Twin-Robot Dialogue System with Robustness against Speech Recognition Failure in Human-Robot Dialogue with Elderly People

 ,
,
Abstract
Featured Application
Abstract
1. Introduction
2. Related Work
3. Question–Answer–Response Dialogue Model
- The model regards a dialogue as a transition process which comprises four states.
- Every time a state is transitioned to the next state, a system selects a suitable utterance (among a set of utterances defined in the next state) for the robot.
3.1. States
- The structure makes a dialogue robust against speech recognition failures. Although speech recognition may fail, a robot can sustain a coherent dialogue by providing an ambiguous response; independent of user answer. Consider the dialogue in Figure 1. The user might answer “yes”, “no”, or “so-so” instead of “I don’t remember”. However, the response of the robot sounds coherent in any of the three ways. It means that the robot can sustain a coherent dialogue even when the speech recognition result is doubtful.
- The structure makes it easy to control the direction of a dialogue. A dialogue with the elderly is basically non-task-oriented (i.e., chat). However, the dialogue often has some type of implicit purposes. For example, it would be expected to stimulate users’ cognitive function abilities or to get users to pay attention to their daily lifestyle. To achieve such a purpose, a robot needs to mainly control the direction of the dialogue such that it can talk with the user about certain topics. Because the structure compels the robot to take the initiative in a dialogue, the robot would control the direction of the dialogue more easily than if it had been a free-style chat.
- The structure makes it easier to create a scenario of a dialogue. In the present natural language processing technology, it is still difficult to generate robot responses suitable for user utterances automatically. In particular, it is quite difficult to generate robot responses that facilitate dialogue with implicit purposes. In view of this, we had to create a scenario manually, consulting experts of such dialogues (i.e., caregivers). In general, creating a scenario from scratch is difficult. A scenario writer needs to consider many factors; for example, what kind of story the robot tells, how the story unfolds, whether each topic of the story remains coherent, when and how the robot asks, and for how long the robot should take the initiative. In contrast to the difficulty in considering such factors, using the proposed structure, a scenario writer needs to only create pairs of questions asked by a robot and responses to answers the user might give. This is relatively easier than creating scenarios from scratch.
3.2. Transition Rules
3.3. Utterance Selection in Each State
| Listing 1: Objects of the question state. |
 |
| Listing 2: Objects in the backchannel state. |
 |
| Listing 3: Objects in the comment state. |
 |
4. Participation of Multiple Robots
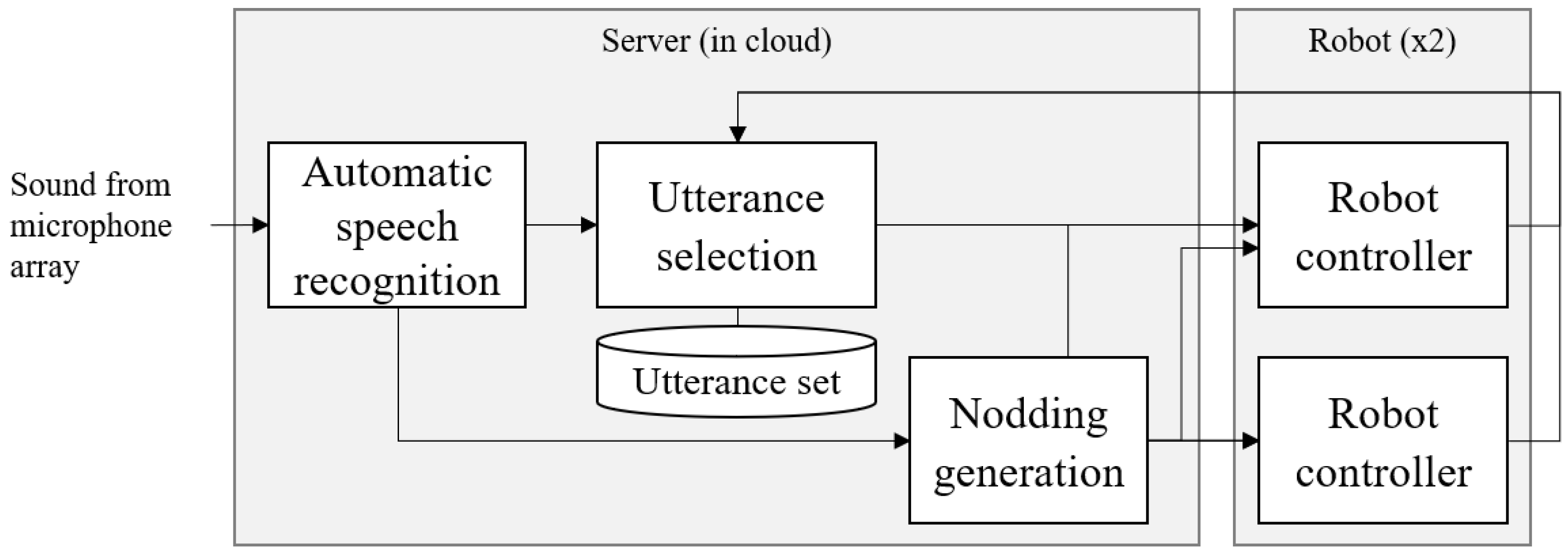
5. System
6. Field Trial
6.1. Purpose
6.2. Participants
6.3. Scenarios
- One-robot scenario. One robot participated in a dialogue. The robot performed tasks according to the question–answer–response dialogue model (see Section 3).
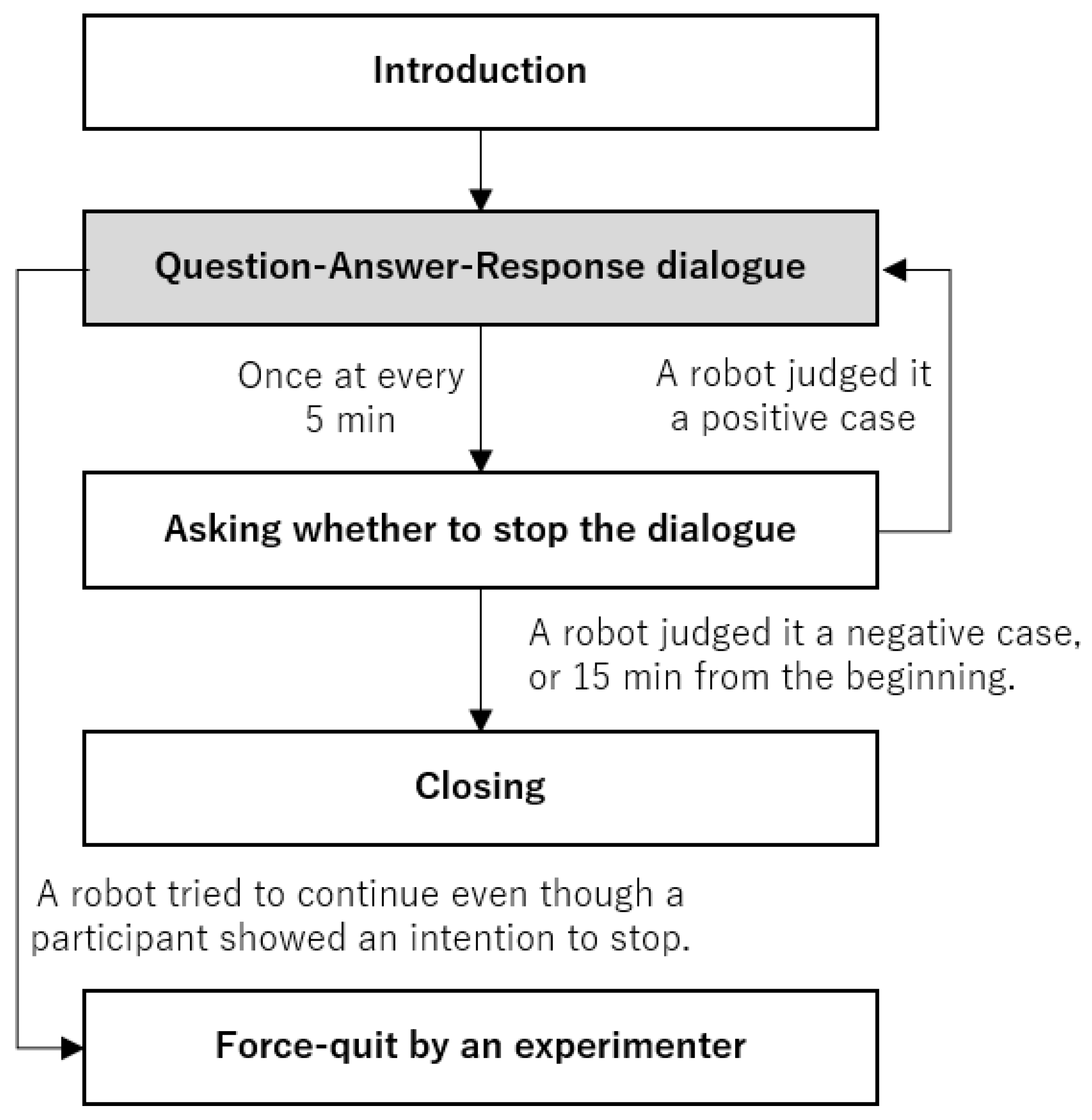
6.4. Procedure
6.5. Dialogue Contents
6.6. Measurements
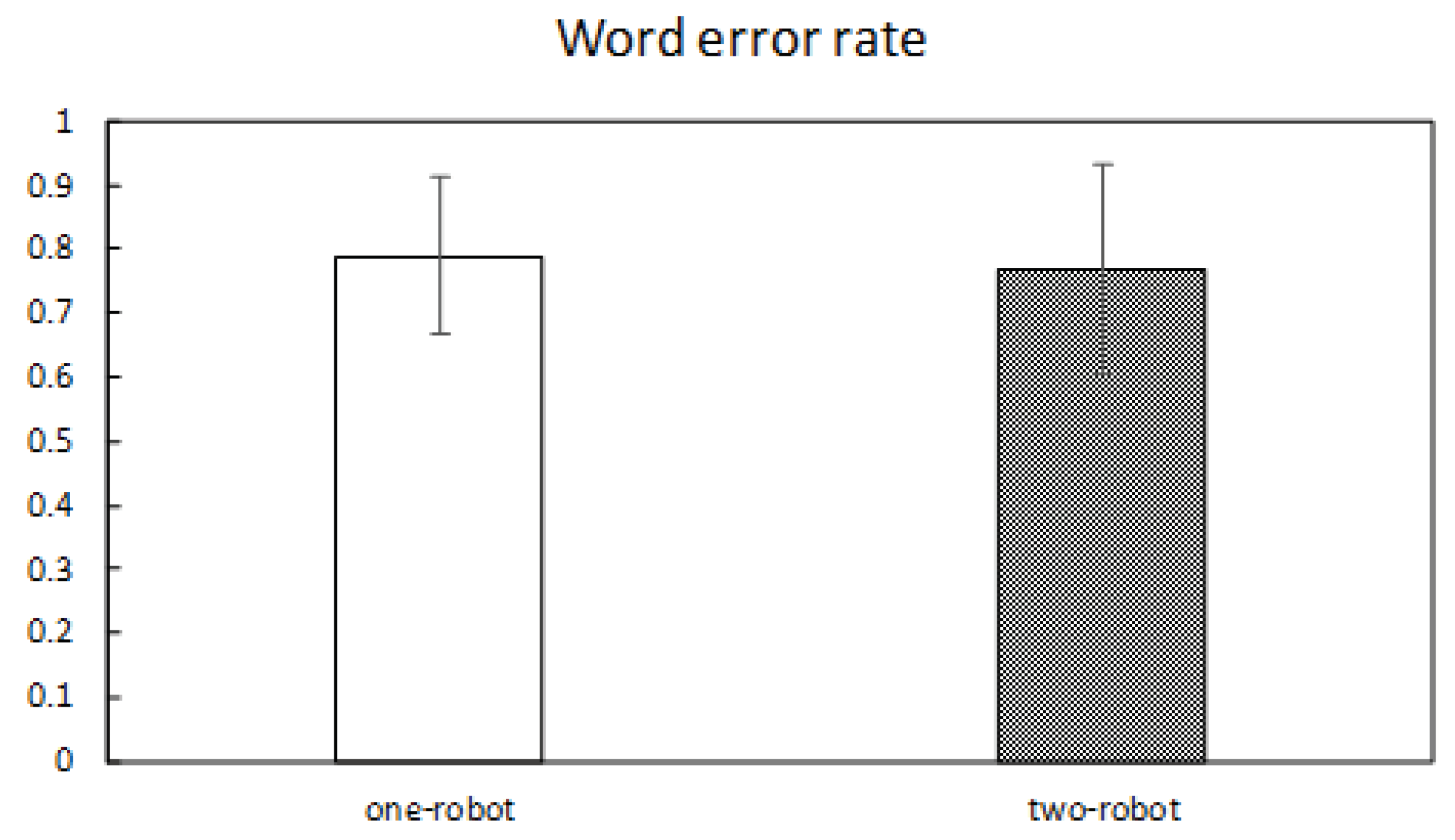
6.6.1. Word Error Rate
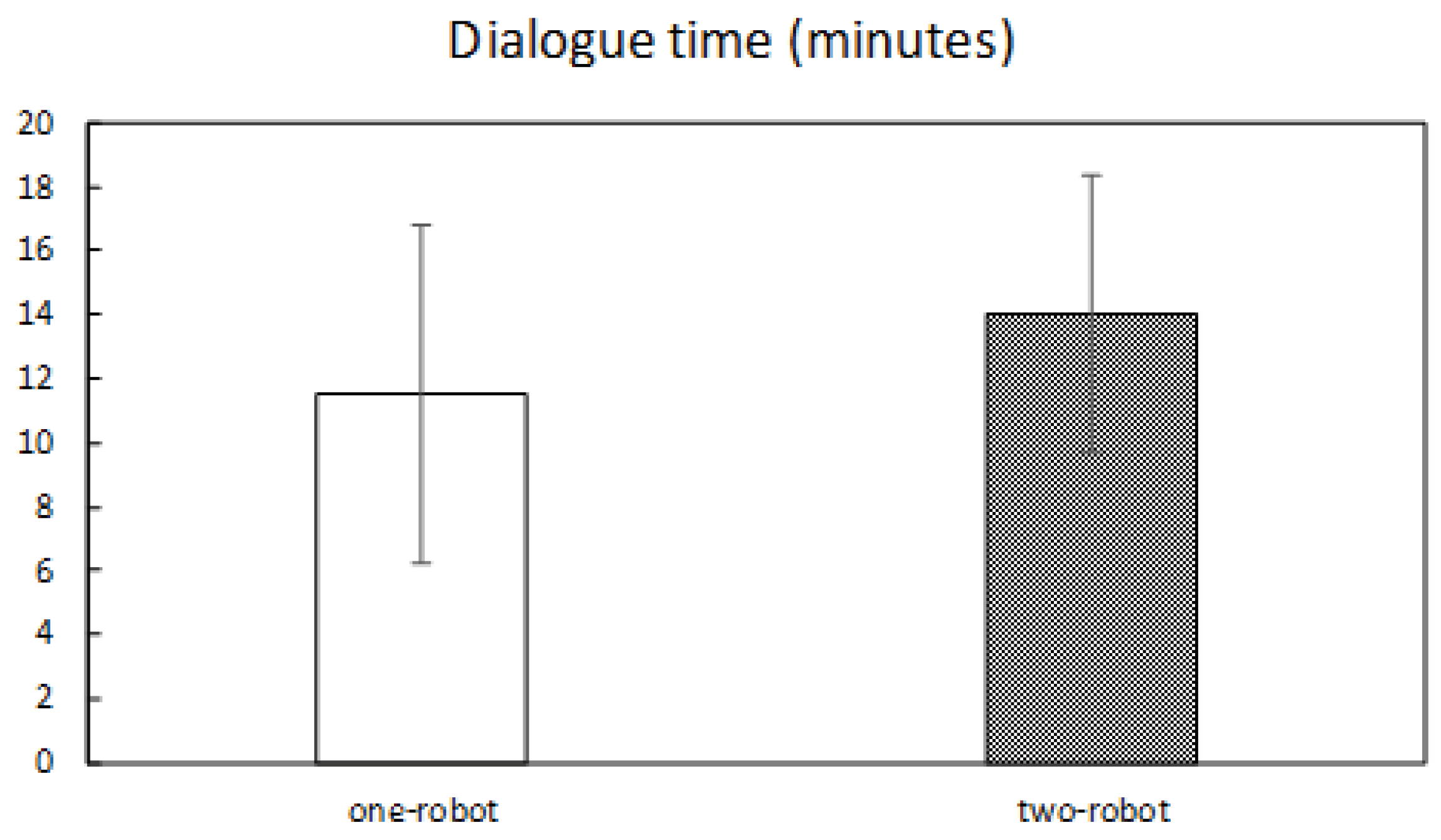
6.6.2. Dialogue Time
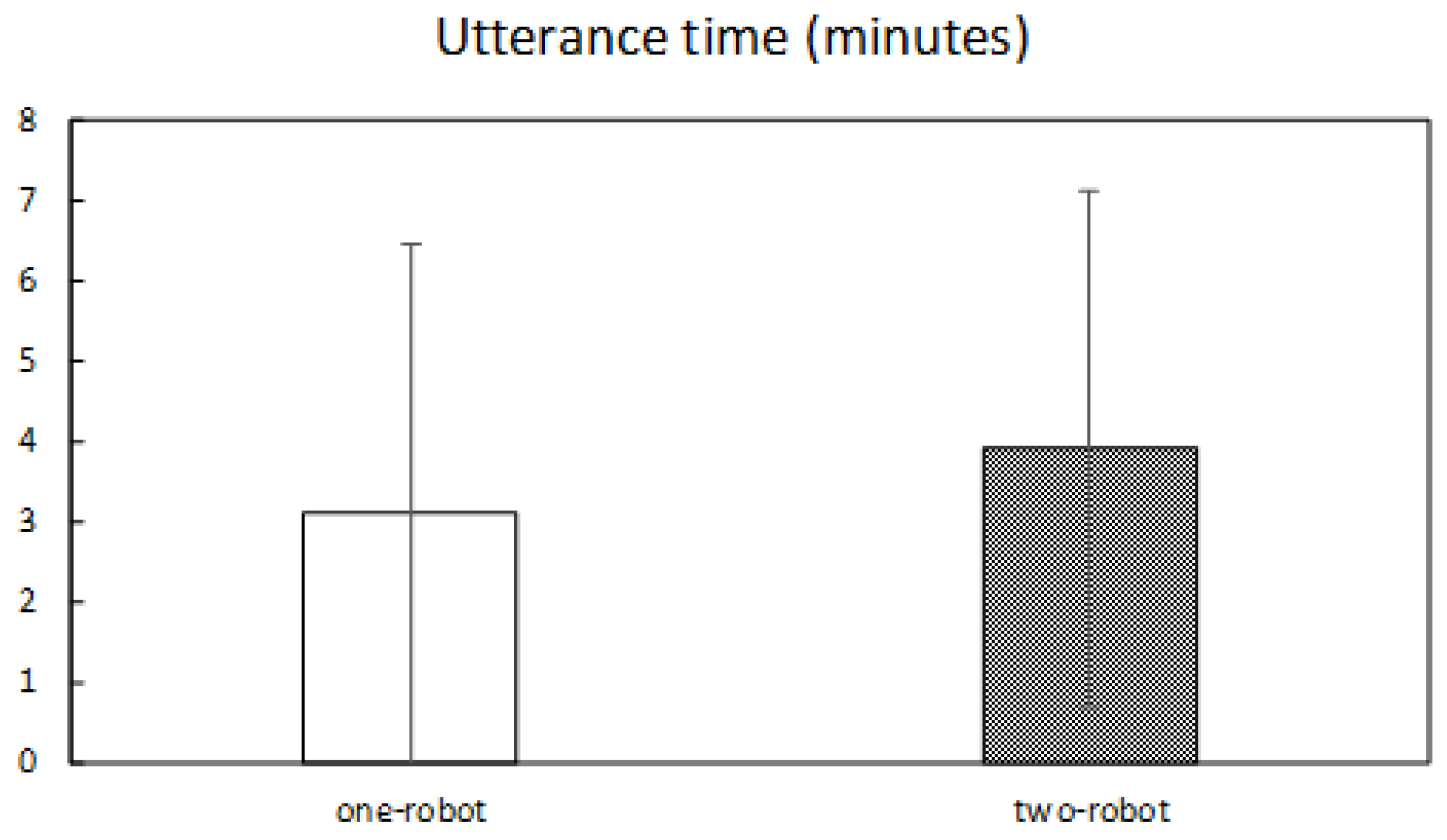
6.6.3. Participant Utterance Time
6.6.4. Participant Subjective Impression
6.6.5. Caregiver Subjective Impression
7. Results
7.1. Word Error Rate
7.2. Dialogue Time
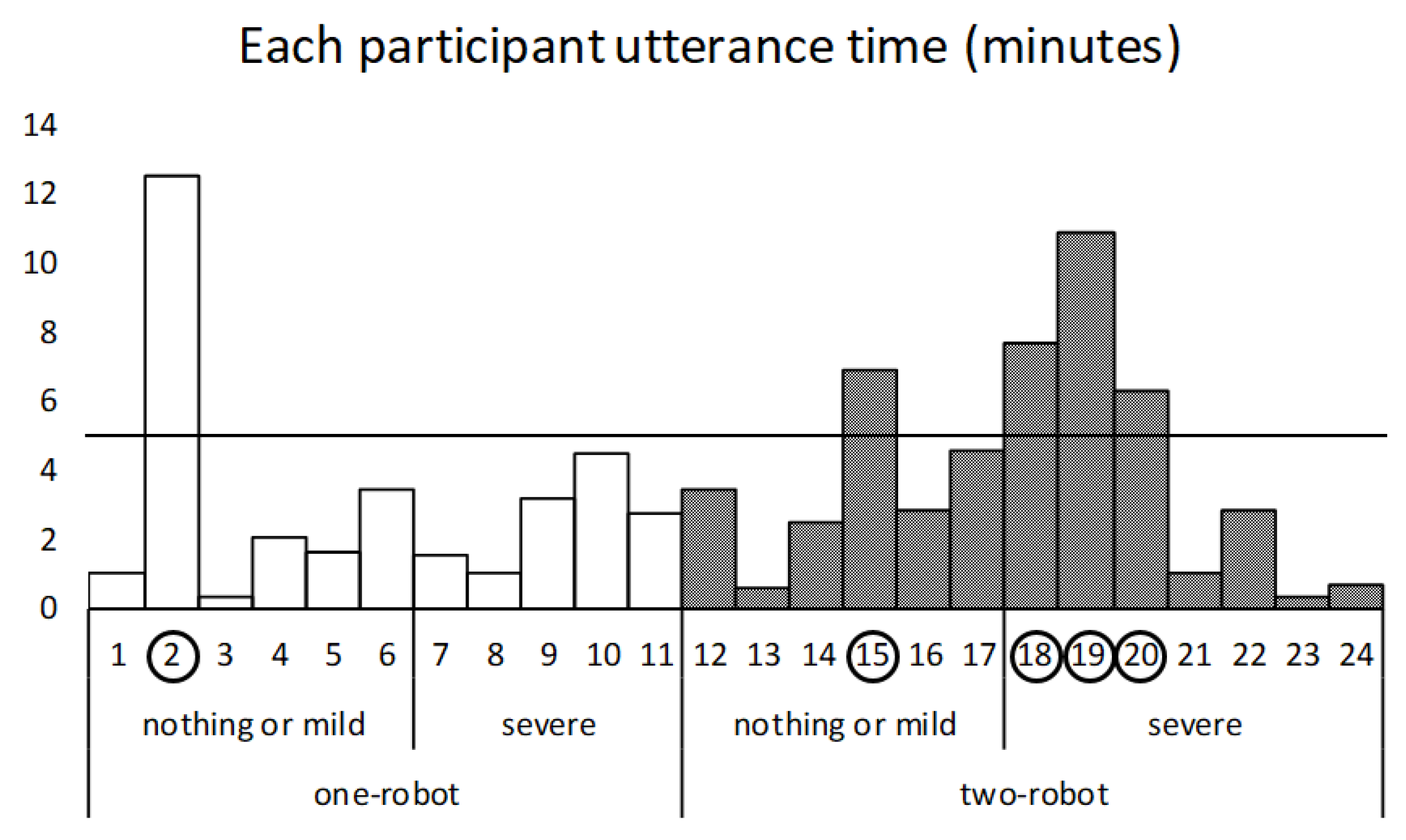
7.3. Participant Utterance Time
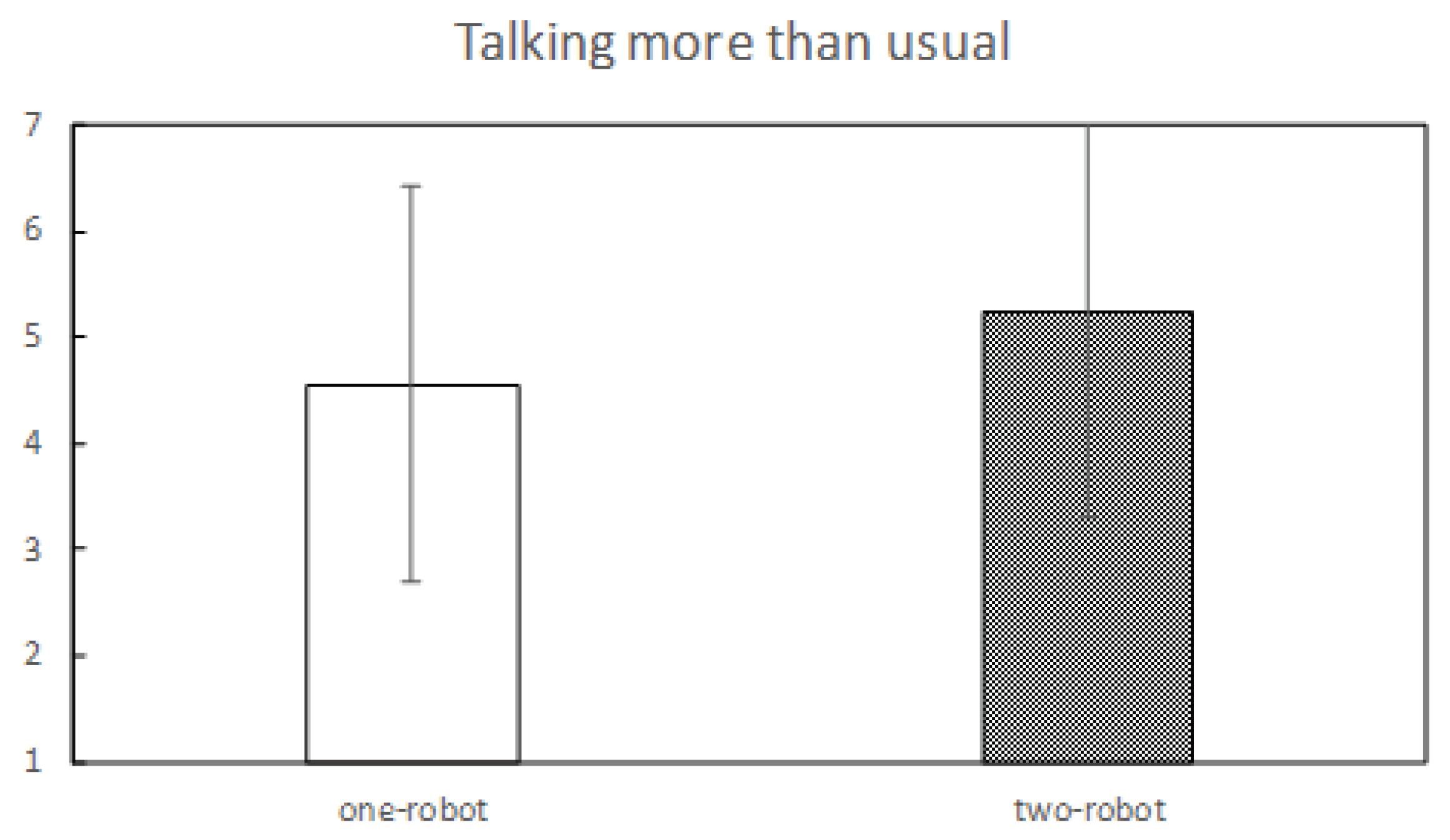
7.4. Participant Subjective Impression
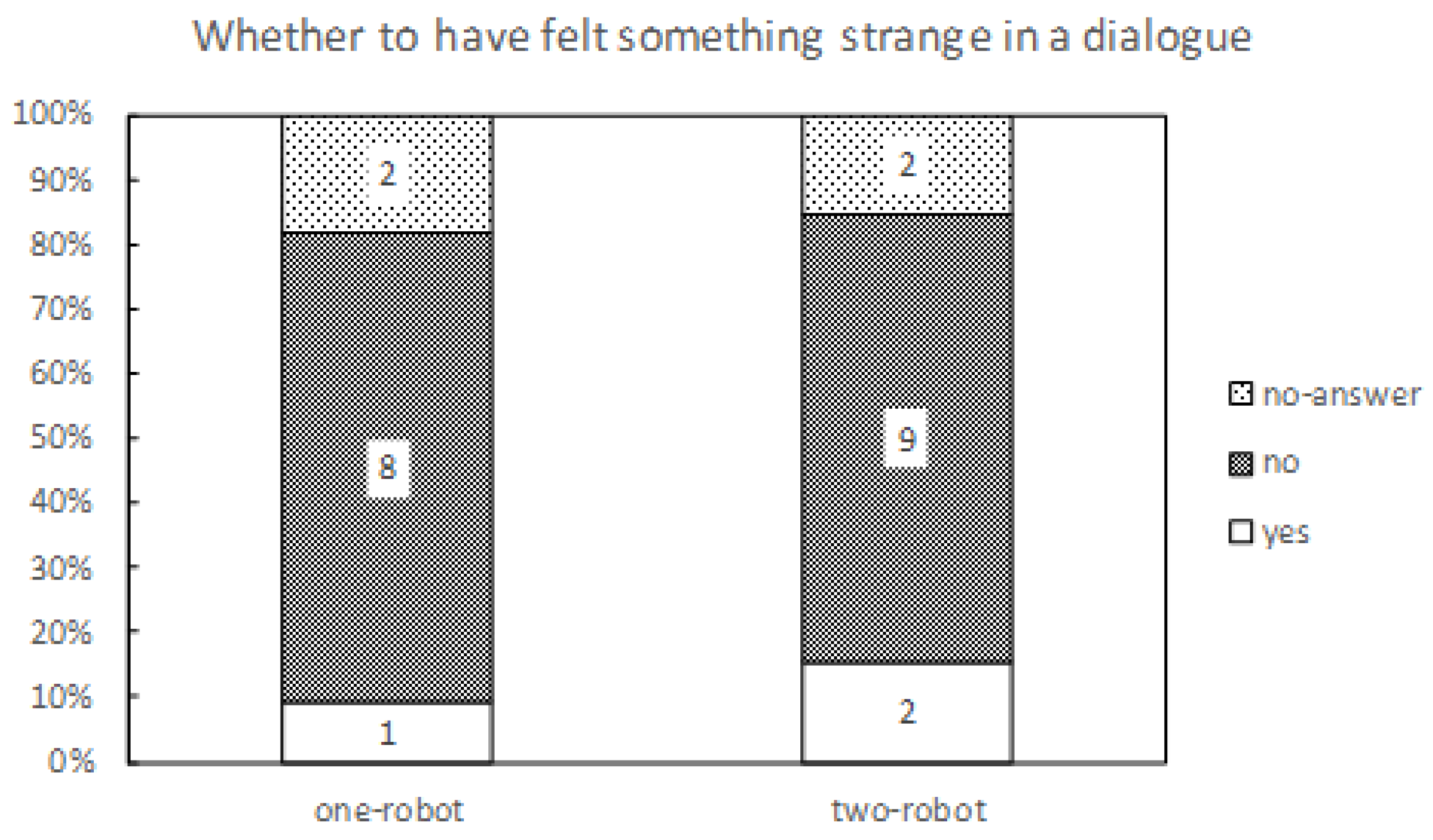
7.5. Caregiver Subjective Impression
8. Discussion and Conclusions
8.1. Interpretation of the Results
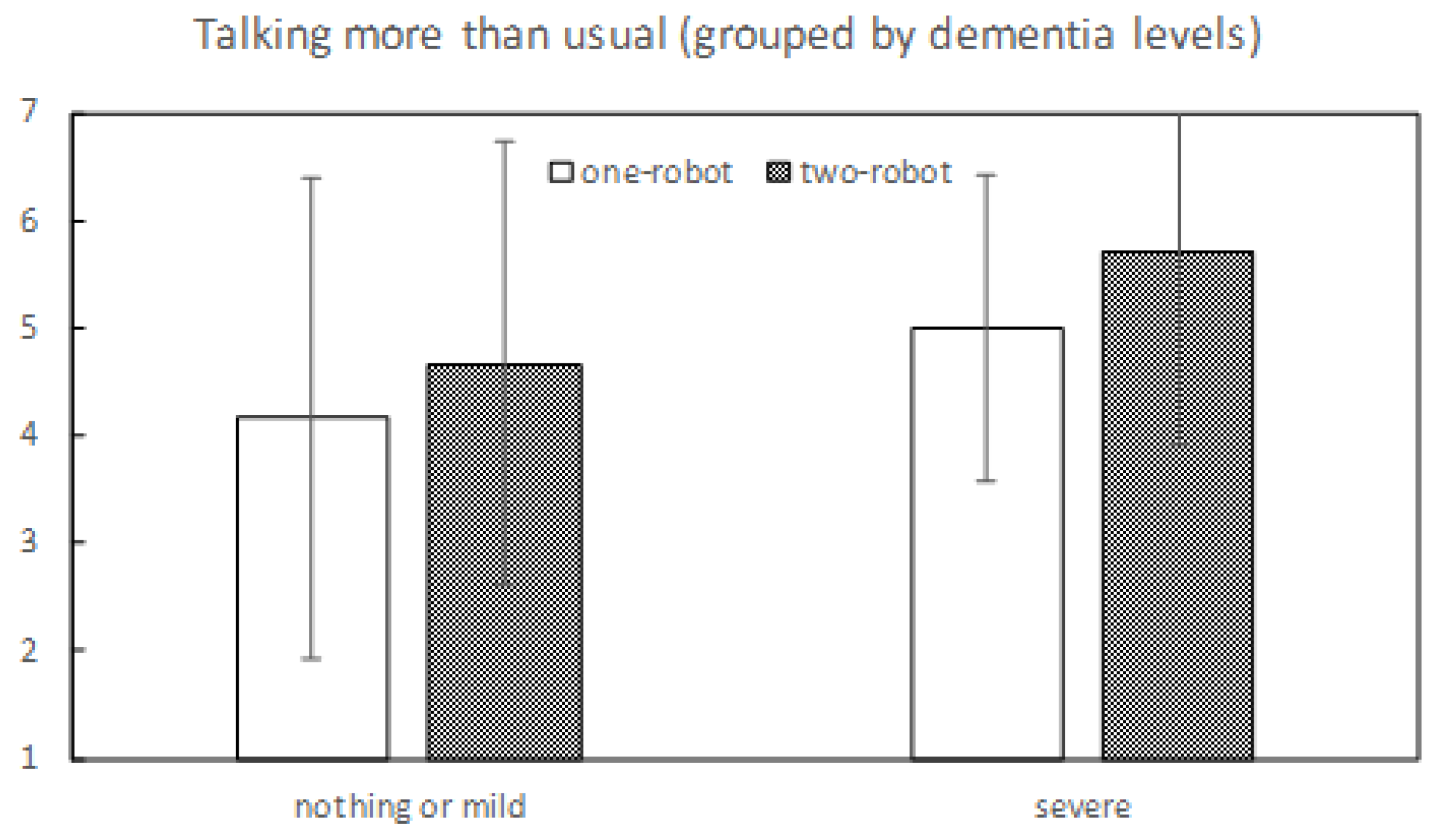
8.2. Effects on the Elderly with Dementia
8.3. Influence of Topics on Participants’ Utterance Time
8.4. Pros and Cons of Our System
- Leading a dialogue by a robot
- Pros. Participants who have no topic to discuss might have easily taken part in a dialogue. In general, it is quite challenging for people to initiate a dialogue unless they have topics they would want to talk about. We found that many participants had no topic to discuss with the robot. By the robot initiating a dialogue, those participants could have participated in the dialogue without worrying about initiating it.
- Cons. Dialogue initiation by the robot may have frustrated some participants in case they had something they would have preferred to talk about with the robot.
- Patterning a dialogue
- Pros. Participants who are not good at communicating smoothly might have easily followed a dialogue because the user could have predicted the flow of the dialogue. This aspect should be important in dialogues for elderly people with declining cognitive ability.
- Cons. Participants who have no communication problems might have felt bored earlier during a dialogue if the dialogue was monotonous.
- Choosing robot responses by using keyword match of user answers
- Pros. This method was clearly robust against speech recognition failures. In our question–answer–response dialogue model, if the speech recognition result contains words of the keyword attribute, the backchannel (comment) associated with the keyword is selected. Otherwise, the backchannel (comment) associated with no keyword (i.e., the default backchannel (comment)) is selected. Therefore, when the speech recognition result is a broken sentence, the default backchannel (comment) is selected in most cases. Because the default backchannel (comment) is a sentence that is coherent for any answer, the dialogue was usually coherent even if the speech recognition fails.
- Cons. There are two situations for a dialogue to break down. First, there is the case where a user asks a robot a question while the robot is in the “answer mode”. Here, the sentence associated with the default attribute is selected unless it was time for the user to be posing a question to the robot. Because the sentence of the default attribute is not meaningful to the question, the dialogue would become unnatural. Second, there is the case where a keyword is matched owing to speech recognition failures, although this will rarely happen. For example, let us consider the following situation: a robot asks “Which countries do you want to travel, France or England?”. Although a user answers France, the speech recognition result could be England. At this point, the dialogue would be strange because the robot would choose “England” as the response. To avoid this, we need more sophisticated algorithms.
8.5. Application of the System
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- House, J.S.; Landis, K.R.; Umberson, D. Social relationships and health. Science 1988, 241, 540–545. [Google Scholar] [CrossRef] [PubMed]
- Cornwell, E.Y.; Waite, L.J. Social disconnectedness, perceived isolation, and health among older adults. J. Health Soc. Behav. 2009, 50, 31–48. [Google Scholar] [CrossRef] [PubMed]
- Holt-Lunstad, J.; Smith, T.B.; Baker, M.; Harris, T.; Stephenson, D. Loneliness and social isolation as risk factors for mortality: A meta-analytic review. Perspect. Psychol. Sci. 2015, 10, 227–237. [Google Scholar] [CrossRef] [PubMed]
- Kotwal, A.A.; Kim, J.; Waite, L.; Dale, W. Social function and cognitive status: Results from a US nationally representative survey of older adults. J. Gen. Intern. Med. 2016, 31, 854–862. [Google Scholar] [CrossRef]
- Poey, J.L.; Burr, J.A.; Roberts, J.S. Social connectedness, perceived isolation, and dementia: Does the social environment moderate the relationship between genetic risk and cognitive well-being? Gerontologist 2017, 57, 1031–1040. [Google Scholar] [CrossRef]
- Heikkinen, R.L.; Kauppinen, M. Depressive symptoms in late life: A 10-year follow-up. Arch. Gerontol. Geriatr. 2004, 38, 239–250. [Google Scholar] [CrossRef]
- Berkman, L.F.; Syme, S.L. Social networks, host resistance, and mortality: A nine-year follow-up study of Alameda County residents. Am. J. Epidemiol. 1979, 109, 186–204. [Google Scholar] [CrossRef]
- Japan Cabinet Office: Annual Report on the Ageing Society: 2018 (Summary), <Viewpoint 2> Establishing a New Paradigm of Health through Science and Technology in Ageing Society. Available online: https://www8.cao.go.jp/kourei/english/annualreport/2018/2018pdf_e.html (accessed on 20 February 2020).
- Broadbent, E.; Stafford, R.; MacDonald, B. Acceptance of healthcare robots for the older population: Review and future directions. Int. J. Soc. Robot. 2009, 1, 319. [Google Scholar] [CrossRef]
- Kachouie, R.; Sedighadeli, S.; Khosla, R.; Chu, M.T. Socially assistive robots in elderly care: A mixed-method systematic literature review. Int. J. Hum.-Comput. Interact. 2014, 30, 369–393. [Google Scholar] [CrossRef]
- Erber, N.P. Conversation as therapy for older adults in residential care: The case for intervention. Int. J. Lang. Commun. Disord. 1994, 29, 269–278. [Google Scholar] [CrossRef]
- Caris-Verhallen, W.M.; Kerkstra, A.; Bensing, J.M. The role of communications in nursing care for elderly people: A review of the literature. J. Adv. Nurs. 1997, 25, 915–933. [Google Scholar] [CrossRef] [PubMed]
- Grainger, K. Communication and the institutionalized elderly. In Handbook of Communication and Aging Research; Routledge: Abingdon, UK, 2004; pp. 479–497. [Google Scholar]
- Allen, C.I.; Turner, P.S. The effect of an intervention programme on interactions on a continuing care ward for older people. J. Adv. Nurs. 1991, 16, 1172–1177. [Google Scholar] [CrossRef] [PubMed]
- Allen-Burge, R.; Burgio, L.D.; Bourgeois, M.S.; Sims, R.; Nunnikhoven, J. Increasing communication among nursing home residents. J. Clin. Geropsychol. 2001, 7, 213–230. [Google Scholar] [CrossRef]
- Nieuwenhuis, R. Breaking the speech barrier. Nurs. Times 1989, 85, 34. [Google Scholar] [PubMed]
- Kopp, S.; Brandt, M.; Buschmeier, H.; Cyra, K.; Freigang, F.; Krämer, N.; Straßmann, C. Conversational Assistants for Elderly Users–The Importance of Socially Cooperative Dialogue. In Proceedings of the AAMAS Workshop on Intelligent Conversation Agents in Home and Geriatric Care Applications, Stockholm, Sweden, 15 July 2018. [Google Scholar]
- Young, V.; Mihailidis, A. Difficulties in automatic speech recognition of dysarthric speakers and implications for speech-based applications used by the elderly: A literature review. Assist. Technol. 2010, 22, 99–112. [Google Scholar] [CrossRef]
- Yaghoubzadeh, R.; Kramer, M.; Pitsch, K.; Kopp, S. Virtual agents as daily assistants for elderly or cognitively impaired people. In Proceedings of the International Workshop on Intelligent Virtual Agents, Edinburgh, UK, 29–31 August 2013; pp. 79–91. [Google Scholar]
- Feil-Seifer, D.; Mataric, M.J. Defining socially assistive robotics. In Proceedings of the 9th International Conference on Rehabilitation Robotics—ICORR 2005, Chicago, IL, USA, 28 June–1 July2005; pp. 465–468. [Google Scholar]
- Gomi, T.; Griffith, A. Developing intelligent wheelchairs for the handicapped. In Assistive Technology and Artificial Intelligence; Springer: Berlin/Heidelberg, Germany, 1998; pp. 150–178. [Google Scholar]
- Shiomi, M.; Iio, T.; Kamei, K.; Sharma, C.; Hagita, N. Effectiveness of social behaviors for autonomous wheelchair robot to support elderly people in Japan. PLoS ONE 2015, 10, e0128031. [Google Scholar] [CrossRef] [PubMed]
- Kazerooni, H.; Steger, R.; Huang, L. Hybrid control of the Berkeley lower extremity exoskeleton (BLEEX). Int. J. Robot. Res. 2006, 25, 561–573. [Google Scholar] [CrossRef]
- Kiguchi, K.; Rahman, M.H.; Sasaki, M.; Teramoto, K. Development of a 3DOF mobile exoskeleton robot for human upper-limb motion assist. Robot. Auton. Syst. 2008, 56, 678–691. [Google Scholar] [CrossRef]
- Pollack, M.E.; Brown, L.; Colbry, D.; Orosz, C.; Peintner, B.; Ramakrishnan, S.; Thrun, S. Pearl: A mobile robotic assistant for the elderly. In Proceedings of the AAAI Workshop on Automation as Eldercare, Edmonton, AB, Canada, 28–29 July 2002; Volume 2002, pp. 85–91. [Google Scholar]
- Beskow, J.; Edlund, J.; Granström, B.; Gustafson, J.; Skantze, G.; Tobiasson, H. The MonAMI Reminder: A spoken dialogue system for face-to-face interaction. In Proceedings of the Tenth Annual Conference of the International Speech Communication Association, Brighton, UK, 6–10 September 2009. [Google Scholar]
- Noury, N.; Rumeau, P.; Bourke, A.K.; ÓLaighin, G.; Lundy, J.E. A proposal for the classification and evaluation of fall detectors. IRBM 2008, 29, 340–349. [Google Scholar] [CrossRef]
- Iio, T.; Shiomi, M.; Kamei, K.; Sharma, C.; Hagita, N. Social acceptance by senior citizens and caregivers of a fall detection system using range sensors in a nursing home. Adv. Robot. 2016, 30, 190–205. [Google Scholar] [CrossRef]
- Dario, P.; Guglielmelli, E.; Laschi, C.; Teti, G. MOVAID: A personal robot in everyday life of disabled and elderly people. Technol. Disabil. 1999, 10, 77–93. [Google Scholar] [CrossRef]
- Graf, B.; Hans, M.; Schraft, R.D. Mobile robot assistants. IEEE Robot. Autom. Mag. 2004, 11, 67–77. [Google Scholar] [CrossRef]
- Iwamura, Y.; Shiomi, M.; Kanda, T.; Ishiguro, H.; Hagita, N. Do elderly people prefer a conversational humanoid as a shopping assistant partner in supermarkets? In Proceedings of the 6th International Conference on Human-Robot Interaction, Lausanne, Switzerland, 6–9 March 2011; pp. 449–456. [Google Scholar]
- Shibata, T.; Wada, K. Robot therapy: A new approach for mental healthcare of the elderly–a mini-review. Gerontology 2011, 57, 378–386. [Google Scholar] [CrossRef] [PubMed]
- Kanamori, M.; Suzuki, M.; Oshiro, H.; Tanaka, M.; Inoguchi, T.; Takasugi, H.; Yokoyama, T. Pilot study on improvement of quality of life among elderly using a pet-type robot. In Proceedings of the 2003 IEEE International Symposium on Computational Intelligence in Robotics and Automation. Computational Intelligence in Robotics and Automation for the New Millennium (Cat. No. 03EX694), Kobe, Japan, 16–20 July 2003; Volume 1, pp. 107–112. [Google Scholar]
- Tamura, T.; Yonemitsu, S.; Itoh, A.; Oikawa, D.; Kawakami, A.; Higashi, Y.; Fujimoto, T.; Nakajima, K. Is an entertainment robot useful in the care of elderly people with severe dementia? J. Gerontol. Ser. A Biol. Sci. Med. Sci. 2004, 59, M83–M85. [Google Scholar] [CrossRef] [PubMed]
- Libin, A.; Cohen-Mansfield, J. Therapeutic robocat for nursing home residents with dementia: Preliminary inquiry. Am. J. Alzheimer’s Dis. Other Dement. 2004, 19, 111–116. [Google Scholar] [CrossRef] [PubMed]
- Abdollahi, H.; Mollahosseini, A.; Lane, J.T.; Mahoor, M.H. A pilot study on using an intelligent life-like robot as a companion for elderly individuals with dementia and depression. In Proceedings of the 2017 IEEE-RAS 17th International Conference on Humanoid Robotics (Humanoids), Birmingham, UK, 15–17 November 2017; pp. 541–546. [Google Scholar]
- Yaghoubzadeh, R.; Buschmeier, H.; Kopp, S. Socially cooperative behavior for artificial companions for elderly and cognitively impaired people. In Proceedings of the 1st International Symposium on Companion-Technology, Ulm, Germany, 23–25 September 2015. [Google Scholar]
- Kanoh, M.; Oida, Y.; Nomura, Y.; Araki, A.; Konagaya, Y.; Ihara, K.; Kimura, K. Examination of practicability of communication robot-assisted activity program for elderly people. J. Robot. Mechatron. 2011, 23, 3. [Google Scholar] [CrossRef]
- Khosla, R.; Chu, M.T.; Kachouie, R.; Yamada, K.; Yamaguchi, T. Embodying care in Matilda: An affective communication robot for the elderly in Australia. In Proceedings of the 2nd ACM SIGHIT International Health Informatics Symposium, Miami, FL, USA, 28–30 January 2012; pp. 295–304. [Google Scholar]
- Minami, H.; Kawanami, H.; Kanbara, M.; Hagita, N. Chat robot coupling machine responses and social media comments for continuous conversation. In Proceedings of the 2016 IEEE International Conference on Multimedia and Expo Workshops (ICMEW), Seattle, WA, USA, 11–15 July 2016; pp. 1–6. [Google Scholar]
- Otaki, H.; Otake, M. Interactive Robotic System Assisting Image Based Dialogue for the Purpose of Cognitive Training of Older Adults. In Proceedings of the 2017 AAAI Spring Symposium Series, Stanford, CA, USA, 27–29 March 2017. [Google Scholar]
- Otake, M.; Kato, M.; Takagi, T.; Asama, H. The coimagination method and its evaluation via the conversation interactivity measuring method. In Early Detection and Rehabilitation Technologies for Dementia: Neuroscience and Biomedical Applications; IGI Global: Hershey, PA, USA, 2011; pp. 356–364. [Google Scholar]
- Sakakibara, S.; Saiki, S.; Nakamura, M.; Yasuda, K. Generating personalized dialogue towards daily counseling system for home dementia care. In Proceedings of the International Conference on Digital Human Modeling and Applications in Health, Safety, Ergonomics and Risk Management, Vancouver, BC, Canada, 9–14 July 2017; pp. 161–172. [Google Scholar]
- Jokinen, K. Dialogue models for socially intelligent robots. In Proceedings of the International Conference on Social Robotics, Qingdao, China, 28–30 November 2018; pp. 127–138. [Google Scholar]
- Jokinen, K.; Nishimura, S.; Watanabe, K.; Nishimura, T. Human-robot dialogues for explaining activities. In Proceedings of the 9th International Workshop on Spoken Dialogue System Technology, Singapore, 18–20 April 2019; pp. 239–251. [Google Scholar]
- Arimoto, T.; Yoshikawa, Y.; Ishiguro, H. Multiple-robot conversational patterns for concealing incoherent responses. Int. J. Soc. Robot. 2018, 10, 583–593. [Google Scholar] [CrossRef]
- Iio, T.; Yoshikawa, Y.; Ishiguro, H. Retaining Human-Robots Conversation: Comparing Single Robot to Multiple Robots in a Real Event. J. Adv. Comput. Intell. Intell. Inform. 2017, 21, 675–685. [Google Scholar] [CrossRef]
- Todo, Y.; Nishimura, R.; Yamamoto, K.; Nakagawa, S. Development and evaluation of spoken dialog systems with one or two agents through two domains. In Proceedings of the International Conference on Text, Speech and Dialogue, Pilsen, Czech Republic, 1–5 September 2013; pp. 185–192. [Google Scholar]
- Shibahara, Y.; Yamamoto, K.; Nakagawa, S. Effect of sympathetic relation and unsympathetic relation in multi-agent spoken dialogue system. In Proceedings of the 2016 International Conference On Advanced Informatics: Concepts, Theory and Application (ICAICTA), George Town, Malaysia, 16–19 August 2016; pp. 1–6. [Google Scholar]
- Arimoto, T.; Yoshikawa, Y.; Ishiguro, H. Nodding responses by collective proxy robots for enhancing social telepresence. In Proceedings of the Second International Conference on Human-Agent Interaction, Tsukuba, Japan, 28–30 October 2014; pp. 97–102. [Google Scholar]
- Karatas, N.; Yoshikawa, S.; Okada, M. Namida: Sociable driving agents with multiparty conversation. In Proceedings of the Fourth International Conference on Human Agent Interaction, Singapore, 4–7 October 2016; pp. 35–42. [Google Scholar]
- Sakamoto, D.; Hayashi, K.; Kanda, T.; Shiomi, M.; Koizumi, S.; Ishiguro, H.; Ogasawara, t.; Hagita, N. Humanoid robots as a broadcasting communication medium in open public spaces. Int. J. Soc. Robot. 2009, 1, 157–169. [Google Scholar] [CrossRef]
- Goffman, E. Forms of Talk; University of Pennsylvania Press: Philadelphia, PA, USA, 1981. [Google Scholar]
- Sacks, H.; Schegloff, E.A.; Jefferson, G. A simplest systematics for the organization of turn taking for conversation. In Studies in the Organization of Conversational Interaction; Academic Press: Cambridge, MA, USA, 1978; pp. 7–55. [Google Scholar]
- Clark, H.H.; Carlson, T.B. Hearers and speech acts. Language 1982, 58, 332–373. [Google Scholar] [CrossRef]
- Schegloff, E.A.; Sacks, H. Opening up closings. Semiotica 1973, 8, 289–327. [Google Scholar] [CrossRef]
- Schegloff, E.A. Sequence Organization in Interaction: A Primer in Conversation Analysis I (Vol. 1); Cambridge University Press: Cambridge, UK, 2007. [Google Scholar]
- McCowan, I.A.; Moore, D.; Dines, J.; Gatica-Perez, D.; Flynn, M.; Wellner, P.; Bourlard, H. On the Use of Information Retrieval Measures for Speech Recognition Evaluation (No. REP_WORK); IDIAP: Martigny, Switzerland, 2004. [Google Scholar]
- The Jamovi Project. Jamovi (Version 0.9) [Computer Software]. 2019. Available online: https://www.jamovi.org (accessed on 20 February 2020).














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| State | RUC | UUR | TO |
|---|---|---|---|
| Question | Answer | - | - |
| Answer | - | Backchannel | Comment |
| Backchannel | Comment | - | - |
| Comment | Question | - | - |
| Cognitive Capacities | Scenario | Total | |
|---|---|---|---|
| One-Robot | Two-Robot | ||
| Noting or mild | 6 | 6 | 12 |
| Severe | 5 | 7 | 12 |
| Total | 11 | 13 | 24 |
| Topic | Number | Example |
|---|---|---|
| Childhood | 16 | “Where did you usually play?” |
| “What toy did you want?” | ||
| “Did you like to go to school?” | ||
| Travel | 20 | "Do you like travel?” |
| “Where have you traveled so far?” | ||
| “What was the best food you have had in travel?” | ||
| Health | 19 | “Have you had severe illness so far?” |
| “Do you like walking?” | ||
| “Do you have food you eat for health?” |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Iio, T.; Yoshikawa, Y.; Chiba, M.; Asami, T.; Isoda, Y.; Ishiguro, H. Twin-Robot Dialogue System with Robustness against Speech Recognition Failure in Human-Robot Dialogue with Elderly People. Appl. Sci. 2020, 10, 1522. https://doi.org/10.3390/app10041522
Iio T, Yoshikawa Y, Chiba M, Asami T, Isoda Y, Ishiguro H. Twin-Robot Dialogue System with Robustness against Speech Recognition Failure in Human-Robot Dialogue with Elderly People. Applied Sciences. 2020; 10(4):1522. https://doi.org/10.3390/app10041522
Chicago/Turabian StyleIio, Takamasa, Yuichiro Yoshikawa, Mariko Chiba, Taichi Asami, Yoshinori Isoda, and Hiroshi Ishiguro. 2020. "Twin-Robot Dialogue System with Robustness against Speech Recognition Failure in Human-Robot Dialogue with Elderly People" Applied Sciences 10, no. 4: 1522. https://doi.org/10.3390/app10041522
APA StyleIio, T., Yoshikawa, Y., Chiba, M., Asami, T., Isoda, Y., & Ishiguro, H. (2020). Twin-Robot Dialogue System with Robustness against Speech Recognition Failure in Human-Robot Dialogue with Elderly People. Applied Sciences, 10(4), 1522. https://doi.org/10.3390/app10041522