A High-Performance Deep Learning Algorithm for the Automated Optical Inspection of Laser Welding

Abstract
:1. Introduction
2. Welding Area Image Acquisition and Defect Classification
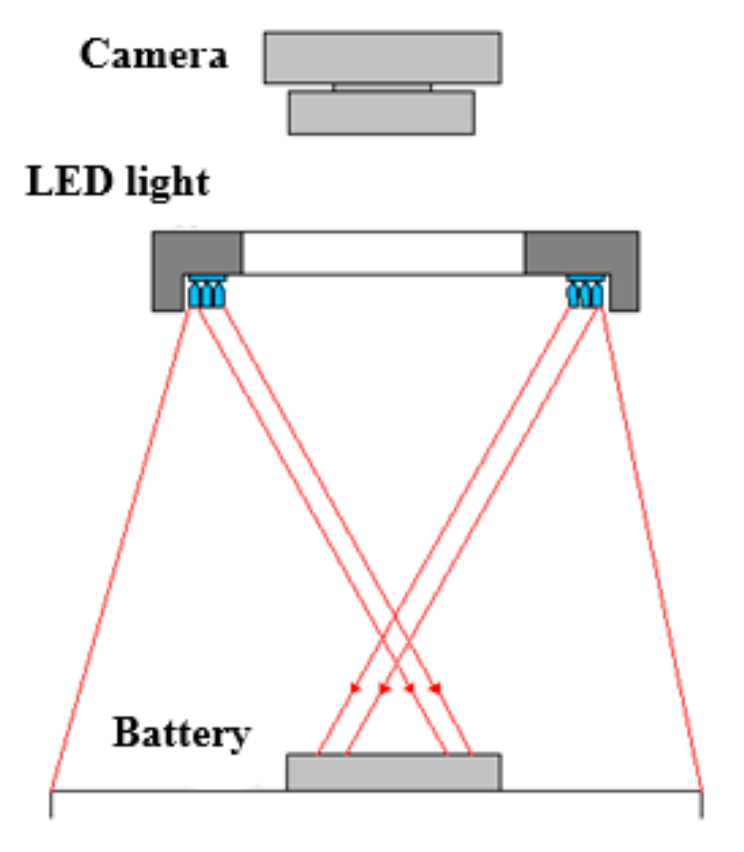
2.1. Welding Area Image Acquisition
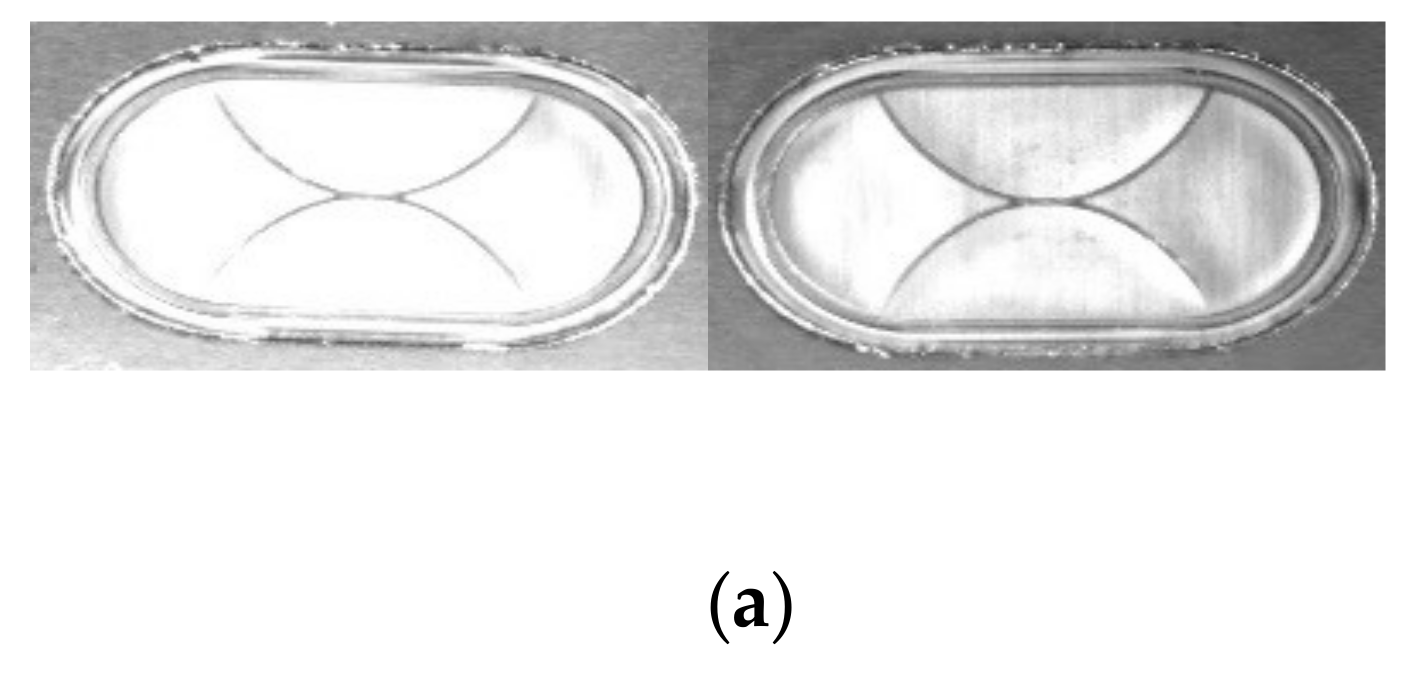
2.2. Defect Classification of the Safety Vent
3. Optimized Visual Geometry Group Model
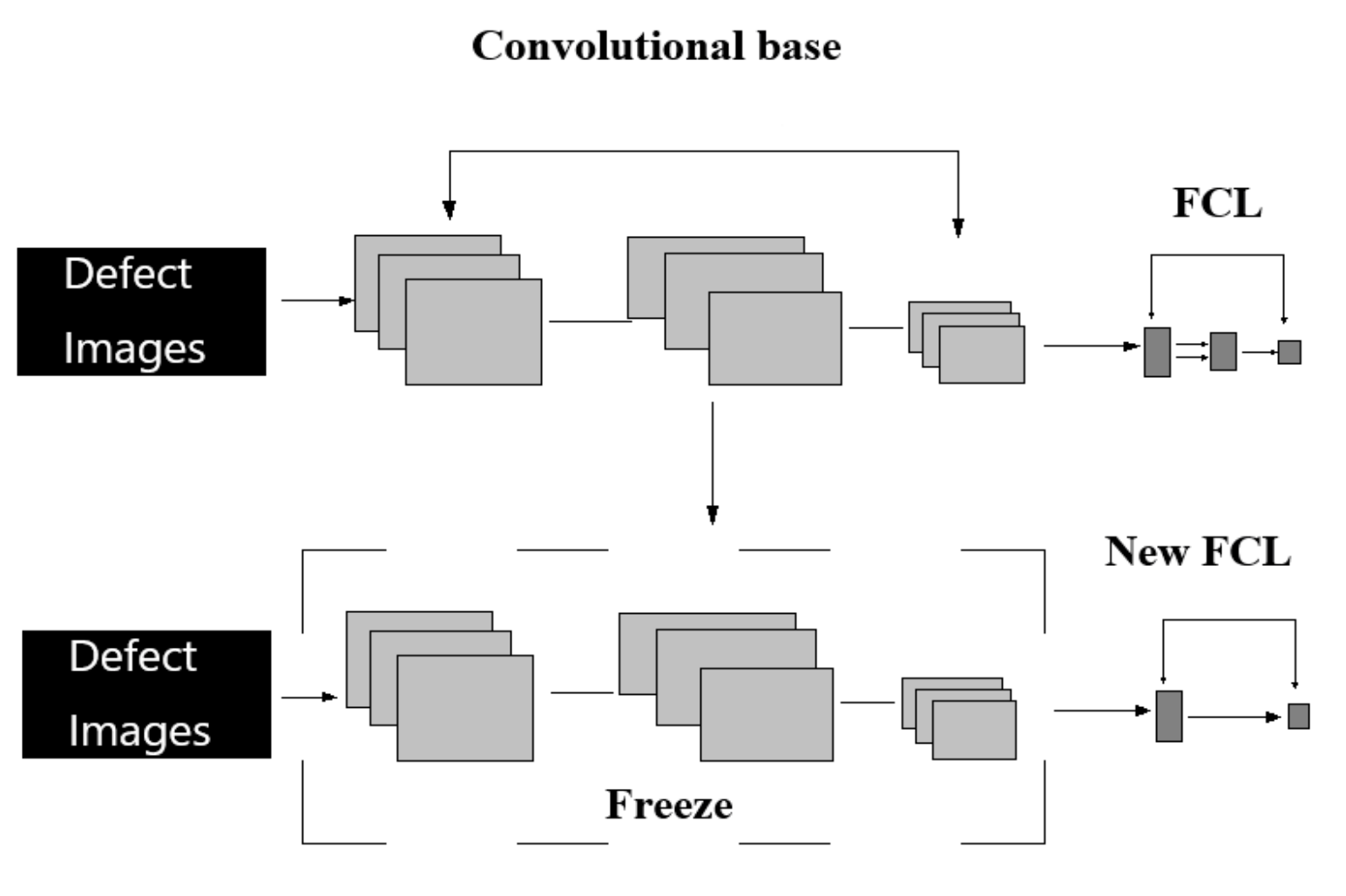
3.1. CNN Architecture
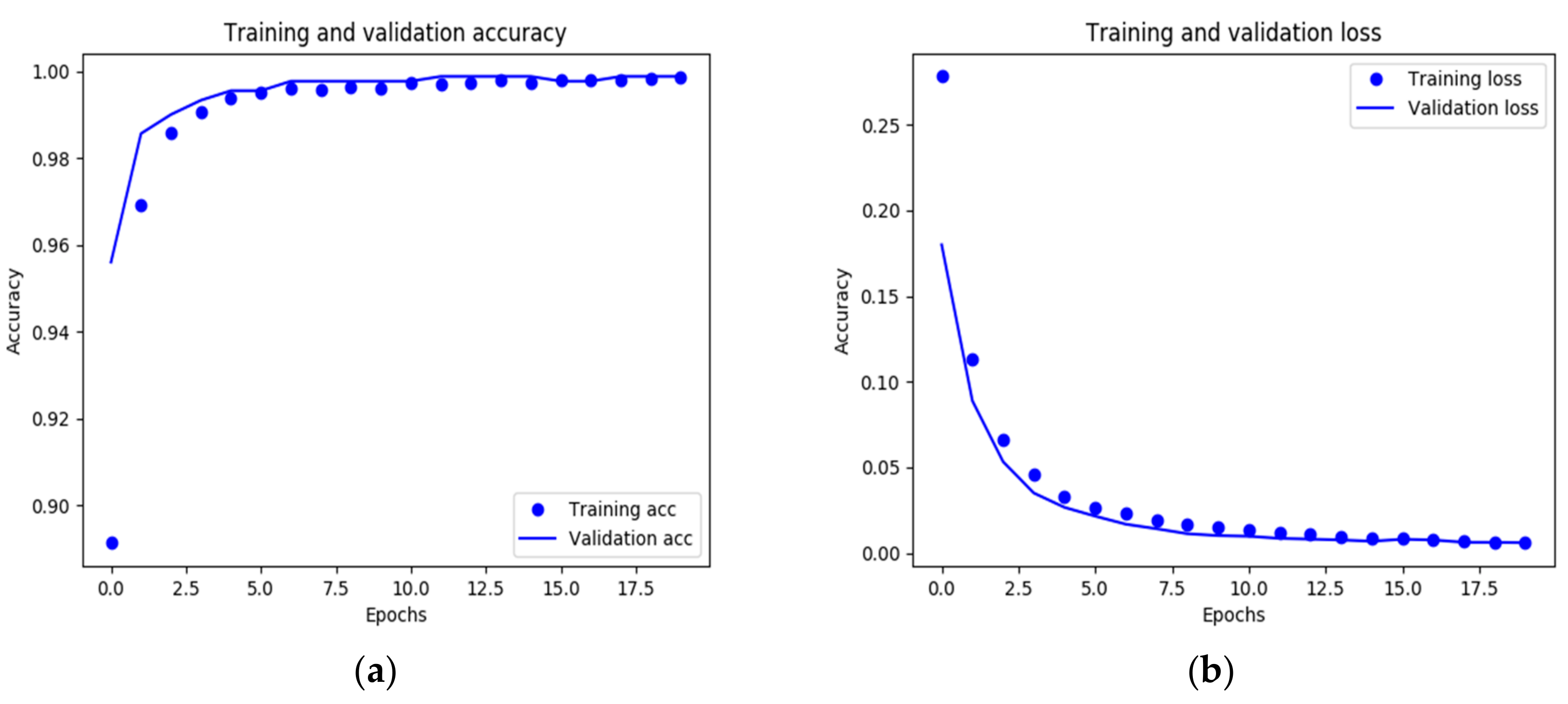
3.2. Training
3.3. Testing
4. Verification and Visualization
4.1. Verification
4.2. Visualizing What the CNNs Learned
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Lee, S.S.; Kim, T.H.; Hu, S.J.; Cai, W.W.; Abell, J.A. Joining Technologies for Automotive Lithium-Ion Battery Manufacturing: A Review. In Proceedings of the ASME 2010, International Manufacturing Science and Engineering Conference, Erie, PA, USA, 12–15 October 2010; pp. 541–549. [Google Scholar]
- Shawn Lee, S.; Hyung Kim, T.; Jack Hu, S.; Cai, W.W.; Abell, J.A.; Li, J. Characterization of Joint Quality in Ultrasonic Welding of Battery Tabs. J. Manuf. Sci. Eng. 2013, 135, 021004. [Google Scholar] [CrossRef]
- Muhammad, J.; Altun, H.; Abo-Serie, E. A robust butt welding seam finding technique for intelligent robotic welding system using active laser vision. Int. J. Adv. Manuf. Technol. 2018, 94, 13–29. [Google Scholar] [CrossRef]
- Thornton, M.; Han, L.; Shergold, M. Progress in NDT of resistance spot welding of aluminium using ultrasonic C-scan. NDT E Int. 2012, 48, 30–38. [Google Scholar] [CrossRef]
- Lashkia, V. Defect detection in X-ray images using fuzzy reasoning. Image Vision Comput. 2001, 19, 261–269. [Google Scholar] [CrossRef]
- Jiaxin, S.; Han, S.; Dong, D.; Li, W.; Huayong, C. Automatic weld defect detection in real-time X-ray images based on support vector machine. In Proceedings of the 4th International Congress on Image and Signal Processing (CISP 2011), Shanghai, China, 15–17 October 2011; pp. 1842–1846. [Google Scholar]
- Wu, H.; Zhang, X.; Xie, H.; Kuang, Y.; Ouyang, G. Classification of Solder Joint Using Feature Selection Based on Bayes and Support Vector Machine. IEEE Trans. Compon. Pack. Manuf. Technol. 2013, 3, 516–522. [Google Scholar] [CrossRef]
- Fonseka, C.; Jayasinghe, J. Implementation of an Automatic Optical Inspection System for Solder Quality Classification of THT Solder Joints. IEEE Trans. Compon. Pack. Manuf. Technol. 2019, 9, 353–366. [Google Scholar] [CrossRef]
- Besl, P.; Delp, E.; Jain, R. Automatic visual solder joint inspection. IEEE J. Robot. Autom. 1985, 1, 42–56. [Google Scholar] [CrossRef]
- Cai, N.; Lin, J.; Ye, Q.; Wang, H.; Weng, S.; Ling, B.W. A New IC Solder Joint Inspection Method for an Automatic Optical Inspection System Based on an Improved Visual Background Extraction Algorithm. IEEE Trans. Compon. Packag. Manuf. Technol. 2016, 6, 161–172. [Google Scholar]
- Jiang, J.; Cheng, J.; Tao, D. Color Biological Features-Based Solder Paste Defects Detection and Classification on Printed Circuit Boards. IEEE Transact. Compon. Packag. Manuf. Technol. 2012, 2, 1536–1544. [Google Scholar] [CrossRef]
- Yang, Z.; Ye, Q.; Wang, H.; Liu, G.; Cai, N. IC solder joint inspection based on the Gaussian mixture model. Solder. Surf. Mount Technol. 2016, 28, 207–214. [Google Scholar]
- Song, J.D.; Kim, Y.G.; Park, T.H. SMT defect classification by feature extraction region optimization and machine learning. Int. J. Adv. Manuf. Technol. 2019, 101, 1303–1313. [Google Scholar] [CrossRef]
- Yun, T.S.; Sim, K.J.; Kim, H.J. Support vector machine-based inspection of solder joints using circular illumination. Electron. Lett. 2000, 36, 949–951. [Google Scholar] [CrossRef]
- Hongwei, X.; Zhang, X.; Yongcong, K.; Gaofei, O. Solder Joint Inspection Method for Chip Component Using Improved AdaBoost and Decision Tree; IEEE: New Jersey, NJ, USA, 2011; Volume 1. [Google Scholar]
- Song, J.-D.; Kim, Y.-G.; Park, T.-H. Defect Classification Method of PCB Solder Joint by Color Features and Region Segmentation. J. Instit. Control Robot. Syst. 2017, 23, 1086–1091. [Google Scholar] [CrossRef]
- Lecun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with deep Convolutional Neural Networks, Proceedings of the 25th International Conference on Neural Information Processing Systems, Siem Reap, Cambodia, 13–16 December 2018—Volume 1; Curran Associates Inc.: Lake Tahoe, NV, USA, 2012; pp. 1097–1105. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Prasasti, A.L.; Mengko, R.K.W.; Adiprawita, W. Vein Tracking Using 880nm Near Infrared and CMOS Sensor with Maximum Curvature Points Segmentation, Proceedings of the 7th Wacbe World Congress on Bioengineering 2015, Singapore, 6–8 July 2015; Goh, J., Lim, C.T., Eds.; Springer: New York, NY, USA, 2015; Volume 52, pp. 206–209. [Google Scholar]
- Chen, Y.-J.; Fan, C.-Y.; Chang, K.-H. Manufacturing intelligence for reducing false alarm of defect classification by integrating similarity matching approach in CMOS image sensor manufacturing. Comput. Indust. Eng. 2016, 99, 465–473. [Google Scholar] [CrossRef]
- Qawaqneh, Z.; Abu Mallouh, A.; Barkana, B.D. Deep Convolutional Neural Network for Age Estimation based on VGG-Face Model. arXiv 2017, arXiv:1709.01664. [Google Scholar]
- Donahue, J.; Jia, Y.; Vinyals, O.; Hoffman, J.; Zhang, N.; Tzeng, E.; Darrell, T. DeCAF: A Deep Convolutional Activation Feature for Generic Visual Recognition. arXiv 2013, arXiv:1310.1531. [Google Scholar]
- Feng, L.; Po, L.-M.; Li, Y.; Xu, X.; Yuan, F.; Cheung, T.C.-H.; Cheung, K.-W. Integration of image quality and motion cues for face anti-spoofing: A neural network approach. J. Vis. Commun. Image Represent. 2016, 38, 451–460. [Google Scholar] [CrossRef]
- Xu, B.; Wang, N.; Chen, T.; Li, M. Empirical Evaluation of Rectified Activations in Convolutional Network. arXiv 2015, arXiv:1505.00853. [Google Scholar]
- Liu, W.; Wen, Y.; Yu, Z.; Yang, M. Large-Margin Softmax Loss for Convolutional Neural Networks. arXiv 2016, arXiv:1612.02295. [Google Scholar]
- Wilson, A.C.; Roelofs, R.; Stern, M.; Srebro, N.; Recht, B. The Marginal Value of Adaptive Gradient Methods in Machine Learning; NIPS: San Diego, CA, USA, 2017; pp. 4148–4158. [Google Scholar]
- Sermanet, P.; Eigen, D.; Zhang, X.; Mathieu, M.; Fergus, R.; LeCun, Y. OverFeat: Integrated Recognition, Localization and Detection using Convolutional Networks; Cornell University: Ithaca, NY, USA, 2013. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. arXiv 2015, arXiv:1512.03385. [Google Scholar]
- Huang, G.; Liu, Z.; van der Maaten, L.; Weinberger, K.Q. Densely Connected Convolutional Networks; Cornell University: Ithaca, NY, USA, 2016. [Google Scholar]
- Howard, A.; Sandler, M.; Chu, G.; Chen, L.-C.; Chen, B.; Tan, M.; Wang, W.; Zhu, Y.; Pang, R.; Vasudevan, V.; et al. Searching for MobileNetV3. arXiv 2019, arXiv:1905.02244. [Google Scholar]
- Zeiler, M.D.; Fergus, R. Visualizing and Understanding Convolutional Networks; Springer International Publishing: Cham, Switzerland, 2014; pp. 818–833. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Input (150*150 Grey Image) (New) |
|---|
| VGG-16 conv_base |
| FC-256 (new) |
| FC-N (new) |
| soft-max |
| Model | AlexNet | VGG- 16 | Resnet-50 | Densenet-121 | MobileNetV3-Large | Pre-AlexNet | Pre-VGG-16 | Pre-Resnet-50 | Pre- Densenet-121 |
|---|---|---|---|---|---|---|---|---|---|
| 3 Classes (val, test) Accuracy (%) | 70.25 72.1 | 76.46 74.64 | 71.69 89.1 | 74.84 81.80 | 71.69 71.86 | 62.0 60.1 | 74.54 77.02 | 74.50 81.58 | 71.75 81.80 |
| Q-D (val, test) Accuracy (%) | 90.04 86.72 | 99.75 99.3 | 99.89 99.87 | 99.89 98.52 | 99.34 99.14 | 99.0 98.40 | 99.89 99.87 | 99.89 99.87 | 99.89 99.87 |
| Qualified (precision, recall) | 0.99 0.50 | 0.98 0.96 | 0.98 0.96 | 0.99 0.93 | 0.98 0.96 | 0.98 0.97 | 0.99 0.99 | 0.99 0.99 | 0.99 0.99 |
| Fault Positive Rate (%) | 0.67 | 0.83 | 0.16 | 0.16 | 0.16 | 0.67 | 0.16 | 0.16 | 0.16 |
| (Q-D) Model_size | 460M | 1.6G | 2G | 5G | 70M | -- | 16M | 30M | 33M |
| (Q-D) Training Time | 30h | 3h (GPU) | 4h (GPU) | 7h (GPU) | 1.6h (GPU) | -- | 1h | 17 min (GPU); | 30 min (GPU) |
| (Q-D) Predict Time (ms) | 148 | 172 | 1230 | 2860 | 134 | -- | 40 | 240 | 684 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, Y.; Pan, L.; Ma, J.; Yang, R.; Zhu, Y.; Yang, Y.; Zhang, L. A High-Performance Deep Learning Algorithm for the Automated Optical Inspection of Laser Welding. Appl. Sci. 2020, 10, 933. https://doi.org/10.3390/app10030933
Yang Y, Pan L, Ma J, Yang R, Zhu Y, Yang Y, Zhang L. A High-Performance Deep Learning Algorithm for the Automated Optical Inspection of Laser Welding. Applied Sciences. 2020; 10(3):933. https://doi.org/10.3390/app10030933
Chicago/Turabian StyleYang, Yatao, Longhui Pan, Junxian Ma, Runze Yang, Yishuang Zhu, Yanzhao Yang, and Li Zhang. 2020. "A High-Performance Deep Learning Algorithm for the Automated Optical Inspection of Laser Welding" Applied Sciences 10, no. 3: 933. https://doi.org/10.3390/app10030933
APA StyleYang, Y., Pan, L., Ma, J., Yang, R., Zhu, Y., Yang, Y., & Zhang, L. (2020). A High-Performance Deep Learning Algorithm for the Automated Optical Inspection of Laser Welding. Applied Sciences, 10(3), 933. https://doi.org/10.3390/app10030933