A Novel Assisted Artificial Neural Network Modeling Approach for Improved Accuracy Using Small Datasets: Application in Residual Strength Evaluation of Panels with Multiple Site Damage Cracks



Abstract
1. Introduction
2. Background
2.1. Residual Strength of Panels with MSD
- σ: The remote applied stress.
- a: Lead crack half-length.
- βW: Finite width correction factor.
- βa/ℓ: Cracks interaction correction factor for the effect of MSD cracks on the lead crack.
- L: Length of the ligament between the lead crack and MSD crack.
- ℓ: MSD crack half-length.
- βa: The overall SIF correction factor for the lead crack tip.
- βℓ: The overall SIF correction factor for the adjacent MSD crack tip.
- βH: Correction factor for the effect of the hole.
- βℓ/a: The cracks interaction correction factor for the effect of the lead crack on MSD cracks.
2.2. ANN Input Parameters Selection
3. The Experimental Dataset
4. ANN Modeling Procedure
4.1. Traditional ANN Modeling Approach
4.2. Assisted-ANN Modeling Approach
- First assistance level: here, the panel configuration SIF correction factor (βP-config) is used as an assistance parameter. This correction factor corrects the SIF of the lead crack for all effects related to the panel configuration, where the unstiffened panel configuration (seen in Figure 1) is taken as a reference configuration. Therefore, the value of βP-config for the unstiffened panels (listed in Table A1) is unity (βP-config = 1) since this is the reference configuration. For the stiffened panels, the panel configuration correction factor is basically the stiffeners’ effect correction factor (βP-config = βstf), and its value for each of the different cracks/stiffeners configurations is given in Table A2. This stiffeners’ effect correction factor accounts not only for the presence of the stiffeners and their arrangement, but it also accounts for their cross-sectional area and spacing, the fasteners stiffness and spacing, and the crack location and length. Finally, for the lap-joint panels, the panel configuration correction factor is the lap-joint effect correction factor (βP-config = βLJ), and its value for each of the different cracks configurations is given in Table A3. This factor mainly accounts for the fasteners arrangement, stiffness and spacing, and for the point loads induced by the fasteners along the crack plane.
- Second assistance level: here, instead of using the panel configuration SIF correction factor (βP-config), the overall lead crack SIF correction factor () is used. The βa includes both the finite width correction and the cracks interaction correction (as seen in Equation (5)), and it also includes the panel configuration correction factor (βstf or βLJ). The values of for all the 113 data points are given in Table A1, Table A2 and Table A3.
- Third assistance level: here, instead of using one assistance parameter as in the previous assistance levels, two assistance parameters are used simultaneously. In addition to the overall lead crack SIF correction factor (), which is used in the second assistance level, the overall SIF correction factor for the adjacent MSD crack () is also used. The mainly accounts for the cracks interaction effect and the hole effect (as seen in Equation (6)) and its values are also given in the tables.
- Fourth assistance level: here, instead of using the SIF correction factors, the residual strength value calculated by the linkup model (Equation (4)) is used as the assistance parameter. As can be seen form the linkup model equation, it includes the SIF geometric correction factors as well as the lead and MSD crack lengths, the ligament length and the material’s yield strength. Therefore, the inclusion of the linkup model’s residual strength predictions provides the highest level of assistance since it combines the effects of many of the input parameters together.
4.3. Reduced Size Training Datasets
4.4. ANN Optimization and Performance Evaluation
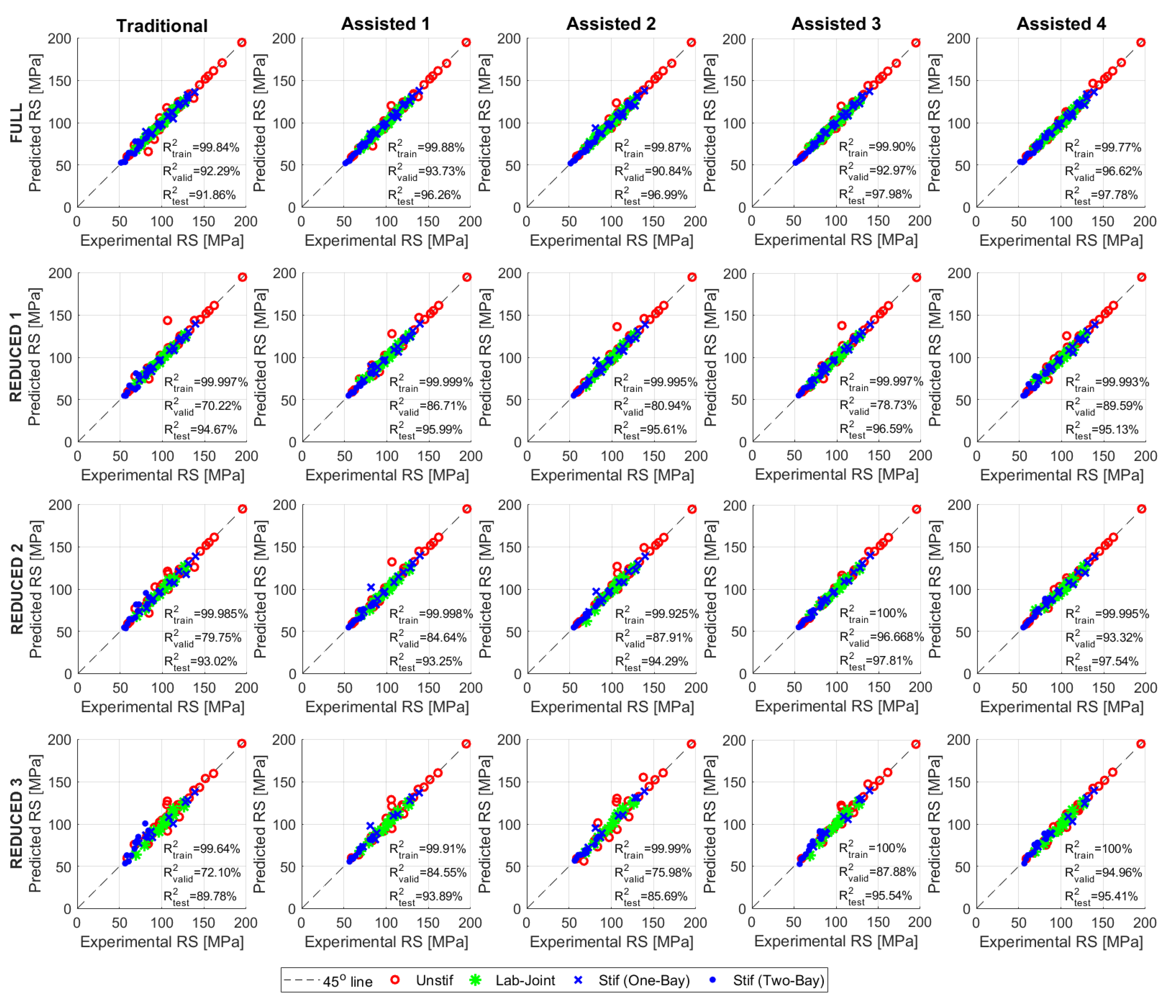
5. Results and Discussion
5.1. Assisted-ANN Performance for Different Learning Algorithms
5.2. Effect of Smaller Training Dataset Size
5.3. ANN Inputs Relative Importance
6. Concluding Remarks
- Different types of parameters can be used as assistance parameters, and one or more assistance parameters can be used at the same time. The assistance parameters can be obtained using any well-established relation that partially or fully relate some (or all) of the inputs with the output (e.g., the SIF correction factors are partial relations while the linkup model is a full relation). The amount of the achieved accuracy improvement depends on the level and the accuracy of the assistance parameter(s) being used.
- The fact that the SIF correction factors can be successfully used as assistance input parameters makes the proposed assisted-ANN approach to be useful in a very wide variety of fracture mechanics applications (both for fatigue crack growth and static fracture). The assisted-ANN approach should prove to be very helpful in cases where the number of data points available for training the ANN is limited, which is generally the case in many experimental investigations in the fracture mechanics field.
- The lower the accuracy of the predictions obtained using the traditional approach, the more the improvement that is achieved using the assisted approach. For the SGC algorithm (it gives the least accurate results), the relative error reduction achieved by the assisted approach reached −46%; whereas for the BR algorithm (it gives the most accurate results), the relative error reduction achieved by the assisted approach reached −22% only.
- As the size of the training dataset gets smaller, the assistance input parameters will play a more significant role in improving the ANN performance. The results show that the relative error reduction generally increases as the size of the training dataset gets smaller. For the 22 data points training dataset, the achieved relative error reduction by the assisted approach reached −37%; whereas for the 75 data points training dataset, the achieved relative error reduction by the assisted approach reached −22% only.
- In the proposed assisted approach, all the direct independent inputs used in the traditional approach are still used and the assistance parameter(s) is/are used as additional input(s). The added assistance parameter(s) will influence the internal configuration of the ANN, especially the neurons’ connection weights. When an assistance parameter is added to the inputs, its relative weight becomes clearly higher than most (or all) of the other direct independent inputs. This shows the importance of adding the assistance parameter and the significant role it plays in the internal ANN structure. Also, when an assistance parameter is added, the relative weight of some of the inputs is reduced significantly, which means that the assistance parameter is taking over their role. Usually, the inputs with very small relative weights are deleted; however, our results show that to be not necessary since the ANN can recognize the importance of each of the inputs and give it its appropriate weight. Furthermore, the results show that the ANN is able to efficiently handle all the different types of inputs whether they are independent or dependent.
Author Contributions
Funding
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Panel ID | σy MPa | W mm | a mm | ℓ mm | L mm | σExp MPa | βa | βℓ | σLU MPa |
|---|---|---|---|---|---|---|---|---|---|
| U-1 a | 310.3 | 610 | 93.35 | 4.45 | 3.81 | 79.84 | 1.190 | 3.380 | 63.33 |
| U-2 a | 310.3 | 610 | 90.81 | 4.45 | 6.35 | 97.15 | 1.126 | 2.714 | 90.90 |
| U-3 a | 310.3 | 610 | 88.27 | 4.45 | 8.89 | 112.18 | 1.102 | 2.350 | 114.02 |
| U-4 a | 275.8 | 610 | 84.46 | 8.26 | 8.89 | 94.25 | 1.146 | 2.100 | 95.80 |
| U-5 a | 275.8 | 610 | 83.19 | 6.99 | 11.43 | 110.04 | 1.103 | 1.989 | 116.25 |
| U-6 a | 275.8 | 610 | 81.92 | 5.72 | 13.97 | 120.04 | 1.085 | 1.903 | 134.84 |
| U-7 a | 275.8 | 610 | 80.65 | 4.45 | 16.51 | 132.52 | 1.063 | 1.789 | 154.39 |
| U-8 a | 275.8 | 610 | 118.75 | 4.45 | 3.81 | 67.57 | 1.238 | 3.536 | 49.41 |
| U-9 a | 275.8 | 610 | 116.21 | 4.45 | 6.35 | 83.36 | 1.166 | 2.985 | 69.93 |
| U-10 a | 275.8 | 610 | 113.67 | 4.45 | 8.89 | 94.94 | 1.141 | 2.600 | 87.15 |
| U-11 a | 275.8 | 610 | 109.86 | 8.26 | 8.89 | 82.33 | 1.184 | 2.360 | 82.20 |
| U-12 a | 275.8 | 610 | 108.59 | 6.99 | 11.43 | 97.15 | 1.139 | 2.224 | 99.60 |
| U-13 a | 275.8 | 610 | 107.32 | 5.72 | 13.97 | 105.7 | 1.117 | 2.122 | 115.52 |
| U-14 a | 275.8 | 610 | 106.05 | 4.45 | 16.51 | 119.77 | 1.098 | 1.997 | 131.35 |
| U-15 a | 310.3 | 610 | 144.15 | 4.45 | 3.81 | 59.02 | 1.305 | 3.900 | 48.39 |
| U-16 a | 310.3 | 610 | 141.61 | 4.45 | 6.35 | 73.98 | 1.228 | 3.255 | 68.48 |
| U-17 a | 310.3 | 610 | 139.07 | 4.45 | 8.89 | 83.71 | 1.198 | 2.798 | 85.45 |
| U-18 a | 275.8 | 610 | 135.26 | 8.26 | 8.89 | 71.23 | 1.239 | 2.590 | 71.70 |
| U-19 a | 275.8 | 610 | 133.99 | 6.99 | 11.43 | 83.50 | 1.191 | 2.438 | 86.71 |
| U-20 a | 275.8 | 610 | 132.72 | 5.72 | 13.97 | 93.91 | 1.174 | 2.319 | 99.79 |
| U-21 a | 275.8 | 610 | 131.45 | 4.45 | 16.51 | 108.73 | 1.149 | 2.194 | 113.58 |
| U-22 a | 275.8 | 610 | 160.66 | 8.26 | 8.89 | 71.23 | 1.314 | 2.770 | 63.00 |
| U-23 b | 324.1 | 2286 | 254 | 6.35 | 6.35 | 61.50 | 1.104 | 3.570 | 58.51 |
| U-24 b | 324.1 | 2286 | 177.8 | 5.08 | 7.62 | 84.12 | 1.066 | 3.224 | 79.31 |
| U-25 b | 324.1 | 2286 | 71.12 | 7.62 | 10.16 | 137.9 | 1.070 | 1.880 | 140.43 |
| U-26 b | 324.1 | 2286 | 195.58 | 5.08 | 15.24 | 97.91 | 1.040 | 2.631 | 113.98 |
| U-27 b | 324.1 | 2286 | 241.3 | 6.35 | 19.05 | 88.95 | 1.050 | 2.560 | 114.11 |
| U-28 b | 324.1 | 2286 | 96.52 | 7.62 | 22.86 | 161.34 | 1.035 | 1.620 | 197.38 |
| U-29 b | 324.1 | 2286 | 273.05 | 6.35 | 25.4 | 91.29 | 1.049 | 2.428 | 125.70 |
| U-30 b | 324.1 | 2286 | 127 | 5.08 | 33.02 | 151.69 | 1.015 | 1.664 | 218.90 |
| U-31 c | 268.9 | 508 | 101.6 | 3.81 | 8.89 | 97.43 | 1.140 | 2.390 | 91.46 |
| U-32 c | 268.9 | 508 | 96.52 | 6.35 | 11.43 | 99.98 | 1.147 | 2.080 | 103.46 |
| U-33 c | 268.9 | 508 | 40.64 | 10.16 | 12.7 | 144.8 | 1.094 | 1.420 | 162.97 |
| U-34 c | 268.9 | 508 | 63.5 | 12.7 | 12.7 | 106.05 | 1.141 | 1.620 | 125.81 |
| U-35 c | 268.9 | 508 | 93.98 | 6.35 | 13.97 | 110.32 | 1.130 | 1.910 | 118.80 |
| U-36 c | 268.9 | 508 | 40.64 | 6.35 | 16.51 | 171.55 | 1.054 | 1.361 | 204.87 |
| U-37 c | 268.9 | 508 | 91.44 | 6.35 | 16.51 | 118.94 | 1.123 | 1.780 | 132.76 |
| U-38 c | 268.9 | 508 | 76.2 | 6.35 | 31.75 | 155.14 | 1.077 | 1.370 | 213.88 |
| U-39 c | 268.9 | 508 | 38.1 | 12.7 | 38.1 | 194.78 | 1.049 | 1.130 | 307.93 |
| U-40 d | 303.4 | 600 | 90 | 7.5 | 8 | 106.83 | 1.144 | 2.150 | 98.28 |
| U-41 d | 303.4 | 600 | 90 | 7.5 | 12 | 120.83 | 1.107 | 1.950 | 126.15 |
| U-42 d | 303.4 | 600 | 90 | 7.5 | 18 | 132 | 1.086 | 1.700 | 161.03 |
| U-43 d | 303.4 | 600 | 111 | 7.5 | 10 | 103 | 1.159 | 2.300 | 98.72 |
| U-44 d | 303.4 | 600 | 111 | 7.5 | 15 | 107.83 | 1.128 | 1.970 | 127.35 |
| U-45 d | 303.4 | 600 | 113 | 7.5 | 15 | 113.33 | 1.131 | 1.980 | 126.04 |
| U-46 d | 303.4 | 600 | 113 | 7.5 | 20 | 119.67 | 1.120 | 1.800 | 148.96 |
| U-47 d | 303.4 | 600 | 136 | 7.5 | 20 | 99 | 1.172 | 1.920 | 131.00 |
| U-48 d | 303.4 | 600 | 138 | 7.5 | 30 | 110.67 | 1.166 | 1.680 | 162.62 |
| U-49 d | 303.4 | 600 | 143 | 7.5 | 20 | 100 | 1.192 | 1.960 | 126.00 |
| U-50 d | 303.4 | 600 | 148 | 7.5 | 30 | 106.67 | 1.195 | 1.740 | 153.63 |
| Panel ID | Stiff. Config. | σy MPa | Astf mm2 | W mm | a mm | ℓ mm | L mm | σExp MPa | βP-config (β s) | βa | β ℓ | σLU MPa |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| S-1 | One-Bay | 275.8 | 105 | 610 | 118.75 | 4.45 | 3.81 | 73.09 | 0.882 | 1.077 | 3.594 | 54.51 |
| S-2 | One-Bay | 275.8 | 105 | 610 | 116.21 | 4.45 | 6.35 | 86.95 | 0.890 | 1.034 | 2.935 | 77.09 |
| S-3 | One-Bay | 275.8 | 105 | 610 | 113.67 | 4.45 | 8.89 | 99.91 | 0.897 | 1.018 | 2.559 | 95.93 |
| S-4 | One-Bay | 275.8 | 105 | 610 | 108.59 | 6.99 | 11.43 | 95.43 | 0.911 | 1.034 | 2.186 | 107.83 |
| S-5 | One-Bay | 275.8 | 105 | 610 | 107.32 | 5.72 | 13.97 | 110.66 | 0.914 | 1.018 | 2.082 | 125.06 |
| S-6 | One-Bay | 275.8 | 105 | 610 | 106.05 | 4.45 | 16.51 | 122.18 | 0.917 | 1.006 | 1.981 | 141.89 |
| S-7 | One-Bay | 275.8 | 105 | 610 | 144.15 | 4.45 | 3.81 | 74.67 | 0.711 | 0.915 | 3.936 | 55.30 |
| S-8 | One-Bay | 275.8 | 105 | 610 | 141.61 | 4.45 | 6.35 | 88.67 | 0.736 | 0.900 | 3.210 | 77.56 |
| S-9 | One-Bay | 275.8 | 105 | 610 | 139.07 | 4.45 | 8.89 | 97.08 | 0.761 | 0.907 | 2.797 | 95.18 |
| S-10 | One-Bay | 275.8 | 105 | 610 | 133.99 | 6.99 | 11.43 | 96.25 | 0.800 | 0.952 | 2.388 | 103.83 |
| S-11 | One-Bay | 275.8 | 105 | 610 | 132.72 | 5.72 | 13.97 | 112.66 | 0.811 | 0.946 | 2.271 | 119.73 |
| S-12 | One-Bay | 275.8 | 105 | 610 | 131.45 | 4.45 | 16.51 | 127.83 | 0.819 | 0.940 | 2.159 | 135.43 |
| S-13 | One-Bay | 310.3 | 161.3 | 610 | 113.67 | 4.45 | 8.89 | 107.08 | 0.875 | 0.993 | 2.559 | 110.08 |
| S-14 | One-Bay | 310.3 | 151.6 | 610 | 108.59 | 6.99 | 11.43 | 108.6 | 0.895 | 1.016 | 2.186 | 122.98 |
| S-15 | One-Bay | 310.3 | 151.6 | 610 | 107.32 | 5.72 | 13.97 | 119.9 | 0.898 | 1.000 | 2.082 | 142.73 |
| S-16 | One-Bay | 310.3 | 151.6 | 610 | 106.05 | 4.45 | 16.51 | 130.8 | 0.900 | 0.987 | 1.981 | 162.21 |
| S-17 | One-Bay | 310.3 | 161.3 | 610 | 144.15 | 4.45 | 3.81 | 81.5 | 0.661 | 0.851 | 3.936 | 65.09 |
| S-18 | One-Bay | 310.3 | 151.6 | 610 | 133.99 | 6.99 | 11.43 | 114.04 | 0.774 | 0.921 | 2.388 | 119.72 |
| S-19 | One-Bay | 310.3 | 161.3 | 610 | 132.72 | 5.72 | 13.97 | 120.32 | 0.783 | 0.913 | 2.271 | 138.51 |
| S-20 | One-Bay | 310.3 | 161.3 | 610 | 131.45 | 4.45 | 16.51 | 139.35 | 0.793 | 0.911 | 2.159 | 156.56 |
| S-21 | One-Bay | 303.4 | 105 | 610 | 81.92 | 5.72 | 13.97 | 130.73 | 0.953 | 1.026 | 1.873 | 155.60 |
| S-22 | Two-Bay * | 275.8 | 105 | 610 | 107.32 | 5.72 | 13.97 | 80.53 | 1.247 | 1.388 | 2.082 | 95.79 |
| S-23 | Two-Bay * | 275.8 | 105 | 610 | 108.59 | 6.99 | 11.43 | 70.88 | 1.244 | 1.412 | 2.186 | 83.42 |
| S-24 | Two-Bay * | 275.8 | 105 | 610 | 109.86 | 8.26 | 8.89 | 58.68 | 1.240 | 1.451 | 2.343 | 69.93 |
| S-25 | Two-Bay * | 275.8 | 105 | 610 | 132.72 | 5.72 | 13.97 | 75.85 | 1.181 | 1.378 | 2.271 | 86.91 |
| S-26 | Two-Bay * | 275.8 | 105 | 610 | 133.99 | 6.99 | 11.43 | 67.85 | 1.177 | 1.401 | 2.388 | 75.79 |
| S-27 | Two-Bay * | 275.8 | 105 | 610 | 135.26 | 8.26 | 8.89 | 56.75 | 1.174 | 1.440 | 2.563 | 63.57 |
| S-28 | Two-Bay * | 275.8 | 105 | 610 | 158.12 | 5.72 | 13.97 | 72.26 | 1.110 | 1.375 | 2.446 | 79.87 |
| S-29 | Two-Bay * | 275.8 | 105 | 610 | 159.39 | 6.99 | 11.43 | 63.92 | 1.106 | 1.399 | 2.574 | 69.67 |
| S-30 | Two-Bay * | 275.8 | 105 | 610 | 160.66 | 8.26 | 8.89 | 54.75 | 1.102 | 1.438 | 2.767 | 58.49 |
| S-31 | Two-Bay * | 275.8 | 105 | 610 | 183.52 | 5.72 | 13.97 | 68.74 | 1.005 | 1.348 | 2.610 | 75.55 |
| S-32 | Two-Bay * | 275.8 | 105 | 610 | 184.79 | 6.99 | 11.43 | 60.95 | 0.997 | 1.367 | 2.748 | 66.10 |
| S-33 | Two-Bay * | 275.8 | 105 | 610 | 186.06 | 8.26 | 8.89 | 51.85 | 0.989 | 1.400 | 2.957 | 55.64 |
| S-34 | Two-Bay * | 310.3 | 105 | 610 | 107.32 | 5.72 | 13.97 | 97.01 | 1.247 | 1.388 | 2.082 | 107.77 |
| S-35 | Two-Bay * | 310.3 | 105 | 610 | 132.72 | 5.72 | 13.97 | 84.26 | 1.181 | 1.378 | 2.271 | 97.77 |
| S-36 | Two-Bay * | 310.3 | 105 | 610 | 158.12 | 5.72 | 13.97 | 82.33 | 1.110 | 1.375 | 2.446 | 89.85 |
| Panel ID | σy MPa | W mm | a mm | ℓ mm | L mm | σExp MPa | βP-config (β LJ) | βa | β ℓ | σLU MPa |
|---|---|---|---|---|---|---|---|---|---|---|
| LJ-1 | 268.9 | 610 | 106.52 | 3.65 | 16.83 | 126.73 | 0.843 | 0.922 | 2.506 | 146.46 |
| LJ-2 | 268.9 | 610 | 106.52 | 4.92 | 15.56 | 115.77 | 0.846 | 0.935 | 2.323 | 137.17 |
| LJ-3 | 268.9 | 610 | 107.79 | 3.65 | 15.56 | 126.73 | 0.821 | 0.904 | 2.574 | 141.51 |
| LJ-4 | 268.9 | 610 | 107.79 | 4.92 | 14.29 | 113.35 | 0.826 | 0.918 | 2.393 | 131.79 |
| LJ-5 | 268.9 | 610 | 107.79 | 6.19 | 13.02 | 106.53 | 0.834 | 0.934 | 2.268 | 122.30 |
| LJ-6 | 268.9 | 610 | 109.06 | 3.65 | 14.29 | 119.84 | 0.810 | 0.889 | 2.656 | 135.86 |
| LJ-7 | 268.9 | 610 | 109.06 | 4.92 | 13.02 | 113.56 | 0.815 | 0.905 | 2.466 | 125.64 |
| LJ-8 | 268.9 | 610 | 109.06 | 6.19 | 11.75 | 105.77 | 0.818 | 0.923 | 2.346 | 115.69 |
| LJ-9 | 268.9 | 610 | 109.06 | 7.46 | 10.48 | 101.49 | 0.821 | 0.944 | 2.294 | 105.38 |
| LJ-10 | 268.9 | 610 | 131.92 | 3.65 | 16.83 | 107.29 | 0.828 | 0.948 | 2.853 | 128.10 |
| LJ-11 | 268.9 | 610 | 131.92 | 4.92 | 15.56 | 102.6 | 0.831 | 0.961 | 2.642 | 120.00 |
| LJ-12 | 268.9 | 610 | 133.19 | 3.65 | 15.56 | 105.91 | 0.810 | 0.930 | 2.930 | 123.87 |
| LJ-13 | 268.9 | 610 | 133.19 | 4.92 | 14.29 | 97.29 | 0.812 | 0.941 | 2.720 | 115.66 |
| LJ-14 | 268.9 | 610 | 133.19 | 6.19 | 13.02 | 90.32 | 0.816 | 0.958 | 2.572 | 107.41 |
| LJ-15 | 268.9 | 610 | 134.46 | 3.65 | 14.29 | 102.18 | 0.793 | 0.915 | 3.034 | 118.92 |
| LJ-16 | 268.9 | 610 | 134.46 | 4.92 | 13.02 | 96.25 | 0.799 | 0.930 | 2.799 | 110.25 |
| LJ-17 | 268.9 | 610 | 134.46 | 6.19 | 11.75 | 88.26 | 0.802 | 0.949 | 2.663 | 101.50 |
| LJ-18 | 268.9 | 610 | 134.46 | 7.46 | 10.48 | 81.91 | 0.807 | 0.971 | 2.613 | 92.34 |
| LJ-19 | 268.9 | 610 | 157.32 | 3.65 | 16.83 | 89.29 | 0.816 | 0.992 | 3.314 | 111.70 |
| LJ-20 | 268.9 | 610 | 157.32 | 4.92 | 15.56 | 86.26 | 0.820 | 1.007 | 3.028 | 104.84 |
| LJ-21 | 268.9 | 610 | 158.59 | 3.65 | 15.56 | 87.84 | 0.802 | 0.979 | 3.403 | 107.63 |
| LJ-22 | 268.9 | 610 | 158.59 | 4.92 | 14.29 | 81.29 | 0.806 | 0.994 | 3.113 | 100.53 |
| LJ-23 | 268.9 | 610 | 158.59 | 6.19 | 13.02 | 75.02 | 0.812 | 1.012 | 2.952 | 93.26 |
| LJ-24 | 268.9 | 610 | 159.86 | 3.65 | 14.29 | 84.46 | 0.787 | 0.964 | 3.503 | 103.38 |
| LJ-25 | 268.9 | 610 | 159.86 | 4.92 | 13.02 | 79.78 | 0.793 | 0.981 | 3.218 | 95.89 |
| LJ-26 | 268.9 | 610 | 159.86 | 6.19 | 11.75 | 74.12 | 0.796 | 1.001 | 3.059 | 88.26 |
| LJ-27 | 268.9 | 610 | 159.86 | 7.46 | 10.48 | 69.23 | 0.801 | 1.025 | 2.988 | 80.39 |
References
- Haykin, S. Neural Networks: A Comprehensive Foundation; Prentice-Hall Inc.: Upper Saddle River, NJ, USA, 2007. [Google Scholar]
- He, W.; Yan, Z.; Sun, Y.; Ou, Y.; Sun, C. Neural-Learning-Based Control for a Constrained Robotic Manipulator with Flexible Joints. IEEE Trans. Neural Netw. Learn. Syst. 2018, 29, 5993–6003. [Google Scholar] [CrossRef] [PubMed]
- Elsheikh, A.H.; Sharshir, S.W.; Elaziz, M.A.; Kabeel, A.; Guilan, W.; Zhang, H. Modeling of solar energy systems using artificial neural network: A comprehensive review. Sol. Energy 2019, 180, 622–639. [Google Scholar] [CrossRef]
- Al-Dahidi, S.; Ayadi, O.; Alrbai, M.; Adeeb, J. Ensemble Approach of Optimized Artificial Neural Networks for Solar Photovoltaic Power Prediction. IEEE Access 2019, 7, 81741–81758. [Google Scholar] [CrossRef]
- Cao, J.; Fang, Z.; Qu, G.; Sun, H.; Zhang, D. An accurate traffic classification model based on support vector machines. Int. J. Netw. Manag. 2017, 27, e1962. [Google Scholar] [CrossRef]
- Mehdy, M.M.; Ng, P.Y.; Shair, E.F.; Saleh, N.I.M.; Gomes, C. Artificial Neural Networks in Image Processing for Early Detection of Breast Cancer. Comput. Math. Methods Med. 2017, 2017, 1–15. [Google Scholar] [CrossRef]
- Mendes, N.; Ferrer, J.; Vitorino, J.; Safeea, M.; Neto, P. Human Behavior and Hand Gesture Classification for Smart Human-robot Interaction. Procedia Manuf. 2017, 11, 91–98. [Google Scholar] [CrossRef]
- Yamanaka, A.; Kamijyo, R.; Koenuma, K.; Watanabe, I.; Kuwabara, T. Deep neural network approach to estimate biaxial stress-strain curves of sheet metals. Mater. Des. 2020, 195, 108970. [Google Scholar] [CrossRef]
- Altarazi, S.; Ammouri, M.; Hijazi, A.L. Artificial neural network modeling to evaluate polyvinylchloride composites’ properties. Comput. Mater. Sci. 2018, 153, 1–9. [Google Scholar] [CrossRef]
- Altarazi, S.; Allaf, R.M.; Al-Hindawi, F. Machine Learning Models for Predicting and Classifying the Tensile Strength of Polymeric Films Fabricated via Different Production Processes. Materials 2019, 12, 1475. [Google Scholar] [CrossRef]
- Dagli, C.H. Artificial Neural Networks for Intelligent Manufacturing; Springer Science & Business Media: Dordrecht, The Netherlands, 2012. [Google Scholar]
- Ashhab, M.S.; Breitsprecher, T.; Wartzack, S. Neural network based modeling and optimization of deep drawing—Extrusion combined process. J. Intell. Manuf. 2014, 25, 77–84. [Google Scholar] [CrossRef]
- Nasiri, S.; Khosravani, M.R.; Weinberg, K. Fracture mechanics and mechanical fault detection by artificial intelligence methods: A review. Eng. Fail. Anal. 2017, 81, 270–293. [Google Scholar] [CrossRef]
- Feng, S.; Zhou, H.; Dong, H.B. Using deep neural network with small dataset to predict material defects. Mater. Des. 2019, 162, 300–310. [Google Scholar] [CrossRef]
- Balcioglu, H.E.; Seçkin, A.Ç.; Aktas, M. Failure load prediction of adhesively bonded pultruded composites using artificial neural network. J. Compos. Mater. 2016, 50, 3267–3281. [Google Scholar] [CrossRef]
- Hakim, S.J.S.; Razak, H.A. Structural damage detection of steel bridge girder using artificial neural networks and finite element models. Steel Compos. Struct. 2013, 14, 367–377. [Google Scholar] [CrossRef]
- Janssens, O.; Slavkovikj, V.; Vervisch, B.; Stockman, K.; Loccufier, M.; Verstockt, S.; Van De Walle, R.; Van Hoecke, S. Convolutional Neural Network Based Fault Detection for Rotating Machinery. J. Sound Vib. 2016, 377, 331–345. [Google Scholar] [CrossRef]
- Shu, J.; Zhang, Z.; González, I.; Karoumi, R. The application of a damage detection method using Artificial Neural Network and train-induced vibrations on a simplified railway bridge model. Eng. Struct. 2013, 52, 408–421. [Google Scholar] [CrossRef]
- Nechval, K.N.; Nechval, N.A.; Bausova, I.; Skiltere, D.; Strelchonok, V.F. Prediction of fatigue crack growth process via artificial neural network technique. Int. J. Comput. 2006, 5, 21–32. [Google Scholar]
- Hamdia, K.M.; Lahmer, T.; Nguyen-Thoi, T.; Rabczuk, T. Predicting the fracture toughness of PNCs: A stochastic approach based on ANN and ANFIS. Comput. Mater. Sci. 2015, 102, 304–313. [Google Scholar] [CrossRef]
- Mortazavi, S.; Ince, A. An artificial neural network modeling approach for short and long fatigue crack propagation. Comput. Mater. Sci. 2020, 185, 109962. [Google Scholar] [CrossRef]
- Seibi, A.; Al-Alawi, S. Prediction of fracture toughness using artificial neural networks (ANNs). Eng. Fract. Mech. 1997, 56, 311–319. [Google Scholar] [CrossRef]
- Ince, R. Prediction of fracture parameters of concrete by Artificial Neural Networks. Eng. Fract. Mech. 2004, 71, 2143–2159. [Google Scholar] [CrossRef]
- Spear, A.D.; Priest, A.R.; Veilleux, M.G.; Ingraffea, A.R.; Hochhalter, J.D. Surrogate Modeling of High-Fidelity Fracture Simulations for Real-Time Residual Strength Predictions. AIAA J. 2011, 49, 2770–2782. [Google Scholar] [CrossRef]
- Pidaparti, R.M.; Jayanti, S.; Palakal, M.J. Residual Strength and Corrosion Rate Predictions of Aging Aircraft Panels: Neural Network Study. J. Aircr. 2002, 39, 175–180. [Google Scholar] [CrossRef]
- Pidaparti, R. Aircraft structural integrity assessment through computational intelligence techniques. Struct. Durab. Health Monit. 2006, 2, 131. [Google Scholar]
- Hijazi, A.; Al-Dahidi, S.; Altarazi, S. Residual Strength Prediction of Aluminum Panels with Multiple Site Damage Using Artificial Neural Networks. Materials 2020, 13, 5216. [Google Scholar] [CrossRef]
- Swift, T. Widespread Fatigue Damage Monitoring: Issues and Concerns. In Proceedings of the 5th International Conference on Structural Airworthiness of New and Ageing Aircraft, Hamburg, Germany, 16–18 June 1993; pp. 113–150. [Google Scholar]
- Hijazi, A.L. Residual Strength of Thin-Sheet Aluminum Panels with Multiple Site Damage. Ph.D. Thesis, Wichita State University, Wichita, KS, USA, 2002. [Google Scholar]
- Smith, B.L.; Saville, P.A.; Mouak, A.; Myose, R.Y. Strength of 2024-T3 Aluminum Panels with Multiple Site Damage. J. Aircr. 2000, 37, 325–331. [Google Scholar] [CrossRef]
- Smith, B.L.; Hijazi, A.L.; Haque, A.K.M.; Myose, R.Y. Strength of Stiffened 2024-T3 Aluminum Panels with Multiple Site Damage. J. Aircr. 2001, 38, 764–768. [Google Scholar] [CrossRef]
- Hijazi, A.L.; Smith, B.L.; Lacy, T.E. Linkup Strength of 2024-T3 Bolted Lap Joint Panels with Multiple Site Damage. J. Aircr. 2004, 41, 359–364. [Google Scholar] [CrossRef]
- Hijazi, A.L.; Lacy, T.E.; Smith, B.L. Comparison of Residual Strength Estimates for Bolted Lap-Joint Panels. J. Aircr. 2004, 41, 657–664. [Google Scholar] [CrossRef]
- Xu, W.; Wang, H.; Wu, X.; Zhang, X.; Bai, G.; Huang, X. A novel method for residual strength prediction for sheets with multiple site damage: Methodology and experimental validation. Int. J. Solids Struct. 2014, 51, 551–565. [Google Scholar] [CrossRef]
- Wu, S.; Zhou, X.-G.; Cao, G.-M.; Liu, Z.; Wang, G.-D. The improvement on constitutive modeling of Nb-Ti micro alloyed steel by using intelligent algorithms. Mater. Des. 2017, 116, 676–685. [Google Scholar] [CrossRef]
- Qiao, L.; Liu, Y.; Zhu, J. Application of generalized regression neural network optimized by fruit fly optimization algorithm for fracture toughness in a pearlitic steel. Eng. Fract. Mech. 2020, 235, 107105. [Google Scholar] [CrossRef]
- Candelieri, A.; Sormani, R.; Arosio, G.; Giordani, I.; Archetti, F. Assessing structural health of helicopter fuselage panels through artificial neural networks hierarchies. Int. J. Reliab. Saf. 2013, 7, 216. [Google Scholar] [CrossRef]
- Li, D.-C.; Chen, L.-S.; Lin, Y.-S. Using Functional Virtual Population as assistance to learn scheduling knowledge in dynamic manufacturing environments. Int. J. Prod. Res. 2003, 41, 4011–4024. [Google Scholar] [CrossRef]
- Shaikhina, T.; Khovanova, N.A. Handling limited datasets with neural networks in medical applications: A small-data approach. Artif. Intell. Med. 2017, 75, 51–63. [Google Scholar] [CrossRef]
- Mao, R.; Zhu, H.; Zhang, L.; Chen, A.; Zhu, R.M.H. A New Method to Assist Small Data Set Neural Network Learning. In Proceedings of the Sixth International Conference on Intelligent Systems Design and Applications, Jinan, China, 16–18 October 2006; Volume 1, pp. 17–22. [Google Scholar]
- Thomson, D.; Hoadley, D.; McHatton, J. Load Tests of Flat and Curved Panels with Multiple Cracks; Foster-Miller Draft Final Report; FAA Technical Center: Egg Harbor Township, NJ, USA, 1993. [Google Scholar]
- Dewit, R.; Fields, R.J.; Mordfin, L.; Low, S.R.; Harne, D. Fracture Behavior of Large-Scale Thin-Sheet Aluminum Alloy; NIST Technical Report 5661; NIST: Gaithersburg, MD, USA, 1995.
- Anderson, T.L. Fracture Mechanics: Fundamentals and Applications; CRC Press: Boca Raton, FL, USA, 2017. [Google Scholar]
- Smith, B.L.; Hijazi, A.L.; Myose, R.Y. Strength of 7075-T6 and 2024-T3 Aluminum Panels with Multiple-Site Damage. J. Aircr. 2002, 39, 354–358. [Google Scholar] [CrossRef]
- Smith, B.L.; Flores, T.L.Z.; Hijazi, A.L. Link-Up Strength of 2524-T3 and 2024-T3 Aluminum Panels with Multiple Site Damage. J. Aircr. 2005, 42, 535–541. [Google Scholar] [CrossRef]
- Dandy, G.; Maier, H.R. Review of Input Variable Selection Methods for Artificial Neural Networks. Artif. Neural Netw. Methodol. Adv. Biomed. Appl. 2011, 10, 16004. [Google Scholar] [CrossRef]
- Bowden, G.J.; Dandy, G.C.; Maier, H.R. Input determination for neural network models in water resources applications. Part 1—Background and methodology. J. Hydrol. 2005, 301, 75–92. [Google Scholar] [CrossRef]
- May, R.; Dandy, G.C.; Maier, H.R.; Nixon, J.B. Application of partial mutual information variable selection to ANN forecasting of water quality in water distribution systems. Environ. Model. Softw. 2008, 23, 1289–1299. [Google Scholar] [CrossRef]
- Li, K.; Hu, C.; Liu, G.; Xue, W. Building’s electricity consumption prediction using optimized artificial neural networks and principal component analysis. Energy Build. 2015, 108, 106–113. [Google Scholar]
- Yang, C.; Kim, Y.; Ryu, S.; Gu, G.X. Prediction of composite microstructure stress-strain curves using convolutional neural networks. Mater. Des. 2020, 189, 108509. [Google Scholar] [CrossRef]
- Yu, S.; Chou, K. Integration of independent component analysis and neural networks for ECG beat classification. Expert Syst. Appl. 2008, 34, 2841–2846. [Google Scholar] [CrossRef]
- Yadav, A.K.; Malik, H.; Chandel, S. Selection of most relevant input parameters using WEKA for artificial neural network based solar radiation prediction models. Renew. Sustain. Energy Rev. 2014, 31, 509–519. [Google Scholar] [CrossRef]
- Dolara, A.; Grimaccia, F.; Leva, S.; Mussetta, M.; Ogliari, E. A Physical Hybrid Artificial Neural Network for Short Term Forecasting of PV Plant Power Output. Energies 2015, 8, 1138–1153. [Google Scholar] [CrossRef]
- US Department of Defense. Handbook: Metallic Materials and Elements for Aerospace Vehicle Structures; Military Handbook No. MIL-HDBK-5H, Section 5; US Department of Defense: Arlington, VA, USA, 1998.
- Bendat, J.S.; Piersol, A.G. Random Data: Analysis and Measurement Procedures; John Wiley & Sons: Hoboken, NJ, USA, 2011. [Google Scholar]
- Poe, C., Jr. Stress Intensity Factor for a Cracked Sheet with Riveted and Uniformly Spaced Stringers; NASA/TR 1971, R-358; NASA: Washington, DC, USA, 1985.
- Rooke, D.P.; Cartwright, D.J. Compendium of Stress Intensity Factors; Ministry of Defence: London, UK, 1976.
- Swift, T. Fracture Analysis of Stiffened Structure. In Damage Tolerance of Metallic Structures: Analysis Methods and Applications; ASTM International: West Conshohocken, PA, USA, 1984. [Google Scholar]
- Baghirli, O. Comparison of Lavenberg-Marquardt, Scaled Conjugate Gradient and Bayesian Regularization Backpropagation Algorithms for Multistep Ahead Wind Speed Forecasting Using Multilayer Perceptron Feedforward Neural Network. Master’s Thesis, Uppsala University, Uppsala, Sweden, 2015. [Google Scholar]
- Peters, S.O.; Sinecen, M.; Gallagher, G.R.; Pebworth, L.A.; Hatfield, J.S.; Kizilkaya, K. 1690 Comparison of linear model and artificial neural network using antler beam diameter and beam length of white-tailed deer (Odocoileus virginianus). J. Anim. Sci. 2016, 94, 823–824. [Google Scholar] [CrossRef]
- Al-Dahidi, S.; Ayadi, O.; Adeeb, J.; Louzazni, M. Assessment of Artificial Neural Networks Learning Algorithms and Training Datasets for Solar Photovoltaic Power Production Prediction. Front. Energy Res. 2019, 7, 130. [Google Scholar] [CrossRef]
- Arora, M.; Ashraf, F.; Saxena, V.; Mahendru, G.; Kaushik, M.; Shubham, P. A Neural Network-Based Comparative Analysis of BR, LM, and SCG Algorithms for the Detection of Particulate Matter. In Advances in Interdisciplinary Engineering; Springer: Singapore, 2019; pp. 619–634. [Google Scholar]
- Hagan, M.T.; Demuth, H.B.; Beale, M.H. Neural Network ToolboxTM 6 User’s Guide; MathWorks: Natick, MA, USA, 2015. [Google Scholar]
- Olden, J.D.; Jackson, D.A. Illuminating the “black box”: A randomization approach for understanding variable contributions in artificial neural networks. Ecol. Model. 2002, 154, 135–150. [Google Scholar] [CrossRef]
- Ibrahim, O.M. A comparison of methods for assessing the relative importance of input variables in artificial neural networks. J. Appl. Sci. Res. 2013, 9, 5692–5700. [Google Scholar]








| Assistance Level | AP1 | AP2 |
|---|---|---|
| 1 | βP-config | - |
| 2 | βa | - |
| 3 | βa | βℓ |
| 4 | σLU | - |
| Scenario | BR | LM | SGC | ||||||
|---|---|---|---|---|---|---|---|---|---|
| MAEP [%] | RSMEP [%] | R2 [%] | MAEP [%] | RSMEP [%] | R2 [%] | MAEP [%] | RSMEP [%] | R2 [%] | |
| Traditional | 3.8 | 5.51 | 92.39 | 5.59 | 7.89 | 81.19 | 7.65 | 10.33 | 75.94 |
| Assisted 1 | 3.76 | 5.42 | 92.61 | 5.56 | 7.92 | 84.56 | 6.41 | 8.67 | 83.32 |
| Assisted 2 | 3.45 | 5.04 | 93.16 | 4.86 | 6.8 | 87.89 | 6.05 | 8.16 | 84.49 |
| Assisted 3 | 3.13 | 4.26 | 95.14 | 4.42 | 6.17 | 89.85 | 5.52 | 7.22 | 87.96 |
| Assisted 4 | 2.97 | 4.07 | 96.21 | 3.31 | 4.2 | 96.04 | 4.13 | 5.48 | 92.9 |
| Scenario | Reduced 1 (48) | Reduced 2 (35) | Reduced 3 (22) | ||||||
|---|---|---|---|---|---|---|---|---|---|
| MAEP [%] | RSMEP [%] | R2 [%] | MAEP [%] | RSMEP [%] | R2 [%] | MAEP [%] | RSMEP [%] | R2 [%] | |
| Traditional | 4.68 | 6.52 | 88.73 | 5.55 | 7.52 | 85.77 | 6.86 | 9.54 | 80.97 |
| Assisted 1 | 4.67 | 6.61 | 89.59 | 5.1 | 7.01 | 87.65 | 4.51 | 5.93 | 90.24 |
| Assisted 2 | 4.16 | 5.82 | 91.46 | 4.65 | 6.32 | 90.2 | 4.52 | 5.92 | 90.97 |
| Assisted 3 | 3.55 | 4.88 | 93.91 | 3.84 | 5.33 | 92.85 | 4.63 | 6.21 | 91.64 |
| Assisted 4 | 3.46 | 4.54 | 95.21 | 3.46 | 4.52 | 95.16 | 4.26 | 5.83 | 92.81 |
| Scenario | Direct Independent Inputs | Assistance Input Parameters | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| a | l | L | W | Astf | σy | Config ID | βP-config | βa | βℓ | σLU | |
| Traditional | 2 | 4 | 1 | 7 | 6 | 5 | 3 | - | - | - | - |
| Assisted 1 | 1 | 4 | 2 | 6 | 8 | 5 | 7 | 3 | - | - | - |
| Assisted 2 | 1 | 6 | 2 | 7 | 8 | 4 | 5 | - | 3 | - | - |
| Assisted 3 | 3 | 5 | 4 | 9 | 7 | 6 | 8 | - | 1 | 2 | - |
| Assisted 4 | 8 | 4 | 2 | 5 | 6 | 7 | 3 | - | - | - | 1 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hijazi, A.; Al-Dahidi, S.; Altarazi, S. A Novel Assisted Artificial Neural Network Modeling Approach for Improved Accuracy Using Small Datasets: Application in Residual Strength Evaluation of Panels with Multiple Site Damage Cracks. Appl. Sci. 2020, 10, 8255. https://doi.org/10.3390/app10228255
Hijazi A, Al-Dahidi S, Altarazi S. A Novel Assisted Artificial Neural Network Modeling Approach for Improved Accuracy Using Small Datasets: Application in Residual Strength Evaluation of Panels with Multiple Site Damage Cracks. Applied Sciences. 2020; 10(22):8255. https://doi.org/10.3390/app10228255
Chicago/Turabian StyleHijazi, Ala, Sameer Al-Dahidi, and Safwan Altarazi. 2020. "A Novel Assisted Artificial Neural Network Modeling Approach for Improved Accuracy Using Small Datasets: Application in Residual Strength Evaluation of Panels with Multiple Site Damage Cracks" Applied Sciences 10, no. 22: 8255. https://doi.org/10.3390/app10228255
APA StyleHijazi, A., Al-Dahidi, S., & Altarazi, S. (2020). A Novel Assisted Artificial Neural Network Modeling Approach for Improved Accuracy Using Small Datasets: Application in Residual Strength Evaluation of Panels with Multiple Site Damage Cracks. Applied Sciences, 10(22), 8255. https://doi.org/10.3390/app10228255