This section is organized into three parts. First, a general description of the dataset is provided. The datasets are mainly based on geographic distribution across Taiwan. The second part discusses the detailed development of AQI prediction models following their parameter setting and imputation. The last part evaluates the performance of the AQI forecasting models.
4.1. Data Summary
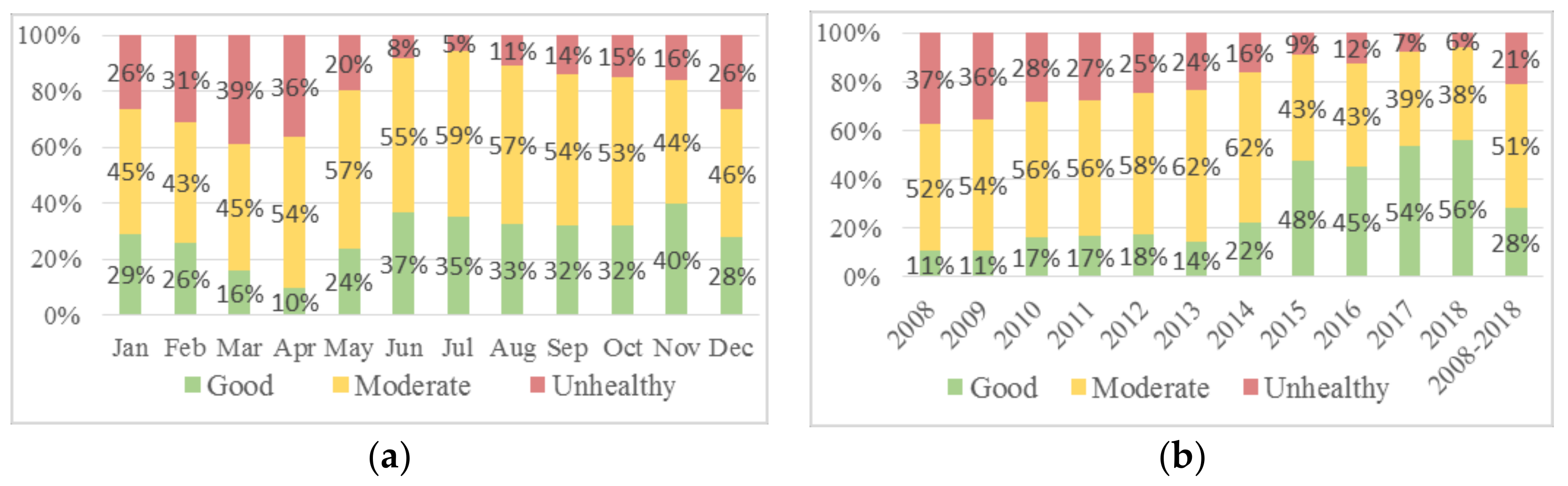
In the Zhongli dataset, moderate is the most frequent AQI level in any given month (
Figure 5a).
Unhealthy occurs more frequently in December through April, indicating that peak pollution usually occurs in winter and spring. The year-based grouping (
Figure 5b) clearly shows a general drop in pollution levels from 2014 to 2018, with a small uptick in 2016. In general, the moderate class accounts for 51% cases while good and unhealthy, respectively, account for 28% and 21%.
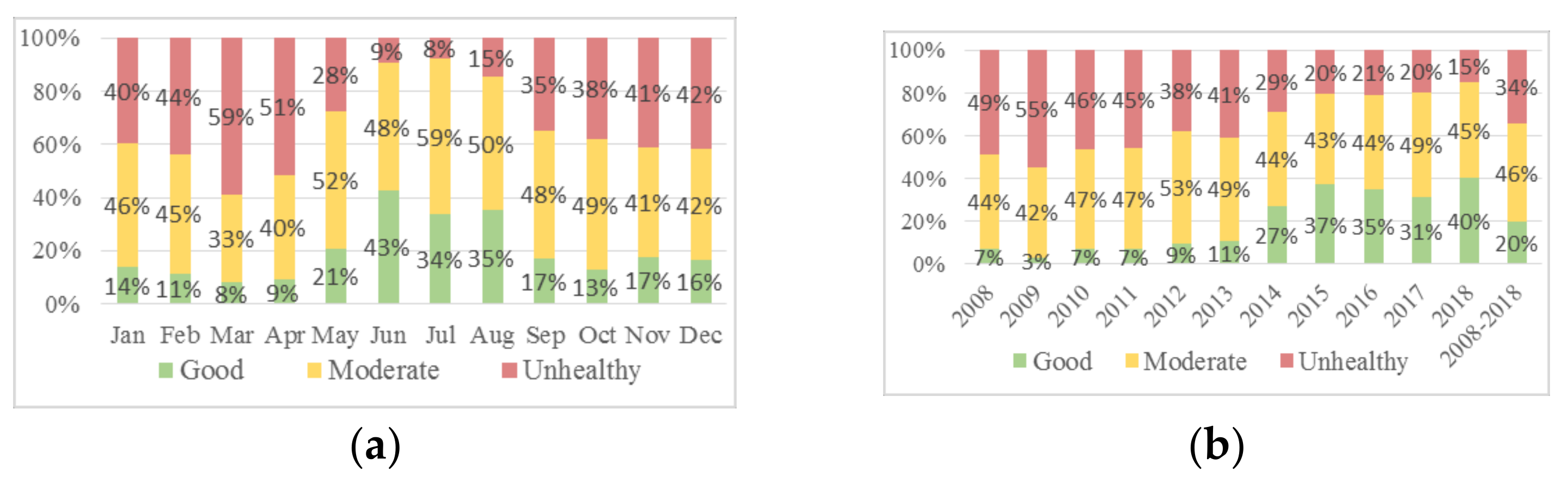
Similar to the Zhongli AQI pattern, pollution in Changhua peaks in March (
Figure 6a). However, the degree of air pollution is more severe in Changhua, with unhealthy accounting for 59% of March readings, as opposed to 39% for Zhongli. Like Zhongli, higher AQI levels in Changhua are also clustered in winter and spring, but September, October, and November also featured significant instances of the unhealthy class (respectively 35%, 38%, and 41%). In general, Changhua has poorer air quality than Zhongli, with more frequent AQI > 100 incidents both monthly and annually. However, the full-year AQI readings in
Figure 6b show that air quality has gradually improved over time, with a 34% drop in instances of unhealthy from 2008 to 2018.
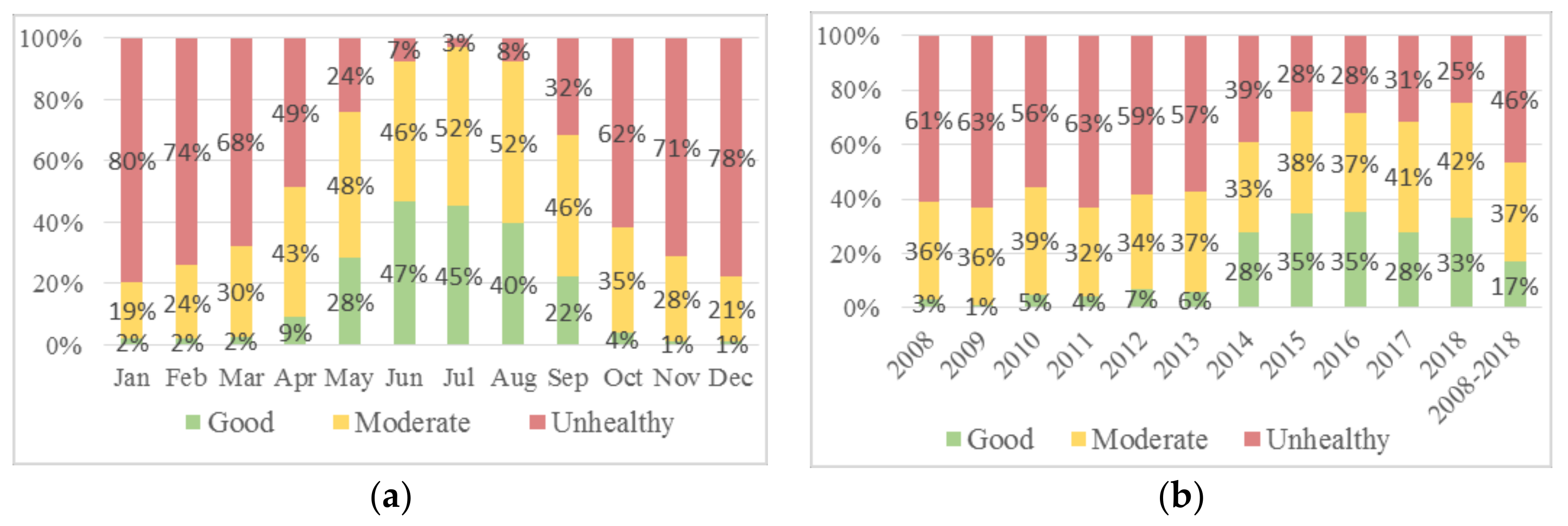
Southern Taiwan, especially Kaohsiung City, is notorious for its poor air quality due not only to emissions from nearby industrial parks but from particulate matter blowing in from China and Southeast Asia.
Figure 7a,b shows significant instances of the unhealthy class (red bars) air quality for most of the year, with reduced pollution levels only in May to September. The worst air quality is concentrated in December and January (respectively 78% and 80% unhealthy).
The winter spike in air pollution is partly due to seasonal atmospheric phenomena that trap air pollution closer to the ground for extended periods. From October to March, Fengshan air quality readings are good less than 5% of the time. In terms of year-based AQI class composition, not much improvement is seen until in 2014–2015 with a sharply declined unhealthy scores after which levels remain relatively stable. Overall, for the 11 years, the Fengshan dataset is dominated by AQI 100 (46%) followed by 51 AQI 100 (37%), and AQI 50 (17%).
4.2. AQI Prediction Model
Table 3 specifies the design of the parameters used to generate the prediction models for all dataset (Zhongli, Changhua, and Fengshan). Note that each particular constant for each dataset supposedly contains three values. However, to ease the documentation, any similar value being used across all datasets or at least across different time steps will be written only once. For example, Changhua dataset which uses the number of trees (i.e., 100) in AdaBoost for all time step categories. Additionally, parameter
m in the random forest has only one value in all models. To be able to evaluate the ability of each model in accomplishing the task, 80% of data points will be fed into each training process, while the remaining 20% are spared for the testing purpose.
Table 4 describes the evaluation results of Zhongli F1-AQI prediction using 5 methods with and without imputation. It can be inferred that machine learning algorithms performed very well in predicting future AQI levels in Zhongli for the following hour. The linear kernel is shown to be the best input transformation technique for SVM, with
R2 results of 0.953 (without imputation) and 0.963 (with imputation). Imputation allows SVM to produce improvement in all evaluation metrics. Furthermore, in terms of MAE score, SVM-RBF outperforms SVM-Linear, but the opposite is true for the RMSE score. This may be due to RBF having more samples with a larger prediction error despite a smaller average error (larger errors produce a greater penalty for RMSE).
The performance of random forest, AdaBoost, ANN, and stacking ensemble algorithm are all comparable. Random forest and stacking ensemble algorithm obtain slightly better R2 performance (0.001). Unlike with SVM, imputation does not affect the prediction results for AdaBoost, random forest or the stacking ensemble algorithm, indicating their robustness to missing data. On the other hand, imputation only provides a small degree of improvement on ANN, resulting in tied R2 values with AdaBoost. Several loss regression functions (square, linear, exponential) are tested on AdaBoost but without a decisive performance outcome due to efforts to avoid bias since the interpretation could be distorted by randomness, especially given very minor degrees of difference.
Table 5 summarizes the results for the 8-h Zhongli AQI prediction. The
R2 value of 0.764 is the best value obtained by the stacking ensemble method. Nonetheless, the performance of SVM becomes worse with an
R2 value less than 0.6 across all kernels. The values of MAE and RMSE are 17 and 23, respectively. However, ANN and random forest perform better than SVM, with
R2 scores exceeding 0.7 and error metrics just slightly lower than those obtained with AdaBoost and stacking ensemble. The results match the expectation since the uncertainty increases with the longer period and leads to higher difficulty in the forecast. The study also finds that the overall values are worse than that of the F1-AQI prediction.
Table 6 shows that no method used for targeting F24-AQI prediction produced an
R2 score above 0.6, with the lowest score of 0.091. Simply put, the yielded predictions fit the dataset poorly. Stacking ensemble still ranks first, but the
R2 gap to the second-best method (AdaBoost-Linear) is larger than in the previous cases. SVM performance tracked far behind the other methods with the highest score for evaluation metrics obtained by RBF kernel. However, the
R2 score is so low that the SVM method is considered not preferable for 24-h prediction.
Predictive model results for F1-AQI Changhua are similar to those for F1-AQI Zhongli. Stacking ensemble, AdaBoost, and random forest provide the best performance for one-hour AQI level prediction (see
Table 7). These algorithms perform better for all evaluation metrics in Changhua than in Zhongli. Also, the imputation process reduces the performance of SVM, but not the other algorithms.
When it comes to the F8-AQI prediction (as shown in
Table 8), the Changhua prediction again outperforms that of Zhongli. AdaBoost and stacking ensemble both yield
R2 scores exceeding 0.8. Without imputation, stacking ensemble outperforms the other methods. However, with imputation, AdaBoost performance is comparable to that of stacking ensemble. SVM-linear gives the highest MAE and RMSE results, i.e., 23.412 and 31.189, respectively. These error metrics can be further reduced to 19.623 and 25.628 by imputation.
In the Zhongli dataset, the time step selection affects the performance of machine learning methods, and this is consistent with the results for the F24-AQI prediction models in Changhua (
Table 9). Declination occurs across all models with a very low
R2. The SVM-Polynomial gives the worst performance for the imputed dataset and an MAE value exceeding 30, and an RMSE value exceeding 40. The best performance is still obtained by the stacking ensemble method, with an
R2 score of 0.605, and MAE and RMSE values respectively below 19 and 26. Among all kernels used by SVM, the radial basis function appears to be the most effective for 24-h AQI predictions. Moreover, AdaBoost-exponential slightly underperforms stacking ensemble in terms of
R2 and RMSE, but consistently provides better MAE results.
Table 10 summarizes the results for the one-hour prediction model without and with
k-NN imputation step in the Fengshan dataset. Stacking ensemble learning outperforms other techniques in terms of RMSE and
R2, while SVM obtains the worst performance in every prediction case. However, imputation slightly enhances the results, particularly for the RBF and linear kernels, but not for the polynomial kernel which shows a performance decline using the imputed dataset. Also note that while comparing with the results in the other two cities, Zhongli and Changhua, Fengshan shows the best performance in all evaluation measures.
In terms of eight-hour prediction, imputation has a significant impact on SVM-Linear, increasing
R2 from 0.318 to 0.546 (as shown in
Table 11). RMSE and MAE are also improved by 10% and shift closer to the performance of other SVM kernels. Of the three locations, application of machine learning algorithms has the biggest impact on 8-h predictions in Fengshan, with stacking ensemble providing the greatest improvement, followed by AdaBoost, random forest, ANN, and SVM. This sequence is consistent for all results.
As summarized in
Table 12, for the 24-h predictions in Fengshan, while overall SVM results are not promising, the other methods show quite acceptable evaluation scores. The top three methods (stacking ensemble, AdaBoost, and random forest) obtained
R2 scores exceeding 0.71 for which the MAE and RMSE results are comparable to the F8-AQI prediction for Fengshan. Surprisingly, the stacking ensemble is found to be affected by imputation but, even with imputation, the MAE value is still higher than that of all AdaBoost versions (linear, square, and exponential). AdaBoost and stacking ensemble show consistent results, and AdaBoost generally obtains worse RMSE and
R2 but better MAE.
4.3. Implementation of AQI Forecasting Model
This section describes a simulation-like AQI forecasting using stacking ensemble and AdaBoost (the two best methods from the analyses in
Section 4.2) as backend techniques. Each prediction is accompanied by a prediction interval (PI) within a 95% confidence level, which describes a given tolerance for the prediction value such that there is 95% chance that the actual observation could fall within this range. The prediction interval is calculated using the formula below [
21]:
where
represents the standard deviation of the residual errors defined as [
22]:
Prediction intervals that reflect the uncertainty of a model’s output should be adjusted dynamically as new observations are received every hour, thus ensuring that the prediction interval is always current. The one-month samples (December 2018) from the Zhongli dataset are used to obtain the standard deviation.
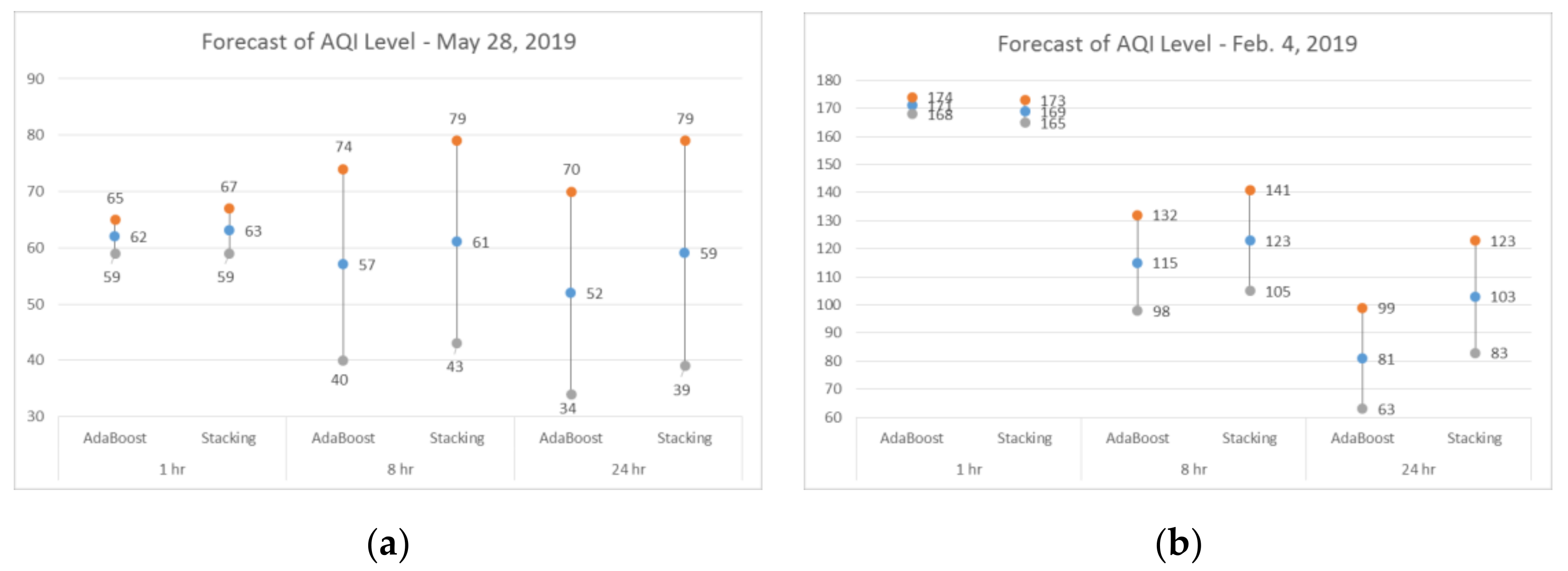
As shown in
Figure 8a, the higher the prediction time step, the wider the tolerance needed to represent the estimation. AdaBoost and stacking ensemble outperform the other techniques tested in the previous section, obtaining similar predictions and prediction intervals. The predictions here are all based on authentic data, where the best models in each prediction category are reused.
Figure 8b shows another forecast constructed during winter, providing an example of poor air quality cases captured in the prediction of F1-AQI, F8-AQI, and F24-AQI using AdaBoost and stacking ensemble.
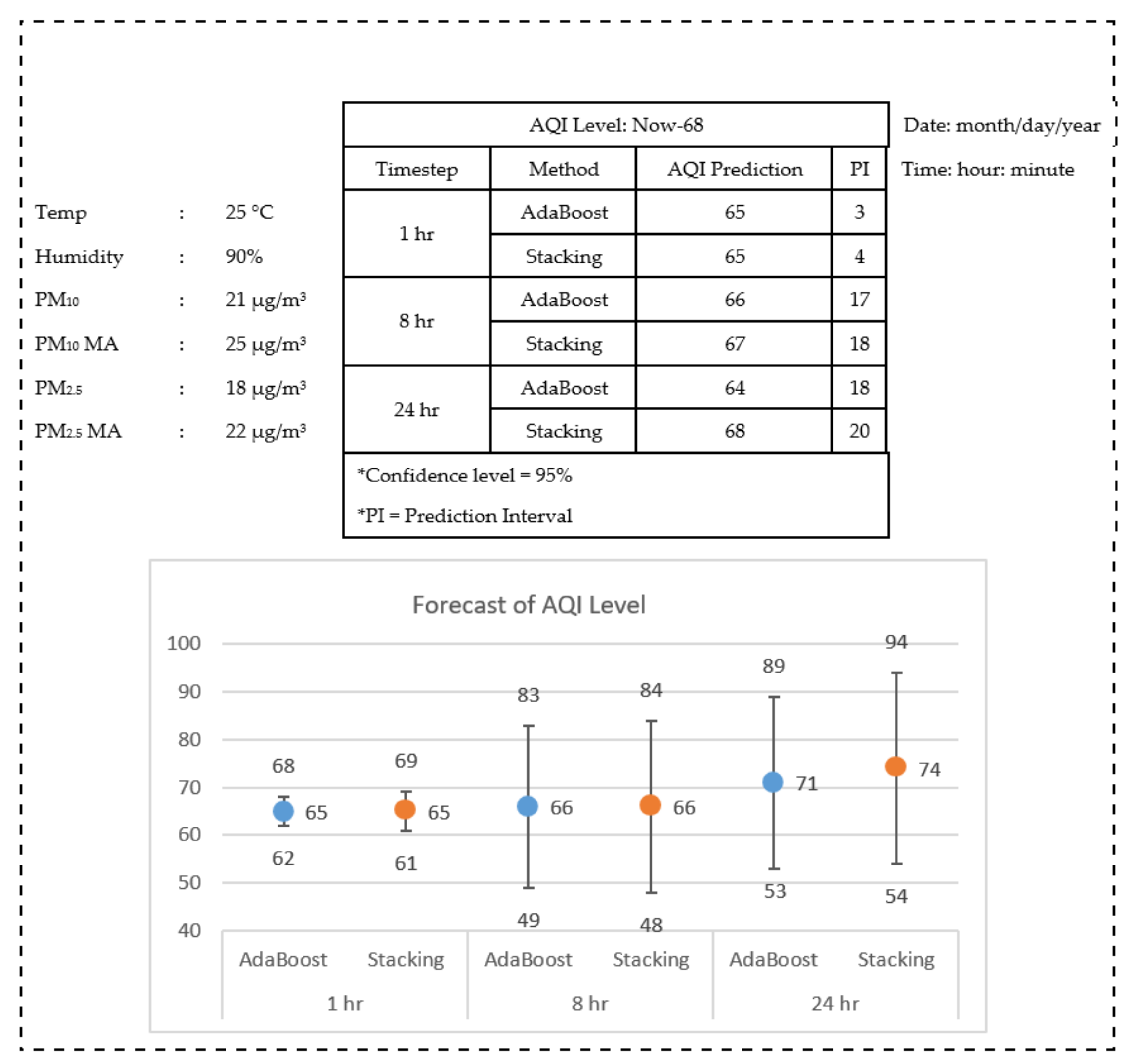
Figure 9 provides an illustration on how the information will be provided and visualized given a sample of upcoming data for the monitoring and forecasting of the air quality. Noted that as shown by the graph, the higher the time step of prediction the wider the tolerance needed to escort the estimation. AdaBoost and stacking are two methods that outperform other techniques tested in the previous section. Their predictions are close to each other and so are the prediction intervals. The predictions here are based on the real scheme, where the best models of them in each category of prediction were reused again by incorporating the actual values from 24 features.

 and
and 









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}