 |
| Pohang | 74 |
| Damage Scale | Associated Risk |
|---|---|
| 1 | Light: Hairline inclined and flexural cracks were observed in structural elements. |
| 2 | Moderate: Wider cracks or spalling of concrete was observed. |
| 3 | Severe: At least one element had a structural failure. |
| 4 | Collapse: At least one floor slab or part of it lost its elevation. |
| Feature | Mean Accuracy (%) |
|---|---|
| No. of floor | 64 |
| Total floor area | 65 |
| Column area | 65 |
| Concrete wall area (NS) | 66 |
| Concrete wall area (EW) | 67 |
| Masonry wall area (NS) | 66 |
| Masonry wall area (EW) | 65 |
| Captive Columns | 66 |
| No. of Sample per Split | Mean Accuracy (%) |
|---|---|
| 2 | 64 |
| 3 | 65 |
| 4 | 65 |
| 5 | 65 |
| 6 | 65 |
| 7 | 65 |
| 8 | 64 |
| 9 | 63 |
| 10 | 62 |
| Feature (No. of Tree) | Mean Accuracy (%) |
|---|---|
| 10 | 63 |
| 20 | 64 |
| 30 | 65 |
| 40 | 68 |
| Feature | Mean Accuracy (%) |
|---|---|
| No. of floor | 61 |
| Total floor area | 60 |
| Column area | 62 |
| Concrete wall area (NS) | 64 |
| Concrete wall area (EW) | 63 |
| Masonry wall area (NS) | 63 |
| Masonry wall area (EW) | 63 |
| Captive Columns | 66 |
| No. of Sample per Split | Mean Accuracy (%) |
|---|---|
| 2 | 64 |
| 3 | 65 |
| 4 | 64 |
| 5 | 66 |
| 6 | 62 |
| 7 | 63 |
| 8 | 62 |
| 9 | 61 |
| 10 | 62 |
| Feature (No. of Tree) | Mean Accuracy (%) |
|---|---|
| 10 | 60 |
| 20 | 65 |
| 30 | 66 |
| 40 | 63 |
| Feature | Mean Accuracy (%) |
|---|---|
| No. of floor | 68 |
| Total floor area | 70 |
| Column area | 69 |
| Concrete wall area (NS) | 68 |
| Concrete wall area (EW) | 68 |
| Masonry wall area (NS) | 69 |
| Masonry wall area (EW) | 68 |
| Captive Columns | 70 |
| No. of Sample per Split | Mean Accuracy (%) |
|---|---|
| 2 | 65 |
| 3 | 64 |
| 4 | 67 |
| 5 | 65 |
| 6 | 65 |
| 7 | 64 |
| 8 | 64 |
| 9 | 63 |
| 10 | 63 |
| Feature (No. of Trees) | Mean Accuracy (%) |
|---|---|
| 10 | 66 |
| 20 | 67 |
| 30 | 68 |
| 40 | 71 |
| Feature | Mean Accuracy (%) |
|---|---|
| No. of floor | 72 |
| Total floor area | 70 |
| Column area | 71 |
| Concrete wall area (NS) | 70 |
| Concrete wall area (EW) | 72 |
| Masonry wall area (NS) | 71 |
| Masonry wall area (EW) | 71 |
| Captive Columns | 71 |
| No. of Sample per Split | Mean Accuracy (%) |
|---|---|
| 2 | 62 |
| 3 | 61 |
| 4 | 60 |
| 5 | 60 |
| 6 | 60 |
| 7 | 61 |
| 8 | 60 |
| 9 | 61 |
| 10 | 53 |
| No. of Tree | Mean Accuracy (%) |
|---|---|
| 10 | 61 |
| 20 | 63 |
| 30 | 65 |
| 40 | 64 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Harirchian, E.; Kumari, V.; Jadhav, K.; Rasulzade, S.; Lahmer, T.; Raj Das, R. A Synthesized Study Based on Machine Learning Approaches for Rapid Classifying Earthquake Damage Grades to RC Buildings. Appl. Sci. 2021, 11, 7540. https://doi.org/10.3390/app11167540
Harirchian E, Kumari V, Jadhav K, Rasulzade S, Lahmer T, Raj Das R. A Synthesized Study Based on Machine Learning Approaches for Rapid Classifying Earthquake Damage Grades to RC Buildings. Applied Sciences. 2021; 11(16):7540. https://doi.org/10.3390/app11167540
Chicago/Turabian StyleHarirchian, Ehsan, Vandana Kumari, Kirti Jadhav, Shahla Rasulzade, Tom Lahmer, and Rohan Raj Das. 2021. "A Synthesized Study Based on Machine Learning Approaches for Rapid Classifying Earthquake Damage Grades to RC Buildings" Applied Sciences 11, no. 16: 7540. https://doi.org/10.3390/app11167540
APA StyleHarirchian, E., Kumari, V., Jadhav, K., Rasulzade, S., Lahmer, T., & Raj Das, R. (2021). A Synthesized Study Based on Machine Learning Approaches for Rapid Classifying Earthquake Damage Grades to RC Buildings. Applied Sciences, 11(16), 7540. https://doi.org/10.3390/app11167540