CRANK: A Hybrid Model for User and Content Sentiment Classification Using Social Context and Community Detection



Abstract
1. Introduction
2. Related Work
2.1. Sentiment Analysis
2.2. Social Network Analysis
2.3. Social Context
2.4. Sentiment Analysis Using Social Context
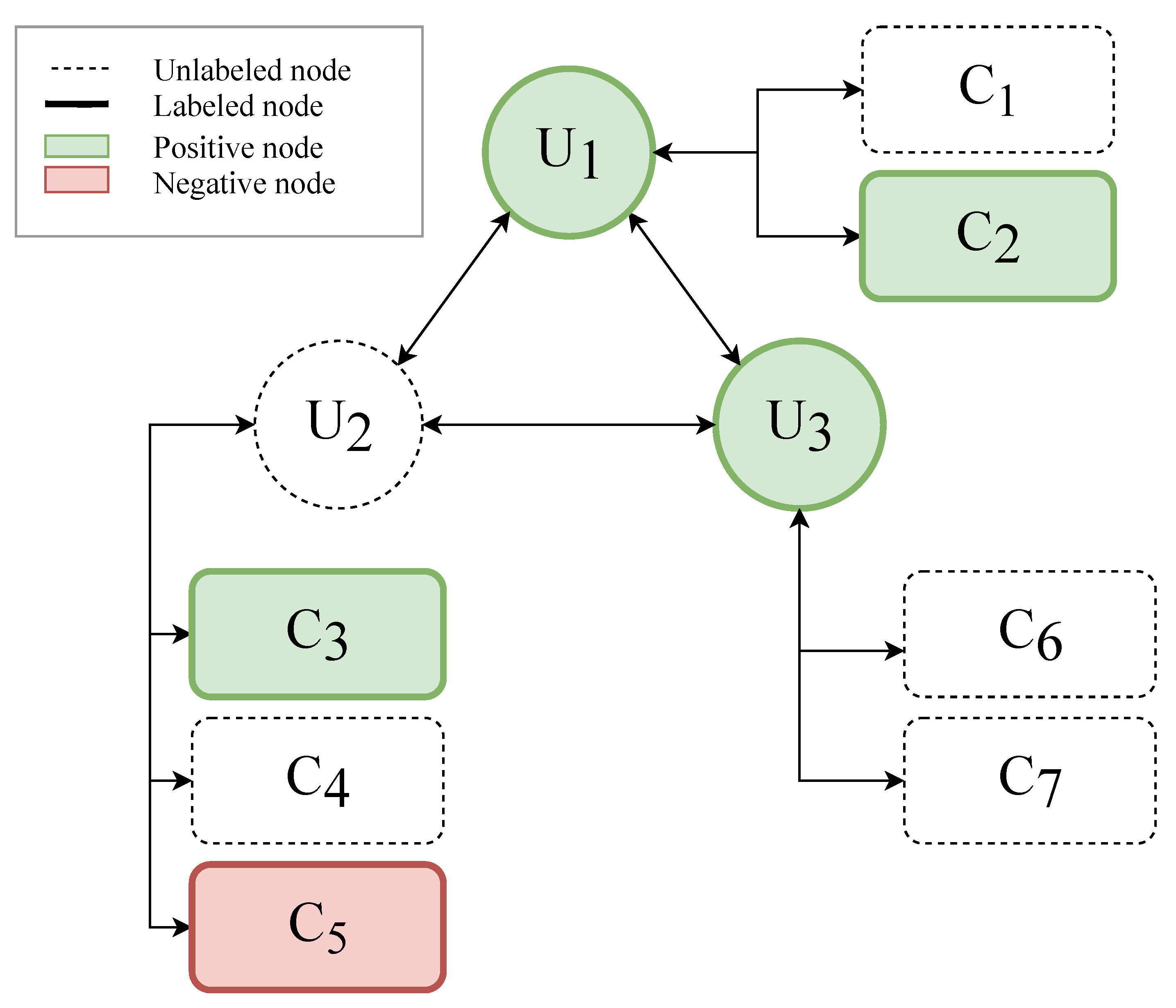
3. Sentiment Classification
3.1. Probability Model
3.2. Parameter Estimation and Classification
| Algorithm 1 Sentiment detection. | |
| Input | |
| ▹ Known user labels | |
| ▹ Known content labels | |
| ▹ Edges connecting users | |
| ▹ Edges between users and content | |
| ▹ Performance (accuracy) | |
| ▹ Objective function | |
| Output | |
| ▹ Estimated user labels | |
| ▹ Estimated content labels | |
| ▹ Learned weights | |
| 1: | ▹ Community detection. This is skipped in CrankNoComm |
| 2: | |
| 3: | |
| 4: for to do | |
| 5: | ▹ Randomly modify only one label |
| 6: | |
| 7: | |
| 8: if then | ▹ Performance is worse, objective is better |
| 9: | ▹ Performance is better, objective is worse |
| 10: else if then | |
| 11: | ▹ Converge if there are no changes in a given number of steps |
| 12: if then | |
| 13: | |
| 14: if then return | |
| 15: else | |
| 16: | |
| 17: if then | ▹ Performance is better, and objective function is at least the same |
| 18: | |
| 19: | |
| 20: |
4. Data
4.1. Datasets
4.2. Gathering and Analyzing Social Context
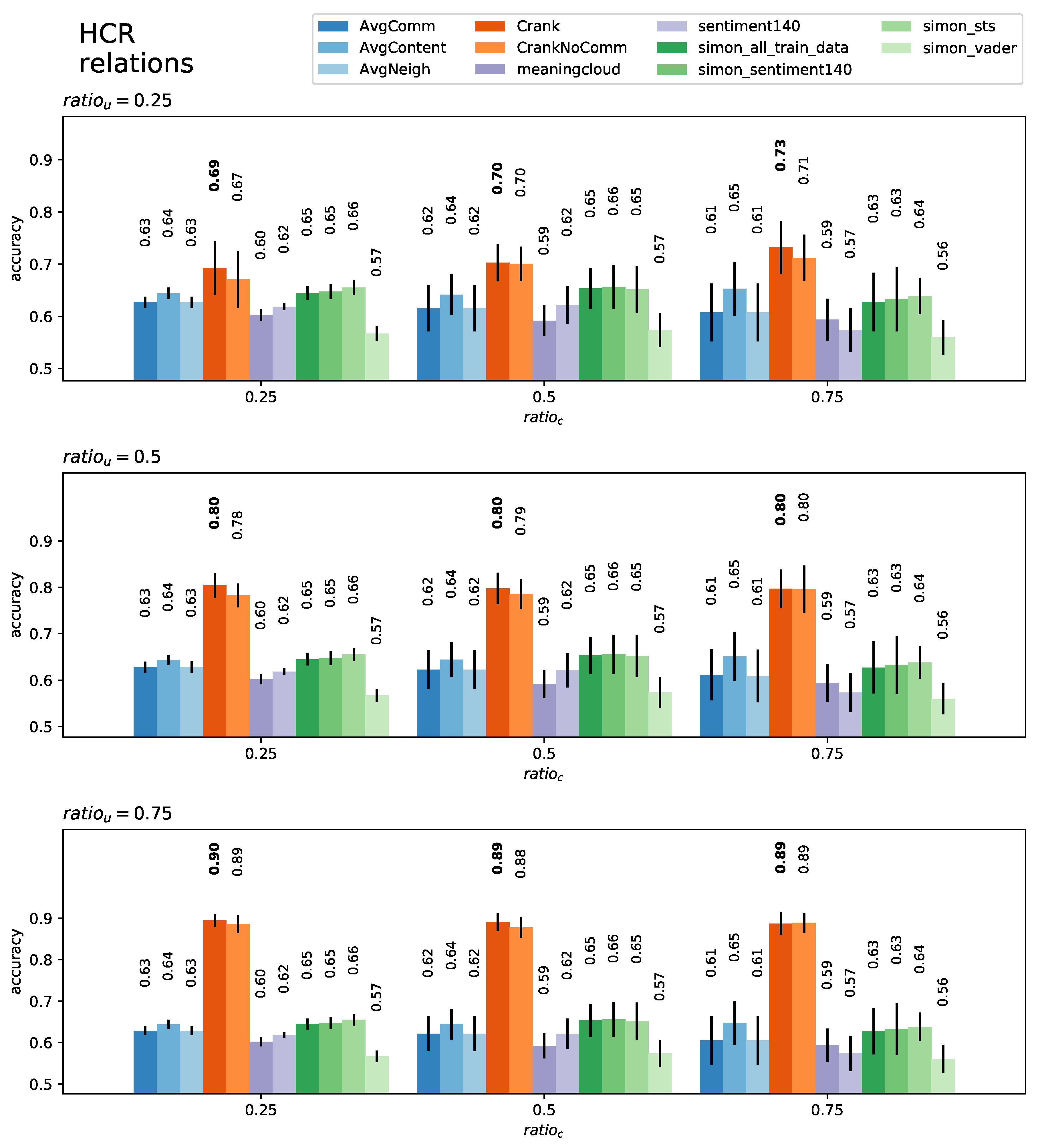
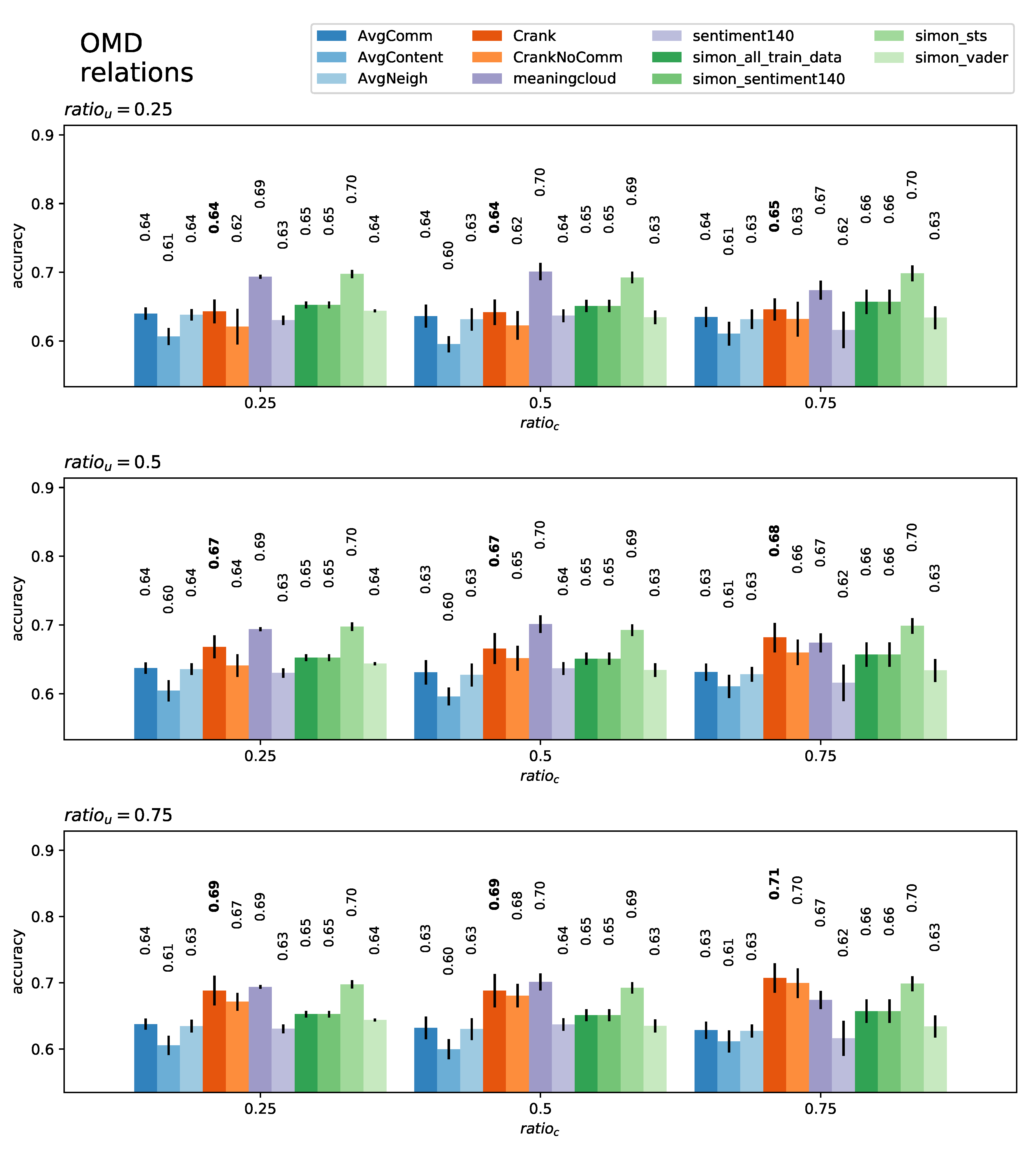
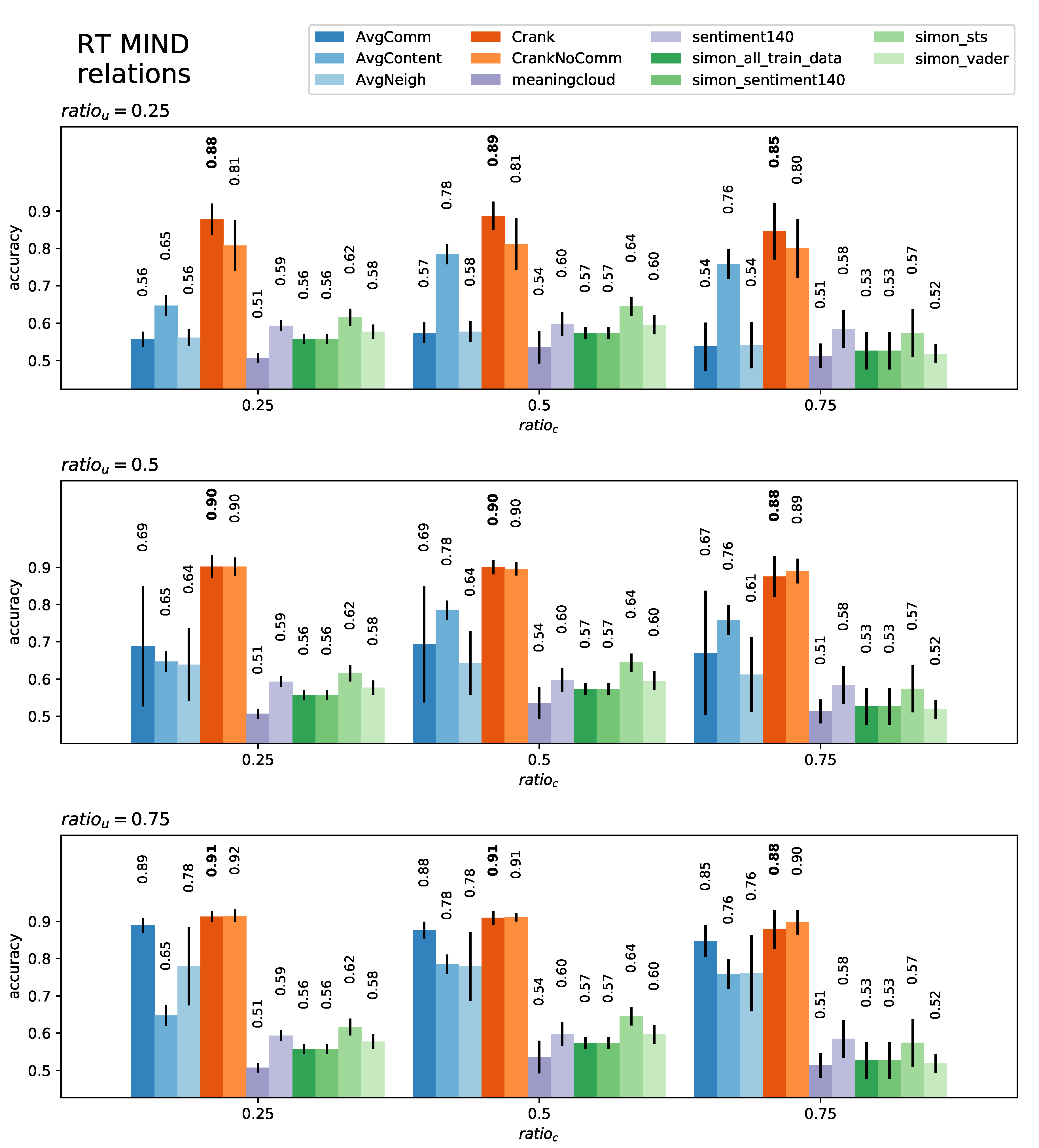
5. Evaluation
5.1. User-Level Classification
- Average content (AvgContent) (): Content was applied the same label as the majority of content by the same user, and users were labeled according to the majority label of their content.
- Naive majority (AvgNeigh) ( or , depending on the context): Users were labeled with the majority label in their group of neighbors in the network. Unlabeled content was given the label of its creator.
- Majority in the community (AvgComm) (): Users were grouped into communities, and each user was given the majority label of the users in their community. Content was given the label of its creator.
- CRANK without community detection ( or , depending on the context): The CRANK model described in Algorithm 1, but using original edges instead of applying community detection.
- CRANK (): Before applying Algorithm 1, the communities between users were extracted and converted to user edges, i.e., users in the same community were connected by an edge.
5.2. Content-Level Classification
- Simon [40] (): A sentiment analysis model based on semantic similarity. The model can be trained with different datasets. In our evaluation, we compared with the Simon model trained on different datasets: STS, Vader, Sentiment140, and a combination of all three.
- Sentiment140 (https://www.sentiment140.com) service (): This is a public sentiment analysis service, tailored to Twitter. It outputs three labels: positive, negative, and neutral. This results in lower accuracy for the negative and positive labels. In fact, of all the models tested, this was the one with the lowest accuracy. If all tweets labeled neutral by the service are ignored, its accuracy reaches standard levels (around 60%). Unfortunately, this means that around 80% of tweets have to be ignored.
- Meaningcloud (https://www.meaningcloud.com/) Sentiment Analysis (): An enterprise service that provides several types of text analysis, including sentiment analysis. It poses the same restrictions for evaluation as Sentiment140, as it provides positive, negative, and neutral labels. Fortunately, the subjectivity detection of this service for our datasets was better than that of Sentiment140.
- Average Content (AvgContent) (): Content is applied the same label as the majority of content by the same user, and users are labeled according to the majority label of their content.
- Naive majority (AvgNeigh) ( or , depending on the context): Users are labeled with the majority label in their group of neighbors in the network. Unlabeled content is given the label of its creator.
- Majority in the community (AvgComm) (): Users are grouped into communities, and each user is given the majority label of the users in their community. Content is given the label of its creator.
- CRANK without community detection ( or , depending on the context): The CRANK model described in Algorithm 1, but using original edges instead of applying community detection.
- CRANK (): Before applying Algorithm 1, the communities between users are extracted and converted to user edges, i.e., users in the same community are connected by an edge.
- Label propagation [38] (Speriosu): Based on the results reported in the original paper for these datasets.
5.3. Statistical Analysis
6. Conclusions and Future Work
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Sánchez-Rada, J.F.; Iglesias, C.A. Social Context in Sentiment Analysis: Formal Definition, Overview of Current Trends and Framework for Comparison. Inf. Fus. 2019. [Google Scholar] [CrossRef]
- Pozzi, F.A.; Maccagnola, D.; Fersini, E.; Messina, E. Enhance user-level sentiment analysis on microblogs with approval relations. In Proceedings of the Congress of the Italian Association for Artificial Intelligence; Springer: Turin, Italy, 2013; pp. 133–144. [Google Scholar]
- Pang, B.; Lee, L. Opinion Mining and Sentiment Analysis. Found. Trends® Inf. Retr. 2008, 2, 1–135. [Google Scholar] [CrossRef]
- Ravi, K.; Ravi, V. A survey on opinion mining and sentiment analysis: Tasks, approaches and applications. Knowl.-Based Syst. 2015, 89, 14–46. [Google Scholar] [CrossRef]
- Sharma, A.; Dey, S. A comparative study of feature selection and machine learning techniques for sentiment analysis. In Proceedings of the 2012 ACM Research in Applied Computation Symposium; ACM: New York, NY, USA, 2012; pp. 1–7. [Google Scholar]
- Taboada, M.; Brooke, J.; Tofiloski, M.; Voll, K.; Stede, M. Lexicon-Based Methods for Sentiment Analysis. Comput. Linguist. 2011, 37, 267–307. [Google Scholar] [CrossRef]
- García-Pablos, A.; Cuadros Oller, M.; Rigau Claramunt, G. A comparison of domain-based word polarity estimation using different word embeddings. In Proceedings of the Tenth International Conference on Language Resources and Evaluation, Portoroz, Slovenia, 23–28 May 2016. [Google Scholar]
- Cambria, E. Affective computing and sentiment analysis. IEEE Intell. Syst. 2016, 31, 102–107. [Google Scholar] [CrossRef]
- Kiritchenko, S.; Zhu, X.; Mohammad, S.M. Sentiment Analysis of Short Informal Texts. J. Artif. Intell. Res. 2014, 50, 723–762. [Google Scholar] [CrossRef]
- Melville, P.; Gryc, W.; Lawrence, R.D. Sentiment Analysis of Blogs by Combining Lexical Knowledge with Text Classification. In Proceedings of the 15th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining; ACM: New York, NY, USA, 2009; pp. 1275–1284. [Google Scholar]
- Nasukawa, T.; Yi, J. Sentiment Analysis: Capturing Favorability Using Natural Language Processing. In Proceedings of the 2Nd International Conference on Knowledge Capture; ACM: New York, NY, USA, 2003; pp. 70–77. [Google Scholar]
- Araque, O.; Corcuera-Platas, I.; Sánchez-Rada, J.F.; Iglesias, C.A. Enhancing Deep Learning Sentiment Analysis with Ensemble Techniques in Social Applications. Expert Syst. Appl. 2017, 77, 236–246. [Google Scholar] [CrossRef]
- Pang, B.; Lee, L.; Vaithyanathan, S. Thumbs Up?: Sentiment Classification Using Machine Learning Techniques. In Proceedings of the ACL-02 Conference on Empirical Methods in Natural Language Processing; Association for Computational Linguistics: Stroudsburg, PA, USA, 2002; Volume 10, pp. 79–86. [Google Scholar]
- Wang, S.; Manning, C.D. Baselines and Bigrams: Simple, Good Sentiment and Topic Classification. In Proceedings of the 50th Annual Meeting of the Association for Computational Linguistics: Short Papers; Association for Computational Linguistics: Stroudsburg, PA, USA, 2012; pp. 90–94. Volume 2. [Google Scholar]
- Jiang, F.; Liu, Y.Q.; Luan, H.B.; Sun, J.S.; Zhu, X.; Zhang, M.; Ma, S.P. Microblog sentiment analysis with emoticon space model. J. Comput. Sci. Technol. 2015, 30, 1120–1129. [Google Scholar] [CrossRef]
- Hogenboom, A.; Bal, D.; Frasincar, F.; Bal, M.; De Jong, F.; Kaymak, U. Exploiting Emoticons in Polarity Classification of Text. J. Web Eng. 2015, 14, 22–40. [Google Scholar]
- Novak, P.K.; Smailović, J.; Sluban, B.; Mozetič, I. Sentiment of emojis. PLoS ONE 2015, 10, e0144296. [Google Scholar]
- Collobert, R.; Weston, J.; Bottou, L.; Karlen, M.; Kavukcuoglu, K.; Kuksa, P. Natural language processing (almost) from scratch. J. Mach. Learn. Res. 2011, 12, 2493–2537. [Google Scholar]
- Bengio, Y. Learning Deep Architectures for AI. Found. Trends® Mach. Learn. 2009, 2, 1–127. [Google Scholar] [CrossRef]
- Marcus, G. Deep learning: A critical appraisal. arXiv 2018, arXiv:1801.00631. [Google Scholar]
- Lipton, Z.C. The mythos of model interpretability. arXiv 2016, arXiv:1606.03490. [Google Scholar] [CrossRef]
- Kim, Y. Convolutional neural networks for sentence classification. arXiv 2014, arXiv:1408.5882. [Google Scholar]
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient estimation of word representations in vector space. arXiv 2013, arXiv:1301.3781. [Google Scholar]
- Otte, E.; Rousseau, R. Social network analysis: a powerful strategy, also for the information sciences. J. Inf. Sci. 2002, 28, 441–453. [Google Scholar] [CrossRef]
- Sixto, J.; Almeida, A.; López-de Ipiña, D. Analysis of the Structured Information for Subjectivity Detection in Twitter. In Proceedings of the Transactions on Computational Collective Intelligence XXIX, Bristol, UK, 5–7 September 2018; pp. 163–181. [Google Scholar]
- Hajian, B.; White, T. Modelling Influence in a Social Network: Metrics and Evaluation. In Proceedings of the 2011 IEEE Third International Conference on Privacy, Security, Risk and Trust and 2011 IEEE Third International Conference on Social Computing, Security, Boston, MA, USA, 9–11 October 2011; pp. 497–500. [Google Scholar]
- Noro, T.; Tokuda, T. Searching for Relevant Tweets Based on Topic-related User Activities. J. Web Eng. 2016, 15, 249–276. [Google Scholar]
- Papadopoulos, S.; Kompatsiaris, Y.; Vakali, A.; Spyridonos, P. Community detection in social media. Data Min. Knowl. Discov. 2012, 24, 515–554. [Google Scholar] [CrossRef]
- Deitrick, W.; Hu, W. Mutually Enhancing Community Detection and Sentiment Analysis on Twitter Networks. J. Data Anal. Inf. Process. 2013, 01, 19–29. [Google Scholar] [CrossRef]
- Gao, B.; Berendt, B.; Clarke, D.; De Wolf, R.; Peetz, T.; Pierson, J.; Sayaf, R. Interactive grouping of friends in OSN: Towards online context management. In Proceedings of the 2012 IEEE 12th International Conference on Data Mining Workshops (ICDMW), Brussels, Belgium, 10 December 2012; pp. 555–562. [Google Scholar]
- Orman, G.K.; Labatut, V.; Cherifi, H. Qualitative comparison of community detection algorithms. In Proceedings of the 2011 International Conference on Digital Information and Communication Technology and Its Applications, Bangkok, Thailand, 21–23 June 2011; pp. 265–279. [Google Scholar]
- Tan, C.; Lee, L.; Tang, J.; Jiang, L.; Zhou, M.; Li, P. User-level Sentiment Analysis Incorporating Social Networks. In Proceedings of the 17th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining; ACM: New York, NY, USA, 2011; pp. 1397–1405. [Google Scholar]
- Hu, X.; Tang, L.; Tang, J.; Liu, H. Exploiting Social Relations for Sentiment Analysis in Microblogging. In Proceedings of the Sixth ACM International Conference on Web Search and Data Mining; ACM: New York, NY, USA, 2013; pp. 537–546. [Google Scholar]
- Xiaomei, Z.; Jing, Y.; Jianpei, Z.; Hongyu, H. Microblog sentiment analysis with weak dependency connections. Knowl.-Based Syst. 2018, 142, 170–180. [Google Scholar] [CrossRef]
- Wick, M.L.; Rohanimanesh, K.; Bellare, K.; Culotta, A.; McCallum, A. SampleRank: Training Factor Graphs with Atomic Gradients; ICML: Vienna, Austria, 2011; Volume 5, p. 1. [Google Scholar]
- Blondel, V.D.; Guillaume, J.L.; Lambiotte, R.; Lefebvre, E. Fast unfolding of communities in large networks. J. Stat. Mech. 2008, 2008, P10008. [Google Scholar] [CrossRef]
- Shamma, D.A.; Kennedy, L.; Churchill, E.F. Tweet the Debates: Understanding Community Annotation of Uncollected Sources. In Proceedings of the First SIGMM Workshop on Social Media; ACM: New York, NY, USA, 2009; pp. 3–10. [Google Scholar]
- Speriosu, M.; Sudan, N.; Upadhyay, S.; Baldridge, J. Twitter Polarity Classification with Label Propagation over Lexical Links and the Follower Graph. In Proceedings of the Conference on Empirical Methods in Natural Language Processing; Association for Computational Linguistics: Stroudsburg, PA, USA, 2011; pp. 53–56. [Google Scholar]
- Kwak, H.; Lee, C.; Park, H.; Moon, S. What is Twitter, a Social Network or a News Media? In Proceedings of the 19th International Conference on World Wide Web; ACM: New York, NY, USA, 2010; pp. 591–600. [Google Scholar]
- Araque, O.; Zhu, G.; Iglesias, C.A. A semantic similarity-based perspective of affect lexicons for sentiment analysis. Knowl.-Based Syst. 2019, 165, 346–359. [Google Scholar] [CrossRef]
- Demšar, J. Statistical comparisons of classifiers over multiple data sets. J. Mach. Learn. Res. 2006, 7, 1–30. [Google Scholar]
- West, R.; Paskov, H.S.; Leskovec, J.; Potts, C. Exploiting Social Network Structure for Person-to-Person Sentiment Analysis. Trans. Assoc. Comput. Linguist. 2014, 2, 297–310. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Source | Users | Entries | Year | |
|---|---|---|---|---|
| OMD [37] | 893 | 1261 | 2009 | |
| HCR [38] | 277 | 1434 | 2011 | |
| RTMind [2] | 62 | 159 | 2013 |
| Dataset | Variant | Content Mean | Content Median | Degree | Isolation Ratio | Majority Agreement | # Edges | # Nodes | Total Agreement | Content Label Ratio | USer Label Ratio |
|---|---|---|---|---|---|---|---|---|---|---|---|
| RT Mind | relations | 2.56 | 3.00 | 8.61 | 0.00 | 0.90 | 267 | 62 | 0.52 | 0.56 | 0.52 |
| OMD | relations | 2.56 | 1.00 | 14.25 | 0.24 | 0.39 | 6364 | 893 | 0.16 | 0.61 | 0.69 |
| common | 2.56 | 1.00 | 9.59 | 0.24 | 0.30 | 4280 | 893 | 0.15 | 0.61 | 0.69 | |
| HCR | relations | 1.21 | 1.00 | 0.02 | 0.99 | 0.01 | 3 | 277 | 0.01 | 0.62 | 0.60 |
| common | 1.21 | 1.00 | 2.89 | 0.80 | 0.19 | 400 | 277 | 0.18 | 0.62 | 0.60 |
| Dataset | Model | AvgComm | AvgContent | AvgNeigh | CRANK | CrankNoComm | |
|---|---|---|---|---|---|---|---|
| RT Mind | 0.25 | 0.25 | 0.536 | 0.692 | 0.540 | 0.883 | 0.815 |
| 0.50 | 0.661 | 0.670 | 0.651 | 0.950 | 0.939 | ||
| 0.75 | 0.954 | 0.642 | 0.791 | 0.962 | 0.985 | ||
| 0.50 | 0.25 | 0.536 | 0.860 | 0.540 | 0.933 | 0.828 | |
| 0.50 | 0.663 | 0.843 | 0.651 | 0.964 | 0.961 | ||
| 0.75 | 0.951 | 0.861 | 0.791 | 0.965 | 0.985 | ||
| HCR | 0.25 | 0.25 | 0.597 | 0.713 | 0.597 | 0.681 | 0.660 |
| 0.50 | 0.608 | 0.712 | 0.607 | 0.698 | 0.681 | ||
| 0.75 | 0.636 | 0.742 | 0.636 | 0.697 | 0.684 | ||
| 0.50 | 0.25 | 0.597 | 0.807 | 0.597 | 0.789 | 0.789 | |
| 0.50 | 0.610 | 0.816 | 0.610 | 0.795 | 0.791 | ||
| 0.75 | 0.636 | 0.814 | 0.636 | 0.796 | 0.767 | ||
| OMD | 0.25 | 0.25 | 0.701 | 0.756 | 0.699 | 0.710 | 0.674 |
| 0.50 | 0.706 | 0.763 | 0.704 | 0.720 | 0.706 | ||
| 0.75 | 0.703 | 0.763 | 0.699 | 0.724 | 0.708 | ||
| 0.50 | 0.25 | 0.702 | 0.811 | 0.700 | 0.712 | 0.684 | |
| 0.50 | 0.706 | 0.811 | 0.705 | 0.736 | 0.724 | ||
| 0.75 | 0.701 | 0.819 | 0.699 | 0.731 | 0.731 |
| Dataset | Algo | AvgComm | AvgContent | AvgNeigh | CRANK | CrankNoComm | Meaningcloud | Sentiment140 | Simon_All_Train_Data | Simon_Sentiment140 | Simon_sts | Simon_Vader | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| RT Mind | 0.25 | 0.25 | 0.56 | 0.65 | 0.56 | 0.88 | 0.81 | 0.51 | 0.59 | 0.56 | 0.56 | 0.62 | 0.58 |
| 0.50 | 0.57 | 0.78 | 0.58 | 0.89 | 0.81 | 0.54 | 0.60 | 0.57 | 0.57 | 0.64 | 0.60 | ||
| 0.75 | 0.54 | 0.76 | 0.54 | 0.85 | 0.80 | 0.51 | 0.58 | 0.53 | 0.53 | 0.57 | 0.52 | ||
| 0.50 | 0.25 | 0.69 | 0.65 | 0.64 | 0.90 | 0.90 | 0.51 | 0.59 | 0.56 | 0.56 | 0.62 | 0.58 | |
| 0.50 | 0.69 | 0.78 | 0.64 | 0.90 | 0.90 | 0.54 | 0.60 | 0.57 | 0.57 | 0.64 | 0.60 | ||
| 0.75 | 0.67 | 0.76 | 0.61 | 0.88 | 0.89 | 0.51 | 0.58 | 0.53 | 0.53 | 0.57 | 0.52 | ||
| 0.75 | 0.25 | 0.89 | 0.65 | 0.78 | 0.91 | 0.92 | 0.51 | 0.59 | 0.56 | 0.56 | 0.62 | 0.58 | |
| 0.50 | 0.88 | 0.78 | 0.78 | 0.91 | 0.91 | 0.54 | 0.60 | 0.57 | 0.57 | 0.64 | 0.60 | ||
| 0.75 | 0.85 | 0.76 | 0.76 | 0.88 | 0.90 | 0.51 | 0.58 | 0.53 | 0.53 | 0.57 | 0.52 | ||
| HCR | 0.25 | 0.25 | 0.63 | 0.64 | 0.63 | 0.69 | 0.67 | 0.60 | 0.62 | 0.65 | 0.65 | 0.66 | 0.57 |
| 0.50 | 0.62 | 0.64 | 0.62 | 0.70 | 0.70 | 0.59 | 0.62 | 0.65 | 0.66 | 0.65 | 0.57 | ||
| 0.75 | 0.61 | 0.65 | 0.61 | 0.73 | 0.71 | 0.59 | 0.57 | 0.63 | 0.63 | 0.64 | 0.56 | ||
| 0.50 | 0.25 | 0.63 | 0.64 | 0.63 | 0.80 | 0.78 | 0.60 | 0.62 | 0.65 | 0.65 | 0.66 | 0.57 | |
| 0.50 | 0.62 | 0.64 | 0.62 | 0.80 | 0.79 | 0.59 | 0.62 | 0.65 | 0.66 | 0.65 | 0.57 | ||
| 0.75 | 0.61 | 0.65 | 0.61 | 0.80 | 0.80 | 0.59 | 0.57 | 0.63 | 0.63 | 0.64 | 0.56 | ||
| 0.75 | 0.25 | 0.63 | 0.64 | 0.63 | 0.90 | 0.89 | 0.60 | 0.62 | 0.65 | 0.65 | 0.66 | 0.57 | |
| 0.50 | 0.62 | 0.64 | 0.62 | 0.89 | 0.88 | 0.59 | 0.62 | 0.65 | 0.66 | 0.65 | 0.57 | ||
| 0.75 | 0.61 | 0.65 | 0.61 | 0.89 | 0.89 | 0.59 | 0.57 | 0.63 | 0.63 | 0.64 | 0.56 | ||
| OMD | 0.25 | 0.25 | 0.64 | 0.61 | 0.64 | 0.64 | 0.62 | 0.69 | 0.63 | 0.65 | 0.65 | 0.70 | 0.64 |
| 0.50 | 0.64 | 0.60 | 0.63 | 0.64 | 0.62 | 0.70 | 0.64 | 0.65 | 0.65 | 0.69 | 0.63 | ||
| 0.75 | 0.64 | 0.61 | 0.63 | 0.65 | 0.63 | 0.67 | 0.62 | 0.66 | 0.66 | 0.70 | 0.63 | ||
| 0.50 | 0.25 | 0.64 | 0.60 | 0.64 | 0.67 | 0.64 | 0.69 | 0.63 | 0.65 | 0.65 | 0.70 | 0.64 | |
| 0.50 | 0.63 | 0.60 | 0.63 | 0.67 | 0.65 | 0.70 | 0.64 | 0.65 | 0.65 | 0.69 | 0.63 | ||
| 00.75 | 0.63 | 0.61 | 0.63 | 0.68 | 0.66 | 0.67 | 0.62 | 0.66 | 0.66 | 0.70 | 0.63 | ||
| 0.75 | 00.25 | 0.64 | 0.61 | 0.63 | 0.69 | 0.67 | 0.69 | 0.63 | 0.65 | 0.65 | 0.70 | 0.64 | |
| 00.50 | 0.63 | 0.60 | 0.63 | 0.69 | 0.68 | 0.70 | 0.64 | 0.65 | 0.65 | 0.69 | 0.63 | ||
| 00.75 | 0.63 | 0.61 | 0.63 | 0.71 | 0.70 | 0.67 | 0.62 | 0.66 | 0.66 | 0.70 | 0.63 |
| sentiment140 | AvgContent | CRANK | CrankNoComm | Speriosu | meaningcloud | simon_all_train_data | simon_sentiment140 | simon_sts | simon_vader | |
|---|---|---|---|---|---|---|---|---|---|---|
| Pass | Baseline | No | Yes | Yes | No | No | No | No | Yes | No |
| Diff. | 0.0 | 0.81 | 4.96 | 4.04 | 1.52 | 0.56 | 0.85 | 1.19 | 3.52 | −1.0 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sánchez-Rada, J.F.; Iglesias, C.A. CRANK: A Hybrid Model for User and Content Sentiment Classification Using Social Context and Community Detection. Appl. Sci. 2020, 10, 1662. https://doi.org/10.3390/app10051662
Sánchez-Rada JF, Iglesias CA. CRANK: A Hybrid Model for User and Content Sentiment Classification Using Social Context and Community Detection. Applied Sciences. 2020; 10(5):1662. https://doi.org/10.3390/app10051662
Chicago/Turabian StyleSánchez-Rada, J. Fernando, and Carlos A. Iglesias. 2020. "CRANK: A Hybrid Model for User and Content Sentiment Classification Using Social Context and Community Detection" Applied Sciences 10, no. 5: 1662. https://doi.org/10.3390/app10051662
APA StyleSánchez-Rada, J. F., & Iglesias, C. A. (2020). CRANK: A Hybrid Model for User and Content Sentiment Classification Using Social Context and Community Detection. Applied Sciences, 10(5), 1662. https://doi.org/10.3390/app10051662