1. Introduction
Over the past few decades, the number and the variety of industrial products has grown, as well as the complexity of machinery in industrial plants. Furthermore, Industry 4.0—that is the trend towards the computerization of manufacturing—is leading to an exchange of a great quantity of technical information among machines, storage systems, production facilities, and people [
1]. A category of information associated with a product or a machine is that of technical documentation, including use and maintenance manuals, operating instructions, and installation manuals [
2]. This documentation is composed of technical information assets that may describe a component, provide instructions for a task, data, and so on.
Most of the technical information assets are increasingly available in various digital formats. They are usually conveyed through visual cues: video, text, image, CAD models, and so on. Consequently, also the devices used to convey technical documentation are evolving from the traditional ones as paper manuals and monitors, to handheld devices and holographic displays. A key technology that is going to be used for displaying these next-generation manuals is augmented reality (AR).
Operators can be different one from the other. They can have different levels of expertise and experience. As to experience level, we can distinguish from novice to expert operators according to the knowledge acquired performing technical procedures. However, a same operator could have a greater expertise on a particular machine/product than on others. Experience can regard different skills as assembling skills, using the tools, problem solving, and so on. Thus, some operators may want to read the explanation of each step, while others may understand everything by just looking at an image of the procedure. Operators could have also different needs when consulting a technical manual given a certain task, someone may want to check a single step, others may have to follow the entire guide step-by-step. Younger people are digital natives [
3,
4] and thus more oriented towards innovative displays, whereas older people would be more attached to traditional media. Finally, people speak different languages and come from different cultures [
5], then also technical documentation is affected by these differences. The domain of technical documentation covers several application environments. This might allow the use of some specific user interfaces for conveying information while making impossible or dangerous to use some others. For example, some application environments may not require great attention to the real world, while others may be critical or dangerous tasks, allowing attention loss on reality for just a few seconds [
6].
As a result, the increasing number of technical documentations to produce, the variety of ways to convey information, the differences among people, and the variable environmental conditions, make sure that the authoring and the management of technical documentation becomes an issue. Many works on adaptive AR interfaces propose algorithms to determine optimal text styles (e.g., text color and drawing style, position of labeling), based on the background of the environment [
7,
8,
9]. However, these works do not consider dynamically altering the information content or other contextual elements.
The management of large informative systems is a problem which has been broadly investigated in many fields, for example in information retrieval by research engines. Advanced context-aware information retrieval systems have shown excellent results in the e-learning and e-training contexts [
10,
11]. However, to our best knowledge, the results from these studies often ignore the ‘people’ factor. The user must manually search for the information they are looking for, using some research keys. This requires previous knowledge in the domain that they may not have. Moreover, of similar approaches found in the literature [
12,
13,
14,
15,
16], most do not specifically consider a large set of context features. Therefore, a contribution of this work includes a technical information manager for AR user interfaces capable of adapting to a number of contextual dimensions and therefore usable in a wide array of operating conditions.
This work draws motivation from our previous work in industrial AR-based maintenance. By developing practical industrial case studies, we faced issues in managing the presentation of technical information. Therefore, in this work, we implemented a system called CATIM (Context-Aware Technical Information Manager) that acquires data about the context (operator, activity, environment), and, based on these data, proposes documentation tailored to the current operating context. We made also a first evaluation of CATIM in a real industrial case study.
In
Section 2, we present related work. In
Section 3, we describe our approach. In
Section 4, we explain the architecture and the implementation of CATIM. In
Section 5, we report the application of CATIM to the case study. In
Section 6, we present the results of this application and their discussion. In the final section, we provide conclusions and future work.
2. Related Work
In literature, there are many works that quantify the effectiveness of AR for visually presenting technical information and manuals as measured by reduced time and operator error in the fulfillment of procedural task (e.g., [
17,
18,
19]).
Beyond simply presenting technical information via fixed AR user interface designs, other researchers have looked to increase the utility of AR interfaces by incorporating context-aware features into AR applications. The context can condition the choice of the information content, the style of this content, or both.
For example, Oh et al. [
12] combined context awareness and mobile augmented reality, proposing CAMAR (Context-Aware Mobile Augmented Reality). CAMAR customizes the content to be preferable to a user according to his/her profile, and to share augmented objects with other mobile users selectively in a customized way.
Grubert et al. [
14] present a state-of-the-art context-aware AR system that considers the effect of context both on the content and the presentation style. They introduced the concept of pervasive augmented reality as a continuous, context-aware augmented reality experience. A goal of this work was to build an AR interface that is actually context-controlled, moving away from the single purpose AR application towards a multipurpose pervasive AR experience. However, their approach is limited to: (i) presenting the concept of pervasive AR; (ii) developing a taxonomy for it; (iii) providing a comprehensive overview of existing AR systems towards their vision of pervasive AR; and; (iv) identifying opportunities for future research. Our work can further this pervasive AR vision by providing a context-aware AR system that adapts well in many possible situations that an operator may encounter in industrial applications.
Ruta et al. [
20] present a software system to assist in the discovery of points of interest for tourists in AR and their description in a way that can match users’ interests. Even if the scope of this work is different from ours, the approach is similar in spirit: the automatic choice of the information to display and a customized way of displaying it, both based on the current usage context.
Hervás et al. [
15] define mechanisms for the management of contextual information, reasoning techniques, and adaptable user interfaces to support augmented reality services that provide functionality to make decisions about what available information should be offered and how. The variables taken into account by their system are too abstract in terms of possible applications and user profiling. Furthermore, they do not cover maintenance/assembly tasks.
The previous works discussed thus far are not focused on the application of context-aware interfaces to industrial AR. Akbarinasaji and Homayounvala [
21], present an optimized context-aware AR-based framework to assist technicians conducting maintenance tasks. The proposed framework makes use of collected raw context data and performs reasoning on them to obtain new inferred data and to provide adaptive behavior using an ontology.
Flatt et al. [
22] present a system to display information in AR in an industrial context. Their approach implements a general-purpose application capable of applying textual ‘sticky notes’ to real objects, describing them with a semantic notation to be retrieved later. This work is more oriented to dynamic authoring and annotation rather than dynamic management of user interface information and presentation styles.
In many related previous works, there is a lack of focus on the field of maintenance and even in these cases just a few user interface assets are used (e.g., text, signs, and symbols). Thus, we applied the lessons learned in these previous studies about the use of AR in an industrial domain, to propose an appropriate behavior of CATIM. We considered the most relevant factors influencing the design of an AR interface in an industrial domain, as well as a wider range of technical information assets with a specific semantic description on when to use them.
Zhu et al. [
16] present an authorable context-aware AR system (ACARS) using a specialized context description. They describe the maintenance procedure, the tools and the devices involved, as well as more synthetic information about users and the working environment. The context-aware system developed captures some parameters to select a set of information and a level of detail at which the information should be rendered. Although the system seems very interesting for our goals, their target is on-site authoring capability to assist maintenance technicians.
3. Materials and Methods
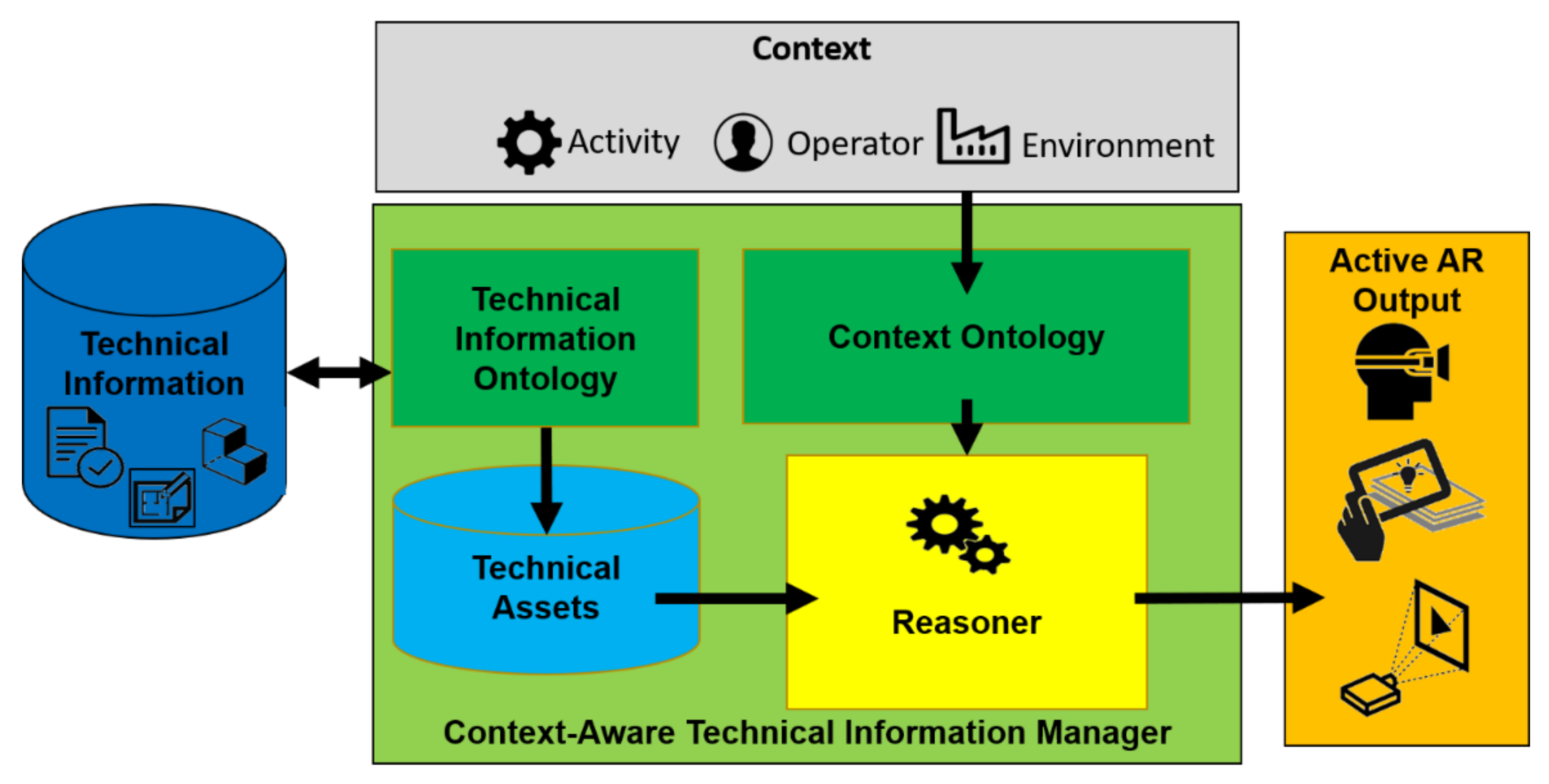
Our approach, whose functional scheme is depicted in
Figure 1, aims to present the operator with the ‘best’ technical assets available for the context. A technical asset is an atomic piece of technical information conveyed in a specific modality. Technical assets are usually visual cues such as CAD models, video, text, images, icons, graphs, and so on. The technical assets can be static but also associated to dynamic and time-dependent information. It is worth noting that, in our definition, the same technical information can be mapped to different assets sharing the same content but with different media and interface presentation style (e.g., short text, long text, animated text, video, audio). Thus, the choice of the optimal technical asset for the same technical information is paramount.
For CATIM, we assume that the context in which to perform a task can be known. For example, the system could infer the activity to be performed by automatically using state sensing, IoT or by user selection. CATIM could know the operator technical, physical and cognitive skills, as well as interface preferences by, for example, user profiling and wearable sensors. User profiling is currently carried out through a preliminary questionnaire provided to the operator. Lastly, the system could sense the environment using sensor suites and computer vision to identify available tools, lighting condition, available AR devices, and so forth.
Using our proposed approach, upon operator initiation of a task procedure, CATIM browses the technical information database to find the technical assets which best match the context and presents them to the operator via an AR user interface. The information search is based on the context description rather than having the user selecting the information needed. The information associated with each step of the procedure can be conveyed alternatively using different technical assets (e.g., text, icon, video, audio). Each asset (as used in each step of a procedure) can be linked to a particular state of the activity, of a process, of a product. Therefore, a procedure can be presented at runtime to the operator as a sequence of best context matching technical assets. Consequently, the presentation can be dynamically adapted to an operator’s learning curve, as the operator can be continuously profiled by the acquired data (e.g., number of presentations of the same asset and task time for a repetitive procedure).
In the following sub-sections, we provide further details on each component of CATIM.
3.1. Technical Information
Most of the technical information associated with a product or machine is stored in the form of technical documentation (i.e., manuals, technical drawings, specifications, standards, common practices). This technical documentation is increasingly composed of assets available in various digital formats. In these cases, CATIM can help identify specific assets (from a large set of possible assets) that are well-suited for the specific context and provide an alternative form if needed.
3.2. Context
Context may include any information that is relevant to CATIM to provide user with the best technical assets. Among all the dimensions generally used to define and describe the context, we consider only the following three to be representative of typical industrial AR settings.
3.2.1. Activity
The activity (i.e., a specific routine of definite steps to be performed on an equipment, as defined in [
21]) is crucial for identifying the right technical information to present. The activity can be tracked in the simplest way by user selection (e.g., using a menu, by voice commands) or tracking automatically the state of the product, of a process or procedure (e.g., using object tracking, IoT sensors, and more generally any data available in Industry 4.0 cyber-physical systems). The tracked activity completion (or object state) can trigger the presentation of information related to the next activity. Thus, the activity can have a strong influence in the choice of the technical assets and even of the preferred AR device among those available.
3.2.2. Operator
Users of AR technical documentation can be very different. Demographic, genre, and anthropometric data may affect an operator’s physical and cognitive performance. For example, the range of movement of operations, and tooling may be adapted to improve operator ergonomics. In addition, users can have different levels of expertise and experience that can vary for different machines/products. Thus, some operators need to be instructed step-by-step in offline training sessions, while others may need just an overview at working time. Younger operators as digital natives may easily accept complex, 3D multimedia contents, whereas older people may prefer traditional media. Operators may come from different cultures and nationality; therefore, the technical documentation may adapt to their culture and language (e.g., language spoken, color coding). Finally, also operator personal media presentation preferences should be considered for inclusive purposes (e.g., color blindness, disabilities, impaired hearing).
3.2.3. Environment
Industrial environments are generally complex and risky due to the presence of static and moveable products, components, machinery, consumables, and tools. They may present very different conditions in terms of location (indoors and outdoors), network or system constraints, illumination, temperature, dirt, smoke, noises, dust, etc. Most industrial environments are characterized by the presence of hazards that may compromise the safety of the workers. Industrial environments, therefore, must follow mandatory safety regulations and procedures and operators must wear personal security devices (e.g., helmets and gloves). Industrial conditions and safety devices may reduce users sensing and perceptual capabilities like hearing, vision, touch, etc. To assist operators in these dynamic settings, active AR user interfaces should cope with the environment and complementary safety devices worn by operators during duty time. AR devices’ availability and capabilities (e.g., contrast ratio, luminance, color gamut) must further fit the environmental context. Thus, the context-aware AR application interface and interaction must be designed according to the environment in order to assist operators physical and cognitive capabilities (e.g., operators’ visual attention) and to avoid risks. Industrial environments may also limit situated visualization capabilities (e.g., uneven light conditions, dirt, moving machinery, etc.). Products, components, machinery, consumables, and tools, (e.g., screwdrivers, wrenches, etc.) often belong to an environment and may be available or not to the operator. Industrial objects can be easily tracked nowadays with IoT technology and full environment data will likely be available in the near future.
It is important to note that the dimensions presented herein are exemplary of industrial AR setting but could be extended to include other dimensions such as social contexts (e.g., impacts of other team workers), transient physiology in users (e.g., fatigue, sensitivity, mental workload), and so forth. Furthermore, CATIM can support additional dimensions altogether that in turn could support context-aware AR interfaces in other application domains.
3.3. Context-Aware Technical Information Manager
Technical information is mapped onto a database of technical assets using an ontology for technical information. The context is then dynamically mapped onto a context vector also using a context ontology to describe the application domain. This vector contains data about the activity, the operator, and the environment. It can also contain other elements as tools and key performance indicators that can influence the choice of technical assets. A reasoner, using recommender system technology, selects the best technical assets according to the context vector and presents them dynamically using an active AR interface to the user.
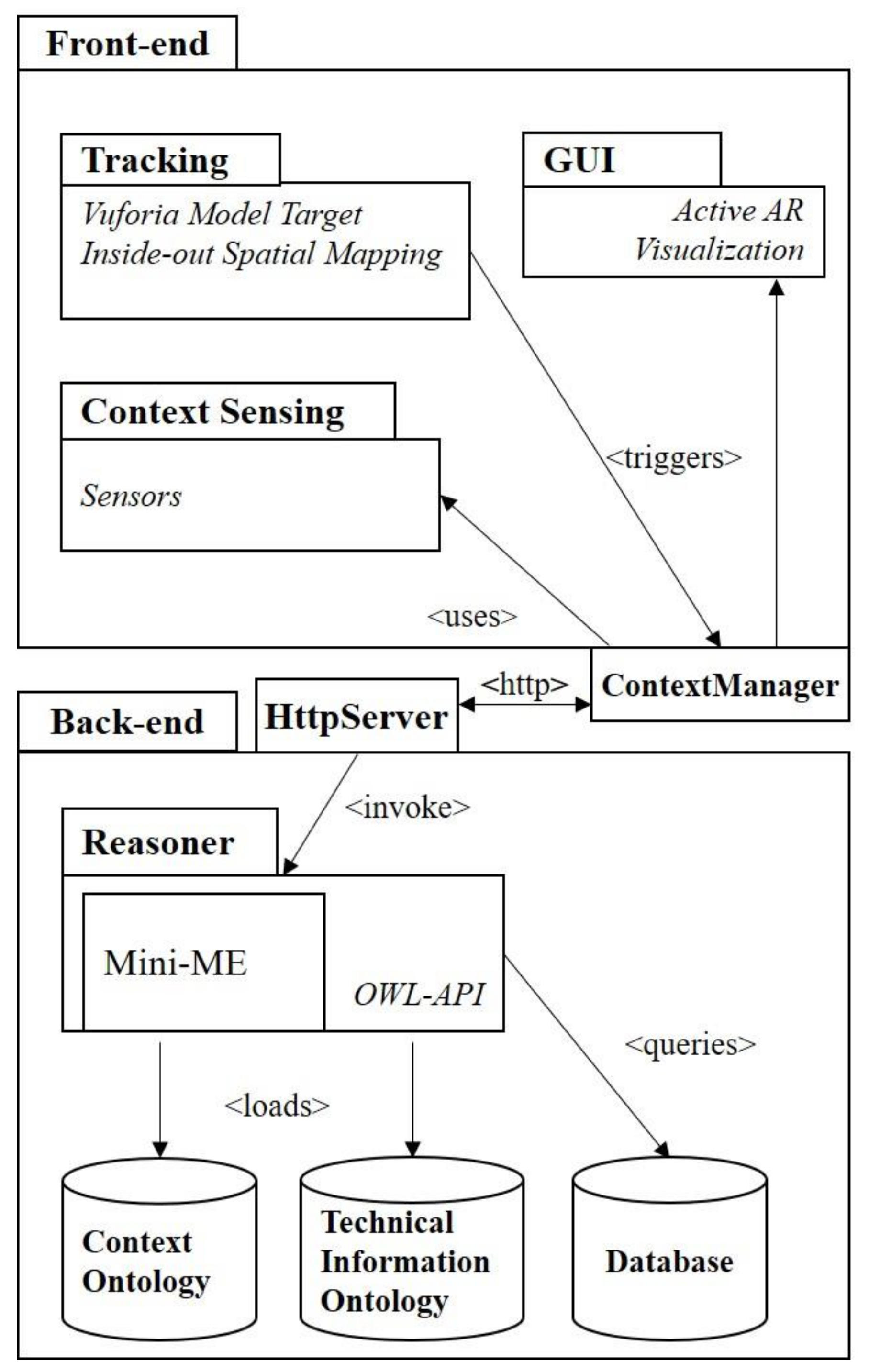
Our system implementation uses a Java http back-end and a front-end mobile application implemented with Unity 3D to manage the active AR output on the AR device (see
Figure 2).
The Java http back-end receives context information and reasons using the ontology on the currently loaded domain. Both the technical information ontology and the context ontology are handled by Protégé, a broadly used software for the assisted generation/customization of OWL ontologies [
23]. The reasoner uses two non-standard reasoning algorithms. For the technical information recommendation (i.e., what information to present), a concept contraction/abduction reasoning algorithm is used. For the technical asset type selection (i.e., how to present the information), we use the concept covering algorithm implemented in Mini-ME [
24], which tries to compute the best consistent coverage for the current context. The various asset type descriptions are associated to ‘rules’, predefined by the application designer, to try to cover (without contradictions) all the concepts that describe the current context. The concept covering rules are used by the reasoner to compute the distance between the assets and the context vector. The back-end replies to front-end requests with a list of compatible technical assets, ordered according the concept covering distance. This ranking suggests the technical assets more appropriate to the current context. There could be some context scenarios where CATIM is not able to display instructions. This is mainly due to safety issues. For example, if the operator must have free hands for safety reasons and only smartphone is available as device, CATIM will not provide instructions suggesting using other displaying output (e.g., a monitor or a paper-based support). In this way, CATIM is also able to prevent specific risks in industrial environments.
3.4. Active AR Output
The active AR output application, running on the AR device as front-end, acquires information sent by the back-end and presents the technical assets organizing them according to context information (context-dependent layout). User selection on the AR interface triggers a request to the backend for the analysis of the current context. Then, the frontend application, on the AR device, receives the ordered set of compatible technical assets. The active AR application shows just the first asset (i.e., the one with the shortest distance) is selected for visualization, but the user, through a button in the GUI or with voice command, can show the other assets in the set.
The registration of virtual AR objects on the real world is made possible using the Vuforia Model Target Feature, which recognizes and tracks a physical object using a digital 3D model of the object. We developed this application both for Android mobile devices and for the Microsoft HoloLens. For HoloLens, we also used its inside-out spatial mapping for the positioning of the GUI in a fixed region of the surrounding space. We implemented a basic interface whose purpose is just to test the right behavior of CATIM. User selection is made by tapping on a virtual element (handheld device) or by using an air-tap (i.e., one of the standard gestures recognized by HoloLens).
4. Deployment of CATIM in an Industrial Case Study
In this first evaluation, we show how CATIM can be applied to a maintenance procedure for a hydraulic elevator component. Specifically, we examine how context-aware AR can assist in the inspection of a valve that manages oil pressure (
Figure 3). Since this inspection is typically performed before the valve’s installation, we set up the valve on a table in our laboratory to represent an inspection station.
The operator’s inspection instruction is representative of some of the most common tasks in the industrial field: part localization, manual and checking operations. We used the CAD model of the valve and the text instructions taken from the manufacturer’s technical manual for the valve: “Open shut-off valve 7 until a working pressure value is read on the pressure gauge”. The case study presented herein is limited to a single inspection instruction, thus the interaction between users and the AR application is not related to browsing different instructions, but to the request of additional visual assets respect to those proposed by CATIM. However, the system can support also lengthy procedures consisting of many inspection instructions, thus producing an interactive AR manual that can be browsed by operators.
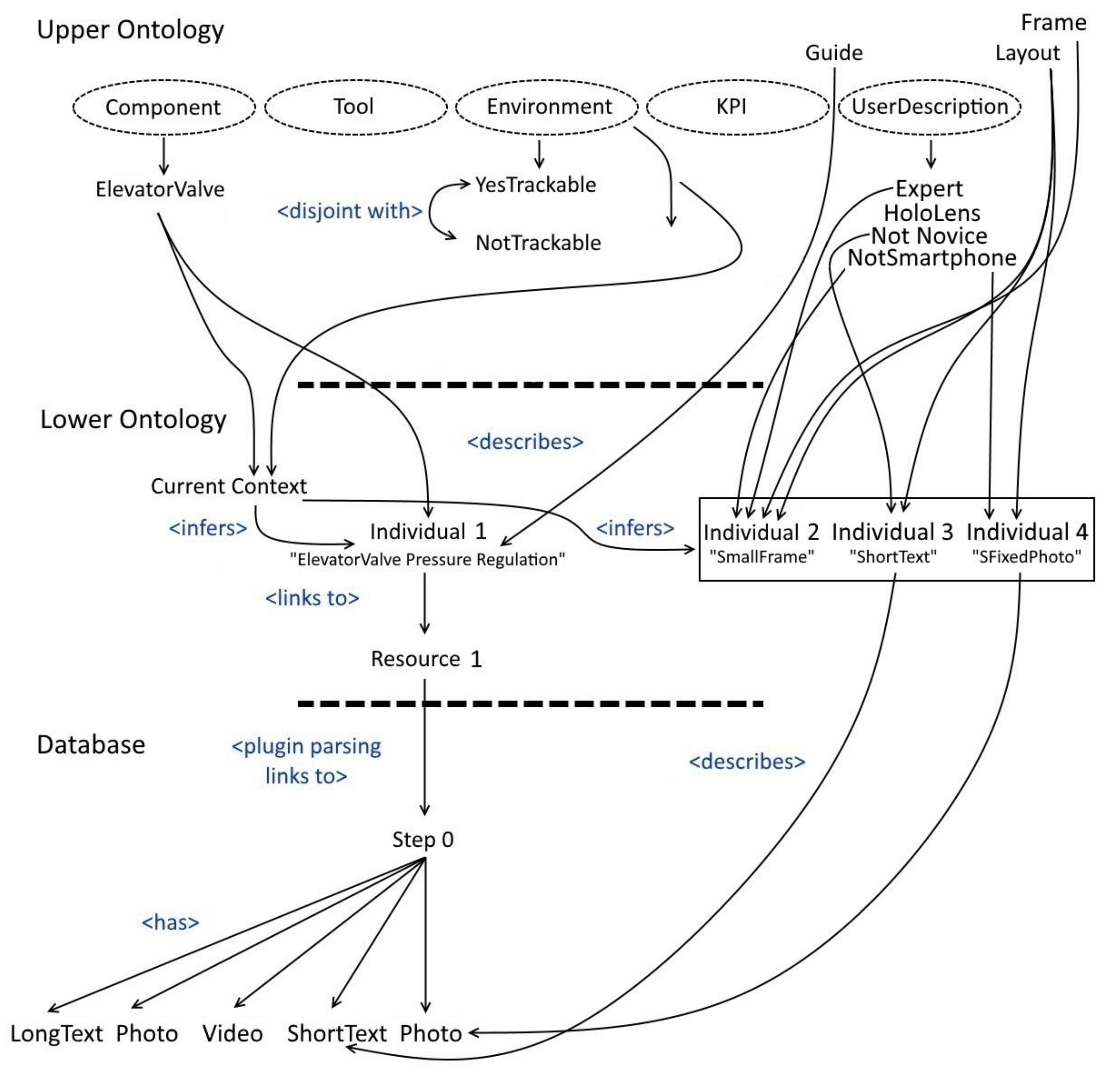
The ontology architecture for the case study is designed specifically for the information contained in technical manuals and it is composed of three levels: upper ontology, lower ontology, and database as described in
Figure 4.
The PC used as the backend in the case study run an i7-6700HQ (2.60 GHz) with 16 GB RAM, with Windows 10 operating system. The AR visualization devices were:
Microsoft HoloLens (2016);
Samsung Galaxy S7 Edge (AnTuTu v7 [
25] score: 158.313);
Sony Xperia Z3 compact (AnTuTu v7 score: 59.887);
Google LG Nexus 5 (AnTuTu v7 score: 57.006).
4.1. Technical Assets
We defined the technical asset types to be used in our case study and, starting from the available technical information, we generated the correspondent technical assets:
Short text, taken verbatim from the real manual: “Open shut-off valve 7 until you read a work pressure value on the pressure gauge”.
Long text, that details the instruction for novice users: “Turn counterclockwise the shut-off valve 7 that you can find at the bottom right, until you read a pressure value of 35 bar on the pressure gauge, then stop”.
Short audio, that is the short text delivered by a speech synthesis program.
Long audio, that is the long text delivered by a speech synthesis program.
Annotated photograph, that is a picture of the valve with annotations useful to understand the tasks to accomplish (
Figure 5a).
Product model, that is the animation of the CAD model of shut-off valve 7 to indicate the direction of rotation, and of the gauge to locate it (
Figure 5b).
Video tutorial, that is the recording of the operation previously accomplished by an operator (
Figure 5c). As for the annotated photograph, the video can be either screen-fixed or world-fixed.
Through AR devices, visual assets can be either directly superimposed on real-world referents (world-fixed) or fixed to a designated area within a display’s field of view (screen-fixed). A photograph can be rendered at a fixed location on the GUI (i.e., screen-fixed) or at a specific location in the real world (i.e., world-fixed).
4.2. Context Ontology: Activity, Operator, Environment
For the context, we consider the activity as fixed (i.e., the chosen single instruction). For the operator, we consider the single attribute of user experience (values: novice and expert user). For the environment, we consider three attributes: (i) object trackability for situated visualization (values: trackable or not trackable), (ii) noise (values: noisy and acceptable), and (iii) AR device (values: HoloLens and smartphone). In this evaluation, we simulated that these values were automatically recognized by CATIM through sensors (noise), user profiling (experience, device), retrieval of object information from the database (trackability). Various combinations of these simulated values were manually forced in the context vector.
The concept covering rules, presented in
Table 1, are defined once for the scope of the application to formalize the design choices. The following design choices were made together with the operators that constantly collaborate with us. For operator experience, we decided not to show to an expert operator detailed technical information assets such as long text/audio, world-fixed assets, and the video tutorial. We assume that an expert operator knows how to accomplish the task, whereas a novice operator could need more detailed instructions. As to device, with the HoloLens we decided not to show long text because of its limited field of view (FOV), while with the smartphone such screen-fixed content could occlude the real world. As to trackability, when the scene\objects are not trackable, we decided not to show world-fixed contents. This could be due either to the inadequacy of the target objects for the tracking method chosen or to external factors such as the forbiddance to put the optical marker on the scene. Finally, as to noise, we decided not to use audio in noisy environments.
4.3. Active AR Output
The Active AR output application, running on the AR device, displays the technical assets according to a context-dependent layout. To test this concept, we designed two GUI layouts: a small and a large one (see
Figure 6). The small one is suggested for expert operators who receive less detailed information. In this way, there is less occlusion of the real world and this is particularly crucial for the HoloLens due to the limited FOV. The visual assets were arranged into two main areas in the layouts: one for text assets and the other for non-text assets. The GUI provides other features as playback control buttons for the audio assets, help button, navigation bar, and so on.
5. Results and Discussion
We tested the effectiveness of the proposed CATIM verifying its interactivity by measuring two execution times: the reasoning time and the turnaround time. The reasoning time we define as the time the back-end takes to load all required information into memory and then to send the recommended response to front-end. The turnaround time we define as the elapsed time from which the user requests information to the time in which technical assets are rendered on AR user interface. During this time, users must wait for CATIM and thus cannot perform any interaction. Reasoning and turnaround time were measured without considering network communication time, as all assets are stored in the back-end which runs on the local network. We recorded reasoning and turnaround time seven times for each AR device. The mean reasoning time for the 28 (7 trial × 4 devices) measures was 18.3 ms. The mean turnaround times for the four devices are reported in
Figure 7 and suggest that CATIM can support highly-interactive user experiences. We observed that the ranking of times measured for the smartphones match that of the AnTuTu benchmark, as expected. Finally, we observed that the standard deviations are higher on smartphones that have many external processes and thus their execution times may vary.
These results suggest that CATIM can support interactive system performance rates, showing acceptable performance in terms of turnaround time over a series of tested devices. While we used a reduced context dataset for this work, the system is designed in a way to maintain interactive processing speeds with larger datasets. The properties of the recommendation system allow it to be scalable, eventually dividing the ontologies into knowledge subsets, while the visualization engine does not depend in any way on the system size. For this purpose, a valuable attribute of the system would be the possibility of automatically populating the ontology with a set of technical manuals, by taking them from large datasets (e.g., IFixit), often written in authoring-oriented standards, like oManual [
26], DITA [
27] or DocBook [
28].
As to the context-awareness capability, we tested all the possible context vectors (i.e., activity/operator/environment attribute combination) verifying which technical assets are recommended by CATIM. The results were consistent with what we would predict according to the concept covering rules for the current context. As expected, the recommendation process removes all the asset types which create contradictions with the current context. Some of the responses reported more than one compatible asset, suggested in decreasing order of importance, thus only the first asset was automatically shown, while the others were hidden (but still manually selectable by the operator if desired). In the case of an expert user, the number of technical information assets suggested is lower, as s/he is expected to need less information to accomplish familiar and common tasks.
Comparing CATIM with other context-aware AR systems presented in the literature, we can say that CATIM can: (i) manage all the possible types of visual assets; (ii) consider the ‘people’ factor; and (iii) implement user-defined rules for the management. This last aspect is crucial because when established standard about the visualization of technical documentation in AR will be available [
29], it would be possible to integrate them in the reasoner for the right choice of technical assets.
By taking a closer look at the results for the context with a novice operator, we can observe that the world-fixed assets are always returned by the system in a specific order (CAD > Video > Photo). This behavior is due to the limited description we adopted for this experiment: if two asset types have the same covering on the current context, the one first declared in the ontology that is chosen. This feature of CATIM can be used to establish an order of importance inside the ontology, which can derive from a finer user profiling that also considers user preferences for visual assets. User profiling is normally used in everyone’s everyday life (e.g., in web browsing, banks) even if issues related to ethics and acceptable uses of technology will become increasingly critical to its creation and usage. In this prototype, we did not consider ethic issues derived from user profiling. In future works, we will ask for operator permissions to use personal data for the scope of the application, as usually made in other scenarios.
While CATIM was designed to help in the management of technical documentation for AR user interfaces, it can be also be used for the authoring phase because authors can create new manuals with novel technical information assets, describe them in the ontology, and simulate the composition of the manual. Thus, CATIM could be the basis for further implementations and experiments for next-generation operator manuals.
6. Conclusions
In this work, we describe a novel approach for the implementation of a context-aware technical information manager (CATIM) that acquires context data about activity, operator, and environment, and then based on these data, proposes a dynamic AR user interface tailored to the current operating context. A main contribution of this work is that CATIM can propose dynamically composed AR user interfaces, based on multiple parameters detected from the context in real-time. While we use activity, operator, and environmental parameters in this use case, CATIM is capable of working with arbitrary sets of parameters. Thus, this work can serve as a springboard for other AR user interface researchers looking to create real-time, adaptive AR user interfaces.
In this work, we limited the presentation of our approach to the implementation of CATIM, providing also a first evaluation in a real scenario to better explain how the system works. We limited the number of variables in the context and their attributes (e.g., expert/novice, smartphone/HoloLens) for the sake of clarity. However, other variables (e.g., operator’s language, preference, environment hazards, and so on) and attributes (e.g., other devices as video see-through head worn displays, monitors) can be added to the ontology. We decided to test CATIM with a specific user study in future works, due to the large number of variables to control.
The final objective of the ongoing research would lead to the development of the following two parts: (i) an optimized active AR user interface, not bounded by any fixed layout, capable of interpreting user properties and environment constraints; and, (ii) an automatic recognition of technical documentation needed in a certain context. As to the dynamic AR interface, the current implementation is bounded to a limited set of fixed layouts even if they are populated dynamically. Future work will include also dynamic arrangement of assets in the interface layout.

 ,
, 











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}