CLEANIR: Controllable Attribute-Preserving Natural Identity Remover


Abstract
1. Introduction
- A network architecture that explicitly disentangle latent vector to parts of personal identity and facial attributes
- An end-to-end scheme that can effectively change appearance of faces while keeping important attributes
- Exhaustive experiments carried thoroughly to validate the proposed method
2. Related Work
2.1. Deep Generative Model
2.2. Face Swapping
2.3. Face De-Identification
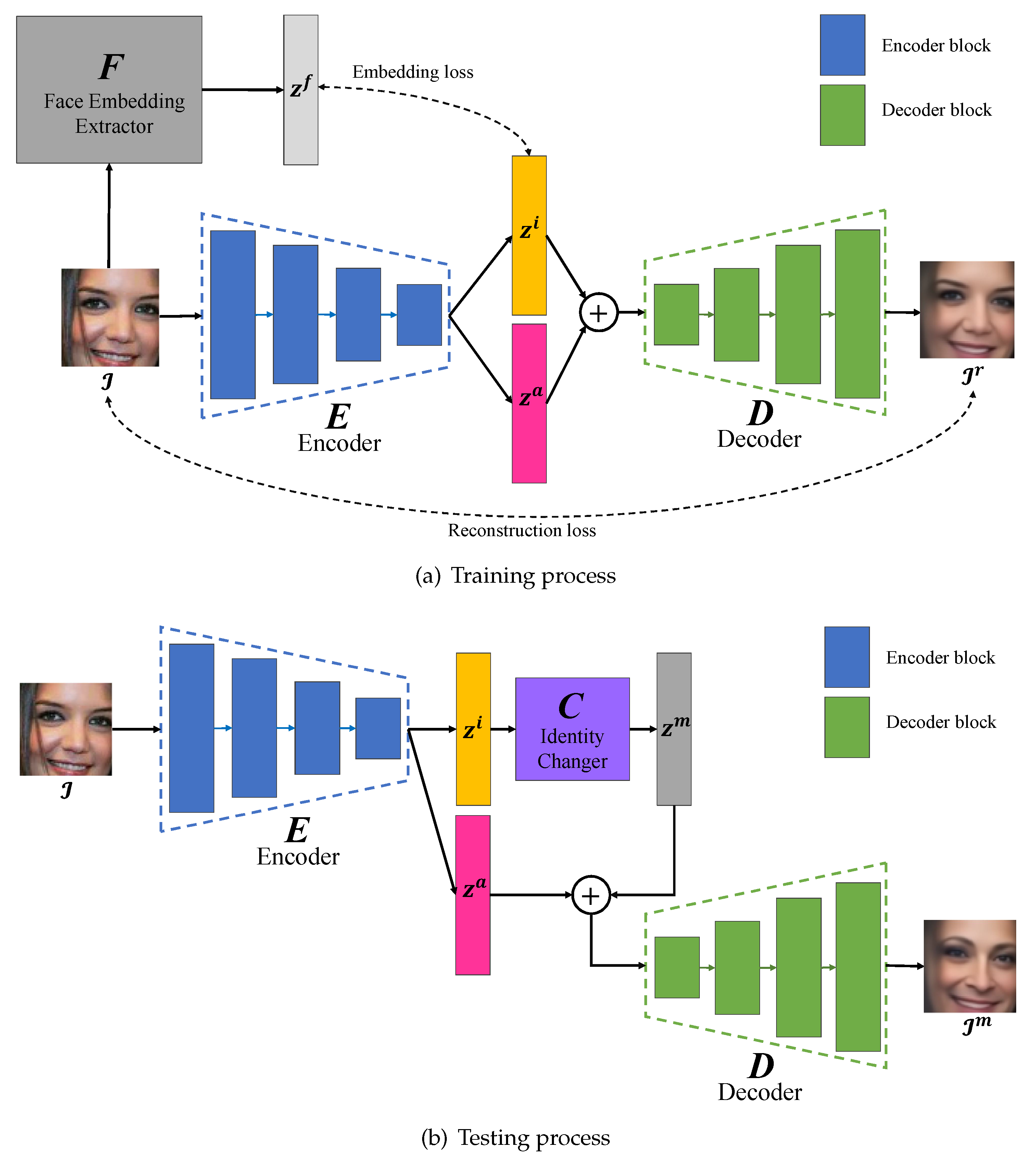
3. Proposed Method
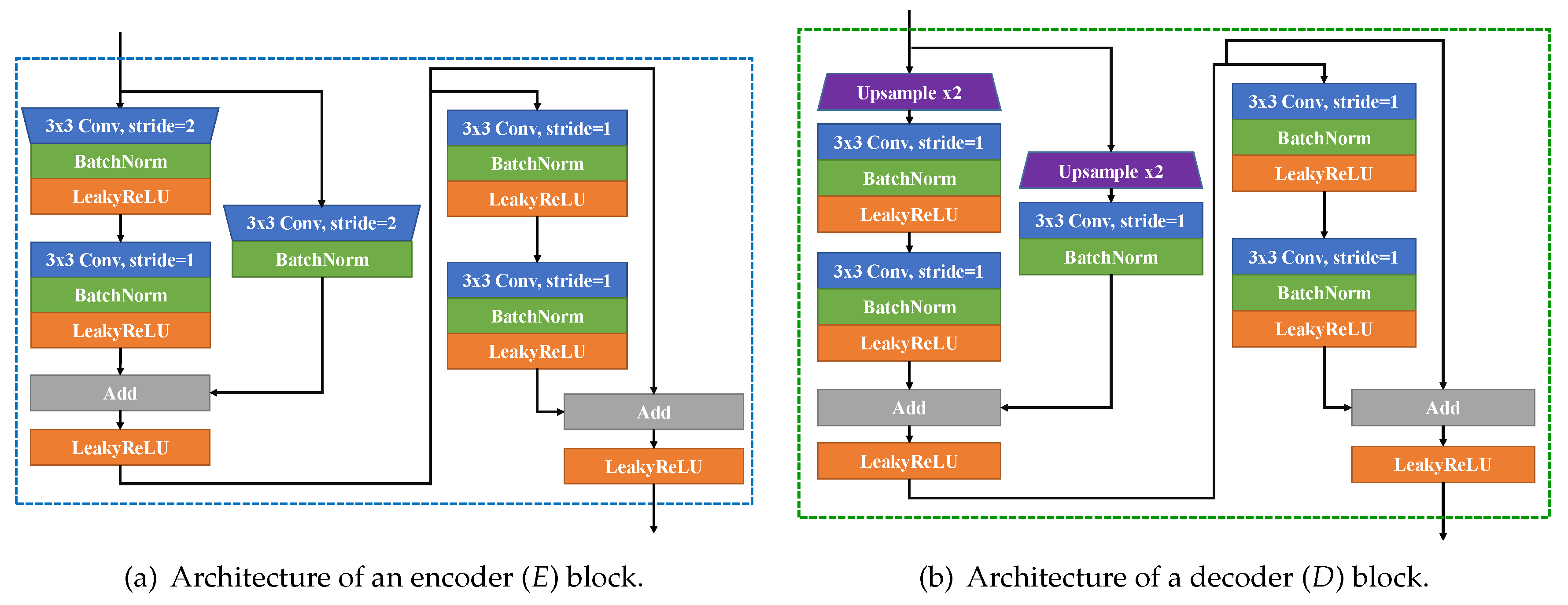
3.1. Network Architecture
3.2. Training Process
3.3. Testing Process
4. Experiments
4.1. Experimental Setup
4.2. Evaluation on De-Identification
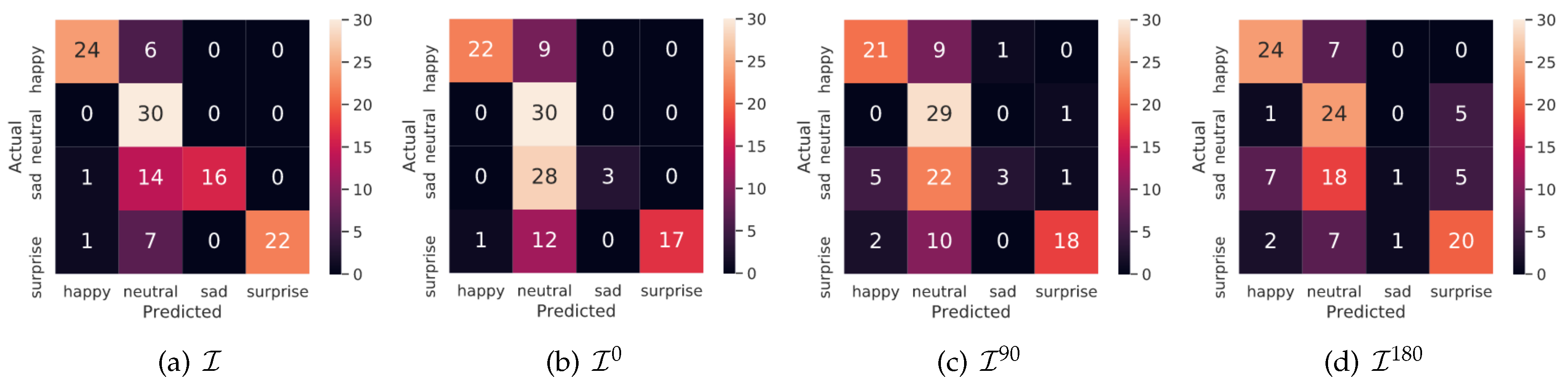
4.3. Evaluation on Preserving Facial Attributes
4.3.1. Qualitative Analysis
4.3.2. Quantitative Analysis
4.4. Qualitative Analysis on Videos
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Conflicts of Interest
References
- Neustaedter, C.; Greenberg, S. Balancing privacy and awareness in home media spaces. Workshop on Ubicomp Communities: Privacy as Boundary Negotiation. In Proceedings of the Conjunction with the 5th International Conference ON Ubiquitous Computing (UBICOMP), Seattle, WA, USA, 12–15 October 2003. [Google Scholar]
- Butler, D.J.; Huang, J.; Roesner, F.; Cakmak, M. The Privacy-Utility Tradeoff for Remotely Teleoperated Robots. In Proceedings of the Tenth Annual ACM/IEEE International Conference on Human-Robot Interaction, HRI ’15, Portland, OR, USA, 2–5 March 2015; ACM: New York, NY, USA, 2015; pp. 27–34. [Google Scholar] [CrossRef]
- Ryoo, M.; Rothrock, B.; Fleming, C.; Yang, H.J. Privacy-Preserving Human Activity Recognition from Extreme Low Resolution. In Proceedings of the AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017. [Google Scholar]
- Brooks, A.L. Subject Anonymisation in Video Reporting. Is Animation an option? In Proceedings of the 9th International Conference on Disability, Virtual Reality and Associated Technologies, Laval, France, 10–12 September 2012; Sharkey, P.M., Klinger, E., Eds.; University of Reading: Reading, UK, 2012; pp. 431–433. [Google Scholar]
- Ren, Z.; Lee, Y.J.; Ryoo, M.S. Learning to Anonymize Faces for Privacy Preserving Action Detection. arXiv 2018, arXiv:1803.11556. [Google Scholar]
- Chen, J.; Konrad, J.; Ishwar, P. VGAN-Based Image Representation Learning for Privacy-Preserving Facial Expression Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Wu, Y.; Yang, F.; Xu, Y.; Ling, H. Privacy-Protective-GAN for Privacy Preserving Face De-Identification. J. Comput. Sci. Technol. 2019, 34, 47–60. [Google Scholar] [CrossRef]
- Hukkelås, H.; Mester, R.; Lindseth, F. DeepPrivacy: A Generative Adversarial Network for Face Anonymization. arXiv 2019, arXiv:cs.CV/1909.04538. [Google Scholar]
- Li, T.; Lin, L. AnonymousNet: Natural Face De-Identification with Measurable Privacy. arXiv 2019, arXiv:cs.CV/1904.12620. [Google Scholar]
- Bitouk, D.; Kumar, N.; Dhillon, S.; Belhumeur, P.; Nayar, S.K. Face Swapping: Automatically Replacing Faces in Photographs. In ACM SIGGRAPH 2008 Papers; SIGGRAPH ’08; ACM: New York, NY, USA, 2008; pp. 39:1–39:8. [Google Scholar] [CrossRef]
- Vlasic, D.; Brand, M.; Pfister, H.; Popović, J. Face Transfer with Multilinear Models. In ACM SIGGRAPH 2005 Papers; SIGGRAPH ’05; ACM: New York, NY, USA, 2005; pp. 426–433. [Google Scholar] [CrossRef]
- Dale, K.; Sunkavalli, K.; Johnson, M.K.; Vlasic, D.; Matusik, W.; Pfister, H. Video Face Replacement. In Proceedings of the 2011 SIGGRAPH Asia Conference, SA ’11, Hong Kong, China, 11–16 December 2011; ACM: New York, NY, USA; pp. 130:1–130:10. [Google Scholar] [CrossRef]
- Korshunova, I.; Shi, W.; Dambre, J.; Theis, L. Fast Face-Swap Using Convolutional Neural Networks. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017. [Google Scholar]
- Kingma, D.P.; Welling, M. Auto-Encoding Variational Bayes. In Proceedings of the International Conference on Learning Representations, Banff, AB, Canada, 14–16 April 2014. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014; pp. 2672–2680. [Google Scholar]
- de Bem, R.; Ghosh, A.; Ajanthan, T.; Miksik, O.; Siddharth, N.; Torr, P. A semi-supervised deep generative model for human body analysis. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Kingma, D.P.; Mohamed, S.; Rezende, D.J.; Welling, M. Semi-supervised learning with deep generative models. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014; pp. 3581–3589. [Google Scholar]
- Siddharth, N.; Paige, B.; Van de Meent, J.W.; Desmaison, A.; Goodman, N.; Kohli, P.; Wood, F.; Torr, P. Learning disentangled representations with semi-supervised deep generative models. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 5925–5935. [Google Scholar]
- Gulrajani, I.; Ahmed, F.; Arjovsky, M.; Dumoulin, V.; Courville, A.C. Improved training of wasserstein gans. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 5767–5777. [Google Scholar]
- Mroueh, Y.; Sercu, T.; Goel, V. McGan: Mean and covariance feature matching GAN. In Proceedings of the 34th International Conference on Machine Learning-Volume 70. JMLR. org, Sydney, Australia, 6–11 August 2017; pp. 2527–2535. [Google Scholar]
- Karras, T.; Aila, T.; Laine, S.; Lehtinen, J. Progressive growing of gans for improved quality, stability, and variation. arXiv 2017, arXiv:1710.10196. [Google Scholar]
- Sohn, K.; Lee, H.; Yan, X. Learning structured output representation using deep conditional generative models. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015; pp. 3483–3491. [Google Scholar]
- Mirza, M.; Osindero, S. Conditional generative adversarial nets. arXiv 2014, arXiv:1411.1784. [Google Scholar]
- Odena, A.; Olah, C.; Shlens, J. Conditional Image Synthesis with Auxiliary Classifier GANs. In Proceedings of the 34th International Conference on Machine Learning-Volume 70. JMLE. org, Sydney, Australia, 6–11 August 2017; pp. 2642–2651. [Google Scholar]
- Yan, X.; Yang, J.; Sohn, K.; Lee, H. Attribute2Image: Conditional Image Generation from Visual Attributes. In Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2016; pp. 776–791. [Google Scholar]
- Reed, S.; Akata, Z.; Yan, X.; Logeswaran, L.; Schiele, B.; Lee, H. Generative Adversarial Text to Image Synthesis. In Proceedings of the 33rd International Conference on International Conference on Machine Learning, ICML’16, New York, NY, USA, 19–24 June 2016; Volume 48, pp. 1060–1069. [Google Scholar]
- Walker, J.; Doersch, C.; Gupta, A.; Hebert, M. An Uncertain Future: Forecasting from Static Images Using Variational Autoencoders. In Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2016; pp. 835–851. [Google Scholar]
- Zheng, Z.; Yang, X.; Yu, Z.; Zheng, L.; Yang, Y.; Kautz, J. Joint Discriminative and Generative Learning for Person Re-Identification. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019. [Google Scholar] [CrossRef]
- Larsen, A.B.L.; Sønderby, S.K.; Larochelle, H.; Winther, O. Autoencoding beyond pixels using a learned similarity metric. In Proceedings of the International Conference on Machine Learning, New York, NY, USA, 19–24 June 2016; pp. 1558–1566. [Google Scholar]
- Bao, J.; Chen, D.; Wen, F.; Li, H.; Hua, G. CVAE-GAN: Fine-grained image generation through asymmetric training. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2745–2754. [Google Scholar]
- Blanz, V.; Romdhani, S.; Vetter, T. Face identification across different poses and illuminations with a 3d morphable model. In Proceedings of the Fifth IEEE International Conference on Automatic Face Gesture Recognition, Washington, DC, USA, 20–21 May 2002; pp. 202–207. [Google Scholar]
- Blanz, V.; Vetter, T. Face recognition based on fitting a 3d morphable model. IEEE Trans. Pattern Anal. Mach. Intell. 2003, 25, 1063–1074. [Google Scholar] [CrossRef]
- Korshunova, I.; Shi, W.; Dambre, J.; Theis, L. Fast Face-swap Using Convolutional Neural Networks. arXiv 2016, arXiv:1611.09577. [Google Scholar]
- Nirkin, Y.; Masi, I.; Tran Tuan, A.; Hassner, T.; Medioni, G. On Face Segmentation, Face Swapping, and Face Perception. In Proceedings of the 2018 13th IEEE International Conference on Automatic Face & Gesture Recognition (FG 2018), Xi’an, China, 15–19 May 2018. [Google Scholar] [CrossRef]
- Natsume, R.; Yatagawa, T.; Morishima, S. RSGAN: Face Swapping and Editing using Face and Hair Representation in Latent Spaces. In ACM SIGGRAPH 2018 Posters on—SIGGRAPH ’18; Association for Computing Machinery: New York, NY, USA, 2018. [Google Scholar] [CrossRef]
- Natsume, R.; Yatagawa, T.; Morishima, S. FSNet: An Identity-Aware Generative Model for Image-Based Face Swapping. In Computer Vision—ACCV 2018; Jawahar, C., Li, H., Mori, G., Schindler, K., Eds.; Springer International Publishing: Cham, Switzerland, 2019; pp. 117–132. [Google Scholar]
- Nirkin, Y.; Keller, Y.; Hassner, T. FSGAN: Subject Agnostic Face Swapping and Reenactment. arXiv 2019, arXiv:cs.CV/1908.05932. [Google Scholar]
- Blanz, V.; Scherbaum, K.; Vetter, T.; Seidel, H.P. Exchanging faces in images. In Computer Graphics Forum; Wiley Online Library: Hoboken, NJ, USA, 2004; Volume 23, pp. 669–676. [Google Scholar]
- Lin, Y.; Wang, S.; Lin, Q.; Tang, F. Face swapping under large pose variations: A 3D model based approach. In Proceedings of the 2012 IEEE International Conference on Multimedia and Expo, Melbourne, VIC, Australia, 9–13 July 2012; pp. 333–338. [Google Scholar]
- Mosaddegh, S.; Simon, L.; Jurie, F. Photorealistic Face De-Identification by Aggregating Donors’ Face Components. Computer Vision—ACCV 2014; Cremers, D., Reid, I., Saito, H., Yang, M.H., Eds.; Springer International Publishing: Cham, Switzerland, 2015; pp. 159–174. [Google Scholar]
- Ribaric, S.; Ariyaeeinia, A.; Pavesic, N. De-identification for privacy protection in multimedia content: A survey. Signal Process. Image Commun. 2016, 47, 131–151. [Google Scholar] [CrossRef]
- Sweeney, L. k-ANONYMITY: A MODEL FOR PROTECTING PRIVACY. Int. J. Uncertain. Fuzziness Knowl.-Based Syst. 2002, 10, 557–570. [Google Scholar] [CrossRef]
- Newton, E.M.; Sweeney, L.; Malin, B. Preserving privacy by de-identifying face images. IEEE Trans. Knowl. Data Eng. 2005, 17, 232–243. [Google Scholar] [CrossRef]
- Gross, R.; Airoldi, E.; Malin, B.; Sweeney, L. Integrating Utility into Face De-identification. In Privacy Enhancing Technologies; Danezis, G., Martin, D., Eds.; Springer: Berlin/Heidelberg, Germany, 2006; pp. 227–242. [Google Scholar]
- Gross, R.; Sweeney, L.; de la Torre, F.; Baker, S. Model-Based Face De-Identification. In Proceeding of the 2006 Conference on Computer Vision and Pattern Recognition Workshop (CVPRW’06), New York, NY, USA, 17–22 June 2006; p. 161. [Google Scholar] [CrossRef]
- Cootes, T.F.; Edwards, G.J.; Taylor, C.J. Active appearance models. IEEE Trans. Pattern Anal. Mach. Intell. 2001, 23, 681–685. [Google Scholar] [CrossRef]
- Du, L.; Yi, M.; Blasch, E.; Ling, H. GARP-face: Balancing privacy protection and utility preservation in face de-identification. In Proceedings of the IEEE International Joint Conference on Biometrics, Clearwater, FL, USA, 29 September–2 October 2014; pp. 1–8. [Google Scholar] [CrossRef]
- Jourabloo, A.; Yin, X.; Liu, X. Attribute preserved face de-identification. In Proceedings of the 2015 International Conference on Biometrics (ICB), Phuket, Thailand, 19–22 May 2015; pp. 278–285. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016. [Google Scholar]
- Fausto Morales. Keras-facenet. 2019. Available online: https://github.com/faustomorales/keras-facenet (accessed on 18 November 2019).
- Schroff, F.; Kalenichenko, D.; Philbin, J. FaceNet: A unified embedding for face recognition and clustering. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 815–823. [Google Scholar] [CrossRef]
- Szegedy, C.; Ioffe, S.; Vanhoucke, V. Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning. arXiv 2016, arXiv:1602.07261. [Google Scholar]
- Cao, Q.; Shen, L.; Xie, W.; Parkhi, O.M.; Zisserman, A. VGGFace2: A dataset for recognising faces across pose and age. In Proceedings of the International Conference on Automatic Face and Gesture Recognition, Xi’an, China, 15–19 May 2018. [Google Scholar]
- King, D.E. Max-margin object detection. arXiv 2015, arXiv:1502.00046. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. In Proceedings of the 3rd International Conference on Learning Representations, ICLR 2015, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Huang, G.B.; Mattar, M.; Lee, H.; Learned-Miller, E. Learning to Align from Scratch. In Proceedings of the Advances in Neural Information Processing Systems, Lake Tahoe, NV, USA, 3–8 December 2012. [Google Scholar]
- Huang, G.B.; Ramesh, M.; Berg, T.; Learned-Miller, E. Labeled Faces in the Wild: A Database for Studying Face Recognition in Unconstrained Environments; Technical Report 07-49; University of Massachusetts: Amherst, MA, USA, 2007. [Google Scholar]
- Learned-Miller, G.B.H.E. Labeled Faces in the Wild: Updates and New Reporting Procedures; Technical Report UM-CS-2014-003; University of Massachusetts: Amherst, MA, USA, 2014. [Google Scholar]
- Lyons, M.; Akamatsu, S.; Kamachi, M.; Gyoba, J. Coding facial expressions with Gabor wavelets. In Proceedings of the Third IEEE International Conference on Automatic Face and Gesture Recognition, Nara, Japan, 14–16 April 1998; pp. 200–205. [Google Scholar] [CrossRef]
- Microsoft. Azure Cognitive Services Face API. 2019. Available online: https://azure.microsoft.com/en-us/services/cognitive-services/face (accessed on 18 November 2019).
- Aifanti, N.; Papachristou, C.; Delopoulos, A. The MUG facial expression database. In Proceedings of the 11th International Workshop on Image Analysis for Multimedia Interactive Services WIAMIS 10, Desenzano del Garda, Italy, 12–14 April 2010; pp. 1–4. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Name | Operations | Input | Output Size |
|---|---|---|---|
| Enc0 | 7x7 Conv(stride=2)-BN-LReLU | Input image | 32 × 32 × 64 |
| EncBlock1_1 | 3x3 Conv(stride=2)-BN-LReLU- 3x3 Conv(stride=1)-BN-LReLU | Enc0 | 16 × 16 × 64 |
| EncBlock1_2 | 3x3 Conv(stride=2)-BN | Enc0 | 16 × 16 × 64 |
| EncBlock1_3 | Add-LReLU | EncBlock1_1, EncBlock1_2 | 16 × 16 × 64 |
| EncBlock1_4 | { 3x3 Conv(stride=1)-BN-LReLU } x2 | EncBlock1_3 | 16 × 16 × 64 |
| EncBlock1_5 | Add-LReLU | EncBlock1_3, EncBlock1_4 | 16 × 16 × 64 |
| EncBlock2_1 | 3x3 Conv(stride=2)-BN-LReLU- 3x3 Conv(stride=1)-BN-LReLU | EncBlock1_5 | 8 × 8 × 128 |
| EncBlock2_2 | 3x3 Conv(stride=2)-BN | EncBlock1_5 | 8 × 8 × 128 |
| EncBlock2_3 | Add-LReLU | EncBlock2_1, EncBlock2_2 | 8 × 8 × 128 |
| EncBlock2_4 | { 3x3 Conv(stride=1)-BN-LReLU } x2 | EncBlock2_3 | 8 × 8 × 128 |
| EncBlock2_5 | Add-LReLU | EncBlock2_3, EncBlock2_4 | 8 × 8 × 128 |
| EncBlock3_1 | 3x3 Conv(stride=2)-BN-LReLU- 3x3 Conv(stride=1)-BN-LReLU | EncBlock2_5 | 4 × 4 × 192 |
| EncBlock3_2 | 3x3 Conv(stride=2)-BN | EncBlock2_5 | 4 × 4 × 192 |
| EncBlock3_3 | Add-LReLU | EncBlock3_1, EncBlock3_2 | 4 × 4 × 192 |
| EncBlock3_4 | { 3x3 Conv(stride=1)-BN-LReLU } x2 | EncBlock3_3 | 4 × 4 × 192 |
| EncBlock3_5 | Add-LReLU | EncBlock3_3, EncBlock3_4 | 4 × 4 × 192 |
| EncBlock4_1 | 3x3 Conv(stride=2)-BN-LReLU- 3x3 Conv(stride=1)-BN-LReLU | EncBlock3_5 | 2 × 2 × 256 |
| EncBlock4_2 | 3x3 Conv(stride=2)-BN | EncBlock3_5 | 2 × 2 × 256 |
| EncBlock4_3 | Add-LReLU | EncBlock4_1, EncBlock4_2 | 2 × 2 × 256 |
| EncBlock4_4 | { 3x3 Conv(stride=1)-BN-LReLU } x2 | EncBlock4_3 | 2 × 2 × 256 |
| EncBlock4_5 | Add-LReLU | EncBlock4_3, EncBlock4_4 | 2 × 2 × 256 |
| EncL | 3x3 AvgPool-FC-LReLU-BN | EncBlock4_5 | 1 × 1024 |
| Dec0 | FC-Reshape-LReLU | EncL | 4 × 4 × 512 |
| DecBlock1_1 | Upsample- { 3x3 Conv(stride=1)-BN-LReLU } x2 | Dec0 | 8 × 8 × 256 |
| DecBlock1_2 | Upsample-3x3 Conv(stride=1)-BN | Dec0 | 8 × 8 × 256 |
| DecBlock1_3 | Add-LReLU | DecBlock1_1, DecBlock1_2 | 8 × 8 × 256 |
| DecBlock1_4 | { 3x3 Conv(stride=1)-BN-LReLU } x2 | DecBlock1_3 | 8 × 8 × 256 |
| DecBlock1_5 | Add-LReLU | DecBlock1_3, DecBlock1_4 | 8 × 8 × 256 |
| DecBlock2_1 | Upsample- { 3x3 Conv(stride=1)-BN-LReLU } x2 | DecBlock1_5 | 16 × 16 × 128 |
| DecBlock2_2 | Upsample-3x3 Conv(stride=1)-BN | DecBlock1_5 | 16 × 16 × 128 |
| DecBlock2_3 | Add-LReLU | DecBlock2_1, DecBlock2_2 | 16 × 16 × 128 |
| DecBlock2_4 | { 3x3 Conv(stride=1)-BN-LReLU } x2 | DecBlock2_3 | 16 × 16 × 128 |
| DecBlock2_5 | Add-LReLU | DecBlock2_3, DecBlock2_4 | 16 × 16 × 128 |
| DecBlock3_1 | Upsample- { 3x3 Conv(stride=1)-BN-LReLU } x2 | DecBlock2_5 | 32 × 32 × 64 |
| DecBlock3_2 | Upsample-3x3 Conv(stride=1)-BN | DecBlock2_5 | 32 × 32 × 64 |
| DecBlock3_3 | Add-LReLU | DecBlock3_1, DecBlock3_2 | 32 × 32 × 64 |
| DecBlock3_4 | { 3x3 Conv(stride=1)-BN-LReLU } x2 | DecBlock3_3 | 32 × 32 × 64 |
| DecBlock3_5 | Add-LReLU | DecBlock3_3, DecBlock3_4 | 32 × 32 × 64 |
| DecBlock4_1 | Upsample- { 3x3 Conv(stride=1)-BN-LReLU } x2 | DecBlock3_5 | 64 × 64 × 32 |
| DecBlock4_2 | Upsample-3x3 Conv(stride=1)-BN | DecBlock3_5 | 64 × 64 × 32 |
| DecBlock4_3 | Add-LReLU | DecBlock4_1, DecBlock4_2 | 64 × 64 × 32 |
| DecBlock4_4 | { 3x3 Conv(stride=1)-BN-LReLU } x2 | DecBlock4_3 | 64 × 64 × 32 |
| DecBlock4_5 | Add-LReLU | DecBlock4_3, DecBlock4_4 | 64 × 64 × 32 |
| DecL | LReLU-3x3 Conv(stride=1) | DecBlock4_5 | 64 × 64 × 3 |
| Matching Rate | ||||||||
|---|---|---|---|---|---|---|---|---|
| 0.1 | 0.017 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 |
| 0.2 | 0.215 | 0.014 | 0.009 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 |
| 0.3 | 0.524 | 0.109 | 0.085 | 0.014 | 0.000 | 0.000 | 0.000 | 0.000 |
| 0.4 | 0.763 | 0.342 | 0.290 | 0.097 | 0.002 | 0.000 | 0.000 | 0.000 |
| 0.5 | 0.905 | 0.608 | 0.565 | 0.309 | 0.019 | 0.001 | 0.000 | 0.000 |
| 0.6 | 0.963 | 0.797 | 0.767 | 0.585 | 0.081 | 0.001 | 0.000 | 0.000 |
| 0.7 | 0.984 | 0.913 | 0.900 | 0.788 | 0.224 | 0.011 | 0.002 | 0.001 |
| 0.8 | 0.990 | 0.964 | 0.959 | 0.916 | 0.452 | 0.050 | 0.007 | 0.005 |
| 0.9 | 0.994 | 0.986 | 0.986 | 0.972 | 0.704 | 0.131 | 0.030 | 0.019 |
| 1.0 | 0.998 | 0.995 | 0.995 | 0.991 | 0.880 | 0.280 | 0.093 | 0.061 |
| 1.1 | 0.998 | 0.998 | 0.998 | 0.997 | 0.965 | 0.507 | 0.219 | 0.161 |
| 1.2 | 0.999 | 0.999 | 1.000 | 1.000 | 0.990 | 0.731 | 0.409 | 0.343 |
| 1.3 | 1.000 | 1.000 | 1.000 | 1.000 | 0.999 | 0.899 | 0.657 | 0.577 |
| 1.4 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 0.978 | 0.843 | 0.784 |
| 1.5 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 0.995 | 0.964 | 0.935 |
| 1.6 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 0.996 | 0.992 |
| 1.7 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cho, D.; Lee, J.H.; Suh, I.H. CLEANIR: Controllable Attribute-Preserving Natural Identity Remover. Appl. Sci. 2020, 10, 1120. https://doi.org/10.3390/app10031120
Cho D, Lee JH, Suh IH. CLEANIR: Controllable Attribute-Preserving Natural Identity Remover. Applied Sciences. 2020; 10(3):1120. https://doi.org/10.3390/app10031120
Chicago/Turabian StyleCho, Durkhyun, Jin Han Lee, and Il Hong Suh. 2020. "CLEANIR: Controllable Attribute-Preserving Natural Identity Remover" Applied Sciences 10, no. 3: 1120. https://doi.org/10.3390/app10031120
APA StyleCho, D., Lee, J. H., & Suh, I. H. (2020). CLEANIR: Controllable Attribute-Preserving Natural Identity Remover. Applied Sciences, 10(3), 1120. https://doi.org/10.3390/app10031120