Prediction of High Capabilities in the Development of Kindergarten Children

 ,
, 

Abstract
1. Introduction
2. Materials and Methods
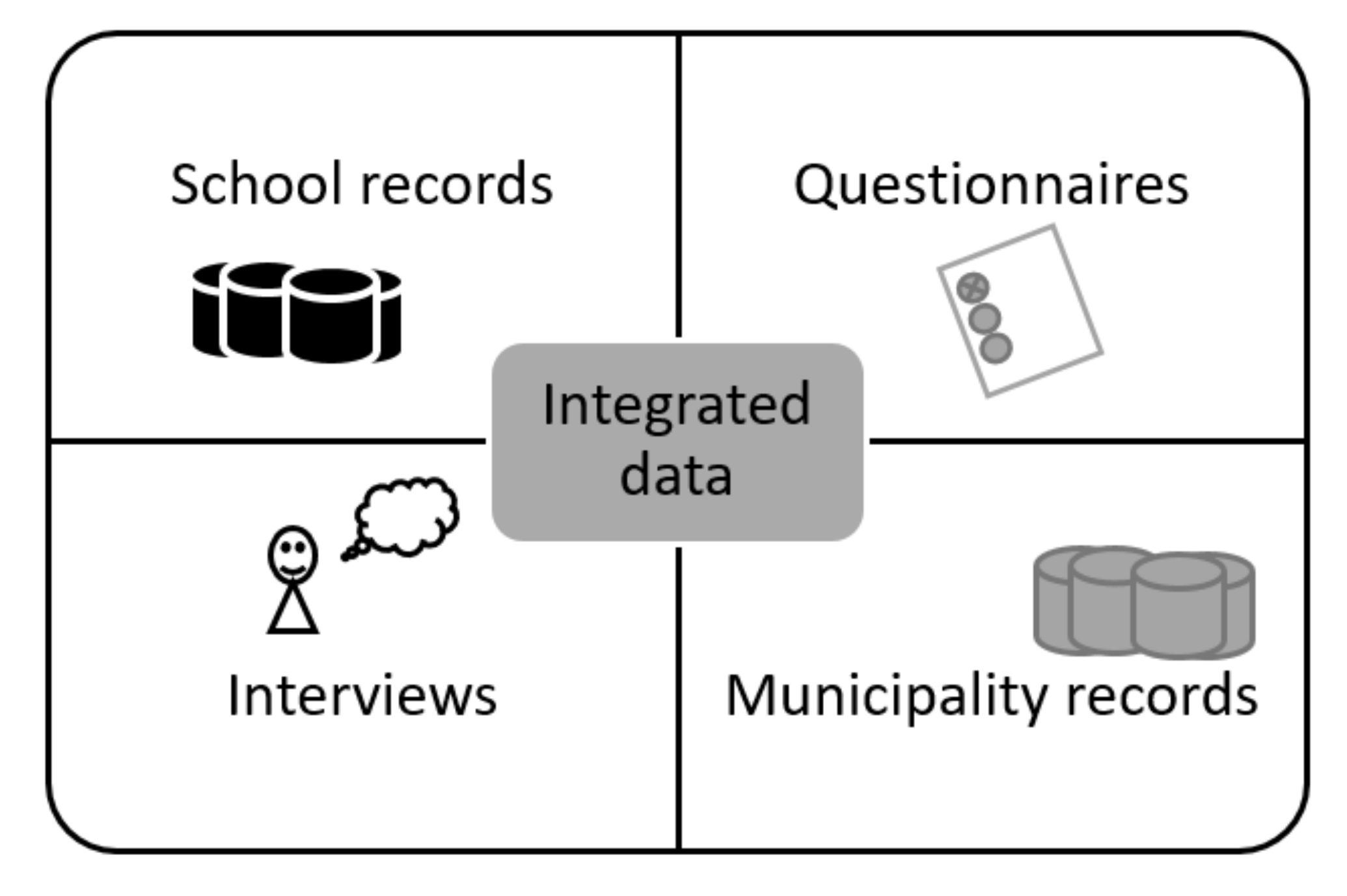
2.1. The Kindergarten Children Data
2.2. Data Mining Algorithms
3. Data Preprocessing
3.1. Fundamentals of Rough Set Theory
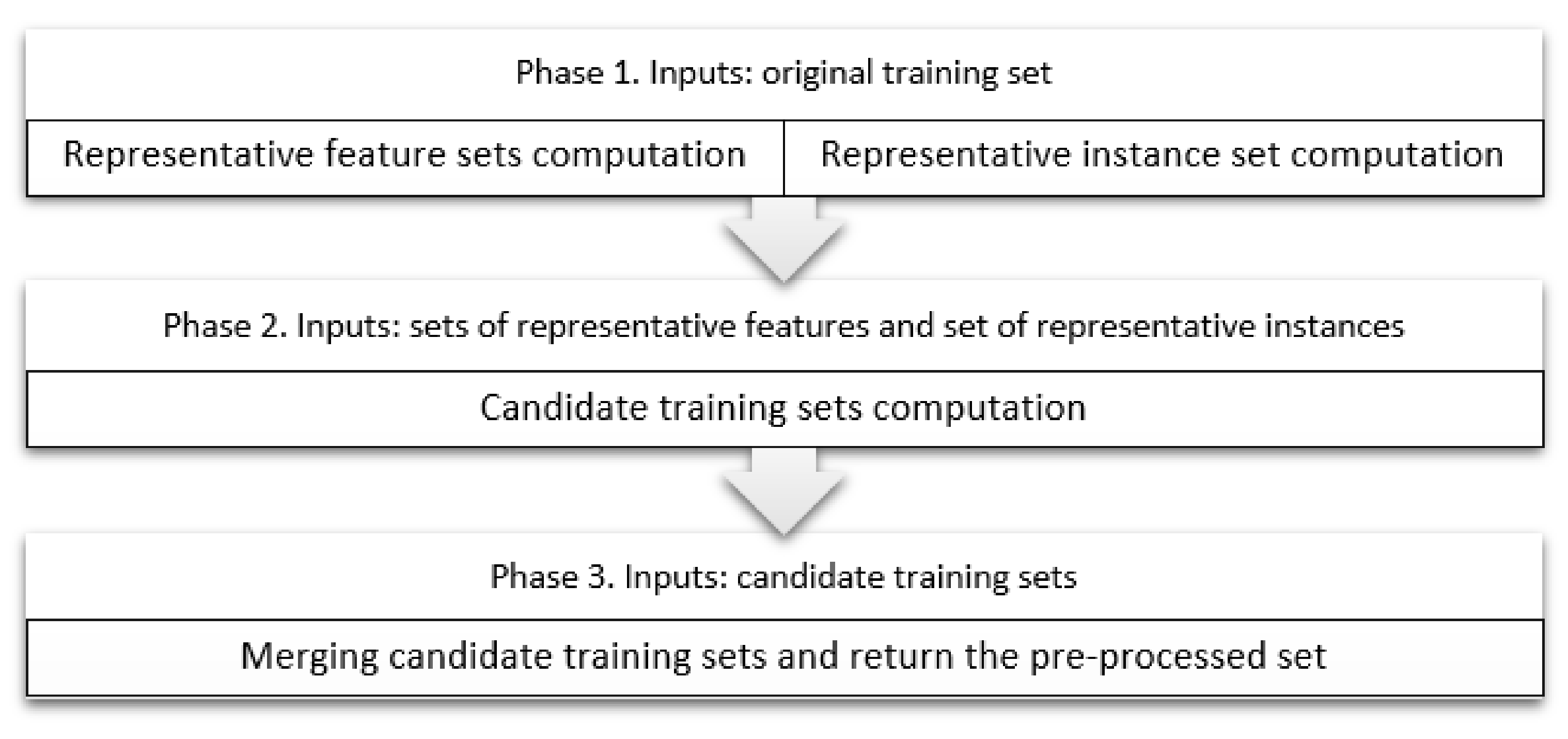
3.2. Proposed Preprocessing Technique
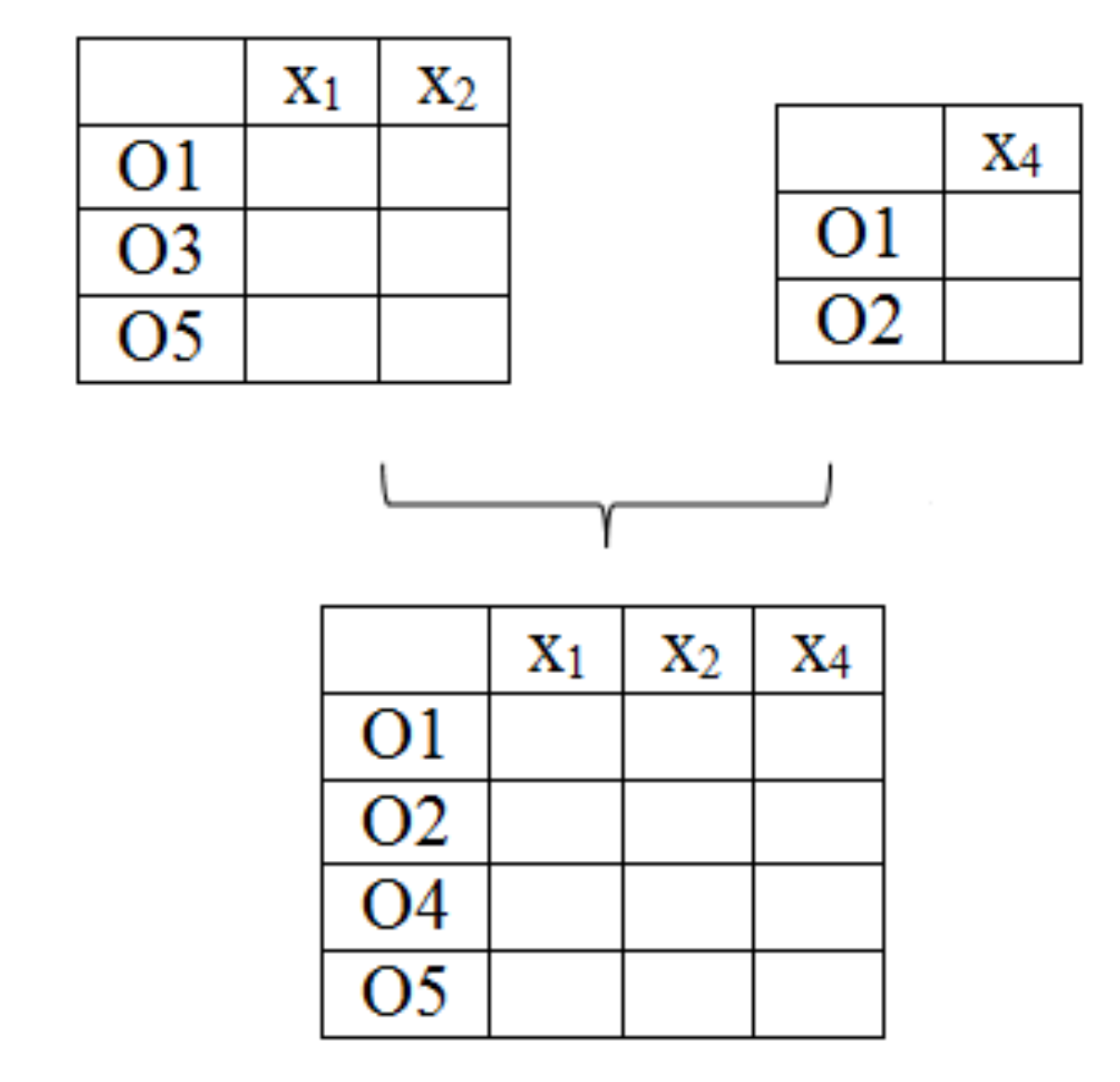
3.2.1. Parallel Computation of Relevant Features and Instances
- (a)
- (b)
- (c)
- Every isolated instance is a degenerated compact set.
| Algorithm 1. Pseudocode of the proposed algorithm. |
| Algorithm to compute the representative instance set |
| Inputs: training set X |
| Output: representative set C |
Steps:
|
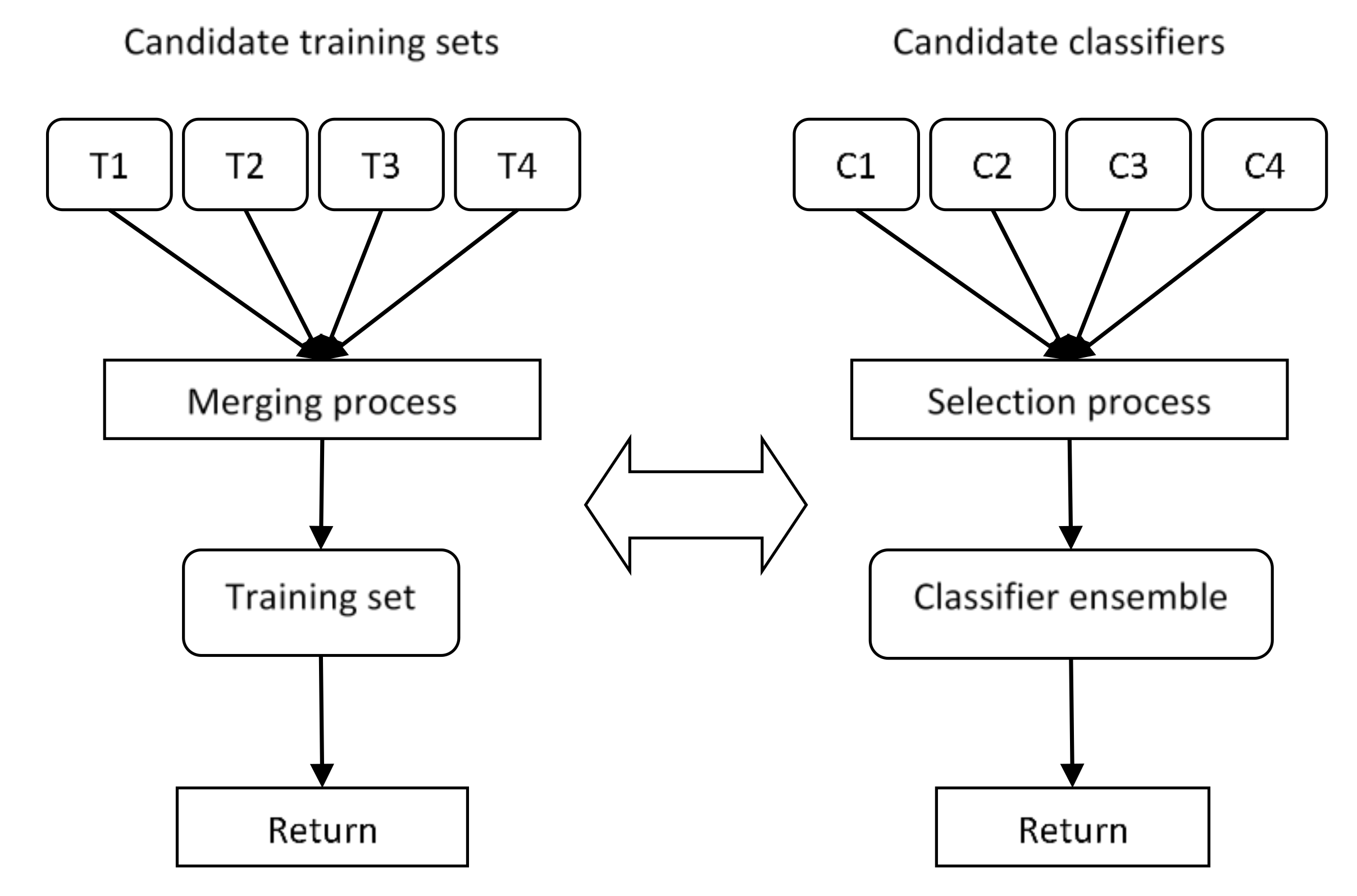
3.2.2. Computation of Candidate Training Sets
3.2.3. Merging of Candidate Training Sets
| Algorithm 2. Pseudocode of the proposed merging strategy. |
| Merging of candidate training sets |
| Inputs: Φ: correlation measure, T: set of candidate training sets, O: original training set Output: preprocessed training set |
Steps:
|
4. Results and Discussion
4.1. Results for Educational Data
4.2. Results for Repository Data
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Smutny, J.F.; Walker, S.Y.; Meckstroth, E.A. Teaching Young Gifted Children in the Regular Classroom: Indentifying, Nurturing, and Challenging Ages; Free Spirit Publishing: Minneapolis, MN, USA, 1997. [Google Scholar]
- Mooij, T. Designing instruction and learning for cognitively gifted pupils in preschool and primary school. Int. J. Incl. Educ. 2013, 17, 597–613. [Google Scholar] [CrossRef][Green Version]
- Dal Forno, L.; Bahia, S.; Veiga, F. Gifted amongst Preschool Children: An Analysis on How Teachers Recognize Giftedness. Int. J. Technol. Incl. Educ. 2015, 5, 707–715. [Google Scholar] [CrossRef]
- Sternberg, R.J.; Ferrari, M.; Clinkenbeard, P.; Grigorenko, E.L. Identification, instruction, and assessment of gifted children: A construct validation of a triarchic model. Gift. Child Q. 1996, 40, 129–137. [Google Scholar] [CrossRef]
- Calero, M.D.; García-Martin, M.B.; Robles, M.A. Learning potential in high IQ children: The contribution of dynamic assessment to the identification of gifted children. Learn. Individ. Differ. 2015, 21, 176–181. [Google Scholar] [CrossRef]
- Walsh, R.L.; Kemp, C.R.; Hodge, K.A.; Bowes, J.M. Searching for Evidence-Based Practice A Review of the Research on Educational Interventions for Intellectually Gifted Children in the Early Childhood Years. J. Educ. Gift. 2012, 35, 103–128. [Google Scholar] [CrossRef]
- Callahan, C.M.; Hertberg-Davis, H.L. Fundamentals of Gifted Education: Considering Multiple Perspectives; Taylor & Francis: Abingdon, UK, 2013. [Google Scholar]
- Karnes, M.B. The Underserved: Our Young Gifted Children; The Council for Exceptional Children, Publication Sales: Reston, VA, USA, 1983. [Google Scholar]
- Cline, S.; Schwartz, D. Diverse Populations of Gifted Children: Meeting Their Needs in the Regular Classroom and Beyond; Merrill/Prentice Hall: Old Tappan, NJ, USA, 1999. [Google Scholar]
- Webb, J.T. Nurturing Social Emotional Development of Gifted Children; ERIC, Clearinghouse: Reston, VA, USA, 1994. [Google Scholar]
- Galbraith, J.; Delisle, J. When Gifted Kids Don’t Have All the Answers: How to Meet Their Social and Emotional Needs; Free Spirit Publishing: Minneapolis, MN, USA, 2015. [Google Scholar]
- Cover, T.M.; Hart, P.E. Nearest Neighbor pattern classification. IEEE Trans. Inf. Theory 1967, 13, 21–27. [Google Scholar] [CrossRef]
- Villuendas-Rey, Y.; Rey-Benguría, C.; Caballero-Mota, Y.; García-Lorenzo, M.M. Improving the family orientation process in Cuban Special Schools through Nearest Prototype Classification. Int. J. Artif. Intell. Interact. Multimed. Spec. Issue Artif. Intell. Soc. Appl. 2013, 2, 12–22. [Google Scholar]
- Pawlak, Z. Rough Sets. Int. J. Inf. Comput. Sci. 1982, 11, 341–356. [Google Scholar] [CrossRef]
- Martínez-Trinidad, J.F.; Ruiz-Shulcloper, J.; Lazo-Cortés, M.S. Structuralization of universes. Fuzzy Sets Syst. 2000, 112, 485–500. [Google Scholar] [CrossRef]
- Renzulli, J.S.; Reis, S.M. Identification of Students for Gifted and Talented Programs; Corwin Press: Thousand Oaks, CA, USA, 2004. [Google Scholar]
- Duda, R.O.; Hart, P.E.; Stork, D.G. Pattern Classification; John Wiley & Sons: Hoboken, NJ, USA, 2001. [Google Scholar]
- Garía-Laencina, P.J.; Sancho-Gómez, J.-L.; Figueiras-Vidal, A.R. Pattern classification with missing data: A review. Neural Comput. Appl. 2010, 19, 263–282. [Google Scholar] [CrossRef]
- Derrac, J.; Cornelis, C.; García, S.; Herrera, F. Enhancing evolutionary instance selection algorithms by means of fuzzy rough set based feature selection. Inf. Sci. 2012, 186, 73–92. [Google Scholar] [CrossRef]
- Chen, Y.; Zhu, Q.; Xu, H. Finding rough set reducts with fish swarm algorithm. Knowl. Based Syst. 2015, 81, 22–29. [Google Scholar] [CrossRef]
- Villuendas-Rey, Y.; Caballero-Mota, Y.; García-Lorenzo, M.M. Using Rough Sets and Maximum Similarity Graphs for Nearest Prototype Classification. Lect. Notes Comput. Sci. 2012, 7441, 300–307. [Google Scholar]
- Santiesteban, Y.; Pons-Porrata, A. LEX: A new algorithm to calculate typical testors. Math. Sci. J. 2003, 21, 31–40. [Google Scholar]
- García-Borroto, M.; Ruiz-Shulcloper, J. Selecting Prototypes in Mixed Incomplete Data. Lect. Notes Comput. Sci. 2005, 3773, 450–459. [Google Scholar]
- Kuncheva, L.I. Combining Pattern Classifiers. Methods and Algorithms; John Wiley & Sons: Hoboken, NJ, USA, 2004. [Google Scholar]
- Orrite, C.; Rodríguez, M.; Martínez, F.; Fairhurst, M. Classifier Ensemble Generation for the Majority Vote Rule. Lect. Notes Comput. Sci. 2008, 5197, 340–347. [Google Scholar]
- Kuncheva, L.I.; Whitaker, C.J. Measures of diversity in classifier ensembles and their relationship with the ensemble accuracy. Mach. Learn. 2003, 51, 181–207. [Google Scholar] [CrossRef]
- Bradley, A.P. The use of the area under the ROC curve in the evaluation of machine learning algorithms. Pattern Recognit. 1997, 30, 1145–1159. [Google Scholar] [CrossRef]
- Tsai, C.-F.; Eberle, W.; Chu, C.-Y. Genetic algorithms in feature and instance selection. Knowl. Based Syst. 2013, 39, 240–247. [Google Scholar] [CrossRef]
- Ishibuchi, H.; Nakashima, T. Evolution of reference sets in nearest neighbor classification. In Simulated Evolution and Learning; Springer: Berlin, Germany, 1998; pp. 82–89. [Google Scholar]
- Kuncheva, L.I.; Jain, L.C. Nearest neighbor classifier: Simultaneous editing and feature selection. Pattern Recognit. Lett. 1999, 20, 1149–1156. [Google Scholar] [CrossRef]
- Ahn, H.; Kim, K.-J.; Han, I. A case-based reasoning system with the two-dimensional reduction technique for customer classification. Expert Syst. Appl. 2007, 32, 1011–1019. [Google Scholar] [CrossRef]
- Villuendas-Rey, Y.; García-Borroto, M.; Ruiz-Shulcloper, J. Selecting features and objects for mixed and incomplete data. Lect. Notes Comput. Sci. 2008, 5197, 381–388. [Google Scholar]
- Lichman, M. UCI Machine Learning Repository; School of Information and Computer Science, University of California: Irvine, CA, USA, 2013; Available online: http://archive.ics.uci.edu/ml (accessed on 10 April 2020).
- Wilson, R.D.; Martinez, T.R. Improved Heterogeneous Distance Functions. J. Artif. Intell. Res. 1997, 6, 1–34. [Google Scholar] [CrossRef]
- Demsar, J. Statistical comparison of classifiers over multiple datasets. J. Mach. Learn. Res. 2006, 7, 1–30. [Google Scholar]
- Fernandez, A.; LóPez, V.; Galar, M.; Del Jesus, M.J.; Herrera, F. Analysing the classification of imbalanced data-sets with multiple classes: Binarization techniques and ad-hoc approaches. Knowl. Based Syst. 2013, 42, 97–110. [Google Scholar] [CrossRef]
- Witten, I.H.; Frank, E.; Trigg, L.E.; Hall, M.A.; Holmes, G.; Cunningham, S.J. Weka: Practical Machine Learning Tools and Techniques with Java Implementations; Department of Computer Science, University of Waikato: Hamilton, New Zealand, 1999. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Group | No. | Name | Description |
|---|---|---|---|
| 1 | 1 | age | Age, in months, of the child (from 56 to 68 months) |
| 2 | sex | Gender of the child (Male/Female) | |
| 3 | family | Whether the family encourages the child’s development (Yes/No) | |
| 4 | antecedents | Whether there exists a history of high potential in the family (Yes/No) | |
| 5 | prior education | Did the child receive previous educational attention? (Yes/No) | |
| 6 | performance | Quality of the teacher’s performance (Very good/Good/Average) | |
| 2 | 7 | nutrition | The nutritional status of the child (Well nurtured/Poorly nurtured) |
| 8 | environment | How is the environment, neighborhood or place where the child is growing up (Socially challenging/Average/ Favorable) | |
| 9 | house | Condition of the dwelling where the child lives (Good/Average/Bad) | |
| 10 | hygiene | Hygiene conditions of the dwelling (Good/Poor) | |
| 11 | lifestyle | Lifestyle of the family (Healthy/Unhealthy) | |
| 3 | 12 | originality | Does the child like to be different or non-repetitive? (Yes/No) |
| 13 | help | Does the child like to help other children with their tasks, in addition to its own? (Yes/No) | |
| 14 | quality | The quality of the child’s schoolwork (Very good/Good/Average/Poor) | |
| 15 | speed | The speed with which the child works (Fast/Average/Slow) | |
| 4 | 16 | activity | Is the child active and energetic? (Yes/No) |
| 17 | relationships | Does the child enjoy the company of its peers or does it prefer to be alone? (Socializes well/Usually alone) | |
| 18 | adult | Whether the child prefers the company of an adult over being with other children (Yes/No) | |
| 19 | play | Interest and participation of the child in collective play (High/Low) | |
| 5 | 20 | curiosity | Whether the child is curious and likes to learn new things (Yes/No) |
| 21 | interest | Whether the child shows interest in its surroundings (Yes/No) | |
| 22 | boredom | Is the child easily bored when faced with easy tasks? (Yes/No) | |
| 23 | self-esteem | The degree of self-esteem that the child has (High/Low) | |
| 24 | superiority | Does the child feel superior to his peers? (Yes/No) |
| Quick | Average | Slow | |
|---|---|---|---|
| Quick | 0 | 0.5 | 1 |
| Average | 0.5 | 0 | 0.5 |
| Slow | 1 | 0.5 | 0 |
| Very Good | Good | Regular | Bad | |
|---|---|---|---|---|
| Very Good | 0 | 0.1 | 0.4 | 1 |
| Good | 0.1 | 0 | 0.2 | 0.7 |
| Regular | 0.4 | 0.2 | 0 | 0.6 |
| Bad | 1 | 0.7 | 0.6 | 0 |
| Very Good | Good | Average | |
|---|---|---|---|
| Very Good | 0 | 0.4 | 1 |
| Good | 0.4 | 0 | 0.4 |
| Average | 1 | 0.6 | 0 |
| Favorable | Average | Socially Challenging | |
|---|---|---|---|
| Favorable | 0 | 0.5 | 1 |
| Average | 0.5 | 0 | 0.5 |
| Socially challenging | 1 | 0.5 | 0 |
| Good | Average | Bad | |
|---|---|---|---|
| Good | 0 | 0.7 | 1 |
| Average | 0.3 | 0 | 0.5 |
| Bad | 1 | 0.6 | 0 |
| Classified as | ||
|---|---|---|
| Examples | Positive | Negative |
| Positive | True positive (tp) | False negative (fn) |
| Negative | False positive (fp) | True negative (tn) |
| Algorithm | Parameters |
|---|---|
| AKH-GA | Iterations: 20 Population count: 200 individuals Crossover probability: 0.7 Mutation probability: 0.1 per bit |
| EIS-RFS | MAX_EVALUATIONS: 10,000 Population count: 50 Crossover probability: 1.0 Mutation probability: 0.005 per bit a: 0.5, b: 0.75 MaxGamma: 1.0 UpdateFS: 100 |
| IN-GA | Iterations: 500 Population count: 50 individuals Crossover probability: 1.0 Mutation probability for features: 0.01 per bit Mutation probability for instances: and |
| KJ-GA | Iterations: 100 Population count: 10 individuals Crossover probability: 1.0 Mutation probability: 0.1 per bit |
| TCCS | No user-defined parameter |
| Algorithm | ONN | TCCS | EIS-RFS | AKH-GA | IN-GA | KJ-GA | FIS-SM |
|---|---|---|---|---|---|---|---|
| AUC | 0.94 | 0.94 | 0.93 | 0.87 | 0.64 | 0.76 | 0.95 |
| Instance Reduction | 0.00 | 0.70 | 0.44 | 0.45 | 0.21 | 0.68 | 0.93 |
| Feature Reduction | 0.00 | 0.52 | 0.00 | 0.71 | 0.52 | 0.43 | 0.73 |
| Datasets | Nominal Attributes | Numeric Attributes | Instances | Classes | Missing Values | Imbalance Ratio |
|---|---|---|---|---|---|---|
| breast-w | 0 | 9 | 699 | 2 | 1.90 | |
| credit-a | 9 | 6 | 690 | 2 | x | 1.25 |
| diabetes | 0 | 8 | 768 | 2 | 1.87 | |
| heart-c | 7 | 6 | 303 | 5 | x | 1.20 |
| hepatitis | 13 | 6 | 155 | 2 | x | 3.87 |
| labor | 6 | 8 | 57 | 2 | 1.86 | |
| wine | 0 | 13 | 178 | 3 | x | 1.47 |
| zoo | 16 | 1 | 101 | 7 | 10.46 |
| Datasets | ONN | TCCS | EIS-RFS | AKH-GA | IN-GA | KJ-GA | FIS-SM |
|---|---|---|---|---|---|---|---|
| breast-w | 0.94 | 0.94 | 0.95 | 0.94 | 0.91 | 0.91 | 0.96 |
| credit-a | 0.81 | 0.78 | 0.78 | 0.79 | 0.64 | 0.63 | 0.85 |
| diabetes | 0.68 | 0.58 | 0.65 | 0.64 | 0.63 | 0.60 | 0.69 |
| heart-c | 0.70 | 0.69 | 0.77 | 0.64 | 0.63 | 0.60 | 0.71 |
| hepatitis | 0.63 | 0.71 | 0.63 | 0.79 | 0.73 | 0.76 | 0.76 |
| tic-tac-toe | 0.76 | 0.73 | 0.53 | 0.75 | 0.70 | 0.84 | 0.79 |
| wine | 0.96 | 0.41 | 0.96 | 0.81 | 0.82 | 0.83 | 0.96 |
| zoo | 0.97 | 0.90 | 0.97 | 0.80 | 0.71 | 0.81 | 0.95 |
| Datasets | TCCS | EIS-RFS | AKH-GA | IN-GA | KJ-GA | FIS-SM |
|---|---|---|---|---|---|---|
| breast-w | 0.32 | 0.02 | 0.50 | 0.47 | 0.46 | 0.25 |
| credit-a | 0.51 | 0.01 | 0.49 | 0.49 | 0.48 | 0.32 |
| diabetes | 0.58 | 0.01 | 0.49 | 0.47 | 0.48 | 0.28 |
| heart-c | 0.59 | 0.01 | 0.49 | 0.47 | 0.48 | 0.30 |
| hepatitis | 0.56 | 0.03 | 0.51 | 0.43 | 0.46 | 0.30 |
| labor | 0.75 | 0.07 | 0.52 | 0.51 | 0.48 | 0.39 |
| wine | 0.95 | 0.04 | 0.51 | 0.45 | 0.45 | 0.37 |
| zoo | 0.52 | 0.05 | 0.49 | 0.49 | 0.47 | 0.12 |
| Datasets | TCCS | EIS-RFS | AKH-GA | IN-GA | KJ-GA | FIS-SM |
|---|---|---|---|---|---|---|
| breast-w | 1.00 | 1.00 | 0.62 | 0.40 | 0.49 | 1.00 |
| credit-a | 0.87 | 1.00 | 0.58 | 0.39 | 0.45 | 0.87 |
| diabetes | 1.00 | 1.00 | 0.63 | 0.31 | 0.40 | 1.00 |
| heart-c | 0.81 | 1.00 | 0.63 | 0.31 | 0.40 | 0.83 |
| hepatitis | 0.67 | 1.00 | 0.60 | 0.43 | 0.54 | 0.73 |
| labor | 0.53 | 0.49 | 0.41 | 0.44 | 0.49 | 0.53 |
| wine | 0.73 | 0.88 | 0.52 | 0.44 | 0.45 | 0.73 |
| zoo | 0.43 | 0.12 | 0.44 | 0.43 | 0.54 | 0.43 |
| Pair | Avg_Acc | Instance Retention | Feature Retention | |||
|---|---|---|---|---|---|---|
| w–l–t | Probability | w–l–t | Probability | w–l–t | Probability | |
| FIS-SM vs. ONN | 6-1-1 | 0.075 | 8-0-0 | 0.012 | 6-2-0 | 0.270 |
| FIS-SM vs. TCCS | 6-2-0 | 0.012 | 8-0-0 | 0.012 | 0-2-6 | 0.180 |
| FIS-SM vs. EIS-RFS | 5-2-1 | 0.176 | 0-8-0 | 0.012 | 4-2-2 | 0.463 |
| FIS-SM vs. AKH-GA | 7-1-0 | 0.025 | 8-0-0 | 0.012 | 1-7-0 | 0.017 |
| FIS-SM vs. IN-GA | 7-1-0 | 0.012 | 8-0-0 | 0.012 | 0-7-1 | 0.018 |
| FIS-SM vs. KJ-GA | 6-2-0 | 0.034 | 8-0-0 | 0.012 | 1-7-0 | 0.025 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Villuendas-Rey, Y.; Rey-Benguría, C.F.; Camacho-Nieto, O.; Yáñez-Márquez, C. Prediction of High Capabilities in the Development of Kindergarten Children. Appl. Sci. 2020, 10, 2710. https://doi.org/10.3390/app10082710
Villuendas-Rey Y, Rey-Benguría CF, Camacho-Nieto O, Yáñez-Márquez C. Prediction of High Capabilities in the Development of Kindergarten Children. Applied Sciences. 2020; 10(8):2710. https://doi.org/10.3390/app10082710
Chicago/Turabian StyleVilluendas-Rey, Yenny, Carmen F. Rey-Benguría, Oscar Camacho-Nieto, and Cornelio Yáñez-Márquez. 2020. "Prediction of High Capabilities in the Development of Kindergarten Children" Applied Sciences 10, no. 8: 2710. https://doi.org/10.3390/app10082710
APA StyleVilluendas-Rey, Y., Rey-Benguría, C. F., Camacho-Nieto, O., & Yáñez-Márquez, C. (2020). Prediction of High Capabilities in the Development of Kindergarten Children. Applied Sciences, 10(8), 2710. https://doi.org/10.3390/app10082710