1. Introduction
Recent advances in automatic speech recognition (ASR) have made this technology a potential solution for transcribing audio input for computer-assisted pronunciation training (CAPT) tools [
1,
2]. Available ASR technology, properly adapted, might help human instructors with pronunciation assessment tasks, freeing them from hours of tedious work, allowing for the simultaneous and fast assessment of several students, and providing a form of assessment that is not affected by subjectivity, emotion, fatigue, or accidental lack of concentration [
3]. Thus, ASR systems can help in the assessment and feedback of learner production, reducing human costs [
4,
5]. Although most of the scarce empirical studies which include ASR technology in CAPT tools assess sentences in large portions of either reading or spontaneous speech [
6,
7], the assessment of words in isolation remains a substantial challenge [
8,
9].
General-purpose off-the-shelf ASR systems such as Google ASR (
https://cloud.google.com/speech-to-text, accessed on 27 June 2021) (gASR) are becoming progressively more popular each day due to their easy accessibility, scalability, and, most importantly, effectiveness [
10,
11]. These services provide accurate speech-to-text capabilities to companies and academics who might not have the possibility of training, developing, and maintaining a specific-purpose ASR system. However, despite the advantages of these systems (e.g., they are trained on large datasets and span different domains), there is an obvious need for improving their performance when used on in-domain data-specific scenarios, such as segmental approaches in CAPT for non-native speakers. Concerning the existing ASR toolkits, Kaldi has shown its leading role in recent years, with its advantages of having flexible and modern code that is easy to understand, modify, and extend [
12], becoming a highly matured development tool for almost any language [
13,
14].
English is the most frequently addressed L2 in CAPT experiments [
6] and in commercial language learning applications, such as Duolingo (
https://www.duolingo.com/, accessed on 27 June 2021) or Babbel (
https://www.babbel.com/, accessed on 27 June 2021). However, there are scarce empirical experiments in the state-of-the-art which focus on pronunciation instruction and assessment for native Japanese learners of Spanish as a foreign language, and as far as we are concerned, no one has included ASR technology. For instance, 1440 utterances of Japanese learners of Spanish as a foreign language (A1–A2) were analyzed manually with Praat by phonetics experts in [
15]. Students performed different perception and production tasks with an instructor, and they achieved positive significant differences (at the segmental level) between the pre-test and post-test values. A pilot study on the perception of Spanish stress by Japanese learners of Spanish was reported in [
16]. Native and non-native participants listened to natural speech recorded by a native Spanish speaker and were asked to mark one of three possibilities (the same word with three stress variants) on an answer sheet. Non-native speech was manually transcribed with Praat by phonetic experts in [
17], in an attempt to establish rule-based strategies for labeling intermediate realizations, helping to detect both canonical and erroneous realizations in a potential error detection system. Different perception tasks were carried out in [
18]. It was reported how the speakers of native language (L1) Japanese tend to perceive Spanish /y/ when it is pronounced by native speakers of Spanish, and how the L1 Spanish and L1 Japanese listeners evaluate and accept various consonants as allophones of Spanish /y/, comparing both groups.
In previous work, we presented the development and the first pilot test of a CAPT application with ASR and text-to-speech (TTS) technology, Japañol, through a training protocol [
19,
20]. This learning application for smart devices includes a specific exposure–perception–production cycle of training activities with minimal pairs, which are presented to students in lessons on the most difficult Spanish constructs for native Japanese speakers. We were able to empirically measure a statistically significant improvement between the pre and post-test values of eight native Japanese speakers in a single experimental group. The students’ utterances were assessed by experts in phonetics and by the gASR system, obtaining strong correlations between human and machine values. After this first pilot test, we wanted to take a step further and to find pronunciation mistakes associated with key features of the proficiency-level characterization of more participants (33) and different groups (3). However, assessing such a quantity of utterances by human raters can lead to problems regarding time and resources. Furthermore, the gASR pricing policy and its limited black-box functionalities also motivated us to look for alternatives to assess all the utterances, developing a specific ASR system for Spanish from scratch, using Kaldi (kASR). In this work, we analyze the audio utterances of the pre-test and post-test of 33 Japanese learners of Spanish as a foreign language with two different ASR systems (gASR and kASR) to address the research question of how these general and specific-purpose ASR systems compare in the assessment of short isolated words used as challenges in a learning application for CAPT.
This paper is organized as follows. The experimental procedure is described in
Section 2, which includes the participants and protocol definition, a description of the CAPT tool, a brief description of the process for elaborating the kASR system, and the collection of metrics and instruments for collecting the necessary data.
Section 3 presents, on one hand, the results of the training of the users that worked with the CAPT tool and, on the other hand, the performance of the two versions of the ASR systems: the word error rate (WER) values of the kASR system developed, the pronunciation assessment of the participants at the beginning and at the end of the experiment, including intra- and inter-group differences, and the ASR scores’ correlation of both ASR systems. Then, we discuss the user interaction with the CAPT tool, the performance of both state-of-the-art ASR systems in CAPT, and we shed light on lines of future work. Finally, we end this paper with the main conclusions.
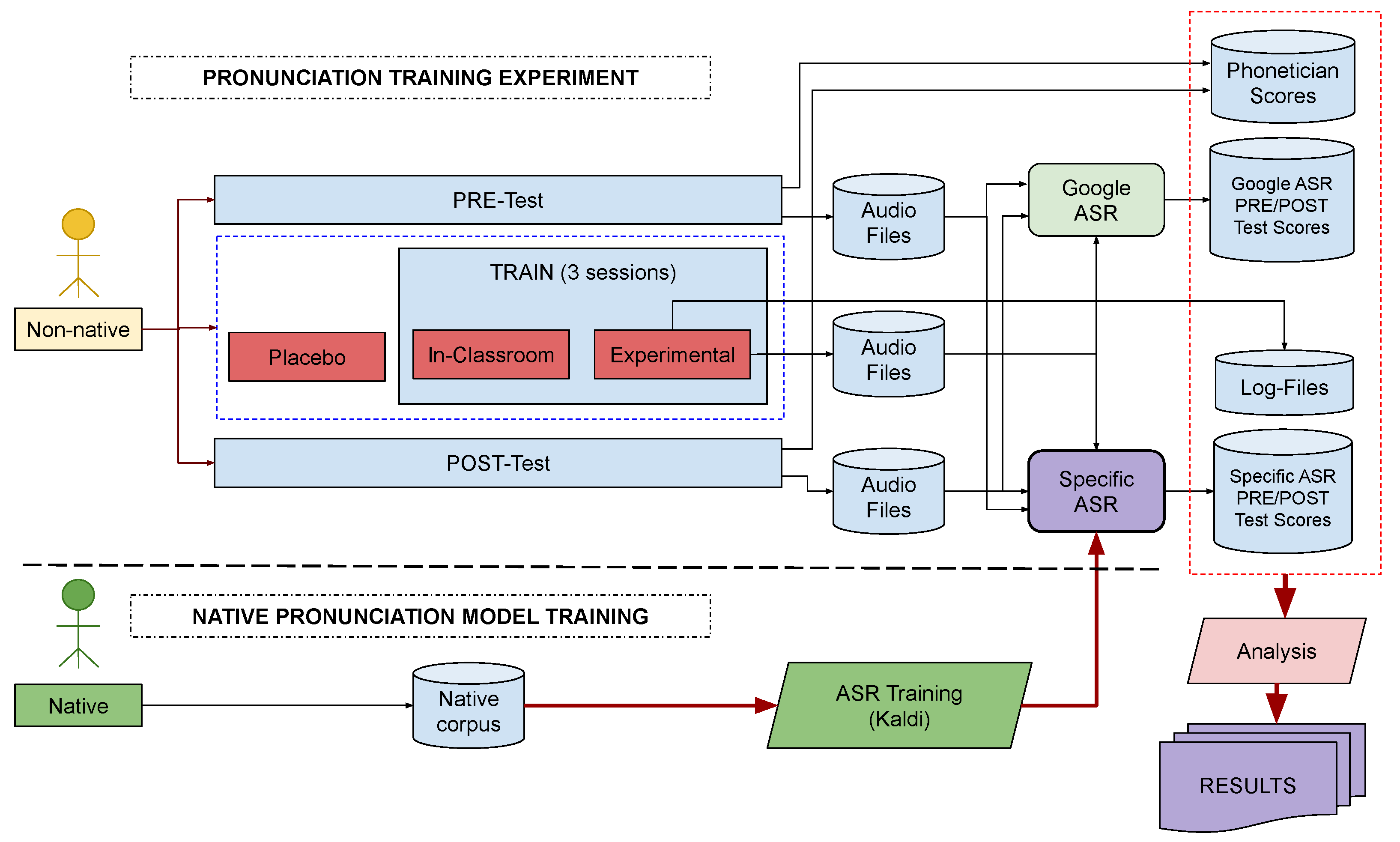
2. Experimental Procedure
Figure 1 shows the experimental procedure followed in this work. At the bottom, we see that a set of recordings of native speakers is used to train a kASR of Spanish words. On the upper part of the diagram, we see that a group of non-native speakers are evaluated in pre/post-tests in order to measure improvements after training. Speakers are separated into three different groups (placebo, in-classroom, and experimental) to compare different conditions. Both the utterances of the pre/post-tests and the interactions with the software tool (experimental group) are recorded, so that a corpus of non-native speech is collected. The non-native audio files are then evaluated with both the gASR and the kASR systems, so that the students’ performance during training can be analyzed.
The whole procedure can be compared with the one used in previous experiments [
19,
20] where human-based scores (provided by expert phoneticians) were used.
Section 2.1 describes the set of informants that participated in the evaluation and audio recordings.
Section 2.2 describes the protocol of the training sessions, including details of the pre- and post-tests.
Section 2.5 shows the training of the kASR system.
Section 2.6 presents the instruments and metrics used for the evaluation of the experiment.
2.1. Participants
A total of 33 native Japanese speakers aged between 18 and 26 years participated voluntarily in the evaluation of the experimental prototype. Participants came from two different locations: 8 students (5 female, 3 male) were registered in a Spanish intensive course provided at the Language Center of the University of Valladolid and had recently arrived in Spain from Japan in order to start the L2 Spanish course; the remainder comprised 25 female students of the Spanish philology degree from the University of Seisen, Japan. The results of the first location (Valladolid) allowed us to verify that there were no particularly differentiating aspects in the results analyzed by gender [
19]. Therefore, we did not expect the fact that all participants were female in the location to have a significant impact on the results. All of them declared a low level of Spanish as a foreign language, with no previous training in Spanish phonetics. None of them had stayed in any Spanish speaking country for more than 3 months. Furthermore, they were requested not to complete any extra work in Spanish (e.g., conversation exchanges with natives or extra phonetics research) while the experiment was still active.
Participants were randomly divided into three groups: (1) experimental group, 18 students (15 female, 3 male) who trained their Spanish pronunciation with Japañol, during three sessions of 60 min; (2) in-classroom group, 8 female students who attended three 60 min pronunciation teaching sessions within the Spanish course, with their usual instructor, making no use of any computer-assisted interactive tools; and (3) placebo group, 7 female students who only took the pre-test and post-test. They attended neither the classroom nor the laboratory for Spanish phonetics instruction.
2.2. Protocol Description
We followed a four-week protocol which included a pre-test, three training sessions, and a post-test for the non-native participants (see
Appendix A to see the content of the tests). Native speakers recorded the speech training corpus for the kASR system. At the beginning, the non-native subjects took part in the pre-test session individually in a quiet testing room. The utterances were recorded with a microphone and an audio recorder (the procedure was the same for the post-test). All the students took the pre-test under the sole supervision of a member of the research team. They were asked to read aloud the 28 minimal pairs administered via a sheet of paper with no time limitation (
https://github.com/eca-simm/minimal-pairs-japanol-eses-jpjp, accessed on 27 June 2021). The pairs came from 7 contrasts containing Spanish consonant sounds considered the most difficult to perceive and produce by native Japanese speakers (see more details in [
19]): [θ]–[f], [θ]–[s], [fu]–[xu], [l]–[ɾ], [l]–[r], [ɾ]–[rr], and [fl]–[fɾ]. Students were free to repeat each contrast as many times as they wished if they thought they might have mispronounced them.
From the same 7 contrasts, a total of 84 minimal pairs (
https://github.com/eca-simm/minimal-pairs-japanol-eses-jpjp, accessed on 27 June 2021) were presented to the experimental and in-classroom group participants in 7 lessons across three training sessions. The minimal pairs were carefully selected by experts considering the gASR limitations (homophones, word-frequency, very short words, and out-of-context words, in a similar process as in [
8]). The lessons were included in the CAPT tool for the experimental group and during the class sessions for the in-classroom group (12 minimal pairs per lesson, 2 lessons per session, except for the last session that included 3 lessons; see more details about the training activities in [
19]). The training protocol sessions were carried out during students’ course lectures in the classroom, in which a minimal pair was practiced in each lesson (blocked practice) and most phonemes were practiced again in later sessions (spaced practice). Regarding the sounds practiced in each session, in the first one, sounds [fu]–[xu] and [l]–[ɾ] were contrasted, then [l]–[r] and [ɾ]–[rr], and the last session involved the sounds [fl]–[fɾ], [θ]–[f], and [θ]–[s]. Finally, subjects of the placebo group did not participate in the training sessions. They were supposed to take the pre-test and post-test and obtain results without significant differences. All participants were awarded with a diploma and a reward after completing all stages of the experiment.
2.3. Description of the CAPT Mobile Application
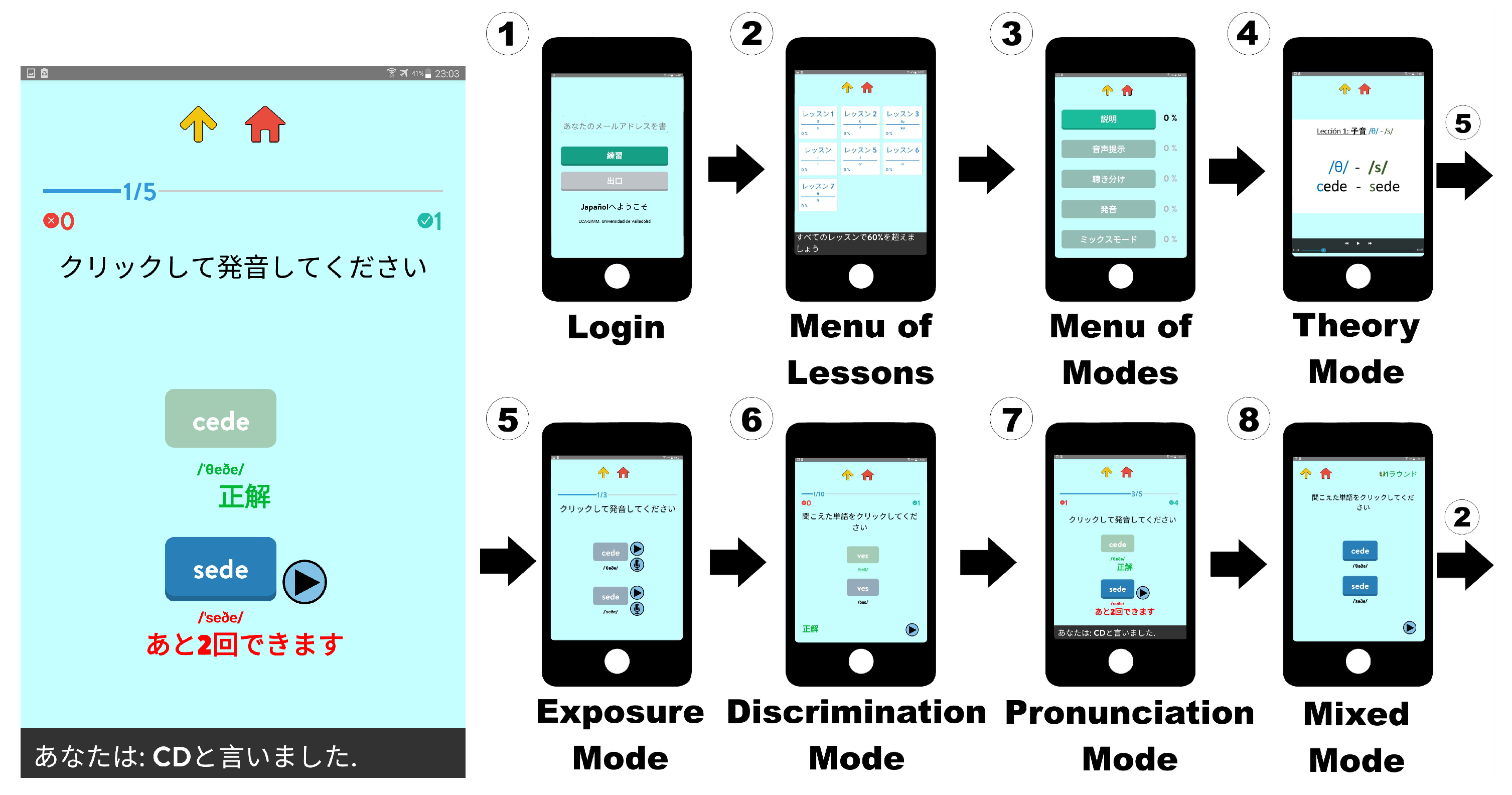
To carry out all the experiments, we built a mobile app, Japañol, starting from a previous prototype app designed for self-directed training of English as an L2 [
8].
Figure 2 shows the regular sequence of steps to complete a lesson in Japañol. After user authentication in (step 1), seven lessons are presented at the main menu of the application (step 2). Each lesson includes a pair of Spanish sound contrasts and users achieve a particular score, expressed as a percentage. Lessons are divided into five main training modes, Theory, Exposure, Discrimination, Pronunciation, and Mixed Modes (step 3), in which each one proposes several task types with a fixed number of mandatory task tokens. The final lesson score is the mean score of the last three modes. Users are guided by the system in order to complete all training modes of a lesson. When reaching a score below 60% in Discrimination, Pronunciation, or Mixed Modes, users are recommended to return to Exposure mode as a feedback resource and then return to the failed mode. Moreover, the next lesson is enabled when users reach a minimum score of 60%.
The first training mode is Theory (step 4). A brief and simple video describing the target contrast of the lesson is presented to the user as the first contact with feedback. At the end of the video, the next mode becomes available, but users may choose to review the material as many times as they want. Exposure (step 5) is the second mode. Users strengthen the lesson contrast experience previously introduced in Theory mode, in order to support their assimilation. Three minimal pairs are displayed to the user. In each one of them, both words are synthetically produced by Google TTS five times (highlighting the current word), alternately and slowly. After this, users must record themselves at least one time per word and listen to their own and the system’s sound. Words are represented with their orthographic and phonemic forms. A replay button allows users to listen to the specified word again. Synthetic output is produced by Google’s offline Text-To-Speech tool for Android. After all previous required events per minimal pair (listen-record-compare), participants are allowed to remain in this mode for as long as they wish, listening, recording, and comparing at will, before returning to the Modes menu. Step 6 refers to Discrimination mode, in which ten minimal pairs are presented to the user consecutively. In each one of them, one of the words is synthetically produced, randomly. The challenge of this mode consists of identifying which word is produced. As feedback elements, words have their orthographic and phonetic transcription representations. Users can also request to listen to the target word again with a replay button. Speed varies alternately between slow and normal speed rates. Finally, the system changes the word color to green (success) or red (failure) with a chime sound. Pronunciation is the fourth mode (step 7), whose aim is to produce, as well as possible, both words, separately, of the five minimal pairs presented with their phonetic transcription. gASR determines automatically and in real time acceptable or non-acceptable inputs. In each production attempt, the tool displays a text message with the recognized speech, plays a right/wrong sound, and changes the word’s color to green or red. The maximum number of attempts per word is five in order not to discourage users. However, after three consecutive failures, the system offers to the user the possibility of requesting a word synthesis as an explicit feedback as many times as they want with a replay button. Mixed mode is the last mode of each lesson (step 8). Nine production and perception tasks alternate at random in order to further consolidate the obtained skills and knowledge. Regarding listening tasks with the TTS, mandatory listenings are those which are associated with mandatory activities with the tool and non-mandatory listenings are those which are freely undertaken by the user whenever she has doubts about the pronunciation of a given word.
2.4. Native Corpus Preparation
A group of 10 native Spanish speakers from the theater company Pie Izquierdo of Valladolid (5 women and 5 men) participated in the recording of a total of 41,000 utterances (7.1 h of speech data) for the training corpus of the kASR system for assessing the students’ utterances gathered during the experimentation.
Each one of the native speakers recorded individually 164 words (
https://github.com/eca-simm/minimal-pairs-japanol-eses-jpjp, accessed on 27 June 2021) 25 times, (41,000 utterances in total) presented randomly in five-hour sessions, for elaborating the training corpus for the kASR system. The average, minimum, maximum, and standard deviation of the word lengths were: 4.29, 2, 8, and 1.07, respectively. The phoneme frequency (%) was: [a]: 16.9, [o]: 11.3, [r]: 9.0, [e]: 7.8, [f]: 5.3, [s]: 5.0, [ɾ]: 4.8, [l]: 4.5, [t]: 3.6, [k]: 3.6, [u]: 3.2, [i]: 3.2, [θ]: 3.2, [n]: 2.8, [m]: 2.3, [ɣ]: 1.8, [j]: 1.4, [ð]: 1.5, [x]: 1.3, [b]: 1.3, [p]: 1.1, [d]: 1.1, [β]: 0.9, [w]: 0.9, [ŋ]: 0.7, [g]: 0.3, [ʤ]: 0.2, and [z]: 0.1.
The recording sessions were carried out in an anechoic chamber at the University of Valladolid with the help of a member of the ECA-SIMM research group. The machine configuration on which the kASR system was installed was CentOS 8 (64-bit operating system), Intel(R) Core(TM) i7-8700K CPU (12 cores) processor with 3.70 GHz.
2.5. Developing an ASR System with Kaldi
Until now, in our previous works, we have always used gASR for the automatic assessment of pre/post-tests as a complement to or replacement for subjective assessment. Since gASR works as a black-box and does not allow us to obtain details on the quality of each individual speech fragment, we decided to develop an in-house ASR system of our own using Kaldi (kASR). In this subsection, we present the ASR pipeline that we implemented for the kASR system and we provide details about its general architecture and specific parameters.
Our kASR system uses a standard context-dependent triphone system with a simple Gaussian Mixture Model–Hidden Markov Model (GMM–HMM) [
21], adapted from existing Kaldi recipes [
22]. Although recent studies report excellent outcomes from neural models with Kaldi [
23], we did not find relevant differences in preliminary runs due to, mainly, the small size of the training corpus (described in
Section 2.4). After collecting and preparing the speech data for training and testing, the first step is to extract acoustic features from the audio utterances and training monophone models. These features are Mel frequency cepstral coefficients (MFCCs) with per-speaker cepstral mean and variance statistics. Since Kaldi is based on a finite-state transducer-based framework to build language models from the raw text, we use the SRILM toolkit for building a 2-g language model [
24].
To train a model, monophone GMMs are first iteratively trained and used to generate a basic alignment. Triphone GMMs are then trained to take the surrounding phonetic context into account, in addition to clustering of triphones to combat sparsity. The triphone models are used to generate alignments, which are then used for learning acoustic feature transforms on a per-speaker basis in order to make them more suited to speakers in other datasets [
25]. In our case, we set 2000 total Gaussian components for the monophone training. Then, we realigned and retrained these models four times (tri4) with 5 states per HMM. In particular, in the first triphone pass, we used MFCCs, delta, and delta–delta features (2500 leaves and 15,000 Gaussian components); in the second triphone pass, we included linear discriminant analysis (LDA) and Maximum Likelihood Linear Transform (MLLT) with 3500 leaves and 20,000 Gaussian components; the third triphone pass combined LDA and MLLT with 4200 leaves and 40,000 Gaussian components, and the final step (tri4) included LDA, MLLT, and speaker adaptive training (SAT) with 5000 leaves and 50,000 Gaussian components. The language model was a bigram with 164 unique words (same probability) for the lexicon, 26 nonsilence phones, and the standard SIL and UNK phones.
2.6. Instruments and Metrics
We gathered data from five different sources: (1) a registration form with students’ demographic information, (2) pre-test utterances, (3) log files, (4) utterances of users’ interactions with Japañol, and (5) post-test utterances. Personal information included name, age, gender, L1, academic level, and final consent to analyze all gathered data. Log files gathered all low-level interaction events with the CAPT tool and monitored all user activities with timestamps. From these files, we computed a CAPT score per speaker which refers to the final performance at the end of the experiment. It includes the number of correct answers in both perception and production (in which we used gASR) tasks while training with Japañol [
19]. Pre/post-test utterances consisted in oral productions of the minimal pairs lists provided to the students.
A set of experimental variables was computed: (1) WER values of the train/test set models for the specific-purpose kASR system developed in a [0, 100] scale; (2) the student’s pronunciation improvement at the segmental level comparing the difference between the number of correct words at the beginning (pre-test) and at the end (post-test) of the experiment in a [0, 10] scale. We used this scale for helping teachers to understand the score as they use it in the course’s exams. This value consists of the mean of correct productions in relation to the total number of utterances. Finally, we used (3) the correlation values between gASR and kASR systems of the pre/post-test utterances and between the CAPT score and both ASR systems at the end of the experiment (post-test) in a [0, 1] scale.
By way of statistical metrics and indexes, Wilcoxon signed-rank tests were used to compare the differences between the pre/post-test utterances of each group (intra-group), Mann–Whitney U tests were used to compare the differences between the groups (inter-group), and Pearson correlations were used to explain the statistical relationship between the values of the ASR systems and the final CAPT scores.
4. Discussion
Results showed that the Japañol CAPT tool led experimental group users to carry out a significantly large number of listening, perception, and pronunciation exercises (
Table 1). With an effective and objectively registered 57% of the total time, per participant, devoted to training (102.2 min out of 180), high training intensity was confirmed in the experimental group. Each one of the subjects in the CAPT group listened to an average of 612.5 synthesized utterances and produced an average of 291.4 word utterances, which were immediately identified, triggering, when needed, automatic feedback. This intensity of training (hardly obtainable within a conventional classroom) implied a significant level of time investment in tasks, which might establish a relevant factor in explaining the larger gain mediated by Japañol.
Results also suggested that discrimination and production skills were asymmetrically interrelated. Subjects were usually better at discrimination than production (8.5 vs. 10.1 tries per user, see
Table 1, #Tries row). Participants consistently resorted to the TTS when faced with difficulties both in perception and production modes (
Table 1, #Req.List. row; and
Table 2 and
Table 3, #Lis column). While a good production level seemed to be preceded by a good performance in discrimination, a good perception attempt did not guarantee an equally good production. Thus, the system was sensitive to the expected difficulty of each type of task.
Table 2 and
Table 3 identified the most difficult phonemes for users while training with Japañol. Users encountered more difficulties in activities related to production. In particular, Japanese learners of Spanish have difficulty with [f] in the onset cluster position in both perception (
Table 2) and production (
Table 3) [
27]. [s]–[θ] present similar results: speakers tended to substitute [θ] by [s], but this pronunciation is accepted in Latin American Spanish [
28]. Japanese speakers are also more successful at phonetically producing [l] and [ɾ] than discriminating these phonemes [
29]. Japanese speakers have already acquired these sounds since they are allophones of the same liquid phoneme in Japanese. For this reason, it does not seem to be necessary to distinguish them in Japanese (unlike in Spanish).
Regarding the pre/post-test results, we have reported on empirical evidence about the significant pronunciation improvement at the segmental level of the native Japanese beginner-level speakers of Spanish after training with the Japañol CAPT tool (
Table 5). In particular, we used two state-of-the-art ASR systems to assess the pre/post-test values. The experimental and in-classroom group speakers improved 0.7|1.1 and 0.6|0.9 points out of 10, assessed by gASR|kASR systems, respectively, after just three one-hour training sessions. These results agreed with previous works which follow a similar methodology [
8,
30]. Thus, the training protocol and the technology included, such as the CAPT tool and the ASR systems, provided a very useful and didactic instrument that can be used complementary with other forms of second language acquisition in larger and more ambitious language learning projects.
Our specific-purpose kASR system allowed us to reliably measure the pronunciation quality of the substantial quantity of utterances recorded after testing different training models (
Table 4). In particular, this ASR system proved to be useful for working at the segmental (phone) level for non-native speakers. We followed standard preparation procedures for the models, restricted to closed small vocabulary tasks, where the words were selected according to minimal pairs trained with our tool. In this way, what is novel is the fact that we started from a native pronunciation model and transferred it directly to Japanese speakers. Developing an in-house ASR system allowed us not only to customize the post-analysis of the speech without the black-box and pricing limitations of the general-purpose gASR system, but also to neither pre-discard specific words (e.g., out-of-context, infrequent, and very short words) nor worry about the data privacy and preparation costs. Moreover, future research studies might follow the same procedure to develop a similar ASR system for minimal pairs focusing on specific sounds. Despite the positive results reported about the kASR, the training corpus was limited in both quantity and variety of words and the experiment was carried out under a controlled environment. Data augmentation, noise reduction, and a systematic study of the non-native speech data gathered to find pronunciation mistakes associated with key features of proficiency-level characterization with the help of experts for its automatic characterization [
4,
17] must be considered in the future to expand the project.
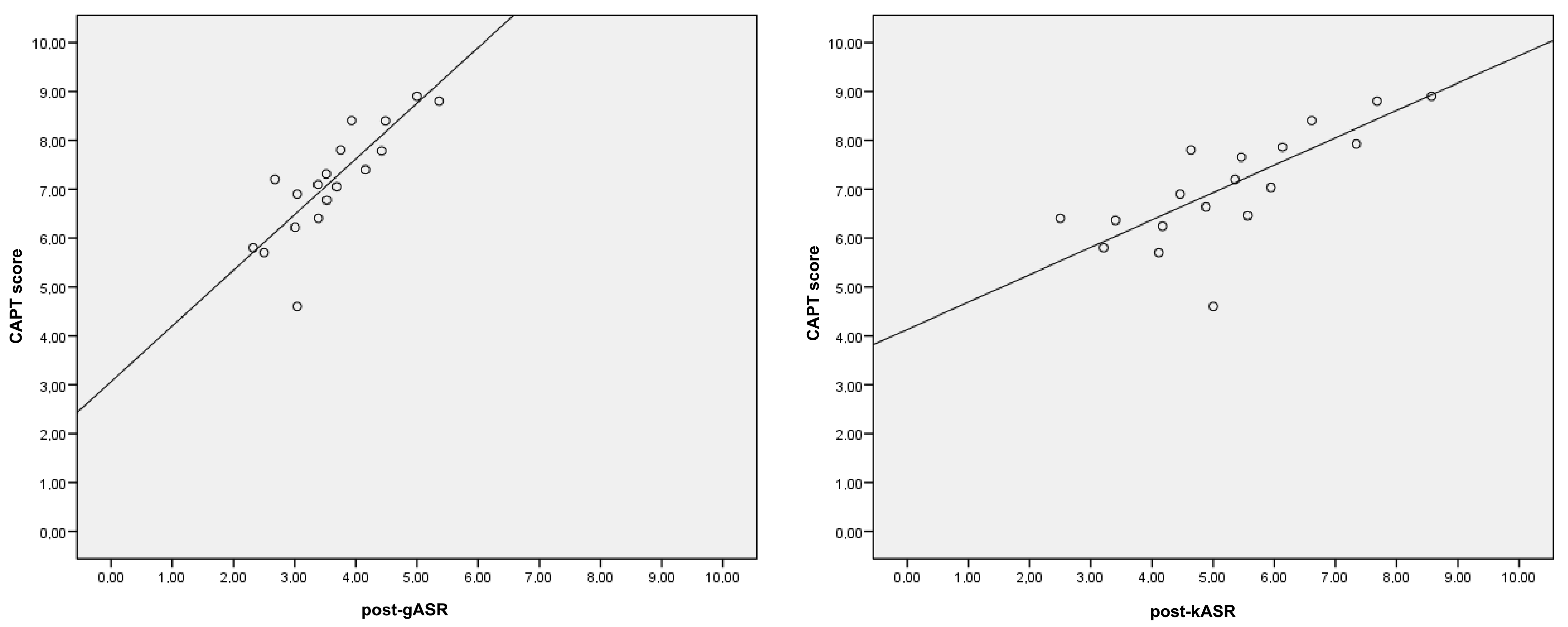
Finally, we compared the scores provided by kASR to the gASR ones, obtaining moderate positive correlations between them (
Table 7 and
Figure 3). The post-test values of both gASR and kASR systems also strongly correlated with the final scores provided by the CAPT tool of the experimental group speakers (
Table 7 and
Figure 4). In other words, although the training words in Japañol were not the same as the pre/post-test ones, the phonemes trained were actually the same and the speakers were able to assimilate the lessons learned from the training sessions to the final post-test. Therefore, we were able to ensure that both scoring alternatives are valid and can be used for assessing Spanish minimal pairs for certain phonemes and contexts (e.g., availability of resources, learning, place, data privacy, or costs), even though our specific-purpose ASR system is not as accurate as gASR (30.0% vs. 44.22% WER values,
Table 4). Future work will consist of fine-tuning our kASR system with more speech data and retraining techniques, such as deep or recurrent neural networks, combining both native and non-native speech in order to improve the current results and to obtain a better customization of the ASR system to the specific phoneme-level tasks. Thus, researchers, scholars, and developers can decide which one to integrate into their CAPT tools depending on the tasks and resources available.
5. Conclusions
The Japañol CAPT tool allows L1 Japanese students to practice Spanish pronunciation of certain pairs of phonemes, achieving improvements comparable with the ones obtained in in-classroom activities. The use of minimal pairs permits us to objectively identify the most difficult phonemes to be pronounced by initial-level students of Spanish. Thus, we believe it is worth taking into account when thinking about possible teaching complements since it promotes a high level of training intensity and a corresponding increase in learning.
We have presented the development of a specific-purpose ASR system that is specialized in the recognition of single words of Spanish minimal pairs. Results show that the performance of this new ASR system is comparable with that obtained with the general ASR gASR system. The advantage is not only that the new ASR permits substitution of the commercial system, but also that it will permit us in future applications to obtain information about the pronunciation quality at the level of phoneme.
We have seen that ASR systems can help in the costly intervention of human teachers in the evaluation of L2 learners’ pronunciation in pre/post-tests. It is our future challenge to provide information about the personal and recurrent mistakes of speakers that occur at the phoneme level while training.






{kind=link}
{kind=link}
{kind=link}
{kind=link}






