Hybrid-Recursive Feature Elimination for Efficient Feature Selection


Abstract
1. Introduction
2. Materials and Methods
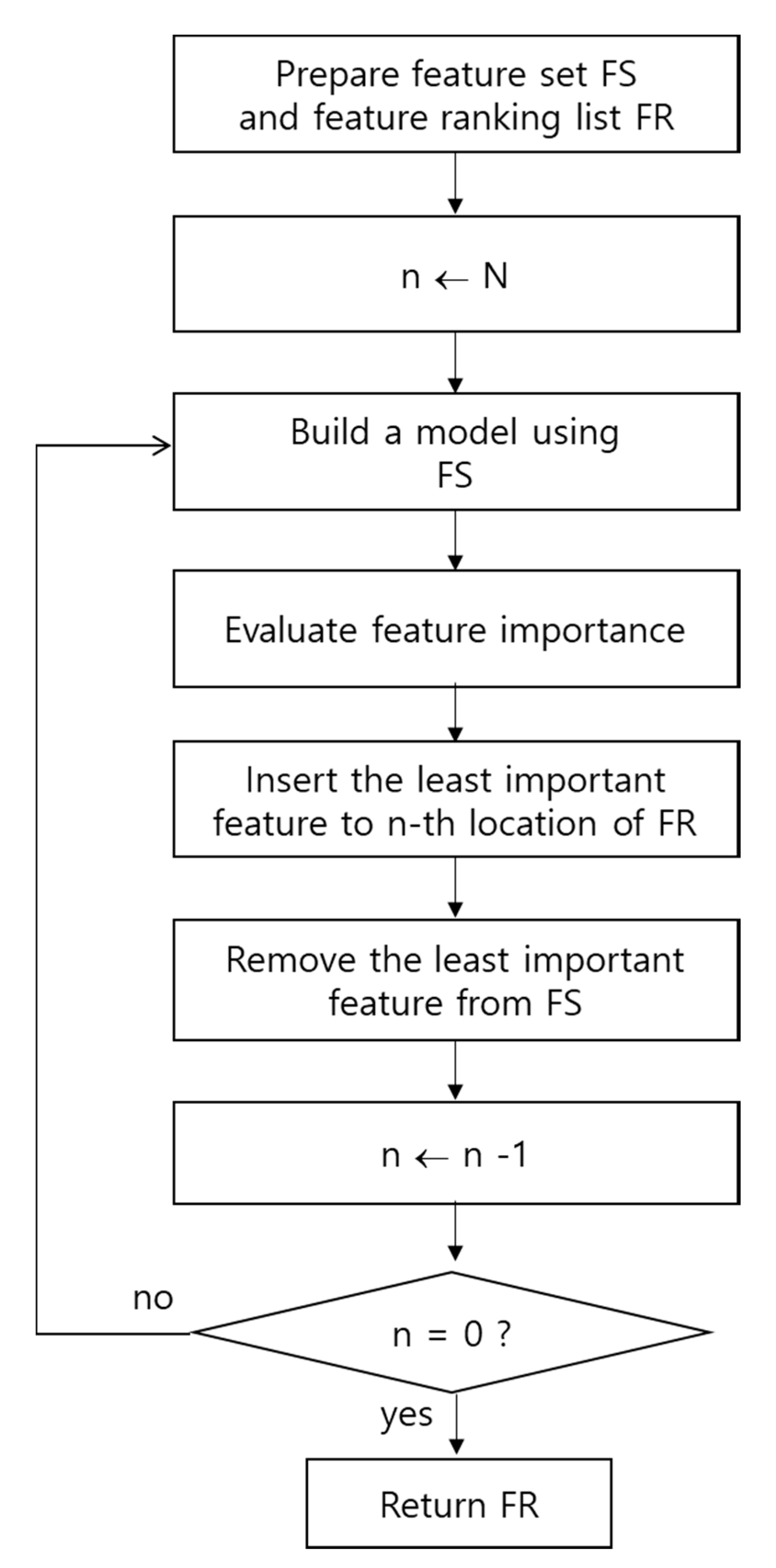
2.1. Idea of Hybrid Recursive Feature Elimination
2.2. Hybrid Method: Simple Sum
2.3. Hybrid Method: Weighted Sum
3. Results
3.1. Datasets
3.2. Experiments
3.3. Experimental Results
4. Discussion
Supplementary Materials
Author Contributions
Funding
Conflicts of Interest
References
- Tang, J.; Alelyani, S.; Liu, H. Feature Selection for Classification: A Review; Chapman and Hall/CRC: New York, NY, USA, 2014; pp. 37–64. [Google Scholar] [CrossRef]
- Bellman, R. Dynamic Programming, 6th ed.; Princeton Univ. Press: Prinston, NJ, USA, 1957; p. 4. [Google Scholar]
- Kumar, V.; Minz, S. Feature selection: A literature review. SmartCR 2014, 4, 211–229. [Google Scholar] [CrossRef]
- Tang, J.; Alelyani, S.; Liu, H. Feature selection for classification: A review. Data Class Algor. Appl. 2014, 37, 1–29. [Google Scholar]
- Bolón-Canedo, V.; Sánchez-Marono, N.; Alonso-Betanzos, A.; Benítez, J.M.; Herrera, F. A review of microarray datasets and applied feature selection methods. Inform. Sci. 2014, 282, 111–135. [Google Scholar] [CrossRef]
- Ang, J.C.; Mirzal, A.; Haron, H.; Hamed, H.N.A. Supervised, unsupervised, and semi-supervised feature selection: A review on gene selection. IEEE/ACM Trans. Comput. Biol. Bioinform. 2015, 13, 971–989. [Google Scholar] [CrossRef] [PubMed]
- Saeys, Y.; Inza, I.; Larrañaga, P. A review of feature selection techniques in bioinformatics. Bioinformatics 2007, 23, 2507–2517. [Google Scholar] [CrossRef] [PubMed]
- Liu, H.; Motoda, H. Computational Methods of Feature Selection; Chapman and Hall/CRC: New York, NY, USA, 2007. [Google Scholar]
- Liu, H.; Yu, L. Toward integrating feature selection algorithms for classification and clustering. IEEE Trans. Knowl. Data Eng. 2005, 17, 491. [Google Scholar]
- Guyon, I.; Weston, J.; Barnhill, S.; Vapnik, V. Gene selection for cancer classification using support vector machines. Mach. Learn. 2002, 46, 389–422. [Google Scholar] [CrossRef]
- Duan, K.B.; Rajapakse, J.C.; Wang, H.; Azuaje, F. Multiple SVM-RFE for gene selection in cancer classification with expression data. IEEE Trans. Nanobiosci. 2005, 4, 228–234. [Google Scholar] [CrossRef] [PubMed]
- Mundra, P.A.; Rajapakse, J.C. SVM-RFE with MRMR filter for gene selection. IEEE Trans. Nanobiosci. 2009, 9, 31–37. [Google Scholar] [CrossRef] [PubMed]
- Zhou, X.; Tuck, D.P. MSVM-RFE: Extensions of SVM-RFE for multiclass gene selection on DNA microarray data. Bioinformatics 2007, 23, 1106–1114. [Google Scholar] [CrossRef] [PubMed]
- Tang, Y.; Zhang, Y.Q.; Huang, Z. Development of two-stage SVM-RFE gene selection strategy for microarray expression data analysis. IEEE/ACM Trans. Comput. Biol. Bioinform. 2007, 4, 365–381. [Google Scholar] [CrossRef] [PubMed]
- Ding, Y.; Wilkins, D. Improving the performance of SVM-RFE to select genes in microarray data. BMC Bioinform. 2006, 7, S12. [Google Scholar] [CrossRef] [PubMed]
- Granitto, P.M.; Furlanello, C.L.; Biasioli, F.; Gasperi, F. Recursive feature elimination with random forest for PTR-MS analysis of agroindustrial products. Chemom. Intell. Lab. Syst. 2006, 83, 83–90. [Google Scholar] [CrossRef]
- Hierpe, A. Computing Random Forests Variable Importance Measures (VIM) on Mixed Continuous and Categorical Data. Master’s Thesis, KTH Royal Institute of Technology, Stockholm, Sweden, 2016. [Google Scholar]



{kind=link}
{kind=link}
| No. | Dataset | # of Observations | # of Features | # of Classes |
|---|---|---|---|---|
| 1 | satellite | 6435 | 36 | 6 |
| 2 | messidor | 351 | 33 | 2 |
| 3 | sonar | 208 | 60 | 2 |
| 4 | messidor | 1151 | 20 | 2 |
| 5 | GDS1027 | 154 | 1000 | 4 |
| 6 | GDS2546 | 167 | 1000 | 4 |
| 7 | GDS2547 | 164 | 1000 | 4 |
| 8 | GDS3715 | 109 | 1000 | 3 |
| Classifier | R package |
|---|---|
| KNN | class |
| SVM | e1071 |
| RF | randomForest |
| NB | e1071 |
| Dataset | Algorithm | Accuracy | RFE Methods | ||||
|---|---|---|---|---|---|---|---|
| on Entire Feature Set | SVM-RFE | RF-RFE | GBM-RFE | Hybrid-RFE (SS) 1 | Hybrid-RFE (WS) 2 | ||
| satellite | KNN | 0.904 | 0.904 (36) | 0.904 (36) | 0.904 (36) | 0.907 (31) | 0.904 (31) |
| SVM | 0.898 | 0.899 (27) | 0.898 (36) | 0.898 (36) | 0.898 (35) | 0.899 (31) | |
| RF | 0.918 | 0.919 (36) | 0.919 (36) | 0.919 (36) | 0.919 (36) | 0.919 (33) | |
| NB | 0.773 | 0.778 (24) | 0.773 (36) | 0.783 (11) | 0.785 (18) | 0.780 (10) | |
| ionosphere | KNN | 0.855 | 0.904 (19) | 0.915 (12) | 0.901 (21) | 0.906 (10) | 0.918 (12) |
| SVM | 0.949 | 0.951 (21) | 0.939 (33) | 0.949 (33) | 0.952 (28) | 0.958 (23) | |
| RF | 0.923 | 0.938 (33) | 0.938 (27) | 0.929 (32) | 0.932 (26) | 0.933 (27) | |
| NB | 0.724 | 0.781 (12) | 0.858 (12) | 0.808 (10) | 0.849 (13) | 0.835 (11) | |
| sonar | KNN | 0.815 | 0.856 (32) | 0.831 (28) | 0.859 (30) | 0.854 (28) | 0.840 (39) |
| SVM | 0.824 | 0.815 (55) | 0.821 (31) | 0.836 (48) | 0.843 (52) | 0.825 (44) | |
| RF | 0.811 | 0.833 (54) | 0.820 (29) | 0.833 (57) | 0.846 (27) | 0.850 (44) | |
| NB | 0.753 | 0.746 (42) | 0.769 (33) | 0.753 (60) | 0.770 (42) | 0.763 (35) | |
| messidor | KNN | 0.615 | 0.647 (10) | 0.644 (10) | 0.637 (16) | 0.652 (11) | 0.633 (10) |
| SVM | 0.710 | 0.710 (19) | 0.710 (19) | 0.710 (19) | 0.710 (19) | 0.710 (19) | |
| RF | 0.690 | 0.702 (11) | 0.697 (11) | 0.689 (19) | 0.709 (11) | 0.699 (15) | |
| NB | 0.610 | 0.610 (18) | 0.610 (19) | 0.613 (16) | 0.610 (19) | 0.610 (19) | |
| GDS1027 | KNN | 0.812 | 0.802 (962) | 0.807 (789) | 0.803 (732) | 0.833 (680) | 0.825 (637) |
| SVM | 0.565 | 0.552 (68) | 0.547 (361) | 0.540 (52) | 0.532 (360) | 0.545 (103) | |
| RF | 0.623 | 0.633 (943) | 0.625 (971) | 0.628 (791) | 0.631 (978) | 0.656 (477) | |
| NB | 0.475 | 0.511 (218) | 0.528 (804) | 0.530 (896) | 0.537 (798) | 0.572 (132) | |
| GDS2546 | KNN | 0.629 | 0.667 (684) | 0.697 (12) | 0.661 (95) | 0.685 (161) | 0.668 (11) |
| SVM | 0.706 | 0.730 (155) | 0.712 (63) | 0.731 (266) | 0.727 (140) | 0.732 (44) | |
| RF | 0.719 | 0.712 (847) | 0.761 (25) | 0.725 (13) | 0.718 (11) | 0.742 (125) | |
| NB | 0.711 | 0.743 (61) | 0.729 (637) | 0.740 (540) | 0.746 (246) | 0.748 (46) | |
| GDS2547 | KNN | 0.64 | 0.644 (680) | 0.632 (932) | 0.660 (907) | 0.656 (257) | 0.689 (231) |
| SVM | 0.607 | 0.648 (708) | 0.653 (421) | 0.637 (870) | 0.653 (55) | 0.644 (84) | |
| RF | 0.672 | 0.679 (852) | 0.678 (951) | 0.704 (377) | 0.685 (884) | 0.689 (498) | |
| NB | 0.69 | 0.704 (806) | 0.680 (848) | 0.705 (265) | 0.698 (395) | 0.699 (814) | |
| GDS3715 | KNN | 0.799 | 0.821 (244) | 0.804 (50) | 0.813 (191) | 0.837 (347) | 0.804 (92) |
| SVM | 0.816 | 0.848 (133) | 0.846 (125) | 0.854 (691) | 0.863 (110) | 0.863 (317) | |
| RF | 0.816 | 0.848 (917) | 0.849 (761) | 0.840 (742) | 0.847 (505) | 0.861 (306) | |
| NB | 0.652 | 0.773 (841) | 0.773 (971) | 0.775 (716) | 0.775 (488) | 0.790 (87) | |
| SVM-RFE | RF-RFE | GBM-RFE | Hybrid-RFE (ss) | Hybrid-RFE (ws) |
|---|---|---|---|---|
| 2 | 4 | 4 | 10 | 11 |
| SVM-RFE | RF-RFE | GBM-RFE | Hybrid-RFE (ss) | Hybrid-RFE (ws) |
|---|---|---|---|---|
| 570 | 545 | 509 | 401 | 250 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jeon, H.; Oh, S. Hybrid-Recursive Feature Elimination for Efficient Feature Selection. Appl. Sci. 2020, 10, 3211. https://doi.org/10.3390/app10093211
Jeon H, Oh S. Hybrid-Recursive Feature Elimination for Efficient Feature Selection. Applied Sciences. 2020; 10(9):3211. https://doi.org/10.3390/app10093211
Chicago/Turabian StyleJeon, Hyelynn, and Sejong Oh. 2020. "Hybrid-Recursive Feature Elimination for Efficient Feature Selection" Applied Sciences 10, no. 9: 3211. https://doi.org/10.3390/app10093211
APA StyleJeon, H., & Oh, S. (2020). Hybrid-Recursive Feature Elimination for Efficient Feature Selection. Applied Sciences, 10(9), 3211. https://doi.org/10.3390/app10093211