
Comparative Analysis of Exemplar-Based Approaches for Students’ Learning Style Diagnosis Purposes



Abstract
:Featured Application
Abstract
1. Introduction
2. Methods
2.1. Combining Case-Based Reasoning and Bayesian Approach for Students’ Learning Style Modelling
2.2. Case-Based Reasoning and Similarity-Based Retrieval
2.3. Bayesian Approach and Bayesian Inference in Generative Models
- using Monte Carlo methods (for example, Gibbs sampling), when posterior distribution is represented as a collection of weighted samples;
- representing posterior distribution as parametric distribution and using variational methods for analytical approximation to the posterior probability of the unobserved variables;
- making amortized inference: learning to do inference quickly (“bottom-up”, “pattern-recognition”, “data-driven”).
2.4. Related Works
2.5. Modelling Based on Bayesian Approach and/or Case-Based Reasoning
2.5.1. Mixture Model
2.5.2. Latent Dirichlet Allocation-Mixed Membership Model
2.5.3. Differences between Mixed and Mixed Membership Models
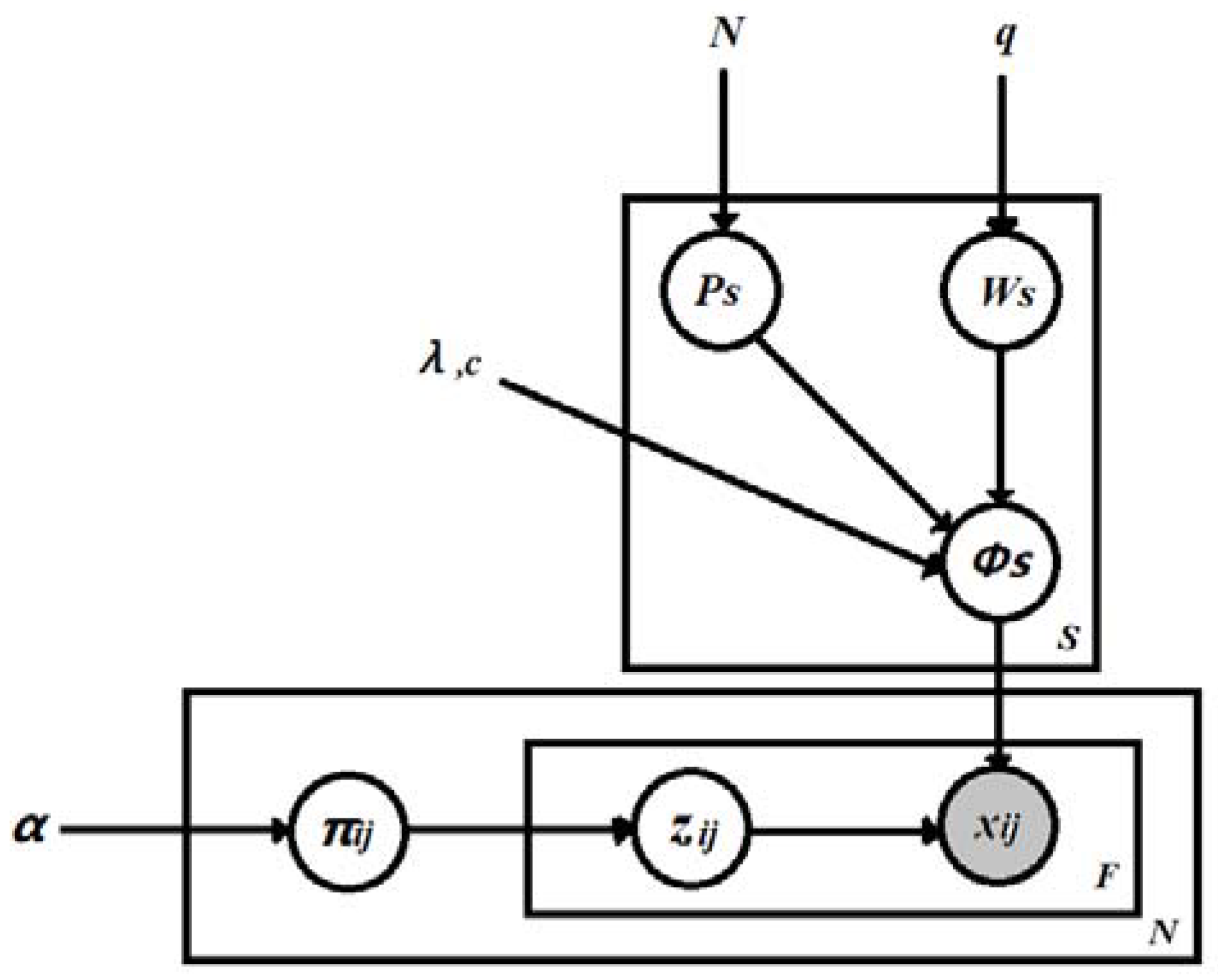
2.5.4. Bayesian Case Model
- ∀ s, j;
- ;
- ~Multinomial () ∀ i, j;
- ~Multinomial () ∀ i, j;
2.6. Proposed Approach for Students’ Learning Style Prediction
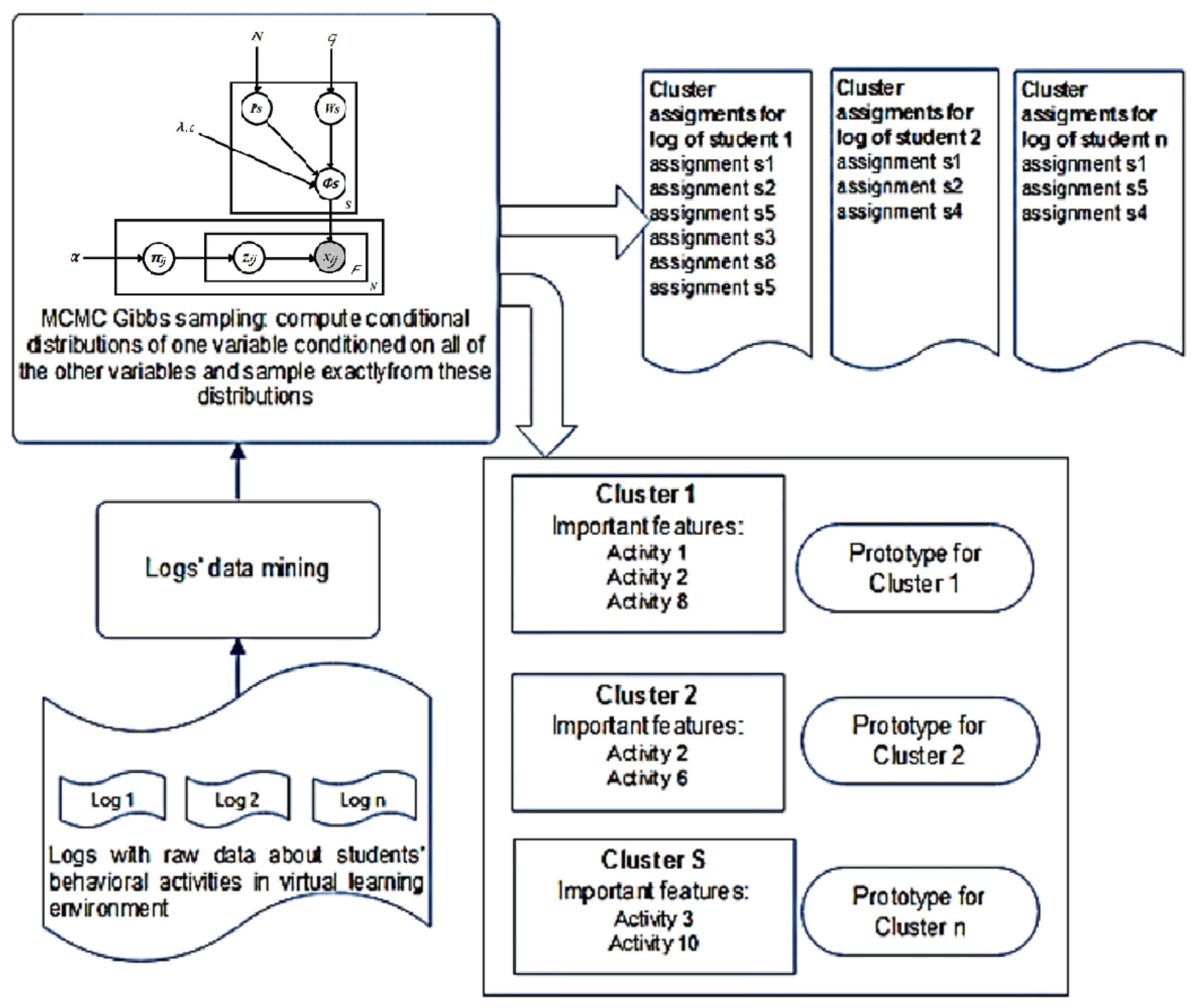
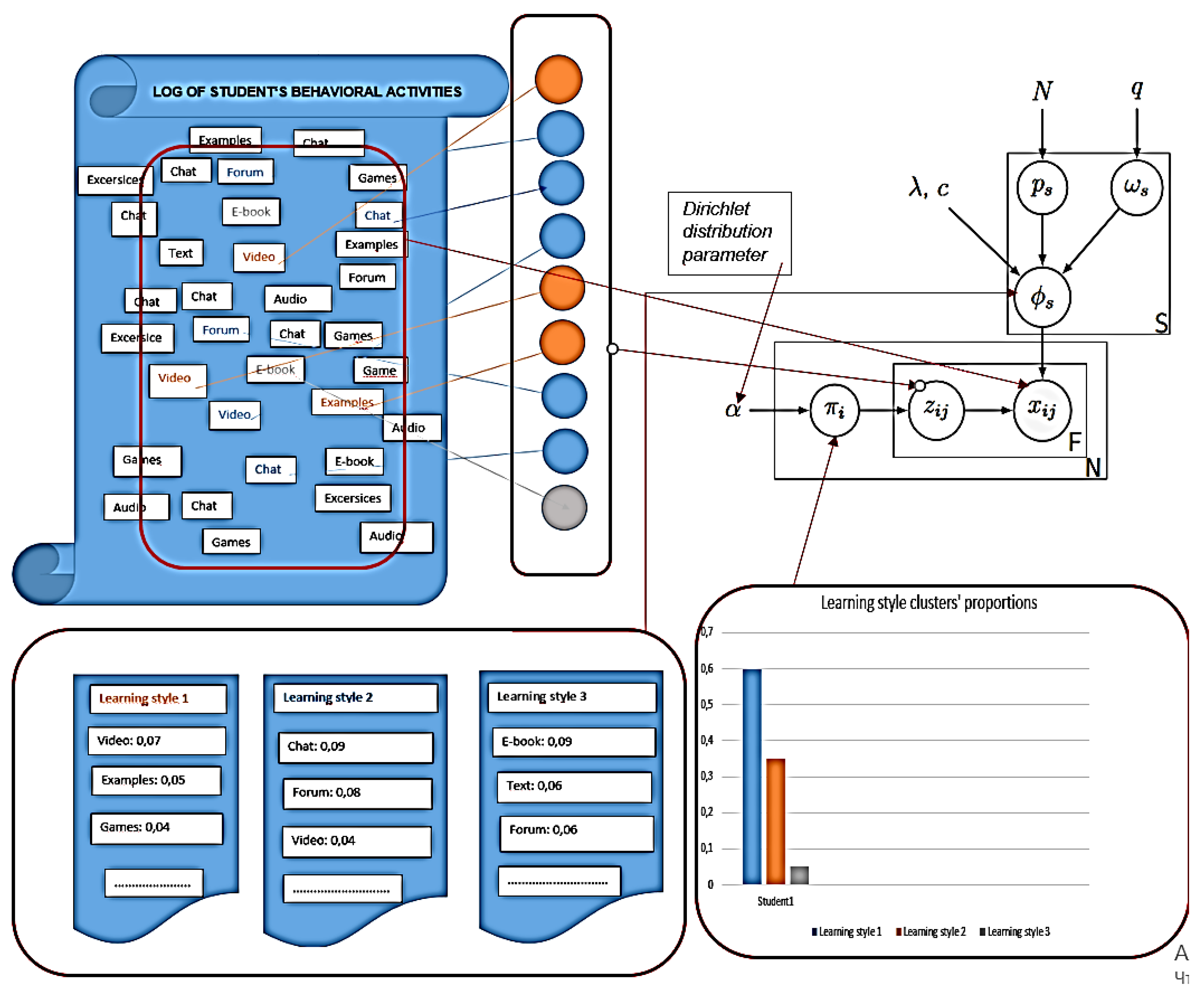
2.6.1. Bayesian Case Model for Students’ Learning Style Modelling
2.6.2. Enhanced Bayesian Case Model: Interactivity
2.6.3. Bayesian Patchworks
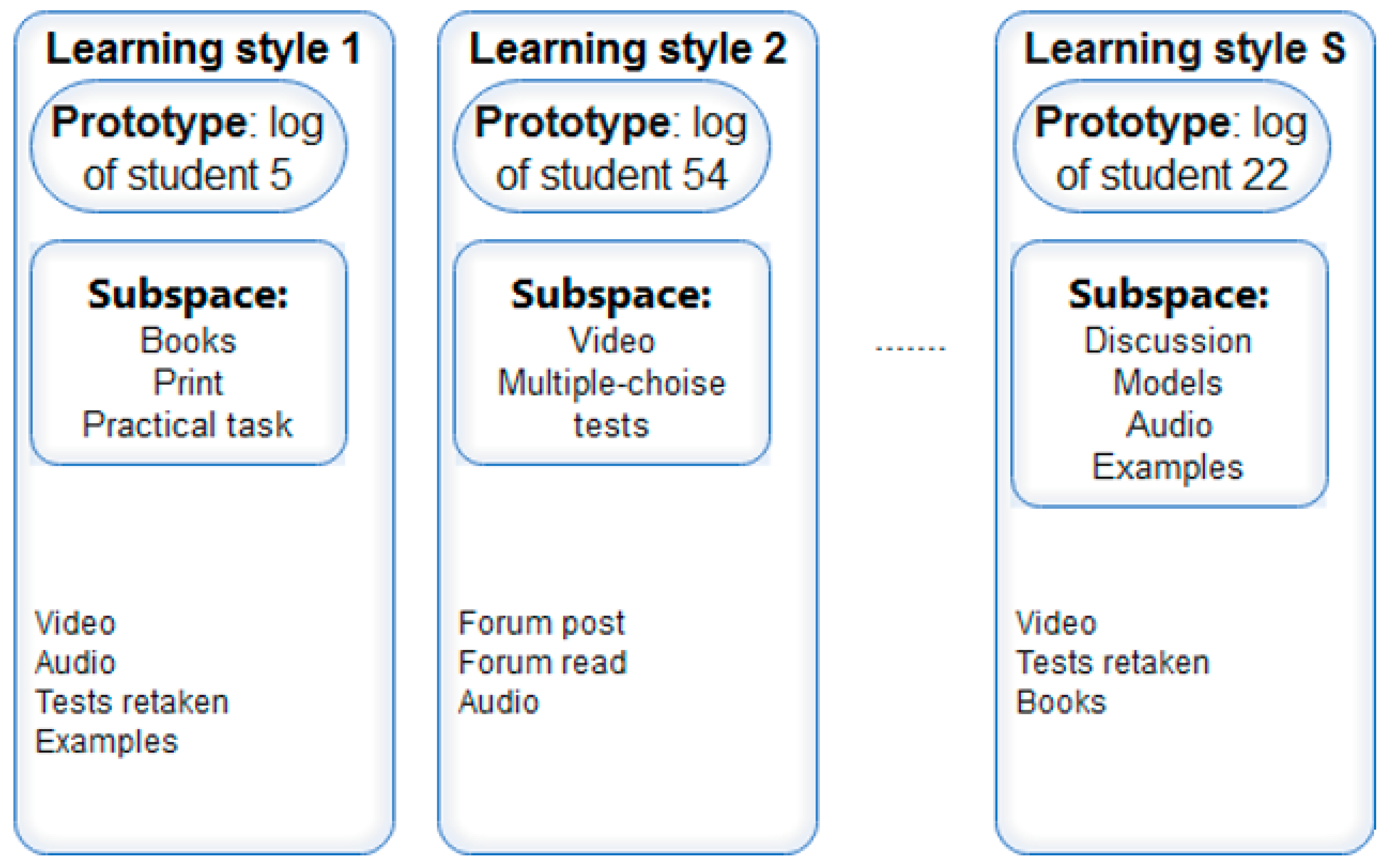
2.6.4. Interpretability
- prototype presented as log of behavioral activities of the student; this log best represents the cluster; in turn, a cluster represents learning style, and its features (for learning style modeling–behavioral activities) have cluster labels;
- subspace of important features, i.e., behavioral activities that have been performed most frequently in the virtual hypermedia learning environment by students whose learning style corresponds to the style represented by the cluster (Figure 4).
2.7. Comparative Analysis of Models and Networks
3. Discussion
4. Comparing Performances of LDA and BCM
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| CBR | Case-Based Reasoning |
| BN | Bayesian Networks |
| iBCM | interactive Bayesian Case model |
| LDA | Latent dirichlet allocation |
| VLE | virtual learning environment |
| EM | Expectation maximization |
| ML | maximum likelihood |
| DA | data augmentation |
| LC | latent class |
| MCMC | Markov chain Monte Carlo |
References
- Kurilovas, E. On Data-Driven Decision-Making for Quality Education. Comput. Hum. Behav. 2020, 207, 105774. [Google Scholar] [CrossRef]
- Jevsikova, T.; Berniukevičius, A.; Kurilovas, E. Application of Resource Description Framework to Personalise Learning: Systematic Review and Methodology. Inform. Educ. 2017, 16, 61–82. [Google Scholar] [CrossRef]
- Kurilovas, E.; Dagiene, V. Computational Thinking Skills and Adaptation Quality of Virtual Learning Environments for Learning Informatics. Int. J. Eng. Educ. 2016, 32, 1596–1603. [Google Scholar]
- Kurilovas, E.; Kurilova, J.; Andruskevic, T. On Suitability Index to Create Optimal Personalised Learning Packages. In Proceedings of the International Conference on Information and Software Technologies, Druskininkai, Lithuania, 13–15 October 2016. [Google Scholar]
- Kurilovas, E. Advanced Machine Learning Approaches to Personalize Learning: Learning Analytics and Decision Making. Behav. Inf. Technol. 2019, 38, 410–421. [Google Scholar] [CrossRef]
- Kim, B.; Glassman, E.; Johnson, B.; Shah, J. iBCM: Interactive Bayesian case model empowering humans via intuitive interaction. In Computer Science and Artificial Intelligence Laboratory Technical Report; DSpace@MIT, Massachusetts Institute of Technologies: Cambridge, MA, USA, 2015. [Google Scholar]
- Richter, M.M.; Weber, R.O. Case-Based Reasoning: A Textbook; Springer: Berlin, Germany, 2013; ISBN 978-3-642-40167-1. [Google Scholar]
- Kim, B. Interactive and Interpretable Machine Learning Models for Human Machine Collaboration. Ph.D. Thesis, Massachusetts Institute of Technology, Cambridge, MA, USA, 2015. [Google Scholar]
- Aamodt, A.; Plaza, E. Case-Based Reasoning: Foundational Issues, Methodological Variations, and System Approaches. AI Commun. 1994, 7, 39–59. [Google Scholar] [CrossRef]
- Costa, M.; Sousa, O.; Neves, J. Managing Legal Precedents with Case Retrieval Nets. 1999. Available online: http://jurix.nl/pdf/j99-02.pdf (accessed on 14 March 2021).
- Forbus, K.; Gentner, D.; Law, K. MAC/FAC: Model of similarity-based retrieval. Cogn. Sci. 1995, 19, 141–205. [Google Scholar] [CrossRef]
- Kramer, A. Introduction to Bayesian Inference. 2016. Available online: https://www.datascience.com/blog/introduction-to-bayesian-inference-learn-data-science-tutorials (accessed on 7 January 2021).
- Stack Exchange. 2018. Available online: https://stats.stackexchange.com/questions/307882/why-is-it-necessary-to-sample-from-the-posterior-distribution-if-we-already-know (accessed on 7 January 2021).
- Doll, T. LDA Topic Modeling: An Explanation. 2018. Available online: https://towardsdatascience.com/lda-topic-modeling-an-explanation-e184c90aadcd (accessed on 14 March 2021).
- Liu, S. Latent Dirichlet Distribution. 2019. Available online: https://towardsdatascience.com/dirichlet-distribution-a82ab942a879 (accessed on 14 March 2021).
- Stack Exchange. Bayesian Updating without Conjugate Prior. 2013. Available online: https://stats.stackexchange.com/questions/45371/bayesian-updating-without-conjugate-prior?rq=1 (accessed on 14 March 2021).
- Hewitt, L. Bayesian Inference in Generative Models. 2018. Available online: https://www.youtube.com/watch?v=PRY2NbOXbHk (accessed on 14 March 2021).
- Franzen, J. Bayesian Inference for a Mixture Model Using the Gibbs Sampler. 2006. Available online: http://gauss.stat.su.se/rr/RR2006_1.pdf (accessed on 14 March 2021).
- Quora. Why Is LDA a Mixture Model. Available online: https://www.quora.com/Why-is-LDA-a-mixture-model (accessed on 14 March 2021).
- Grosse, R.; Srivastava, N. Lecture 16: Mixture Models. 2018. Available online: http://www.cs.toronto.edu/~rgrosse/csc321/mixture_models.pdf (accessed on 14 March 2021).
- r/learnmath-Explain to Me Like I’m Five: Gibbs Sampling. 2012. Available online: https://www.reddit.com/r/learnmath/comments/x4pqe/explain_to_me_like_im_five_gibbs_sampling/ (accessed on 14 March 2021).
- Bruland, T.; Aamodt, A.; Langseth, H. Architectures Integrating Case-Based Reasoning and Bayesian Networks for Clinical Decision Support. In Proceedings of the Intelligent Information Processing V—6th IFIP TC 12 International Conference, Manchester, UK, 13–16 October 2010. [Google Scholar]
- Prentzas, J.; Hatzilygeroudis, I. Case-based reasoning integration: Approaches and applications. In Case-Based Reasoning: Processes, Suitability and Applications; Nova Science Publishers: New York, NY, USA, 2011; pp. 1–28. [Google Scholar]
- Marling, C.; Sqalli, M.; Rissland, E.; Munoz-Avila, H.; Aha, D. Case-based reasoning integrations. AI Mag. 2002, 23, 69. [Google Scholar] [CrossRef] [Green Version]
- Houeland, T.; Bruland, T.; Aamodt, A.; Langseth, H. A Hybrid Meta Reasoning Architecture Combining Case-Based Reasoning and Bayesian Networks; Semantic Scolar, Allen Institute for AI: Seattle, WA, USA, 2011. [Google Scholar]
- Schiaffino, S.; Amandi, A. User profiling with case-based reasoning and Bayesian networks. In Proceedings of the International Joint Conference IBERAMIA-SBIA 2000, Atibaia, Brazil, 19–22 November 2000; pp. 12–21. [Google Scholar]
- Nikpour, H. Prediction and explanation by combined model-based and case-based reasoning. In Proceedings of the Twenty-Fourth International Conference on Case-Based Reasoning (ICCBR 2016), Atlanta, GA, USA, 31 October–2 November 2016. [Google Scholar]
- Nikpour, H.; Aamodt, A.; Bach, K. Bayesian-Supported Retrieval in BNCreek: A Knowledge-Intensive Case-Based Reasoning System. In Case-Based Reasoning Research and Development; Springer: Cham, Switzerland, 2018; pp. 323–338. [Google Scholar]
- Gonzalez, K.; Burguillo, J.C.; Llamas, M. A qualitative comparison of techniques for student modelling in intelligent tutoring systems. In Proceedings of the Frontiers in Education, 36th Annual Conference, San Diego, CA, USA, 27–31 October 2006. [Google Scholar]
- Bannacer, L.; Ciavaglia, L.; Chibani, A.; Amirat, Y. Optimization of fault diagnosis based on the combination of Bayesian networks and case-based reasoning. In Proceedings of the 2012 IEEE Network Operations and Management Symposium, Maui, HI, USA, 16–20 April 2012. [Google Scholar]
- Aamodt, A.; Langseth, H. Integrating Bayesian networks into knowledge intensive CBR. In AAAI Technical Report WS-98-15; AAAI: Palo Alto, CA, USA, 1998. [Google Scholar]
- Khamparia, A. Knowledge and intelligent computing methods in e-learning. Int. J. Technol. Enhanc. Learn. 2015, 7, 221–242. [Google Scholar] [CrossRef]
- Ferreira, L.D.; Spadon, G.; Carvalho, A.C.; Rodrigues, J.F. A comparative analysis of the automatic modeling of Learning Styles through Machine Learning techniques. In Proceedings of the 2018 IEEE Frontiers in Education Conference (FIE), San Jose, CA, USA, 3–6 October 2018. [Google Scholar]
- Vidotto, D.; Kaptein, M.C.; Vermunt, J.K. Multiple Imputation of Missing Categorical Data using Latent Class Models: State of the Art. Psychol. Test Assess. Model. 2015, 57, 542. [Google Scholar]
- Neal, R.M. Bayesian mixture modeling by Monte Carlo simulation. In Technical Report CRG-TR-91-2; Computer Science, University of Toronto: Toronto, ON, Canada, 1991. [Google Scholar]
- Celeux, G.; Kamry, K.; Malsiner-Walli, G.; Marin, J.-M.; Robert, C. Computational Solutions for Bayesian Inference in Mixture Models. 2018. Available online: https://www.researchgate.net/publication/329772148_Computational_Solutions_for_Bayesian_Inference_in_Mixture_Models (accessed on 14 March 2021).
- While My MCMC Gently Samples, Bayesian Modelling, Data Science and Phython. MCMC Sampling for Dummies. 2015. Available online: https://twiecki.io/blog/2015/11/10/mcmc-sampling/ (accessed on 7 January 2021).
- Dwivedi, P. Doing Cool Things with Data. NLP: Extracting the Main Topics from Your Dataset Using LDA in Minutes. 2018. Available online: https://towardsdatascience.com/nlp-extracting-the-main-topics-from-your-dataset-using-lda-in-minutes-21486f5aa925 (accessed on 14 March 2021).
- Gormley, M. Dirichlet process and Dirichlet process mixtures. In Probabilistic Graphical Models; School of Computer Science, Carnegie Mellon University: Pittsburgh, PA, USA, 2016. [Google Scholar]
- Blei, D.; Ng, A.; Jordan, M. Latent Dirichlet allocation. J. Mach. Learn. Res. 2003, 3, 993–1022. [Google Scholar]
- De Paulo Faleiros, T.; de Andrade Lopes, A. On the equivalence between algorithms for non-negative Matrix Factorization and Latent Dirichlet Allocation. In Proceedings of the International Conference on Computational Science and Its Applications, Trieste, Italy, 3–6 July 2017. [Google Scholar]
- Airoldi, E.M.; Blei, D.M.; Erosheva, E.A.; Fienberg, S.E. Introduction to Mixed Membership Models and Methods. Handb. Mix. Membsh. Model. Appl. 2020, 100, 3–14. [Google Scholar]
- Shalizi, C. Mixture Models. 2020. Available online: https://www.stat.cmu.edu/~cshalizi/uADA/12/lectures/ch20.pdf (accessed on 10 June 2021).
- About: Plate Notation. 2019. Available online: http://dbpedia.org/page/Plate_notation (accessed on 19 January 2021).
- Zinkov, R. Stop Using Plate Notation. 2013. Available online: https://www.zinkov.com/posts/2013-07-28-stop-using-plates/ (accessed on 7 January 2021).
- Lu, S.; Yu, L.; Feng, S.; Zhu, Y.; Zhang, W.; Yu, Y. CoT: Cooperative Training for Generative Modeling of Discrete Data. In Proceedings of the ICLR 2019 Conference, New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Neal, R.M. Markov chain sampling methods for Dirichlet process mixture models. J. Comput. Graph. Stat. 2000, 9, 249–265. [Google Scholar]
- Wikipedia. Maximum Entropy Probability Distribution. 2019. Available online: https://en.wikipedia.org/wiki/Maximum_entropy_probability_distribution (accessed on 14 March 2021).
- Liu, J.S. The Collapsed Gibbs Sampler in Bayesian Computations with Applications to a Gene Regulation Problem. J. Am. Stat. Assoc. 1994, 89, 958–966. [Google Scholar] [CrossRef]
- Goštautaitė, D. Recommendation systems and recommendation dashboards for learning personalization. In Proceedings of the INTED2019—13th International Technology, Education and Development Conference, Valencia, Spain, 11–13 March 2019. [Google Scholar]
- Kim, B.; Rudin, T.; Sah, J. The Bayesian CASE model: A generative approach for case-based reasoning and prototype classification. In Proceedings of the Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014. [Google Scholar]
- Moghaddass, R.; Rudin, C. Bayesian Patchworks: An Approach to Case-Based Reasoning. 2018. Available online: https://arxiv.org/abs/1809.03541v1 (accessed on 14 March 2021).
- Molnar, C. Interpretable Machine Learning. A Guide for Making Black Box Models Explainable. Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License. 2019. Available online: https://christophm.github.io/interpretable-ml-book/index.html (accessed on 12 May 2021).
- Kim, B.; Khanna, R.; Koyejo, O.O. Examples are not enough, learn to criticize! Criticism for interpretability. In Proceedings of the NIPS’16: 30th International Conference on Neural Information Processing Systems, Barcelona, Spain, 5 December 2016. [Google Scholar]
- Garg, V.K.; Wang, Y. Signal Types, Properties, and Processes. In The Electrical Engineering Handbook; Academic Press: New York, NY, USA, 2005. [Google Scholar]
- Miller, T. Explanation in Artificial Intelligence: Insights from the Social Sciences. 2018. Available online: https://arxiv.org/pdf/1706.07269.pdf (accessed on 12 May 2021).
- Quora. What Is the Good Explanation of HDP Latent Dirichlet Allocation. 2015. Available online: https://www.quora.com/What-is-the-good-explanation-of-HDP-latent-Dirichlet-allocation (accessed on 14 March 2021).
- Kim, B. Bayesian CASE Model—Generative Approach for Case-Based Reasoning and Prototype Classification. 2015. Available online: https://www.youtube.com/watch?v=xSViWMPF7tE (accessed on 19 January 2021).
- Guo, H.; Hsu, W. A Survey of Algorithms for Real-Time Bayesian Network Inference. In AAAI Technical Report WS-02-15; AAAI: Palo Alto, CA, USA, 2002. [Google Scholar]
- Biostatistics and Medical Informatics. Learning Bayesian Networks. 2018. Available online: http://pages.cs.wisc.edu/~dpage/cs760/BNall.pdf (accessed on 12 May 2021).
- Riggelsen, C.; Feelders, A. Learning Bayesian Network Models from Incomplete Data using Importance Sampling. In Proceedings of the Tenth International Workshop on Artificial Intelligence and Statistics, Bridgetown, Barbados, 6–8 January 2005. [Google Scholar]
- Rai, S.S. 3 Methods to Handle Missing Data. 2019. Available online: https://www.datascience.com/blog/missing-data-imputation (accessed on 10 May 2021).
- Sauro, J. 7 Ways to Handle Missing Data. 2015. Available online: https://measuringu.com/handle-missing-data/ (accessed on 12 May 2021).
- Lacave, C.; Diez, F.J. A review of explanation methods for Bayesian networks. Knowl. Eng. Rev. 2002, 17, 107–127. [Google Scholar] [CrossRef]
- Tomar, A. Machine Learning. Topic Modelling Using LDA and Gibbs Sampling Explained. 2018. Available online: https://medium.com/@tomar.ankur287/topic-modeling-using-lda-and-gibbs-sampling-explained-49d49b3d1045 (accessed on 7 January 2021).
- Yu, H.F.; Hsieh, C.J.; Dhillon, I. Fast and Scalable Algorithms for Topic Modeling. 2015. Available online: https://bigdata.oden.utexas.edu/project/scalable-topic-modeling/ (accessed on 12 May 2021).
- Mohanty, N.; Rath, T.M. Handbook of Statistics; Elsevier: Amsterdam, The Netherlands, 2013. [Google Scholar]
- Shiffrin, R.M.; Lee, M.D.; Kim, W.; Wagenmakers, E.J. A Survey of Model Evaluation Approaches with a Tutorial on Hierarchical Bayesian Methods. Cogn. Sci. 2008, 32, 1248–1284. [Google Scholar] [CrossRef] [PubMed]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Criteria | BN/CBR | Optimized BN + CBR [30] | BCM [8,50,54,57,58] | Bayesian Patchworks [52] | Mixed Membership [57] |
|---|---|---|---|---|---|
| Model structure learning | heuristic algorithms | chi-squared test for construction of relationships between nodes and in case of change of number of nodes | generative mixture model, feature values exist in a discrete set that is not necessarily binary; uses clustering, number of clusters is previously defined | Bayesian hierarchical model, generative | generative statistical model, Latent Dirichlet allocation (LDA, standard mixture model); students are represented as random mixtures over latent learning styles, where each learning style is characterized by a distribution over all the behavioral activities in the student’s log |
| Features’ learning from data | expert-centric, data-centric | expert-centric, data-centric; effect centric | BCM uses generative story to explain parameters; generation of features is a result of a single prototype sharing its feature with the new observation; generation of features is correlated; collapsed Gibbs sampling being used converges quite quickly; After training the model, BCM cannot add new features | generation of features is a result of a vote among parents; generation of features is correlated | reverse-engineering the process where students’ logs are created by picking a set of learning styles and then for each learning style picking a set of behavioral activities; assumption that each feature value is generated independently; |
| Inference process | exact inference [59]: conditional probability tables’ update by marginal probability; using Bayes theorem; message passing algorithm | exact inference [59]: conditional probability tables’ update by marginal probability; using Bayes theorem; message passing algorithm on the subset of relevant nodes only | BCM is brute-force (proof by exhaustion, or proof by case analysis, complete induction); BCM makes joint approximate inference on latent and evidence variables; it uses Gibbs update, approximation of the posterior distribution using collapsed Gibbs sampling [59] | joint approximate inference on the selection of past cases that are influential to each new case, the subset of features of the past cases that are relevant to the new case, and how strong the influences of the past cases are on the new case; Metropolis-within-Gibbs sampling [59]; similar to nearest neighbors | variational Bayes approximation of the posterior distribution; alternative inference techniques use Gibbs sampling [59] and expectation propagation |
| Influence/effect on values of BN features/parameters | calculate the new (posterior) joint distribution of the network by conditioning it on the evidence | calculate the new (posterior) joint distribution of the network by conditioning it on the evidence | at cluster level, using prototype; BCM limits new cases to be compared with only certain learned past cases (the prototypes) [52]; BCM’s generation of features is a result of a single prototype sharing its feature with the new observation [52]; generation of features is correlated through clusters [52] | at individual (parents) level: the distribution of values for any feature is generated by parents; BPatch’s generation of features is a result of a vote among parents [52]; generation of features is correlated through parents [52] | cluster proportions’ level; LDA has a strong (and false) assumption that each feature value is generated independently [52] |
| Computation time; use of memory | learning BN is NP hard; depends on inference algorithm [59] | comparing with BN/CBR: reduced time of computation due to saving of previous cases and reuse of them thus avoiding calculation of inference repeatedly; and due to reduction of complexity (reduction of the number of nodes involved in the diagnosis process) | generative story: convergence to the true distribution is extremely slow | slightly slower than BCM; comparing to BN + CBR: much slower; more memory than BCM; suited for small datasets the total number of influential neighbors for each new case is a critical factor in the performance of the model | fast collapsed Gibbs sampling for LDA can be as much as 8 times faster than the standard collapsed Gibbs sampler for LDA |
| Prediction accuracy | ±80%; prediction accuracy decreases with an increase of BN size | prediction accuracy greater that in BN/CBR due to saving of previous cases and reuse of them | high unsupervised clustering accuracy as a function of iterations; prediction accuracy comparable to or better than prior art for standard datasets, in BCM classification accuracy was 85.9% [8,51]; prediction accuracy better than in LDA | high; classification accuracy depends on hyperparameters | ±80%; |
| Handling missing data points | two main approaches for learning BN parameters are Expectation-Maximization (EM) and a simulation-based Gibbs sampler called Data Augmentation (DA) [60]. The Expectation step involves the performance of inference in order to obtain sufficient statistics. In Maximization step the Maximum Likelihood (ML) estimates are computed from the sufficient statistics. These two steps are iterated until the parameter estimates converge [61]. Data Augmentation is similar, but it is non-deterministic. Instead of calculating expected statistics, a value is drawn from a predictive distribution and imputed. Similarly, instead of calculating the ML estimates, draws from the posterior distribution on the parameter space (conditioned on the sufficient statistics of the most recent imputed dataset) are made. Based on Markov chain Monte Carlo theory, this will eventually return realizations from the posterior parameter distribution [61]. Other: Bound and Collapse (BC) approach; structural EM (SEM); eMC3; eMC4 (importance sampling, that does not require exact inference in a BN; specifying an approximate distribution is cheaper than a perfect one) [61]. When data are missing at random, Multivariate Imputation by Chained Equations (MICE) method may be applied [62]. It imputes data on a variable-by-variable basis by specifying an imputation model per variable [62]. Depending on the nature of the data, Random forest, a non-parametric imputation method, may be applicable to various variable types that works well with both data missing at random and not missing at random [62]. In some cases, list-wise or pair-wise deletion of the missing observations can be used or other methods may be applied [63] | BCM will ignore missing features and only focus on what is common between data points explicitly for clustering or cluster all data points with missing feature (-s) in one cluster-existing Bayesian Case model [8,51] is not targeted for missing data | any method for imputation may be used. Besides that, for each dimension of features, an artificial output representing missing value can be added | implementations of latent class (LC) models (i.e., mixture models that describe the distribution of categorical data) for multiple imputation (MI) [34]: The Maximum Likelihood LC model (MLLC), the standard Bayesian LC model (BLC), the Divisive LC model (DLC), and the Dirichlet Process Mixture of Multinomial distributions (DPMM) | |
| Explanations | heuristic and normative methods exist for BN explanations. According to [64], there are the following types of explanations: explanations of evidence (abduction: Pearl’s propagation, linear restrictions system, weighted Boolean function acyclic directed graph, genetic algorithm based or stochastic annealing based approximate abduction), explanations of model (static explanations, containing information in data base) and explanations of reasoning at micro and macro levels (dynamic explanations: reasoning process that produced results; explanations why the network did not produce expected results; hypothetical reasoning)) [64]. Verbal, graphical, multimedia explanations may be presented. As CBR represents domain knowledge-oriented method, general domain model combined with CBR enables to generate targeted explanations for the user as well as for its internal reasoning process [27]. Typically, BN + CBR generate explanations given the observed symptoms. CBR models designed explicitly to produce explanations rely on the backward chaining of the causal relation from a solution, which does not scale as complexity increases [8,51]; other CBR models require to be created by experts; | in BCM, the underlying structure of the observations is represented by a standard discrete mixture model. Explanations produced by mixture models are typically presented as distributions over features [8,51]. BCM uses generative story to explain parameters. BCM preserves the power of CBR in generating interpretable output, where interpretability comes not only from sparsity but from the prototype exemplars [8,51]. Explanations are based on natural exemplars: a prototype and a set of important features defining a cluster [8,51]; | model provides explanations that are similar to the way the reasons are presented naturally. Deep insights into data | explanations presented as distributions over features. LDA represents documents as mixtures of topics that spit out words with certain probabilities. It is a way of automatically discovering topics that documents contain–LDA finds a set of topics that are likely to have generated the collection of documents | |
| Scalability | high number of features and complexity hinder performance of BN. CBR improves BN performance, reducing the complexity | No restrictions on network size and topology | in BCM, Gibbs sampling [65] inference technique is used to perform inference. However, there are other techniques that may scale better for larger datasets (e.g., variational inference, tensor decomposition methods). Since not all distributions used in BCM are within the exponential families (exponential distribution is a case of the gamma distribution, and it is a memoryless distribution), the current BCM model does not offer closed-form updates (i.e., updates that can be evaluated in a finite number of operations, solved analytically) when using variational inference. Modification or approximation of the BCM model may ease the derivation of variational inference [8,51] | generally, patchwork is a distributed density clustering algorithm with linear computational complexity and linear horizontal scalability. Bayesian Patchworks may be treated as a form of adaptive k nearest neighbors. Each case is generated by several neighbors, each using a different distance measure to the present case. Considering neighbors through different lenses makes more sense than fixing one distance measure, and having only one way to search for nearest neighbors [52] | variational inference, F + LDA, F + Nomad LDA, Alias LDA, Light LDA, Warp LDA, LDA* or other methods should be used instead of Gibbs sampling for large data sets and/or scalable and efficient distribution of the computation across multiple machines [66] |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Goštautaitė, D.; Kurilov, J. Comparative Analysis of Exemplar-Based Approaches for Students’ Learning Style Diagnosis Purposes. Appl. Sci. 2021, 11, 7083. https://doi.org/10.3390/app11157083
Goštautaitė D, Kurilov J. Comparative Analysis of Exemplar-Based Approaches for Students’ Learning Style Diagnosis Purposes. Applied Sciences. 2021; 11(15):7083. https://doi.org/10.3390/app11157083
Chicago/Turabian StyleGoštautaitė, Daiva, and Jevgenij Kurilov. 2021. "Comparative Analysis of Exemplar-Based Approaches for Students’ Learning Style Diagnosis Purposes" Applied Sciences 11, no. 15: 7083. https://doi.org/10.3390/app11157083
APA StyleGoštautaitė, D., & Kurilov, J. (2021). Comparative Analysis of Exemplar-Based Approaches for Students’ Learning Style Diagnosis Purposes. Applied Sciences, 11(15), 7083. https://doi.org/10.3390/app11157083