Ext-LOUDS: A Space Efficient Extended LOUDS Index for Superset Query




Abstract
1. Introduction
2. Problem Definition and Necessary Preliminaries
2.1. Set Superset Query
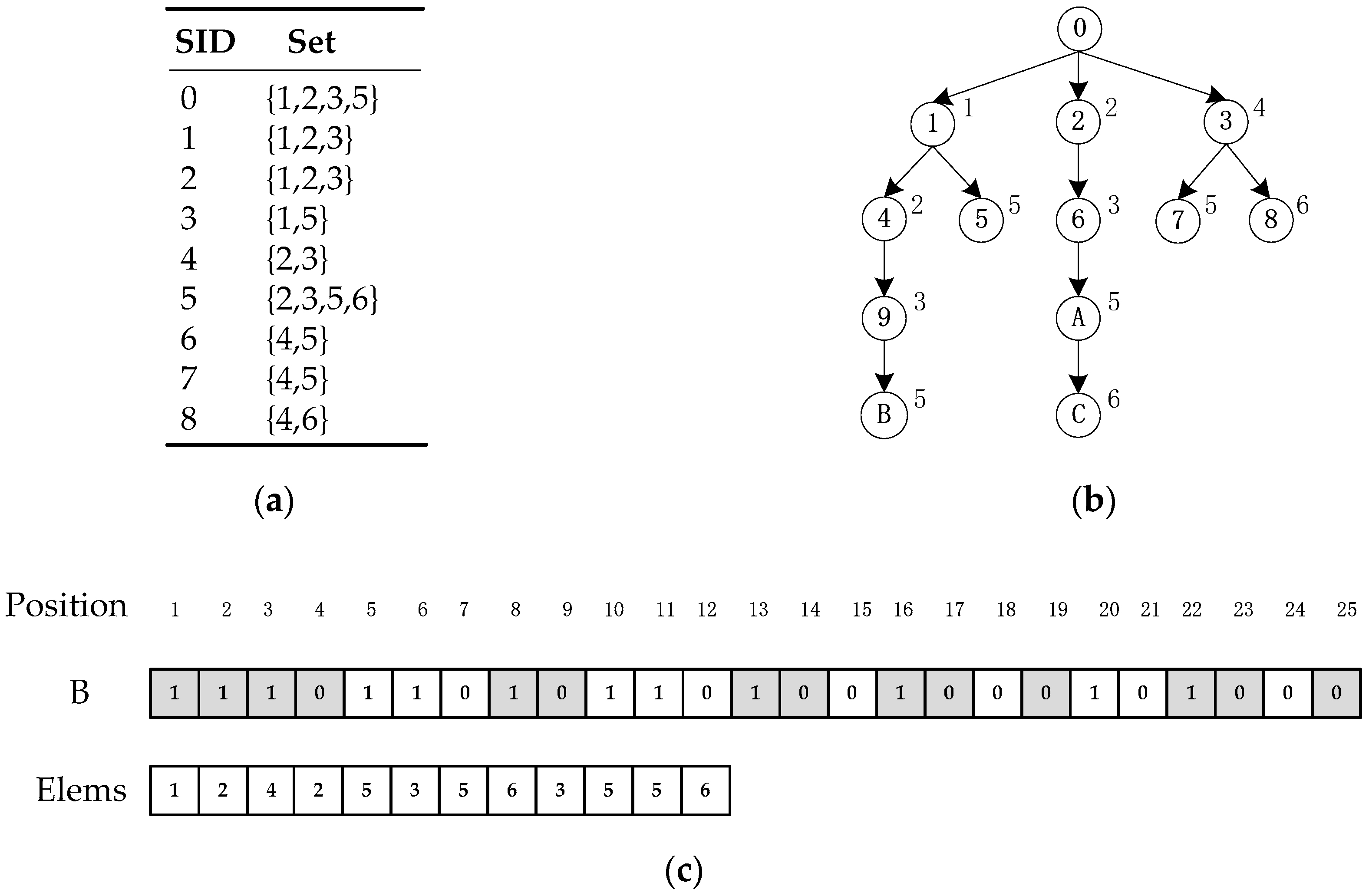
2.2. LOUDS
3. Ext-LOUDS
3.1. Data Preprocessing
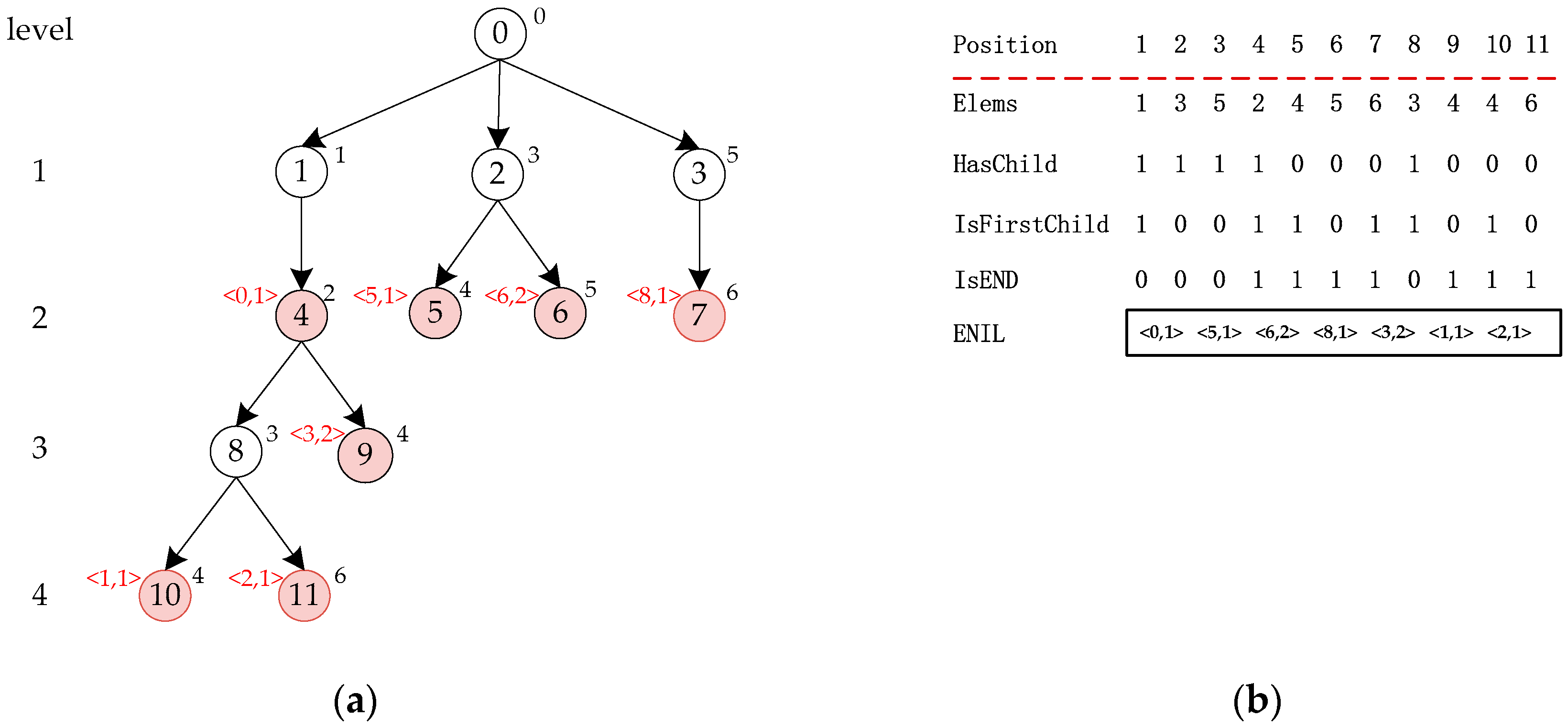
3.2. Ext-LOUDS
3.3. ELOUDS-Super Algorithm
- Perform a SELECT operation on IsFirstChild vector to obtain the starting position and the ending position of the child nodes of node indicated by node_num (lines 2 and 3);
- Perform a binary search to obtain the position of the current query element in Elems vector (line 4);
- If the node corresponding to is an end node, perform a RANK operation on IsEnd vector to obtain the qualifying sets corresponding to the node, and merge it into the result set (lines 5–7);
- If the node corresponding to has child nodes, obtain the internalID and execute the algorithm recursively (lines 8–10).
| Algorithm 1 ELOUDS-Super algorithm |
| //Input: Q, a query having the same ordering with dataset |
| Level: the depth of the trie, starts with 0 node_num: ID of non-leaf node, the ID of root is 0 |
| //Output: RS: results of superset query |
| 1. While(level!=|Q|) |
| 2. pstart←select1(IsFirstChild, node_num+1) |
| 3. pend←select1(IsFirstChild, node_num+2) |
| 4. p←binary(Elems, pstart, pend, Q[level]) |
| 5. if(IsEnd[p]) |
| 6. i←rank1(IsEnd, p) |
| 7. RS←RS U ENIL[i] |
| 8. if(Haschild[p]) |
| 9. node_num←rank1(HasChild, p) |
| 10. Superset(Q, level+1,node_num) |
| 11. level←level+1 |
3.4. Algorithm Complexity Analysis
4. Discussions
4.1. Experimental Environment and Datasets
4.1.1. Real Datasets
4.1.2. Synthetic Datasets
4.2. Comparisons
4.2.1. Experiments on Real Datasets
The Effects of Different Ordering
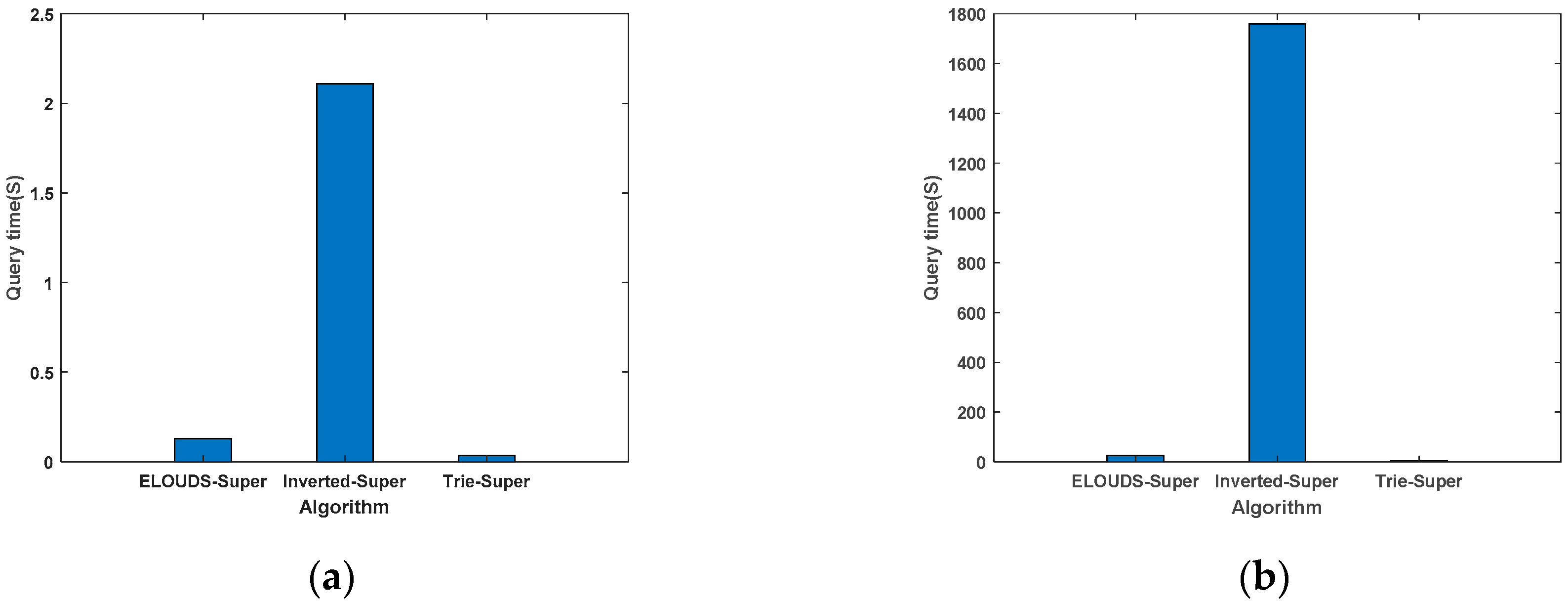
Compared with Different Indexes
The Effects of Duplication Ratio
4.2.2. Experiments on Synthetic Datasets
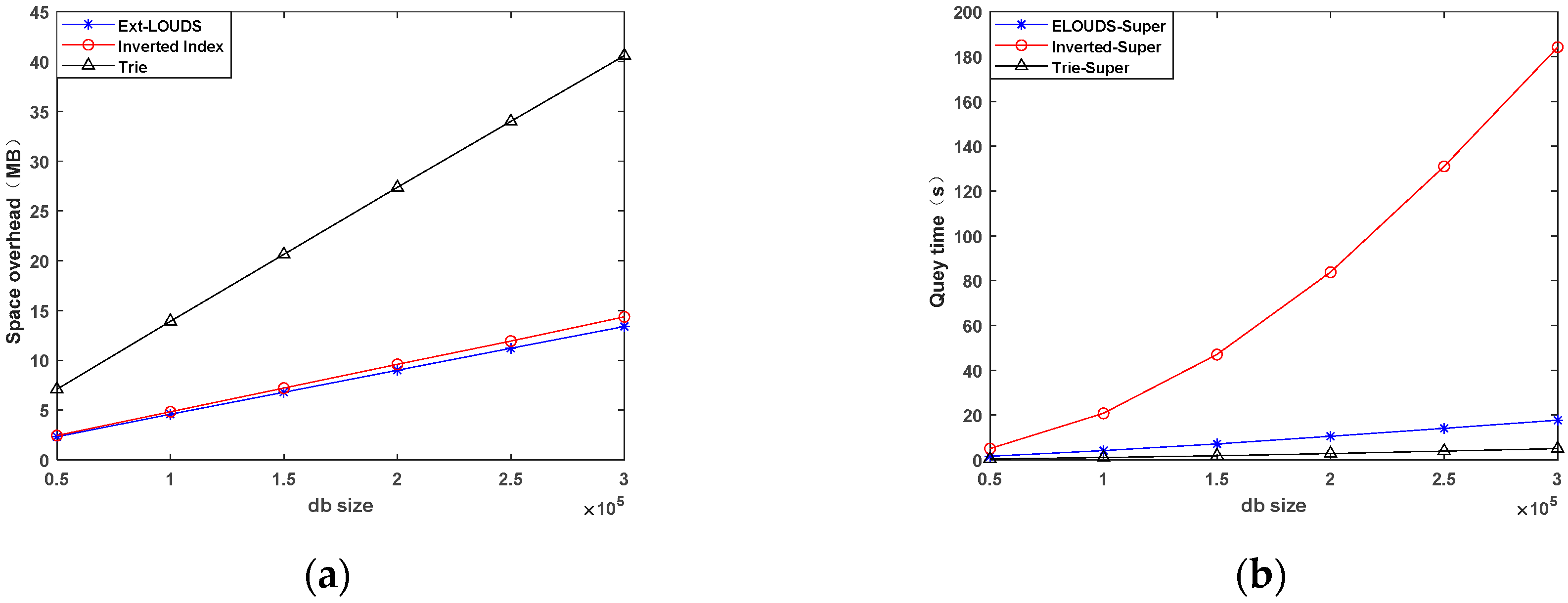
The Effects of |D|
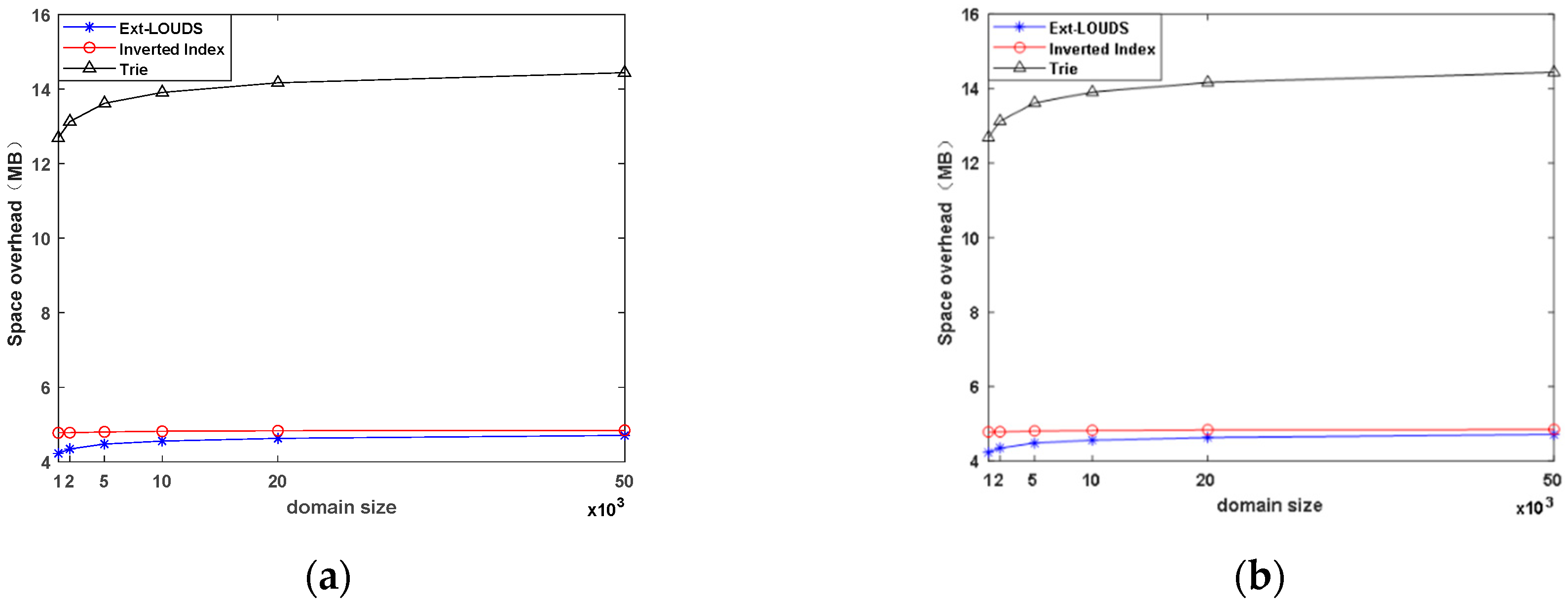
The Effects of |U|
5. Conclusions and Future Work
Author Contributions
Funding
Conflicts of Interest
References
- Savnik, I. Index Data Structure for Fast Subset and Superset Queries. In Proceedings of the International Conference on Availability, Reliability, and Security, Regensburg, Germany, 2–6 September 2013; pp. 134–148. [Google Scholar]
- Deng, D.; Yang, C.; Shang, S. LCJoin: Set Containment Join via List Crosscutting. In Proceedings of the IEEE 35th International Conference on Data Engineering (ICDE), Macau, China, 8–11 April 2019. [Google Scholar]
- Bouros, P.; Mamoulis, N.; Ge, S.; Terrovitis, M. Set containment join revisited. Knowl. Inf. Syst. 2016, 49, 375–402. [Google Scholar] [CrossRef]
- Luo, J.; Zhang, W.; Shi, S.; Gao, H.; Jiang, S. FreshJoin: An Efficient and Adaptive Algorithm for Set Containment Join. Data Sci. Eng. 2019, 4, 293–308. [Google Scholar] [CrossRef]
- Yang, Y.; Zhang, W.; Zhang, Y.; Lin, X.; Wang, L. Selectivity Estimation on Set Containment Search; Springer: Cham, Switzerland, 2019; Volume 4. [Google Scholar]
- Helmer, S.; Moerkotte, G. A performance study of four index structures for set-valued attributes of low cardinality. Vldb J. 2003, 12, 244–261. [Google Scholar] [CrossRef]
- Terrovitis, M.; Bouros, P.; Vassiliadis, P.; Sellis, T.K.; Mamoulis, N. Efficient answering of set containment queries for skewed item distributions. In Proceedings of the International Conference on Edbt, Uppsala, Sweden, 21–24 March 2011. [Google Scholar]
- Agrawal, P.; Arasu, A.; Kaushik, R. On indexing error-tolerant set containment. In Proceedings of the ACM SIGMOD International Conference on Management of Data, SIGMOD 2010, Indianapolis, IN, USA, 6–10 June 2010. [Google Scholar]
- Jia, L. Research on Set Similarity and Set Containtment in Main Memory Database; South China University of Technology: Guangzhou, China, 2012. (In Chinese) [Google Scholar]
- Yang, J.; Zhang, W.; Yang, S.; Zhang, Y.; Lin, X. TT-Join: Efficient Set Containment Join. In Proceedings of the IEEE International Conference on Data Engineering, San Diego, CA, USA, 19–22 April 2017. [Google Scholar]
- Aoe, J.-I. An Efficient Digital Search Algorithm by Using a Double-Array Structure. IEEE Trans. Softw. Eng. 1989, 15, 1066–1077. [Google Scholar] [CrossRef]
- Jia, L.; Zhang, C.; Li, M.; Chen, Y.; Ding, J. An Efficient Two-Level-Partitioning-Based Double Array and Its Parallelization. Appl. Sci. 2020, 10, 5266. [Google Scholar] [CrossRef]
- Jacobson, G. Space-efficient static trees and graphs. In Proceedings of the Symposium on Foundations of Computer Science, Research Triangle Park, NC, USA, 30 October–1 November 1989. [Google Scholar]
- Delpratt, O.N.; Rahman, N.; Raman, R. Engineering the LOUDS Succinct Tree Representation; Springer: Berlin/Heidelberg, Germany, 2006; pp. 134–145. [Google Scholar]
- Zhang, H.; Lim, H.; Leis, V.; Andersen, D.G.; Kaminsky, M.; Keeton, K.; Pavlo, A. Succinct Range Filters. ACM Trans. Database Syst. (TODS) 2020, 45, 1–31. [Google Scholar] [CrossRef]
- Fuketa, M.; Kitagawa, H.; Ogawa, T.; Morita, K.; Aoe, J.I. Compression of double array structures for fixed length keywords. Inf. Process. Manag. 2014, 50, 796–806. [Google Scholar] [CrossRef]
- Kanda, S.; Fuketa, M.; Morita, K.; Aoe, J.I. A compression method of double-array structures using linear functions. Knowl. Inf. Syst. 2016, 48, 55–80. [Google Scholar] [CrossRef]
- Zhou, D.; Andersen, D.G.; Kaminsky, M. Space-Efficient, High-Performance Rank and Select Structures on Uncompressed Bit Sequences; Springer: Berlin/Heidelberg, Germany, 2013; pp. 151–163. [Google Scholar]
- Navarro, G.; Providel, E. Fast, Small, Simple Rank/Select on Bitmaps; Springer: Berlin/Heidelberg, Germany, 2012; pp. 295–306. [Google Scholar]
- Ermanno Pibiri, G.; Kanda, S. Rank/Select Queries over Mutable Bitmaps. arXiv 2020, arXiv:2009.12809. Available online: https://arxiv.org/abs/2009.12809 (accessed on 10 November 2020).
- He, M.; Munro, J.I.; Nekrich, Y.; Wild, S.; Wu, K. Distance Oracles for Interval Graphs via Breadth-First Rank/Select in Succinct Trees. arXiv 2020, arXiv:2005.07644. Available online: https://arxiv.org/abs/2005.07644 (accessed on 13 November 2020).
- Navarro, G.; Ord’On˜Ez, A. Grammar Compressed Sequences with Rank/Select Support. In International Symposium on String Processing and Information Retrieval; Springer: Cham, Switzerland, 2014. [Google Scholar]
- Kai, B.; Johannes, F. High-Order Entropy Compressed Bit Vectors with Rank/Select. Algorithms 2014, 7, 608–620. [Google Scholar]
- Bay, S.D.; Kibler, D.; Pazzani, M.J.; Smyth, P. The UCI KDD archive of large data sets for data mining research and experimentation. SIGKDD Explor. Newsl. 2000, 2, 81–85. [Google Scholar] [CrossRef]
- Ley, M. The DBLP Computer Science Bibliography: Evolution, Research Issues, Perspectives. In Proceedings of the String Processing & Information Retrieval, International Symposium, Spire, Lisbon, Portugal, 11–13 September 2002. [Google Scholar]










{kind=link}
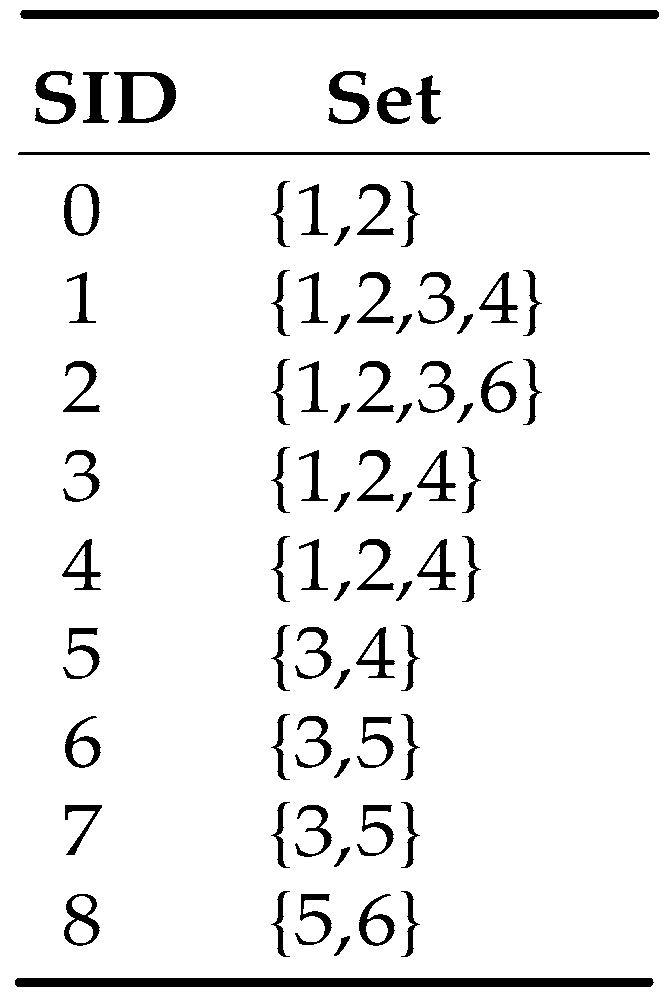{kind=link}
{kind=link}
{kind=link}
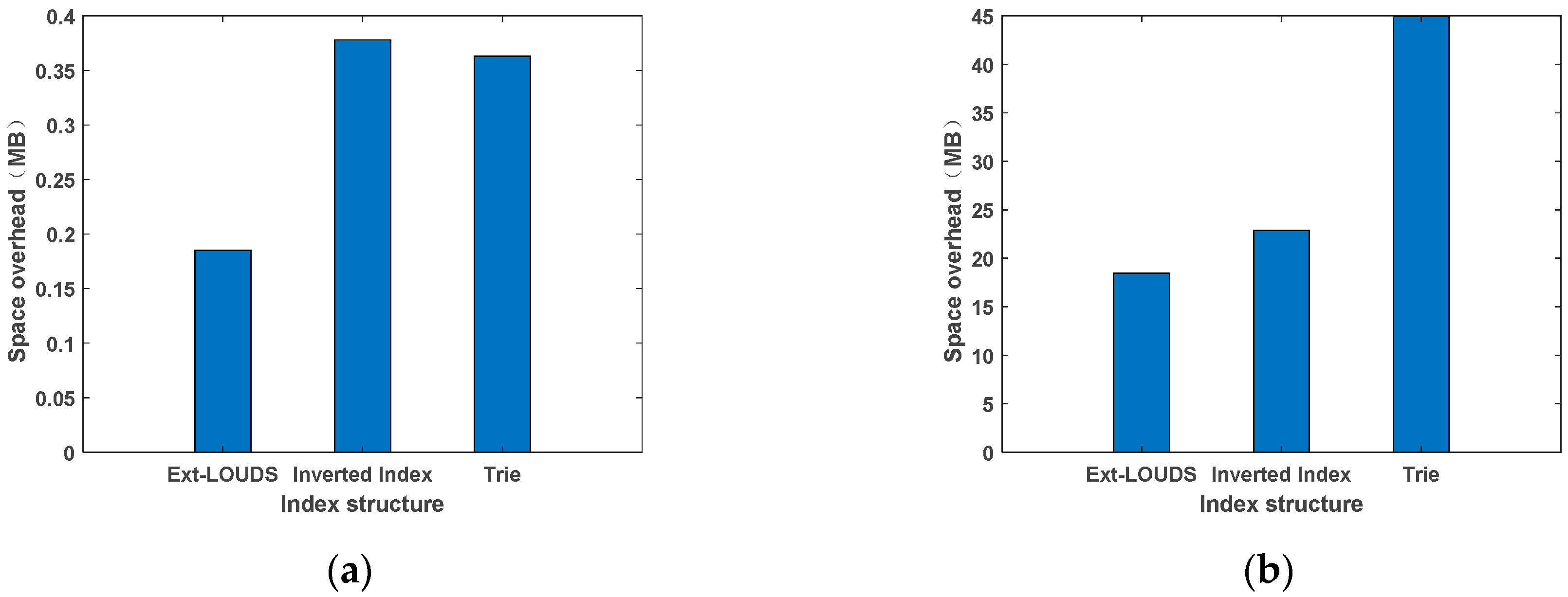{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Symbol | Parameter Value |
|---|---|---|
| Dataset cardinality | |D| | 50 k–300 k |
| Set cardinality | |R| | 5–20 |
| Distinct elements | |U| | 1 k–50 k |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jia, L.; Zhang, Y.; Ding, J.; You, J.; Chen, Y.; Li, R. Ext-LOUDS: A Space Efficient Extended LOUDS Index for Superset Query. Appl. Sci. 2020, 10, 8530. https://doi.org/10.3390/app10238530
Jia L, Zhang Y, Ding J, You J, Chen Y, Li R. Ext-LOUDS: A Space Efficient Extended LOUDS Index for Superset Query. Applied Sciences. 2020; 10(23):8530. https://doi.org/10.3390/app10238530
Chicago/Turabian StyleJia, Lianyin, Yuna Zhang, Jiaman Ding, Jinguo You, Yinong Chen, and Runxin Li. 2020. "Ext-LOUDS: A Space Efficient Extended LOUDS Index for Superset Query" Applied Sciences 10, no. 23: 8530. https://doi.org/10.3390/app10238530
APA StyleJia, L., Zhang, Y., Ding, J., You, J., Chen, Y., & Li, R. (2020). Ext-LOUDS: A Space Efficient Extended LOUDS Index for Superset Query. Applied Sciences, 10(23), 8530. https://doi.org/10.3390/app10238530