Gait Recognition via Deep Learning of the Center-of-Pressure Trajectory


Abstract
Featured Application
Abstract
1. Introduction
2. Related Works
3. Materials and Methods
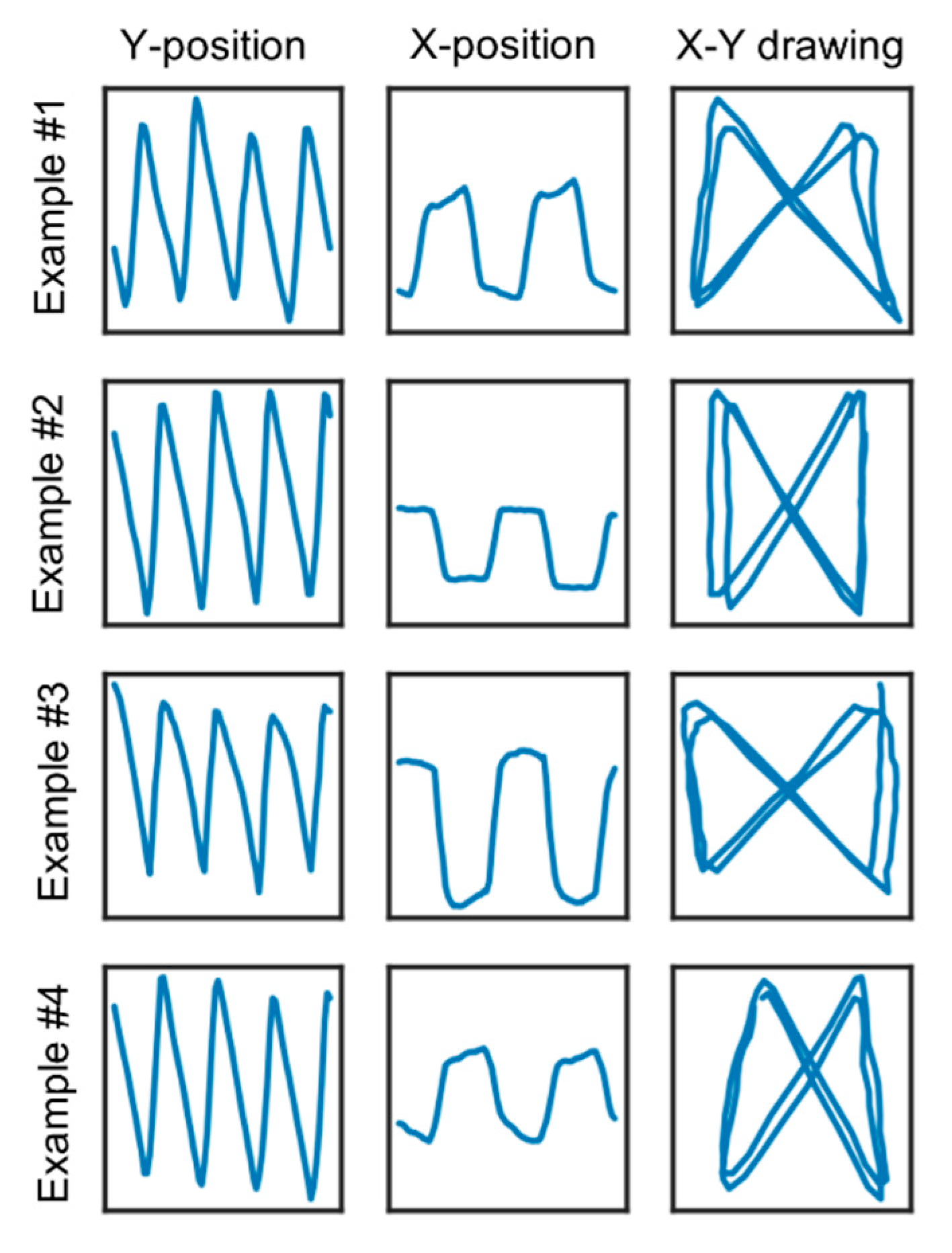
3.1. Data Collection and Pre-Processing
3.2. Software and Data Availability
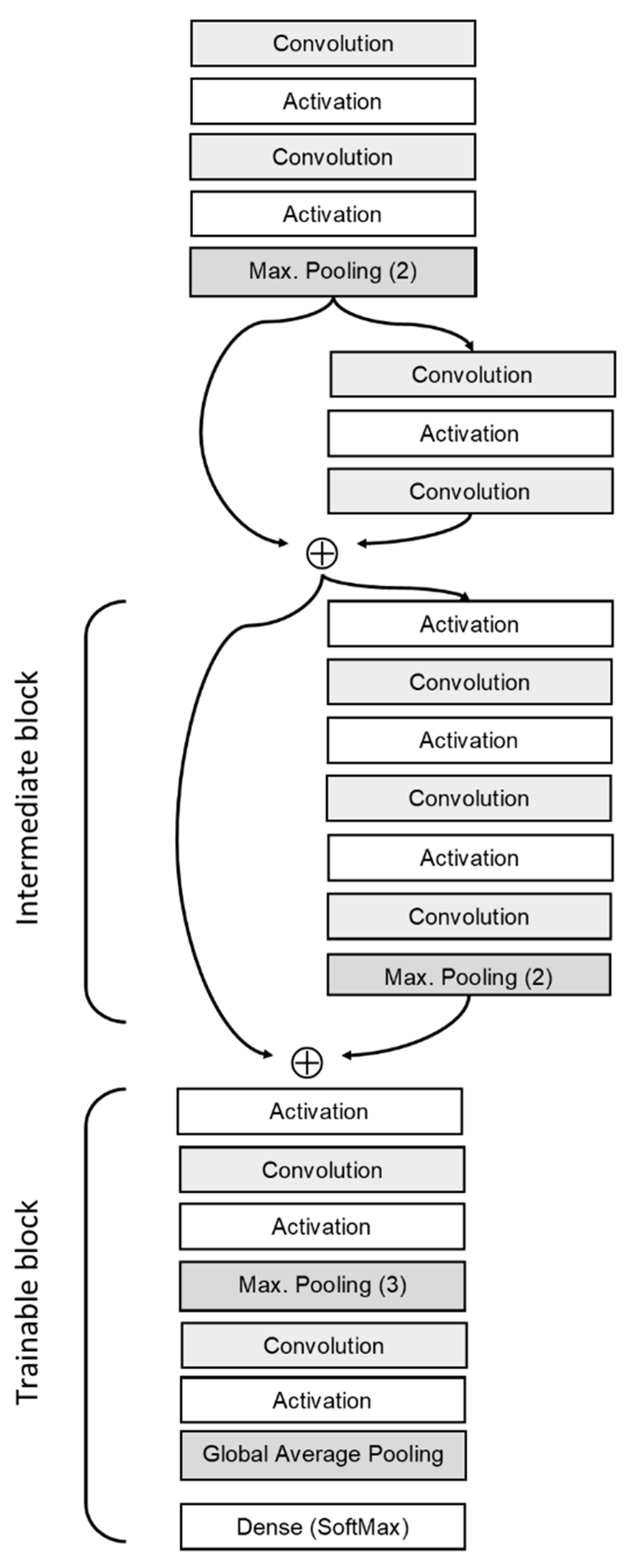
3.3. CNN
3.4. Hyperparameter Tuning and Model Testing
3.5. Transfer Learning
3.6. Verification
3.7. Class Activation Mapping
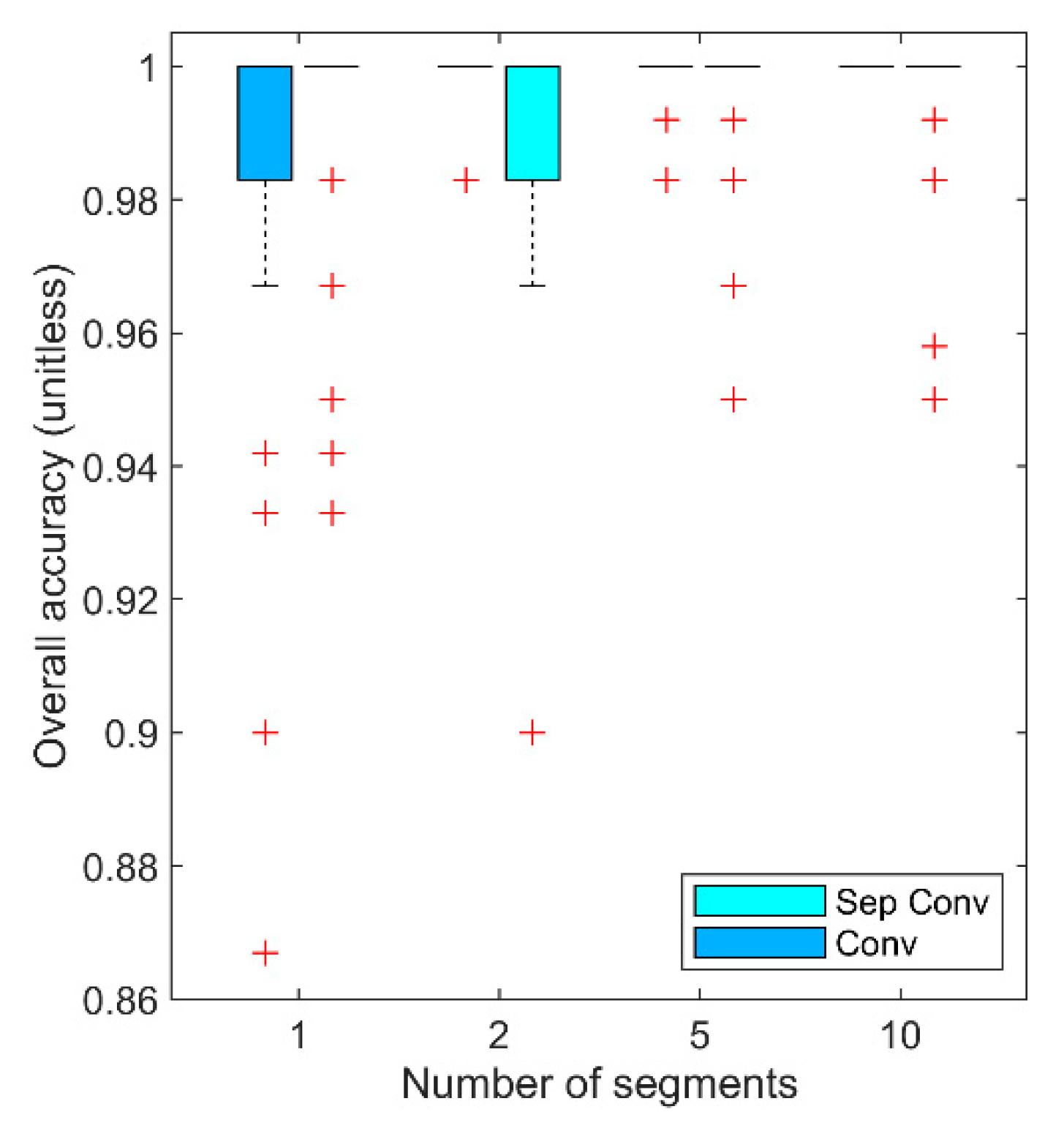
4. Results
5. Discussion
6. Conclusions
Supplementary Materials
Funding
Acknowledgments
Conflicts of Interest
References
- Holt, K.G.; Jeng, S.F.; Ratcliffe, R.; Hamill, J. Energetic Cost and Stability during Human Walking at the Preferred Stride Frequency. J. Mot. Behav. 1995, 27, 164–178. [Google Scholar] [CrossRef] [PubMed]
- Connor, P.; Ross, A. Biometric recognition by gait: A survey of modalities and features. Comput. Vis. Image Underst. 2018, 167, 1–27. [Google Scholar] [CrossRef]
- Rida, I.; Almaadeed, N.; Almaadeed, S. Robust gait recognition: A comprehensive survey. IET Biom. 2018, 8, 14–28. [Google Scholar] [CrossRef]
- Singh, J.P.; Jain, S.; Arora, S.; Singh, U.P. Vision-based gait recognition: A survey. IEEE Access 2018, 6, 70497–70527. [Google Scholar] [CrossRef]
- Makihara, Y.; Matovski, D.S.; Nixon, M.S.; Carter, J.N.; Yagi, Y. Gait Recognition: Databases, Representations, and Applications. In Wiley Encyclopedia of Electrical and Electronics Engineering; John Wiley & Sons, Inc.: Hoboken, NJ, USA, 2015; pp. 1–15. ISBN 978-0-471-34608-1. [Google Scholar]
- Takemura, N.; Makihara, Y.; Muramatsu, D.; Echigo, T.; Yagi, Y. Multi-view large population gait dataset and its performance evaluation for cross-view gait recognition. IPSJ Trans. Comput. Vis. Appl. 2018, 10, 4. [Google Scholar] [CrossRef]
- Gafurov, D.; Snekkenes, E. Gait Recognition Using Wearable Motion Recording Sensors. EURASIP J. Adv. Signal Process. 2009, 2009, 415817. [Google Scholar] [CrossRef]
- Sprager, S.; Juric, M.B. Inertial Sensor-Based Gait Recognition: A Review. Sensors 2015, 15, 22089–22127. [Google Scholar] [CrossRef]
- Vienne, A.; Barrois, R.P.; Buffat, S.; Ricard, D.; Vidal, P.-P. Inertial Sensors to Assess Gait Quality in Patients with Neurological Disorders: A Systematic Review of Technical and Analytical Challenges. Front. Psychol. 2017, 8, 817. [Google Scholar] [CrossRef]
- Zhang, Y.; Pan, G.; Jia, K.; Lu, M.; Wang, Y.; Wu, Z. Accelerometer-Based Gait Recognition by Sparse Representation of Signature Points With Clusters. IEEE Trans. Cybern. 2015, 45, 1864–1875. [Google Scholar] [CrossRef]
- Sprager, S.; Juric, M.B. An Efficient HOS-Based Gait Authentication of Accelerometer Data. IEEE Trans. Inf. Forensics Secur. 2015, 10, 1486–1498. [Google Scholar] [CrossRef]
- Rodriguez, R.V.; Evans, N.; Mason, J.S.D. Footstep Recognition. In Encyclopedia of Biometrics; Li, S.Z., Jain, A.K., Eds.; Springer: Boston, MA, USA, 2015; pp. 693–700. ISBN 978-1-4899-7488-4. [Google Scholar]
- Yao, Z.; Zhou, X.; Lin, E.; Xu, S.; Sun, Y. A novel biometrie recognition system based on ground reaction force measurements of continuous gait. In Proceedings of the 3rd International Conference on Human System Interaction, Rzeszow, Poland, 13–15 May 2010; pp. 452–458. [Google Scholar]
- Derlatka, M. Modified kNN Algorithm for Improved Recognition Accuracy of Biometrics System Based on Gait. In Proceedings of the Computer Information Systems and Industrial Management, Krakow, Poland, 25–27 September 2013; Saeed, K., Chaki, R., Cortesi, A., Wierzchoń, S., Eds.; Springer: Berlin/Heidelberg, Germany, 2013; pp. 59–66. [Google Scholar]
- Moustakidis, S.P.; Theocharis, J.B.; Giakas, G. Subject recognition based on ground reaction force measurements of gait signals. IEEE Trans. Syst. Man Cybern. Part B Cybern. 2008, 38, 1476–1485. [Google Scholar] [CrossRef] [PubMed]
- Pataky, T.C.; Mu, T.; Bosch, K.; Rosenbaum, D.; Goulermas, J.Y. Gait recognition: Highly unique dynamic plantar pressure patterns among 104 individuals. J. R. Soc. Interface 2012, 9, 790–800. [Google Scholar] [CrossRef] [PubMed]
- Jung, J.-W.; Bien, Z.; Sato, T. Person recognition method using sequential walking footprints via overlapped foot shape and center-of-pressure trajectory. IEICE Trans. Fundam. Electron. Commun. Comput. Sci. 2004, 87, 1393–1400. [Google Scholar]
- Suutala, J.; Röning, J. Methods for person identification on a pressure-sensitive floor: Experiments with multiple classifiers and reject option. Inf. Fusion 2008, 9, 21–40. [Google Scholar] [CrossRef]
- Wu, Z.; Huang, Y.; Wang, L.; Wang, X.; Tan, T. A Comprehensive Study on Cross-View Gait Based Human Identification with Deep CNNs. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 209–226. [Google Scholar] [CrossRef]
- Shiraga, K.; Makihara, Y.; Muramatsu, D.; Echigo, T.; Yagi, Y. GEINet: View-invariant gait recognition using a convolutional neural network. In Proceedings of the 2016 International Conference on Biometrics (ICB), Halmstad, Sweden, 13–16 June 2016; pp. 1–8. [Google Scholar]
- Zhao, B.; Lu, H.; Chen, S.; Liu, J.; Wu, D. Convolutional neural networks for time series classification. J. Syst. Eng. Electron. 2017, 28, 162–169. [Google Scholar] [CrossRef]
- Wang, Z.; Yan, W.; Oates, T. Time series classification from scratch with deep neural networks: A strong baseline. In Proceedings of the 2017 International Joint Conference on Neural Networks (IJCNN), Anchorage, AK, USA, 14–19 May 2017; pp. 1578–1585. [Google Scholar]
- Connor, P.C. Comparing and combining underfoot pressure features for shod and unshod gait biometrics. In Proceedings of the 2015 IEEE International Symposium on Technologies for Homeland Security (HST), Waltham, MA, USA, 14–16 April 2015; pp. 1–7. [Google Scholar]
- Terrier, P. Fractal Fluctuations in Human Walking: Comparison between Auditory and Visually Guided Stepping. Ann. Biomed. Eng. 2016, 44, 2785–2793. [Google Scholar] [CrossRef]
- Terrier, P. Complexity of human walking: The attractor complexity index is sensitive to gait synchronization with visual and auditory cues. PeerJ. 2019, 7, e7417. [Google Scholar] [CrossRef]
- Roerdink, M.; Coolen, B.H.; Clairbois, B.H.E.; Lamoth, C.J.C.; Beek, P.J. Online gait event detection using a large force platform embedded in a treadmill. J. Biomech. 2008, 41, 2628–2632. [Google Scholar] [CrossRef]
- Van Ooijen, M.W.; Roerdink, M.; Trekop, M.; Visschedijk, J.; Janssen, T.W.; Beek, P.J. Functional gait rehabilitation in elderly people following a fall-related hip fracture using a treadmill with visual context: Design of a randomized controlled trial. BMC Geriatr. 2013, 13, 34. [Google Scholar] [CrossRef]
- Kalron, A.; Frid, L. The “butterfly diagram”: A gait marker for neurological and cerebellar impairment in people with multiple sclerosis. J. Neurol. Sci. 2015, 358, 92–100. [Google Scholar] [CrossRef] [PubMed]
- Terrier, P.; Dériaz, O. Non-linear dynamics of human locomotion: Effects of rhythmic auditory cueing on local dynamic stability. Front. Physiol. 2013, 4, 230. [Google Scholar] [CrossRef] [PubMed]
- Terrier, P. Complexity of Human Walking: The Attractor Complexity Index is Sensitive to Gait Synchronization with Visual and Auditory Cues. Available online: https://figshare.com/articles/Complexity_of_human_walking_the_attractor_complexity_index_is_sensitive_to_gait_synchronization_with_visual_and_auditory_cues/8166902 (accessed on 12 July 2019).
- Terrier, P. Gait recognition via deep learning of center-of-pressure trajectory [Source Code]. Available online: https://doi.org/10.24433/CO.0792128.v1 (accessed on 21 January 2020).
- Ioffe, S.; Szegedy, C. Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift. In Proceedings of the International Conference on Machine Learning, Lille, France, 6–11 July 2015; pp. 448–456. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Veit, A.; Wilber, M.J.; Belongie, S. Residual Networks Behave Like Ensembles of Relatively Shallow Networks. In Proceedings of the International Conference on Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016; Lee, D.D., Sugiyama, M., Luxburg, U.V., Guyon, I., Garnett, R., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2016; pp. 550–558. [Google Scholar]
- Chollet, F. Xception: Deep Learning with Depthwise Separable Convolutions. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 1800–1807. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Dozat, T. Incorporating Nesterov Momentum into Adam. Available online: https://openreview.net/forum?id=OM0jvwB8jIp57ZJjtNEZ¬eId=OM0jvwB8jIp57ZJjtNEZ (accessed on 13 October 2018).
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Sutskever, I.; Martens, J.; Dahl, G.; Hinton, G. On the importance of initialization and momentum in deep learning. In Proceedings of the International Conference on Machine Learning, Atlanta, GA, USA, 16–21 June 2013; pp. 1139–1147. [Google Scholar]
- Lin, M.; Chen, Q.; Yan, S. Network in Network. arXiv 2013, arXiv:1312.4400. [Google Scholar]
- Maas, A.L.; Hannun, A.Y.; Ng, A.Y. Rectifier nonlinearities improve neural network acoustic models. In Proceedings of the in ICML Workshop on Deep Learning for Audio, Speech and Language Processing, Atlanta, GA, USA, 16 June 2013. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 1026–1034. [Google Scholar]
- Ramachandran, P.; Zoph, B.; Le, Q.V. Searching for Activation Functions. arXiv 2017, arXiv:1710.05941. [Google Scholar]
- Elfwing, S.; Uchibe, E.; Doya, K. Sigmoid-weighted linear units for neural network function approximation in reinforcement learning. Neural Netw. 2018, 107, 3–11. [Google Scholar] [CrossRef]
- Glorot, X.; Bengio, Y. Understanding the difficulty of training deep feedforward neural networks. In Proceedings of the Thirteenth International Conference on Artificial Intelligence and Statistics, Sardinia, Italy, 13–15 May 2010; pp. 249–256. [Google Scholar]
- Bergstra, J.S.; Bardenet, R.; Bengio, Y.; Kégl, B. Algorithms for Hyper-Parameter Optimization. In Proceedings of the International Conference on Neural Information Processing Systems, Granada, Spain, 12–17 December 2011; Shawe-Taylor, J., Zemel, R.S., Bartlett, P.L., Pereira, F., Weinberger, K.Q., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2011; pp. 2546–2554. [Google Scholar]
- Bergstra, J.; Komer, B.; Eliasmith, C.; Yamins, D.; Cox, D.D. Hyperopt: A Python library for model selection and hyperparameter optimization. Comput. Sci. Discov. 2015, 8, 014008. [Google Scholar] [CrossRef]
- Pumperla, M. Keras + Hyperopt: A very Simple Wrapper for Convenient Hyperparameter Optimization: Maxpumperla/Hyperas. Available online: https://github.com/maxpumperla/hyperas (accessed on 21 January 2020).
- Van Der Maaten, L.; Hinton, G. Visualizing data using t-SNE. J. Mach. Learn. Res. 2008, 9, 2579–2625. [Google Scholar]
- Straube, S.; Krell, M.M. How to evaluate an agent’s behavior to infrequent events?—Reliable performance estimation insensitive to class distribution. Front. Comput. Neurosci. 2014, 8, 43. [Google Scholar] [CrossRef]
- Tharwat, A. Classification assessment methods. Appl. Comput. Inf. 2018. [Google Scholar] [CrossRef]
- Zhou, B.; Khosla, A.; Lapedriza, A.; Oliva, A.; Torralba, A. Learning Deep Features for Discriminative Localization. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 2921–2929. [Google Scholar]
- Ismail Fawaz, H.; Forestier, G.; Weber, J.; Idoumghar, L.; Muller, P.-A. Evaluating Surgical Skills from Kinematic Data Using Convolutional Neural Networks. In Proceedings of the Medical Image Computing and Computer Assisted Intervention—MICCAI, Granada, Spain, 16–20 September 2018; Frangi, A.F., Schnabel, J.A., Davatzikos, C., Alberola-López, C., Fichtinger, G., Eds.; Springer: Berlin/Heidelberg, Germany, 2018; pp. 214–221. [Google Scholar]
- Han, J.; Bhanu, B. Performance prediction for individual recognition by gait. Pattern Recognit. Lett. 2005, 26, 615–624. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. In Advances in Neural Information Processing Systems 25; Pereira, F., Burges, C.J.C., Bottou, L., Weinberger, K.Q., Eds.; Curran Associates, Inc.: Brooklyn, NY, USA, 2012; pp. 1097–1105. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Terrier, P.; Turner, V.; Schutz, Y. GPS analysis of human locomotion: Further evidence for long-range correlations in stride-to-stride fluctuations of gait parameters. Hum. Mov. Sci. 2005, 24, 97–115. [Google Scholar] [CrossRef] [PubMed]
- Nüesch, C.; Overberg, J.-A.; Schwameder, H.; Pagenstert, G.; Mündermann, A. Repeatability of spatiotemporal, plantar pressure and force parameters during treadmill walking and running. Gait Posture 2018, 62, 117–123. [Google Scholar] [CrossRef] [PubMed]
- Item-Glatthorn, J.F.; Casartelli, N.C.; Maffiuletti, N.A. Reproducibility of gait parameters at different surface inclinations and speeds using an instrumented treadmill system. Gait Posture 2016, 44, 259–264. [Google Scholar] [CrossRef]
- Stolze, H.; Kuhtz-Buschbeck, J.P.; Mondwurf, C.; Jöhnk, K.; Friege, L. Retest reliability of spatiotemporal gait parameters in children and adults. Gait Posture 1998, 7, 125–130. [Google Scholar] [CrossRef]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef]
- Terrier, P.; Dériaz, O. Kinematic variability, fractal dynamics and local dynamic stability of treadmill walking. J. Neuroeng. Rehabil. 2011, 8, 12. [Google Scholar] [CrossRef]
- White, S.C.; Yack, H.J.; Tucker, C.A.; Lin, H.Y. Comparison of vertical ground reaction forces during overground and treadmill walking. Med. Sci. Sports Exerc. 1998, 30, 1537–1542. [Google Scholar] [CrossRef]
- Grieco, J.C.; Gouelle, A.; Weeber, E.J. Identification of spatiotemporal gait parameters and pressure-related characteristics in children with Angelman syndrome: A pilot study. J. Appl. Res. Intellect. Disabil. 2018, 31, 1219–1224. [Google Scholar] [CrossRef] [PubMed]
- Oberg, T.; Karsznia, A.; Oberg, K. Basic gait parameters: Reference data for normal subjects, 10–79 years of age. J. Rehabil. Res. Dev. 1993, 30, 210–223. [Google Scholar] [PubMed]
- Terrier, P.; Dériaz, O. Persistent and anti-persistent pattern in stride-to-stride variability of treadmill walking: Influence of rhythmic auditory cueing. Hum. Mov. Sci. 2012, 31, 1585–1597. [Google Scholar] [CrossRef] [PubMed]
- Terrier, P. Step-to-step variability in treadmill walking: Influence of rhythmic auditory cueing. PLoS ONE 2012, 7, e47171. [Google Scholar] [CrossRef]
- Roerdink, M.; de Jonge, C.P.; Smid, L.M.; Daffertshofer, A. Tightening up the Control of Treadmill Walking: Effects of Maneuverability Range and Acoustic Pacing on Stride-to-Stride Fluctuations. Front. Physiol. 2019, 10, 257. [Google Scholar] [CrossRef]
- Veilleux, L.N.; Robert, M.; Ballaz, L.; Lemay, M.; Rauch, F. Gait analysis using a force-measuring gangway: Intrasession repeatability in healthy adults. J. Musculoskelet. Neuronal Interact 2011, 11, 27–33. [Google Scholar]
- Scorza, A.; Massaroni, C.; Orsini, F.; D’Anna, C.; Conforto, S.; Silvestri, S.; Sciuto, S.A. A review on methods and devices for force platforms calibration in medical applications. J. Eng. Sci. Technol. Rev. 2018, 11, 10–18. [Google Scholar] [CrossRef]
- Andries, M.; Simonin, O.; Charpillet, F. Localization of Humans, Objects, and Robots Interacting on Load-Sensing Floors. IEEE Sens. J. 2016, 16, 1026–1037. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Hyperparameters | Method | Values | Best Results | |
|---|---|---|---|---|
| CNN | sepCNN | |||
| CNN architecture | ||||
| Filter size in layers | Choice | A: 15, 13, 11, 11, [11, 11, 11], 3, 2 | C | C |
| B: 11, 9, 7, 7, [7, 7, 7], 3, 2 | ||||
| C: 9, 7, 5, 5, [5, 5, 5], 3, 2 | ||||
| Number of filters in layers | Choice | A: 16, 16, 32, 64, [64,64, 64],64, 128, (128) | B | D |
| B: 32, 32, 64, 128, [128, 128, 128], 128, 256, (256) | ||||
| C: 64, 64, 128, 256, [256, 256, 256], 256, 512, (512) | ||||
| D: 128, 128, 256, 512, [512, 512, 512], 512, 1024, (1024) | ||||
| Number of intermediate blocks | Choice | 0, 1, 2, 3 | 2 | 1 |
| Top-layer configuration | Choice | A: Global Average Pooling + Dense (Softmax) | A | A |
| B: Flatten + Dense + Dropout + Dense (Softmax) | ||||
| Weight initialization | ||||
| Choice | A: Glorot (Xavier) normal initializer | A | A | |
| B: He normal initializer | ||||
| Activation | ||||
| Choice | ReLU | Swish | Swish | |
| LeakyReLU | ||||
| PReLU | ||||
| Trainable Swish | ||||
| Regularization | ||||
| L2 lambda | Log-uniform | 10−7 to 10−3 | 1.33 × 10−5 | 1.01 × 10−7 |
| Optimization | ||||
| Initial learning rate | Log-uniform | 0.0002 to 0.004 | 0.00068 | 0.00111 |
| 30 Subjects | 36 Subjects (Transfer Learning) | |||
|---|---|---|---|---|
| Trial | CNN | sepCNN | CNN | sepCNN |
| 1 | 0.998 | 1.000 | 1.000 | 1.000 |
| 2 | 1.000 | 1.000 | 0.999 | 1.000 |
| 3 | 0.976 | 0.998 | 0.999 | 0.999 |
| 4 | 1.000 | 0.999 | 0.999 | 1.000 |
| 5 | 0.998 | 0.999 | 0.999 | 0.999 |
| 6 | 0.999 | 0.998 | 0.999 | 0.999 |
| 7 | 0.998 | 0.903 | 0.999 | 0.999 |
| 8 | 0.999 | 0.999 | 0.999 | 0.999 |
| 9 | 0.999 | 1.000 | 0.999 | 0.999 |
| 10 | 0.998 | 0.998 | 0.999 | 0.999 |
| Median | 99.84% | 99.89% | 99.91% | 99.93% |
| First quartile | 99.82% | 99.82% | 99.88% | 99.93% |
| Third quartile | 99.87% | 99.94% | 99.93% | 99.96% |
| Authorized Users | Unauthorized Users | AUC (Median) | AUC (1st Quartile) | AUC (3rd Quartile) | EER (Median) | EER (1st Quartile) | EER (3rd Quartile) |
|---|---|---|---|---|---|---|---|
| 10 | 26 | 0.99997 | 0.99994 | 0.99999 | 0.27% | 0.23% | 0.31% |
| 15 | 21 | 0.99997 | 0.99994 | 0.99998 | 0.25% | 0.19% | 0.33% |
| 20 | 16 | 0.99995 | 0.99991 | 0.99996 | 0.33% | 0.25% | 0.41% |
| 25 | 11 | 0.99996 | 0.99995 | 0.99999 | 0.32% | 0.23% | 0.39% |
| Average | 0.99997 | 0.29% |
| Study | Subj. | Steps | Footwear | Feature | Classifier | Performance |
|---|---|---|---|---|---|---|
| Jung et al. 2004 [17] | 11 | 440 | Barefoot | Foot shape + COP trajectory | HMM | FRR: 1.36%FAR: 0.14% |
| Suutala et al. 2007 [18] | 11 | 440 | Shod | Vertical GRF profile | SVM, MLP | ACC: 95% |
| Moustadikis et al. 2008 [15] | 40 | 2800 | Shod | 3D GRF profile | SVM | ACC: 98.2% |
| Pataky et al. 2011 [16] | 104 | 1040 | Barefoot | Plantar pressure pattern | KNN | ACC: 99.6% |
| Derlatka 2013 [14] | 142 | 2500 | Shod | 3D GRF profile | KNN | ACC: 98% |
| Connor 2015 [23] | 92 | 3000 | Barefoot and Shod | Mixed | KNN | ACC: 99.8% (Barefoot) ACC: 99.5% (Shod) |
| This study, identification | 36 | 108,000 | Shod | COP trajectory | CNN | ACC: 99.9% |
| This study, verification | 36 | 108,000 | Shod | COP trajectory | CNN | EER: 0.3% |
© 2020 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Terrier, P. Gait Recognition via Deep Learning of the Center-of-Pressure Trajectory. Appl. Sci. 2020, 10, 774. https://doi.org/10.3390/app10030774
Terrier P. Gait Recognition via Deep Learning of the Center-of-Pressure Trajectory. Applied Sciences. 2020; 10(3):774. https://doi.org/10.3390/app10030774
Chicago/Turabian StyleTerrier, Philippe. 2020. "Gait Recognition via Deep Learning of the Center-of-Pressure Trajectory" Applied Sciences 10, no. 3: 774. https://doi.org/10.3390/app10030774
APA StyleTerrier, P. (2020). Gait Recognition via Deep Learning of the Center-of-Pressure Trajectory. Applied Sciences, 10(3), 774. https://doi.org/10.3390/app10030774