
Improved Ensemble-Learning Algorithm for Predictive Maintenance in the Manufacturing Process


Abstract
:1. Introduction
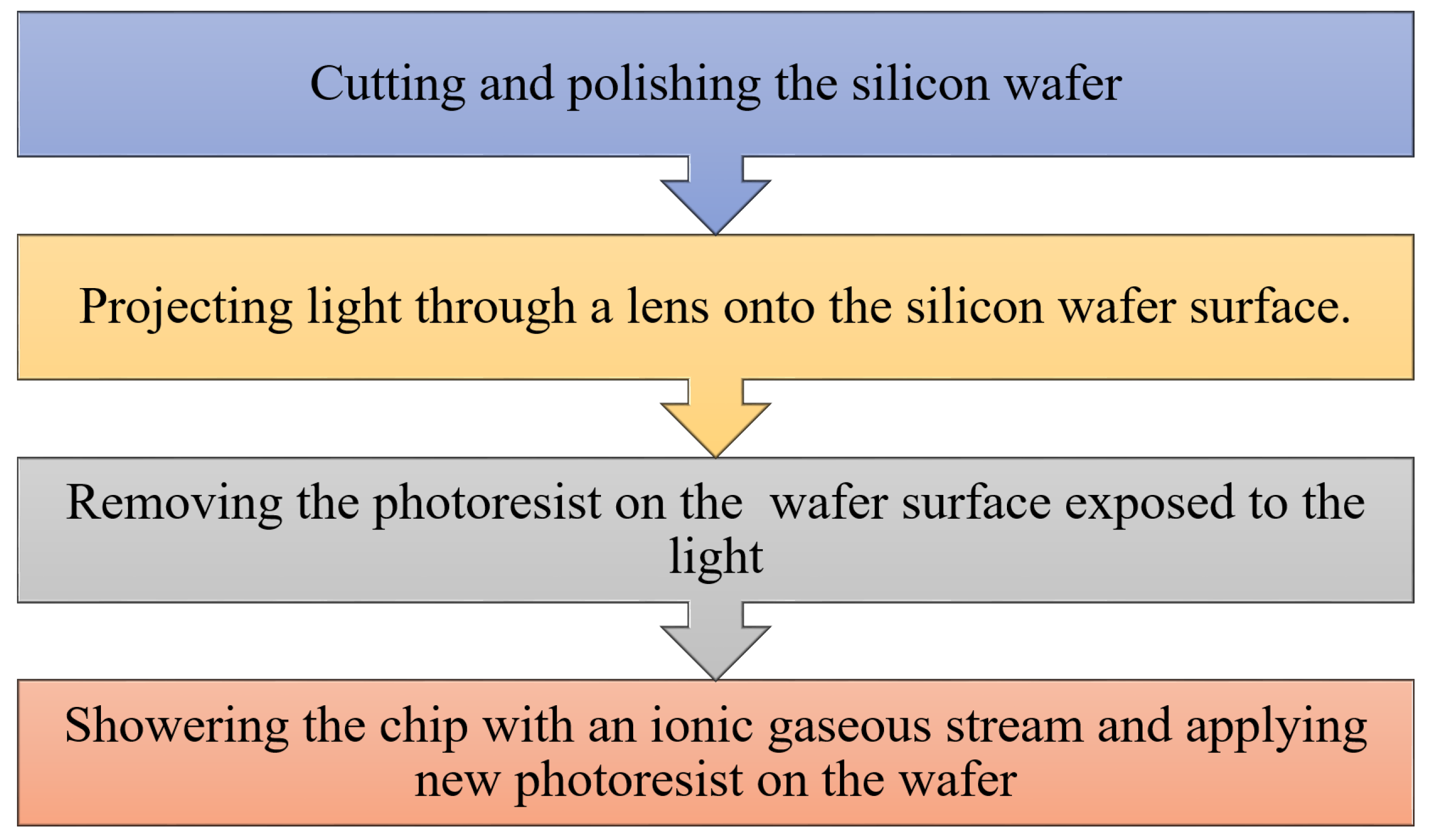
1.1. Semiconductor Manufacturing Process
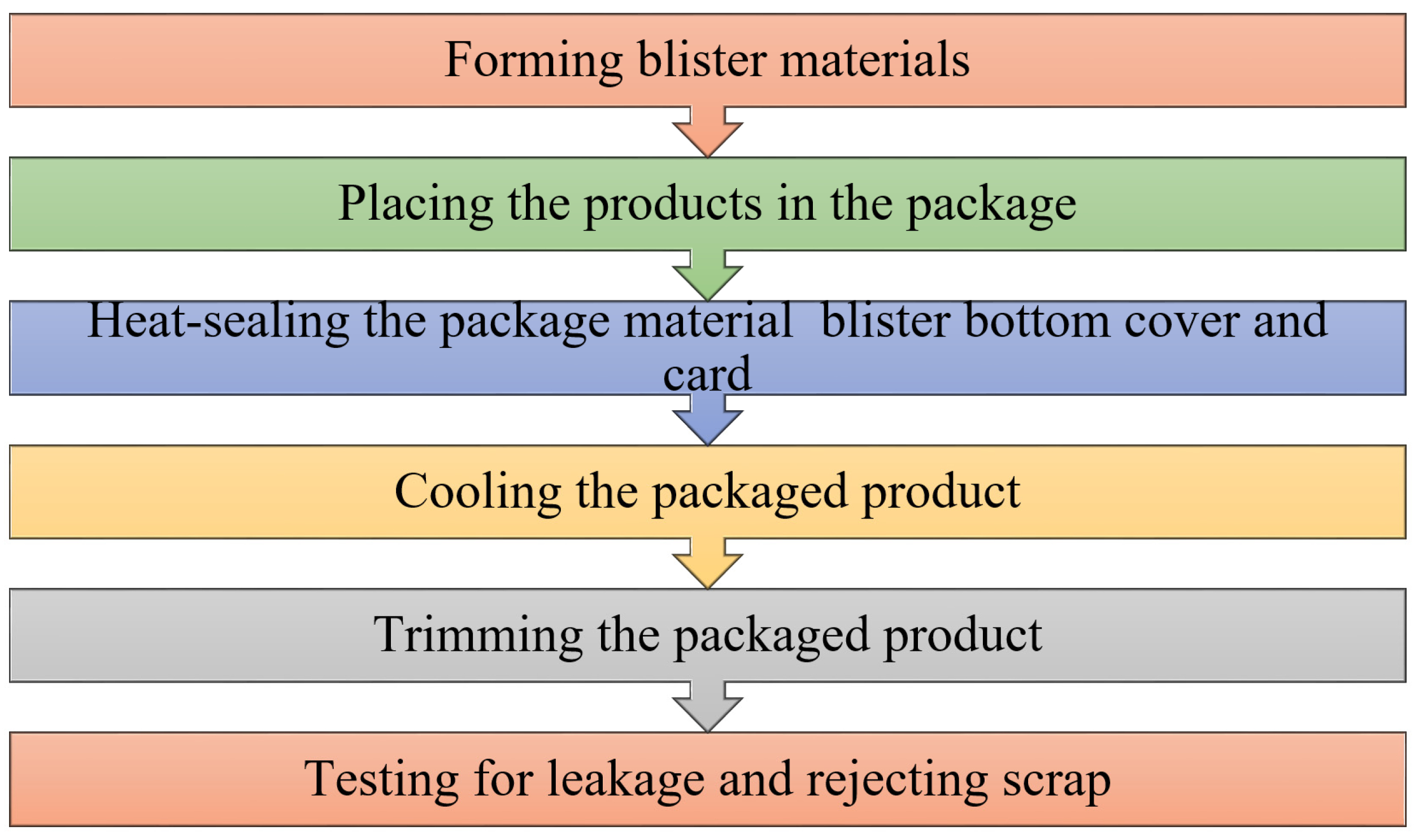
1.2. Scissor Product Packaging Machining Process
- Develop a new approach to improve the computation performance of boosted decision trees.
- Investigate the effect of ELAs and single models on manufacturing.
- Forecast yield failure in the semiconductor manufacturing process.
- Predict the package quality of the blister packing machine.
- Provide a prediagnostic suggestion for equipment configuration to improve work efficiency.
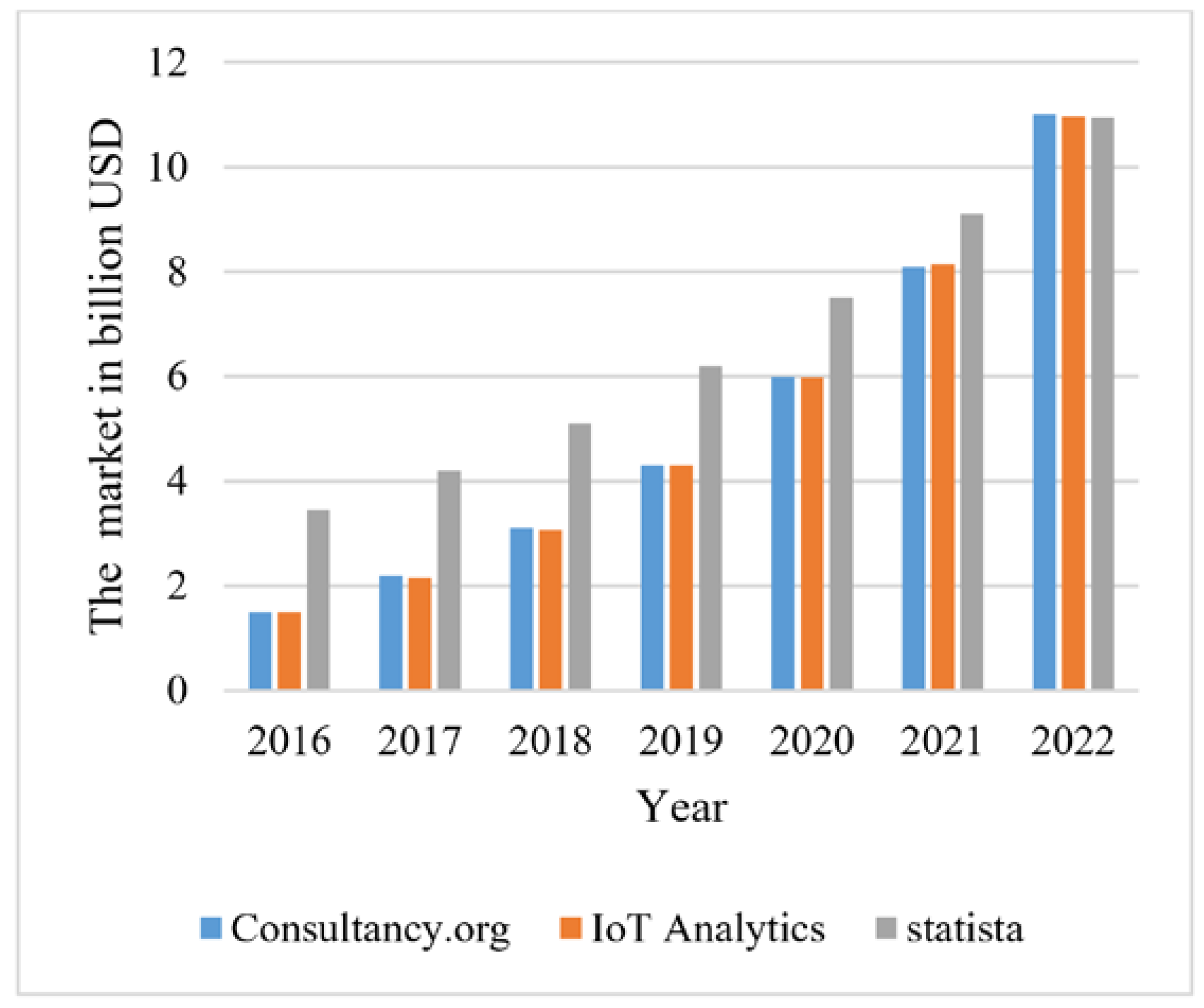
2. Current Trend of IIoT-Based PdM
3. IIoT-Based PdM-Related Studies
3.1. IIoT-Based PdM-Related Studies
3.2. Application of Ensemble Learning in Predictive Maintenance
4. Methodology
4.1. Data Preprocessing
- Step 1: exploring the minority class input data point.
- Step 2: finding the KNNs of the explored input data point.
- Step 3: select one of these neighbors’ point, and place a new point on the path connecting the point under consideration and its chosen neighbor.
- Step 4: Repeat Steps 1 and 2 until the termination condition is met (i.e., until the data are balanced).
4.2. Training Module
4.2.1. Decision Jungle
4.2.2. Boosted Decision Trees
4.2.3. Proposed Method: Adaptive Boosted Decision Trees
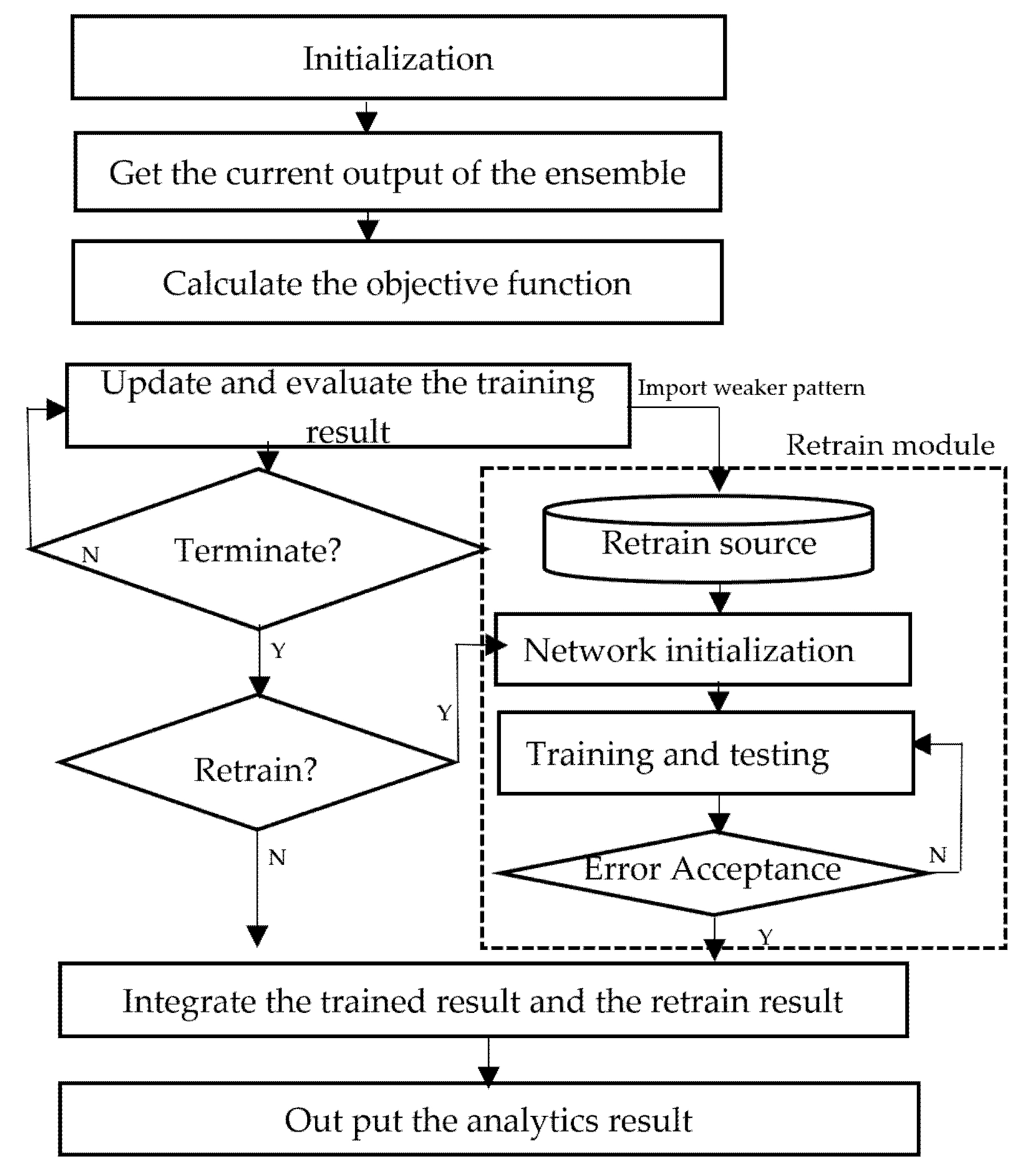
4.3. Module Deployment
5. Experiment
5.1. Case Data Description
5.2. Evaluation Criteria
5.2.1. Accuracy
5.2.2. Recall Rate (Sensitivity)
5.2.3. Receiver Operating Characteristic
5.2.4. Area under the ROC Curve
6. Result
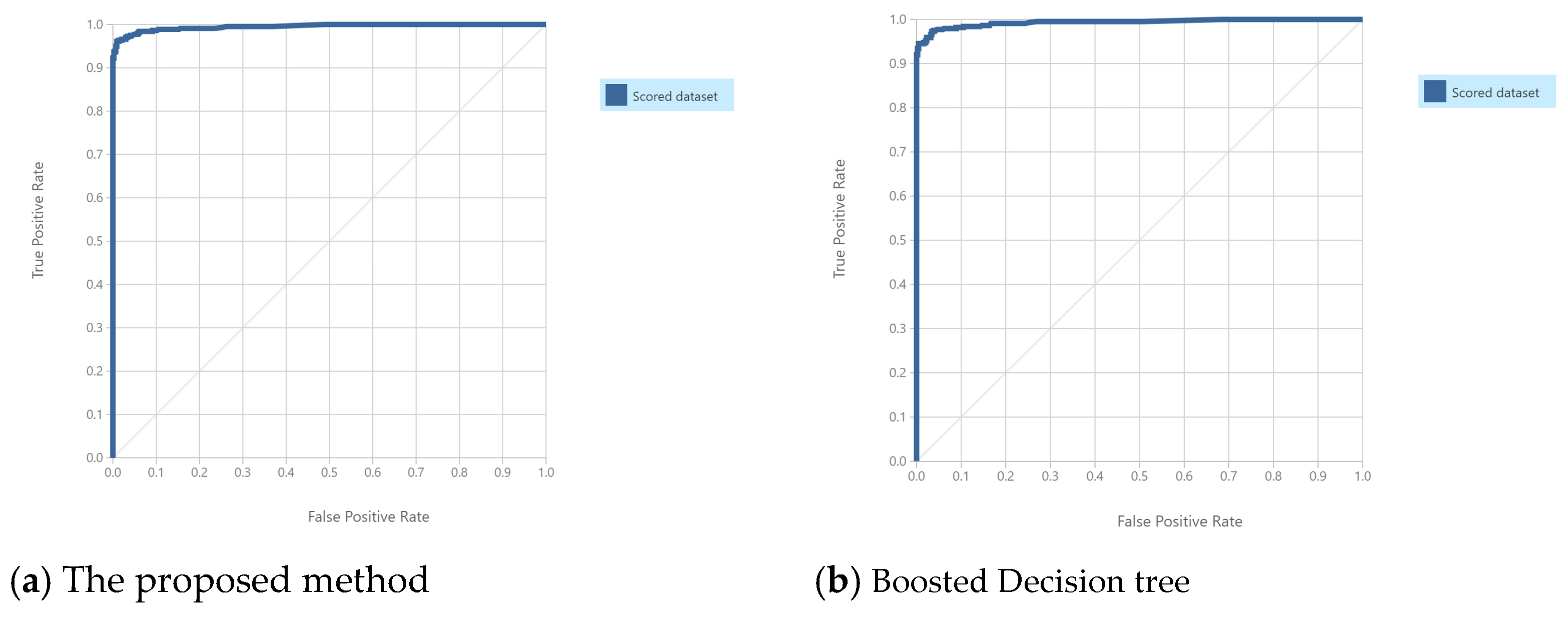
6.1. Yield Failure Prediction in the Semiconductor Manufacturing Process
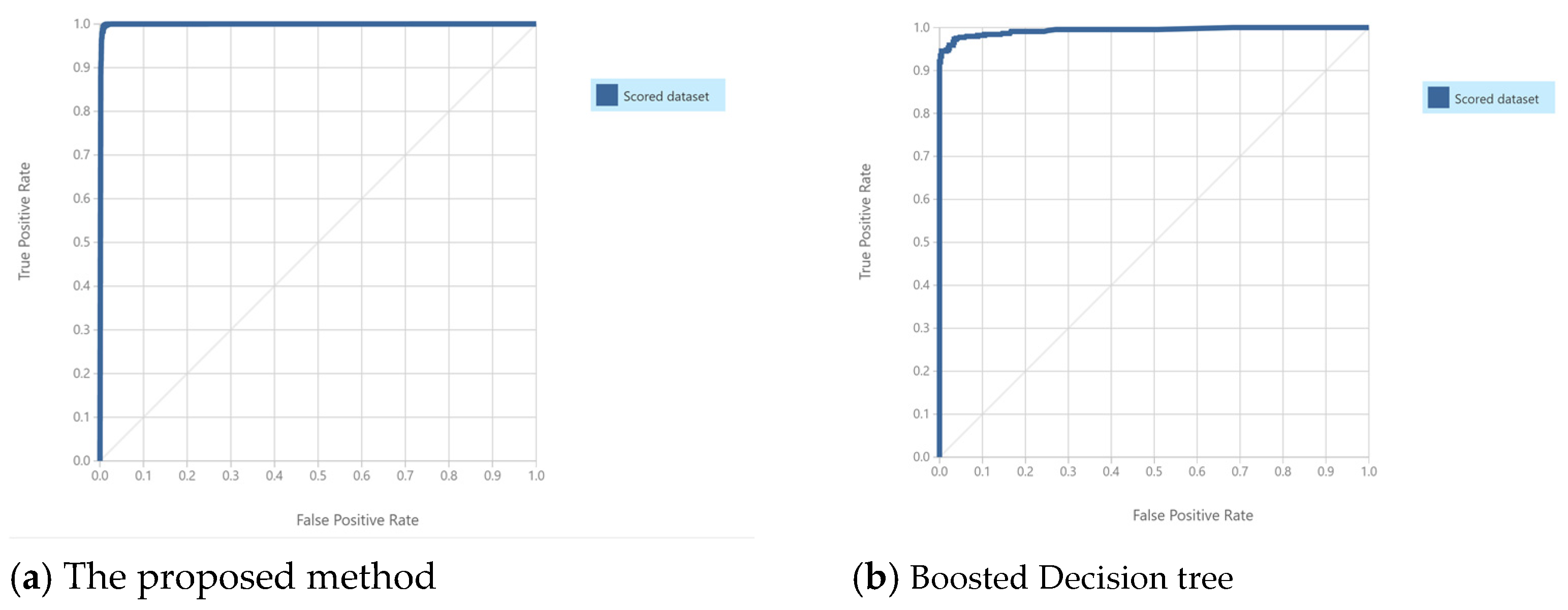
6.2. Quality Prediction of Scissor Product Packaging in Blister Packing Machining Process
7. Discussion
7.1. Potential of the Improved Ensemble-Learning Algorithm
7.2. Edge-Based Analytics and Fog-Based Analytics
8. Conclusions
8.1. Limitation of the Study
8.2. Future Study
Funding
Conflicts of Interest
References
- Dua, D.; Graff, C. UCI Machine Learning Repository, Archive.ics.uci.edu. 2020. Available online: http://archive.ics.uci.edu/ml (accessed on 22 November 2020).
- Rehman, M.H.U.; Ahmed, E.; Yaqoob, I.; Hashem, I.A.T.; Imran, M.; Ahmad, S. Big Data Analytics in Industrial IoT Using a Concentric Computing Model. IEEE Commun. Mag. 2018, 56, 37–43. [Google Scholar] [CrossRef]
- Slaughter, A.; Bean, G.; Mittal, A. Connected Barrels: Transforming Oil and Gas Strategies with the Internet of Things, Deloitte Insights. 2020. Available online: https://www2.deloitte.com/us/en/insights/focus/internet-of-things/iot-in-oil-and-gas-industry.html (accessed on 22 November 2020).
- Top 53 Big Data Platforms and Big Data Analytics Software in 2020-Reviews, Features, Pricing, Comparison-PAT RE-SEARCH: B2B Reviews, Buying Guides & Best Practices. 2020. Available online: https://www.predictiveanalyticstoday.com/bigdata-platforms-bigdata-analytics-software/ (accessed on 22 November 2020).
- Steady Commercial and Consumer Adoption Will Drive Worldwide Spending on the Internet of Things to $1.1 Trillion in 2023, According to a New IDC Spending Guide, IDC: The Premier Global Market Intelligence Company. 2020. Available online: https://www.idc.com/getdoc.jsp?containerId=prUS45197719 (accessed on 22 November 2020).
- Centerity.com. 2020. Available online: http://www.centerity.com/wp-content/uploads/2016/11/IoT-WhitePaper.pdf (accessed on 22 November 2020).
- Industrial Internet of Things (IIoT). Market Research Report: Market Size, Industry Outlook, Market Forecast, Demand Analy-sis, Market Share, Market Report 2018–2023. Industryarc.com. 2020. Available online: http://industryarc.com/Report/7385/industrial-internet-of-things-(IIoT)-market-report.html (accessed on 22 November 2020).
- Industrial IoT Market Size (IIoT). 2020. Available online: https://www.t4.ai/industry/industrial-iot-market-size-iiot (accessed on 22 November 2020).
- Industrial IoT (IIoT). Market by Device & Technology. Marketsandmarkets.com. 2020. Available online: https://www.marketsandmarkets.com/pdfdownloadNew.asp?id=129733727 (accessed on 15 January 2020).
- Industrial IoT. Market Size Worth $949.42 Billion By 2025 | CAGR: 29.4%, Grandviewresearch.com. 2020. Available online: https://www.grandviewresearch.com/press-release/global-industrial-internet-of-things-iiot-market (accessed on 15 January 2020).
- Global Predictive Analytics Market Size 2016–2022 | Statista, Statista. 2020. Available online: https://www.statista.com/statistics/819415/worldwide-predictive-analytics-market-size/ (accessed on 15 January 2020).
- Market for Predictive Maintenance to Reach $11 billion by 2022. Consultancy.uk. 2020. Available online: https://www.consultancy.uk/news/18408/market-for-predictive-maintenance-to-reach-11-billion-by-2022 (accessed on 15 January 2020).
- Predictive Maintenance Market Report 2017–2022. Iot-analytics.com. 2020. Available online: https://iot-analytics.com/product/predictive-maintenance-market-report-2017–2022/ (accessed on 15 January 2021).
- Predictive Maintenance Market by Component (Solutions and Services), Deployment Mode, Organization Size, Vertical (Government and Defense, Manufacturing, Energy and Utilities, Transportation and Logistics), and Region-Global Forecast to 2024. Marketsandmarkets.com. 2020. Available online: https://www.marketsandmarkets.com/pdfdownloadNew.asp?id=8656856 (accessed on 15 January 2021).
- Gilchrist, A. The Industrial Internet of Things; Apress: New York, NY, USA, 2016. [Google Scholar] [CrossRef]
- Qin, J.; Liu, Y.; Grosvenor, R. A Categorical Framework of Manufacturing for Industry 4.0 and Beyond. Procedia CIRP 2016, 52, 173–178. [Google Scholar] [CrossRef] [Green Version]
- Jeschke, S.; Brecher, C.; Meisen, T.; Özdemir, D.; Eschert, T. Industrial Internet of Things and Cyber Manufacturing Systems. In Industrial Internet of Things; Springer: Cham, Switzerland, 2017; pp. 3–19. [Google Scholar]
- Rose, K.; Eldridge, S.; Chapin, L. The Internet of Things: An Overview. Internet Soc. (ISOC) 2015, 80, 1–50. Available online: https://www.internetsociety.org/sites/default/files/ISOC-IoT-Overview20151014_0.pdf (accessed on 15 January 2020).
- Thoben, K.D.; Wiesner, S.; Wuest, T. “Industrie 4.0” and smart manufacturing-a review of research issues and ap-plication examples. Int. J. Autom. Technology 2017, 11, 4–16. [Google Scholar] [CrossRef] [Green Version]
- Chen, B.; Wan, J.; Shu, L.; Li, P.; Mukherjee, M.; Yin, B. Smart Factory of Industry 4.0: Key Technologies, Application Case, and Challenges. IEEE Access 2018, 6, 6505–6519. [Google Scholar] [CrossRef]
- Tao, F.; Qi, Q.; Liu, A.; Kusiak, A. Data-driven smart manufacturing. J. Manuf. Syst. 2018, 48, 157–169. [Google Scholar] [CrossRef]
- Sisinni, E.; Saifullah, A.; Han, S.; Jennehag, U.; Gidlund, M. Industrial Internet of Things: Challenges, Opportunities, and Directions. IEEE Trans. Ind. Inform. 2018, 14, 4724–4734. [Google Scholar] [CrossRef]
- Bahrin, M.A.K.; Othman, M.F.; Azli, N.H.N.; Talib, M.F. Industry 4.0: A Review on Industrial Automation and Robotic. J. Teknol. 2016, 78. [Google Scholar] [CrossRef] [Green Version]
- Wan, J.; Tang, S.; Li, D.; Wang, S.; Liu, C.; Abbas, H.; Vasilakos, A.V. A Manufacturing Big Data Solution for Active Preventive Maintenance. IEEE Trans. Ind. Inform. 2017, 13, 2039–2047. [Google Scholar] [CrossRef]
- Frank, A.G.; Dalenogare, L.S.; Ayala, N.F. Industry 4.0 technologies: Implementation patterns in manufacturing companies. Int. J. Prod. Econ. 2019, 210, 15–26. [Google Scholar] [CrossRef]
- Derhamy, H.; Eliasson, J.; Delsing, J.; Priller, P. A survey of commercial frameworks for the Internet of Things. In Proceedings of the 2015 IEEE 20th Conference on Emerging Technologies & Factory Automation (ETFA), Luxembourg, 8–11 September 2015; pp. 1–8. [Google Scholar]
- Ghobakhloo, M. The future of manufacturing industry: A strategic roadmap toward Industry 4.0. J. Manuf. Technol. Manag. 2018, 29, 910–936. [Google Scholar] [CrossRef] [Green Version]
- Arnold, C.; Kiel, D.; Voigt, K.-I. How the Industrial Internet of Things Changes Business Models in Different Manufacturing Industries. Int. J. Innov. Manag. 2016, 20, 1640015. [Google Scholar] [CrossRef]
- Li, J.-Q.; Yu, F.R.; Deng, G.; Luo, C.; Ming, Z.; Yan, Q. Industrial Internet: A Survey on the Enabling Technologies, Applications, and Challenges. IEEE Commun. Surv. Tutor. 2017, 19, 1504–1526. [Google Scholar] [CrossRef]
- Mumtaz, S.; Alsohaily, A.; Pang, Z.; Rayes, A.; Tsang, K.F.; Rodriguez, J. Massive Internet of Things for Industrial Applications: Addressing Wireless IIoT Connectivity Challenges and Ecosystem Fragmentation. IEEE Ind. Electron. Mag. 2017, 11, 28–33. [Google Scholar] [CrossRef]
- Ben-Daya, M.; Hassini, E.; Bahroun, Z. Internet of Things and supply chain management: A literature review. Int. J. Prod. Res. 2017, 57, 4719–4742. [Google Scholar] [CrossRef] [Green Version]
- Ehret, M.; Wirtz, J. Unlocking value from machines: Business models and the industrial internet of things. J. Mark. Manag. 2017, 33, 111–130. [Google Scholar] [CrossRef] [Green Version]
- Civerchia, F.; Bocchino, S.; Salvadori, C.; Rossi, E.; Maggiani, L.; Petracca, M. Industrial Internet of Things monitoring solution for advanced predictive maintenance applications. J. Ind. Inf. Integr. 2017, 7, 4–12. [Google Scholar] [CrossRef]
- Maple, C. Security and privacy in the internet of things. J. Cyber Policy 2017, 2, 155–184. [Google Scholar] [CrossRef]
- Kanawaday, A.; Sane, A. Machine learning for predictive maintenance of industrial machines using IoT sensor data. In Proceedings of the 2017 8th IEEE International Conference on Software Engineering and Service Science (ICSESS), Beijing, China, 20–22 November 2017; pp. 87–90. [Google Scholar]
- Li, Z.; Wu, D.; Hu, C.; Terpenny, J. An ensemble learning-based prognostic approach with degradation-dependent weights for remaining useful life prediction. Reliab. Eng. Syst. Saf. 2019, 184, 110–122. [Google Scholar] [CrossRef]
- Wu, D.; Jennings, C.; Terpenny, J.; Kumara, S. Cloud-based machine learning for predictive analytics: Tool wear prediction in milling. In Proceedings of the 2016 IEEE International Conference on Big Data, Big Data, Washington, DC, USA, 5–9 December 2016; pp. 2062–2069. [Google Scholar]
- Magal, R.K.; Jacob, S.G. Improved Random Forest Algorithm for Software Defect Prediction through Data Mining Techniques. Int. J. Comput. Appl. 2015, 117, 18–22. [Google Scholar] [CrossRef]
- Winkler, D.; Haltmeier, M.; Kleidorfer, M.; Rauch, W.; Tscheikner-Gratl, F. Pipe failure modelling for water distri-bution networks using boosted decision trees. Struct. Infrastruct. Eng. 2018, 14, 1402–1411. [Google Scholar] [CrossRef] [Green Version]
- Chawla, N.V.; Bowyer, K.W.; Hall, L.O.; Kegelmeyer, W.P. SMOTE: Synthetic minority over-sampling technique. J. Artif. Intell. Res. 2002, 16, 321–357. [Google Scholar] [CrossRef]
- Shotton, J.; Sharp, T.; Kohli, P.; Nowozin, S.; Winn, J.; Criminisi, A. Decision Jungles: Compact and Rich Models for Classification. 2016. Available online: http://papers.nips.cc/paper/5199-decision-jungles-compact-and-rich-models-for-classification (accessed on 15 January 2020).
- Baek, S.; Kim, K.I.; Kim, T.K. Deep convolutional decision jungle for image classification. arXiv 2017, arXiv:1706.02003. [Google Scholar]
- Sim, D.Y.Y.; Teh, C.S.; Ismail, A.I. Improved Boosted Decision Tree Algorithms by Adaptive Apriori and Post-Pruning for Predicting Obstructive Sleep Apnea. Adv. Sci. Lett. 2018, 24, 1680–1684. [Google Scholar] [CrossRef]
- Wu, D.; Liu, S.; Zhang, L.; Terpenny, J.; Gao, R.X.; Kurfess, T.; Guzzo, J.A. A fog computing-based framework for process monitoring and prognosis in cyber-manufacturing. J. Manuf. Syst. 2017, 43, 25–34. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Year | Description |
|---|---|
| 2016 | Gilchrist et al. presented IIoT potential applications, including data mining, predictive analytics, statistical approaches, and other application opportunities, to increase manufacturing productivity and efficiency [15]. |
| 2016 | Qin et al. implemented the Industry 4.0 framework with a multilayered framework and demonstrated how such an approach affects current manufacturing systems [16]. |
| 2017 | Jeschke et al. introduced future trends of cyber manufacturing systems and IIoT in Industry 4.0 [17]. |
| 2015 | Rose et al. reported that Industry 4.0 significantly affects corporate strategies and competition in many industries [18]. |
| 2017 | Thoben et al. provided an overview of smart manufacturing and Industry 4.0 and programs and analyzed the application potential of cyber–physical systems starting from the production process [19]. |
| 2017 | Chen et al. proposed the hierarchical architecture of a smart factory with three layers and discussed the significant problems and potential solutions to vital emerging technologies [20]. |
| 2018 | Tao et al. discussed that big data play a vital role in supporting smart manufacturing and proposed the conceptual framework for big data analytics [21]. |
| 2018 | Sisinni et al. highlighted the opportunities created by the challenges and potential of IIoT [22]. |
| 2016 | Bahrin et al. investigated the disciplinary distribution of emerging Industry 4.0-related topics [23]. |
| 2017 | Wan et al. proposed a big data solution for active preventive analytics in the manufacturing industry [24]. |
| 2019 | Frank et al. confirmed that Industry 4.0 is associated with front-end technologies, which comprise four parts: smart supply chain, smart working, smart manufacturing, and smart products [25]. |
| 2015 | Derhamy et al. introduced IoT development; IoT-related technologies are enabled to connect massive cyber–physical systems [26]. |
| 2018 | Ghobakhloo et al. surveyed current research on Industry 4.0 and provided a simple guide for the process of Industry 4.0 transition [27]. |
| 2016 | Arnold et al. surveyed the effect of IIoT on the current business model [28]. |
| 2017 | Li et al. provided a systemic overview of the industrial internet. They focused on applications, technologies, and existing challenges [29]. |
| 2017 | Mumtaz et al. referred to the standardization and development of cyber connectivity applications to achieve the goal of IIoT implementation [30]. |
| 2019 | Ben-Daya et al. surveyed the literature concerned with how IoT impacts supply chain management [31]. |
| 2017 | Ehret et al. argued that IIoT provides prospects and emerging business models for enterprises [32]. |
| 2017 | Civerchia et al. introduced the advanced IoT (IIoT) application and proposed a monitoring system for predictive maintenance manufacturing [33]. |
| 2017 | Maple et al. introduced the development of IoT, IoT-related definitions, and IoT-related application areas [34]. |
| Predictive Maintenance Target | Manufacturing Type | Description | Instances |
|---|---|---|---|
| The yield of the manufacturing process | Semiconductor manufacturing process | The data have 591 features containing methods, classifications, and time stamps for each instance. | 1567 |
| Packing quality of the product | Blister packing machine | The data have six attributes: heating time on the left side, heating time on the right side, coding time, pressure, and the packaging card type, and the packing cover type. | 17,836 |
| AUC Range | Level of Discrimination |
|---|---|
| AUC = 0.5 | no discrimination |
| 0.7 ≤ AUC ≤ 0.8 | acceptable discrimination |
| 0.8 ≤ AUC ≤ 0.9 | excellent discrimination |
| 0.9 ≤ AUC ≤ 1.0 | outstanding discrimination |
| Semiconductor Case | Blister Packing Machine Case | |
|---|---|---|
| Predictive Problem | The yield failure in the semiconductor manufacturing process. | The quality of scissor product packaging in the blister packing machining process. |
| Type | Ensemble | Single | ||
|---|---|---|---|---|
| Algorithms | The Proposed Method | Boosted Decision tree | Decision Jungle | Decision Tree |
| Accuracy | 0.974 | 0.966 | 0.941 | 0.952 |
| Recall rate | 0.957 | 0.945 | 0.925 | 0.928 |
| Type | Ensemble | Single | ||
|---|---|---|---|---|
| Algorithms | The Proposed Method | Boosted Decision tree | Decision Jungle | Decision Tree |
| Accuracy | 0.992 | 0.991 | 0.992 | 0.987 |
| Recall rate | 0.997 | 0.993 | 0.992 | 1 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hung, Y.-H. Improved Ensemble-Learning Algorithm for Predictive Maintenance in the Manufacturing Process. Appl. Sci. 2021, 11, 6832. https://doi.org/10.3390/app11156832
Hung Y-H. Improved Ensemble-Learning Algorithm for Predictive Maintenance in the Manufacturing Process. Applied Sciences. 2021; 11(15):6832. https://doi.org/10.3390/app11156832
Chicago/Turabian StyleHung, Yu-Hsin. 2021. "Improved Ensemble-Learning Algorithm for Predictive Maintenance in the Manufacturing Process" Applied Sciences 11, no. 15: 6832. https://doi.org/10.3390/app11156832
APA StyleHung, Y.-H. (2021). Improved Ensemble-Learning Algorithm for Predictive Maintenance in the Manufacturing Process. Applied Sciences, 11(15), 6832. https://doi.org/10.3390/app11156832