Environmental Attention-Guided Branchy Neural Network for Speech Enhancement

Abstract
1. Introduction
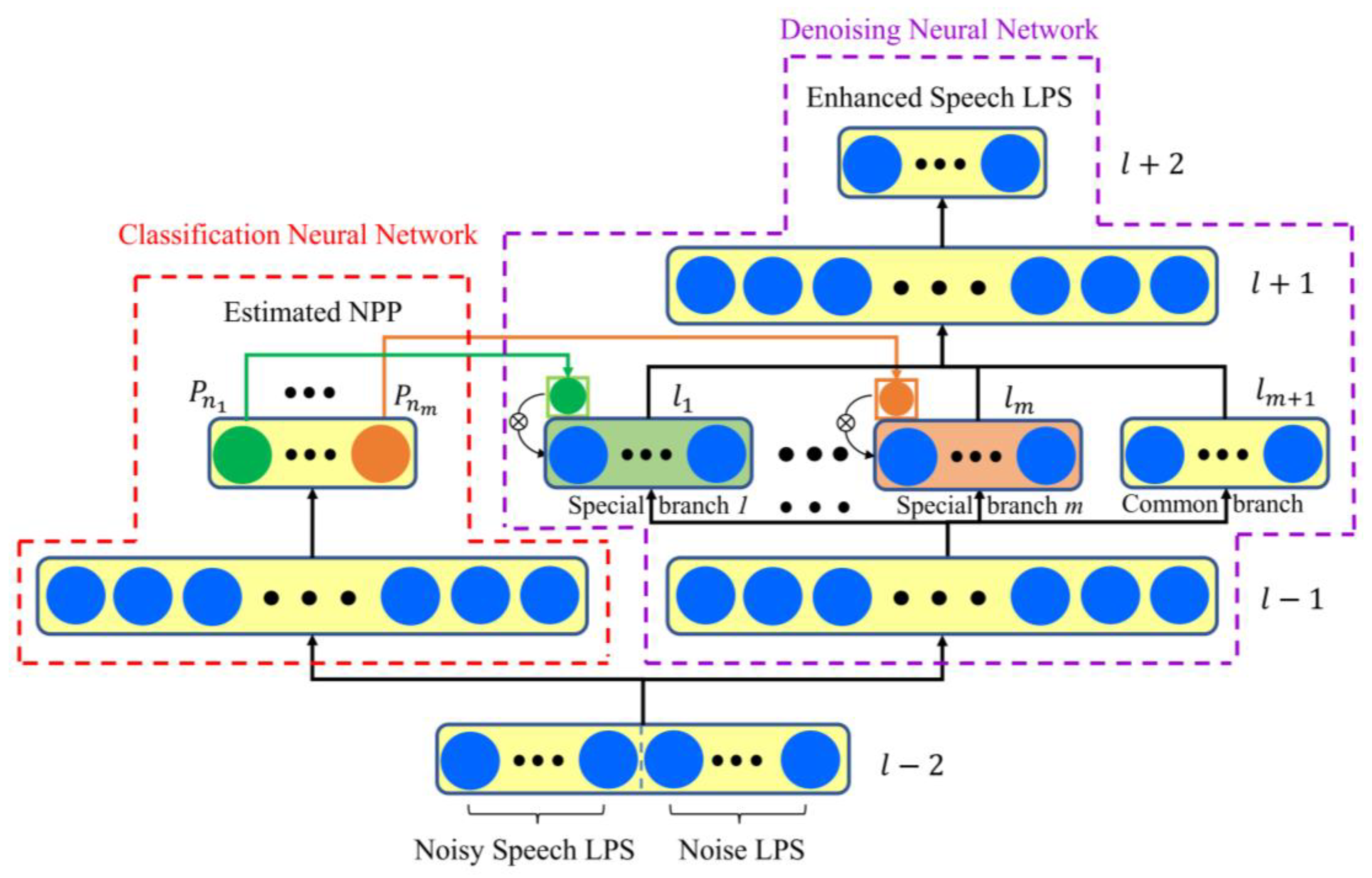
2. Branchy Neural Network with Attention Mechanism
2.1. Classification Neural Network for Attention Allocation
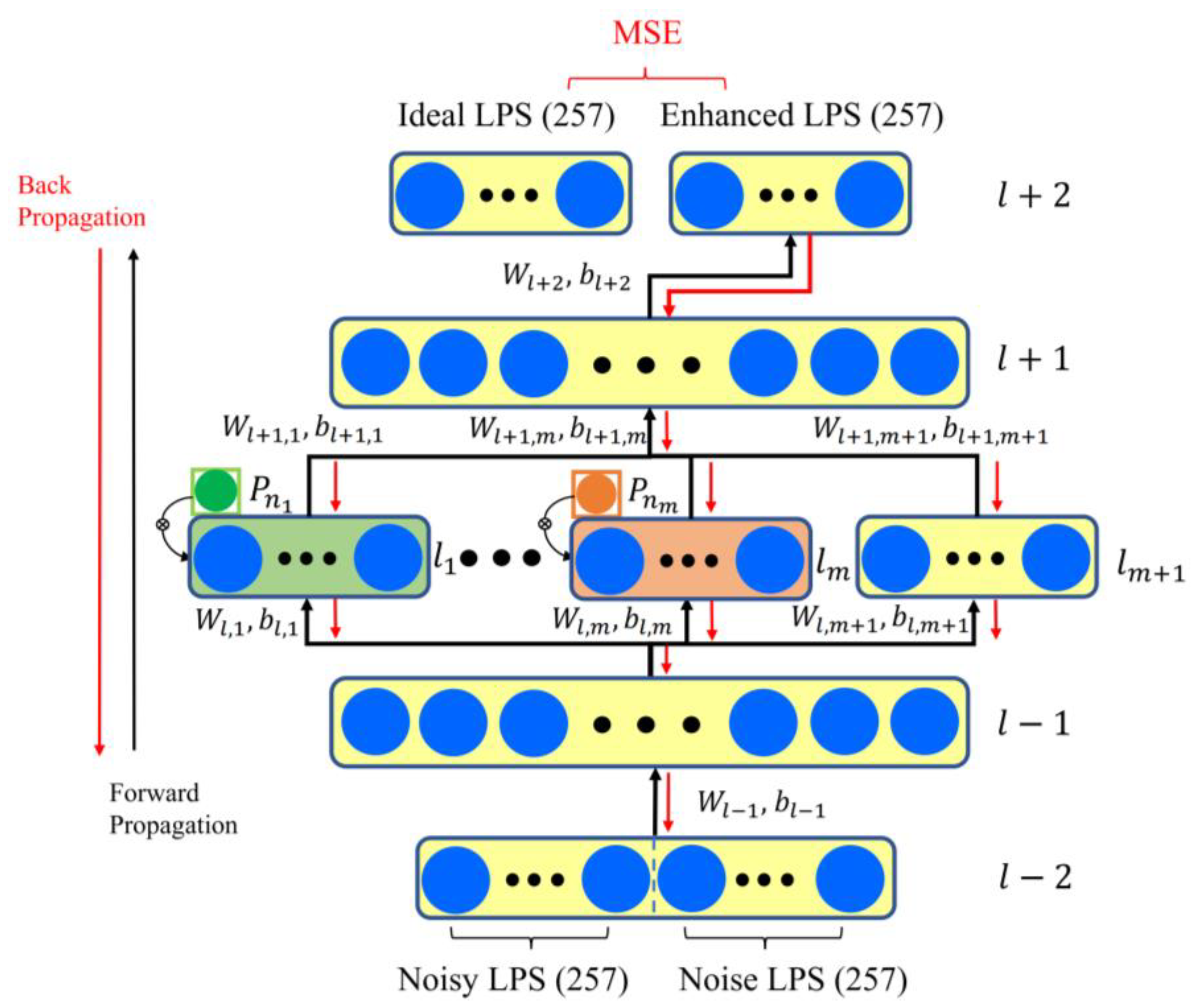
2.2. Denoising Neural Network with Attention-Based Branchy Structure
3. Experiments and Results
3.1. Experimental Settings
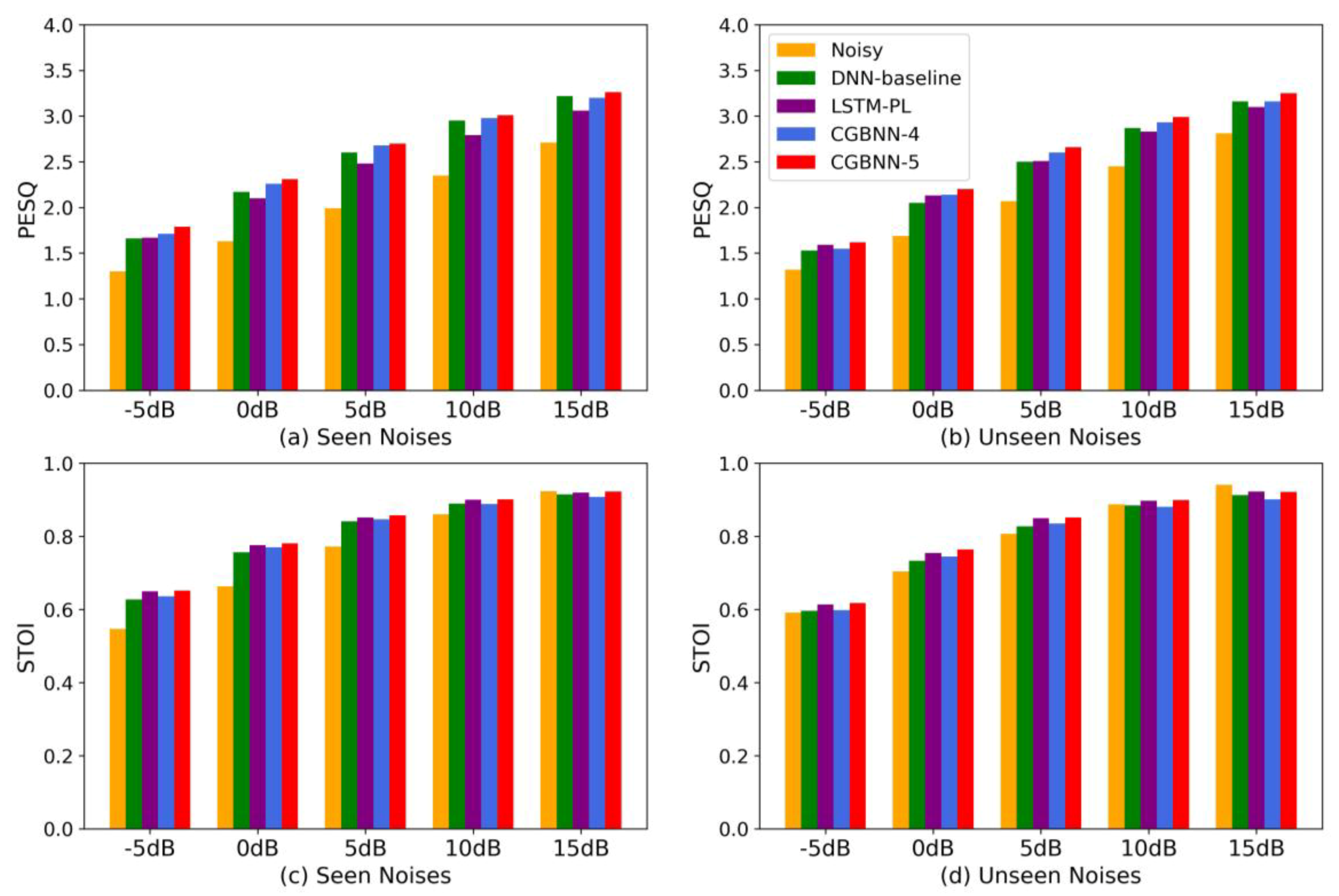
3.2. Performance Evaluation of Branchy Neural Network
3.2.1. Classification Accuracy Evaluation
3.2.2. Denoising Performance Evaluation
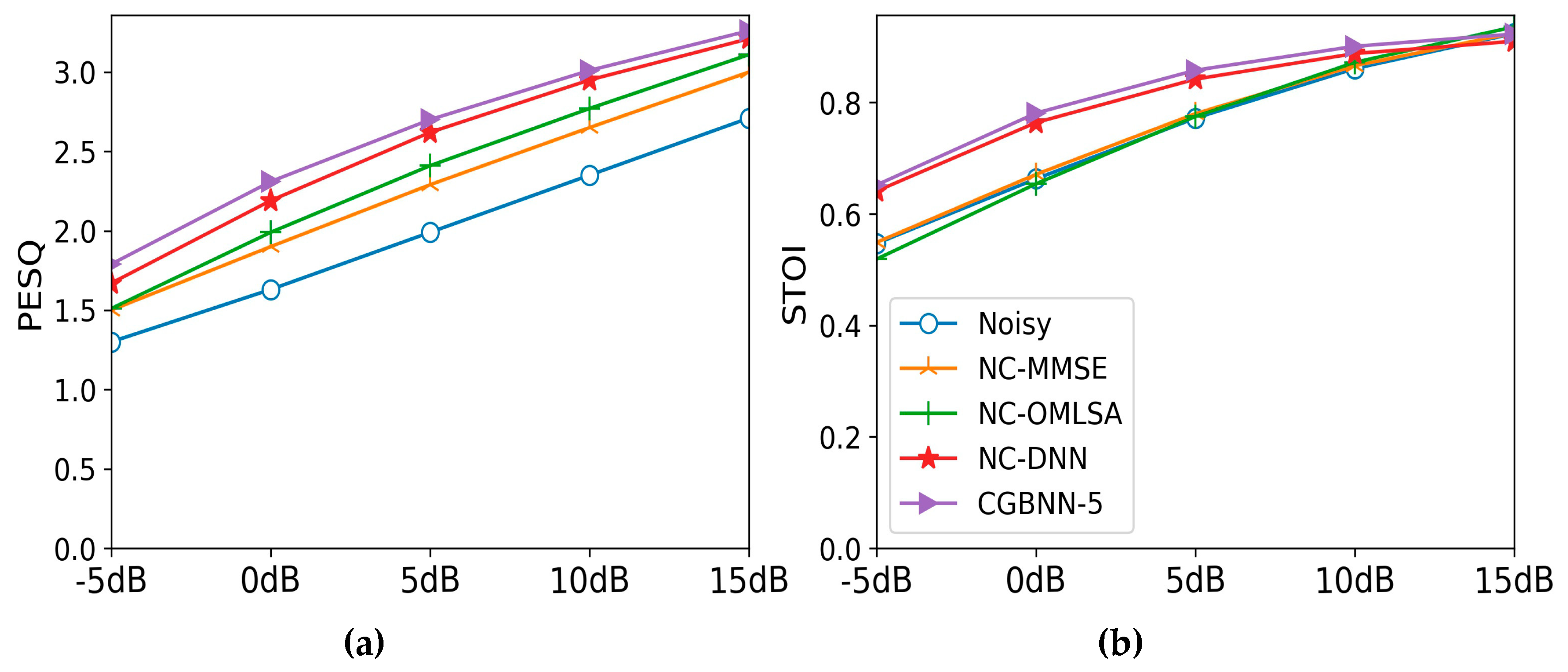
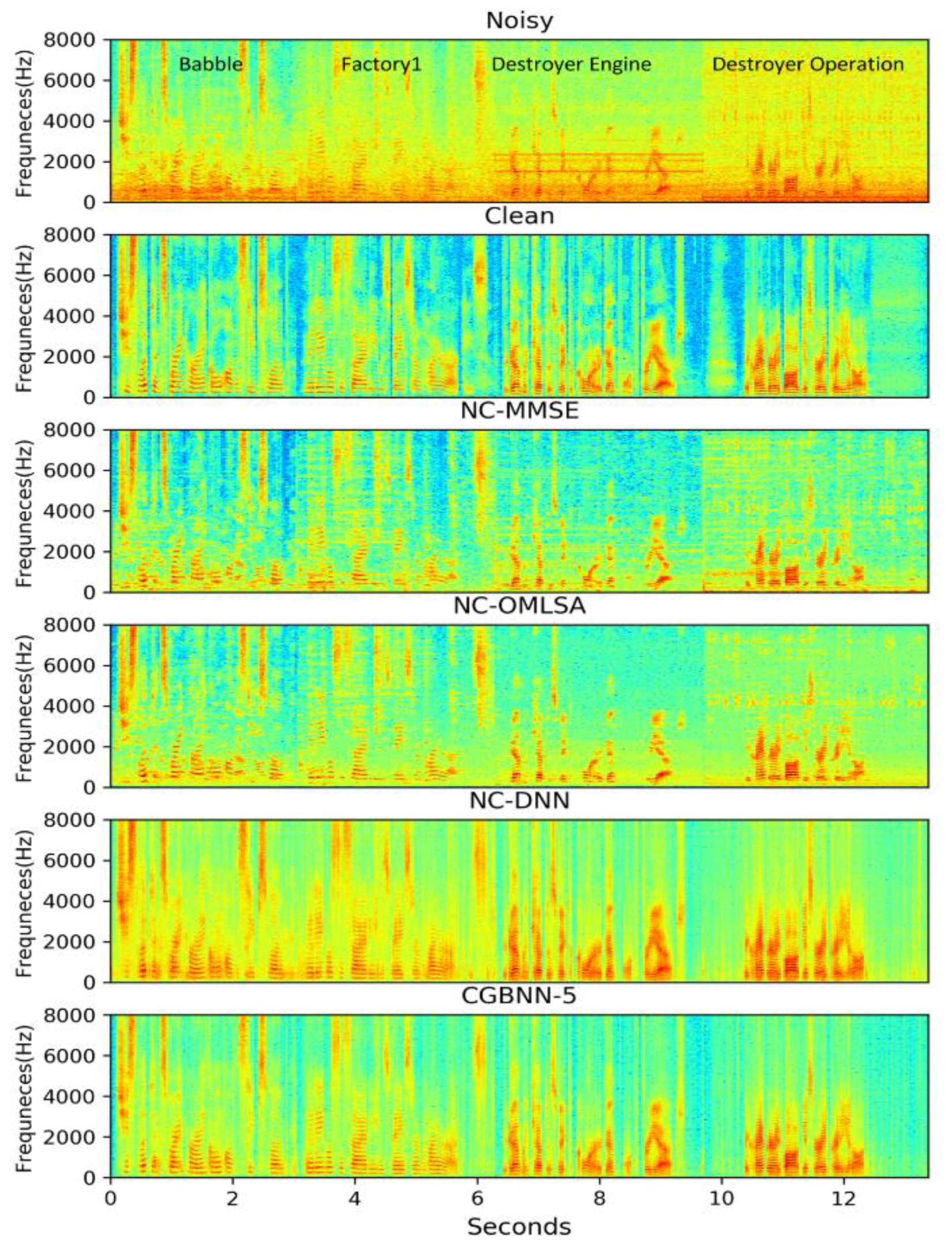
3.3. Performance Comparison with Other Environment-Aware Methods
4. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Appendix A

References
- Scalart, P.; Filho, J.V. Speech enhancement based on a priori signal to noise estimation. In Proceedings of the International Conference on Acoustics, Speech and Signal Processing (ICASSP), Atlanta, GA, USA, 7–10 May 1996; pp. 629–632. [Google Scholar]
- Cohen, I.; Berdugo, B. Speech enhancement for non-stationary noise environments. Signal Process. 2001, 81, 2403–2418. [Google Scholar] [CrossRef]
- Erkelens, J.S.; Hendriks, R.C.; Heusdens, R. Minimum mean-square error estimation of discrete Fourier coefficients with generalized gamma priors. IEEE Trans. Audio Speech Lang. Process. 2007, 15, 1741–1752. [Google Scholar] [CrossRef]
- Martin, R. Noise power spectral density estimation based on optimal smoothing and minimum statistics. IEEE Trans. Audio Speech Lang. Process. 2001, 9, 504–512. [Google Scholar] [CrossRef]
- Cohen, I.; Berdugo, B. Noise estimation by minima controlled recursive averaging for robust speech enhancement. IEEE Signal Process. Lett. 2002, 9, 12–15. [Google Scholar] [CrossRef]
- Gerkmann, T.; Hendriks, R.C. Unbiased MMSE-based noise power estimation with low complexity and low tracking delay. IEEE Trans. Audio Speech Lang. Process. 2012, 20, 1383–1393. [Google Scholar] [CrossRef]
- Ephraim, Y.; Malah, D. Speech enhancement using a minimum mean square error short-time spectral amplitude estimator. IEEE Trans. Audio Speech Lang. Process. 1984, 32, 1109–1121. [Google Scholar] [CrossRef]
- Hasan, M.K.; Salahuddin, S.; Khan, M.R. A modified a priori SNR for speech enhancement using spectral subtraction rules. IEEE Signal Process. Lett. 2004, 11, 450–453. [Google Scholar] [CrossRef]
- Yuxuan, W.; Narayanan, A.; DeLiang, W. On Training targets for supervised speech separation. IEEE Trans. Audio Speech Lang. Process. 2014, 22, 1849–1858. [Google Scholar] [CrossRef]
- Williamson, D.S.; Yuxuan, W.; DeLiang, W. Complex ratio masking for monaural speech separation. IEEE Trans. Audio Speech Lang. Process. 2016, 24, 483–492. [Google Scholar] [CrossRef]
- Tu, M.; Zhang, X. Speech enhancement based on Deep Neural Networks with skip connections. In Proceedings of the International Conference on Acoustics, Speech and Signal Processing (ICASSP), New Orleans, LA, USA, 5–9 May 2017; pp. 5565–5569. [Google Scholar]
- Ding, L.; Smaragdis, P.; Minje, K. Experiments on deep learning for speech denoising. In Proceedings of the International Speech Communication Association (INTERSPEECH), Singapore, 14–18 September 2014; pp. 2685–2689. [Google Scholar]
- Xu, Y.; Jun, D.; Dai, L.-R.; Lee, C.-H. An experimental study on speech enhancement based on deep neural networks. IEEE Signal Process. Lett. 2014, 21, 65–68. [Google Scholar] [CrossRef]
- Xu, Y.; Jun, D.; Dai, L.-R.; Lee, C.-H. regression approach to speech enhancement based on deep neural networks. IEEE Trans. Audio Speech Lang. 2015, 23, 7–19. [Google Scholar] [CrossRef]
- Gao, T.; Du, J.; Dai, L.-R.; Lee, C.-H. SNR-based progressive learning of deep neural network for speech enhancement. In Proceedings of the International Speech Communication Association (INTERSPEECH), San Francesco, CA, USA, 8–12 September 2016; pp. 3713–3717. [Google Scholar]
- Dayana, R.; Jorge, L.; Antonio, M.; Luis, V. Deep speech enhancement for reverberated and noisy signals using wide residual networks. arXiv 2019, arXiv:1901.00660. [Google Scholar]
- Syu-Siang, W.; Yu-You, L.; Jeih-weih, H.; Yu, T.; Hsin-Min, W.; Shih-Hau, F. Distributed microphone speech enhancement based on deep learning. arXiv 2019, arXiv:1911.08153. [Google Scholar]
- Gao, T.; Du, J.; Dai, L.-R.; Lee, C.-H. Densely connected progressive learning for LSTM-based speech enhancement. In Proceedings of the International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018; pp. 5054–5058. [Google Scholar]
- Ke, T.; Jitong, C.; Deliang, W. Gated residual networks with dilated convolutions for monaural speech enhancement. IEEE Trans. Audio Speech Lang. 2019, 27, 189–198. [Google Scholar]
- Kumar., A.; Dinei, F.; Kumar, A.; Dinei, F. Speech enhancement in multiple-noise conditions using deep neural networks. In Proceedings of the International Speech Communication Association (INTERSPEECH), San Francesco, CA, USA, 8–12 September 2016; pp. 3738–3742. [Google Scholar]
- Yuma, K.; Kenta, N.; Yusuke, H. DNN-based source enhancement to increase objective sound quality assessment score. IEEE Trans. Audio Speech Lang. 2018, 26, 1780–1792. [Google Scholar]
- Wu, J.; Hua, Y.; Yang, S.; Qin, H.S.; Qin, H.B. Speech Enhancement Using Generative Adversarial Network by Distilling Knowledge from Statistical Method. Appl. Sci. 2019, 9, 3396. [Google Scholar] [CrossRef]
- Nidhyananthan, S.S.; Kumari, R.S.S.; Prakash, A.A. A review on speech enhancement algorithms and why to combine with environment classification. Int. J. Mod. Phys. C 2014, 25, 1430002. [Google Scholar] [CrossRef]
- Choi, J.H.; Chang, J.H. On using acoustic environment classification for statistical model-based speech enhancement. Speech Commun. 2012, 54, 477–490. [Google Scholar] [CrossRef]
- Chang, J.H. Noisy speech enhancement based on improved minimum statistics incorporating acoustic environment-awareness. Digit. Signal Process. 2013, 23, 1233–1238. [Google Scholar] [CrossRef]
- Yuan, W.; Xia, B. A speech enhancement approach based on noise classification. Appl. Acoust. 2015, 96, 11–19. [Google Scholar] [CrossRef]
- Li, R.; Liu, Y.; Shi, Y. ILMSAF based speech enhancement with DNN and noise classification. Speech Commun. 2016, 85, 53–70. [Google Scholar] [CrossRef]
- Bingyin, X.; Changchun, B. Wiener filtering based speech enhancement with weighted denoising auto-encoder and noise classification. Speech Commun. 2014, 60, 13–29. [Google Scholar]
- Shi, W.; Zhang, X.; Zou, X. Deep neural network and noise classification-based speech enhancement. Mod. Phys. Lett. B 2017, 31, 1740096. [Google Scholar] [CrossRef]
- Loizou, P.C. Speech Enhancement: Theory and Practice, 2nd ed.; CRC: Boca Raton, FL, USA, 2013; pp. 360–363. [Google Scholar]
- Xie, F.; Compernolle, D.V. A family of MLP based nonlinear spectral estimators for noise reduction. In Proceedings of the International Conference on Acoustics, Speech and Signal Processing (ICASSP), Adelaide, Australia, 8–12 May 1994; pp. 53–56. [Google Scholar]
- Garofolo, J.S.; Lamel, L.F.; Fisher, W.M.; Fiscus, J.G.; Pallett, D.S.; Dahlgren, N.L. Getting Started with the DARPA TIMIT CD-ROM: An Acoustic Phonetic Continuous Speech Database; National Institute of Standards and Technology: Gaithersburgh, MD, USA, 1988; pp. 1–79.
- Varga, A.; Steeneken, H.J. Assessment for automatic speech recognition: II. NOISEX-92: A database and an experiment to study the effect of additive noise on speech recognition systems. Speech Commun. 1993, 12, 247–251. [Google Scholar] [CrossRef]
- Rix, A.W.; Beerends, J.G.; Hollier, M.P.; Hekstra, A.P. Perceptual evaluation of speech quality (PESQ)-a new method for speech quality assessment of telephone networks and codecs. In Proceedings of the International Conference on Acoustics, Speech and Signal Processing (ICASSP), Salt Lake City, UT, USA, 7–11 May 2001; pp. 749–752. [Google Scholar]
- Taal, C.H.; Hendriks, R.C.; Heusdens, R.; Jensen, J. An algorithm for intelligibility prediction of time-frequency weighted noisy speech. IEEE Trans. Audio Speech Lang. 2011, 19, 2125–2136. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J.L. Adam: A method for stochastic optimization. In Proceedings of the International Conference on Learning Representations (ICLR), San Diego, CA, USA, 7–9 May 2015; pp. 1–13. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In Proceedings of the International Conference on Learning Representations (ICLR), San Diego, CA, USA, 7–9 May 2015; pp. 448–456. [Google Scholar]
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A simple way to prevent neural networks from overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- Vincent, E.; Gribonval, R.; Fevotte, C. Performance measurement in blind audio source separation. IEEE Trans. Audio Speech Lang. 2006, 14, 1462–1469. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Classification Accuracy (%) | Input Features | |
|---|---|---|
| Noisy LPS | Noisy LPS + Noise LPS | |
| Train dataset | 97.41 | 99.92 |
| Validation dataset | 94.55 | 99.64 |
| Comparing Methods | NC-DNN | CGBNN-5 |
|---|---|---|
| Model size | 1 | 0.65 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, L.; Wang, M.; Zhang, Q.; Liu, M. Environmental Attention-Guided Branchy Neural Network for Speech Enhancement. Appl. Sci. 2020, 10, 1167. https://doi.org/10.3390/app10031167
Zhang L, Wang M, Zhang Q, Liu M. Environmental Attention-Guided Branchy Neural Network for Speech Enhancement. Applied Sciences. 2020; 10(3):1167. https://doi.org/10.3390/app10031167
Chicago/Turabian StyleZhang, Lu, Mingjiang Wang, Qiquan Zhang, and Ming Liu. 2020. "Environmental Attention-Guided Branchy Neural Network for Speech Enhancement" Applied Sciences 10, no. 3: 1167. https://doi.org/10.3390/app10031167
APA StyleZhang, L., Wang, M., Zhang, Q., & Liu, M. (2020). Environmental Attention-Guided Branchy Neural Network for Speech Enhancement. Applied Sciences, 10(3), 1167. https://doi.org/10.3390/app10031167