
Low-Cost Embedded System Using Convolutional Neural Networks-Based Spatiotemporal Feature Map for Real-Time Human Action Recognition



Abstract
:1. Introduction
2. Related Works
2.1. Depth-Based Human Action Recognition
2.2. Skeleton-Based Human Action Recognition
2.3. Vision-Based Human Action Recognition
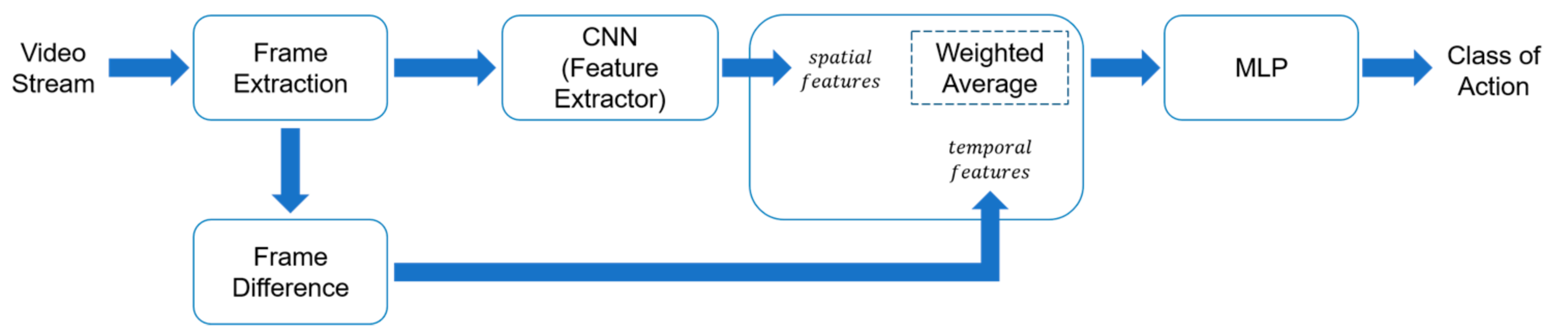
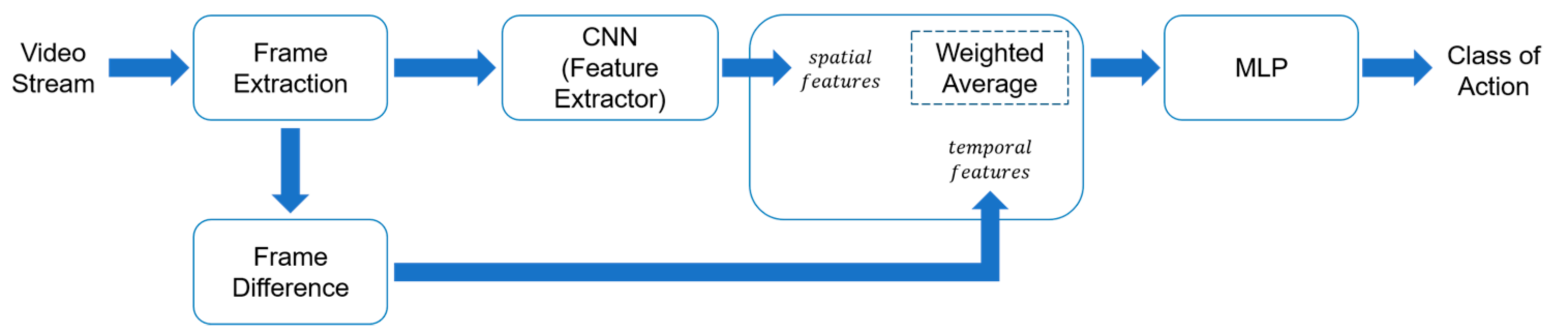
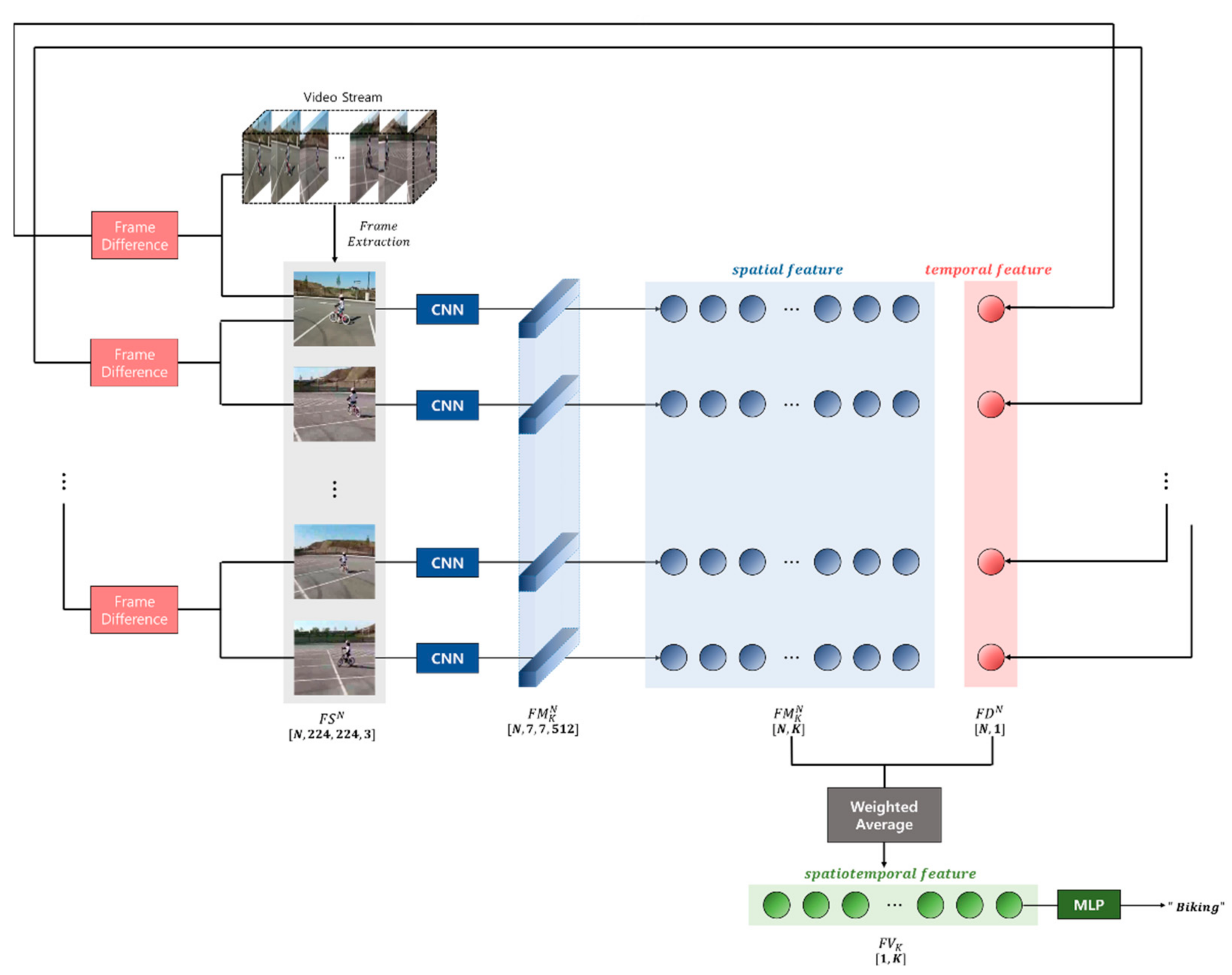
3. Proposed Methodology
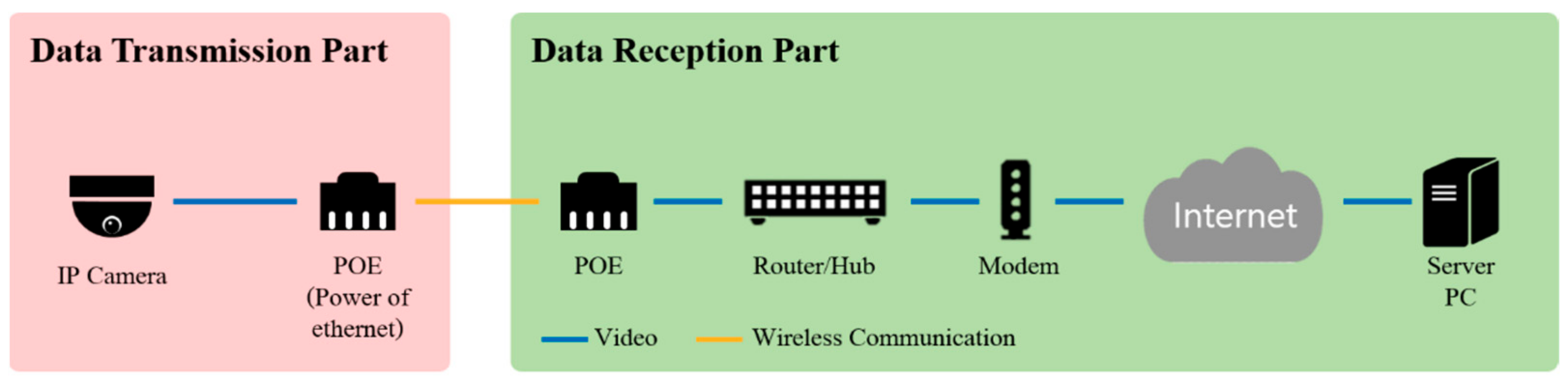
3.1. System Overview
3.2. Extract Spatial Features
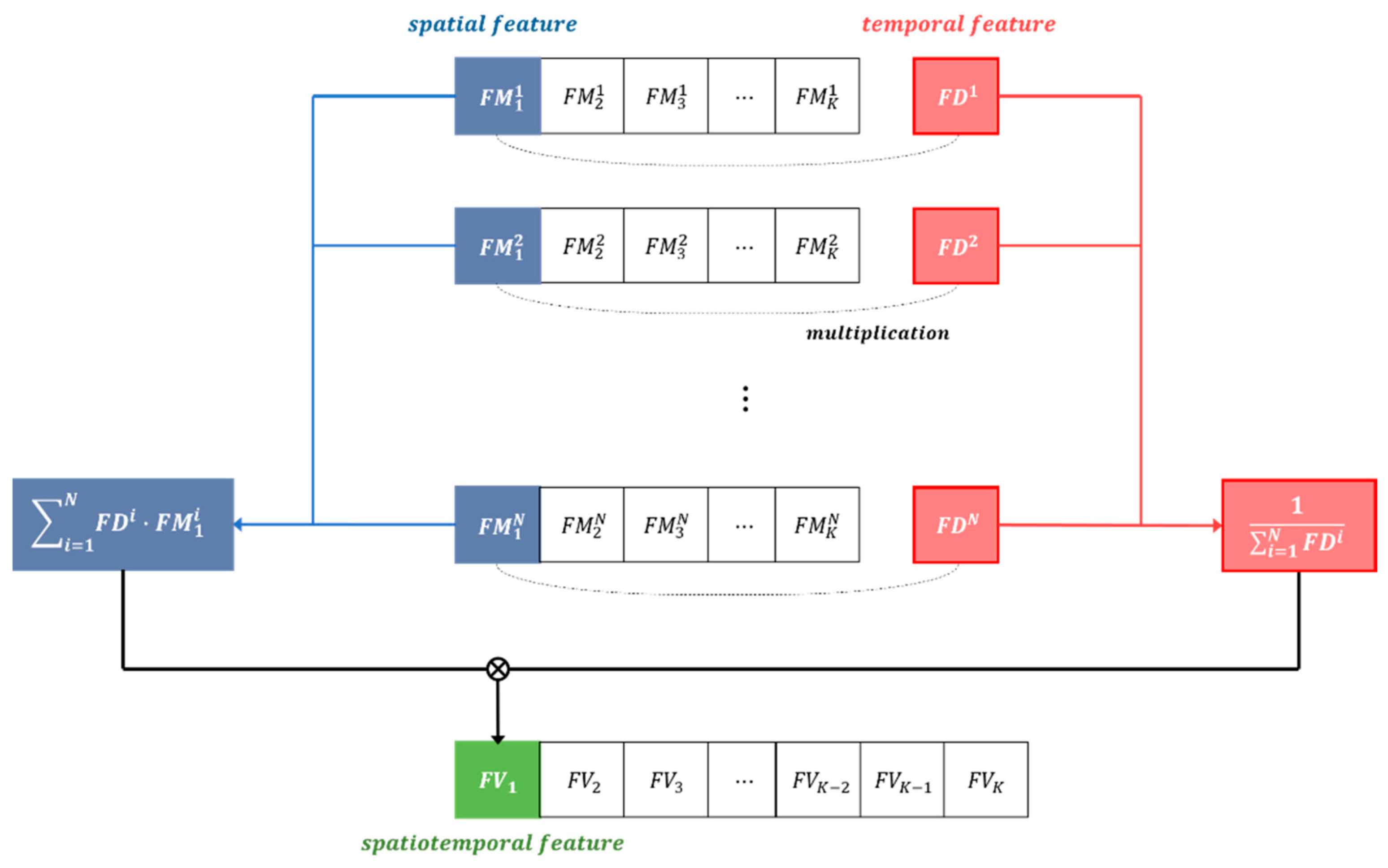
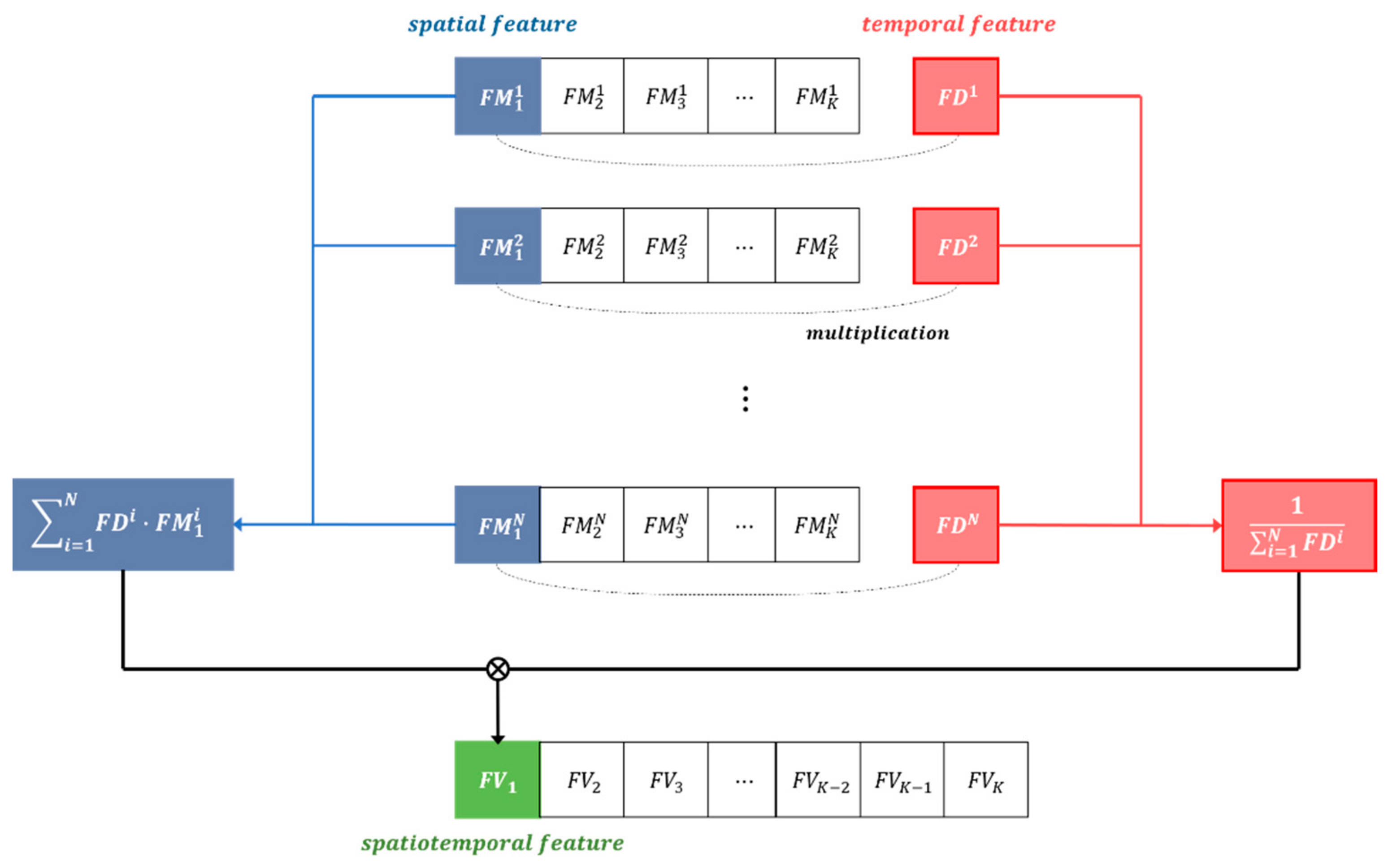
3.3. Integrated Spatial and Temporal Features Based on Weighted Mean
3.4. Action Recognition Using Multilayer Perceptron
4. Experimental Results
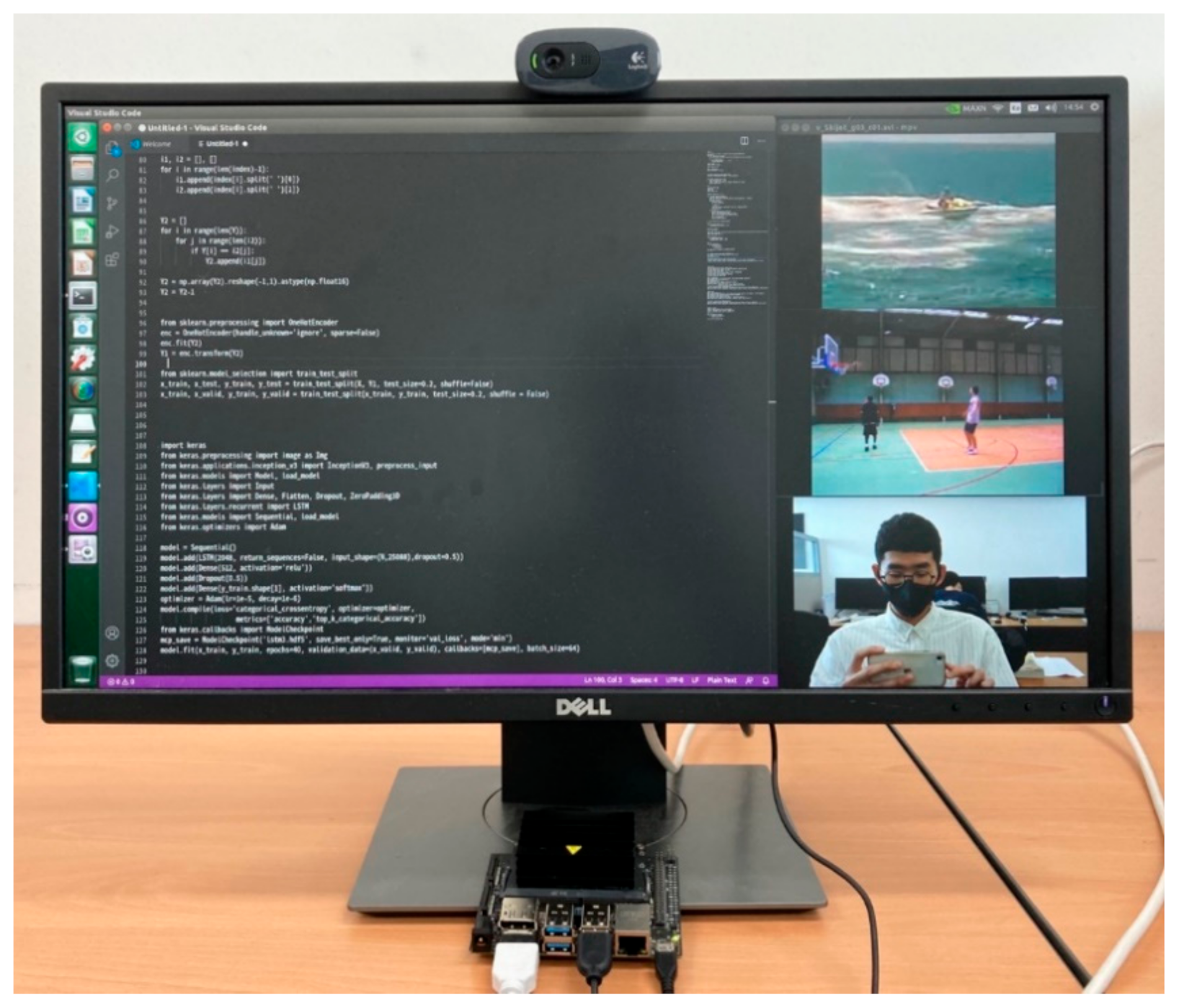
4.1. Experimental Setup
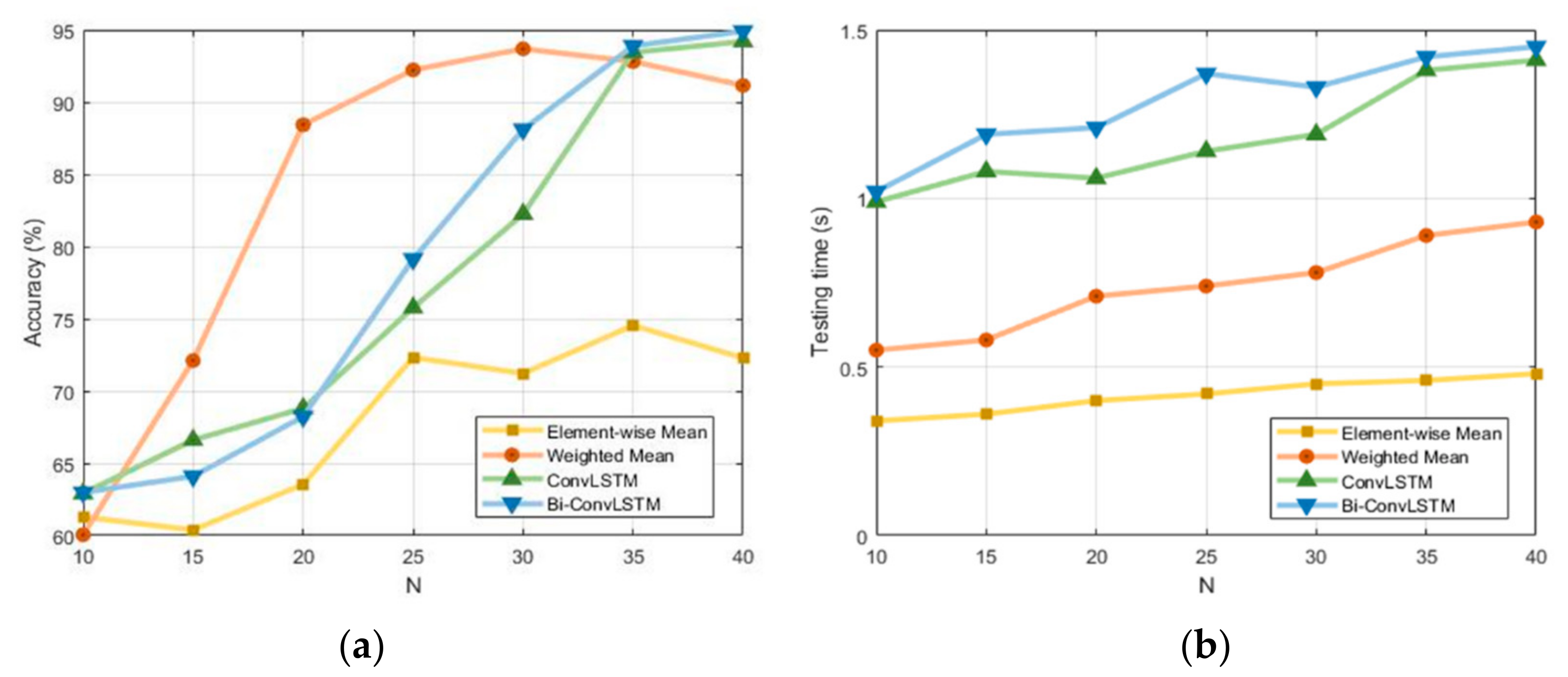
4.2. Performance Evaluation
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Qiu, Z.; Yao, T.; Ngo, C.W.; Tian, X.; Mei, T. Learning spatio-temporal representation with local and global diffusion. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–21 June 2019; pp. 12056–12065. [Google Scholar]
- Rawat, W.; Wang, Z. Deep convolutional neural networks for image classification: A comprehensive review. Neural Comput. 2017, 29, 2352–2449. [Google Scholar] [CrossRef]
- Zhao, Z.-Q.; Zheng, P.; Xu, S.-T.; Wu, X. Object detection with deep learning: A review. IEEE Trans. Neural Netw. Learn. Syst. 2019, 30, 3212–3232. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wu, Q.; Hu, F.; Zhu, A.; Wang, Z.; Bao, Y. Learning spatial-temporal features via a pose-flow relational model for action recognition. AIP Adv. 2020, 10, 075208. [Google Scholar] [CrossRef]
- Liu, A.-A.; Xu, N.; Nie, W.-Z.; Su, Y.-T.; Wong, Y.; Kankanhalli, M. Benchmarking a multimodal and multiview and interactive dataset for human action recognition. IEEE Trans. Cybern. 2016, 47, 1781–1794. [Google Scholar] [CrossRef] [PubMed]
- Gao, Z.; Zhang, Y.; Zhang, H.; Xue, Y.B.; Xu, G.P. Multi-dimensional human action recognition model based on image set and group sparsity. Neurocomputing 2016, 215, 138–149. [Google Scholar] [CrossRef]
- Wang, L.; Xiong, Y.; Wang, Z.; Qiao, Y.; Lin, D.; Tang, X.; Van Gool, L. Temporal segment networks for action recognition in videos. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 41, 2740–2755. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Leong, M.C.; Prasad, D.K.; Lee, Y.T.; Lin, F. Semi-CNN architecture for effective spatio-temporal learning in action recognition. Appl. Sci. 2020, 10, 557. [Google Scholar] [CrossRef] [Green Version]
- Li, S.; Zhao, Z.; Su, F. A spatio-temporal hybrid network for action recognition. In Proceedings of the IEEE Visual Communications and Image Processing (VCIP), Sydney, Australia, 1–4 December 2019; pp. 1–4. [Google Scholar]
- Varol, G.; Laptev, I.; Schmid, C. Long-term temporal convolutions for action recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 1510–1517. [Google Scholar] [CrossRef] [Green Version]
- Ben-Ari, R.; Shpigel, M.; Azulai, O.; Barzelay, U.; Rotman, D. TAEN: Temporal aware embedding network for few-shot action recognition. arXiv 2020, arXiv:2004.10141. [Google Scholar]
- Wang, H.; Song, Z.; Li, W.; Wang, P. A hybrid network for large-scale action recognition from RGB and depth modalities. Sensors 2020, 20, 3305. [Google Scholar] [CrossRef]
- Rodríguez-Moreno, I.; Martínez-Otzeta, J.M.; Sierra, B.; Rodriguez, I.; Jauregi, E. Video activity recognition: State-of-the-Art. Sensors 2019, 19, 3160. [Google Scholar] [CrossRef] [Green Version]
- Carreira, J.; Zisserman, A. Quo Vadis, action recognition? A new model and the kinetics dataset. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 4724–4733. [Google Scholar]
- Diba, A.; Fayyaz, M.; Sharma, V.; Karami, A.H.; Arzani, M.; Yousefzadeh, R.; Gool, L.V. Temporal 3D ConvNets: New architecture and transfer learning for video classification. arXiv 2017, arXiv:1711.08200. [Google Scholar]
- Tran, D.; Ray, J.; Shou, Z.; Chang, S.F.; Paluri, M. ConvNet architecture search for spatiotemporal feature learning. arXiv 2017, arXiv:1708.05038. [Google Scholar]
- Simonyan, K.; Zisserman, A. Two-stream convolutional networks for action recognition in videos. arXiv 2014, arXiv:1406.2199. [Google Scholar]
- Zhao, Y.; Man, K.L.; Smith, J.; Siddique, K.; Guan, S.-U. Improved two-stream model for human action recognition. EURASIP J. Image Video Process. 2020, 2020, 1–9. [Google Scholar] [CrossRef]
- Majd, M.; Safabakhsh, R. A motion-aware ConvLSTM network for action recognition. Appl. Intell. 2019, 49, 2515–2521. [Google Scholar] [CrossRef]
- Lee, J.; Ahn, B. Real-time human action recognition with a low-cost RGB camera and mobile robot platform. Sensors 2020, 20, 2886. [Google Scholar] [CrossRef]
- Shidik, G.F.; Noersasongko, E.; Nugraha, A.; Andono, P.N.; Jumanto, J.; Kusuma, E.J. A systematic review of intelligence video surveillance: Trends, techniques, frameworks, and datasets. IEEE Access 2019, 7, 170457–170473. [Google Scholar] [CrossRef]
- Fahimeh, R.; Sareh, S.; Upcrofit, B.; Michael, M. Action recognition: From static datasets to moving robots. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Marina Bay Sands, Singapore, 29 May–3 June 2017; pp. 3185–3191. [Google Scholar]
- Sreenu, G.; Durai, M.A.S. Intelligent video surveillance: A review through deep learning techniques for crowd analysis. J. Big Data 2019, 6, 48. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E.; Geoffrey, E. ImageNet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 25, 1097–1105. [Google Scholar] [CrossRef]
- Zhang, H.-B.; Zhang, Y.-X.; Zhong, B.; Lei, Q.; Yang, L.; Du, J.-X.; Chen, D.-S. A comprehensive survey of vision-based human action recognition methods. Sensors 2019, 19, 1005. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Chen, C.; Liu, K.; Kehtarnavaz, N. Real-time human action recognition based on depth motion maps. J. Real-Time Image Process. 2016, 12, 155–163. [Google Scholar] [CrossRef]
- Zhanga, J.; Lia, W.; Ogunbonaa, P.O.; Wanga, P.; Tang, C. RGB-D-based action recognition datasets: A survey. Pattern Recognit. 2016, 60, 86–105. [Google Scholar] [CrossRef] [Green Version]
- Yang, X.; Tian, Y. Effective 3D action recognition using EigenJoints. J. Vis. Commun. Image Represent. 2014, 25, 2–11. [Google Scholar] [CrossRef]
- Oreifej, O.; Liu, Z. HON4D: Histogram of oriented 4D normals for activity recognition from depth sequences. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Portland, OR, USA, 23–28 June 2013; pp. 716–723. [Google Scholar]
- Yang, X.; Tian, Y.L. Super normal vector for activity recognition using depth sequences. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Columbus, OH, USA, 24–27 June 2014; pp. 804–811. [Google Scholar]
- Warcho, D.; Kapuściński, T. Human action recognition using bone pair descriptor and distance descriptor. Symmetry 2014, 12, 1580. [Google Scholar] [CrossRef]
- Muralikrishna, S.N.; Muniyal, B.; Acharya, U.D.; Holla, R. Enhanced human action recognition using fusion of skeletal joint dynamics and structural features. J. Robot. 2020, 2020, 3096858. [Google Scholar] [CrossRef]
- Yang, Y.; Cai, Z.; Yu, Y.D.; Wu, T.; Lin, L. Human action recognition based on skeleton and convolutional neural network. In Proceedings of the Photonics & Electromagnetics Research Symposium-Fall (PIERS-Fall), Xiamen, China, 17–20 December 2019; pp. 1109–1112. [Google Scholar]
- Cao, Z.; Hidalgo, G.; Simon, T.; Wei, S.E.; Sheikh, Y. OpenPose: Realtime multi-person 2D pose estimation using part affinity fields. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 43, 172–186. [Google Scholar] [CrossRef] [Green Version]
- Chaaraoui, A.A.; Padilla-Lopez, J.R.; Florez-Revuelta, F. Fusion of skeletal and silhouette-based features for human action recognition with RGB-D devices. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Portland, OR, USA, 23–28 June 2013; pp. 91–97. [Google Scholar]
- Laptev, I. On Space-Time Interest Points. Int. J. Comput. Vis. 2005, 64, 107–123. [Google Scholar] [CrossRef]
- Klaser, A.; Marszałek, M.; Schmid, C. A spatio-temporal descriptor based on 3D-gradients. In BMVC 2008-19th British Machine Vision Conference 2008; British Machine Vision Association: Durham, UK, 2008; p. 275. [Google Scholar]
- Scovanner, P.; Ali, S. A 3-dimensional sift descriptor and its application to action recognition. In Proceedings of the 15th ACM International Conference on Multimedia: Augsburg, Germany, 24–29 September 2007; pp. 357–360. [Google Scholar]
- Yilmaz, A.; Shah, M. Actions sketch: A novel action representation. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–25 June 2005; pp. 984–989. [Google Scholar]
- Ji, S.; Xu, W.; Yang, M.; Yu, K. 3D Convolutional neural networks for human action recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 221–231. [Google Scholar] [CrossRef] [Green Version]
- Karpathy, A.; Toderici, G.; Shetty, S.; Leung, T.; Sukthankar, R.; Fei-Fei, L. Large-scale video classification with convolutional neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Columbus, OH, USA, 23–28 June 2014; pp. 1725–1732. [Google Scholar]
- Si, C.; Chen, W.; Wang, W.; Wang, L.; Tan, T. An attention enhanced graph convolutional LSTM network for skeleton-based action recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–21 June 2019; pp. 1227–1236. [Google Scholar]
- Liu, J.; Shahroudy, A.; Xu, D.; Wan, G. Spatio-temporal LSTM with trust gates for 3D human action recognition. In Proceedings of the European Conference on Computer Vision (ECCV), Amsterdam, The Netherlands, 8–16 October 2016; pp. 816–833. [Google Scholar]
- Sanchez-Caballero, A.; López-Diz, S.; Fuentes-Jimenez, D.; Losada-Gutiérrez, C.; Marrón-Romera, M.; Casillas-Perez, D.; Sarker, M.I. 3DFCNN: Real-time action recognition using 3D deep neural networks with raw depth information. arXiv 2020, arXiv:2006.07743. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Hara, K.; Kataoka, H.; Satoh, Y. Towards good practice for action recognition with spatiotemporal 3D convolutions. In Proceedings of the 24th International Conference on Pattern Recognition (ICPR), Beijing, China, 20–24 August 2018; pp. 2516–2521. [Google Scholar]
- Tran, D.; Bourdev, L.; Fergus, R.; Torresani, L.; Paluri, M. Learning spatiotemporal features with 3D convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 4489–4497. [Google Scholar]
- Li, Q.; Qiu, Z.; Yao, T.; Mei, T.; Rui, Y.; Luo, J. Action recognition by learning deep multi-granular spatio-temporal video representation. In Proceedings of the ACM on International Conference on Multimedia Retrieval, Melbourne, Australia, 6–9 June 2016; pp. 159–166. [Google Scholar]
- Sun, L.; Jia, K.; Yeung, D.Y.; Shi, B.E. Human action recognition using factorized spatio-temporal convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 4597–4605. [Google Scholar]
- Ullah, A.; Ahmad, J.; Muhammad, K.; Sajjad, M.; Baik, S. Action recognition in video sequences using deep bi-directional LSTM with CNN features. IEEE Access 2017, 6, 1155–1166. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Modality | Advantage | Disadvantage |
|---|---|---|
| Depth | Clearly separate foreground and background | Vulnerable to light |
| Skeleton | Extract correlations from joint points connected by body structure | Data uncertainty |
| Vision | Includes various visual information with high resolution | Data capacity |
| Model | Network | Accuracy (%) | Complexity |
|---|---|---|---|
| Multi-scale CNN [46] | 3D CNN | 84.80 | |
| C3D [47] | 3D CNN | 85.20 | |
| MSD [48] | 3D ConvLSTM | 90.80 | |
| FCN [49] | Single-stream CNN | 88.10 | |
| Deep LSTM [50] | 2D ConvLSTM | 91.21 | |
| Ours | Single-stream CNN | 93.69 |
| Symbol | Definition |
|---|---|
| Number of hidden layers | |
| Feature vector length of the kth hidden layer/output size | |
| Kernel size of the kth hidden layer | |
| Pooling factor in the kth hidden layer | |
| Number of filters in the kth hidden layer | |
| Set of indices of convolutional/pooling layers | |
| Input sequence length |
 |  |  | ||||
| GT: ApplyEyeMakeup | GT: LongJump | GT: Kayaking | ||||
| Method | Accuracy score (%) | Testing time (s) | Accuracy score (%) | Testing time (s) | Accuracy score (%) | Testing time (s) |
| Element-wise Mean | 65.23 | 0.28 | 68.72 | 0.34 | 67.34 | 0.31 |
| Weighted Mean | 88.64 | 0.59 | 89.02 | 0.63 | 88.46 | 0.61 |
| ConvLSTM | 69.25 | 0.89 | 71.87 | 1.05 | 68.53 | 1.26 |
| Bi-ConvLSTM | 71.24 | 0.91 | 72.53 | 1.08 | 67.71 | 1.38 |
 |  | |||||
| GT: Archery | GT: PlayingViolin | GT: HandStandPushups | ||||
| Method | Accuracy score (%) | Testing time (s) | Accuracy score (%) | Testing time (s) | Accuracy score (%) | Testing time (s) |
| Element-wise Mean | 60.92 | 0.35 | 61.73 | 0.42 | 63.73 | 0.25 |
| Weighted Mean | 87.58 | 0.58 | 86.25 | 0.72 | 88.94 | 0.67 |
| ConvLSTM | 70.12 | 0.94 | 71.58 | 1.42 | 69.37 | 1.32 |
| Bi-ConvLSTM | 69.47 | 0.92 | 72.72 | 1.49 | 70.03 | 1.30 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kim, J.; Cho, J. Low-Cost Embedded System Using Convolutional Neural Networks-Based Spatiotemporal Feature Map for Real-Time Human Action Recognition. Appl. Sci. 2021, 11, 4940. https://doi.org/10.3390/app11114940
Kim J, Cho J. Low-Cost Embedded System Using Convolutional Neural Networks-Based Spatiotemporal Feature Map for Real-Time Human Action Recognition. Applied Sciences. 2021; 11(11):4940. https://doi.org/10.3390/app11114940
Chicago/Turabian StyleKim, Jinsoo, and Jeongho Cho. 2021. "Low-Cost Embedded System Using Convolutional Neural Networks-Based Spatiotemporal Feature Map for Real-Time Human Action Recognition" Applied Sciences 11, no. 11: 4940. https://doi.org/10.3390/app11114940
APA StyleKim, J., & Cho, J. (2021). Low-Cost Embedded System Using Convolutional Neural Networks-Based Spatiotemporal Feature Map for Real-Time Human Action Recognition. Applied Sciences, 11(11), 4940. https://doi.org/10.3390/app11114940