1. Introduction
Agriculture is the foundation of social stability and national development in many countries, especially in developing countries. Adequate supply of grain and other basic agricultural products is an irreplaceable foundation for ensuring sufficient stability of market prices. Meanwhile, food security is a crucial support for national economic security. Therefore, it is a particularly urgent and meaningful task to strengthen the macro-control of the food market and ensure food security and market stability at present.
Rice plays an essential role in agricultural production as the most significant food crop [
1]. With the rapid increase in the population, the country’s demand for food is also growing. We have problems with declining soil quality and eutrophication [
2]. Since rice plays a key role in food security, it is necessary to study the growth status of rice. Industrialization reduces the arable land area, so it is required to increase the yield of rice in order to increase the total yield of rice. Therefore, rice growth and cultivation of high-yield varieties has become a major research issue in agricultural research institutions [
3]. The study of rice growth is very critical to political, economic and social stability.
Due to the development of computer information technology, image-processing technology is becoming more and more advanced. In order to detect and extract data from the overall growth state of rice, phenotypic feature data extraction from rice image has been widely used. Compared with artificial experiments, this method can reduce subjective errors and improve the accuracy of data. The main content of image processing is to cut the areas in the original image that need to be studied, and then extract the features of specific areas according to color components and texture features [
4].
Fractal geometry has a self-similar character. When the geometries with fractal characteristics are magnified at different multiples, the observed properties are similar and have a fractal dimension in space [
5,
6]. The concept of fractals was first put forward by B. B. Madelbrot in 1973. He defined a fractal as a set, which expresses the symmetry or self-similarity of the whole and the part in a certain sense. There are many fractal phenomena in nature, such as coastlines, lightning, human lungs, material surfaces, etc., which can be approximately regarded as fractal sets [
7].
However, the typical fractal sets are specially constructed by mathematicians, so they have a standard and strict self-similarity. However, in nature, most of the objects we study do not have strict self-similarity characteristics, but only meet statistical self-similarity. Therefore, in research, we mainly carry out approximate processing on the objects to explore the quasi-self-similarity [
8].
The dimension of fractal geometry is usually not an integer dimension, so the integer dimension used in the traditional Euclidean space cannot describe the fractal shape. Mandelbrot proposed the concept of a non-integer dimension or fractal dimension [
9]. The fractal dimension describes a complex ratio that reflects how the details of the pattern change with the scale of the measurement [
10]. It is used in all areas of science because it provides a measure of the complexity and irregularity of a given object [
11]. Complexity is a change in detail and scale. As the fractal dimension increases, the complexity of the object also increases.
As a long-neglected part of geometry, fractals can help us to study nature from a new perspective and find order in apparent disorder [
12]. Since the 1970s, the application of fractal theory has developed rapidly and gradually become an important new subject. Fractals have been widely used in natural and social sciences such as biology, chemistry, physics, material science, computer graphics, seismology, economics and so on. It is now one of the frontier research disciplines of many disciplines all over the world [
13]. It provides a new method for researchers to solve traditional nonlinear problems more accurately.
The fractal dimension has been widely used in various fields. Pinavega Rogelio et al. [
14] proposed an automatic prediction method for sudden cardiac death (SCD) based on a fractal dimension algorithm and a fuzzy logic system. In the paper, five kinds of fractal dimensions were used for experimental research. The results show that the method of basic fractal dimension could predict SCD events, and the prediction time was up to 60 min before the onset, with an accuracy of 91.54%. Cheng Liu et al. [
15] proposes an improved DBC (IMDBC) to estimate the fractal dimension of three-dimensional (3D) pavement texture images based on a grid displacement mechanism. Combined with the contact characteristics of the road surface and the tire, the most suitable road surface with fractal texture was determined by the fractal stratification method. Compared with traditional DBC, the fitting accuracy of IMDBC is improved by 18.8% (full texture) and 900% (partial texture), respectively. Lucas Glaucio da Silva et al. [
16] analyzed all the images using the FracLAC algorithm in the ImageJ computing environment to obtain the box fractal dimension results. They found that computer-aided diagnostic algorithms can benefit from box fractal dimension data; the cutoff value of the fractal dimension of the specific box produced 0~99% specificity in the diagnosis of breast cancer. Eloy Roura et al. [
17] aimed to evaluate longitudinal changes in brain fractal geometry and its predictive value for disease progression in patients with multiple sclerosis (MS). The box number method was used to calculate the dimensionality of brain differentiation and the space between brain regions. Fractal geometric analysis of brain MRI found that patients had an increased risk of disability over the next 5 years. Shanshan Jin et al. [
18] used pore size distribution curves and pore volume histograms to qualitatively analyze the pore structure before and after freeze-thaw. A fractal model was used to characterize pore distribution. A micro freeze-thaw damage model with fractal dimension as an independent variable was established, and the relationship between the damage parameters calculated by the model and durability factors was analyzed. Parikshaa Gupta et al. [
19] aimed to evaluate the value of fractal dimensions in differentiating benign and malignant HCGS endometrium in liquid cervical specimens. They suggest that fractal dimension analysis is an effective tool to distinguish between different types of cell groups. It is concluded that the fractal dimension detection of cervical cell carcinoma has high sensitivity and can be used as an effective screening method for differentiating benign and malignant cervical cell carcinoma. When the object is relatively complex, it can be studied from the perspective of fractals. The fractal dimension can reflect the complexity of the object, which may improve the analysis effect.
The traditional method of yield estimation is field sampling survey. Observers estimate the yield of a large area according to the growth condition of samples through observation sampling evaluation. This estimation method cannot be standardized and requires a large amount of manpower and material resources. At present, rice yield prediction is mainly divided into meteorological model prediction, remote sensing model prediction and image feature model prediction.
Forecasting based on a meteorological model is mainly to analyze the correlation between meteorological factors and yield. The key meteorological factors are selected to establish a model for yield prediction [
20]. In order to explore the influence of meteorological factors on rice yield, Li Hongyan et al. [
21] used meteorological data and rice yield data of Tongxiang city over 13 years. They used an exponential smoothing method to calculate the trend yield of rice, and conducted correlation analysis with the monthly average temperature, maximum temperature, minimum temperature, sunshine hours and precipitation in the rice growth period. The key factors affecting the yield of rice were determined, and the regression equation was established and tested. The average accuracy of the prediction model was up to 96.2%. Zuo Huiting et al. [
22] studied climate change in different climatic zones, different climatic conditions and recent years. Combined with the variation trend of rice yield in different climatic zones, they analyzed the correlation between rice yield and climatic factors, and selected the main controlling factors of rice yield in each climatic zone. The regression model was established to forecast the production of different climate zones in the next five years, and the results are relatively stable. Meteorological models need a lot of meteorological data and yield data, and need to maintain the consistency of growth conditions. Therefore, the established models have poor generality and are difficult to be popularized.
The prediction based on remote sensing and spectral model prediction is mainly to obtain the plant spectral index through a multi-spectral camera, select key factors and establish a prediction model based on yield data [
23]. Wang Di [
24] extracted vegetation index, end element abundance, texture features and other information by using ground hyperspectral data and multi-spectral data of the UAV platform. Rice yield estimation was studied by stepwise linear regression, BP neural network and random forest algorithm. Liu Shanshan et al. [
25] obtained the normalized vegetation index (NDVI) of remote sensing data according to time series and evaluated it with Pearson product moment correlation coefficient (Pearson) of average rice yield in the field by comparing the mean value of NDVI combination in different time periods. NDVI data were used to establish several prediction models with rice yield, and the best model was selected. Remote sensing yield estimation is generally applicable to large-area yield estimation, but when the planting area is not large enough, the accuracy is often reduced, and it is difficult to obtain remote sensing data.
The prediction is made based on the image feature model, mainly through segmentation of RGB images, extraction of features and establishment of regression model [
26]. Gong Hongju and Ji Changying [
27] made a preliminary study on the relationship between texture features of wheat spike head image and yield by using MATLAB image-processing technology. The mathematical model of spike head image texture and yield was established by using multiple linear regression method, and 84.42% of the samples with an accuracy of more than 15% were measured by using the established model. Li Yinian et al. [
28] performed the segmentation of wheat ears through color space conversion and image-processing technology to identify the number of ears. By predicting the number of grains by panicle area and combining this with 1000-grain weight, they built a model to predict the wheat yield per unit area with an average accuracy of more than 90%. The image feature model can not only make predictions with damage, but also make predictions without damage, and the effect is better when the planting area is small.
Fractal dimension is an important image feature, but it is seldom used in rice yield estimation. The purpose of this study is to combine the characteristics of rice in the early growth stage with the fractal dimension; practical and low-cost models are established. These models can be used to predict the fresh weight, dry weight and plant height of rice, which need to be measured by machine and are highly correlated with yield. The model can not only provide a reference for countries to formulate food security strategies, but also help to measure the yield of smart agriculture, so this study has a strong practical value.
3. Results and Analysis
3.1. Random Forest Regression Model
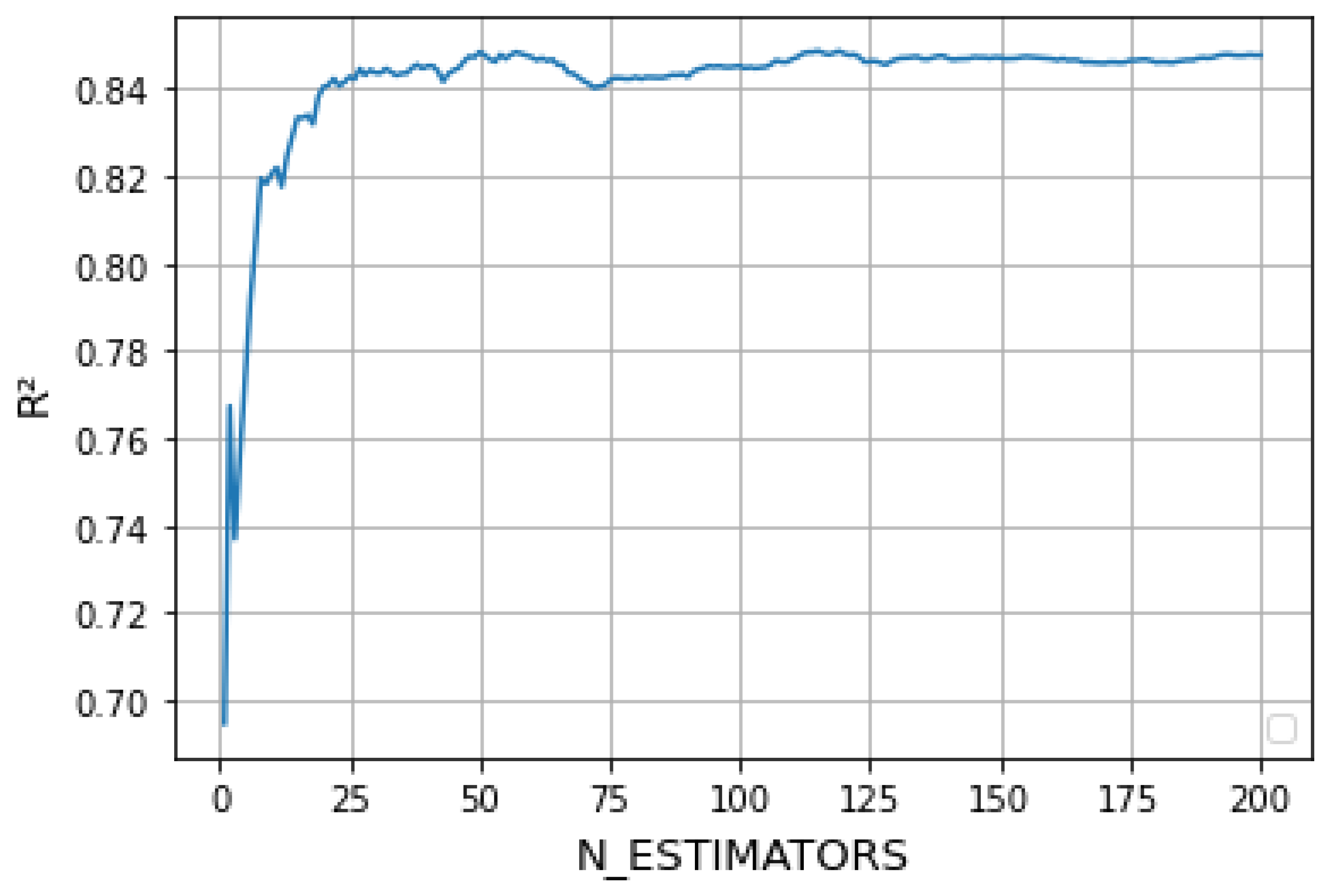
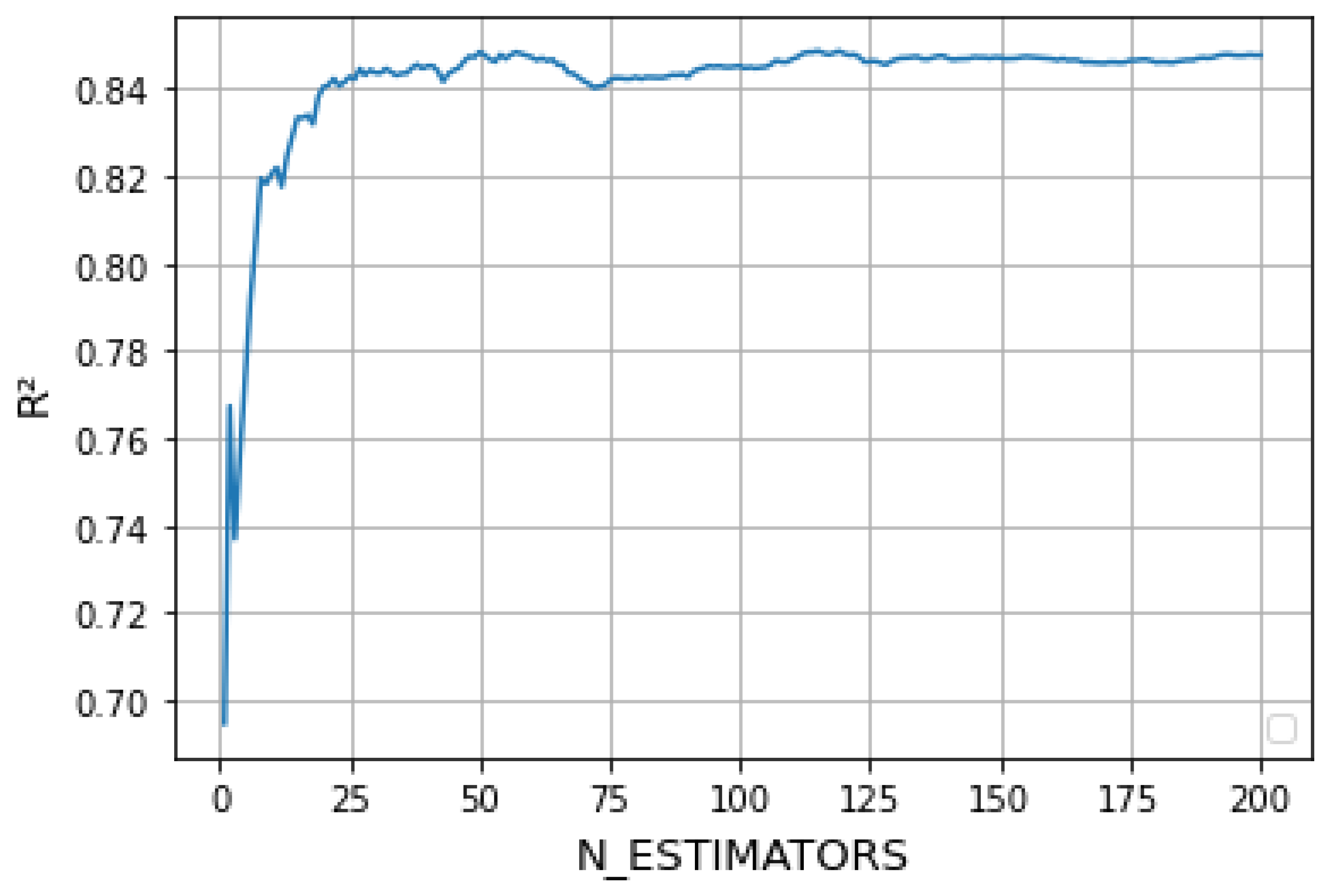
According to the second chapter of this paper, the random forest regression model has a relatively important unknown parameter; that is, the number of regression trees in the forest, N_ESTIMATORS. In order to obtain the best effect of the model, we need to choose the size of the N_ESTIMATORS.
The size of the tree N_ESTIMATORS is selected by drawing the learning curve. By observing the variation of the model’s
with the N_ESTIMATORS, the overall size of the random forest is selected. We can see from
Figure 7 that when the value of N_ESTIMATORS is greater than 50,
tends to be basically stable. The larger N_ESTIMATORS is, the more computation and memory will be needed, and the longer training time will be. When N_ESTIMATORS is equal to 50,
is in the front of the stable part and the calculation time is short. Therefore, the random forest model parameter in this paper is selected as 50.
Based on the data of the three growth stages of rice, the models of dry weight (g), fresh weight (g) and plant height (cm) of rice are established respectively with the characteristic variables selected above. The data is divided into training set and test set in a ratio of 4 to 1. In order to facilitate the comparison of model effects, we used the same test set and training set. The training set is used to build the model, and the test set is used to test the effect of the model.
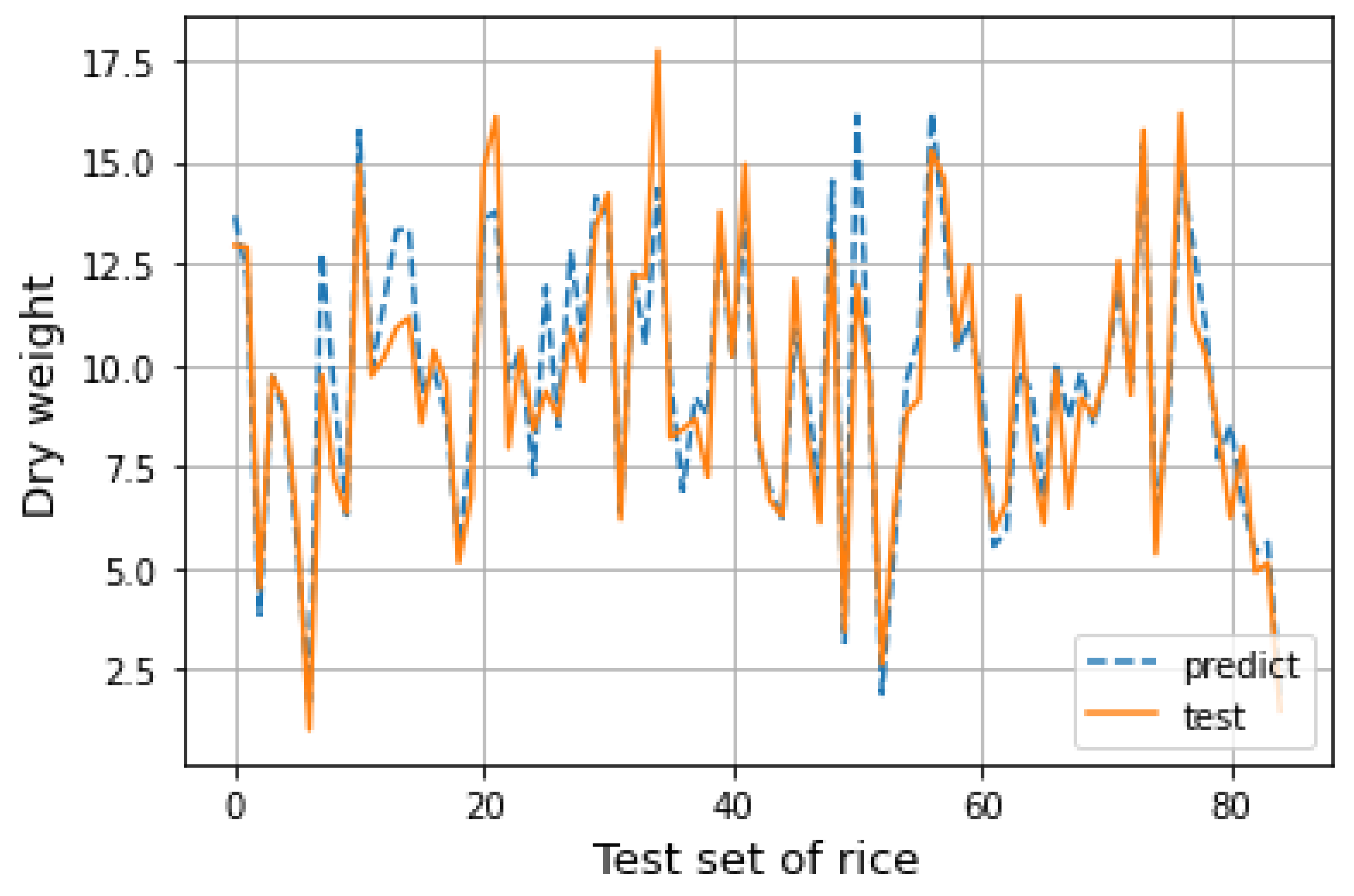
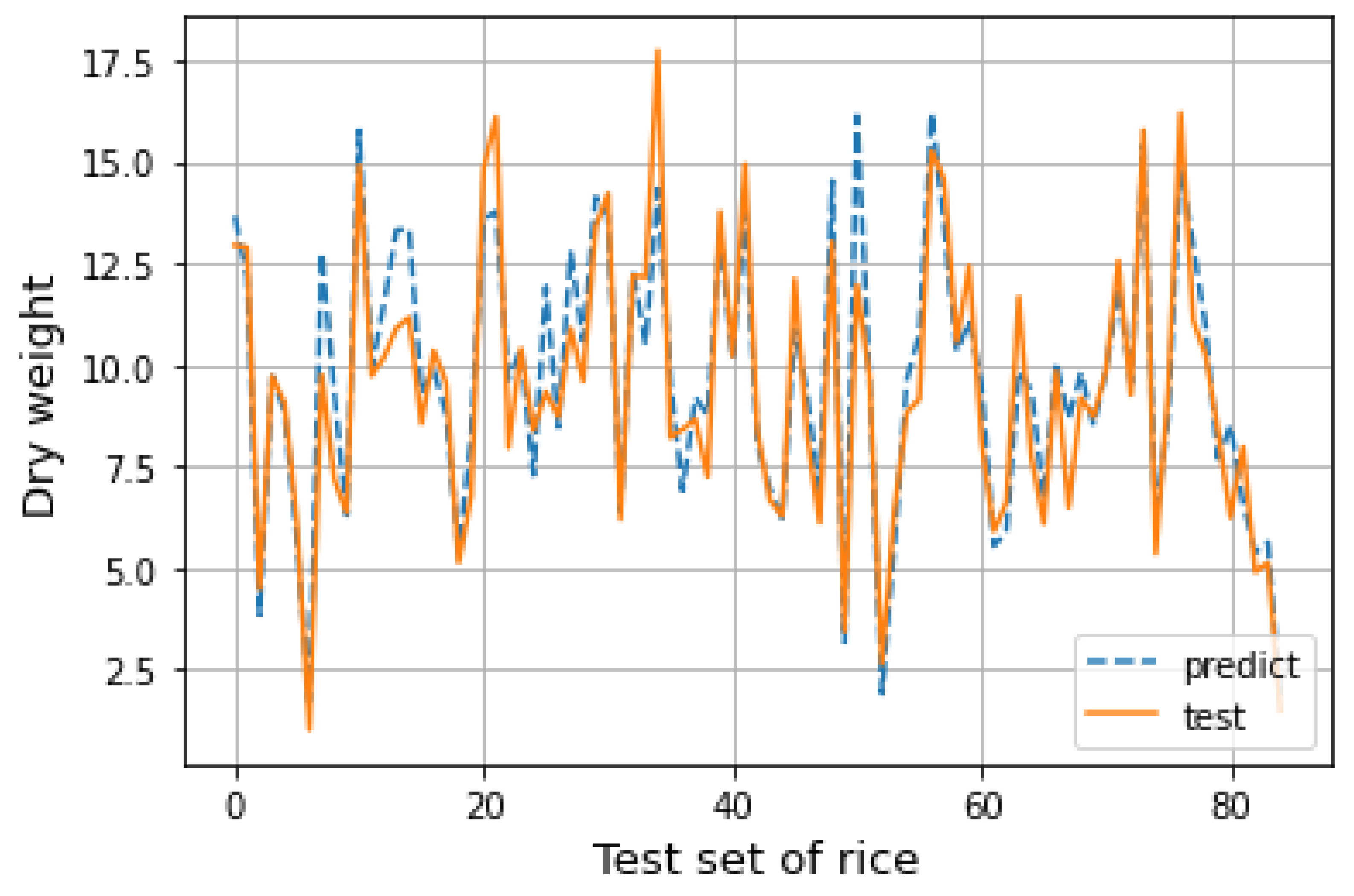
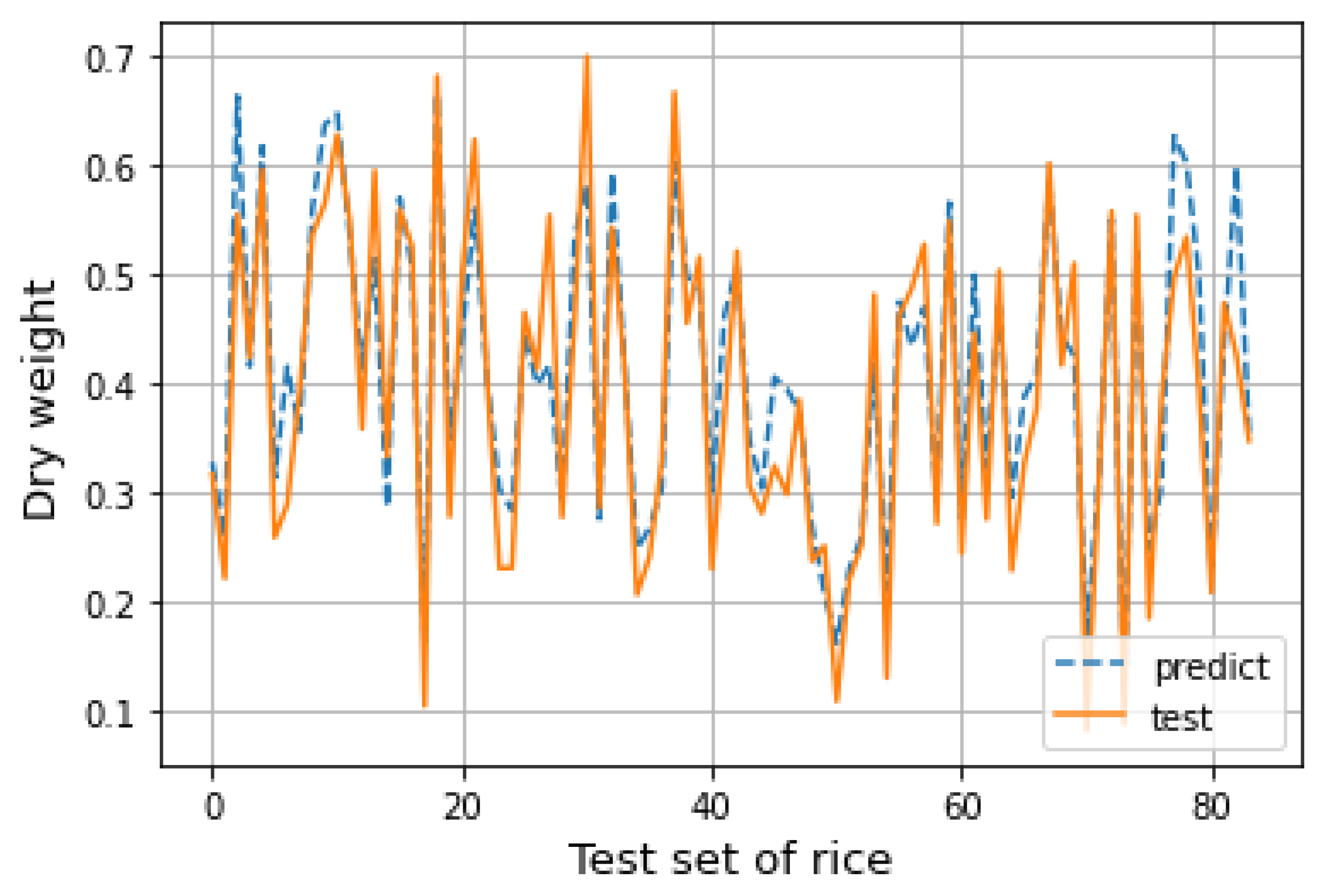
After completing the establishment of the random forest regression model, the test set data are substituted into the model to obtain the corresponding prediction results. The predicted results are drawn into a line chart for fitting with the actual situation in the test set, as shown in the figure below. It can be seen from
Figure 8 that the predicted results of the model are close to the actual situation, and the distribution of data is well fitted. The prediction ability of the model is relatively stable. Under certain conditions, the predicted value of the random forest model established in this section has certain guiding significance.
In order to verify the effectiveness of the fractal dimension in predicting rice dry weight, fresh weight and plant height, the model is established by removing the fractal dimension during modeling, and the established model is compared with the model with the added fractal dimension; their
and
are compared. If the fractal dimension is valid for modeling, the
of these models will be improved and the
will be decreased. The comparison results are shown in
Table 5,
Table 6 and
Table 7.
It can be seen that both the fractal dimension of the rice binary image and the fractal dimension of the rectangle surrounding the rice image have a promoting effect on the fitting effect of the model. For dry weight and fresh weight models of rice, the best effect can be obtained by adding the fractal dimension of the binary image and fractal dimension of the rectangle surrounding the rice image. Although plant height has a low correlation with the fractal dimension of the binary image, it is still closely related to the fractal dimension of the rectangle surrounding the rice image.
With the growth of rice, some characters of rice change greatly, so the characteristic data change to a certain extent. By calculating the correlation coefficient of each stage, it is proved that the characteristic variables of the model did not need to change with the growth stage, but the fitting effect of dry weight, fresh weight and plant height models would all change with the growth stage. The corresponding model
and
of the three stages are shown in
Table 8,
Table 9 and
Table 10.
By comparing
Table 8,
Table 9 and
Table 10, it can be seen that when random forest is used to build the prediction model, the prediction accuracy of the model will also change with the change of the growth stage. Both the dry weight prediction model and the fresh weight prediction model show a downward trend, but even in the third stage, the
and
of the model are still good. However, the plant height prediction model showed an opposite trend. With the growth of rice, the accuracy of the plant height prediction model will increase continuously. In conclusion, although the growth stage will have a certain influence on the effect of the random forest model, the influence is not significant and is within the acceptable range. Therefore, the random forest model has a good effect on the prediction of dry weight, fresh weight and plant height of rice.
3.2. SVR Model
In this section, the rice characteristics selected above are taken as explanatory variables. The dry weight, fresh weight and plant height are explained variables. The sklearn package of Python is used to establish prediction models of rice dry weight, fresh weight and plant height based on support vector regression. The grid search method of 10-fold cross-validation method is used to find the optimal combination of these two parameters, so that the model can achieve the optimal prediction effect. The optimization interval is determined as C belonging to 0 to 150 and Gamma to 0 to 10, respectively. A more detailed search is conducted with a step size of 1. According to the grid search results, when C equals 100 and gamma equals 4, the model achieves the highest .
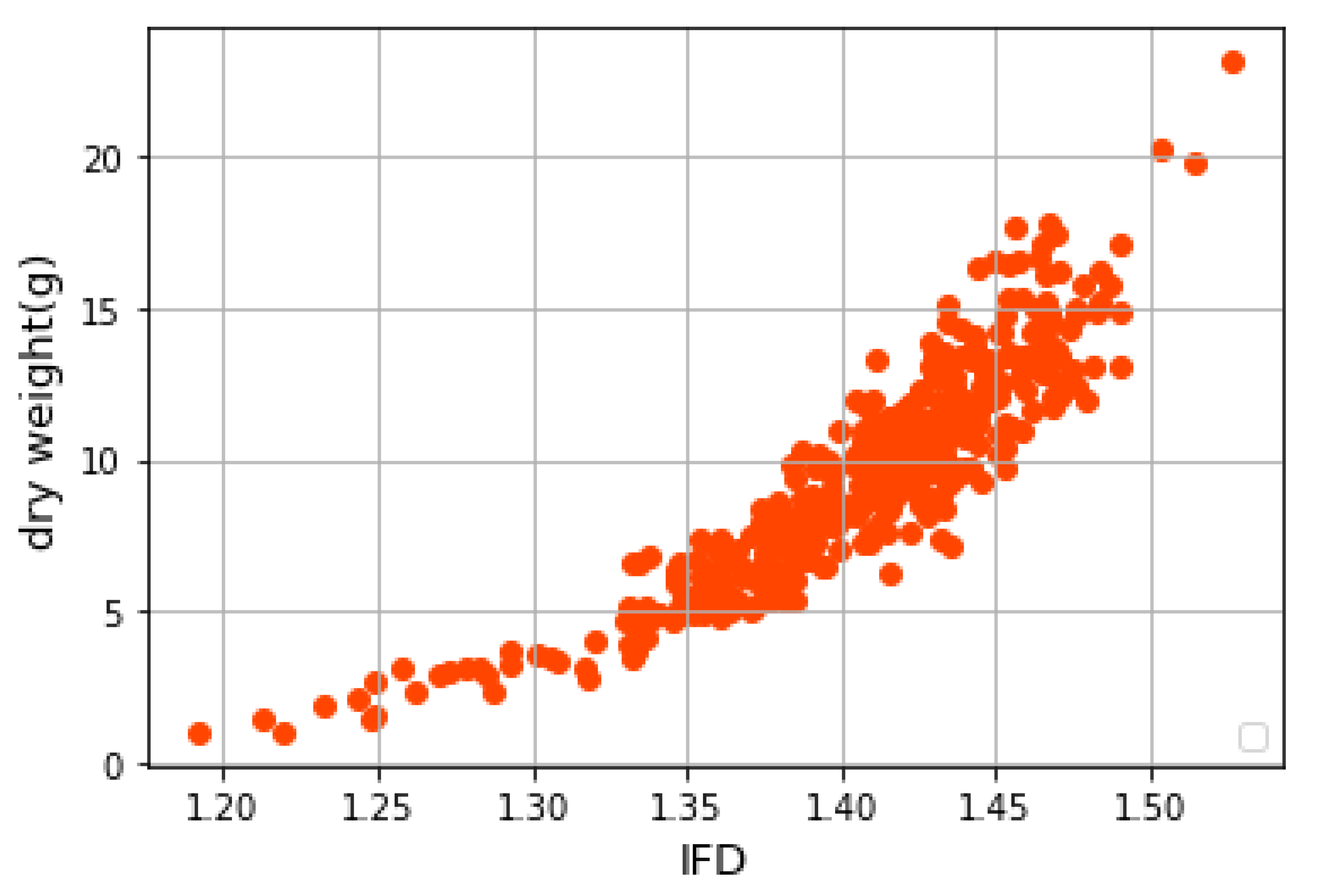
Based on the selected kernel function and the optimal parameter combination, the SVR function in the Python sklearn package is used to build the model. The ‘PW’, ‘SA’, ‘SA/pH (V) × PW’, ‘IFD’, ‘SFD’, ‘G_g’, ‘f1’ and ‘LD1’ of three growth stages are used as explanatory variables to establish a prediction model for fresh weight (g) and dry weight (g). ‘PW’, ‘PH(V)’, ‘PH’, ‘SFD’, ‘G_g’, ‘f1’, ‘f2’ and ‘LD2’ are used as explanatory variables to establish a prediction model of plant height (cm).
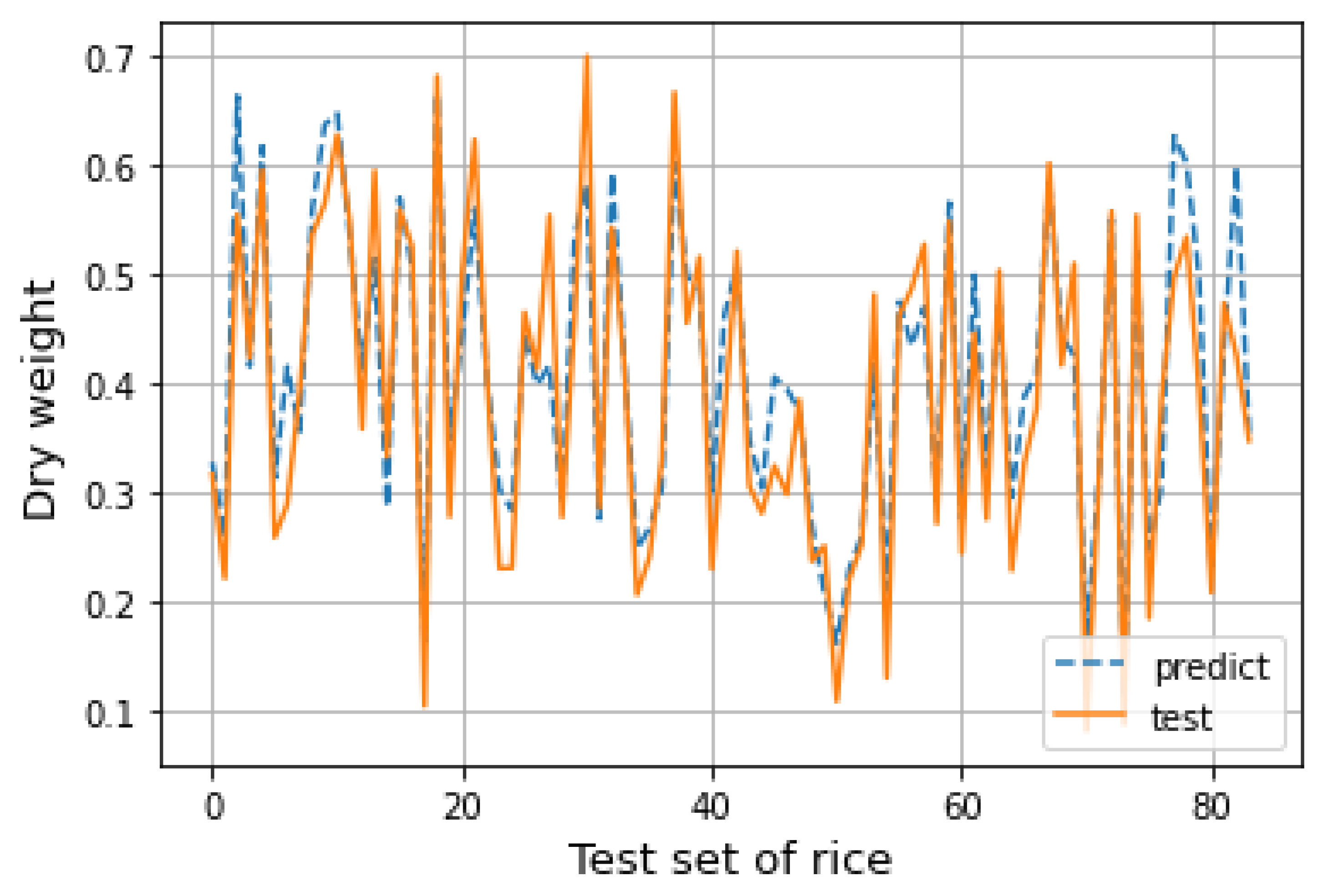
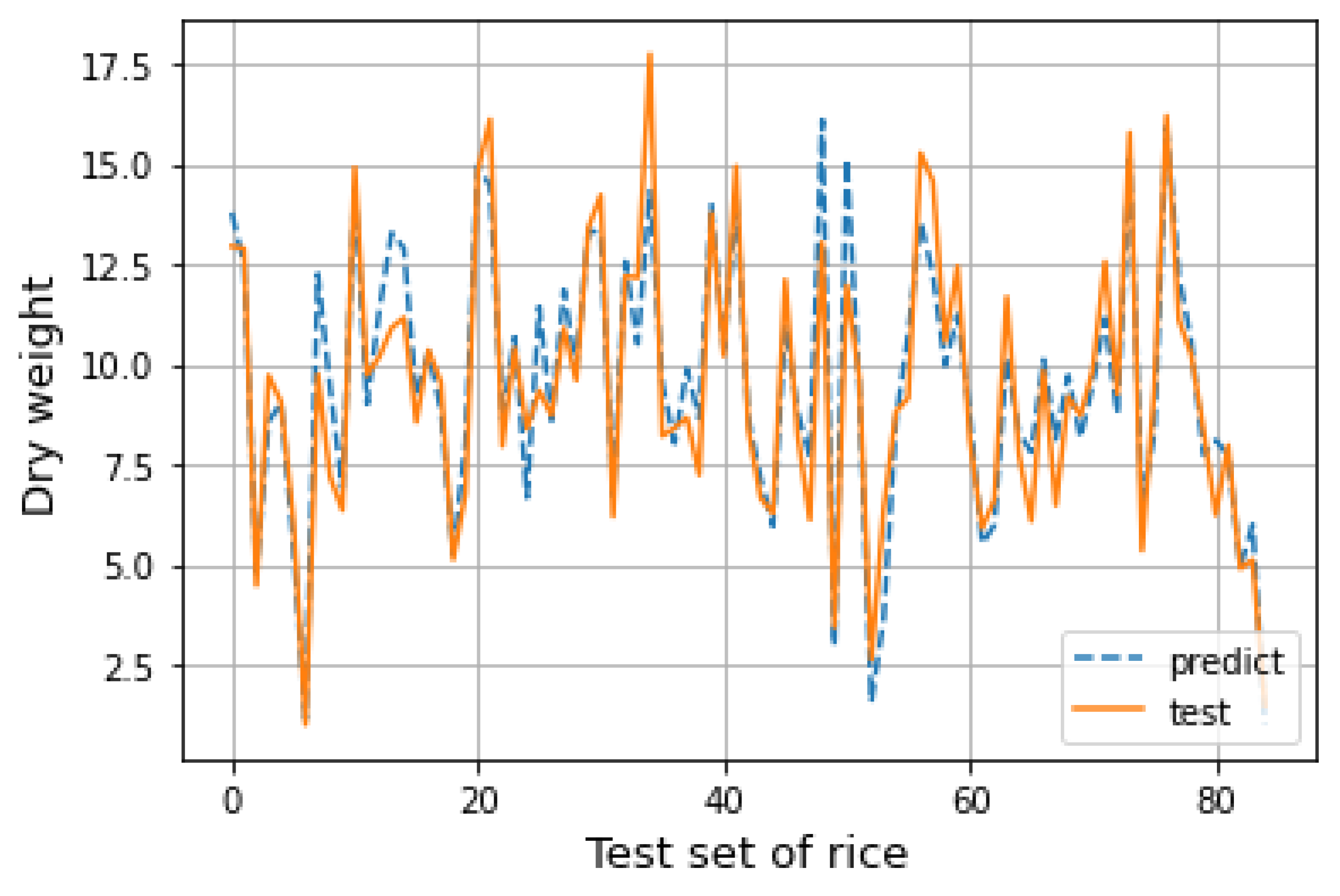
The data need to be normalized first, and then divided into a training set and test set in a ratio of 4 to 1. After the establishment of the SVR model, the corresponding prediction results can be obtained by substituting the data as the test set into the model. The predicted results are drawn into a line chart for fitting with the actual situation of the data in the test set, as shown in
Figure 9. It can be seen from the figure that the predicted results of the model are close to the actual situation, and the distribution of data is well fitted. The prediction ability of the model is relatively stable. Under certain conditions, the predicted value of the model established in this section has certain guiding significance.
According to the above, the growth stage of rice will have an impact on the prediction performance of the model. The
and
of the prediction model at different stages are compared, and the comparison results are shown in
Table 11,
Table 12 and
Table 13.
By comparing
Table 11,
Table 12 and
Table 13, it can be seen that with the growth of rice, the
of the support vector regression model will change greatly and
will hold steady. With the growth of rice, the prediction effect of fresh weight and plant height models will become better and better, and the increase in both models is greater than 0.05 at the third stage, which has a better prediction effect. However, with the growth of rice, the prediction effect of the dry weight model shows a downward trend; the
of the second stage is only 0.6639, and even in the third stage, the
of the model is less than 0.8. Although the
of the dry weight model meets the application standard of the model, the effect is too poor compared with the model obtained by other algorithms. Therefore, support vector regression is not recommended to be used when establishing the dry weight prediction model of rice. However, support vector regression can achieve better results when establishing the prediction model of rice fresh weight and plant height.
3.3. Linear Regression Model
This section uses Python to build a multivariate LinearRegression prediction model using the LinearRegression function in the Sklearn package. The ‘PW’, ‘SA’, ‘SA/PH (V) × PW’, ‘IFD’, ‘SFD’, ‘G_g’, ‘f1’ and ‘LD1’ of three growth stages are used as explanatory variables to establish a prediction model for fresh weight (g) and dry weight (g). Using ‘PW’, ‘PH(V)’, ‘PH’, ‘SFD’, ‘G_g’, ‘f1’, ‘f2’ and ‘LD2’ as explanatory variables, the plant height (cm) prediction model is established.
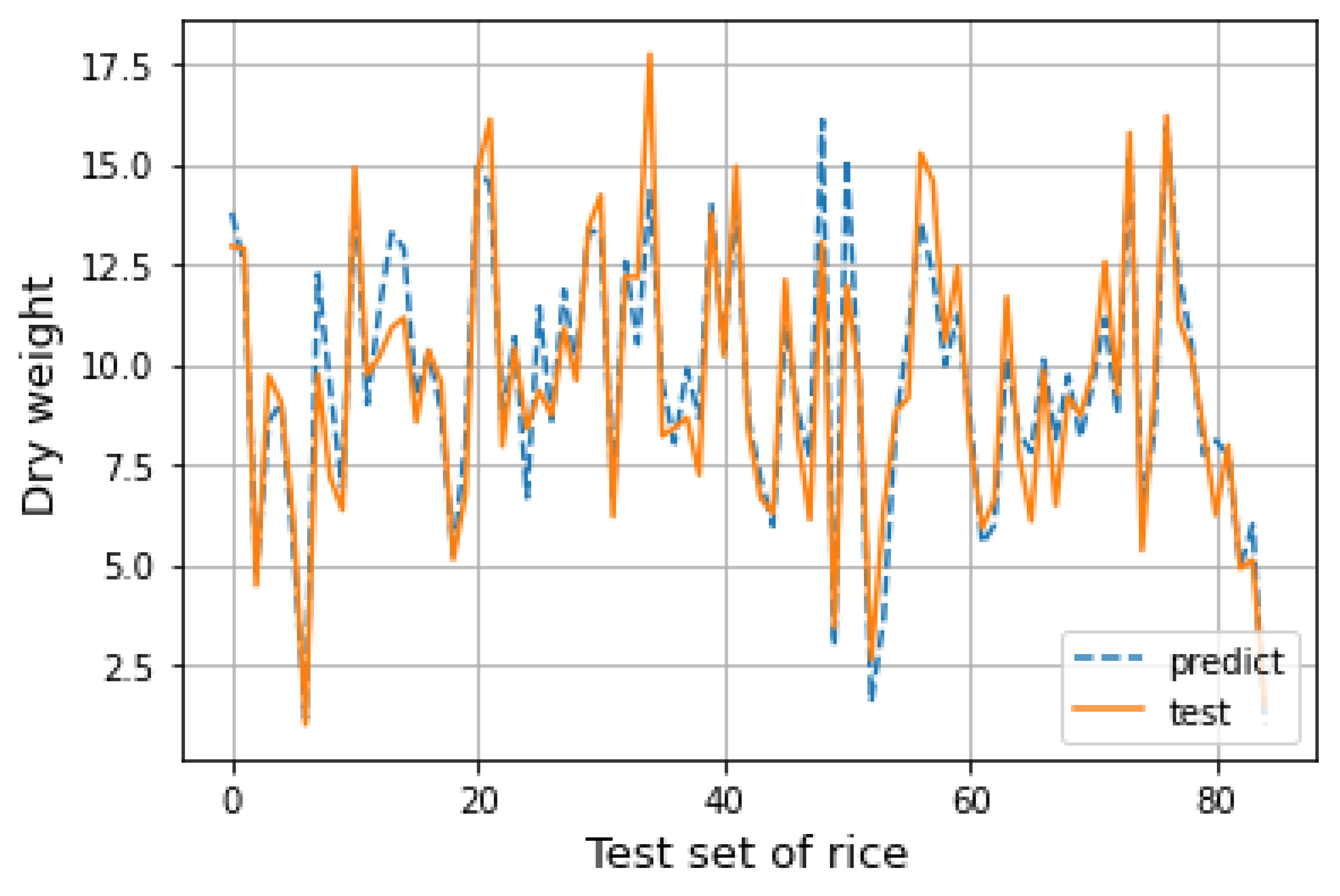
The data are divided into a training set and test set in a ratio of 4 to 1. After the establishment of a multiple linear regression model, the corresponding prediction results can be obtained by substituting the test set data into the model. The predicted results are drawn into a line chart for fitting with the actual situation in the test set, as shown in
Figure 10. It can be seen from the figure that the predicted results of the model are close to the actual situation, and the distribution of data is well fitted. The prediction ability of the model is relatively stable. Under certain conditions, the predicted value of the multiple linear regression model established in this section has certain guiding significance.
Since the growth stage of rice will affect the prediction performance of the model, the
and
of multiple linear regression prediction models at different stages are compared, and the comparison results are shown in
Table 14,
Table 15 and
Table 16.
By comparing
Table 14,
Table 15 and
Table 16, it can be seen that when using the multiple linear regression model to predict the dry weight and fresh weight, the prediction effect of the model will decrease slightly with the growth of rice, but the decline is small and the overall effect is relatively stable, and good results can be achieved. However, the
of the plant height prediction model fluctuates greatly, with the minimum value of 0.8067 in the second stage and the maximum value of 0.9196 in the third stage. The prediction effect of the third stage is the best among the models which are selected in the previous parts of this paper. By comparing the
MAPE of all the models, the
MAPE of linear regression models are much lower than those of random forest models and SVR models.
4. Discussion
In Yang Wanli’s research [
32], he used a SegNet convolutional neural network to segment rice images, and extracted texture features, morphological features and color features from the segmented images. He used the selected features to build a linear regression model to predict the fresh weight and dry weight of rice, and the
of the model was 0.812 and 0.772. The characteristic parameters used in this paper are almost the same as those in Yang’s paper, and the planting conditions of rice are also the same. However, fractal dimension is not paid attention to in Yang’s paper, which may be the reason why the effect of Yang’s model is inferior to that in this paper. Therefore, when establishing the prediction model of rice biomass, we can consider adding the fractal dimension into the model, which may improve the model effect. In Gong Hongju’s research [
33], she proposed the idea and method of establishing a mathematical model for accurate prediction of rice yield based on texture analysis and fractal theory. She obtained the texture features and fractal dimension by analyzing and calculating the binary image of rice, and then used principal component analysis to obtain the variables for establishing the model. She used linear regression to establish the yield prediction model, and the
only reached 0.494, and the model had a poor effect in the posterior error test. Gong Hongju’s use of the fractal dimension to establish the model is innovative, but she ignored the traditional characteristic parameters of rice, which may be the reason for the poor final result of the model. By combining the fractal dimension with the traditional characteristics of rice, the prediction model obtained in this paper has a better effect. Compared with their research, this paper improved the shortcomings of their research and obtained a simple and effective model for predicting rice biomass. The model is based on images of rice and can play a role in the field of smart agriculture.
The multivariate linear regression model is very different from other machine learning algorithms. The model obtained through machine learning belongs to the black box model, and we cannot know the specific structure of the model, nor the role of each explanatory variable in the model, so the model has a low explanatory ability. However, the linear regression model has good explanatory properties, the expression of the model can be obtained and the effect of each variable in the model can be clearly understood through the expression. In the study of rice, researchers often pay close attention to the influence of variables which can guide the improvement in varieties. Therefore, in the prediction of rice biomass, if the effect of the linear regression model is not far from that of the machine learning model, it is suggested to give priority to the linear regression model.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}