1. Introduction
In recent years, the rapid rise of deep learning methods has become the most popular research topic. Deep learning methods have been widely used in classification [
1,
2,
3], identification [
4,
5,
6], and target segmentation [
7,
8,
9]. Deep learning methods are superior to traditional image processing methods, as they do not require the user to determine the capture of image features. They can extract features in images through self-learning of convolutional and pooling layers in a network. Therefore, automatic learning the interested features from the training images is considered to be a good method to replace the features selected by the user. The most typical example is the feature learning and recognition through the convolutional neural network (CNN). LeCun et al. proposed the first CNN architecture, LeNet-5 [
10], and applied this network to the handwriting recognition in the MNIST dataset. The used images are grayscale, and the size of each image is 32 × 32. The recognition accuracy of LeNet-5 is better than those of other traditional image processing methods. Krizhevsky et al. [
11] proposed AlexNet and introduced GPU into deep learning. They also added Dropout [
12] and ReLu [
13] to the deep neural network architecture to improve its recognition accuracy. Szegedy et al. [
14] proposed GoogleNet, and introduced the “Inception” structure into the network. The proposed inception is to increase the breadth of the network—that is, use different convolution kernel sizes to extract different features. In [
14], they also used a 1 × 1 convolution operation to reduce the dimension, which can improve the accuracy when the network reduces the parameters. He et al. [
15] proposed the residual structure to directly map the features of the lower layer to the higher-level network—that is, the deeper network has the representation capabilities close to the previous layers. Therefore, in the deep CNN, the difficult trained problem of the network can be effectively solved.
In the above-mentioned methods, the convolutional neural network uses only a single input. Therefore, some researchers began to study multi-input convolutional neural networks. Su et al. [
16] proposed a multi-view CNN for the classification of 3D models. By shooting 3D models, two-dimensional pictures with different perspectives were taken as network inputs. Sun et al. [
17] used a multi-input CNN for flower grading. They used three different flower images as inputs, and fused the features through convolution and pooling operations. Li et al. [
18] developed a dual-input neural network architecture for detecting coronary artery disease (CAD). They used Electrocardiogram and Phonocardiogram signals as input of the network to extract different signal characteristics. Two signal characteristics are combined to improve the accuracy of classification. These results prove that multi-input CNNs can effectively improve the classification accuracy, and have a better performance than single-input CNNs.
Using multi-input CNNs will provide different features, and the advantage of each network feature to improve the accuracy of the entire system is an extremely important task. How to properly integrate these different features is an important issue, as the individual features obtained by multiple networks have different interpretations of the same image. Some features obtained can allow the network to determine the correct result, and some features obtained can also cause serious misjudgment. In order to solve this problem, a multi-layer network fusion mechanism [
19] is added to the output of a feature network, which partially enhances or suppresses each of the original output features to perform a fusion operation. Thus, multiple features can cooperate with each other and improve the overall recognition rate. In multi-input CNNs, feature fusion techniques such as summation operation [
20], product operation [
21], maximum operation [
22] and concatenation operation [
23] are often used. Feature fusion is the integration of multiple different feature information in order to obtain more prominent feature information. Different feature fusion methods will produce different performances. Choosing a reasonable fusion method has important value for improving accuracy.
In the above-mentioned networks, the parameters designed by the user are not the optimal parameters of CNNs. How to determine a convolutional neural network architecture and its parameters requires continuous experimentation to learn. In the engineering field, there are two common methods for optimizing parameters: the first is the Taguchi method [
24,
25], and the second is the uniform experimental design (UED) [
26,
27]. If it is applied to more factors and levels, the number of experiments is at least the square of the level. The UED has fewer experiments, and then uses multiple regression to find the best parameters in the shortest time.
In this study, the feature fusion and parameter optimization of a dual-input CNN is proposed for the application of face gender classification. In order to improve the traditional feature fusion method, a new feature fusion method, called the weighting fusion method, is proposed and will effectively improve the overall accuracy. In addition, in order to avoid the parameters of the traditional CNN being determined by the user, this paper uses a UED instead of the user to set the network parameters. Two data sets, including CIA and MORPH data sets, are used to evaluate the proposed method.
The remainder of the paper is organized as follows:
Section 2 introduces the proposed dual-input CNN with the feature fusion of weighting operation and the parameter optimization of UED;
Section 3 illustrates the experimental results of a dual-input CNN using the CIA and MORPH datasets; and
Section 4 offers conclusions and future works in this study.
2. The Dual-Input Convolutional Neural Network
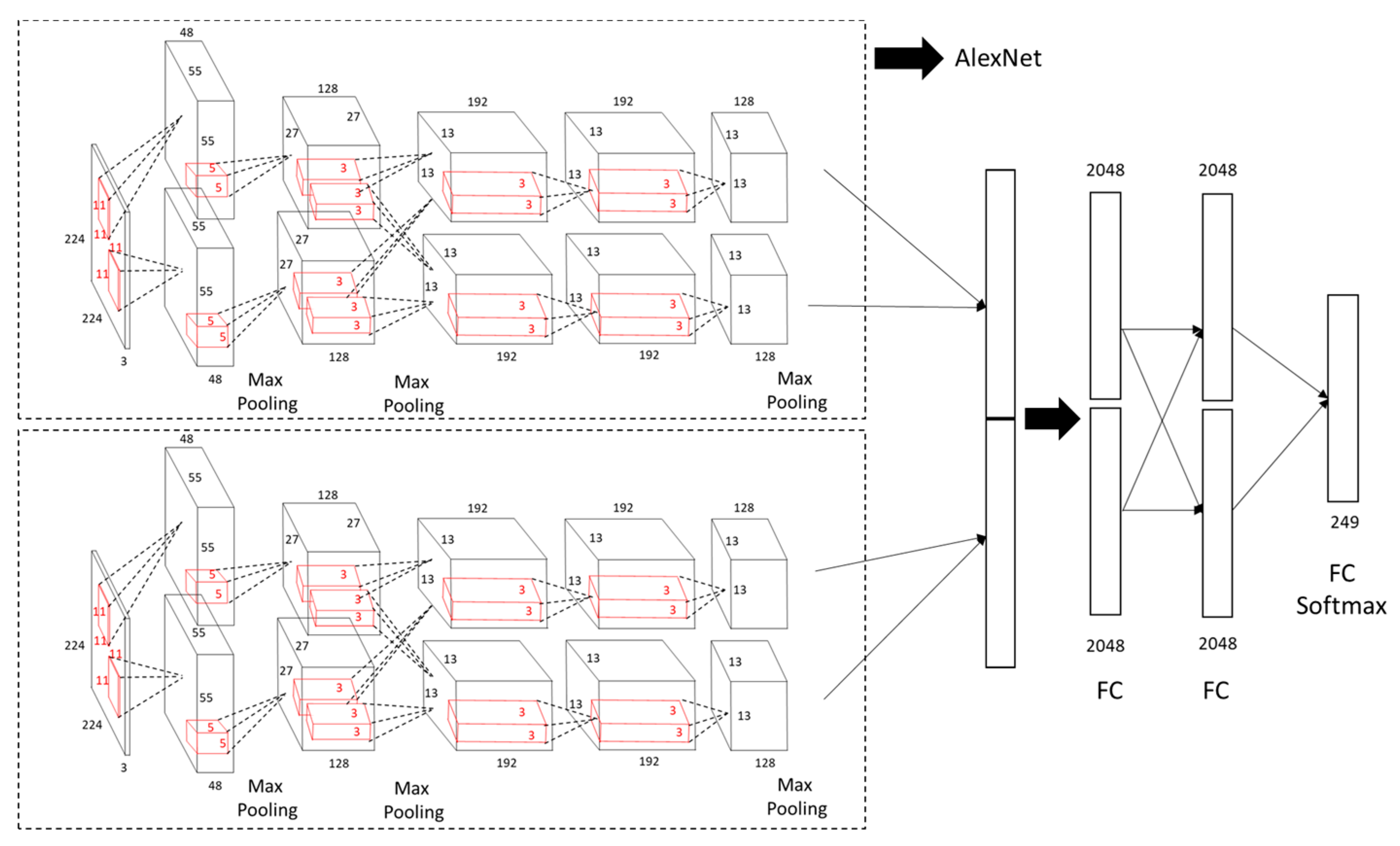
In this section, the dual-input convolutional neural network (Dual-input CNN) is introduced and shown in
Figure 1. The proposed dual-input CNN can arbitrarily construct its feature extraction network. Three well-known CNN architectures commonly used by users are LeNet, AlexNet and GoogleNet. AlexNet has two main characteristics: the first point is the use of a non-linear activation function-ReLU with faster convergence speed; and the second point is that using Dropout in the first and second fully connected layers can effectively reduce the overfitting problem. However, more complex problems still cannot be solved. Although GoogleNet can solve more complex problems, it has a very deep architecture and requires a long training time. Based on the above analysis, this study uses AlexNet with a moderate architecture length as the feature extraction network architecture. In the dual-input CNN, two feature extraction AlexNet results are used for data fusion and then passed to the subsequent fully connected layer.
With regard to data fusion, this study proposes a weighting fusion method that assigns higher weights to strong feature inputs. The weighting fusion result is obtained more effectively than the concatenation method, sum method, product method and maximum method. Fusion function is the fusion of two feature maps and at time t. is the fused feature value. The different fusion methods will be described as follows.
2.1. The Basic Convolutional Neural Network Architecture
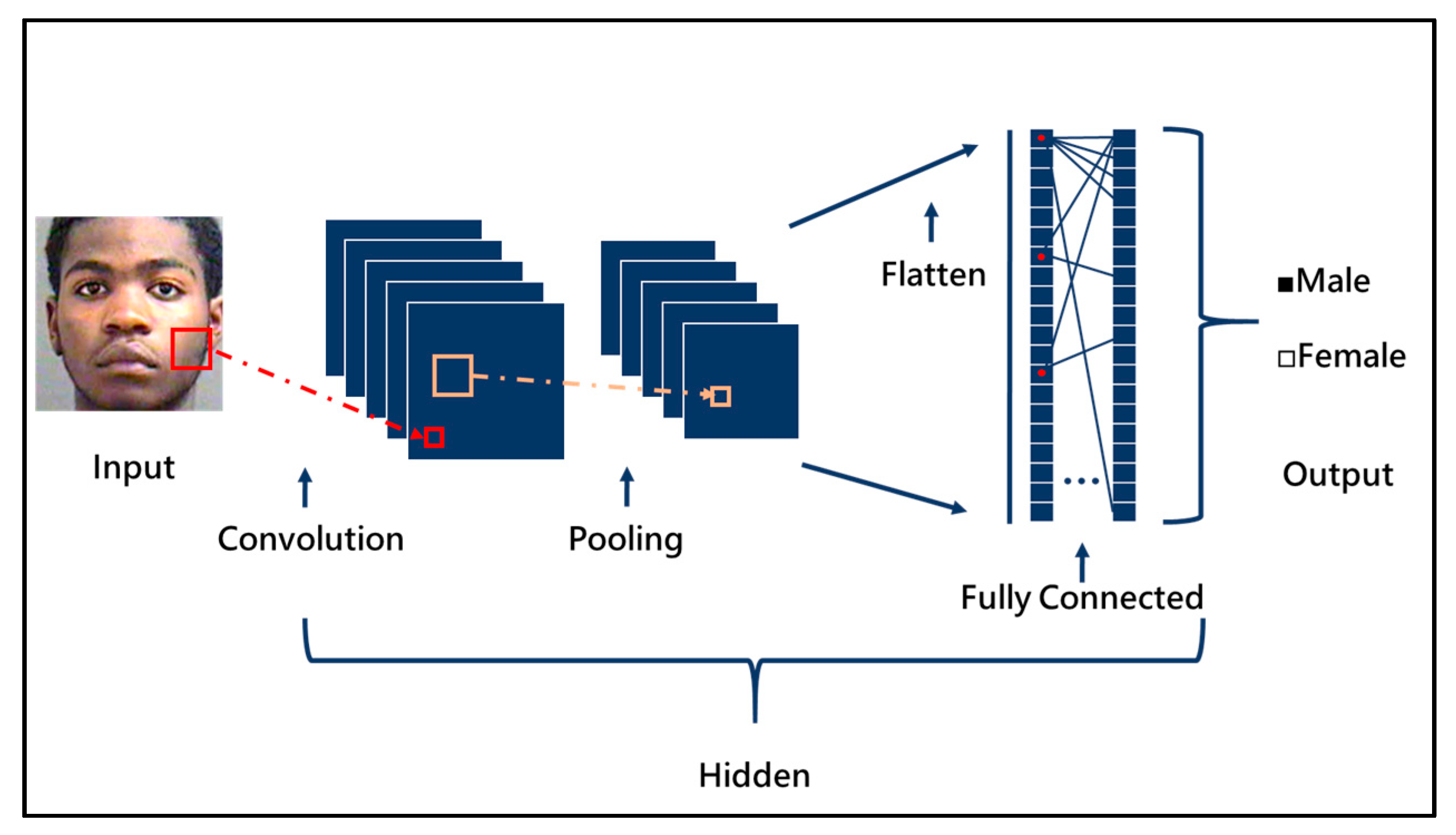
The basic CNN architecture is shown in
Figure 2. It is mainly divided into four parts: a convolution layer; pooling layer; fully connected layer; and activation function. In CNN, the convolutional layer, pooling layer and activation function are mainly used for feature extraction, and the fully connected network classifies the obtained features. The four layers will be described below.
The following subsections describe the three important operations in the feature extraction section, namely convolution, activation function and pooling.
2.1.1. Convolution Layer
The convolution mainly uses the mask of the convolution kernel to perform the convolution operation on the input matrix by the sliding window method. The output matrix obtained has a relative relationship with the convolution kernel size, stride size and padding size of the input matrix. The output matrix is shown in the following formula
where
and
are the height and width of the output matrix, respectively;
and
are the height and width of the input matrix, respectively;
is the number of padding cycles; and
s is the stride during the convolution kernel operation.
2.1.2. Pooling Layer
Pooling is mainly used to reduce the data dimension without losing too much important information. There are two common pooling calculation methods. The first is maximum pooling, which takes the maximum value in the mask as an output, and the others are not calculated. The second is average pooling. The output is the average of all values in the mask.
2.1.3. Fully Connected Layer
A fully connected layer is a fully connected multi-layer neural network. All feature maps are converted into a one-dimensional array as the network input of the fully connected layer. Finally, the fully connected neural network is used for classification or prediction.
2.1.4. Activation Function
The activation function is divided into linear functions and non-linear functions. Non-linear functions have better representation capabilities than linear functions. Therefore, non-linear functions are more commonly used in general neural networks. Currently, ReLU is more commonly used as a non-linear function. The ReLU function is shown in the following formula:
If the input x is greater than 0, the output is x; otherwise, the output is 0.
2.2. Network Parameter Optimization Using Uniform Experimental Design
The uniform experimental design (UED) uses multiple regression to find the optimal parameters. The steps of UED will be explained as follows:
Step 1: Determine the affecting factor. Here, a convolutional neural network is taken as an example, as shown in
Figure 2. In the two convolutional layers, the affecting factors are selected as the convolution kernel size, step size and padding size. There are six affecting factors in total.
After completing the factor selection and parameter setting, determine the number of experiments according to the following equation
where
n is the number of experiments and
S is the number of affecting factors. The number of affecting factors
S is set to 6. If the number of experiments is less than 12, the uniformity will be poor. Therefore, the number of experiments is set to 13.
Step 2: After obtaining the number of experiments, use the following formula to calculate the total number of rows in the uniform table
where
m is the total number of columns. Then, calculate the table information in the uniform table according to the following formula
.
where
and
. According to a uniform table
,
m and n are set as 12 and 13. The initial uniform table is shown in
Table 1.
Step 3: According to the initial uniform table, select the usage table of
, as shown in
Table 2. If the affecting factor is 6, select the 1, 2, 6, 8, 9 and 10 columns. The results are shown in the grey background of
Table 1.
Step 4: Experiment and record the results.
Step 5: Find optimization parameters using multiple regression analysis
where
is error. When ε approaches 0, it means that its coefficient is the optimal weight. Then use this optimal weight to find the optimization parameter, and obtain the optimal parameter result of UED.
is the number of affecting factors.
is the constant, and
are the coefficient of
.
2.3. Feature Fusion Methods
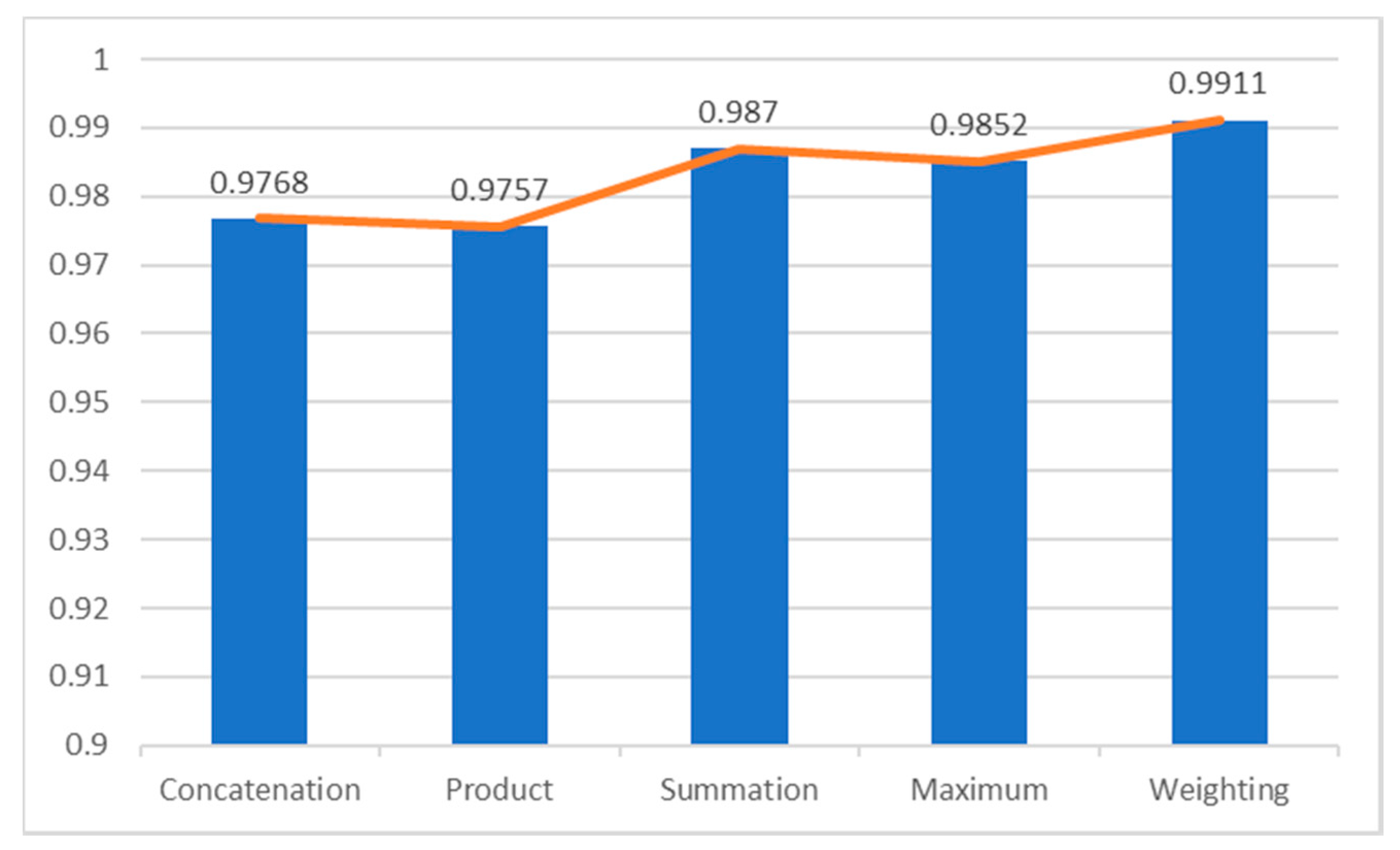
This subsection will introduce five feature fusion methods, namely the traditional concatenation method, the summation method, the product method, the maximum method and the proposed weighting fusion method. In terms of feature fusion methods, the traditional concatenation method is different from the other four methods. When two images are input as an example, the traditional method has twice the input dimensions of the full connection network as the other four methods do.
2.3.1. The Traditional Concatenation Method
The concatenation function is
. When two images are input as an example, the outputs of two feature extraction networks are concatenated—that is, it is to stack different feature elements together. The detailed calculation is as follows:
2.3.2. Summation Method
The summation function is
. It calculates the same spatial position
i and
j of each element in each feature, and the two feature maps on the feature channel
d are added according to the corresponding relationship. The detailed calculation is as follows:
2.3.3. Product Method
The product function is
. It calculates the product of the two feature maps according to the corresponding relationship. At the same time, multiple sets of dot product fusion results are used as the final fusion output. The detailed calculation is as follows:
2.3.4. Maximum Method
Similar to the product function, the maximum function is
. This uses the elements in the two feature maps for comparison, and takes the large value as the output result. The detailed calculation is as follows:
2.3.5. Proposed Weighting Method
The proposed weighting function is
. It uses the backpropagation learning method of the neural network to determine the input with a high degree of influence, and multiplies this input by the appropriate weight (
) ratio. The range of the two weights is between 0 and 1, and the sum of the weights is 1. The detailed calculation is as follows:
4. Conclusions
In this study, the feature fusion and parameter optimization of a dual-input convolutional neural network (Dual-input CNN) is proposed to achieve face gender classification. A new weighting fusion method is proposed, which replaces the traditional feature fusion methods. Both the MORPH and the CIA data sets are used for verifying the face gender classification. Experimental results prove that the average accuracy of the proposed method in the MORPH dataset and the CIA dataset is 99.11% and 99.98%, respectively, and its performance is also better than the traditional feature fusion method. In addition, in the MORPH data set, combined with the proposed weighting fusion method and uniform experimental design (UED) to find the optimal parameter structure, the experimental results prove that the average accuracy of the MORPH data set reaches 99.26%, which is significantly higher 0.13% than when the UED method is not used.
However, there are inevitably limitations on the proposed dual-input CNN. For example, only the first and fifth convolution layers are used as affecting factors, and a dual-input CNN is discussed in this study. Therefore, how to properly select the affecting factors and a multi-input CNN will be considered in future works.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}