1. Introduction
In recent years, three-dimensional (3D) video has become one of the most popular multimedia types. It can provide audience with an immersive visual experience [
1]. Free viewpoint video (FVV) is regarded as an upgraded version of 3D video, which enable the users to freely choose the viewpoint within a certain range [
2]. Accordingly, the capture and transmission of FVV requires a large number of cameras and expensive bandwidth [
3]. In [
4], a realtime compression architecture for 4D performance capture is proposed to realize real-time transmission of 3D data sets while achieving comparable visual quality and bitrate. An encoder that leverages an implicit representation is introduced to represent the observed geometry, as well as its changes through time. On the decoder side, a variational optimization that compensates for quantization residuals is applied to avoid the typical artifacts of block-based coding. In practical applications, it is difficult to configure cameras for all views to achieve free switching of viewpoints [
5]. In this case, one practical way is to transmit only one or several key viewpoints, and the images of other views are synthesized at the receiving end. As described in [
6], a wavelet approach allows the researcher to have information not only on frequencies but even on time. It can obtain all the frequencies which are present in a signal with a good resolution. Therefore, wavelet transform is helpful for 3D-image coding and compression, and improves the quality of data transmission. Pandey et al. [
7] propose a virtual view synthesis method using a single Red-Green-Blue-Depth (RGBD) camera. It can generate novel renderings of the performer based on the past observations from multiple viewpoints and the current RGBD image from a fixed view. Lombardi et al. [
8] present a modeling method for objects and scenes with a semi-transparent volume representation based on end-to-end learning from multi-view RGB images, and the virtual view can be synthesized based on the 3D model. However, these methods are implemented on the basis of machine learning or deep learning. Therefore, the collection of training data is very important and limits the applicable scenarios for view synthesis. For newly added scenes or insufficient training sets, the performance of algorithms based on machine learning will decrease. Depth image-based rendering (DIBR) is a reliable technique for view synthesis in these cases [
9]. It introduces depth information into view synthesis and need not to reconstruct a 3D model. As shown in
Figure 1, all pixels in the reference image are projected to the 3D world coordinate based on the depth value and camera parameters, forming a set of 3D point clouds. The resulting points are then reprojected into the target image plane based on the virtual camera parameters. This core process is called 3D warping.
In the 3D warping process, there would be some artifacts in the synthesized image, resulting in a reduction of visual quality. According to the causes and features, these artifacts can be divided into several types: ghosts, cracks, pixel overlap, and holes [
10]. Ghosts are usually pixels on the foreground edges. In the depth acquisition process, they are given the background depth values, which makes the foreground edges in a depth image mismatched with that of the color image. Cracks are caused by rounding errors when warping 3D points to the target image. Due to the change of viewpoint in 3D warping, the occlusion relationship between objects in the scene has also changed, which is manifested in two forms. On the one hand, multiple pixels in the reference image may be projected into the same position in the virtual image, as shown in
Figure 2. These pixels usually have different depth values, which means they are at different distances from the reference camera. Therefore, the proper approach should be introduced to maintain the correct occlusion relationship. On the other hand, background regions occluded by foreground objects might be exposed in the virtual view. Since no pixels are warped to these regions, large holes appear in the virtual image, called disocclusions [
11]. Moreover, there is another type of hole known as the out-of-field region (OFR). This appears because the virtual view exceeds the capture range of reference view, resulting the region with no information on the edge of virtual image. Therefore, artifacts handling hole filling in particular are a key issue for view synthesis.
Generally, the hole-filling methods can be divided into two categories. The first is to preprocess the depth image by introducing a low-pass filter to reduce the hole size. The generation of disocclusion is related to the depth discontinuity between the foreground and the background. Large depth discontinuity usually causes a large disocclusion. Tam et al. [
12] use a symmetric Gaussian filter to smooth the depth image, aiming to reduce the depth discontinuity on the foreground edge and remove isolated noise pixels. However, this method produces a rubber plate effect, which appears as an uneven enlargement of the object. An asymmetric Gaussian filter is proposed in [
13] to overcome this problem and give stronger smoothness to depth discontinuity in a vertical direction. However, the regions that do not produce disocclusion are also smoothed, causing some distortion in the virtual image and reducing the visual quality of these regions. In this case, an edge-based smoothing filter is proposed to preprocess the foreground edge only [
14]. Liu et al. [
15] implement preprocessing in the transformed domain by applying a structure-aided filter. An adaptive filter can prevent the generation of hole or decrease hole size to some extent. The depth image-smoothing methods are suitable for small baseline configurations. They are hardly used in the large baseline situation. Moreover, OFRs are not caused by depth discontinuities, so they would not be prevented by the smoothing process.
The other type of method is to fill the holes by using the texture correlation of surrounding pixels. Inpainting-based methods are effective solutions to fill the unknown regions, such as Criminisi’s exemplar-based inpainting algorithm [
16]. In this method, the filling priority is first computed based on the texture distribution of surrounding valid pixels, and then the best matching patch in the source region is searched and copied to the hole region. It can produce plausible results without introducing blurring effects. However, for disocclusion filling, as the exposed regions belong to the background, they should be filled with background texture. Directly applying the Criminisi’s method would cause some foreground textures to be sampled to fill the holes, resulting in foreground blending. To overcome this drawback, some methods optimize the inpainting process by introducing the depth features. In [
17], the depth term is added in priority computation to give the patch with lower depth variance a higher priority, and depth weight is considered when searching for the best matching patch. However, this method requires the known depth image of virtual view, which is unrealistic in practical applications. Ahn et al. [
18] synthesizes the virtual depth image in 3D warping, thereby providing depth information for the subsequent inpainting process. But when the depth value of foreground edge is inaccurate, ghosts would affect the hole-filling quality. A depth-based gray-level distance matching cost computation method is proposed in [
19], but some artifacts might be produced due to the depth errors. In order to prevent the interference of foreground texture, some foreground segmentation methods are proposed [
20,
21,
22]. The quality of the synthesized image through these methods is strongly dependent on the accuracy of foreground segmentation. This is a challenging task in some situations, such as the existence of multiple depth layers. Sometimes the seed points need to be manually identified.
In the case where more than one reference view is available, the hole filling would be easier than single-view rendering. Multiple views can cover a larger capture range, and the occluded regions in the primary view may be visible in the auxiliary view. Li et al. [
23] verify that the hole size can be further reduced by using two or more auxiliary views. In [
24], an improved multiview synthesis method is proposed. The virtual view is synthesized by rendering the two nearest views, and for disocclusion filling, the hole regions are filled by the information from all of the additional views. The whole synthesis process is conducted with triangles instead of single pixels. Color of the pixels inside the triangle is linearly interpolated based on the colors and positions of the respective vertices. This process can reduce the hole size, but for regions with rich textures, interpolation computations may cause a distortion of the structure and introduce blurring results. Correspondingly, warping all of the additional views increases the computational cost. In particular, as the number of auxiliary views increases, the area of hole that can be further filled by merging is greatly reduced. In addition, transmitting so much data requires higher bandwidth. Therefore, bidirectional rendering is still a common approach for view synthesis. For this method, some holes still remain after merging as they are not visible in both views. The holes caused by depth errors are also difficult to avoid. In [
25], a modified Gaussian mixture model (GMM) method is proposed to build the background model, aiming to fill the remaining holes after weighted merging. This method cannot obtain the occluded background contents when the foreground objects are stationary. In [
26], a horizontal background extrapolation method is applied to fill the holes. Although its computational complexity is low, pixel-based filling results lack realism, especially for complex backgrounds. Yao et al. [
27] propose a depth-aided inpainting method to deal with the remaining holes. These bidirectional rendering methods perform the full 3D warping process for all the reference views. In fact, a large part of the regions is visible in both views. In [
28], the virtual depth image is inpainted to search the hole regions in the auxiliary image, thus preventing the repeated warping of the common regions. But filling the holes in the depth image increases the computational complexity. The visual quality of a synthesized image depends on the accuracy of depth prediction.
In this paper, we propose an asymmetric bidirectional rendering method for virtual view synthesis. The main contributes are: (1) pixels around foreground edges are optimized in the primary depth image before 3D warping, which can correct the depth value of foreground edges and prevent the ghosts from appearing on disocclusion boundaries. (2) We combine forward and reverse 3D warping to explore the occlusion layer of the primary view in the auxiliary image. By contrast with the traditional method which warps the whole two images and blends them, our method only warps the primary image and the occlusion layer extracted from the auxiliary image. This process can reduce the computational cost a lot. During the merging process, color correction is applied to reduce the brightness difference between the two virtual images. (3) A depth-guided inpainting method is proposed to explore appropriate textures to fill the remaining holes. Compared with Criminisi’s inpainting method, we add the depth and background terms in the priority computation to identify and mask foreground edges. The search for the best matching patch is also updated to a computation that combines color and depth information in the surrounding region. The rest of this paper is organized as follows. A detailed description of the proposed approach is presented in
Section 2. The experimental results and discussion are provided in
Section 3. Finally,
Section 4 concludes the paper and outlines future work.
2. Proposed Asymmetrical Bidirectional Rendering Approach
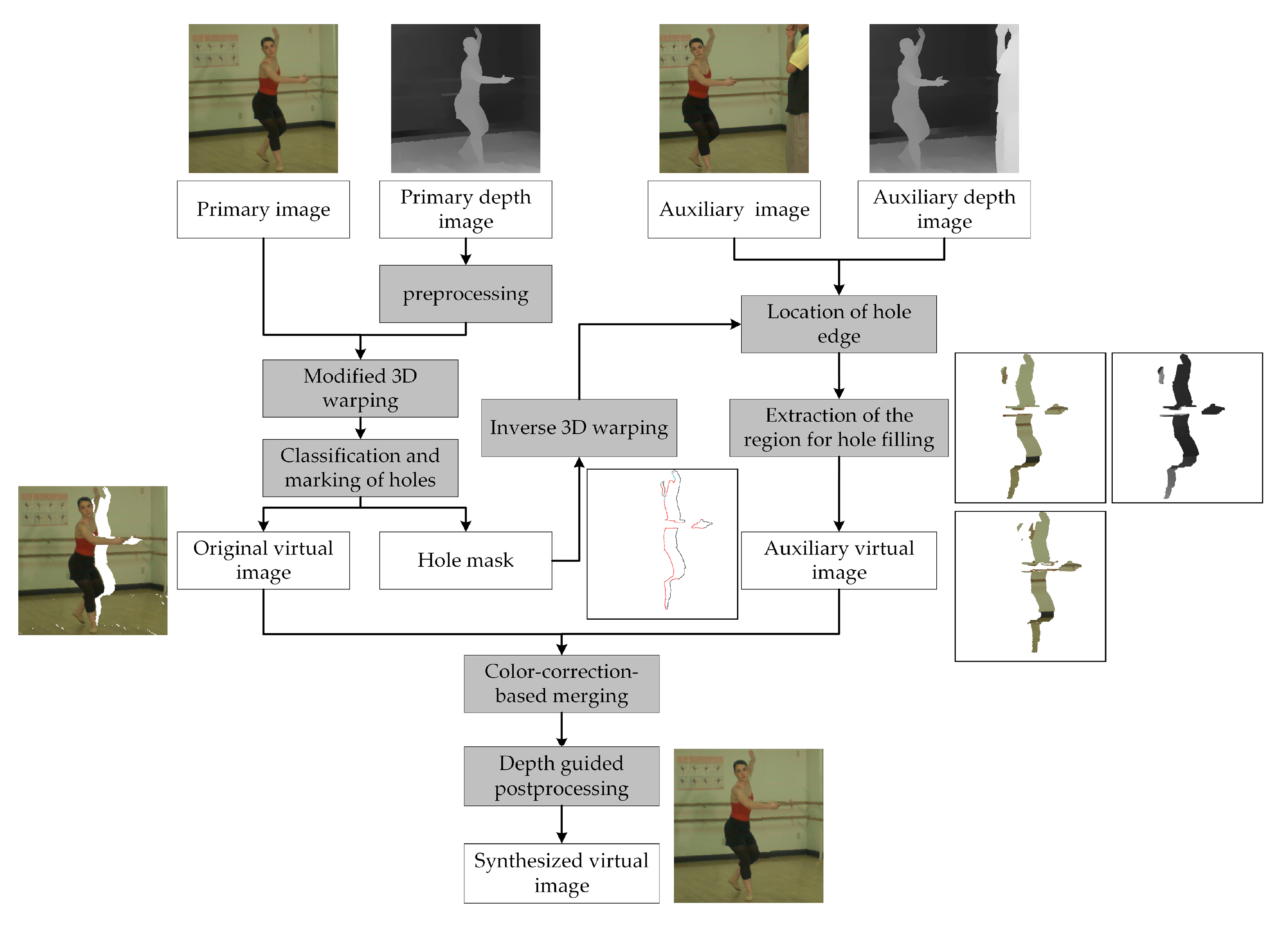
The flowchart of the proposed method is shown in
Figure 3. Our framework mainly contains four parts: depth image preprocessing, asymmetric bidirectional rendering, color-correction-based merging, and depth-guided postprocessing. In the following, these approaches will be described in detail.
2.1. Depth-Image Preprocessing
In general, disocclusions arise because of depth discontinuity between the foreground and background objects. The higher depth discontinuity leads to a larger disocclusion. As the baseline increases, the disocclusion area would increase until the entire foreground object is projected onto the new background. Therefore, accurate depth value is important for the synthesized image quality. Affected by the device accuracy and the deficient stereo matching algorithm, the depth value of the foreground edge might be coarse. This means that the edge of foreground in the depth image is mismatched with that of the color image, causing ghosts to appear around the disocclusion, as shown in
Figure 4b. The mixture of foreground and background pixels on the disocclusion boundary reduces the visual quality and interferes with the background texture propagation in hole filling. Therefore, a local depth-image preprocessing approach is proposed to correct the depth value of the foreground edge.
The preprocessing process includes two steps: foreground edge detection and depth calibration. For the right synthesized image, disocclusions appear on the right side of foregrounds and located between the foreground and background. Therefore, only one side of the foreground edge needs to be extracted. Based on the principle of disocclusion generation, the relevant right foreground edge can be detected according to depth discontinuity and marked as follows:
where
denotes the depth value;
represents the segmentation threshold and is set to 10 in the experiment. When the foreground edges that might produce ghosts are labeled, a one-dimensional template is used to process these pixels. For pixels in the template whose depth value is lower than the labeled pixel, its depth value is replaced by the labeled pixel’s depth value. This means that the edge of the foreground is extended to the background by a certain length. The size of template is set to
as the ghosts are usually 1–2 pixels wide. The preprocessing result is shown in
Figure 4c. It can be seen that most of the ghosts are removed and projected onto the corresponding foreground edges. In the case of large baseline, ghosts may appear on both sides of the disocclusion, so similar pre-processing is necessary for the left edge of foreground. Since this process only modifies the local depth values of the image, the blurring effect would not be produced in the synthesized image. However, large holes are not obviously reduced, and further processing is necessary.
2.2. Asymmetrical Bidirectional Rendering
In the traditional bidirectional DIBR, the left and right reference views are used as input of 3D warping to synthesize the target virtual view respectively. The two synthesized images are then merged to fill the holes. In fact, a large part of area in the virtual image is commonly visible in the left and right reference views. These regions are warped twice during the bidirectional DIBR and increase the computational complexity. As the purpose of bidirectional DIBR is to obtain the missing texture of the holes in single view rendering, we reduce the computational cost by only warping the regions that are useful for hole filling. Hence, an asymmetrical bidirectional rendering approach is proposed in this paper. Based on the hole edge information in the single view rendering result, we explore the helpful textures in the auxiliary image to fill the holes and ignore those regions that may be repeatedly warped.
Set the left reference view as the primary view and the right reference view as the auxiliary view. The primary image and its processed depth image are first warped to the virtual view through the modified 3D warping [
29]. During the warping process, cracks are filled by surrounding valid pixels. The overlapping pixels are sorted according to the depth value and the one with the highest depth value is selected for display. In addition, ghosts are removed in the depth preprocessing. Therefore, holes become the main problem in the synthesized image. With the movement of the viewpoint, the occlusion relationship between objects in the auxiliary view will change further compared with that in the virtual view, as shown in
Figure 5. In this case, the hole in the virtual image can be effectively reduced by extracting the corresponding regions in the auxiliary image and warping them to the virtual view. Since the depth value of the hole is unknown, in this paper, we combine the valid pixels on the edge of the hole to extract the region to be warped in the auxiliary image.
The holes in the virtual image include disocclusions, OFRs, and other small holes caused by depth errors. The last type of holes usually appears inside the foreground or background objects and is characterized by the area size and edge pixel distribution. In our experiment, the hole size threshold is set to 80, and most of the pixels on the edge of the hole belong to the same type (foreground or background). As satisfactory results for filling this type of hole can be obtained by using the inpainting method, only the edges of the disocclusions and OFRs in the virtual image are marked and processed. For OFRs, since they occur on the edges of the virtual image, only part of the valid pixels on the hole edges can be determined. In order to obtain the approximate depth value of the rest, we assume that these edge pixels have the same depth values as those of the primary image when no new foreground objects appear on the edges. In this case, the depth value of all the pixels around the OFR can be determined and ready for subsequent inverse 3D warping.
For disocclusions, as they appear inside the virtual image, the valid pixels on the hole edge can be obtained directly. As shown in
Figure 4c and
Figure 5b, for the right-synthesized image, the right edge pixel of the disocclusion usually belongs to the background, while the left side may have both foreground and background pixels. For each row, it can be divided into two types: background–background (BG–BG) or foreground–background (FG–BG). For the former, since the background pixels around the foreground are always located at the same depth layer, the length of the disocclusion would be maintained in the auxiliary image. For the latter, as the pixels on both sides have different depth values, the distance between them will further increase in the auxiliary image, as shown in
Figure 5c. So not all pixels inside the contour are helpful for hole filling. In the virtual image, the length of each disocclusion is recorded and the edge pixels of the disocclusion are classified based on the depth information. By applying the Laplacian operator to the primary depth image [
30], the foreground edges of the disocclusion can be obtained and labeled as follows:
where
denotes the Laplacian of the depth image and
denotes the warped Laplacian image.
represents the boundary of disocclusion. Based on the depth information, the edge pixels of the disocclusions and OFRs are back-warped into the auxiliary image, so the associated pixels can be located.
Based on the marked pixels through inverse 3D warping, the regions for hole filling are extracted in the auxiliary image, as shown in
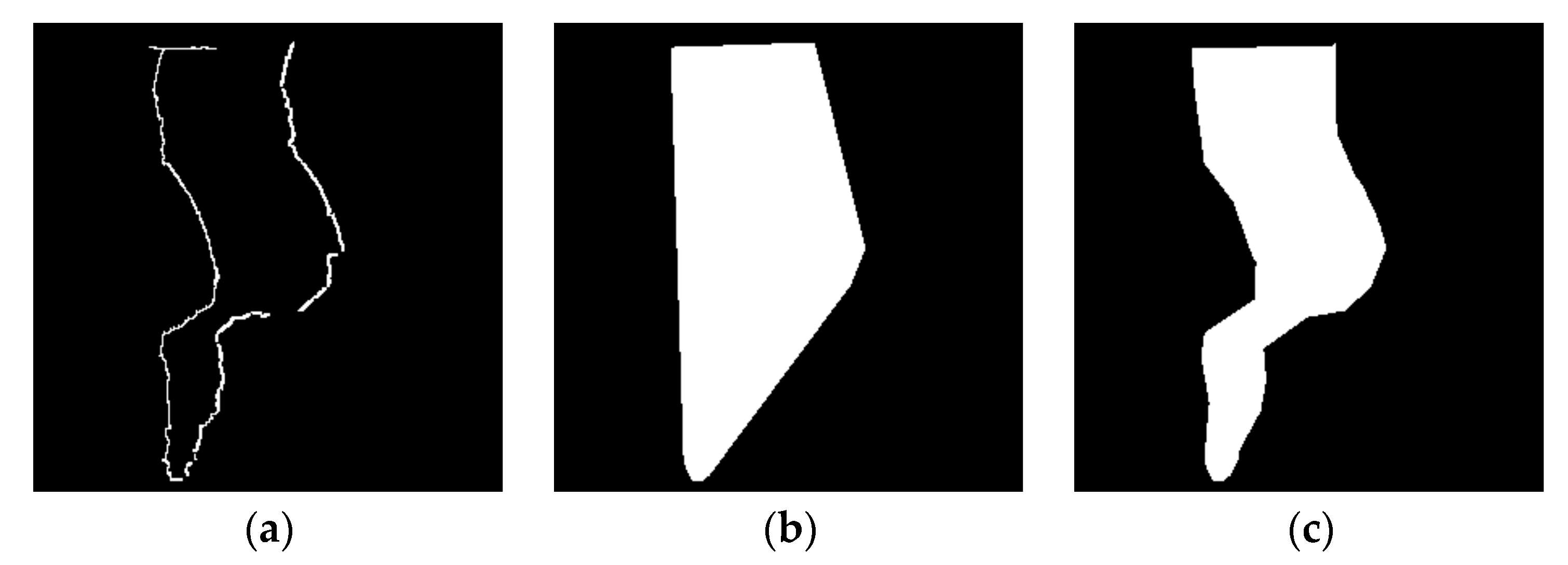
Figure 5c. For the disocclusion, starting from the right background edge, we extend to the left in the horizontal direction and mark the adjacent pixels as the selected pixels for warping. The length of the extension depends on the category of the left edge pixel. For BG–BG disocclusion, all the pixels between the left and right edges are selected. But for FG–BG disocclusion, the pixels of the hole length are selected for warping. As for the OFRs, since the edge pixels are located in the same depth layer, the selected pixels can be determined by extracting the pixels inside the contour. In this process, convex or concave hull extraction is optional. The result in
Figure 6 shows that, for certain applications, the convex hull does not represent well the boundaries of a given set of points. The concept of alpha-shape is introduced as a solution to this problem, and other solutions, such as crust algorithms are also proposed. However, most of the proposed approaches address the reconstruction of surfaces from sets of points belonging to that surface and, therefore, are not optimized for the referred problem. Compared with the convex hull, the concave hull can better reflect the accurate shape of the contour and contain fewer selected pixels, thus reducing the computational cost. Hence, a concave hull extraction method based on K nearest neighbors [
31] is applied in this paper to select the pixels for OFR filling. The K nearest neighbors extraction approach is able to deal with arbitrary sets of points by taking care of a few special cases. The “smoothness” of the computed hull can also be controlled by the user through the k parameter. Unlike the alpha-shape method, the modified K nearest neighbors approach can automatically adjust the value of k according to the distribution of the point set, instead of manually setting it based on the scene. In our experiment, the value of k starts from 3, and its value can be increased recursively in the extraction process until the given points are inside the computed polygon.
It is worth mentioning that most of the virtual views are synthesized through parallel rendering, that is, the virtual view is on the baseline formed by the primary and auxiliary views. In this way, the positional relationship between the left and right edges of the hole can be maintained in the auxiliary image, and almost all the OFRS can find the corresponding content in the auxiliary image. If there is a rotation relationship between the virtual view and reference views, the positional relationship between the edge pixels is changed after inverse 3D warping, and the extension approach mentioned above is no longer appropriate. In this case, the concave hull method is used to extract the warping regions for all types of holes to ensure that all helpful pixels are selected. In addition, to accommodate some possible depth changes and remove ghosts, the background edge of the selected regions is extended outward by using a morphological operation. Once all the selected regions are extracted, the auxiliary virtual image can be synthesized by the modified 3D warping.
2.3. Color Correction-Based Merging
Unlike single view rendering, asymmetric bidirectional rendering uses the two reference images to synthesize the target virtual image. Considering that there may be differences in brightness and color between the two images, some color-correction methods are proposed [
24,
32]. In these methods, two whole images are warped to the virtual view, and the ratio image is created for each virtual image. For pixels which are projected from both views, the color value of them is computed by blending the colors of two corresponding pixels. Then the ratio of these pixels are computed and inserted in the ratio image. For pixels only warped from the left or right reference image, their ratio values are obtained by computing the locally averaged ratio of the adjacent pixels. Then the color correction is performed based on the ratio image. However, in our method, only the occlusion layer in the auxiliary view is warped to the virtual view, the color correction process mentioned above is no longer applicable. Therefore, a modified merging approach based on color correction is proposed in this section. Since the virtual view is located between the left and right reference views, it can be assumed that the color difference among them is gradual. In our method, color correction is performed on the two synthesized images first, and then the contents of the auxiliary virtual image are copied to holes in the primary virtual image.
The color-correction process is performed in the Lab color space because it has a wider color gamut and better perceived uniformity. First we convert the two virtual images from Red-Green-Blue (RGB) color space to Lab color space. Compute the average
L,
a, and
b of each image, as follows:
where
represents the primary and auxiliary virtual image respectively, and
denotes the number of valid pixels in the image. Then the overall mean of each channel is computed as:
In the correction process, taking the
L channel for example, the corrected result can be expressed as:
For the
a and
b channels, the same computation is performed. The processed images are converted from Lab color space to RGB color space. After color correction, the contents in the auxiliary virtual image are used to fill the holes. The merging process can be expressed as follows:
where
and
are the corresponding pixels in the primary and auxiliary images, respectively, and
represents the merging result. During the merging, in order to prevent the ghosts, the pixels on the background edge of the disocclusions are replaced with corresponding valid pixels in the auxiliary image, as:
The local comparison results of direct merging and color correction-based merging are shown in
Figure 7. Compared with direct merging, the proposed merging approach reduces the abrupt changes in brightness, and makes the texture transition more natural. The overall result is shown in
Figure 8a. It can be seen that the proposed asymmetric bidirectional rendering can significantly reduce the holes in the virtual image. Note that even in the bidirectional rendering, there are still holes in the virtual image because some occluded regions are not visible in both reference views. In addition, the holes caused by depth errors are also waiting to be filled.
2.4. Depth-Guided Postprocessing
This part is mainly to deal with the remaining holes after image merging. As mentioned in
Section 1, Criminisi’s method [
16] is not very suitable for filling these holes, because some foreground textures might be sampled to fill the disocclusions. For this task, a depth-guided inpainting method is proposed to fill the remaining holes. As the depth value can reflect that the object belongs to the foreground or background to some extent, depth information is introduced to guide the filling process.
Like Criminisi’s method [
16], the depth-guided inpainting method includes three core steps: priority computation, patch matching, and priority update. The priority computation is performed on all the edge pixels of holes. For pixel
on the hole edge
,
denotes the square template centered at
. The priority of pixel
is computed as follows:
where
and
are the confidence term and data term as defined in [
16].
is depth term, which reflects the depth value of
.
is background term, which is used to identify foreground pixels on the disocclusion edges. The two newly introduced terms are defined as follows:
where
denotes the source region.
and
are the highest and lowest non-zero depth values in the depth image. The depth term tends to give a higher priority to background pixels with lower depth value. The background term can prevent the disocclusion filling from starting from the foreground edge, even if the relevant pixels have higher confidence and texture complexity. In addition, in order to avoid the situation where the priority is equal to 0, a little parameter
is added to Equation (10) and is set as 0.00001.
After all priorities on
are computed, the patch
with the highest priority would be filled first. Considering that content with similar depth value is more suitable for filling holes in the patch, depth information is used to search for the best matching patch. The candidate patch with the smallest matching cost is represented as:
where
is the search region,
is the sum of squared differences of the valid pixels in two patches. The content in
is copied to the empty region in
. After each iteration, the priority items are updated to accommodate the new valid information. The above steps are repeated until all remaining holes are filled. The filling result is shown in
Figure 8b, which does not introduce the blurring effect.















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}