It is representative for 2DRP to combine heuristic placement strategies and meta-heuristic algorithms such as GA. The GA usually includes SGA and various improved genetic algorithms such as AGA. The SGA is prone to premature problems that cannot escape the local optimal solution. Then, some adaptive genetic algorithms such as AGA [
25], AGA [
26], and AGA [
29] were proposed to solve this problem. However, these also have some problems. Since the AGA [
26] is an improvement to the AGA [
25], this section mainly focuses on some problems in AGA [
26] and AGA [
29], presenting further improved AGA for 2DRP by combining heuristic placement strategy.
The packing sequence of rectangles and whether they are rotated are the most important factors that affect the results of the final packing solution. This paper proposes an improved adaptive genetic algorithm as a rectangle sequencing algorithm to determine the packing sequence and rotation state of the rectangles, with the heuristic lowest horizontal line algorithm used as the placement algorithm to determine the position coordinates of the rectangle. First of all, in terms of the genetic algorithm, two-stage encoding is constructed, i.e., the packing sequence is coded by continuous integers from 1 to , and the rotation state is coded with 0 and 1. The initial population is constructed through a combination of sorting rules and random generation. The heuristic lowest horizontal line algorithm is applied to decode, so as to provide the packing solution and calculate the individual fitness. Then, it uses a sort-based method for selection and improved adaptive crossover and mutation operations for evolution. The process of iterative optimization continues until the designed termination rule is reached, and finally, the result decoded by the optimal individual is taken as the final packing solution.
3.1. Encoding and Population Initialization
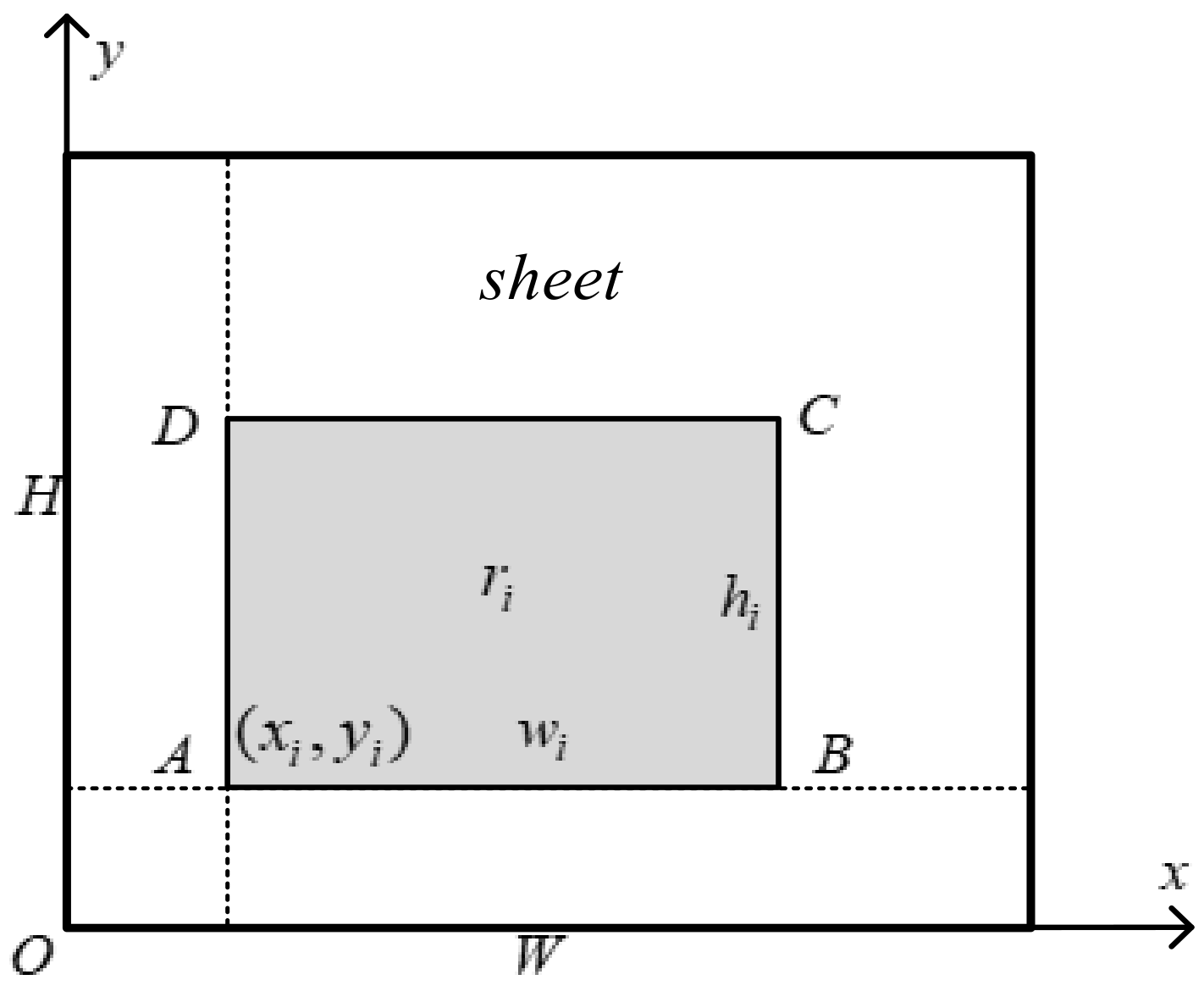
Assuming there are
rectangles
to be packed, the chromosome adopts a two-stage encoding method consisting of the packing sequence and placement state of the rectangles, and the encoding length is
. The former
uses an integer permutation code, and the packing sequence adopts integer numbers, which is the order of the rectangles to be packed. The latter
uses integer coding, and the rectangle placement status is numbered with 0 and 1, in which 1 means the placement rectangle rotates, and 0 represents that it does not rotate. So,
are the rotation state of
rectangles to be packed. The overall encoding of individual chromosomes are as follows:
where
,
, and
. For example, there are eight rectangles numbered 1, 2, 3, 4, 5, 6, 7, and 8 to be loaded into the sheet, and each rectangle can be rotated. The packing sequence and rotation status of the two-stage encoding approach for individual chromosome are shown in
Figure 2. The order of rectangular packing is 4, 2, 5, 1, 8, 6, 3, and 7, and the rectangles numbered 2, 5, 6, and 7 need to be rotated during the packing process.
The above encoding approach accurately describes the factors that affect the packing solution. Considering that the packing sequence sorted by certain attributes tends to be the optimal solution, the following sorting rules [
32] are fully utilized to generate the initial population in combination with random generation to speed up the algorithm when initializing the population.
- (1)
Sort by area in decreasing order.
- (2)
Sort by width in decreasing order.
- (3)
Sort by height in decreasing order.
- (4)
Sort by perimeter in decreasing order.
- (5)
Sort by maximum of width and height in decreasing order.
- (6)
Sort by length of diagonal + width + height in decreasing order.
Figure 3 shows the initial population constructed by
individuals. The individuals from
to
are generated randomly. The packing sequence of the remaining six individuals is generated by the six sorting rules, and the corresponding rotation state of the rectangles is generated randomly. The
is set to 100 in this paper.
Once the chromosome encoding sequence of the individuals in the population is determined, the heuristic placement algorithm can be used to decode and place, and then the individuals can be evaluated through the fitness function.
3.3. Fitness Function and Selection Operator
Generally, the fitness function of the genetic algorithm is often determined by the objective function. In this paper, the fitness function refers to the sheet filling rate of the objective function, and its definition can be seen in the 2DRP mathematical model in
Section 2.
Selection operation is the process of the genetic algorithm to evaluate the survival of the fittest. Its purpose is to keep the individuals with better fitness in the parent population as much as possible to keep good genes. The traditional roulette [
34] selection method gives every individual the opportunity to make a copy, which does not reflect the competitiveness of excellent individuals and cannot realize the principle of survival of the fittest by the genetic algorithm. This paper uses an improved selection method sorted by individual fitness [
35] to replace the roulette selection method. The sort-based selection method is described as follows:
Step1. Calculate the fitness of each individual in the population.
Step2. Sort the individuals in the population in descending order of fitness.
Step3. Divide the sorted individuals into three parts, and the first one was duplicated into two copies.
Step4. Make a copy of the individuals in the middle.
Step5. The remaining individuals ranked behind are not copied.
3.4. Adaptive Crossover Operator and Mutation Operator
This subsection gives an improved genetic algorithm, in which the crossover probability and mutation probability can be adjusted adaptively. The crossover operation is to randomly exchange some genes between two individuals in the population based on the crossover probability so as to combine excellent genes to produce new and better individuals, which is the main part of the genetic algorithm. The mutation operation is to replace genes of an individual with other alleles under a certain mutation probability, thereby forming a new individual, ensuring the diversity of the population and preventing the phenomenon of premature.
Crossover probability and mutation probability are the most important parameters for crossover and mutation operations. Their selection is the key to influencing the behavior and performance of the algorithm and directly affecting the convergence of the algorithm. Regarding the crossover probability, if the crossover probability is too small, the search process will be slow and will easily cause stagnation. However, if the crossover probability is too large, the chromosomal structure of an individual with high fitness will be quickly destroyed and replaced. For the mutation probability, if it is too small, a new individual chromosome structure is not easy to be generated, and the search space will become narrower. Otherwise, if the mutation probability is too large, the genetic algorithm becomes a purely random search algorithm, which makes it easy to fall into a local optimal solution.
The AGA [
26] proposed by Ren is to adaptively change the crossover probability and mutation probability from the local point according to individual fitness without considering whether the dynamic adjustment of crossover and mutation has a positive impact on population evolution from the whole point of population evolution. The AGA [
29] proposed by Jiang dynamically adjusts the crossover probability and mutation probability according to the fitness changes of the optimal individual from the whole point of the evolution of the population offspring. However, the crossover probability and mutation probability of all individuals of a certain generation of population are still the same, and the performance of individuals with different fitness of the generation is consistent, so there is no difference. Moreover, the AGA [
29] is greatly affected by the contemporary optimal fitness and the range of fitness function, which will limit the wide application of the algorithm.
Inspired by Ren and Jiang, this paper proposes an improved method called hybrid adaptive genetic algorithm (HAGA) to solve the 2DRP problem. The adaptive description of the crossover probability is as follows:
where
and
are the upper bound and lower bound of
. In general, the recommended parameters for these two crossover probabilities are 0.9 and 0.6 respectively [
36]; i.e.,
and
. The parameter
is the cumulative number of generations in which the optimal fitness value of the population has not changed. When the optimal fitness value of a certain generation changes, it will be set to 0 for re-accumulation. For example, in the process of iterative optimization, if the best fitness value lasts for ten times without changing, the
is set to 10. The parameter
is a constant to determine the slope of the
function, and
in the experiment.
is the fitness value of the larger individuals that are ready to implement crossover;
is the maximum fitness value of the current population;
is the average fitness value of the current population. The
is an adjustable weight parameter with the range of
, and
in the experiment.
in Formula (2) has a value range of 0–1 when
is greater than or equal to 0, which ensures that
changes between
and
. It also helps to solve the problem for AGA [
29] that is greatly affected by the contemporary optimal fitness, representing the fitness function range with appropriately adjusting
and
. It is beneficial to combine with AGA [
26]. The
is recorded after each iteration to determine the change of
. If
becomes larger, it shows that the optimal fitness of the population evolution has not changed, and the crossover probability needs to be increased to promote the change of the optimal fitness. If
, it reveals that the optimal fitness of the population evolution has increased, and the crossover probability
will drop to
for increasing more possible solutions. Then, combining Formula (3) to increase the difference of crossover operation for different individuals. Combining Formula (2) and Formula (3), it works together to find a better solution from the global perspective of population evolution and the local perspective of individual fitness. In addition, because it can increase the crossover probability from the perspective of the population evolution process, it is also helpful to overcome the problem that evolution is likely to stagnate when
is close to
. The effect of the adaptive mutation probability change in the latter part is similar to this.
When carrying out crossover, the packing sequence gene string adopts the partial matching crossover (PMX), and the rotating state gene string adopts the two-point crossover method. An example of the crossover process is shown in
Figure 4. The procedure of the hybrid adaptive crossover algorithm is described in Algorithm 2.
| Algorithm 2 Hybrid adaptive crossover algorithm |
| HACA(): |
| 1 Initialize the parameter |
| 2 Copy population from the population with individuals |
| 3 Compute with formula (2) |
| 4 Compute for |
| 5 for i in range(): |
| 6 Randomly select two different parents from |
| 7 Compute greater fitness from |
| 8 Compute with formula (3) and with formula (4) |
| 9 Generate a random number between [0, 1] with rand() function |
| 10 if : |
| 11 Generate different random numbers within and within |
| 12 Get two crossed children using the same method of Figure 4 |
| 13 Put two crossed children with Heuristic Packing Procedure |
| 14 Update using two crossed children |
| 15 Add to , Sort them in decreasing order of fitness |
| 16 Delete individuals with small fitness and get crossed population |
| 17 return crossed population |
The adaptive description of mutation probability is as follows:
where
and
are the upper bound and lower bound of
. In the experiment, these two mutation probability parameters recommended are 0.1 and 0.5 respectively [
36]; i.e.,
and
.
is the fitness value of the individual to be mutated;
is the maximum fitness value of the current population; and
is the average fitness value of the current population. For other parameters, refer to the section on adaptive crossover probability. Similarly, we can be aware that Formula (5) is the adaptive mutation probability from the whole point of population offspring evolution, and Formula (6) is the adaptive mutation probability for individual fitness from a local perspective. The hybrid adaptive mutation probability is used to work together to dynamically adjust the mutation probability.
When mutating, the packing sequence gene string adopts the exchange mutation method, and the rotating state gene string takes the two-point basic position mutation method. An example of the mutation process is shown in
Figure 5.
The procedure of the hybrid adaptive mutation algorithm is described in Algorithm 3. In Algorithms 2 and 3,
represents the population in the genetic algorithm;
means the size of the population, i.e., the number of individuals in the population; The parameter
is obtained by comparing the fitness of the best individual in the previous and next generations in the population evolution process. If the optimal individual fitness of the previous generation and the next generation are equal,
; otherwise,
is reset to 0.
| Algorithm 3 Hybrid adaptive mutation algorithm |
| HAMA(): |
| 1 Initialize the parameter |
| 2 Copy population from the population with individuals |
| 3 Compute with formula (5) |
| 4 Compute for |
| 5 for i in range(): |
| 6 Get parent from and compute its fitness |
| 7 Compute with formula (6) and with formula (7) |
| 8 Generate a random number between [0, 1] with rand() function |
| 9 if : |
| 10 Generate different random numbers within and within |
| 11 Get mutated child using the same method of Figure 5 |
| 12 Put mutated child with Heuristic Packing Procedure |
| 13 Update using mutated child |
| 14 Add to , Sort them in decreasing order of fitness |
| 15 Delete individuals with small fitness and get mutated population |
| 16 return mutated population |
In summary, Algorithm 2 plays a role of constructing the hybrid adaptive crossover algorithm (HACA) and Algorithm 3 structures the hybrid adaptive mutation algorithm (HAMA), which are two main parts of HAGA. From the local aspect of individual fitness and the whole evolution of later generations’ population, the crossover probability and mutation probability can be adjusted adaptively to quickly find a further improved solution.
3.5. Termination Rules
The improved adaptive genetic algorithm we proposed shows a convergence trend in the process of searching and optimizing the solution space. For the iterative optimization calculation of 2DRP problem, there are the following termination rules:
(1) After the iterative calculation reaches a certain level, the optimal fitness value has no obvious change in the continuous iterations, and the calculation can be stopped in advance. For example, the is set to 150 in this paper, which means the calculation is terminated if the optimal fitness value does not change through 150 continuous iterations;
(2) Set the desired packing rate in advance. In the process of calculating, the pre-set filling rate is reached, and the calculation can be terminated early. For the expected filling rate, if the theoretical filling rate is known before the experiment, e.g., the theoretical filling rate of the
benchmark instances proposed by Hopper is 100% [
18], it can be set to the theoretical value; otherwise, the user’s expected value can be set according to actual needs;
(3) Set the maximum number of iterations in advance. If the algorithm does not terminate prematurely, when the genetic algebra reaches the maximum number of iterations, the calculation is terminated, and the packing solution and filling rate are obtained.
The combination of the above three termination rules can not only fully optimize within the maximum number of iterations but also terminate the iterative optimization of the algorithm early when the expected value or fitness value is reached and there is no obvious change, which is beneficial to reduce the calculation time of the algorithm. When the iterative optimization of the algorithm is terminated, the packing solution corresponding to the chromosome with the largest fitness value is the optimal packing solution, and the corresponding filling rate is calculated.
3.6. Related Discussion
The proposed algorithm firstly overcomes the problem that is greatly affected by the contemporary optimal fitness and fitness function range for AGA [
29] to expand its application; especially, the fitness function range is not between 0 and 1. Moreover, this algorithm not only obtains the differential performance of a certain generation of individuals by combining AGA [
26] but also handles the impact of dynamic changes on population evolution to find adaptively an improved solution. However, the presented algorithm is not perfect in this paper; it has the following drawbacks:
(1) There are some parameters that need to be controlled, including , , , , , and . The , , , and may be obtained through existing experience. It is necessary to do sets of comparative experiments to establish consistent parameters , to obtain good benefits.
(2) From Formulas (2) and (5), if , it can be concluded that suddenly drops to the minimum of crossover probability and mutation probability and . In the early stage of evolution, the optimal individual is easy to change frequently; that is, there are more times where , which leads to lower crossover probability and mutation probability that are not beneficial to rapid population evolution.
We can set up a series and to determine the appropriate parameters through many experiments. In addition, it is possible for to make continuous descent changes for different evolutionary periods.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}