DE-CapsNet: A Diverse Enhanced Capsule Network with Disperse Dynamic Routing


Abstract
:1. Introduction
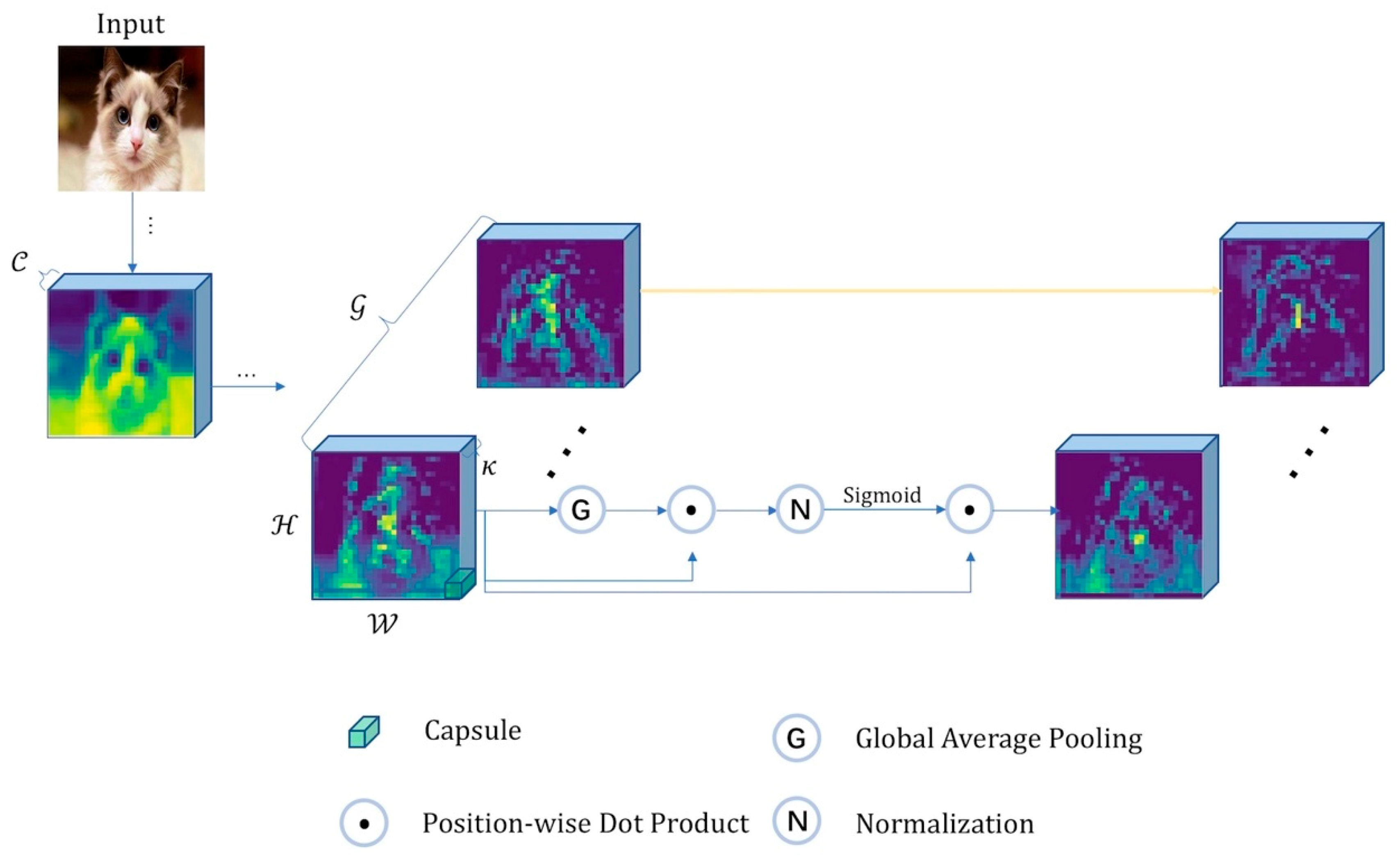
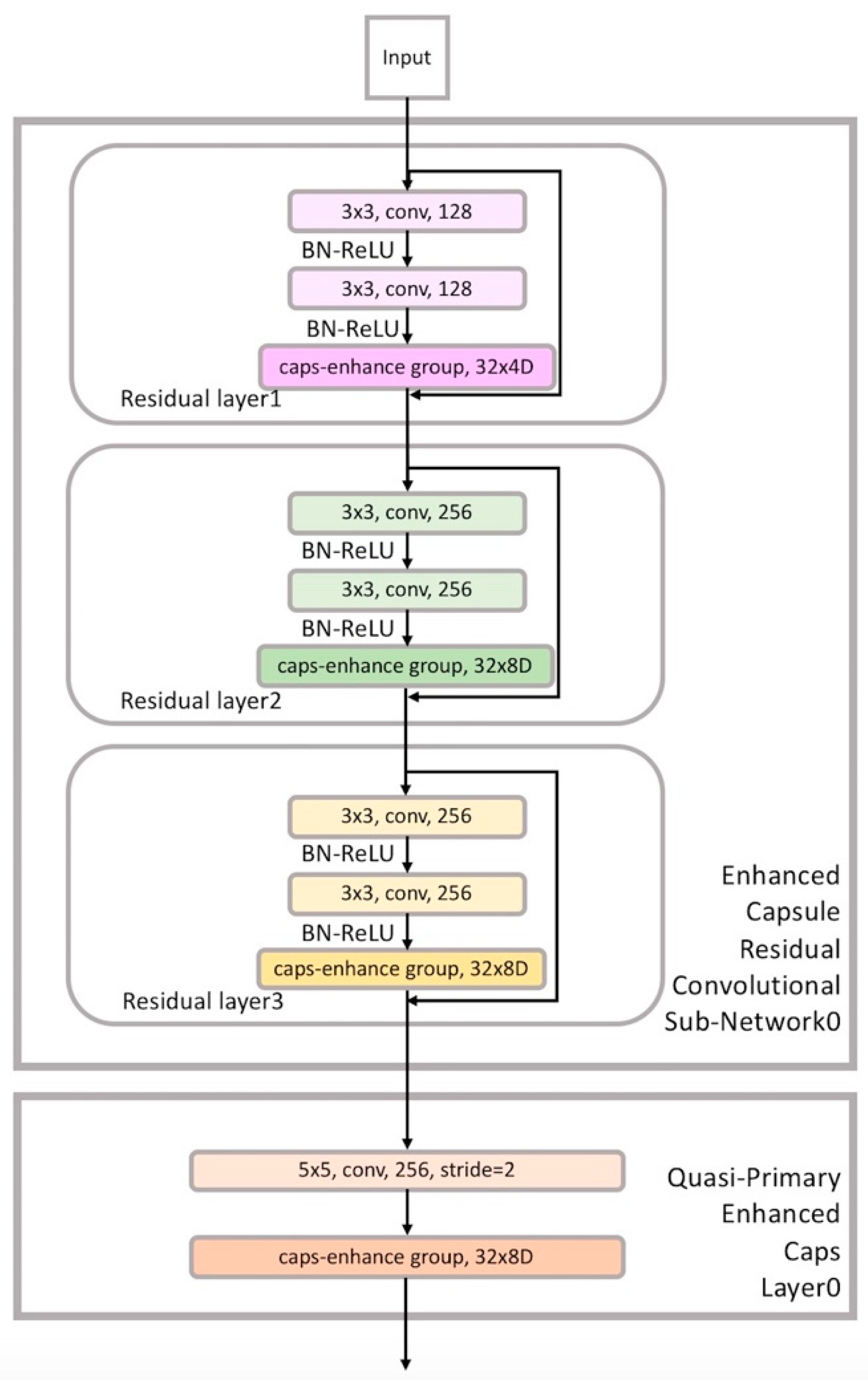
- Drawing from Diverse Capsule Network (DCNet++) [8], we propose a novel architecture called Diverse Enhanced Capsule Network (DE-CapsNet). Multiple-layer residual blocks, instead of one convolutional layer, are used in a residual convolutional subnetwork to extract features from complicated data such as CIFAR-10. The features are input into different levels of primary capsules. DE-CapsNet utilizes a two-level primary capsules hierarchical model to represent different scales of images. Furthermore, the output from the primary capsule is assigned to digit capsules (DigitCaps) by a routing algorithm, and DE-CapsNet fuses the features of the two-level primary capsules together to identify the instantiation. Besides this, the Spatial Group-wise Enhance (SGE) [9] mechanism is introduced into our architecture as the enhancement method for the original capsule-based method. The enhancement is both between the neighboring residual blocks and inside the quasi-primary capsule layers, for the sake of helping the network to build dedicated capsules to improve the representation power of capsules. These dedicated capsules are focused on the true features and restrain susceptibility to the background information. It can tell the network which object or part of an object is truly important to learn.
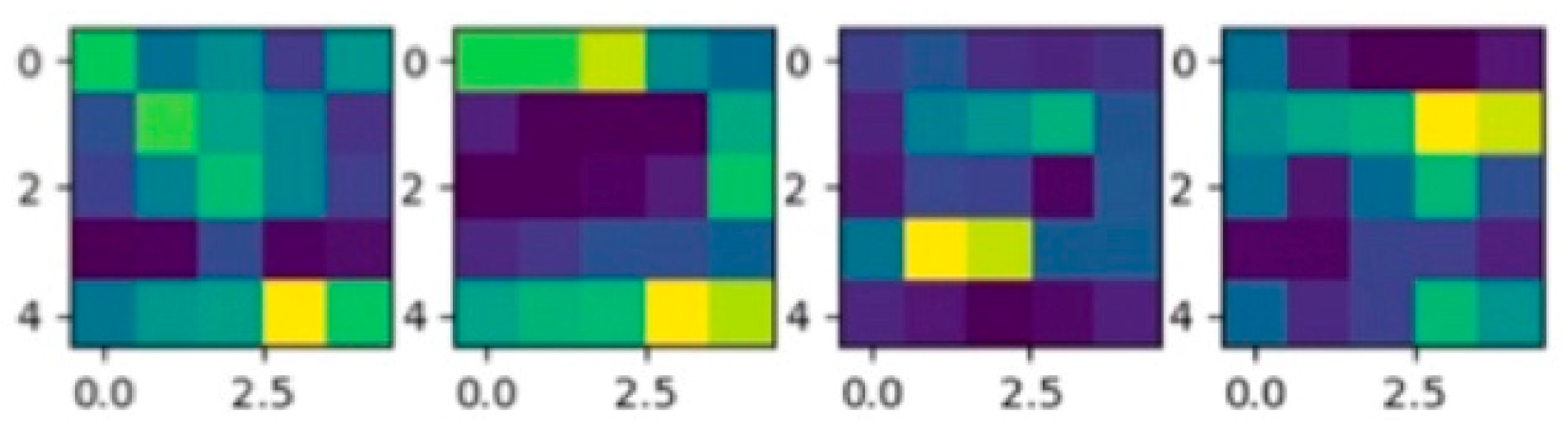
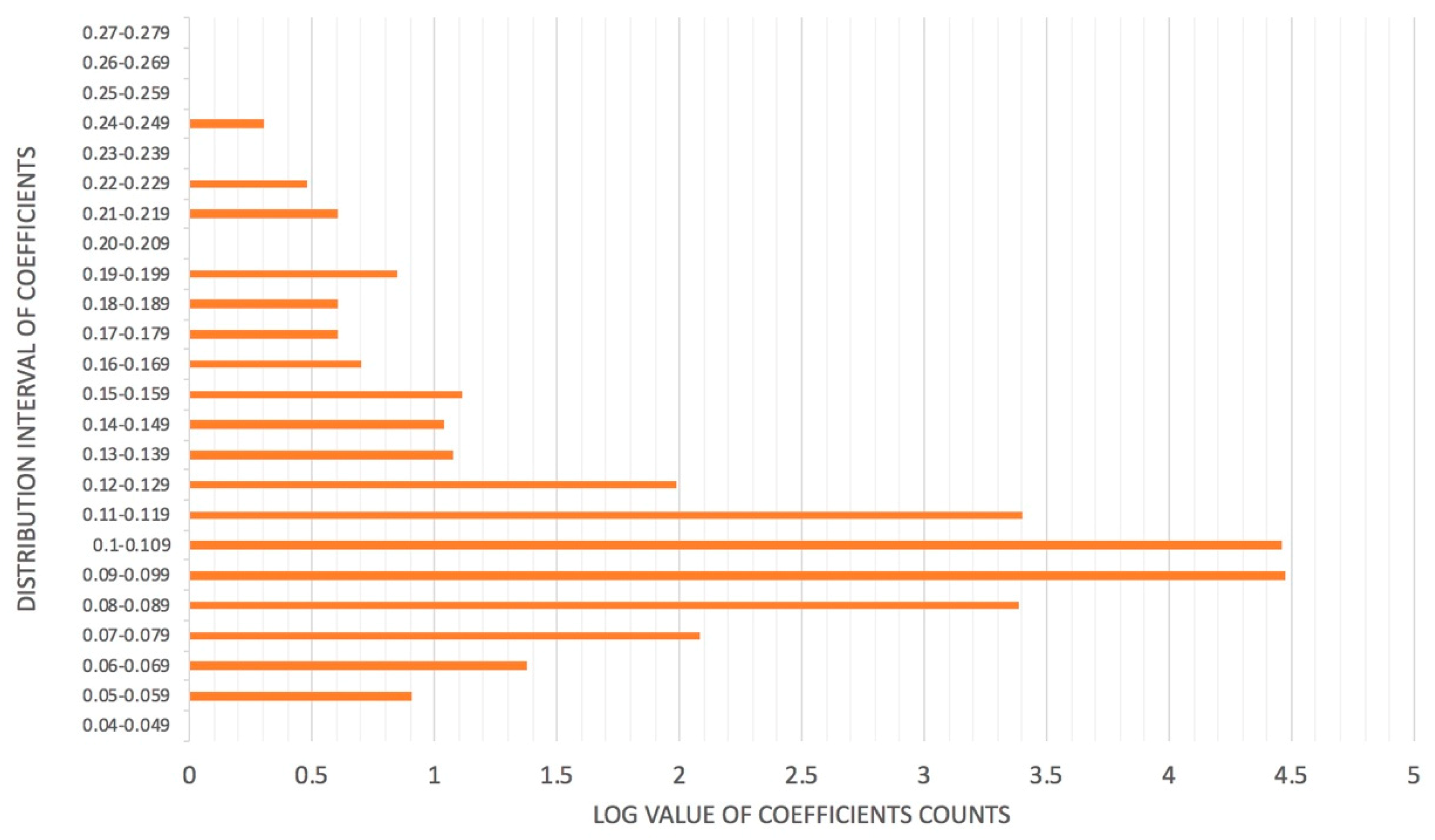
- Disperse dynamic routing is proposed that improves the performance of the dynamic routing algorithm. We found that the coupling coefficients using the Softmax function were mainly distributed around the interregion from 0.09 to 0.109, which is not as well distributed as can be obtained using the Sigmoid function. The Sigmoid function can assign larger coupling coefficients to real features, which transfer the true features actually related to the class to the next capsule layers, while assigning relatively smaller coupling coefficients to the fallacious ones. The true ones can be decisive in preventing the predicted sums of false classes from getting larger values.
- Dynamic agreement routing is time-consuming due to the relatively higher complexity of its constituting elements. Our architecture is designed as two-level primary capsule layers with smaller kernel size in each primary capsule layer in order to reduce the training time compared with the seven ensembles of CapsNets.
2. Related Work
3. Diverse Enhanced Capsule Network
3.1. Enhanced Capsules
3.2. Disperse Dynamic Routing
| Algorithm 1. Softmax Routing Procedure |
| 1: Input to Routing Procedure: () |
| 2: for capsule in layer and capsule in layer (): |
| 3: for iterations: 4: for capsule in layer |
| 5: for capsule in layer (): |
| 6: for capsule in layer (): |
| 7: for capsule in layer and capsule in layer (): 8: Return |
| Algorithm 2. Sigmoid Routing Procedure |
| 1: Input to Routing Procedure: () |
| 2: for all capsule in layer and capsule in layer (): |
| 3: for iterations: |
| 4: for all capsule in layer |
| 5: for all capsule in layer (): |
| 6: for all capsule in layer (): |
| 7: for all capsule in layer and capsule in layer (): |
| 8: Return |
3.3. DE-CapsNet Architecture
4. Experiments
4.1. Datasets
4.2. System Setup
4.3. Results
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going Deeper with Convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, CVPR, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, CVPR, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Huang, G.; Liu, Z.; van der Maaten, L.; Weinberger, K.Q. Densely Connected Convolutional Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, CVPR, Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Sabour, S.; Frosst, N.; Hinton, G.E. Dynamic Routing Between Capsules. In Advances in Neural Information Processing Systems 30. In Proceedings of the Annual Conference on Neural Information Processing Systems, NIPS, Long Beach, CA, USA, 4–9 December 2017; pp. 3856–3866. [Google Scholar]
- Hinton, G.E.; Krizhevsky, A.; Wang, S.D. Transforming Auto-Encoders. In Artificial Neural Networks and Machine Learning—ICANN 2011; Honkela, T., Duch, W., Girolami, M., Kaski, S., Eds.; Springer: Berlin/Heidelberg, Germany, 2011; Volume 6791, pp. 44–51. ISBN 978-3-642-21734-0. [Google Scholar]
- Xi, E.; Bing, S.; Jin, Y. Capsule Network Performance on Complex Data. arXiv 2017, arXiv:1712.03480. [Google Scholar]
- Yang, Z.; Wang, X. Reducing the dilution: An analysis of the information sensitiveness of capsule network with a practical solution. arXiv 2019, arXiv:1903.10588. [Google Scholar]
- Phaye, S.S.R.; Sikka, A.; Dhall, A.; Bathula, D. Dense and Diverse Capsule Networks: Making the Capsules Learn Better. arXiv 2018, arXiv:1805.04001. [Google Scholar]
- Li, X.; Hu, X.; Yang, J. Spatial Group-wise Enhance: Improving Semantic Feature Learning in Convolutional Networks. arXiv 2019, arXiv:1905.09646. [Google Scholar]
- Srivastava, R.K.; Greff, K.; Schmidhuber, J. Training Very Deep Networks. In Advances in Neural Information Processing Systems 28. In Proceedings of the Annual Conference on Neural Information Processing Systems, NIPS 2015, Montreal, QC, Canada, 7–12 December 2015; pp. 2377–2385. [Google Scholar]
- Hinton, G.; Sabour, S.; Frosst, N. Matrix Capsules With EM Routing. In Proceedings of the 6th International Conference on Learning Representations, ICLR, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Deliège, A.; Cioppa, A.; Van Droogenbroeck, M. HitNet: A neural network with capsules embedded in a Hit-or-Miss layer, extended with hybrid data augmentation and ghost capsules. arXiv 2018, arXiv:1806.06519. [Google Scholar]
- Zhao, Z.; Kleinhans, A.; Sandhu, G.; Patel, I.; Unnikrishnan, K.P. Capsule Networks with Max-Min Normalization. arXiv 2019, arXiv:1903.09662. [Google Scholar]
- Wang, D.; Liu, Q. An Optimization View on Dynamic Routing Between Capsules. In Proceedings of the 6th International Conference on Learning Representations, ICLR, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- do Rosario, V.M.; Borin, E.; Breternitz, M., Jr. The Multi-Lane Capsule Network (MLCN). IEEE Signal Process. Lett. 2019, 26, 1006–1010. [Google Scholar] [CrossRef]
- Cheng, X.; He, J.; He, J.; Xu, H. Cv-CapsNet: Complex-Valued Capsule Network. IEEE Access 2019, 7, 85492–85499. [Google Scholar] [CrossRef]
- Rajasegaran, J.; Jayasundara, V.; Jayasekara, S.; Jayasekara, H.; Seneviratne, S.; Rodrigo, R. DeepCaps: Going Deeper with Capsule Networks. In Proceedings of the 2019 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2019, Long Beach, CA, USA, 15–20 June 2019; pp. 10725–10733. [Google Scholar]
- Kınlı, F.; Özcan, B.; Kıraç, F. Fashion Image Retrieval with Capsule Networks. In Proceedings of the 2019 IEEE International Conference on Computer Vision Workshops, ICCV Workshops, Seoul, Korea, 29 October–1 November 2019. [Google Scholar]
- Afshar, P.; Mohammadi, A.; Plataniotis, K.N. Brain Tumor Type Classification via Capsule Networks. In Proceedings of the 25th IEEE International Conference on Image Processing, ICIP, Athens, Greece, 7–10 October 2018; pp. 3129–3133. [Google Scholar]
- Hu, J.; Shen, L.; Albanie, S.; Sun, G.; Wu, E. Squeeze-and-Excitation Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, CVPR, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7132–7141. [Google Scholar]
- Wang, X.; Girshick, R.; Gupta, A.; He, K. Non-local Neural Networks. In Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition, CVPR, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7794–7803. [Google Scholar]
- Cao, Y.; Xu, J.; Lin, S.; Wei, F.; Hu, H. GCNet: Non-local Networks Meet Squeeze-Excitation Networks and Beyond. arXiv 2019, arXiv:1904.11492. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.-Y.; Kweon, I.S. CBAM: Convolutional Block Attention Module. In Proceedings of the 15th European Conference on Computer Vision, ECCV, Part VII, Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift. In Proceedings of the 32nd International Coference on Machine learning, ICML, Ithaca, NY, USA, 6–11 July 2015; pp. 448–456. [Google Scholar]
- Qiao, S.; Wang, H.; Liu, C.; Shen, W.; Yuille, A. Weight Standardization. arXiv 2019, arXiv:1903.10520. [Google Scholar]
- Wu, Y.; He, K. Group Normalization. In Proceedings of the 15th European Conference on Computer Vision, ECCV, Part XIII, Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | CIFAR-10 | F-MNIST |
|---|---|---|
| Sabour et al. [4] | 89.40% | 93.60% |
| HitNet [12] | 73.30% | 92.30% |
| Zhao et al. [13] | 75.92% | 92.07% |
| DeepCaps [17] | 91.01% | 94.46% |
| DeepCaps (7 ensembles) [17] | 92.74% | 94.73% |
| DE-CapsNet (ND) | 92.33% | 93.64% |
| DE-CapsNet | 92.96% | 94.25% |
| Layer Name | Subwork-0 | Subwork-1 | Subwork-2 |
|---|---|---|---|
| Conv1 | 3 × 3, 128, stride = 1 | 1 × 1, 256, stride = 1 | 1 × 1, 64, stride = 1 |
| Conv2_x | |||
| Caps-enhance | Groups = 32 Capsule dimension = 4 | Groups = 32 Capsule dimension = 8 | Groups = 8 Capsule dimension = 8 |
| Conv3_x | |||
| Caps-enhance | Groups = 32 Capsule dimension = 8 | Groups = 32 Capsule dimension = 8 | Groups = 8 Capsule dimension = 8 |
| Conv4_x | |||
| Caps-enhance | Groups = 32 Capsule dimension = 8 | Groups = 32 Capsule dimension = 8 | Groups = 8 Capsule dimension = 8 |
| Quasi-conv | 5 × 5, 256, stride = 2 | 5 × 5, 256, stride = 2 | 3 × 3, 64, stride=1 |
| Quasi-primarycaps-enhance | Groups = 32 Capsule dimension = 8 | Groups = 32 Capsule dimension = 8 | Groups = 8 Capsule dimension = 8 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jia, B.; Huang, Q. DE-CapsNet: A Diverse Enhanced Capsule Network with Disperse Dynamic Routing. Appl. Sci. 2020, 10, 884. https://doi.org/10.3390/app10030884
Jia B, Huang Q. DE-CapsNet: A Diverse Enhanced Capsule Network with Disperse Dynamic Routing. Applied Sciences. 2020; 10(3):884. https://doi.org/10.3390/app10030884
Chicago/Turabian StyleJia, Bohan, and Qiyu Huang. 2020. "DE-CapsNet: A Diverse Enhanced Capsule Network with Disperse Dynamic Routing" Applied Sciences 10, no. 3: 884. https://doi.org/10.3390/app10030884
APA StyleJia, B., & Huang, Q. (2020). DE-CapsNet: A Diverse Enhanced Capsule Network with Disperse Dynamic Routing. Applied Sciences, 10(3), 884. https://doi.org/10.3390/app10030884