1. Introduction
The Flow Shop Scheduling Problem (or FSSP), formulated in both permutation and non-permutation variants [
1], remains one of the most well-known optimization problems in operations research. It is widely used for modeling theoretical and real-life problems in manufacturing and production planning [
2]. In this problem, a number of jobs and machines are given. The objective is to determine a production schedule such that each job is processed on each machine in the same fixed order (given by the technological process) and the given criterion, usually the completion time of all jobs, is minimized. In the permutation variant, each machine processes jobs in the same order, while non-permutation variant has no such restriction.
Due to its practical applications, a great variety of FSSP variants and extensions have been considered over the years. For example, the authors of [
3] considered a cyclic variant, where the initial set of jobs (called Minimal Part Set) is scheduled repeatedly in a cycle with the goal to minimize the cycle time. Another cyclic variant of FSSP, where machines are replaced by single-operator robotic cells, was researched in [
4]. Due to the nature of real-life production processes, another common FSSP variant is based on consideration of uncertainty in the data, as shown in [
5]. Another FSSP variant, represented by both the previous paper and [
6], is multi-criteria FSSP, where two or more optimization criteria are considered simultaneously and the goal is to obtain the Pareto front. For this category of problems, Genetic Algorithms are especially popular recently. For example, the authors in [
7] considered a hybrid variant of FSSP, where energy consumption was chosen as an additional objective. Due to a complex nature of the problem, the mixed integer formulation was solved using a modified NSGA-II (Non-dominated Sorting Genetic Algorithm) [
8]. A Genetic Algorithm (GA) utilizing the concept of a relative entropy of fuzzy sets was proposed in [
9]. To evaluate a Pareto front, the front is first mapped to a fuzzy set and then the relational entropy coefficient is used to measure the similarity to an ideal solution. In experiments for 4, 7, and 10 different criteria, the approach was shown to outperform multiple existing algorithms, including the popular NSGA-III [
8,
10]. GA approaches are commonly used for solving a wide range of problems ranging from multi-objective train scheduling [
11] to continuous process improvement [
12].
FSSP is an NP-hard problem and thus considered difficult even for small instances. As a result, there is a great number of different approaches for tackling FSSP. Machine Learning (ML) is a very popular topic nowadays. The methodology is especially well-suited for data-driven problems, with a large volume of noisy information available. However, purely ML-based end-to-end solving methods are usually inferior in the context of classical scheduling and routing problems. For example, the authors in [
13] solved Travelling Salesman Problem (TSP) with the Pointer Networks that output a permutation of vertices. However, the approach was strictly worse than the best classical TSP solvers, such as Concorde [
14]. Many other authors tried solving TSP using ML methods [
15,
16], but none succeeded in outperforming the state-of-art. In [
17], a more general, data-driven approximation for solving NP-hard problems was presented. The methodology was tested on the Quadratic Assignment Problem. The method was outperformed by a general-purpose commercial solver. On the other hand, ML can also be used as a part of a larger solving algorithm. In a proof-of-concept work [
18], the authors proposed an input-size agnostic deep neural network, integrated with Lawler’s decomposition for solving single machine total tardiness problem. The results showed that the algorithm outperformed the former state-of-the-art heuristics and the method can potentially be applied for other problems.
Among classical exact algorithms for FSSP, one can name approaches like Branch and Bound (
) [
19] and Mixed-Integer Linear Programming (MILP) formulations [
20]. Heuristic methods include both simpler greedy- or rule-based algorithms [
21] and dozens of different metaheuristic algorithms [
6,
22,
23]. Other modeling and solving techniques include the use of fuzzy set theory to represent uncertain data [
24] or speeding up computation by the use of parallel computing [
25,
26]. As reported in of the recent reviews on non-permutation FSSP [
2], Genetic Algorithm (GA), Tabu Search (TS), Simulated Annealing, and Ant Colony Optimization are the most popular metaheuristic algorithms for FSSP. As noted earlier, GA has been used recently to solve many multi-criteria variants FSSP. However, the algorithm is also well-suited for a single-objective FSSP. For example, in [
27], GA was used to solve a variant of a hybrid FSSP with unrelated machines, machine eligibility, and total tardiness minimization. The authors incorporated a new decoding method tuned for the specific objective function considered. The resulting algorithm proved to be competitive in numerical experiments. The authors in [
28] considered a permutational FSSP with flow time minimization. A Biased Random-Key Genetic Algorithm was proposed, introducing a new feature called shaking. Authors compared the results obtained by their algorithms with an Iterated Greedy Search, an Iterated Local Search, and a commercial solver. Variants of the proposed algorithm outperformed the competition, especially for larger instances.
Despite a large variety of extensions, the existing variants of FSSP are often insufficient in practice, when considering problems with machines that have unusual characteristics. Our motivation and an example of such problem is the concreting process, where one of the tasks performed on the site is concrete mix pouring. The concrete mixer needs to load the next batch of the mixture before proceeding with the next site. Moreover, the mixture has to be mixed for appropriate time before pouring—too long or too short mixing can affect the properties of the mixture or even damage the vehicle. However, the mixing should not be included in task time because work on the site can proceed as soon as the concrete mixer leaves the site. In scheduling, we can describe this as an additional dependency between starting or completion times of operations within a single machine (the concrete mixer in our case). As a result, additional gaps of minimum and maximum allowed lengths are inserted into the schedule. We will refer to such restrictions as time couplings and to FSSP with those restrictions as Flow Shop Scheduling Problem with Time Couplings (or FSSP-TC).
The minimal waiting time needed for the concrete mixing can be modeled as a setup time [
22], but this does not model the maximal waiting time. Other similar time constraints found in the literature include a classic no-idle [
29,
30], where each machine, once processing operations are started, cannot be idle until all its operations are completed. Setups and no-idle constraints together were considered in [
31], where subsequent operations or setups must start immediately after previous ones have completed. The authors proposed an MILP formulation as well as several versions of a heuristic based on the Beam Search approach.
Similarly to no-idle, a no-wait constraint describes a requirement whose next operation in a job has to be started directly after completing the previous one. An example of such constraint for FSSP was considered in [
32] and solved through various local-search metaheuristics. In [
33], the authors proposed an application of genetic operators to an Ant Colony Optimization algorithm for the same variant of FSSP. The described algorithm was applied to the 192 benchmark instances from literature. Results were compared with an Adaptive Learning Approach and Genetic Heuristic algorithm. The authors in [
34] considered an energy-efficient no-wait permutation FSSP with makespan and energy consumption minimization. To achieve a better energy utilization, the processing speeds of machines can be dynamically adjusted for different jobs, altering both processing times and energy consumption. To solve the multi-criteria optimization problem, an adaptive multi-objective Variable Neighborhood Search algorithm was proposed, outperforming several state-of-art evolutionary algorithms. A modification of a classic no-wait, a limited wait constraint, in the context of a hybrid FSSP, was considered in [
35]. A limited wait occurs, when some types of products (jobs) can wait for being processed at the next machine, and some cannot. The problem was solved by a discrete Particle Swam Optimization algorithm. In [
36], a two-machine FSSP with both no-idle and no-wait constraints considered simultaneously was researched. Authors proposed a metaheuristic algorithm, utilizing Integer Linear Programming formulation. The method was able to obtain competitive results for instances consisting of up to 500 jobs. Another example of time constraints is minimum-maximum time allowed between consecutive operations of a single job. A two-machine FSSP with such constraints was researched in [
20], where some theoretical proprieties of the problem were proven.
Nevertheless, none of the mentioned problems can precisely model the aforementioned concreting process. An adequate model was shown in [
37], along with
and TS solving methods. However, the authors considered only the permutation variant of FSSP-TC and did not propose any elimination properties. We aim to rectify those drawbacks. Thus, our contributions can be summarized as:
Formulation of the mathematical model for the concreting process.
Identification of several problem properties, including elimination blocks.
Proposal of three solving algorithms for the considered problem: B&B, TS, and GA, out of which TS utilizes the proposed block properties.
The remainder of the paper is organized as follows: in
Section 2, a formal mathematical model of the problem is formulated, along with a graph representation. Next, in
Section 3, several problem properties are proven, including the elimination (block) property. Then, solving algorithms are presented in
Section 4. The algorithms are empirically evaluated in
Section 5. The paper is concluded in
Section 6.
3. Problem Properties
In this section, we will discuss several properties for the problem including: feasibility of solutions, computational complexity of determining the goal function, and an elimination property based on blocks.
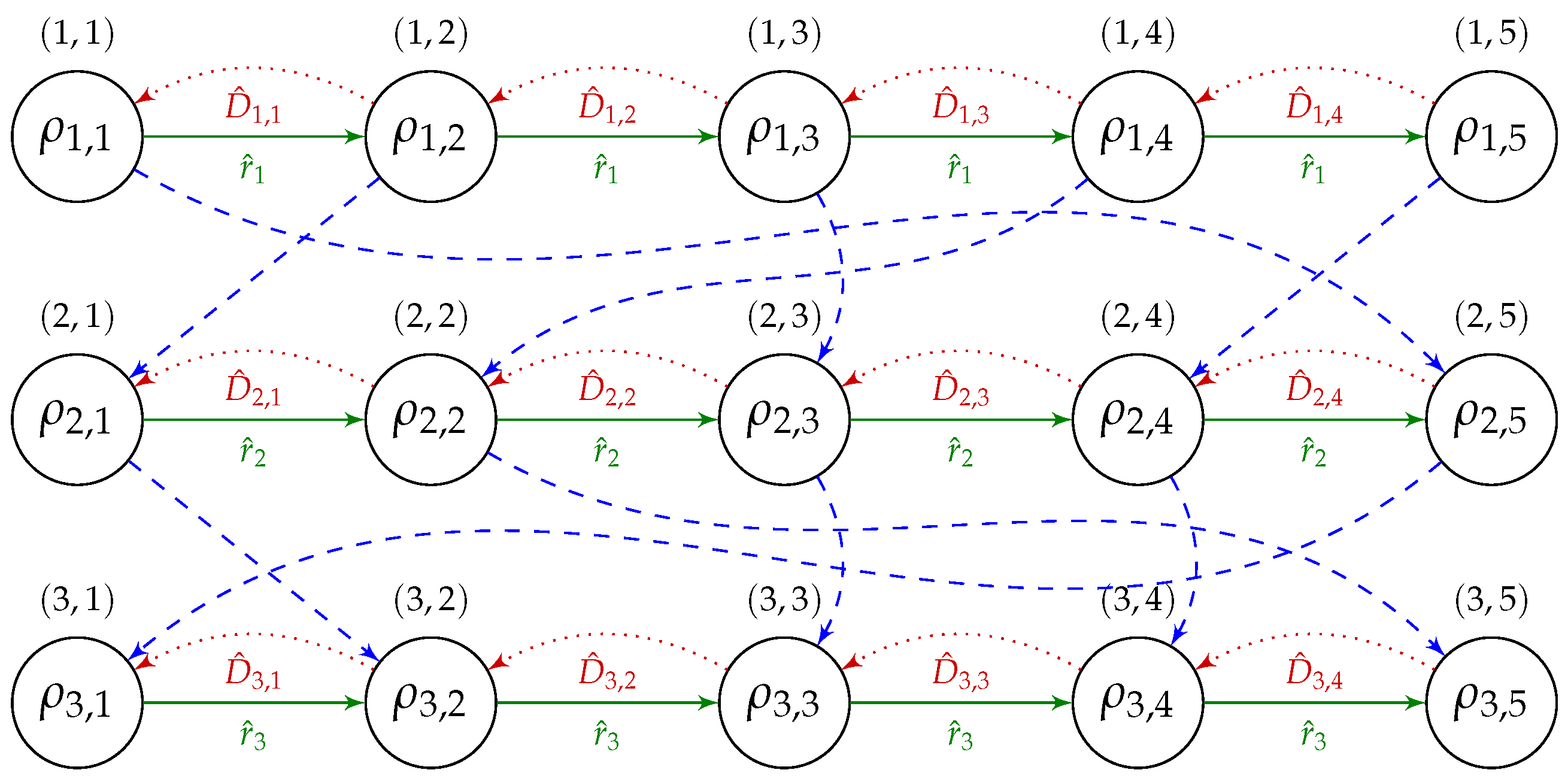
Property 1. For any solution , the solution graph for does not contain cycles of positive length.
Proof. Let us notice that graph does not contain arcs going “upwards” (i.e., no arcs from vertex to for ). Thus, cycles can only be created with the use of “horizontal” arcs.
Let us consider a cycle consisting of two adjacent vertices and . Those vertices have weights and , while the arcs connecting them have weights and . After adding the weights together, the length of such a cycle is equal to .
Now, let us generalize this result to cycles consisting of subsequent vertices in one “row”. Such a cycle contains (for some i and j) vertices from to , as well as “forward” arcs with weights and “return” arcs. Let us now compute the length of such a cycle. Without loss of generality, we can assume that the cycle begins in vertex . Let us consider the inner vertices of this cycle i.e., vertices from to . Let denote one such inner vertex. We pass each vertex twice during the cycle, thus adding weight to the cycle length. Moreover, when passing through vertex , we add the weight twice: once from “return” arc ending at and once from “return” arc starting at . Thus, so far, the cycle length is 0, as all weights and add up to 0.
The above is thus equal to a situation where vertices to have weights 0 and “return” arcs have only term in their weight. The only exceptions are the “return” arc starting at vertex and the “return” arc ending at vertex . Those two arcs still have the terms and in their weights, respectively. However, it is easy to see that those two terms will be negated by the weights of vertices and as we pass those vertices only once during the cycle. Thus, we can compute the cycle length as if all cycle vertices had weights 0 and its “return” arcs had weights with term only. The cycle length is then . □
Therefore, all cycles in are of non-positive length. When computing the value of the makespan, we can ignore those cycles as per the following observation.
Corollary 1. For any solution π, if solution graph for the problem contains a path p with length such that p contains a cycle, then also contains a path P without a cycle, such that: Thus, if a path p in contains a cycle, then either: (1) it is not the longest path in (at least one cycle in p has negative length) or (2) we can construct another path starting and ending at the same vertices and with the same length as p, but not containing a cycle (all cycles in p have length 0).
We will now present the algorithm for determining the left-shifted feasible schedule S (and thus the makespan ), based on the solution . We will also provide the computational complexity of this algorithm.
Theorem 1. For any solution π, there exists a feasible left-shifted schedule S for the problem. Moreover, the value for the schedule S can be determined in time .
Proof. The proof is based on Algorithm 1. Here, we will describe it, including its computational complexity. The algorithm consists of
m phases. In phase
i, we determine the completion times for all operations on machine
i. Every time a completion time
is computed or updated, we also set
. By doing so, we met the constraint (
1) at all times throughout the algorithm.
| Algorithm 1: Constructing left-shifted schedule. |
 |
Phase 1 corresponds to lines 1–3 of the algorithm. In line 1, we set , since the first operation on the first machine has no constraints. Then, in lines 2 and 3, we set completion times for subsequent remaining operations on this machine. Constraints (2) and (3) for this machine will be met because and operations on machine 1 have no technological predecessors. The schedule on machine 1 is thus set, feasible and left-shifted, as scheduling any operation earlier would violate either the left side of constraint (2) or make a negative number. From the pseudocode, it is also easy to see that this phase is computed in time .
Let us now consider phases (lines 4 to 9). We always complete phase i before starting phase (line 4). Each such phase is executed in a similar manner. First, in line 5, we tentatively set , similarly to line 1, except we also consider the technological predecessor of that operation. Then, in lines 6–7, we tentatively set completion times of subsequent operations, taking into account technological predecessor, machine predecessor, and minimal idle time .
By now, the only constraint operations on machine i might still violate is the right side of constraint (2). In order to mitigate that, in lines 8–9, we perform similar operation to lines 6–7, but in reverse order (from operation down to 1). In particular, if and are such that the right side of constraint (2) is violated, then we shift to the right just enough to meet the constraint, after which the value of is final. During this procedure, some of the operations might be rescheduled to start later, thus this change will not violate any constraints. Moreover, now the constraint (2) is guaranteed to hold.
The schedule on machine i is thus feasible and left-shifted. Indeed, if no operation was shifted to be scheduled later during the correction procedure, then we cannot shift any operation to schedule earlier because this would violate either the left side of constraint (2) or constraint (3). Similarly, if an operation was shifted during the correction, then the shift was the smallest that met the right side of constraint (2). Any smaller shift would create infeasible schedule, so shifting the operation to start any earlier is not possible.
We also see from the pseudocode that each phase can by completed in time . Thus, all m phases can be computed in time , allowing us to obtain a feasible left-shifted schedule for any with . □
From the above theorem, it follows that all solutions
are feasible. However, we will show that some of the feasible solutions can be disregarded. Particularly, many solving methods use the concept of a
move. For example, we can define the swap move for the
problem as follows:
where solution
is created from
by swapping together values of
and
. The solution
will be called the neighbor of solution
. Similarly, the set of all solutions created from
by this move will be called the neighborhood of
.
We will now formulate an elimination property showing that some moves do not result in immediate improvement of the makespan, similarly to existing elimination properties for the Job Shop Scheduling problem [
41]. Let us start with the definition of a
block. A sequence of operations
for
will be called a block if and only if:
All operations from B are on the same critical path.
Operations from B are performed subsequently on the same machine i.
Operations from B are processed on i in the order of their appearance in B.
The length of B is maximum i.e., operations from i that are directly before or after B cannot be included in it without violating the first three conditions.
Moreover, for block of operations, we define its inner block as sequence .
Let block be part of critical path K. Then, B is called a right-side block (or R-block) if the first operation from B on K is . Similarly, B will be called a left-side block (or L-block) if the first operation from B on K is .
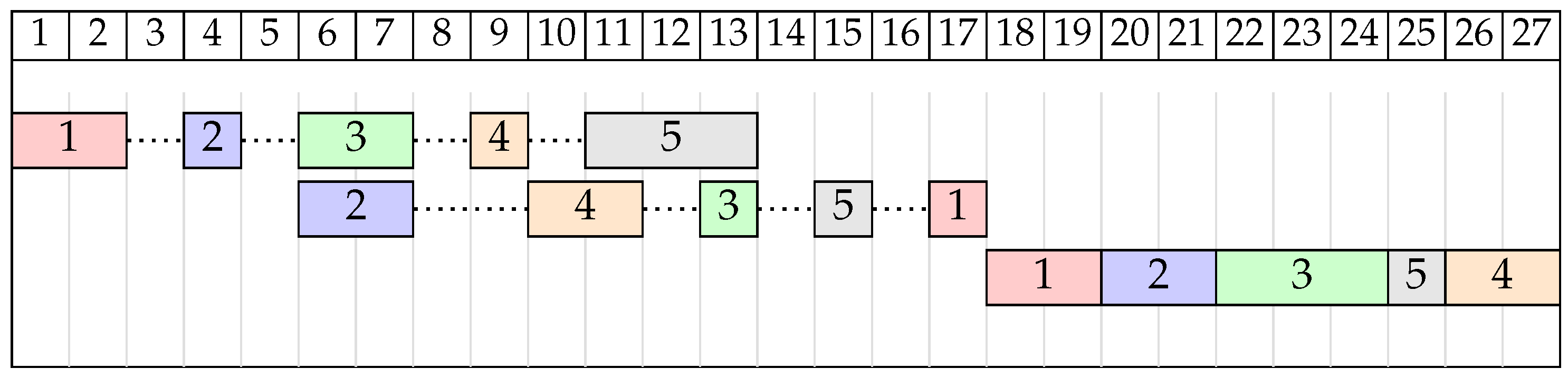
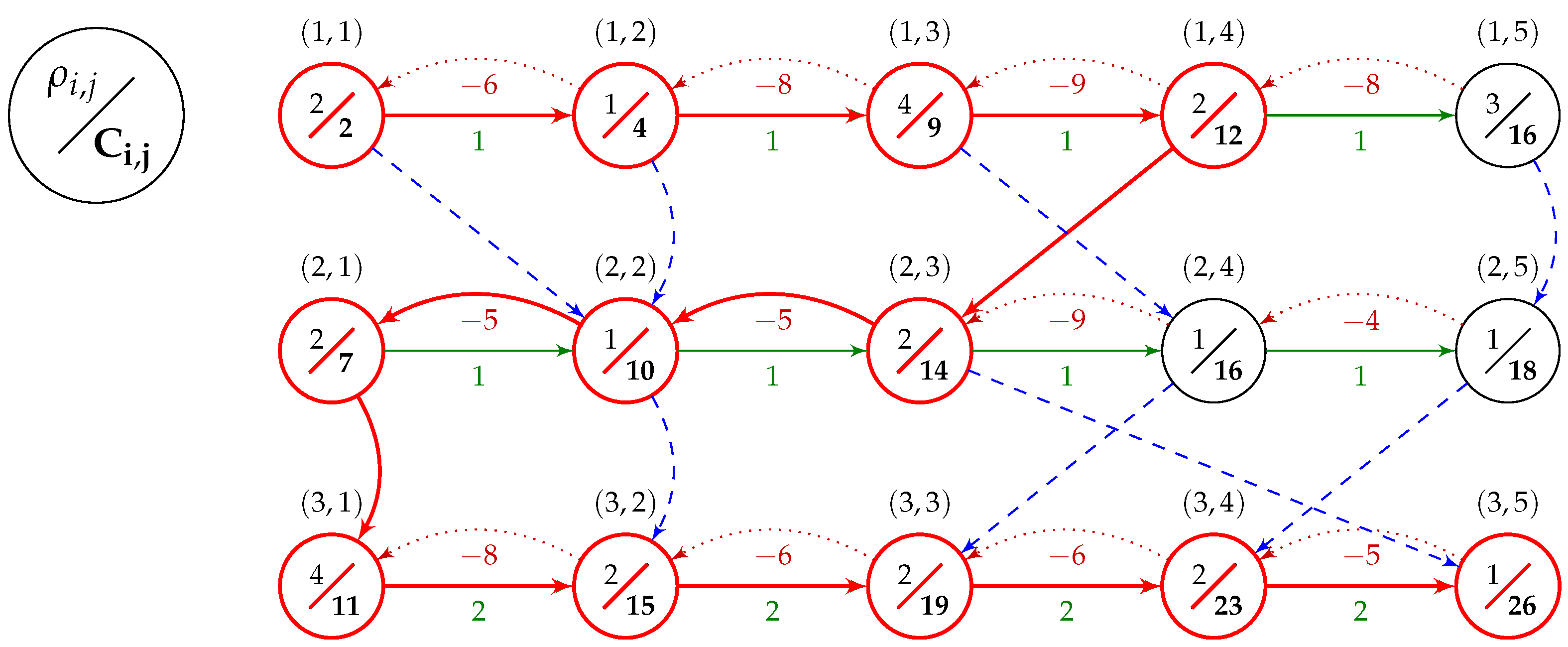
Example 2. Consider the FSSP instance for , from Table 2. Let us assume the order of jobs . Solution graph for this example is shown in Figure 3 with the critical path shown in bolded red. This critical path is composed of three blocks (one for each machine). On the first machine, we have a 4-operation R-block beginning at operation and ending at operation . On the second machine, we have an L-block of size 3 starting at operation and going back to operation . Finally, on the last machine, we again have an R-block which runs through all five operations of that machine. Let us also note that the sizes of the inner blocks are 2, 1, and 3, respectively. The left-shifted schedule for solution π, with , is shown as a Gantt chart in Figure 4. With the concept of blocks and inner blocks defined, we can formulate the block elimination property for the problem.
Theorem 2. Let be a solution to the problem and let , be a block on a critical path K in consisting of operations from machine i. Next, let be a solution created from π by swapping any pair of operation from inner block of B i.e.,:then: Proof. Due to Property 1 and Corollary 1, there is at least one cycle-free critical path that contains the block B. We arbitrarily choose one of such paths to be our critical path K.
It follows that the critical path travels through block B in one direction (the critical path does not change direction in the middle of B). Thus, B is either an L-block or an R-block and we need to prove the elimination property for both types of blocks.
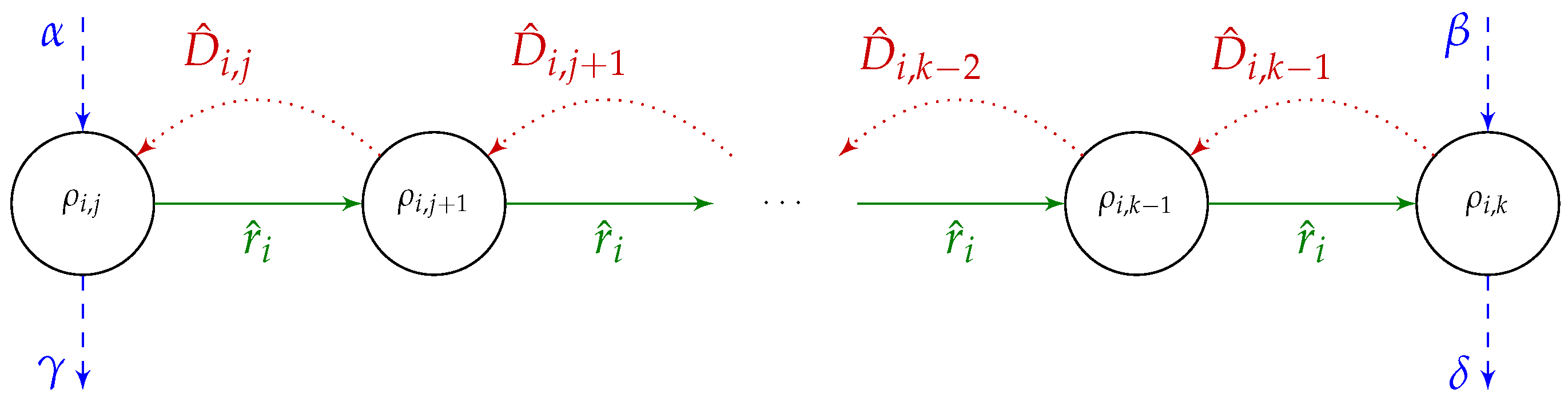
Let us notice that the “downwards” arc entering B from the previous machine (if ) always enters B either at the beginning (at operation ) or at the end (at operation ) of B, making the B and R- and L-block, respectively. The same happens for the arc exiting the block “downwards” onto the next machine (for ): that arc exits from for an L-block and and from for an R-block.
Let us assume that operations
of
B are operations from jobs
, respectively. Let
and
be the lengths of the longest paths ending and starting at vertex
, without the weight of that vertex. Similarly, let
and
be the lengths of the longest path ending and starting at vertex
without the weight of that vertex. The relevant part of graph
, including block
B and paths
,
,
and
is shown in
Figure 5.
Let us start with the R-block case. The length of the critical path will be:
The inner block for
B is
. Now, let us consider swapping any two operations
, with
. Such a swap will not affect the lengths of paths
and
. It will also not change values
and
, as vertices
and
are outside of the inner block. Values
are unaffected as well. The swap of operations
and
will change the order of the values
through
, but their sum will remain unchanged. The length of the considered critical path will thus remain the same. Thus, graph
will contain a path with the length at least as large as the length of path
K in
and in conclusion:
Now, let us consider the L-block case. The length of the critical path is then:
Once again, we consider swapping operations and from inner block of B. The length of paths and does not change, similar to weights of vertices and because they are outside the inner block. The swapping of and will also not affect the sum of weights of vertices to as they will all still be a part of the inner block after the swap, just in a different order.
All that is left to consider are the arc weights through . Part of those weights are the terms which will not change as they are independent from solution (or ). Values and that are part of weights and will not change because they are dependent on weights of vertices and , which were unaffected by the swap. The last remaining contribution to weights for z from j through are the values and . Those values are dependent on vertex and its weight of . However, we know that all weights will remain in the inner block (just changing their order). Thus, the operation swap will not change their total contribution into weights , and the final sum of weights through does not change.
As a result, the graph
will contain a path of the length the same as critical path
K in
, thus:
□
The above theorem proves that the swapping of operations in an inner block will not result in an immediate improvement of . It is similar for the swapping of operations outside of the block (they lie outside of the critical path). Thus, the most promising option is to perform a swapping move where one operation is from the inner block and one is outside of it.
4. Solving Methods
In this section, we will propose three methods for solving the problem: a Branch and Bound () method, as well as Tabu Search (TS) and Genetic Algorithm (GA) metaheuristics. Due to its ability to obtain an optimal solution, the B&B method will be used as a reference for evaluating the quality of the TS method for smaller instances. Similarly, GA will serve as a baseline comparison to TS for larger instances.
4.1. Branch and Bound
Branch and Bound (
) [
19] is an exact method using lower and upper bounds to skip parts of the solution space that cannot contain the optimal solution. Our implementation is based on a priority queue
of nodes. Each queue element
contains a partial solution (
), the machine on which a current algorithm branch is executing (
), a set
of jobs not yet scheduled on this machine, and the lower bound
.
The branching method is similar to the one used for the Job Shop Scheduling Problem [
42]: first, we consider all jobs on the current permutation level before proceeding to the next one, avoiding having to process the same node twice. If
and
, then
is a leaf element (
contains a full solution), and we compute makespan
. If the resulting value is better than the best-known solution so far, then we update the current upper bound
. The initial
is generated by an NEH-like [
21] greedy heuristic. The lower bound
for
is computed as follows:
where:
and
is the last job scheduled on machine
i in partial solution
. The algorithm stops either when
Q becomes empty or the best node on
Q is worse than current
.
4.2. Tabu Search
Tabu search (or TS) is one of the most well-known local search metaheuristics [
23]. In each iteration, we search the
neighborhood of the current solution. The neighborhood
of solution
is defined as all solutions
that can be obtained from
by applying a pre-defined
move function. In our implementation, we considered three types of moves:
Swap move . Neighboring solution is obtained by swapping together values and , where , , . This neighborhood has exactly solutions.
Adjacent swap move . Neighboring solution is obtained by swapping together values and , where , . This neighborhood has exactly solutions.
Block swap move . This move is similar to , except it takes into account the results of Theorem 2. Specifically, if is an inner block on machine i, then the move is only performed when either or . The size of this neighborhood is dynamic, based on on the size of blocks in , but its size is between the sizes of neighborhoods generated by moves and with solutions on average.
Let us also note that all of the above move types are involutions.
Example 3. Let us consider the solution from the graph in Figure 3 for and . For the adjacent swap move, the neighborhood size is 12. This is because we swap only adjacent operations; thus, on the first machine, we can swap operation 1 with 2, 2 with 3, 3 with 4 or 4 with 5. This can be applied to any machine, hence possible moves. In the case of the swap move, for each of five machine operations, we can swap it with any of the remaining four operations, yielding 20 possible swaps on machine and 60 moves in total. Finally, for the block swap move, the number of possible swap moves on machine i is given as , for and 0 for , where is the size of the block on machine i. This is because we can swap any operation from the inner block (which has size ) with any operation out of the inner block (which means operations). In our example, the block sizes are 4, 3, and 5, which yields 6 + 4 + 6 = 16 possible swap moves. In each iteration i of the TS algorithm, we generate the neighborhood of the current solution (according to the chosen move type) and then evaluate (i.e., compute ) all resulting solutions. The best of those solutions will become the current solution in the next iteration (. In addition, if the best neighbor is better then the best known global solution , we replace with . The initial solution () is either random or generated using a simple greedy heuristic.
One of the well-known drawbacks of such neighborhood search strategy is that the algorithm quickly reaches a local optimum and a cycle of solutions is repeated indefinitely. In order to alleviate this, the TS metaheuristic has a short-term memory, usually called tabu list, which is used to define which moves are forbidden (or tabu). Solutions obtained by forbidden moves are generally ignored when choosing . One exception to this rule is when the forbidden neighbor improves ; such a neighbor can be chosen as , despite being forbidden.
When the move is performed, we store its attributes and k on the tabu list for the subsequent C iterations, where C is a parameter called cadence. Moreover, we implemented the tabu list as a three-dimensional matrix. This allowed us to perform all tabu list operations in time . Finally, even with the tabu list in place, the algorithm can still enter a cycle. Thus, we restart TS (by setting current solution to randomly generated) after K subsequent iterations did not improve , where K is a TS parameter.
Due to different neighborhood size, value C was set separately for each neighborhood type: for swap, for adjacent swap and for block swap. After preliminary research, the value K was set to 20.
4.3. Genetic Algorithm
In order to better verify the effectiveness of our approach, we have decided to use an available general (i.e., not relying on any specific block properties) computation framework, which could serve as a “baseline” compared to our approach. In particular, we have chosen Distributed Evolutionary Algorithms in Python (DEAP) [
43], which is used, among others, to implement and run GA methods for a wide class of optimization problems (e.g., [
44] or [
45]). Moreover, GA is among the most commonly used metaheuristic algorithms for FSSP [
2].
While DEAP has many built-in functionalities, such as multi-objective optimisation (NSGA-II, NSGA-III, etc.) or co-evolution of multiple populations, allowing for quick development and prototyping, it does not have the out-of-the-box support for solution representation we needed (sequence of permutations ). Thus, we needed to implement our own version of the following parts of the algorithm:
generation of the initial population—this was done by applying the default DEAP method (random permutation) for all m permutations in .
crossover operator—the operator consisted of applying the pre-defined OX operator to each element in .
mutation operator—the operator consisted of applying the pre-defined Shuffle Indexes operator (which works by applying a simple swap move for each gene with a given probability) to each element in .
As for the hyperparameters, we used either generic ones used for GA or the ones suggested by the DEAP framework. In particular, crossover and mutation probabilities were set to and , respectively. The population size was set to 100. We also used tournament selection with tournament size 3.
5. Computer Experiments
In order to verify the effectiveness of the proposed elimination property, we have prepared a set of computer experiments using solving methods described in
Section 4 as well as a number of benchmark problem instances.
We will start by describing the benchmark instances. Such benchmarks for basic scheduling problems are available in the literature with one of the most well-known being benchmarks proposed by Taillard [
46], which include a set of instances for the FSSP. However, Taillard’s benchmarks do not account for our concept of time couplings. Thus, we have decided to employ our own instance generator, which is based closely on the generator proposed by Taillard. The pseudocode of the instance generation procedure is shown in Algorithm 2. The procedure input is the seed (
s), problem size (
n and
m), and range of processing and coupling times given by lower (
L) and upper (
U) bounds. Lines 1–4 are identical to basic Taillard’s generator except that Taillard simply assumes
and
. Lines 5–12 are used to generate values
and
and ensure that
.
| Algorithm 2: Instance generation procedure. |
 |
We have prepared two sets of testing instances: A and B. The first set contains instances of small size, which we will use to test the effectiveness of the TS metaheuristic by comparing it to the exact method. The second set contains larger instances meant to represent a more practical setting. For the set B, we employ an approach similar to Taillard’s: there are 12 size groups from to , with 10 instances per group. We use the same seeds as the ones proposed by Taillard. However, while Taillard assumed processing times from range 1 to 99 only, we decided to use five groups of processing times and minimum/maximum machine idle times: (1) 1–99, (2) 10–90, (3) 30–70, (4) 40–60, (5) 45–55. Thus, set B contains instances in total.
Our next point of interest is establishing a measure of quality that will allow for comparing instances of different sizes and different goal function values. In our case, that measure is Percentage Relative Deviation (
). Let
be the solution obtained by the considered algorithm for instance
I and
be a reference solution for that instance. Then,
is defined as follows:
In practice, the value of was either the optimal solution (obtained through the method) or the best known solution (i.e., the best of tested algorithms for that instance) if an optimal solution was not known.
All experiments were conducted on a machine with an AMD Ryzen Threadripper 3990X processor @ 3.8 GHz with 63 GB of RAM using Windows Subystem for Linux. The TS method was written in C++ and compiled with g++ 9.3.0 using the -O3 compilation flag. The GA method was run using Python3 version 3.8.2.
In the first experiment, we compared TS and
methods for instance set A. The results are shown in
Table 3. For a given instance size,
is the running time of
for subgroup
f, with different subgroups having different values of
L and
U as described earlier. We observe that, while the running time of
increases with problem size, it also decreases with the subgroup number. For size group
, the
method in subgroup 5 is over 280 times faster than for subgroup 1. This means instances with a smaller range of processing and machine idle times are much easier to solve. We also observe that running times of the TS metaheuristic are much shorter than that of the
method, staying under 35 ms. In this test,
was the solution provided by
(i.e., the optimal solution). Thus, the TS metaheuristic on average provided solutions with a makespan under
away from optimum even for instances of size
.
For the second experiment, we used instance set B to compare four algorithms against each other. The algorithms are as follows:
TS metaheuristic from
Section 4 employing the block swap move proposed in this paper.
Same as above, but employing the regular swap move.
Same as above, but employing the adjacent swap move.
The baseline GA metaheuristic from
Section 4. Since GA is a probabilistic method, we have run it 10 times. The reported results are averaged over those 10 runs.
The stopping condition in all four cases was a time limit. Moreover, for each instance,
was set to the best makespan found by those four algorithms in the given time limit. The results, averaged over instances for each size group, are shown in
Table 4.
We observe that, for five size groups (marked by † in the table), the best solution was always found by the TS method employing the block swap neighborhood. In fact, this method found the best solution out of all four algorithms in 523 out of 600 instances (87.17%). Moreover, for that neighborhood did not exceed , with an average of . The most difficult instances for this neighborhood were the ones with . Without those, for that neighborhood generally did not exceed 0.43. The next best algorithm was TS with adjacent swap move, followed by TS with a swap move and then finally by the GA method. However, average values for those last three algorithms were dozens of times larger. These results indicate that the block elimination property from Theorem 2 was a deciding factor, allowing the TS method to outperform its other variants and the baseline GA method in the given time limit. Moreover, the TS method with block neighborhood converged very quickly, obtaining good solutions in under one second for instances of size up to (1000 operations), meaning 75% of all instances. However, due to average neighborhood size, the total complexity of TS method is , resulting in longer running times (up to 20 min) for largest instances. However, this is true for the remaining TS variants as well.
To verify the statistical significance of the differences between the performances of the algorithms, a Wilcoxon signed-rank test was used. The results were grouped by the instance sizes, and then the algorithms were compared pairwise for each group. With significance reported, for the majority of algorithms pairs, was rejected. The three cases where the hypothesis could not be rejected are:
group, TS with adjacent neighborhood and TS with swap neighborhood;
group, TS with block neighborhood and TS with adjacent neighborhood;
group, TS with block neighborhood and GA.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}