Medical Instructed Real-Time Assistant for Patient with Glaucoma and Diabetic Conditions

 , , and
, , and
Abstract
1. Introduction
- We introduced the MIRA that identifies a disease based on user’s chief complaint, understands single and multiple intent statements about a specific medical condition, and generates an appropriate response.
- We added an identity and access manager, a session manager, and security event logging and monitoring to the MIRA architecture. These provide strong authentication, manage the conversational state, and monitor the system for anomalies, respectively.
- We created a dataset of 816 patient chief complaints that were manually validated under the supervision of medical specialists, and were classified into glaucoma, diabetes, and other labels under the broad category of diseases.
- We designed stock phrases from the recorded 816 dialogue corpora that contain 11,532 utterances. Each utterance was manually annotated for intent and context identification.
- We evaluated MIRA based on a performance measure (including accuracy, precision, sensitivity, specificity, and f-measure), task completion, security, and user experience.
2. Related Work
2.1. Finite State Assistants
2.2. Frame-Based Assistants
2.3. Limitations of Existing Studies
- None of the existing studies considered security as a primary factor except [30], which uses the traditional PIN-based authentication mechanism [40], and it is vulnerable to brute-force attack [41]. The virtual medical assistant interacts with users and gathers health-related information. The leakage of such information may lead to different attacks such as masquerading, and ransomware [42,43]. Moreover, commercially available applications such as Your.MD [21], and Sensely [22] only comply with the security standards.
- Most of the existing studies along with commercially available virtual medical assistants analyze the input symptoms, and either provide a list of specific diseases or relevant information [44]. None of the existing spoken dialogue-based system considered patient chief complaint corpora for disease prediction or medical advice.
- Limited studies focused on frame-based assistants due to various challenges such as intent identification, context awareness, and appropriate response generation. However, it provides interactions in a natural way (i.e., similar to humans) and keeps the user motivated to continue the conversation [45].
2.4. Medical Awareness Survey
3. Methodology
3.1. MIRA System Architecture
3.2. Understanding the MIRA Digital Brain
3.3. Case Study
4. Evaluation
4.1. Experimental Setup
4.2. Performance Evaluation
- Accuracy identifies the effectiveness of an algorithm based on the probability of true values as stated in Equation (1). MIRA gets an overall accuracy of 89.8% because it correctly identified 90.9% glaucoma (30), 84.8% diabetes (28), and 93.9% other (31) labels among the recorded dialogue corpus (99).
- Precision or confidence presents the positive predictive value of a label that can be derived using Equation (2). We obtained the precision for each label including glaucoma (88.24%), diabetes (93.33%), and other (88.57%), with an average precision of 90%.
- Sensitivity (also known as recall) corresponds to the true positive rate of a specific label and can be computed with Equation (3) for glaucoma (90.91%), diabetes (84.85%), and other (93.94%), with an average value of 89.8%.
- Specificity corresponds to the true negative rate and can be computed using Equation (4) for a specific label for glaucoma (93.94%), diabetes (96.97%), and other (93.94%), with an average value of 94.9%.
- The F-measure, also known as F-score or F1-score, is the weighted harmonic mean of precision and sensitivity (recall) as stated in Equation (5). The F-Measures for each label in MIRA were as follows: glaucoma (89.55%), diabetes (88.89%), and other (91.18%), with an average value of 89.8%.We used that evenly balances the F-score based on precision and sensitivity.
4.3. Task Completion
4.4. Security
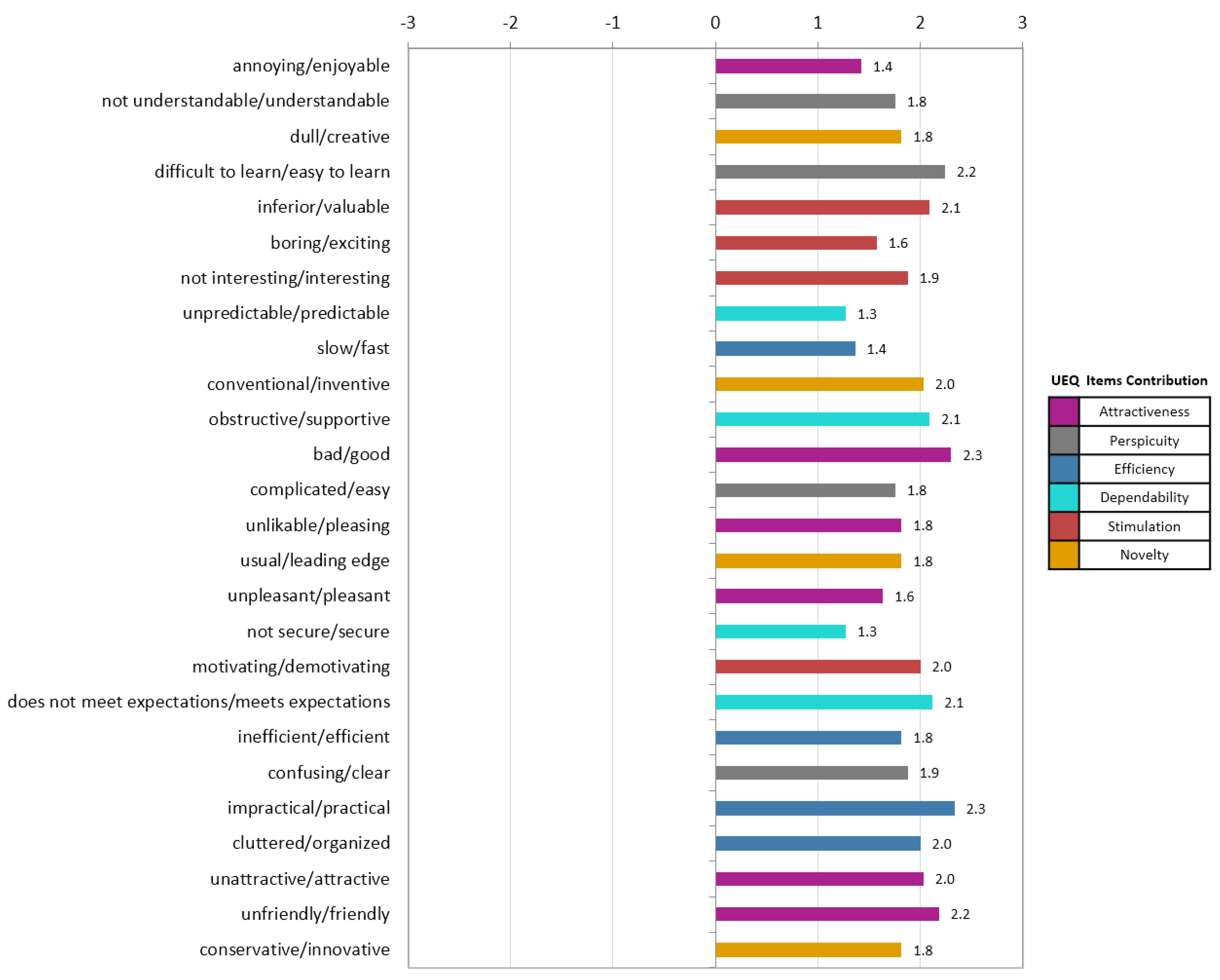
4.5. User Experience
4.6. Discussion
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Canbek, N.G.; Mutlu, M.E. On the track of artificial intelligence: Learning with intelligent personal assistants. J. Hum. Sci. 2016, 13, 592–601. [Google Scholar] [CrossRef]
- Van Os, M.; Saddler, H.J.; Napolitano, L.T.; Russell, J.H.; Lister, P.M.; Dasari, R. Intelligent Automated Assistant for TV User Interactions. U.S. Patent 9,338,493, 2016. [Google Scholar]
- Bartie, P.; Mackaness, W.; Lemon, O.; Dalmas, T.; Janarthanam, S.; Hill, R.L.; Dickinson, A.; Liu, X. A dialogue based mobile virtual assistant for tourists: The SpaceBook Project. Comput. Environ. Urban Syst. 2018, 67, 110–123. [Google Scholar] [CrossRef]
- Page, L.C.; Gehlbach, H. How an artificially intelligent virtual assistant helps students navigate the road to college. AERA Open 2017, 3. [Google Scholar] [CrossRef]
- Lam, M.S. Keeping the Internet Open with an Open-Source Virtual Assistant. In Proceedings of the 24th Annual International Conference on Mobile Computing and Networking; ACM: New York, NY, USA, 2018; pp. 145–146. [Google Scholar]
- Austerjost, J.; Porr, M.; Riedel, N.; Geier, D.; Becker, T.; Scheper, T.; Marquard, D.; Lindner, P.; Beutel, S. Introducing a Virtual Assistant to the Lab: A Voice User Interface for the Intuitive Control of Laboratory Instruments. SLAS TECHNOL. Transl. Life Sci. Innov. 2018, 23, 476–482. [Google Scholar] [CrossRef]
- Yan, R.; Song, Y.; Wu, H. Learning to respond with deep neural networks for retrieval-based human-computer conversation system. In Proceedings of the 39th International ACM SIGIR Conference on Research and Development in Information Retrieval; ACM: New York, NY, USA, 2016; pp. 55–64. [Google Scholar]
- Hwang, E.J.; Jung, J.Y.; Lee, S.K.; Lee, S.E.; Jee, W.H. Machine Learning for Diagnosis of Hematologic Diseases in Magnetic Resonance Imaging of Lumbar Spines. Sci. Rep. 2019, 9, 6046. [Google Scholar] [CrossRef] [PubMed]
- Omondiagbe, D.A.; Veeramani, S.; Sidhu, A.S. Machine Learning Classification Techniques for Breast Cancer Diagnosis. In IOP Conference Series: Materials Science and Engineering; IOP Publishing: Bristol, UK, 2019; Volume 495, p. 012033. [Google Scholar]
- Pigoni, A.; Delvecchio, G.; Madonna, D.; Bressi, C.; Soares, J.; Brambilla, P. Can Machine Learning help us in dealing with treatment resistant depression? A review. J. Affect. Disord. 2019, 259, 21–26. [Google Scholar] [CrossRef]
- Künzel, S.R.; Sekhon, J.S.; Bickel, P.J.; Yu, B. Metalearners for estimating heterogeneous treatment effects using machine learning. Proc. Natl. Acad. Sci. USA 2019, 116, 4156–4165. [Google Scholar] [CrossRef]
- Callahan, A.; Shah, N.H. Machine learning in healthcare. In Key Advances in Clinical Informatics; Elsevier: Amsterdam, The Netherlands, 2017; pp. 279–291. [Google Scholar]
- Sinsky, C.; Colligan, L.; Li, L.; Prgomet, M.; Reynolds, S.; Goeders, L.; Westbrook, J.; Tutty, M.; Blike, G. Allocation of physician time in ambulatory practice: A time and motion study in 4 specialties. Ann. Intern. Med. 2016, 165, 753–760. [Google Scholar] [CrossRef]
- Nuance AI-Powered Virtual Assistants for Healthcare. Available online: https://www.nuance.com/healthcare/ambient-clinical-intelligence/virtual-assistants.html (accessed on 13 March 2019).
- Suki Let Doctors Focus on What Matters. Available online: https://www.suki.ai/about-us (accessed on 23 March 2019).
- Robin Healthcare. Available online: https://www.robinhealthcare.com (accessed on 24 March 2019).
- UHS Drives Quality through Cloud Speech and CDI Workflow. Available online: https://www.nuance.com/content/dam/nuance/en_us/collateral/healthcare/case-study/cs-uhs-en-us.pdf (accessed on 15 March 2019).
- Plastic Surgery Specialist Reduces Time Per Patient Note. Available online: https://resources.suki.ai/home/case-study-dr-ereso-plastic-surgeon (accessed on 24 March 2019).
- Plastic Surgery Specialist Reduces Time Per Patient Note. Available online: https://www.mobihealthnews.com/news/north-america/voice-enabled-clinician-workflow-tool-robin-healthcare-raises-115m (accessed on 2 October 2019).
- Medwhat Virtual Medical Assistant. Available online: https://medwhat.com/ (accessed on 2 April 2019).
- Your.MD Symptom Checker. Available online: https://www.your.md/ (accessed on 2 April 2019).
- Sensely Engage Your Members. Reduce Your Costs. Available online: https://www.sensely.com/ (accessed on 2 April 2019).
- Bickmore, T.W.; Trinh, H.; Olafsson, S.; O’Leary, T.K.; Asadi, R.; Rickles, N.M.; Cruz, R. Patient and consumer safety risks when using conversational assistants for medical information: An observational study of Siri, Alexa, and Google Assistant. J. Med. Internet Res. 2018, 20, e11510. [Google Scholar] [CrossRef]
- Semigran, H.L.; Linder, J.A.; Gidengil, C.; Mehrotra, A. Evaluation of symptom checkers for self diagnosis and triage: Audit study. BMJ 2015, 351, h3480. [Google Scholar] [CrossRef]
- Crestani, F.; Du, H. Written versus spoken queries: A qualitative and quantitative comparative analysis. J. Am. Soc. Inf. Sci. Technol. 2006, 57, 881–890. [Google Scholar] [CrossRef]
- Philip, P.; Bioulac, S.; Sauteraud, A.; Chaufton, C.; Olive, J. Could a virtual human be used to explore excessive daytime sleepiness in patients? Presence Teleop. Vir. Environ. 2014, 23, 369–376. [Google Scholar] [CrossRef]
- Philip, P.; Micoulaud-Franchi, J.A.; Sagaspe, P.; De Sevin, E.; Olive, J.; Bioulac, S.; Sauteraud, A. Virtual human as a new diagnostic tool, a proof of concept study in the field of major depressive disorders. Sci. Rep. 2017, 7, 42656. [Google Scholar] [CrossRef] [PubMed]
- Tanaka, H.; Negoro, H.; Iwasaka, H.; Nakamura, S. Embodied conversational agents for multimodal automated social skills training in people with autism spectrum disorders. PLoS ONE 2017, 12, e0182151. [Google Scholar] [CrossRef] [PubMed]
- Dimeff, L.A.; Jobes, D.A.; Chalker, S.A.; Piehl, B.M.; Duvivier, L.L.; Lok, B.C.; Zalake, M.S.; Chung, J.; Koerner, K. A novel engagement of suicidality in the emergency department: Virtual Collaborative Assessment and Management of Suicidality. In General Hospital Psychiatry; Elsevier: Amsterdam, The Netherlands, 2018. [Google Scholar]
- Levin, E.; Levin, A. Spoken dialog system for real-time data capture. In Proceedings of the Ninth European Conference on Speech Communication and Technology, Lisbon, Portugal, 4–8 September 2005. [Google Scholar]
- Black, L.A.; McTear, M.; Black, N.; Harper, R.; Lemon, M. Appraisal of a conversational artefact and its utility in remote patient monitoring. In Proceedings of the 18th IEEE Symposium on Computer-Based Medical Systems, Dublin, Ireland, 23–24 June 2005; pp. 506–508. [Google Scholar]
- Harper, R.; Nicholl, P.; McTear, M.; Wallace, J.; Black, L.A.; Kearney, P. Automated phone capture of diabetes patients readings with consultant monitoring via the web. In Proceedings of the 15th Annual IEEE International Conference and Workshop on the Engineering of Computer Based Systems, ECBS, Belfast, UK, 31 March–4 April 2008; pp. 219–226. [Google Scholar]
- Lucas, G.M.; Rizzo, A.; Gratch, J.; Scherer, S.; Stratou, G.; Boberg, J.; Morency, L.P. Reporting mental health symptoms: Breaking down barriers to care with virtual human interviewers. Front. Robot. AI 2017, 4, 51. [Google Scholar] [CrossRef]
- Yokotani, K.; Takagi, G.; Wakashima, K. Advantages of virtual agents over clinical psychologists during comprehensive mental health interviews using a mixed methods design. Comput. Hum. Behav. 2018, 85, 135–145. [Google Scholar] [CrossRef]
- Ali, T.; Hussain, J.; Amin, M.B.; Hussain, M.; Akhtar, U.; Khan, W.A.; Lee, S.; Kang, B.H.; Hussain, M.; Afzal, M.; et al. The Intelligent Medical Platform: A Novel Dialogue-Based Platform for Health-Care Services. Computer 2020, 53, 35–45. [Google Scholar] [CrossRef]
- Ireland, D.; Atay, C.; Liddle, J.; Bradford, D.; Lee, H.; Rushin, O.; Mullins, T.; Angus, D.; Wiles, J.; McBride, S.; et al. Hello Harlie: Enabling Speech Monitoring Through Chat-Bot Conversations. Studi. Health Technol. Inf. 2016, 227, 55–60. [Google Scholar]
- Mugoye, K.; Okoyo, H.; Mcoyowo, S. Smart-bot Technology: Conversational Agents Role in Maternal Healthcare Support. In Proceedings of the IEEE 2019 IST-Africa Week Conference (IST-Africa), Nairobi, Kenya, 8–10 May 2019; pp. 1–7. [Google Scholar]
- Giorgino, T.; Azzini, I.; Rognoni, C.; Quaglini, S.; Stefanelli, M.; Gretter, R.; Falavigna, D. Automated spoken dialogue system for hypertensive patient home management. Int. J. Med. Inf. 2005, 74, 159–167. [Google Scholar] [CrossRef]
- Beveridge, M.; Fox, J. Automatic generation of spoken dialogue from medical plans and ontologies. J. Biom. Inf. 2006, 39, 482–499. [Google Scholar] [CrossRef][Green Version]
- Clarke, N.L.; Furnell, S.M.; Rodwell, P.M.; Reynolds, P.L. Acceptance of subscriber authentication methods for mobile telephony devices. Comput. Secur. 2002, 21, 220–228. [Google Scholar] [CrossRef]
- Raza, M.; Iqbal, M.; Sharif, M.; Haider, W. A survey of password attacks and comparative analysis on methods for secure authentication. World Appl. Sci. J. 2012, 19, 439–444. [Google Scholar]
- McDermott, D.S.; Kamerer, J.L.; Birk, A.T. Electronic Health Records: A Literature Review of Cyber Threats and Security Measures. Int. J. Cyber Res. Educ. (IJCRE) 2019, 1, 42–49. [Google Scholar] [CrossRef]
- Frumento, E. Cybersecurity and the Evolutions of Healthcare: Challenges and Threats Behind Its Evolution. In m_Health Current and Future Applications; Springer: Berlin, Germany, 2019; pp. 35–69. [Google Scholar]
- Kao, H.C.; Tang, K.F.; Chang, E.Y. Context-aware symptom checking for disease diagnosis using hierarchical reinforcement learning. In Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence, New Orleans, LO, USA, 2–7 February 2018. [Google Scholar]
- Morreale, S.P.; Spitzberg, B.H.; Barge, J.K. Human Communication: Motivation, Knowledge, and Skills; Cengage Learning: Boston, MA, USA, 2007. [Google Scholar]
- Glass, J. Challenges for spoken dialogue systems. In Proceedings of the 1999 IEEE ASRU Workshop; MIT Laboratory fot Computer Science: Cambridge, MA, USA, 1999. [Google Scholar]
- Kang, S.; Ko, Y.; Seo, J. A dialogue management system using a corpus-based framework and a dynamic dialogue transition model. AI Commun. 2013, 26, 145–159. [Google Scholar] [CrossRef]
- Li, Y.; Feng, Z.; Xiao, Y.; Huang, J. A neural network algorithm for signal processing of LFMCW or IFSCW system. In Proceedings of the 1999 Asia Pacific Microwave Conference—APMC’99—Microwaves Enter the 21st Century, Conference Proceedings (Cat. No.99TH8473), Singapore, 30 November–3 December 1999; Volume 3, pp. 900–903. [Google Scholar]
- Rasa Documentation. Available online: https://rasa.com/docs/rasa/ (accessed on 19 March 2020).
- Unified Medical Language System Documentation. Available online: https://www.nlm.nih.gov/research/umls/index.html (accessed on 19 March 2020).
- Hummer, M.; Groll, S.; Kunz, M.; Fuchs, L.; Pernul, G. Measuring Identity and Access Management Performance-An Expert Survey on Possible Performance Indicators. In Proceedings of the 4th International Conference on Information Systems Security and Privacy, Funchal-Madeira, Portugal, 22–24 January 2018; Available online: https://www.scitepress.org/Papers/2018/65577/65577.pdf (accessed on 23 July 2019).
- Rehman, U.U.; Lee, S. Natural Language Voice based Authentication Mechanism for Smartphones. In Proceedings of the 17th Annual International Conference on Mobile Systems, Applications, and Services; ACM: New York, NY, USA, 2019; pp. 600–601. [Google Scholar]
- Biswas, M. AI and Bot Basics. In Beginning AI Bot Frameworks; Springer: Berlin, Germany, 2018; pp. 1–23. [Google Scholar]
- Find Machine Learning Algorithms for Your Data. Available online: https://mod.rapidminer.com/ (accessed on 22 March 2020).
- Elliot, A.J.; Maier, M.A. Color psychology: Effects of perceiving color on psychological functioning in humans. Ann. Rev. Psychol. 2014, 65, 95–120. [Google Scholar] [CrossRef]
- Walker, M.A.; Litman, D.J.; Kamm, C.A.; Abella, A. PARADISE: A framework for evaluating spoken dialogue agents. arXiv 1997, arXiv:cmp-lg/9704004. [Google Scholar]
- Landis, J.R.; Koch, G.G. The measurement of observer agreement for categorical data. Biometrics 1977, 159–174. Available online: https://www.jstor.org/stable/pdf/2529310.pdf (accessed on 23 March 2019). [CrossRef]
- Pejovic, V.; Bojanic, S.; Carreras, C.; Nieto-Taladriz, O. Detecting masquerading attack in software and in hardware. In Proceedings of the MELECON 2006—2006 IEEE Mediterranean Electrotechnical Conference, Malaga, Spain, 16–19 May 2006; pp. 836–838. [Google Scholar]
- Schrepp, M. User Experience Questionnaire Handbook. In All you Need to Know to Apply the UEQ Successfully in Your Project; 2015; Available online: https://www.ueq-online.org/Material/Handbook.pdf (accessed on 12 May 2019).












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Serial No. | Questions | Responses | ||
|---|---|---|---|---|
| 1 | Do you have awareness of medication? | Yes (25%) | No (75%) | |
| 2 | Are healthcare services expensive in your country? | Yes (83.3%) | No (16.7%) | |
| 3 | 3a | Based on your chief complaint, can you make a decision about an appropriate medical specialist? | Yes (25%) | No (75%) |
| 3b | If you selected ‘No’ in 3a, then with whom will you discuss the situation? | Friends or Family (61.1%) | General Physician (38.9%) | |
| 3c | In the case of ‘Friends or Family’ in 3b, does the discussion help you to decide about the appropriate medical specialist? | Yes (63.6%) | No (36.4%) | |
| 4 | Are you interested in a smartphone application that listens to your chief complaint and recommends a nearby appropriate medical specialist? | Yes (91.7%) | No (8.3%) | |
| 5 | What type of interactive communication medium would you prefer for the smartphone application? | Speech-based (70.8%) | Text-based (29.2%) | |
| Feature Name | Value Range | Measurement Unit | Meaning |
|---|---|---|---|
| Age | [17, 73] | Years | Age of the patients |
| Gender | 0, 1 | Category | Male or Female |
| Urinating often | 0, 1 | Boolean | Frequent urination can be a symptom of many diseases such as diabetes |
| Feeling thirsty | 0, 1 | Boolean | Urge to drink too much may indicate diseases such as diabetes |
| Feeling hungry | 0, 1 | Boolean | Patient may feel strong hunger due to low blood sugar; it may indicate diabetes because of an abnormal glucose level |
| Extreme fatigue | 0, 1 | Boolean | Uncontrolled blood glucose may leads to tiredness |
| Blurry vision | 0, 1 | Boolean | In diabetes, a high blood glucose level may lead to temporary blurring of eyesight; moreover, damaged optic nerves increase the intraocular pressure that may leads to haziness or blurry vision |
| Slow-healing wounds | 0, 1 | Boolean | High blood glucose level may affect the blood circulation, which may leads to the slow-healing of wounds. |
| Weight loss | 0, 1 | Boolean | The body starts burning fat and muscle for energy with insufficient insulin |
| Has tingling sensation | 0, 1 | Boolean | Diabetic neuropathy may lead to tingling sensations in fingers, toes, hands, and feet, and burning may occur as well |
| Pain | 0, 1 | Boolean | Diabetic neuropathy may leads to pain in different body parts such as arms, legs or sometimes the whole body |
| Numbness of hands | 0, 1 | Boolean | Diabetic neuropathy may lead to numbness of hands |
| Numbness of foot | 0, 1 | Boolean | Diabetic neuropathy may lead to numbness of feet |
| Burning sensation in eye | 0, 1 | Boolean | Stinging or irritating sensation in the eyes |
| Color vision impairment | 0, 1 | Boolean | Color vision impairment is the initial symptom of glaucoma |
| Difficulty walking | 0, 1 | Boolean | Glaucoma patients frequently complain of difficulty walking |
| Difficulty in stair climbing | 0, 1 | Boolean | Glaucoma patients frequently complain of difficulty climbing stairs |
| Difficulty in face recognition | 0, 1 | Boolean | Glaucoma patients frequently complain of difficulty recognizing faces |
| Difficulty driving | 0, 1 | Boolean | Glaucoma patients frequently complain of difficulty driving |
| Double vision | 0, 1 | Boolean | Diplopia is considered to be a warning for glaucoma |
| Dryness of eyes | 0, 1 | Boolean | Dryness of eyes is due to the lack of proper tear production |
| Swelling of eyelids | 0, 1 | Boolean | Occurs due to inflammation or excess of fluid |
| Tear in eyes with a strong glare | 0, 1 | Boolean | Unusual squinting or blinking due to a strong glare or light |
| Image quality decrease | 0, 1 | Boolean | Peripheral vision loss may be an early symptom of glaucoma |
| Itchiness | 0, 1 | Boolean | Itchiness caused due to the low quantity of eye fluid or low interocular pressure |
| Nausea and vomiting | 0, 1 | Boolean | Severe eye pain may cause nausea and vomiting |
| Headache | 0, 1 | Boolean | Severe eye pain may cause headache |
| Night blindness | 0, 1 | Boolean | Nyctalopia is a condition where the eye is unable to adapt to the surrounding conditions such as low-light, or nighttime |
| Redness of eyes | 0, 1 | Boolean | Caused due to swollen or dilated blood vessels |
| Severe eye pain | 0, 1 | Boolean | The rapid eye pressure increase causes severe eye pain |
| Sudden onset of visual disturbances usually in low light | 0, 1 | Boolean | The basic signs and symptoms of acute angle closure glaucoma |
| Chief Complaints of Different Diseases (Feel Free to Use Any Synonyms Related to These Chief Complaints) | ||
|---|---|---|
| Glaucoma | Diabetes | Other |
| Blurry vision | Blurry vision | Sweating |
| Burning sensation or dryness or itchiness in eye(s) | Extreme fatigue | Pain |
| Color vision impairment | Feeling very hungry | Nausea and vomiting |
| Difficulty in driving, face recognition, stair climbing, and walking | Feeling very thirsty | Shortness of breath |
| Double vision or decrease in image quality or sudden onset of visual disturbance usually in low light | Numbness of feet | Discomfort in body parts such as neck, jaw, shoulder, upper back, or abdominal |
| Nausea and vomiting with headache | Numbness of hands | Unusual fatigue |
| Night blindness | Pain | Lightheadedness or dizziness |
| Red eyes | Slow healing of cuts and bruises | Stiffness |
| Severe eye pain | Tingling sensation | Swelling |
| Swelling in eyelid | Urinating often | Instability |
| Tears in eyes with a strong glare | Weight loss | Deformity |
| Glaucoma | Diabetes | Other | |
|---|---|---|---|
| Glaucoma | 30 | 1 | 2 |
| Diabetes | 3 | 28 | 2 |
| Other | 1 | 1 | 31 |
| Scale | Alpha-Coefficient |
|---|---|
| Attractiveness | 0.74 |
| Perspicuity | 0.67 |
| Efficiency | 0.77 |
| Dependability | 0.60 |
| Stimulation | 0.67 |
| Novelty | 0.48 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Rehman, U.U.; Chang, D.J.; Jung, Y.; Akhtar, U.; Razzaq, M.A.; Lee, S. Medical Instructed Real-Time Assistant for Patient with Glaucoma and Diabetic Conditions. Appl. Sci. 2020, 10, 2216. https://doi.org/10.3390/app10072216
Rehman UU, Chang DJ, Jung Y, Akhtar U, Razzaq MA, Lee S. Medical Instructed Real-Time Assistant for Patient with Glaucoma and Diabetic Conditions. Applied Sciences. 2020; 10(7):2216. https://doi.org/10.3390/app10072216
Chicago/Turabian StyleRehman, Ubaid Ur, Dong Jin Chang, Younhea Jung, Usman Akhtar, Muhammad Asif Razzaq, and Sungyoung Lee. 2020. "Medical Instructed Real-Time Assistant for Patient with Glaucoma and Diabetic Conditions" Applied Sciences 10, no. 7: 2216. https://doi.org/10.3390/app10072216
APA StyleRehman, U. U., Chang, D. J., Jung, Y., Akhtar, U., Razzaq, M. A., & Lee, S. (2020). Medical Instructed Real-Time Assistant for Patient with Glaucoma and Diabetic Conditions. Applied Sciences, 10(7), 2216. https://doi.org/10.3390/app10072216