1. Introduction
Data centers play a pivotal role in this age of big data. As more applications depend on data-intensive technologies, such as artificial intelligence, bioinformatics, and data analytics, the demand for data centers continues to increase. Despite this increase in popularity, the energy use per computation in data centers has decreased significantly over the past decade. This promising shift stems from the energy efficiency progress that has been made during this time. Virtualization technologies have led to a large reduction in energy use by reducing the number of servers operating in data centers [
1], and advanced power management schemes for processors have contributed to less energy per computation [
2]. Nevertheless, energy efficiency continues to be important for data centers; in the U.S., the electricity used by data centers accounted for 1.3% of worldwide energy production in 2010, and these centers generate more than 43 million tons of CO
emissions per year, equal to 2% of the worldwide figure. The data centers are also estimated to have consumed approximately 1% of worldwide energy use in 2020 [
2]. Given that data centers are energy-intensive and that the demand for their services continues to grow rapidly, additional optimization techniques are required at least to maintain the current flat increase trend in energy use [
3,
4,
5].
In line with above arguments, this paper takes advantage of an opportunity to reduce the energy used by data centers by perspicaciously applying the DVFS (Dynamic Voltage and Frequency Scaling) technique in distributed data systems. DVFS scales down the frequency and voltage of the processors when the performance constraints are not stringent, instilling a trade-off the performance and savings. State-of-the-art distributed data systems, such as Redis [
6], MongoDB [
7], Cassandra [
8], and Ceph [
9], typically provide a replication feature. By maintaining multiple copies of data with the data systems, they provide high reliability, good availability, and rapid responsiveness to end users.
Table 1.
Replication in distributed systems.
Table 1.
Replication in distributed systems.
| Data System | Number of Master | Number of Replica | Operation to Replica | Replication |
|---|
| Redis [6] | Single | Multiple | read | Async |
| Mongodb [7] | Single | Multiple | - | Async |
| HDFS [10] | Single | Multiple | read | Sync(1) Async(N-1) |
| Ceph [11] | Single | Multiple | - | Async |
| Cassandra [8] | Multiple | Multiple | read/write | Async |
| Dynamo [12] | Multiple | Multiple | read/write | Async |
Table 1 summarizes the replication model employed in popular distributed data systems. The most popular replication model is the single–master and multiple–replica model, while a few distributed data systems, such as Dynamo [
12] and Cassandra [
8], allow multiple masters, preferring high availability to data consistency. In the single–master and multiple–replica model, all writes go through a master; the master reflects data changes to its dataset first and then propagates these changes to multiple replicas asynchronously. This mechanism makes it easy to coordinate the concurrent writes occurring with regard to the data without violating the consistency requirement.
We focus on the fact that the performance requirements are disparate across the data nodes of the system due to its asymmetric structure with replication. For master instances, rapid processing capability is expected because these instances are synchronous with user requests. In contrast, replica instances have a relaxed performance requirement in terms of latency because they have little impact on the user-facing performance. This property presents a possibility to gain a benefit by sacrificing the performance up to tolerable limits.
Motivated by this observation, this paper presents a novel DVFS algorithm called
Concerto, which scales down the processor speed for replicas while having the processors in the master run at full speed. Modern processors manufactured by Intel, AMD, and ARM are equipped with the DVFS feature that enables the control of the processor speed within a certain range while using less power [
13,
14,
15]. When the data service nodes are deployed in distributed data systems,
Concerto sets the processor affinity separately for the master and the replica and throttles down the processor frequency for replicas. Considering that the number of replicas is typically twice more than the number of masters, CPU scaling down for replicas can lead to significant savings in power consumption.
Although
Concerto appears to be straightforward conceptually, implementing it in practical systems and making an effective use of it are not without challenges. As a case study, we integrated
Concerto into Redis, which is one of the most popular distributed in-memory NoSQL systems [
6], though, when doing this, we face two major challenges. First, scaling down the processor speed of the replicas undesirably impairs the read performance associated with the replicas. Modern distributed data systems generally allow data reads from replicas to ensure proper load balancing, short latency, and high availability. As read requests are synchronous with users, it is unavoidable for the user-perceived latency to increase under
Concerto. Second, the processing slowdown in replicas can increase the replication lag in distributed data systems. The replication lag refers to the time taken for the data changes of the master to be reflected in the replica. This synchronization delay aggravates the staleness of the replicas, leading to greater data losses in the failure of the master.
We overcome these challenges as follows. To avoid unintended delays in the read latency, Concerto decouples the read and write path in Redis and processes them separately at the different cores, specifically processing reads at the high frequency and writes at the low frequency. Redis is natively designed with a single thread, making it challenging to realize the concurrent execution of reads and writes with it. We achieve this goal by identifying the part that takes a long time but has no dependency with writes in the read path and then offloading it to a different thread running at high speed. This compromise is disadvantageous in terms of energy savings, but it can prevent performance problems when using Concerto. Second, with regard to the replication lag, our in-depth analysis reveals that the scaling down of the processor in the replica has little impact on the replication lag. The master, responsible for several jobs to maintain data over the distributed environment, such as data propagation and/or replica synchronization, takes longer to process a write request than the replica. This performance gap allows room for the replica to operate at the lower speed without increasing the risk of a data loss in a failure.
We implemented the
Concerto architecture in Redis 6.0.1. Performance evaluation with micro- and real-world benchmarks show that
Concerto reduces the energy consumption of data systems by 32% on average and up to 51%, with a performance penalty of 3% compared to when it is not used. The remainder of this paper is organized as follows.
Section 2 presents the background of this study, and
Section 3 briefly highlights the related work.
Section 4 details the design of
Concerto.
Section 5 evaluates
Concerto under various workloads, and
Section 6 discusses its applicability to different environments.
Section 7 concludes the paper.
4. Design of Concerto
In this section, we describe Concerto in detail. To reinforce the practical aspect of the proposed technique, we explain Concerto in the context of Redis in the form of a case study.
4.1. Overview
Concerto as presented here takes advantage of the fact that performance constraints are disparate across instances in distributed systems. Master instances have a great impact on user-perceived performance and, thus, necessitate high data processing capabilities. In contrast, as replica instances act as a substitute for the original corresponding dataset in a sudden failure of the master, they scarcely affect the user experience during normal operations. Based on this property, we present the novel DVFS policy called Concerto, which deliberately scales down the processor speed when they are used to process replicas. This policy can allow for energy savings with a minimal loss of performance.
The
Concerto power manager configures the kernel to use the
userspace governor to control the processor speed as the governor allows a user process to adjust the processor speed as needed. In our implementation, the power manager associates each instance with the specific core on deployment time and shares the information with them. When an instance starts running, it figures out whether it is a master or a replica in distributed data systems, and it sets the frequency of associated core accordingly by making use of the
sysfs interface. The
sysfs is the pseudo-file system interface provided by linux kernel to adjust the frequency of CPU. By writing the proper number into the virtual file (
cpufreq/scaling_mad_freq) internally linked with the processor frequency modulator, the user applications sets the processor speed as desired. Once the processor frequency is all set, the instance sets its CPU affinity to the corresponding core using the
sched_setaffinity library [
38]. By doing so,
Concerto executes the master for the core to run at full speed and the replica for the core to run at slow speed.
This architecture makes sense because modern processors typically have several cores and allow separate adjustments of the P-state levels for each core. In this study, the fast cores for the masters run at the full speed (2.20 GHz), while the cores assigned to the replicas are forcefully scaled down to a lower speed (1.0 GHz). The Concerto power manager automatically detects dynamic changes of the processor speed and resets the processor affinity of the data nodes as necessary.
4.2. Read Path Offloading
One primary intention for replication is to reduce the read latency. By servicing data from a node geographically close to the user, data systems can achieve low latency for reads. For this reason, most distributed data systems allow read operations to replicas, while granting writes only for the master. In Concerto, read queries sent to replicas can experience a performance penalty owing to the scaling down of the processor.
One possible approach by which to mitigate this shortcoming is by adaptive processor throttling. By temporarily increasing the processor speed for read operations, we can prevent the read latency from increasing due to DVFS. This mechanism has an advantage in that it can be applied to single-threaded data systems, such as Redis. However, changing the processor speed frequently for every read query imposes excessive overhead. It not only requires the software overhead to configure the speed through the virtual file system but also adds transition overhead when changing the CPU frequency. This cost outweighs the benefit of processing read queries at high speed.
Based on this observation, Concerto resolves this problem by separating the read and write paths and executing the read operation with a thread running at full speed. To this end, Concerto selectively scales down a subset of the cores and forces the read path to run on the fast-running core. However, realizing concurrent reads and writes in the single-threaded data systems comes at another cost. It significantly increases the code complexity required to resolve the conflict between the concurrent reads and writes. In addition, employing a weaker consistency model, such as snapshot isolation, is inevitable, leading to a decrease of the consistency level of the data system.
To strike a balance between the cost and benefit, we present a partial offloading scheme. This scheme processes the part that requires complex coordination between reads and writes using a single thread called
MainThread, while offloading the part that can be executed independently in the read path to another thread, called
ReadHandler. To this end, we investigate which part of the read path can be offloaded in Redis.
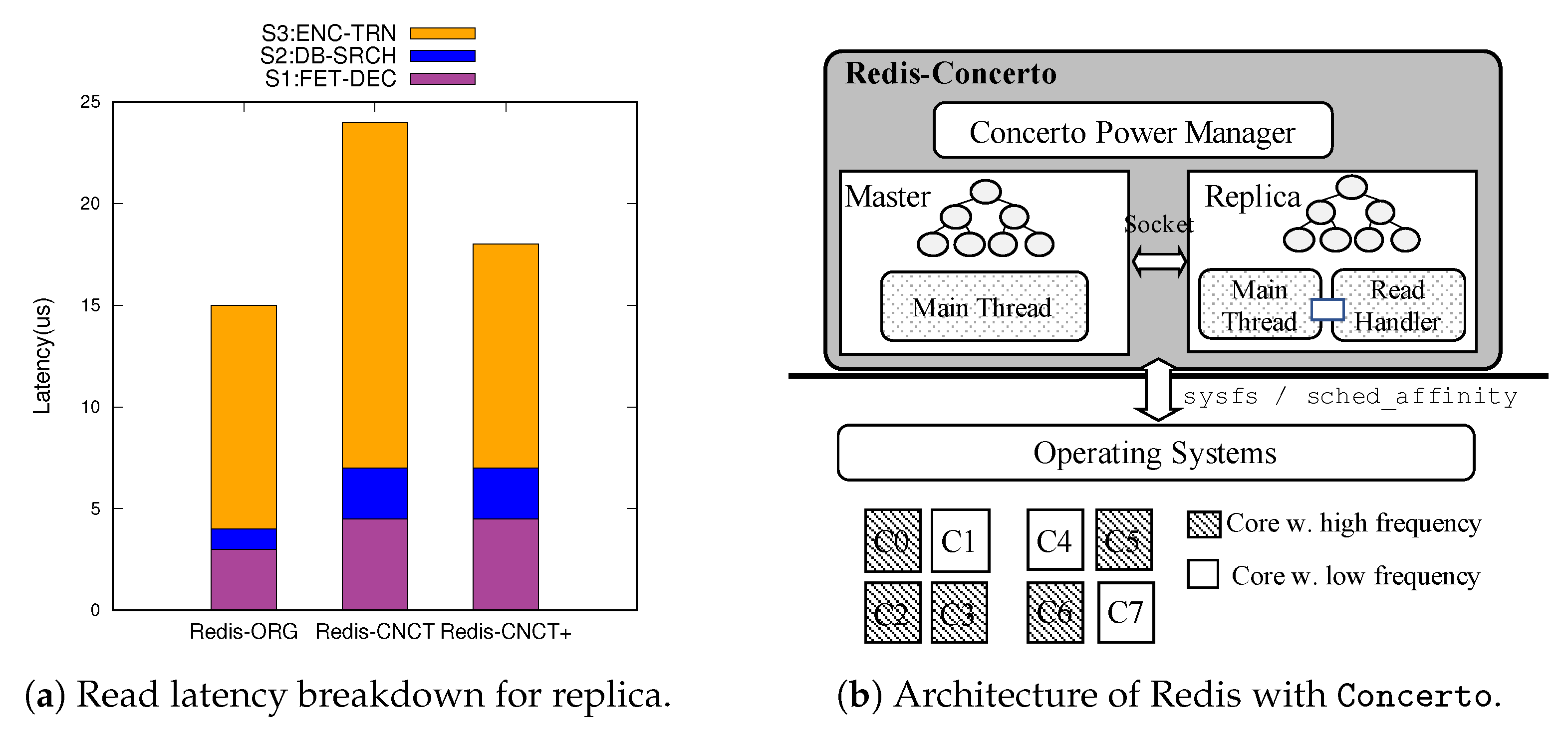
Figure 2a provides a breakdown of the read latency for the three steps of the request in Redis.
Redis-ORG and
Redis-CNCT show the read latency when executing the replica at a high frequency and at a low frequency, respectively. In the first step, Redis records the arrival of a request at the socket and fetches it from the kernel buffer, after which decoding takes place (S1:FET-DEC). If the request is distinguished as a read request, Redis searches the hash table using the given key to retrieve the address of the associated value (S2:DB-SRCH). Lastly, the retrieved value is encoded using the Redis protocol and transferred to the client over a socket communication (S3:ENC-TRN).
The first two steps are not appropriate for offloading. In the first step, Redis cannot determine the type of request. The second step requires access to the database, which is the critical section for concurrent reads and writes. In contrast, the last step can be offloaded because it has no dependency with other write operations. Although the value is updated during the
ReadHandler access step, Redis updates the value in an out-of-place manner; thus, there is no contention between threads to access the value. Moreover,
Figure 2a shows that the last step accounts for a large portion of the read latency and, thus, incurs the most significant delay when the processor scales down. Here, 67% of the delay occurs during the process of encoding and transferring the data. Based on this observation,
Concerto offloads it to
ReadHandler such that encoding and transferring value to the end user can be done at full speed. For a fluid execution of the read operation, we use a lock-free queue for inter-thread communication.
MainThread enqueues the request into the lock-free queue when the value is retrieved from database and wakes
ReadHandler to process it. Consequently, as shown in
Figure 2a, the increase in a read latency caused by the scaling down of the processor is reduced to one third with read-path offloading (
Redis-CNCT+).
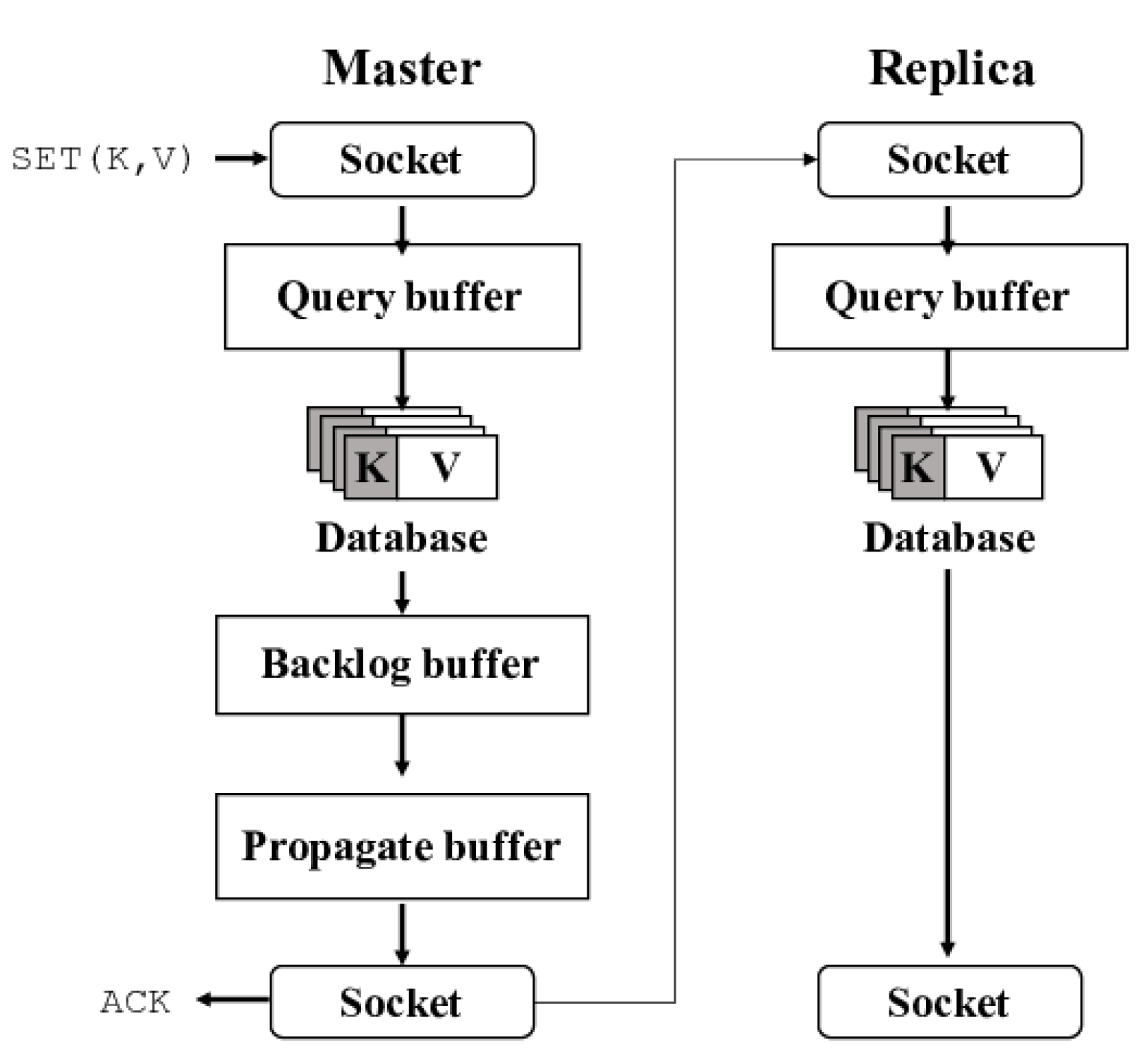
Figure 2b depicts the overall architecture of Redis with
Concerto.
4.3. Replication Lag Analysis
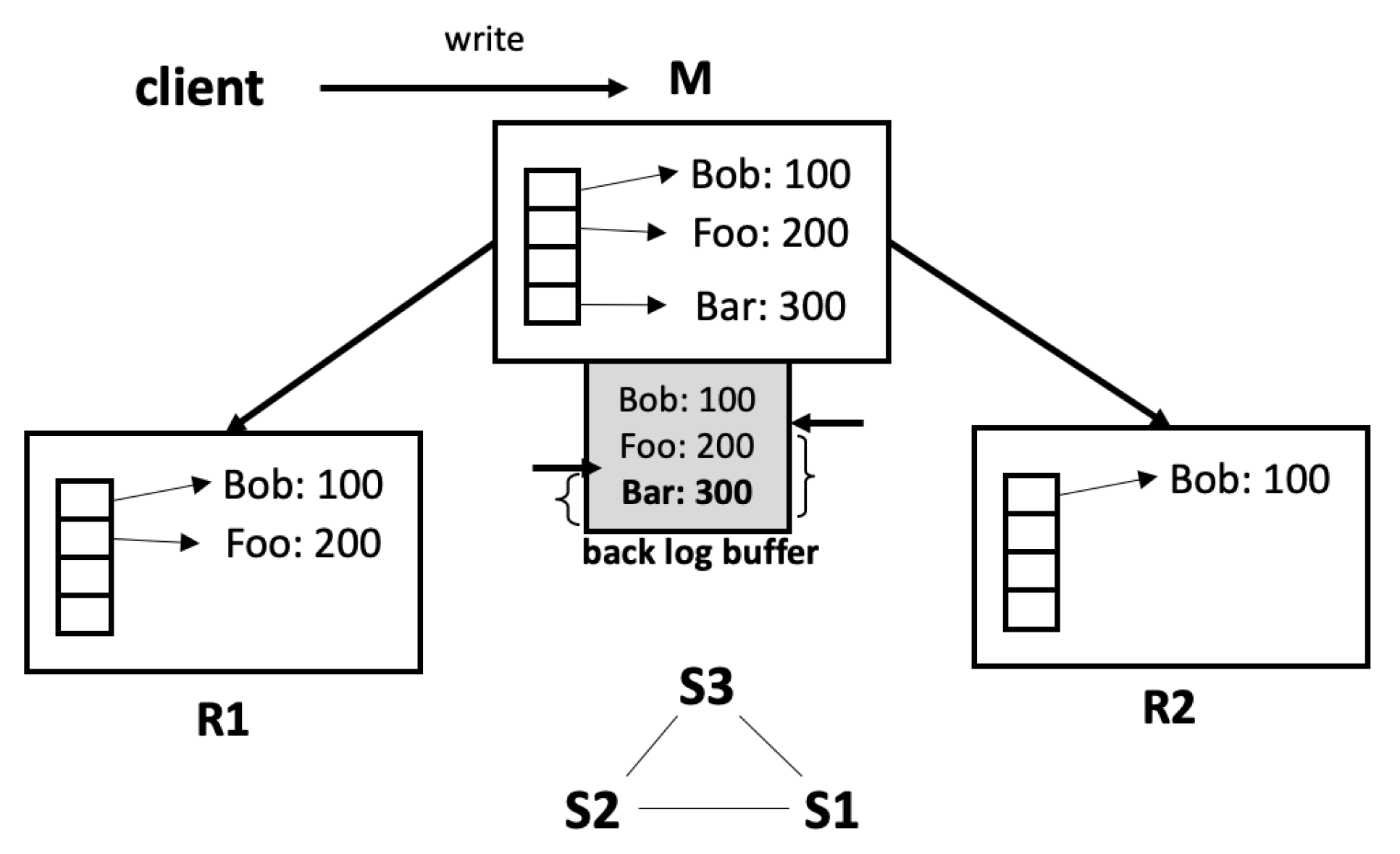
The replication lag refers to the delay between a write occurring to the master and being reflected on the replica. When the replica has long write latency, the replication lag inevitably increases, leading to the provision of more stale data in the replica and increasing the risk of data losses in the failure. In addition, a long replication lag indicates to the master that a problem occurs in data transmission, causing it to re-transmit data to the replicas. This is termed partial synchronization, and it unnecessarily increases both the master-node burden and the network traffic.
However, our experimental analysis shows that it is unlikely for the above situation to occur in practice.
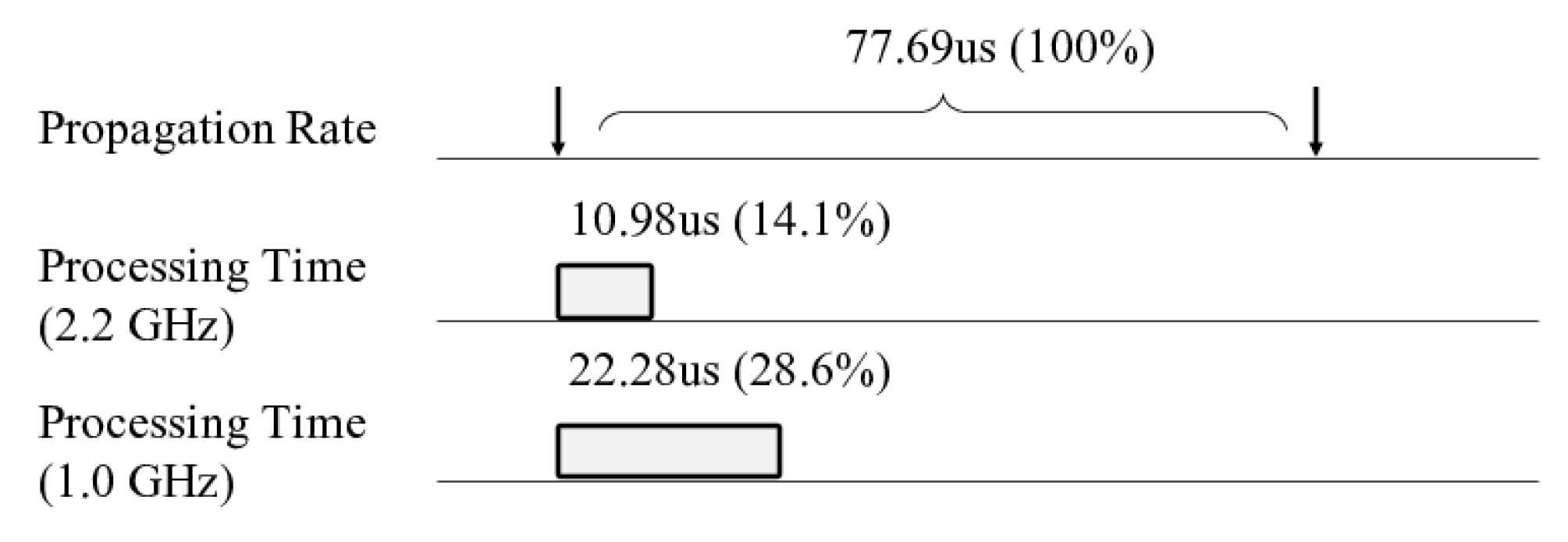
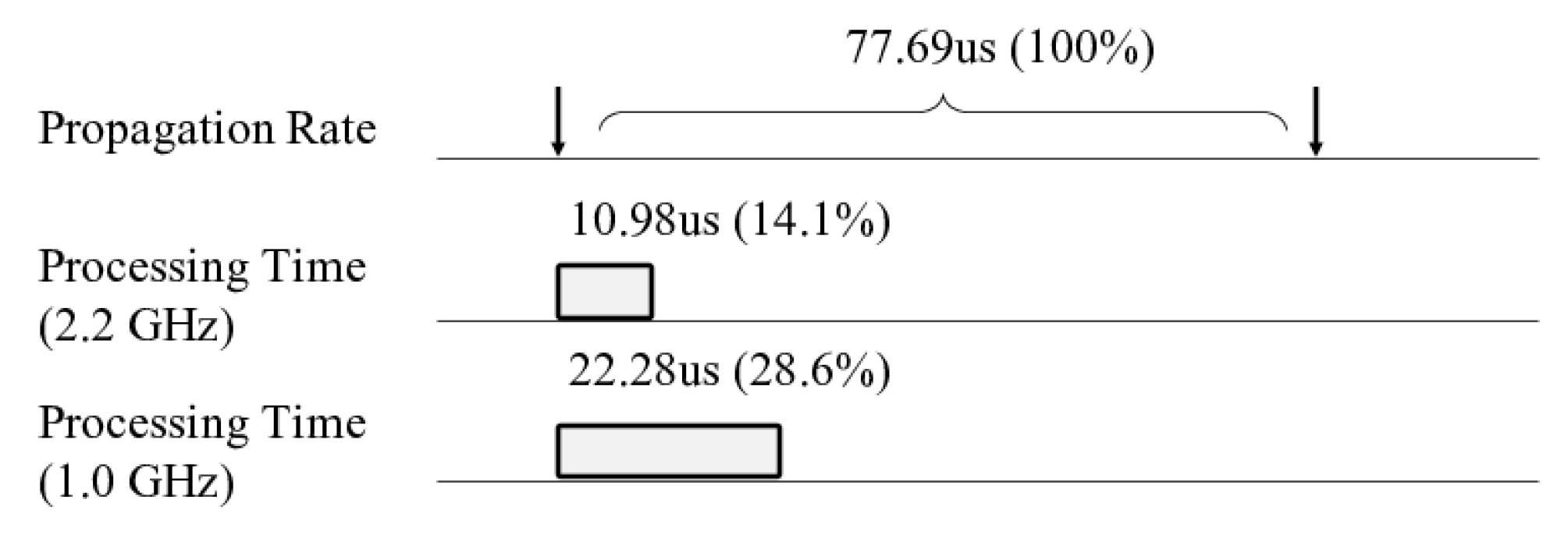
Figure 3 shows the propagation rate of the master and the data processing time in the replica with and without the scaling down of the processor. This result is obtained by measuring the duration of each component in Redis, running the memtier benchmark with one million
SET operations. Each operation has a 16 B key and a 1 KB value. We run Redis with a single master with two replicas. The numbers are the averages of the overall results. In the figure, we find that the processing speed of the replica greatly exceeds the propagation rate even when the processor scales down. The write request from the master arrives once every 77.69 us on average, while the corresponding processing time takes 10.98 us and 22.28 us on the replica when the processor runs at full speed and when it scales down, respectively. Because the master is responsible for more functions than the replica, such as responding to client and synchronizing replicas, it has much longer processing time per request than the replica.
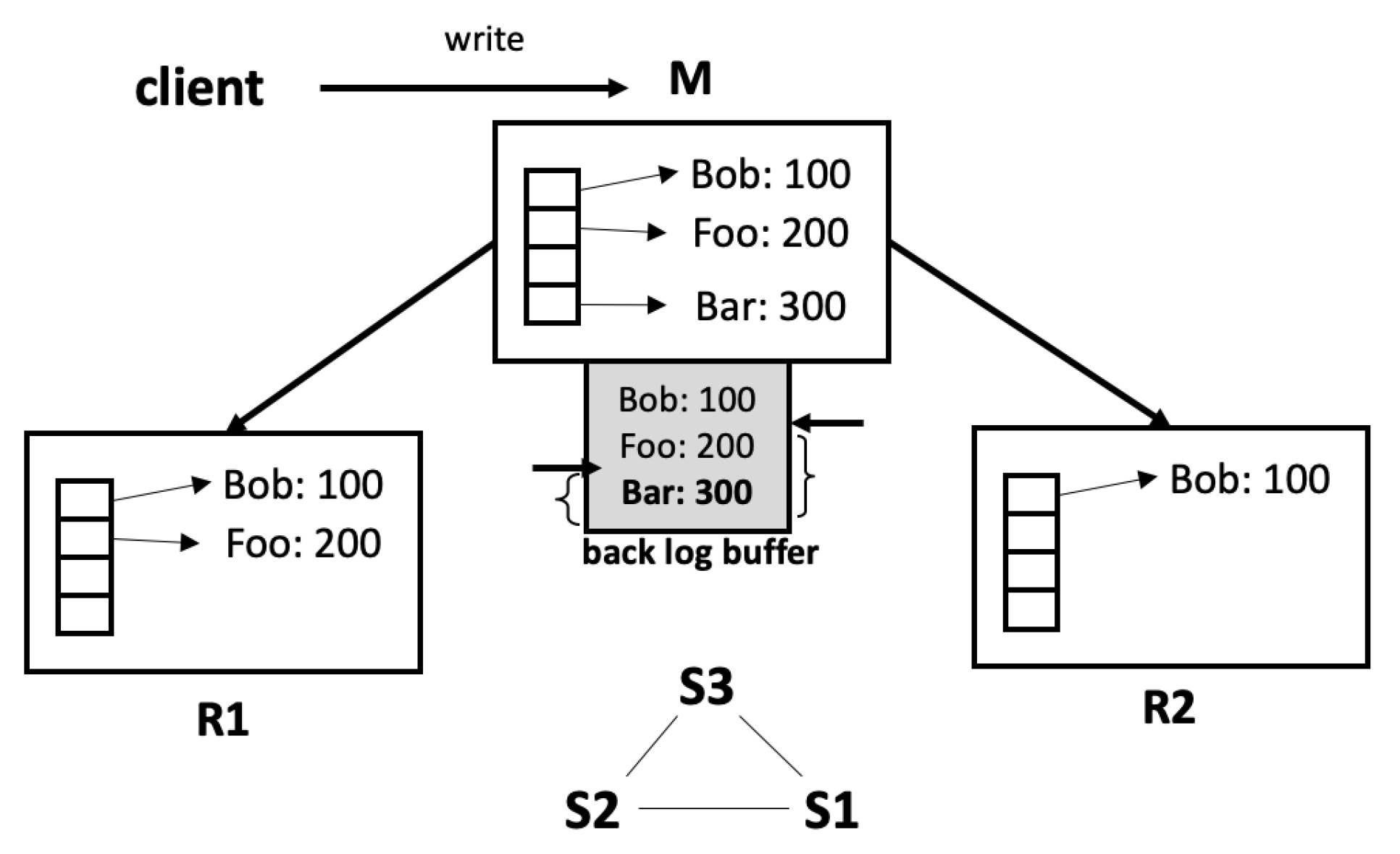
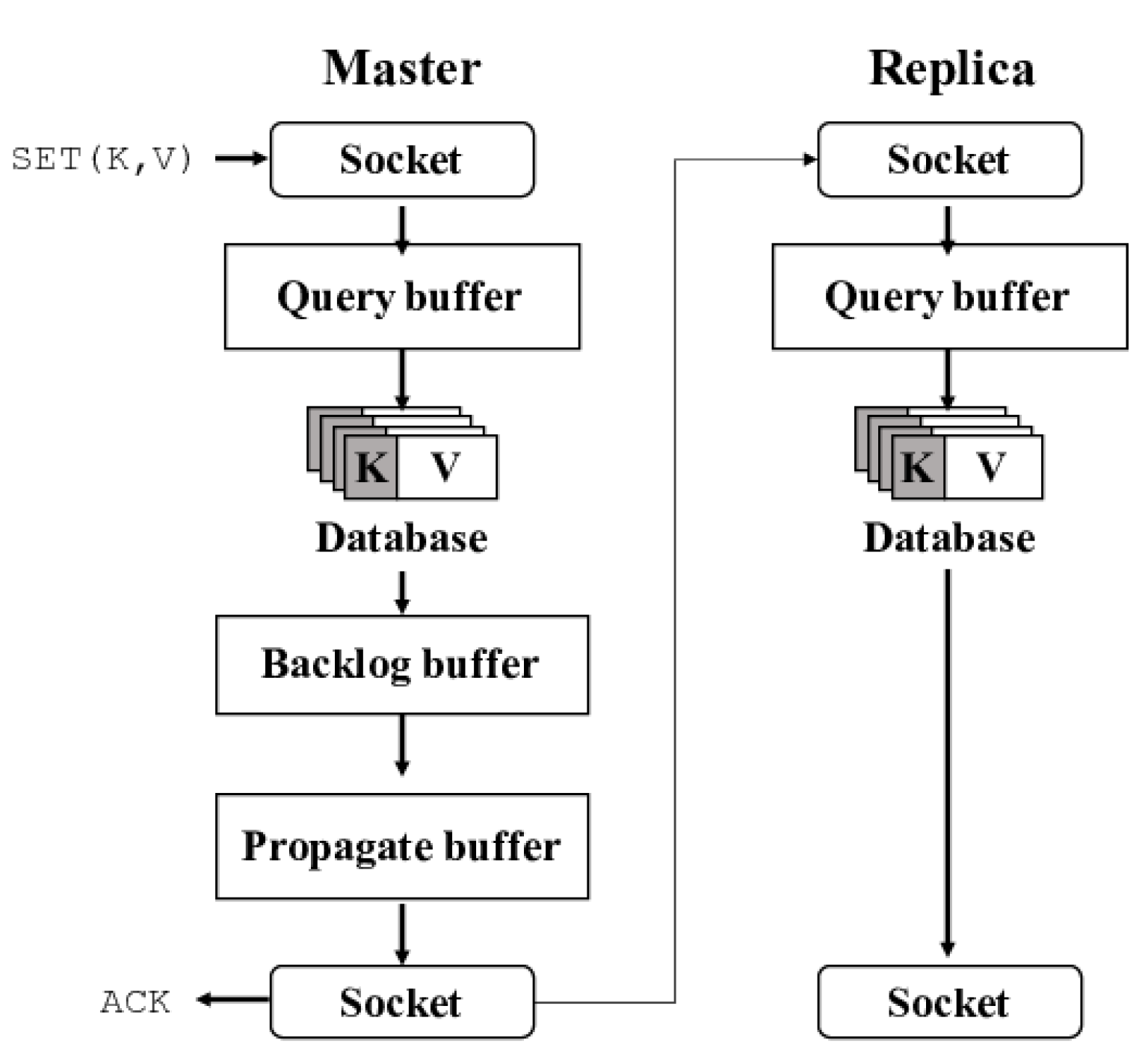
Figure 4 shows the write path of the master and of the replica, respectively. The master initially reads the data from the kernel buffer to the query buffer and applies it to the database. Subsequently, it maintains the data within the two buffers: backlog buffer and propagate buffer. They are needed to propagate the data safely to the replicas. In contrast, the replica only performs the first two steps. As a result, the master undertakes data copying six times in total, while the replica does this only three times. For this reason, the propagation rate of the master lags the processing speed of the replica, even when the replica runs on the scaled-down processor. This outcome shows that, although the write latency increases by nearly two times, it can be hidden because write processing is finished before the next request.
5. Performance Evaluation
To evaluate the effectiveness of
Concerto, we implemented it on Redis 6.0.1. We performed experiments using a prototype on an Intel(R) Xeon(R) Silver 4114 processor with ten cores.
Table 2 shows the P-states available in the processor. The cores assigned to the master run at the full speed (2.20 GHz), while the cores mapped to the replicas are scaled down to the lower speed (1.0 GHz). For the experiments, we deployed a single master and two replicas with Redis, communicating via a socket connection on the same physical machine. This configuration minimizes the effect of any network delay on the performance measurement, highlighting the strength and drawbacks of
Concerto. Note that this setting shows the lower bound of the performance with
Concerto because its impact on the performance decreases as the network delay increases. We investigate the performance and energy tradeoff of
Concerto using the Memtier benchmark [
39] and the YCSB benchmark [
40].
5.1. Benchmark through the Master
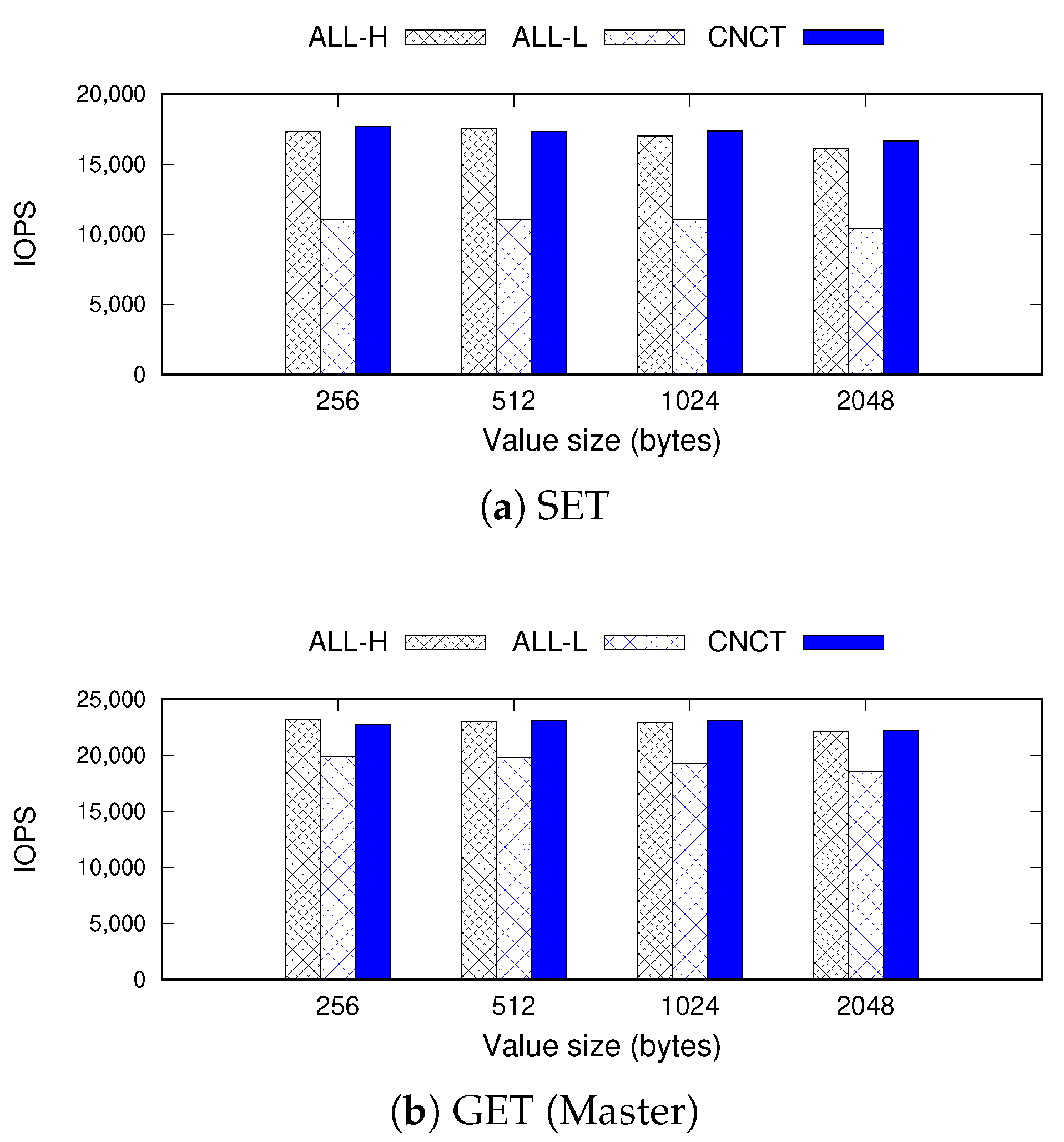
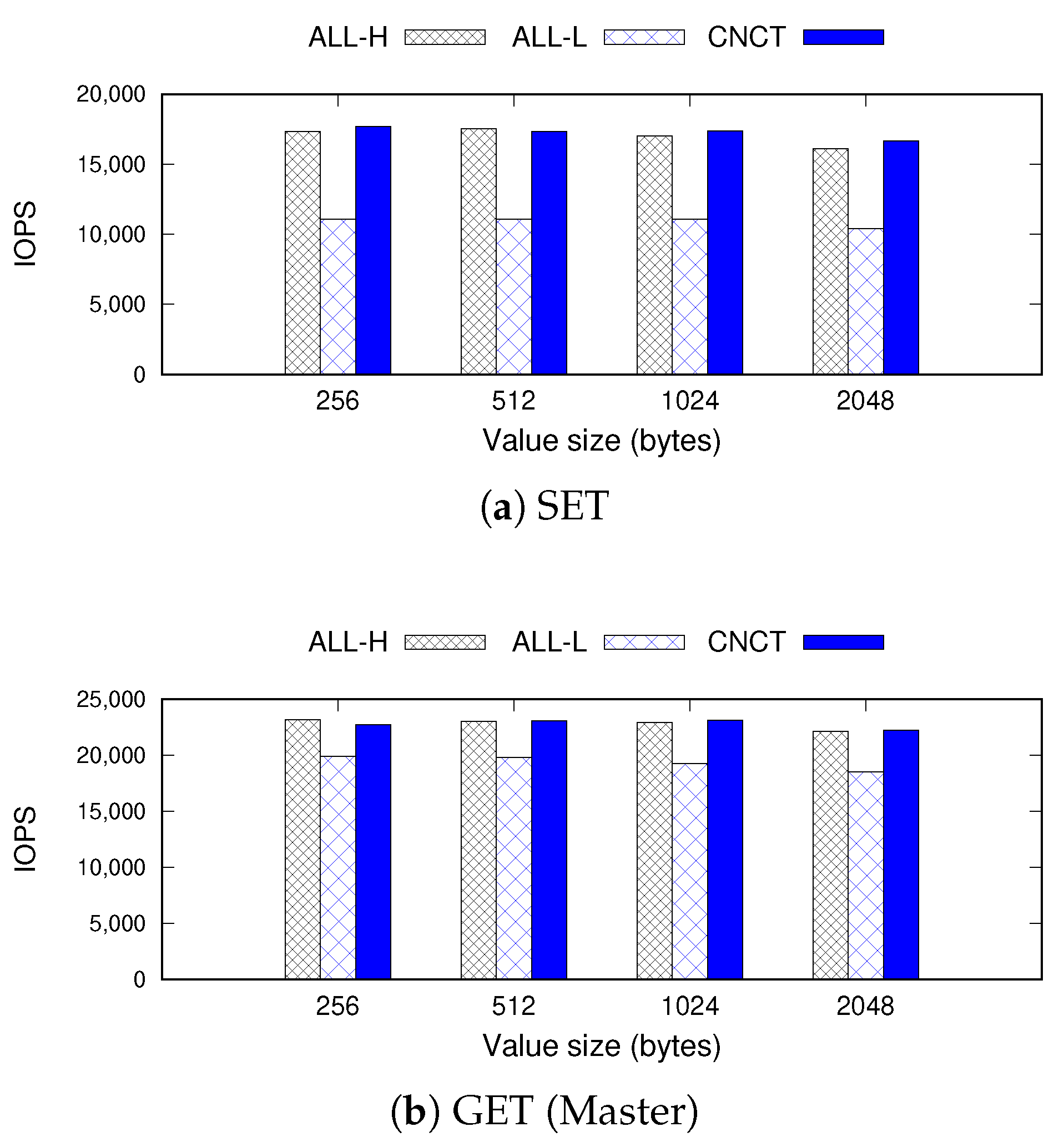
Figure 5 and
Figure 6 show the IOPS and energy consumption outcomes of Redis when running the Memtier benchmark. We generate one million
SET and
GET operations varying the value size from 256 B to 2 KB. In the figures, we compare the performance and energy consumption of
Concerto (
CNCT) with those when executing all nodes at a high frequency (
ALL-H) and at the low frequency (
ALL-L).
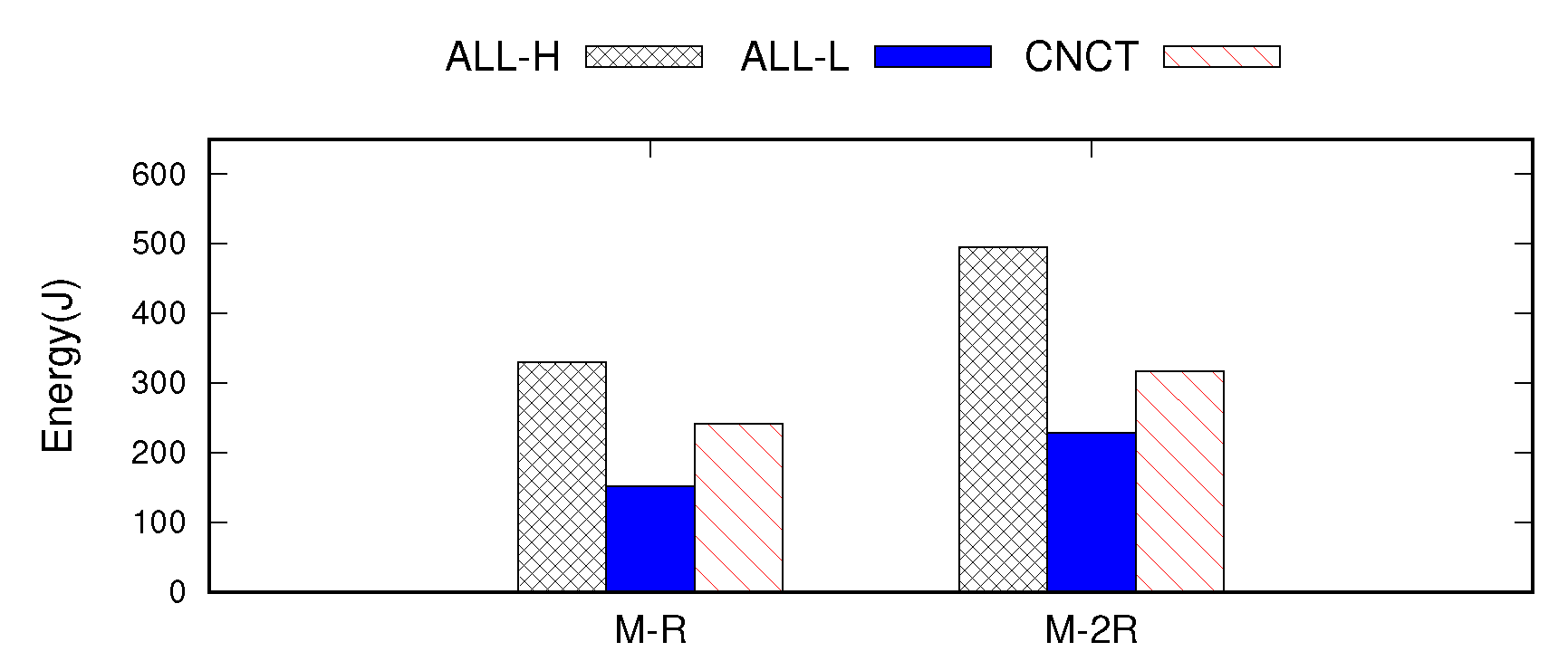
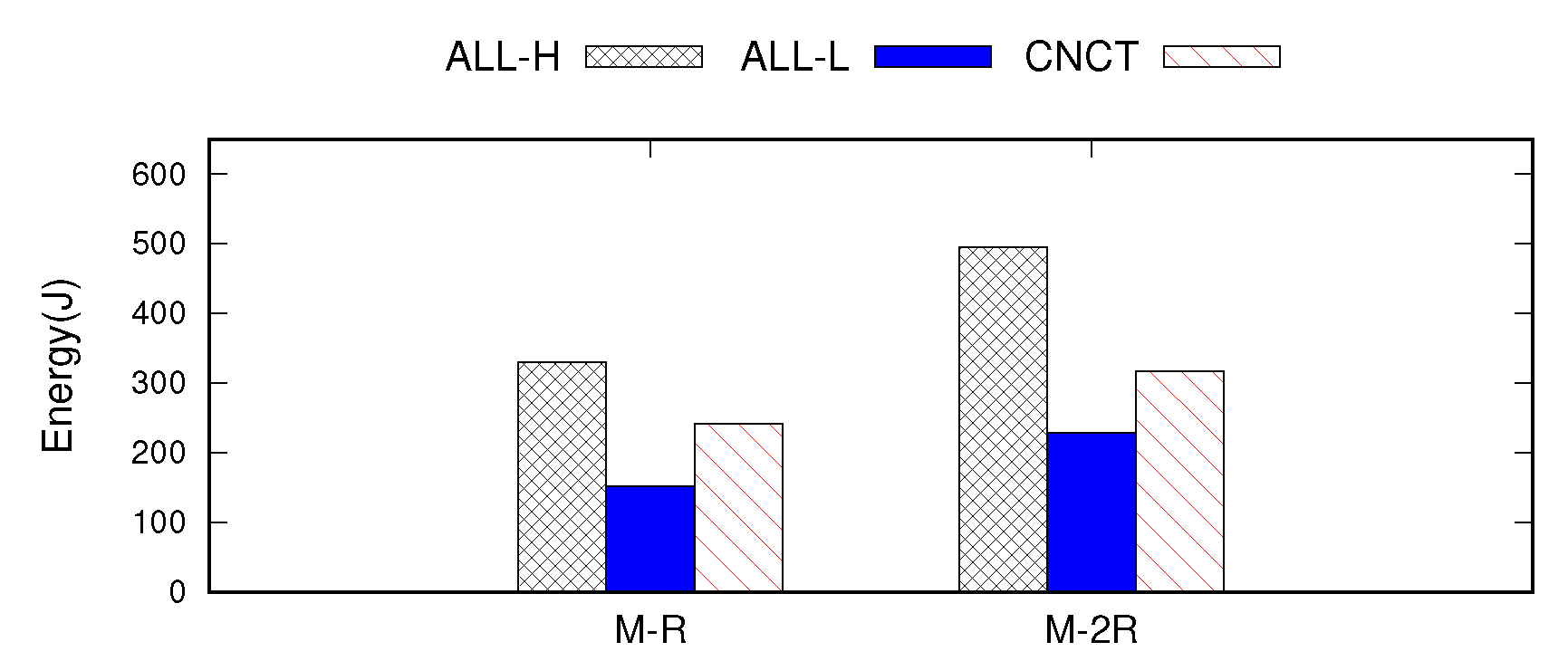
Figure 6 presents the energy consumed by the processor during the execution of the benchmark; this value is calculated by multiplying the power and the total elapsed time for each configuration. For comparison, we plot the energy consumption for two different cases: when a master runs with a single replica (
M–R) and with two replicas (
M–2R). This is done in an effort to observe the energy consumption trend as the replication factor increases.
With respect to energy efficiency, ALL-L achieves the most significant savings, reducing the energy consumption by 54% compared to ALL-H. However, it inhibits the performance significantly, decreasing IOPS by 36% and 15% on average for SET and GET operations compared to ALL-H. In contrast, CNCT decreases the energy consumption by 27–36%, but this is achieved while maintaining the performance. CNCT provides throughput identical to that of ALL-H for both SET and GET operations.
We investigate the effectiveness of
Concerto using YCSB benchmarks. The YCSB benchmark suite has six different workloads, and
Table 3 summarizes the characteristics of each. We initially load one million data items and perform one million operations for each workload.
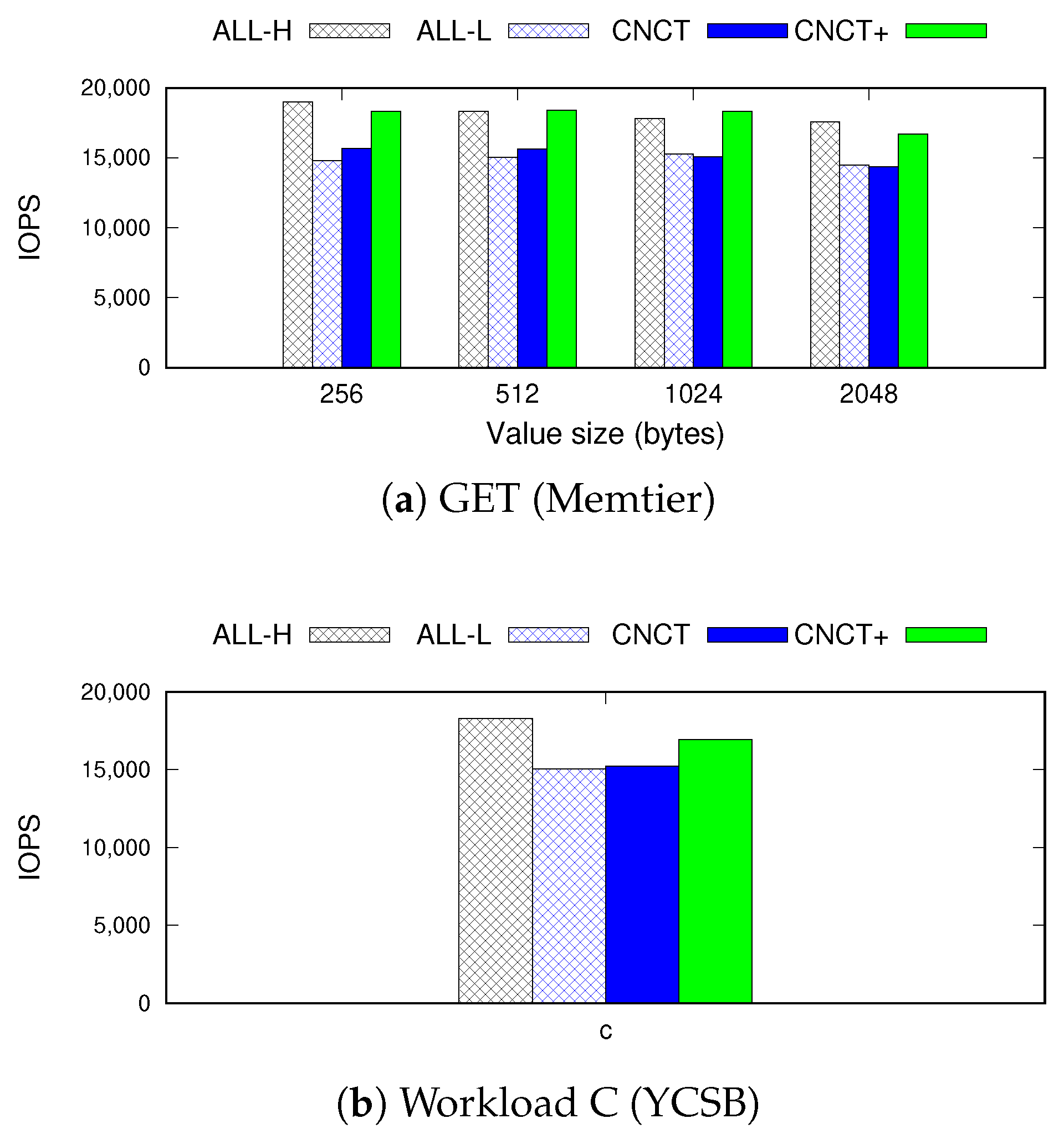
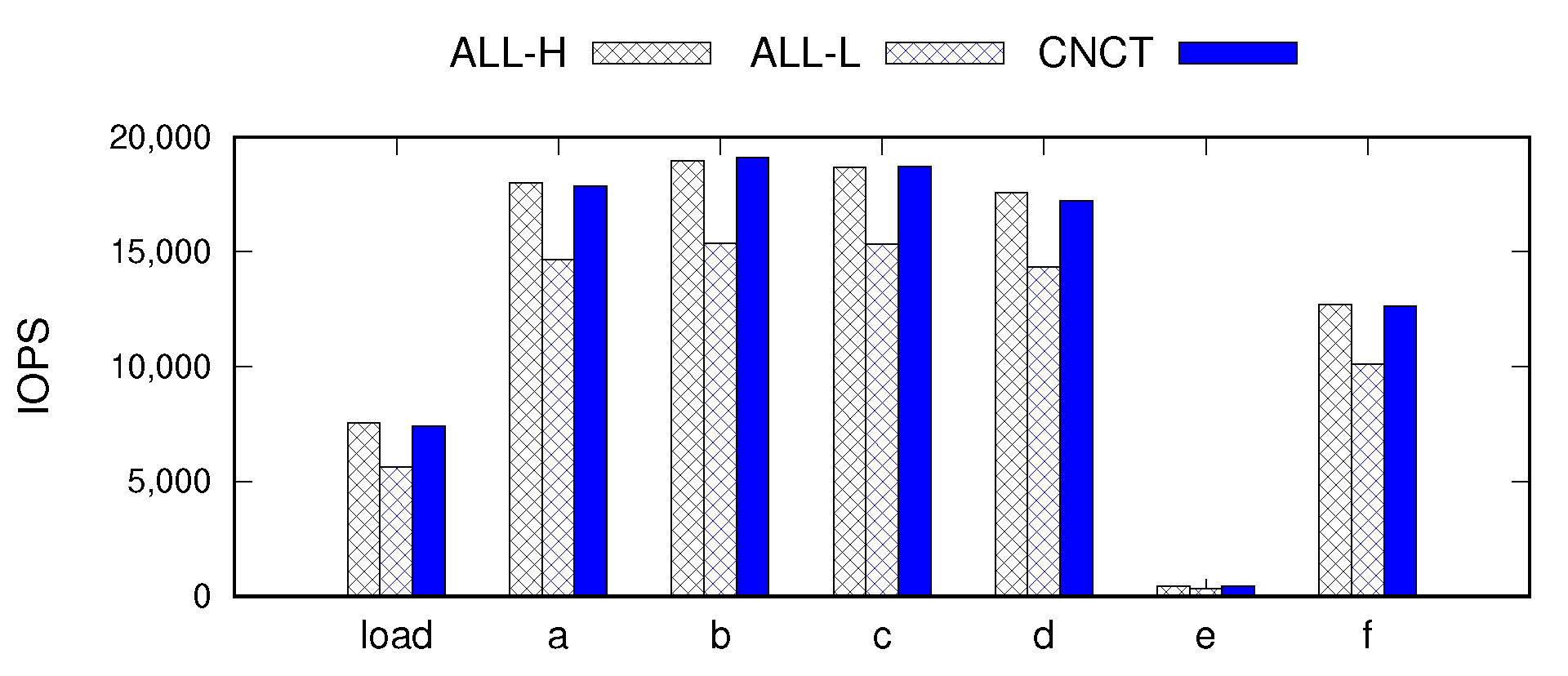
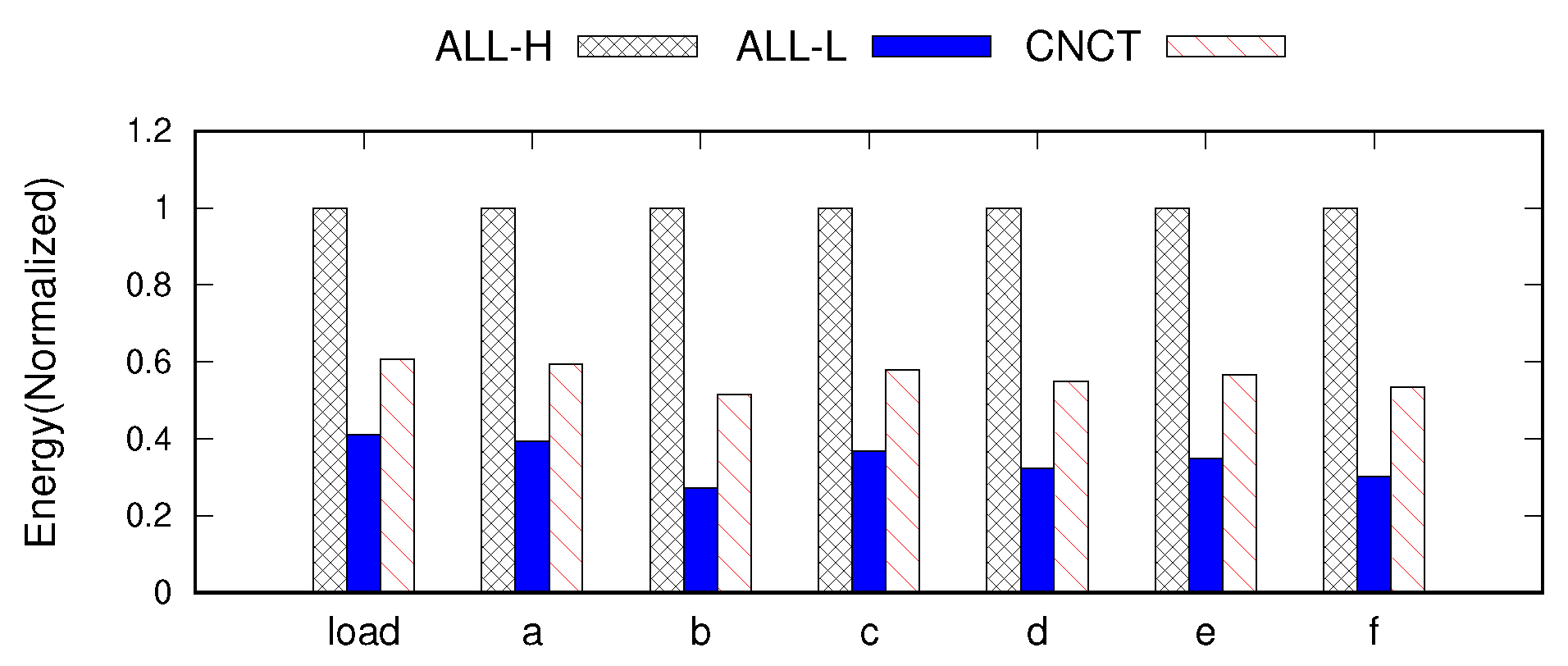
Figure 7 and
Figure 8 show the IOPS and the energy consumption outcomes for the YCSB benchmark. While
ALL-L performs worse than
ALL-H by up to 25% (20% on average),
Concerto achieves a performance similar as
ALL-H across all YCSB workloads. This experimental result demonstrates that the performance relaxation in replicas can be hidden to from the user experience, thus enabling considerable energy savings without a noticeable performance loss.
Table 3.
YCSB workload characteristics.
Table 3.
YCSB workload characteristics.
| WK | Description | Ratio |
|---|
| Load | Initial database establishment | 100% Insert |
| A | Session store recording actions | 50% Read, 50% Update |
| B | Photo tagging and tag reads | 95% Read, 5% Update |
| C | User profile cache | 100% Read |
| D | User status update | 95% Read, 5% Insert |
| E | Recent post scan in conversation | 95% Scan, 5% Insert |
| F | Database | 50% Read, 25% Read-Modify-Write, 25% Update |
With regard to energy consumption, Concerto is inferior to ALL-L because we stick to executing the master node at full speed. Concerto reduces energy consumption by 44% on average compared to AlLL-H, whereas ALL-L uses less energy than ALL-H by 67% on average. However, the advantage of ALL-L in terms of energy is largely compensated for by its performance loss, making it less feasible in practice.
5.2. Benchmark through a Replica
The master–replica model typically allows the replica to accept the read queries, thereby enhancing the availability and performance capabilities of data service platforms. This characteristic is at odds with the concept of
Concerto because scaling down the replica can deliver a decrease in the user experience.
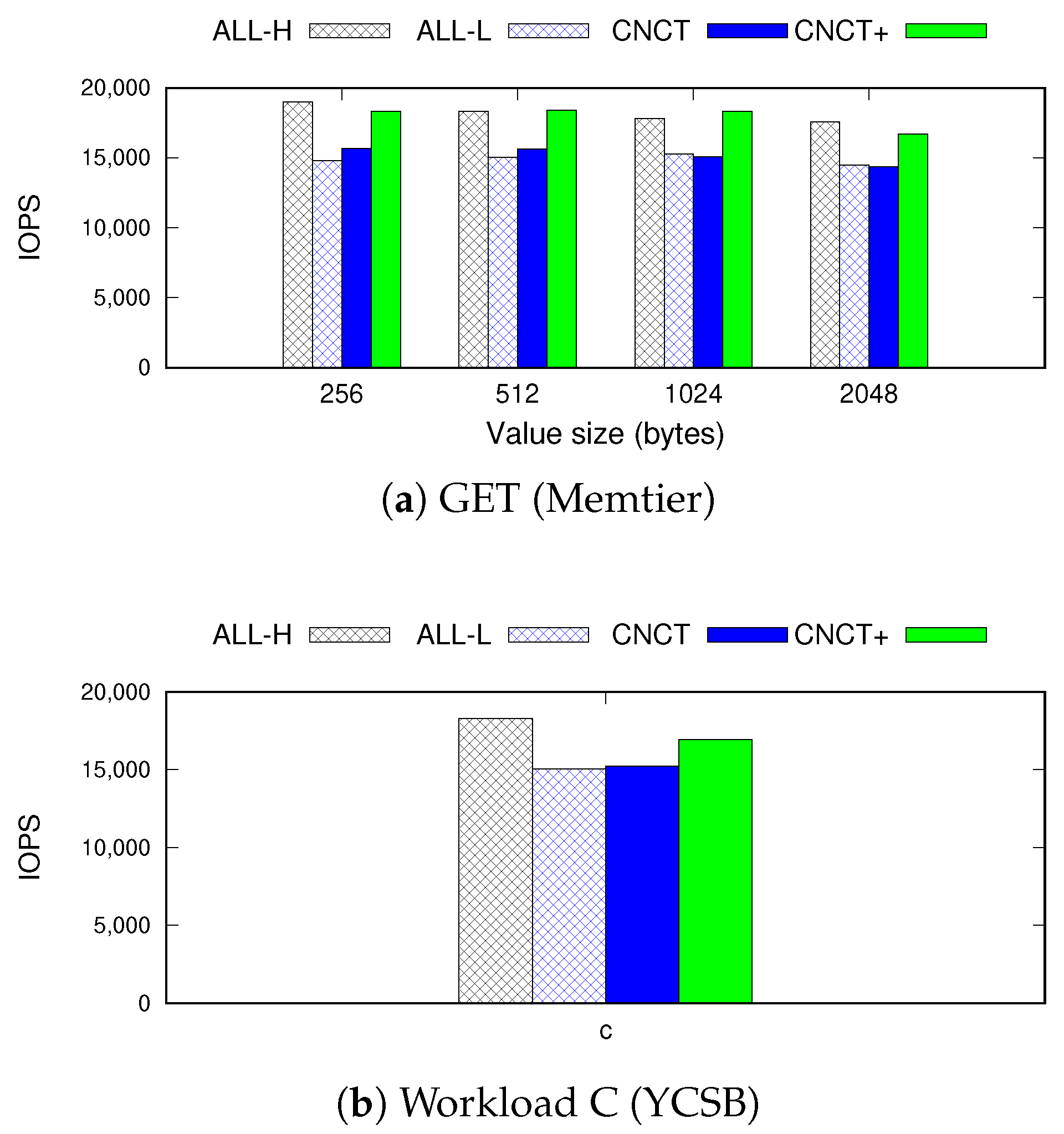
Concerto is augmented to offload the independent part of the read path to the fast-running thread. To evaluate the efficacy of the optimization process, we measured performance by reading data from the replica.
Figure 9 shows the IOPS of Memtier and the YCSB benchmarks when sending the read requests to the replica. For YCSB, we only report the result of workload C because the others include write requests, and, they, therefore, fail when directed to the replica. We study two versions of
Concerto:
CNCT processes all requests (e.g., read requests from users and write requests from master) with a single thread, and
CNCT+ performs the offloading optimization for read requests.
CNCT generates 20% of the performance loss compared to
ALL-H, which is identical to the outcome of
ALL-L. However,
CNCT+ significantly reduces the performance gap with the partial offloading technique, which is only 3% on average. Considering that this measurement is performed under the high-bandwidth network configuration, this performance penalty will be negligible in practice.
6. Discussion
Although our study mostly focuses on the Intel Xeon processor and Redis, it can be generally applied to different architectures and applications. With regard to the underlying processors, AMD uses a power management technology called
AMD PowerNow!, in which fine and dynamic control of the voltage and frequency of the cores is possible [
14]. Similarly, ARM processors, which have been tailored mostly for embedded systems powered by batteries but are now seriously considered for use in data centers, provide various built-in hardware design methods to reduce power usage levels [
15]. They not only support the dynamic on-off switching of the cores (HotPlug) but also allow for modifications of the clock speed according to the computation requirements (DVFS). Furthermore, Amazon EC2 also supports processor state control (C-states/P-states) of the underlying physical machine for the several specific types of instances [
41]. These processors all empower an application to optimize power and performance to best satisfy the user’s requirements. With regard to applications, the relaxation of performance requirement for replicas is not unique in Redis. Distributed data systems that asynchronously maintain replicas, such as Mongodb [
7], HDFS [
10], and Ceph [
9], share this property. Taking into account all of these aspects, we argue that our approach is timely and applicable in a wide range of circumstances, although the implementation methodologies may vary across different systems.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}