A Dynamic Emotional Session Generation Model Based on Seq2Seq and a Dictionary-Based Attention Mechanism


Abstract
1. Introduction
- It proposes to address the emotion factor in large-scale conversation generation.
- It proposes an end-to-end framework (called a DESG) to incorporate emotional influence into large-scale conversation generation via two novel mechanisms: an internal emotion regulator, and an emotion classifier.
- Experimental results with both automatic and human evaluations show that for a given post and an emotion category, our DESG can express the desired emotion explicitly (if possible) or implicitly (if necessary), while successfully generating meaningful responses with a coherent structure.
2. Related Work
3. Model
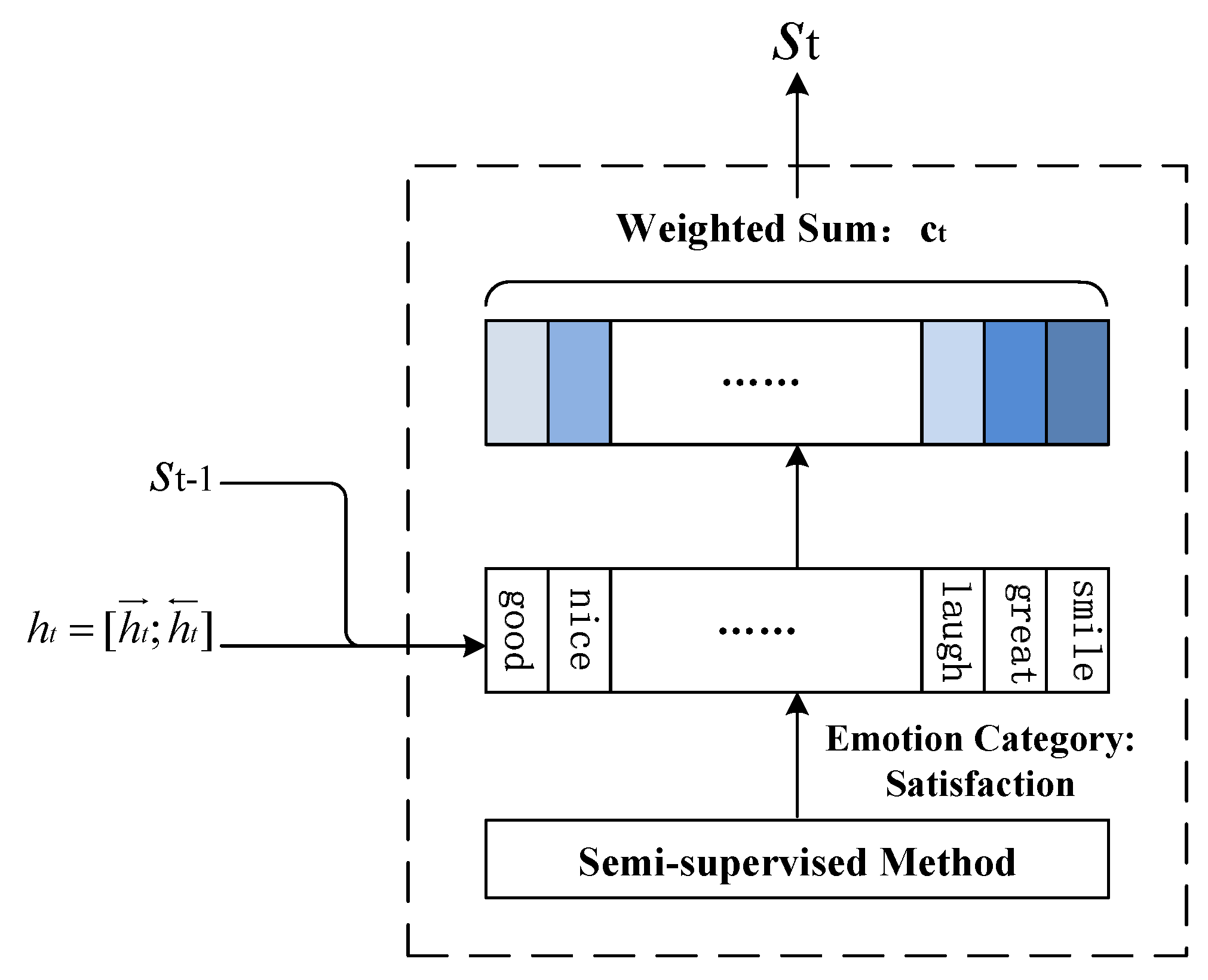
3.1. The Seq2Seq Model Based on a Dictionary-Based Attention Mechanism
3.2. Internal Emotion Regulator
3.3. Emotion Classifier
3.4. Loss Function
3.5. Sorting Algorithm
4. Results
4.1. Experimental Data and Preprocessing
4.2. Experimental Parameters
4.3. Results and Analysis
4.3.1. Evaluation Index
- (1)
- BLEU the geometric average according to the accuracy of the n-word () and measures the similarity between the generated response and the real response [30]. BLEU in this paper refers to the default BLEU4.
- (2)
- A method based on word vector (embedding) that introduces three embedding-based measures: Greedy Matching, Embedding Average, and Vector Extrema [31]. These convert sequence mapping to a semantic vector expression, then the similarity between the generated response and the real response is calculated using a cosine similarity and other methods.
- (3)
- The level of expressed emotion in the output sequence is tested using emotion indicators Emotion-a and Emotion-w [21], where Emotion-a calculates the consistency of the prediction and real labels obtained by the Bi-LSTM emotion classifier, and emotion-w calculates the percentage of the corresponding emotional words in the output sequence.
- (4)
- In order to measure the diversity of the response calculating the ratio of single words to double (Distinct-1 and Distinct-2, respectively) in the generated responses [32].
4.3.2. Comparative Analysis of Experimental Results
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Serban, I.V.; Lowe, R.; Charlin, L. Generative deep neural networks for dialogue: A short review. arXiv 2016, arXiv:1611.06216. [Google Scholar]
- Song, S. Sun R. Ren P. Psychology Dictionary; Guangxi People’s Publishing House: Nanning, China, 1984. [Google Scholar]
- Prendinger, H.; Mori, J.; Ishizuka, M. Using human physiology to evaluate subtle expressivity of a virtual quizmaster in a mathematical game. Int. J. Hum. Comput. Stud. 2005, 62, 231–245. [Google Scholar] [CrossRef]
- Prendinger, H.; Ishizuka, M. The empathic companyon: A character-based interface that addresses users’affective states. Appl. Artif. Intell. 2005, 19, 267–285. [Google Scholar] [CrossRef]
- Ritter, A.; Cherry, C.; Dolan, W.B. Data-driven response generation in social media. In Proceedings of the Empirical Methods in Natural Language Processing, Edinburgh, Scotland, 27–31 July 2011; pp. 583–593. [Google Scholar]
- Chen, C.; Zhu, Q.; Yan, R.; Liu, J. Survey on Deep Learning Based Open Domain Dialogue System. Chin. J. Comput. 2019, 42, 1439–1466. [Google Scholar]
- Zens, R.; Och, F.J.; Ney, H. Phrase-based statistical machine translation. In Proceedings of the German Conference on Ai: Advances in Artificial Intelligence (KI), Aachen, Germany, 16–20 September 2002; Springer: Berlin/Heidelberg, Germany, 2002; pp. 18–32. [Google Scholar]
- Shang, L.; Lu, Z.; Li, H. Neural responding machine for short-text conversation. In Proceedings of the International Joint Conference on Natural Language Processing (IJCAI), Beijing, China, 26–31 July 2015; pp. 1577–1586. [Google Scholar]
- Mei, H.; Bansal, M.; Walter, M.R. Coherent dialogue with attention-based language models. In Proceedings of the National Conference on Artificial Intelligence (NAACL), San Diego, CA, USA, 12–17 June 2016; pp. 3252–3258. [Google Scholar]
- Mayer, J.D.; Salovey, P. What is Emotional Intelligence Emotional Development and Emotional Intelligence; Basic Boks: New York, NY, USA, 1997; pp. 30–31. [Google Scholar]
- Zhiting, H.; Zichao, Y.; Xiaodan, L.; Ruslan, S.; Eric, P.X. Toward controlled generation of text. arXiv 2017, arXiv:1703.00955. [Google Scholar]
- Sayan, G.; Mathieu, C.; Eugene, L.; Louis-Philippe, M.; Stefan, S. Affect-lm: A neural language model for customizable affective text generation. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Beijing, China, 30 July 30–4 August 2017; pp. 634–642. [Google Scholar]
- Xianda, Z.; William, Y.W. Mojitalk: Generating emotional responses at scale. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics, Melbourne, Australia, 15–20 July 2018; pp. 1128–1137. [Google Scholar]
- Li, J.; Galley, M.; Brockett, C.; Gao, J.; Dolan, B. A diversity-promoting objective function for neural conversation models. In Proceedings of the North American Chapter of the Association for Computational Linguistics (NAACL), San Diego, Ca, USA, 12–17 June 2016; pp. 110–119. [Google Scholar]
- Sutskever, I.; Vinyals, O.; Le, Q.V. Sequence to sequence learning with neural networks. In Proceedings of the Advances in Neural Information Processing Systems (NIPS), Montreal, QC, Canada, 8–13 December 2014; pp. 3104–3112. [Google Scholar]
- Asghar, N.; Poupart, P.; Hoey, J.; Jiang, X.; Mou, L. Affective neural response generation. In Proceedings of the European Conference on Information Retrieval (ECIR), Grenoble, France, 25–29 March 2018; pp. 154–166. [Google Scholar]
- Li, Q.; Chen, H.; Ren, Z.; Chen, Z.; Tu, Z.; Ma, J. EmpGAN: Multi-resolution Interactive Empathetic Dialogue Generation. arXiv 2019, arXiv:1911.08698. [Google Scholar]
- Wu, X.; Wu, Y. A Simple Dual-decoder Model for Generating Response with Sentiment. arXiv 2019, arXiv:1905.06597. [Google Scholar]
- Chen, Z.; Song, R.; Xie, X.; Nie, J.Y.; Wang, X.; Zhang, F.; Chen, E. Neural Response Generation with Relevant Emotions for Short Text Conversation. In Proceedings of the CCF International Conference on Natural Language Processing and Chinese Computing, Dunhuang, China, 9–14 October 2019; Springer: Cham, Switzerland, 2019; pp. 117–129. [Google Scholar]
- Zhou, H.; Huang, M.; Zhang, T.; Zhu, X.; Liu, B. Emotional chatting machine: Emotional conversation generation with internal and external memory. In Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence (AAAI), New Orleans, LA, USA, 2–7 February 2018. [Google Scholar]
- Song, Z.; Zheng, X.; Liu, L.; Xu, M.; Huang, X.J. Generating Responses with a Specific Emotion in Dialog. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics (ACL), Florence, Italy, 28 July 2019–2 August 2019; pp. 3685–3695. [Google Scholar]
- Gross, J.J. The emerging field of emotion regulation: An integrative review. Rev. Gen. Psychol. 1998, 2, 71–299. [Google Scholar] [CrossRef]
- Johnson, M.; Schuster, M.; Le, Q.V.; Krikun, M.; Wu, Y.; Chen, Z.; Thorat, N.; Viégas, F.; Wattenberg, M.; Corrado, G.; et al. Google’s multilingual neural machine translation system: Enabling zero-shot translation. Trans. Assoc. Comput. Linguist. 2017, 5, 339–351. [Google Scholar] [CrossRef]
- Lu, Q.; Zhu, Z.; Xu, F.; Guo, Q. Research on Bi-LSTM Chinese sentiment classification method based on grammar rules. Data Anal. Knowl. Discov. 2019, 3, 99–107. [Google Scholar]
- Bahdanau, D.; Cho, K.; Bengio, Y. Neural machine translation by jointly learning to align and translate. arXiv 2014, arXiv:1409.0473. [Google Scholar]
- Luong, M.T.; Pham, H.; Manning, C.D. Effective approaches to attention-based neural machine translation. arXiv 2015, arXiv:1508.04025. [Google Scholar]
- Ghosh, S.; Chollet, M.; Laksana, E.; Morency, L.P.; Scherer, S. Affect-lm: A neural language model for customizable affective text generation. arXiv 2017, arXiv:1704.06851. [Google Scholar]
- Li, J.; Monroe, W.; Jurafsky, D. A simple, fast diverse decoding algorithm for neural generation. arXiv 2016, arXiv:1611.08562. [Google Scholar]
- Lai, T.L.; Robbins, H. Adaptive design and stochastic approximation. Ann. Stat. 1979, 7, 1196–1221. [Google Scholar] [CrossRef]
- Abhaya, A.; Alon, L. Evaluation metrics for highcorrelation with human rankings of machine translation output. In Proceedings of the Third Workshop on Statistical Machine Translation (WTM), Columbus, OH, USA, 19 June 2008; pp. 115–118. [Google Scholar]
- Liu, C.; Lowe, R.; Serban, I.V.; Noseworthy, M.; Charlin, L.; Pineau, J. How not to evaluate your dialogue system: An empirical study of unsupervised evaluation metrics for dialogue response generation. In Proceedings of the Empirical Methods in Natural Language Processing (EMNLP), Austin, TX, USA, 1–5 November 2016; pp. 2122–2132. [Google Scholar]
- Serban, I.V.; Sordoni, A.; Bengio, Y.; Courville, A.; Pineau, J. Building end-to-end dialogue systems using generative hierarchical neural network models. In Proceedings of the Association for the Advancement of Artificial Intelligence (AAAI), Phoenix, AZ, USA, 12–17 February 2016; pp. 3776–3784. [Google Scholar]
- Li, N.; Liu, B.; Han, Z.; Liu, Y.S.; Fu, J. Emotion reinforced visual storytelling. In Proceedings of the International Conference on Multimedia Retrieval, Ottawa, ON, Canada, 10–13 June 2019; pp. 297–305. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Post | Explicit | Implicit |
|---|---|---|
| I bought a beautiful dress yesterday! | Wearing a beautiful dress makes me happy! | Wow, you must feel walking on air! |
| The weather today is really nice. | I like sunny days. | I’m in a better mood today. |
| Emotion Classifier (EC) | Accuracy |
|---|---|
| Lexicon-based | 0.453 |
| RNN | 0.572 |
| LSTM | 0.597 |
| Bi-LSTM | 0.635 |
| Training Set | Validation Set | Test Set | ||||||
|---|---|---|---|---|---|---|---|---|
| Emotion Categories | Total Number of Responses | Total Number | Total Number | |||||
| Anger | Aversion | Satisfaction | Happiness | Sadness | Neutrality | 3,639,739 | 202,207 | 202,207 |
| 194,685 | 515,762 | 324,516 | 965,564 | 474,863 | 1,164,349 | |||
| Baseline Models | BLEU | Word Vector Based Method | Emotional Performance | Responses Diversity | ||||
|---|---|---|---|---|---|---|---|---|
| BLEU | Average | Greedy | Extreme | Emotion-a | Emotion-w | Distinct-1 | Distinct-2 | |
| Seq2Seq | 1.50 | 0.523 | 0.376 | 0.350 | 0.355 | 0.371 | 0.0038 | 0.012 |
| EmoEmb | 1.69 | 0.524 | 0.381 | 0.355 | 0.720 | 0.512 | 0.0054 | 0.0484 |
| ECM | 1.68 | 0.624 | 0.434 | 0.409 | 0.765 | 0.580 | 0.0090 | 0.0735 |
| EmoDS | 1.73 | 0.634 | 0.451 | 0.435 | 0.810 | 0.687 | 0.0113 | 0.0867 |
| DESG | 1.74 | 0.632 | 0.450 | 0.433 | 0.813 | 0.690 | 0.0121 | 0.0869 |
| Models | BLEU | Word Vector-Based Method | Emotional Performance | Responses Diversity | ||||
|---|---|---|---|---|---|---|---|---|
| BLEU | Average | Greedy | Extreme | Emotion-a | Emotion-w | Distinct-1 | Distinct-2 | |
| DESG-MLE | 1.61 | 0.550 | 0.376 | 0.379 | 0.728 | 0.468 | 0.0054 | 0.0671 |
| DESG-EV | 1.64 | 0.569 | 0.398 | 0.387 | 0.749 | 0.472 | 0.0056 | 0.0657 |
| DESG-BS | 1.73 | 0.624 | 0.439 | 0.489 | 0.776 | 0.659 | 0.0050 | 0.0464 |
| DESG-IM | 1.72 | 0.615 | 0.430 | 0.480 | 0.761 | 0.649 | 0.0059 | 0.0670 |
| DESG | 1.74 | 0.633 | 0.450 | 0.434 | 0.813 | 0.690 | 0.0121 | 0.0869 |
| Post | Model | Response | |
|---|---|---|---|
| Beach under the sunset is so beautiful. | Seq2Seq | What do you think of this photo? | |
| DESG | anger | It is not beautiful at all. | |
| aversion | The photo is really ugly. | ||
| satisfaction | I really want to go there. | ||
| happiness | Both the sunset and beach are so beautiful! | ||
| sadness | There is a sense of loneliness! | ||
| Teachers are the most glorious profession in the sun. | Seq2Seq | The profession of a teacher is noble. | |
| DESG | anger | I feel nothing at all. | |
| aversion | I hate the teachers. | ||
| satisfaction | Of course! The teachers are so noble! | ||
| happiness | I love all my teachers. | ||
| sadness | It is sad that people don’t respect teachers. | ||
| The handmade wedding dress. | Seq2Seq | I also want one. | |
| DESG | anger | The dress is not beautiful. | |
| aversion | It looks so bad. | ||
| satisfaction | It is a creative design. | ||
| happiness | I love this wedding dress so much! | ||
| sadness | But I haven’t got a chance to wear it. | ||
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Guo, Q.; Zhu, Z.; Lu, Q.; Zhang, D.; Wu, W. A Dynamic Emotional Session Generation Model Based on Seq2Seq and a Dictionary-Based Attention Mechanism. Appl. Sci. 2020, 10, 1967. https://doi.org/10.3390/app10061967
Guo Q, Zhu Z, Lu Q, Zhang D, Wu W. A Dynamic Emotional Session Generation Model Based on Seq2Seq and a Dictionary-Based Attention Mechanism. Applied Sciences. 2020; 10(6):1967. https://doi.org/10.3390/app10061967
Chicago/Turabian StyleGuo, Qiangqaing, Zhenfang Zhu, Qiang Lu, Dianyuan Zhang, and Wenqing Wu. 2020. "A Dynamic Emotional Session Generation Model Based on Seq2Seq and a Dictionary-Based Attention Mechanism" Applied Sciences 10, no. 6: 1967. https://doi.org/10.3390/app10061967
APA StyleGuo, Q., Zhu, Z., Lu, Q., Zhang, D., & Wu, W. (2020). A Dynamic Emotional Session Generation Model Based on Seq2Seq and a Dictionary-Based Attention Mechanism. Applied Sciences, 10(6), 1967. https://doi.org/10.3390/app10061967