Using Common Spatial Patterns to Select Relevant Pixels for Video Activity Recognition

 , , ,
, , , 
Abstract
1. Introduction
2. Related Work
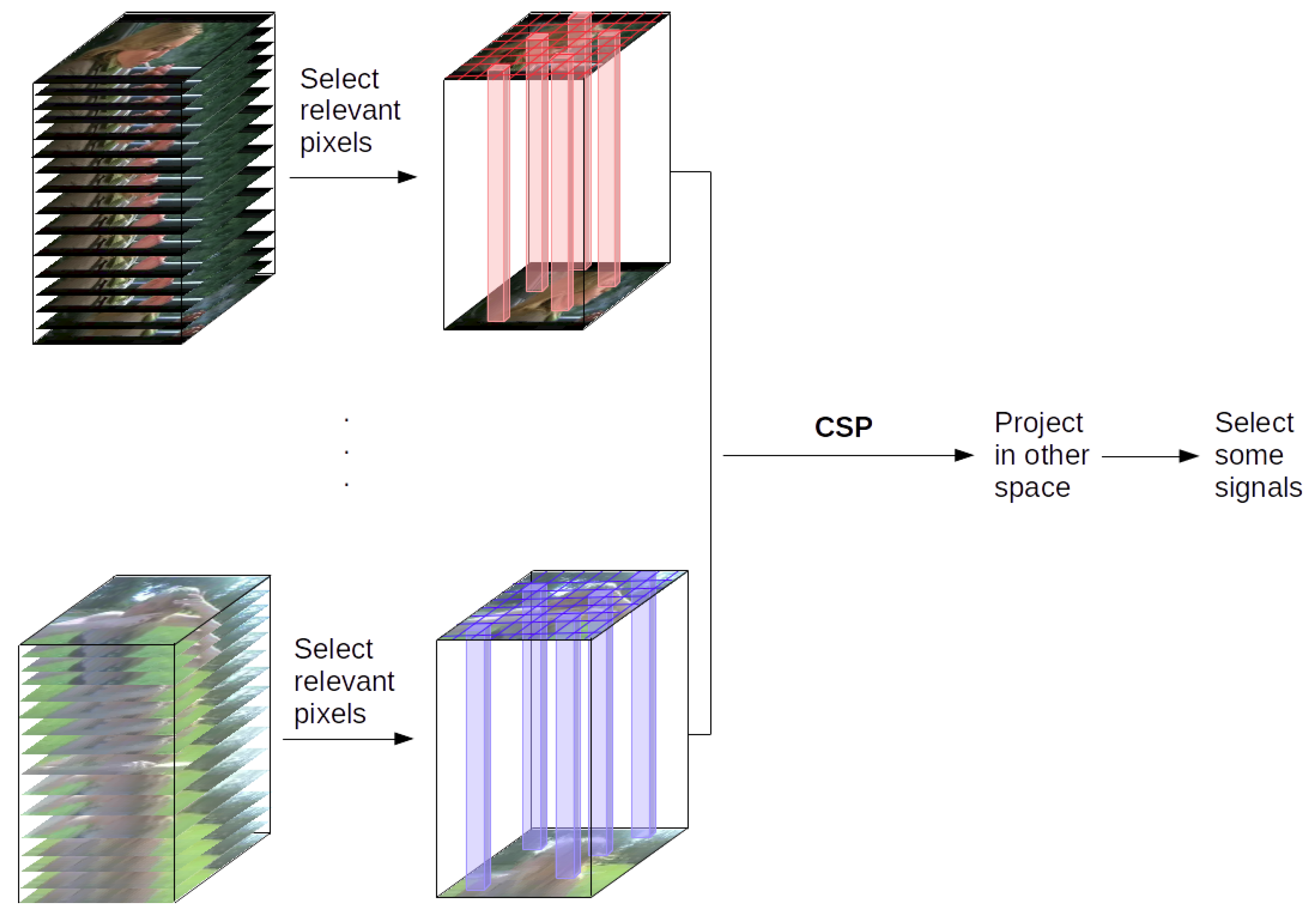
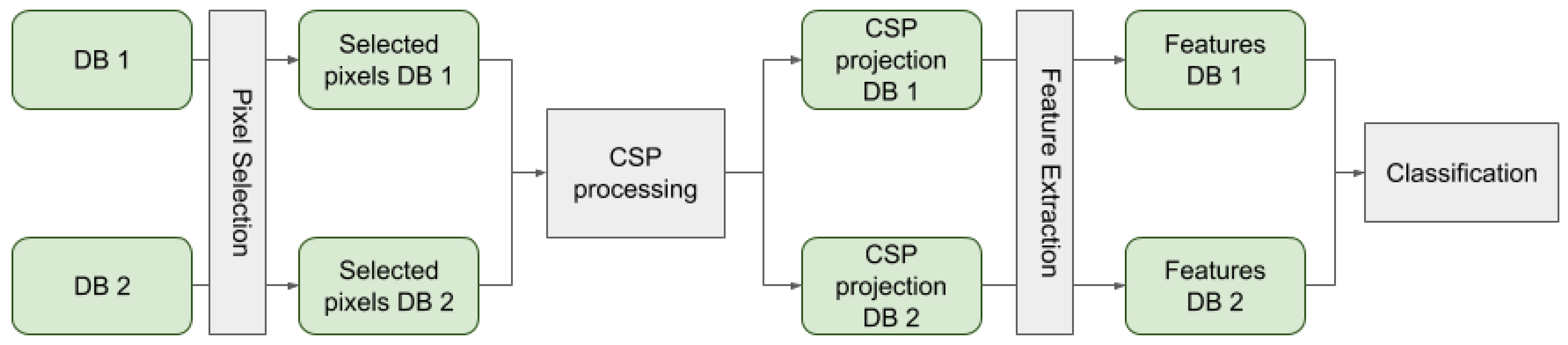
3. CSP-Based Approach
4. Experimental Setup
- General facial actions: smiling, laughing, chewing, talking.
- Facial actions with object manipulation: smoking, eating, drinking.
- General body movements: cartwheeling, clapping hands, climbing, going up stairs, diving, falling down, backhand flipping, handstanding, jumping, pull-ups, push-ups, running, sitting down, sitting up, somersaulting, standing up, turning, walking, waving.
- Body movements with object interaction: brushing hair, catching, drawing a sword, dribbling, playing golf, hitting something, kicking a ball, picking something, pouring, pushing something, riding a bike, riding a horse, shooting a ball, shooting a bow, shooting a gun, swinging a baseball bat, drawing sword, throwing.
- Body movements for human interaction: fencing, hugging, kicking someone, kissing, punching, shaking hands, sword fighting.
4.1. Experiments
Modalities
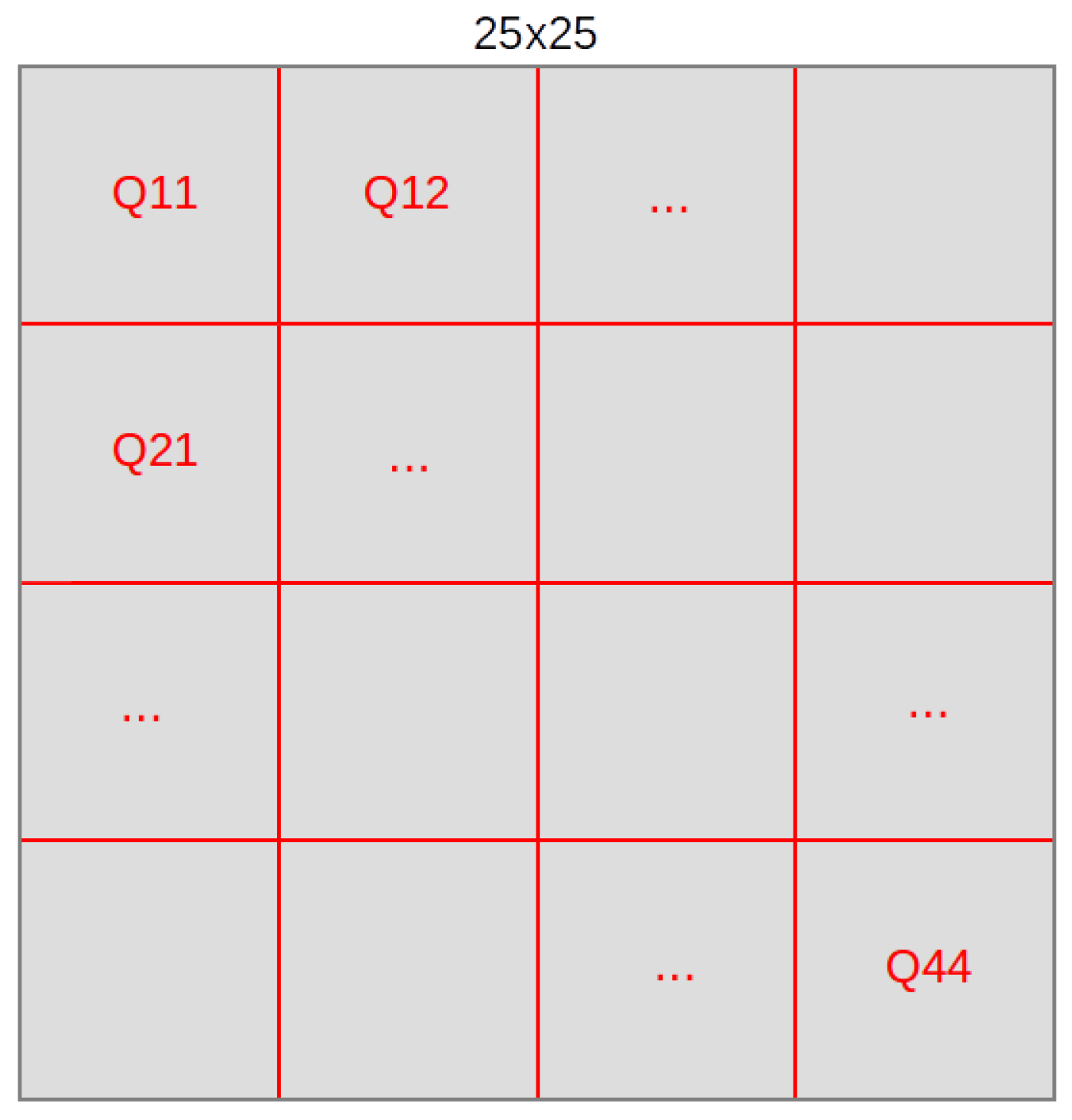
- Separation in quadrants.Taking into account that different actions have to be recognized, where in the video they occur should be taken into account, that is, in which area of the window. In many of the sequences used, the camera is static and the individuals performing the interaction appear almost centered. In these cases, it can be supposed that if the action they are performing is, for instance, smoke, it will be happening at the top of the images, while if the action is kick, it will be happening at the bottom part. In order to consider this approach, it was decided to divide each frame of the video in 16 quadrants as can be seen in Figure 3, and perform the whole classification pipeline for every one of them. Thus, each classifier focuses on an exact area of the videos. The final prediction is the result of the majority voting of these 16 classifiers.
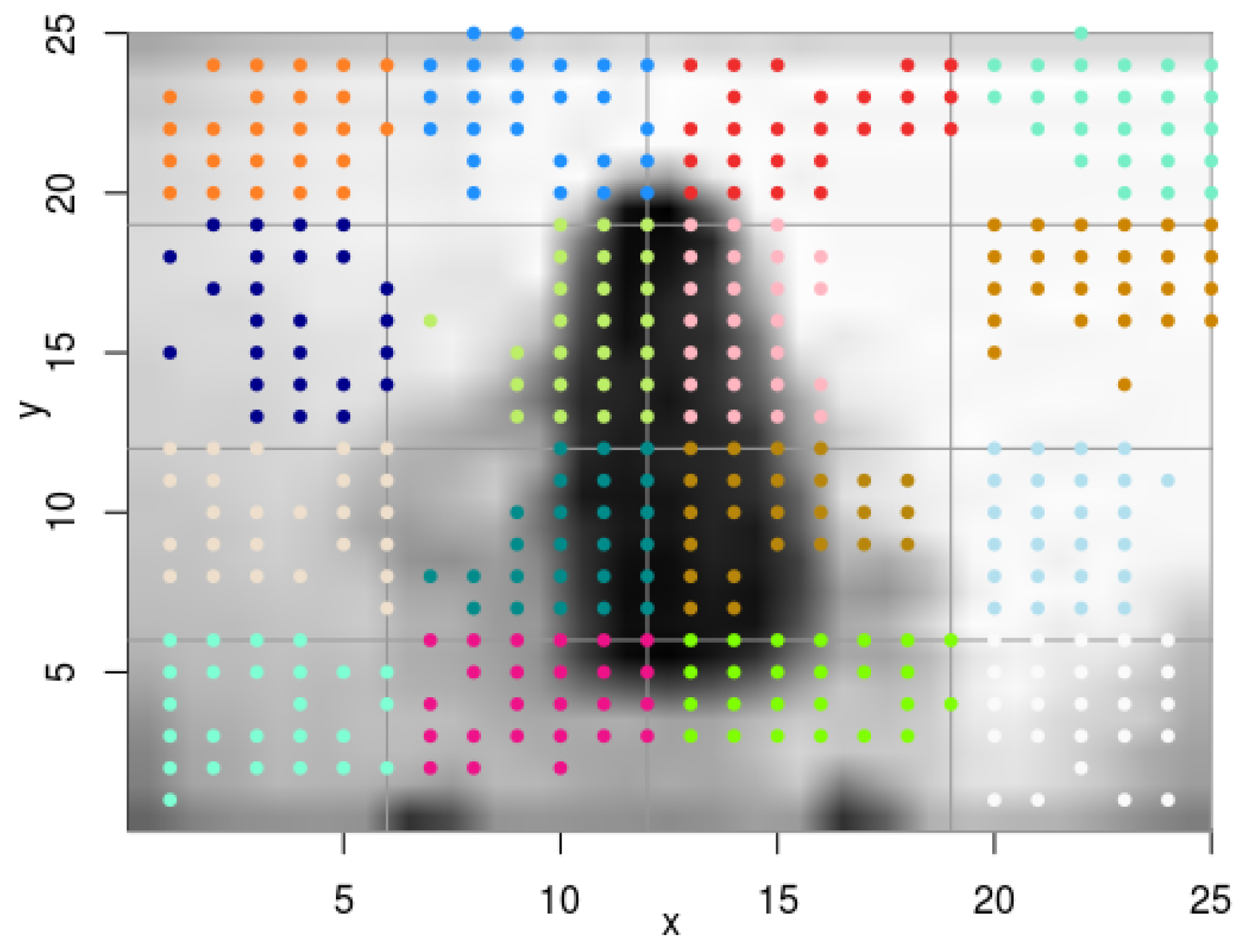
- Pixels with maximum variance.CSP works with the variance of each channel. In some of the video sequences some objects from the scene, such as the background, are static, and do not change over time. The pixels corresponding to these static areas will produce a zero (or near zero, due to random fluctuations in pixel intensity) variance. This, apart from not providing useful information, can cause some problems at the time of executing the algorithm due to the calculation of the logarithm of the variances in the computation of CSP, yielding negative infinite values. In this case, it was decided to first select a group of pixels to extract the features, these are the pixels that change the most over time and therefore have the maximum variances. The hypothesis here is that they are the best candidates to represent the performed action. To select these pixels, the frames were transformed to grayscale, in order to have just one channel when calculating the variance of each pixel. In Figure 4 an example can be seen, where the 25 most relevant pixels have been selected for each quadrant.
- var
- var, min, max, IQR taken together
4.2. Optical Flow
5. Experimental Results
- HOF: the results obtained with the optical flow vectors as features.
- Variance: after calculating the CSP, only the variances are taken as features.
- (a)
- q = 3 : 6 (2*q) variance values are used.
- (b)
- q = 5 : 10 (2*q) variance values are used.
- (c)
- q = 10 : 20 (2*q) variance values are used.
- More info: after calculating the CSP, apart from the variances, the minimum, the maximum and the IQR values of the curve are also taken as features.
- (a)
- q = 3 : 6 (2*q) variance values are used, plus three additional features (min, max, IQR).
- (b)
- q = 5 : 10 (2*q) variance values are used, plus three additional features (min, max, IQR).
- (c)
- q = 10 : 20 (2*q) variance values are used, plus three additional features (min, max, IQR).
Comparison
- Being a data table with m rows and n columns, is calculated where is the order of in every block i.
- Then, the statistic is calculated:
- Finally, the p-value is defined this way, approximating the probability distribution of Q by a distribution:
- H0: there is no difference between the tested models ⇔p-value
- H1: at least 2 of the tested models are different from each other ⇔p-value
- CSP3-LDA and HOF-LDA, p-value .
- CSP5-LDA and HOF-LDA, p-value .
- CSP10-LDA and HOF-LDA, p-value .
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Rodríguez-Moreno, I.; Martínez-Otzeta, J.M.; Goienetxea, I.; Rodriguez-Rodriguez, I.; Sierra, B. Shedding Light on People Action Recognition in Social Robotics by Means of Common Spatial Patterns. Sensors 2020, 20, 2436. [Google Scholar] [CrossRef] [PubMed]
- Astigarraga, A.; Arruti, A.; Muguerza, J.; Santana, R.; Martin, J.I.; Sierra, B. User adapted motor-imaginary brain-computer interface by means of EEG channel selection based on estimation of distributed algorithms. Math. Prob. Eng. 2016, 2016, 1435321. [Google Scholar] [CrossRef]
- Fisher, R.A. The use of multiple measurements in taxonomic problems. Ann. Eugen. 1936, 7, 179–188. [Google Scholar] [CrossRef]
- Cover, T.; Hart, P. Nearest neighbor pattern classification. IEEE Trans. Inf. Theory 1967, 13, 21–27. [Google Scholar] [CrossRef]
- Ho, T.K. Random decision forests. In Proceedings of the 3rd International Conference on Document Analysis and Recognition, Montreal, QC, Canada, 14–16 August 1995; Volume 1, pp. 278–282. [Google Scholar]
- Ke, S.R.; Thuc, H.L.U.; Lee, Y.J.; Hwang, J.N.; Yoo, J.H.; Choi, K.H. A review on video-based human activity recognition. Computers 2013, 2, 88–131. [Google Scholar] [CrossRef]
- Rodríguez-Moreno, I.; Martínez-Otzeta, J.M.; Sierra, B.; Rodriguez, I.; Jauregi, E. Video activity recognition: State-of-the-art. Sensors 2019, 19, 3160. [Google Scholar] [CrossRef] [PubMed]
- Aggarwal, J.K.; Xia, L. Human activity recognition from 3d data: A review. Pattern Recognit. Lett. 2014, 48, 70–80. [Google Scholar] [CrossRef]
- Bregonzio, M.; Gong, S.; Xiang, T. Recognising action as clouds of space-time interest points. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 1948–1955. [Google Scholar]
- Nazir, S.; Yousaf, M.H.; Velastin, S.A. Evaluating a bag-of-visual features approach using spatio-temporal features for action recognition. Comput. Electr. Eng. 2018, 72, 660–669. [Google Scholar] [CrossRef]
- Chakraborty, B.; Holte, M.B.; Moeslund, T.B.; Gonzàlez, J. Selective spatio-temporal interest points. Comput. Vis. Image Underst. 2012, 116, 396–410. [Google Scholar] [CrossRef]
- Wang, J.; Liu, Z.; Chorowski, J.; Chen, Z.; Wu, Y. Robust 3d action recognition with random occupancy patterns. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2012; pp. 872–885. [Google Scholar]
- Arivazhagan, S.; Shebiah, R.N.; Harini, R.; Swetha, S. Human action recognition from RGB-D data using complete local binary pattern. Cogn. Syst. Res. 2019, 58, 94–104. [Google Scholar] [CrossRef]
- Wang, H.; Kläser, A.; Schmid, C.; Liu, C.L. Action recognition by dense trajectories. In Proceedings of the CVPR 2011, Providence, RI, USA, 20–25 June 2011; pp. 3169–3176. [Google Scholar]
- Wang, H.; Schmid, C. Action recognition with improved trajectories. In Proceedings of the IEEE International Conference on Computer Vision, Sydney, Australia, 1–8 December 2013; pp. 3551–3558. [Google Scholar]
- Jain, M.; Jegou, H.; Bouthemy, P. Better exploiting motion for better action recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 2555–2562. [Google Scholar]
- Simonyan, K.; Zisserman, A. Two-stream convolutional networks for action recognition in videos. In Advances in Neural Information Processing Systems; ACM: New York, NY, USA, 2014; pp. 568–576. [Google Scholar]
- Ullah, A.; Ahmad, J.; Muhammad, K.; Sajjad, M.; Baik, S.W. Action recognition in video sequences using deep bi-directional LSTM with CNN features. IEEE Access 2017, 6, 1155–1166. [Google Scholar] [CrossRef]
- Dai, C.; Liu, X.; Lai, J. Human action recognition using two-stream attention based LSTM networks. Appl. Soft Comput. 2020, 86, 105820. [Google Scholar] [CrossRef]
- Fukunaga, K.; Koontz, W.L. Application of the Karhunen-Loève Expansion to Feature Selection and Ordering. IEEE Trans. Comput. 1970, C-99, 311–318. [Google Scholar]
- Ramoser, H.; Muller-Gerking, J.; Pfurtscheller, G. Optimal spatial filtering of single trial EEG during imagined hand movement. IEEE Trans. Rehabil. Eng. 2000, 8, 441–446. [Google Scholar] [CrossRef] [PubMed]
- Wang, Y.; Gao, S.; Gao, X. Common spatial pattern method for channel selection in motor imagery based brain-computer interface. In Proceedings of the 2005 IEEE Engineering in Medicine and Biology 27th Annual Conference, Shanghai, China, 17–18 January 2006; pp. 5392–5395. [Google Scholar]
- Novi, Q.; Guan, C.; Dat, T.H.; Xue, P. Sub-band common spatial pattern (SBCSP) for brain-computer interface. In Proceedings of the 2007 3rd International IEEE/EMBS Conference on Neural Engineering, Kohala Coast, HI, USA, 2–5 May 2007; pp. 204–207. [Google Scholar]
- Alotaiby, T.N.; Alshebeili, S.A.; Aljafar, L.M.; Alsabhan, W.M. ECG-based subject identification using common spatial pattern and SVM. J. Sens. 2019, 2019, 8934905. [Google Scholar] [CrossRef]
- Kim, P.; Kim, K.S.; Kim, S. Using common spatial pattern algorithm for unsupervised real-time estimation of fingertip forces from sEMG signals. In Proceedings of the 2015 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Hamburg, Germany, 28 September–2 October 2015; pp. 5039–5045. [Google Scholar]
- Li, X.; Fang, P.; Tian, L.; Li, G. Increasing the robustness against force variation in EMG motion classification by common spatial patterns. In Proceedings of the 2017 39th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Seogwipo, Korea, 11–15 July 2017; pp. 406–409. [Google Scholar]
- Shapiro, J.; Savransky, D.; Ruffio, J.B.; Ranganathan, N.; Macintosh, B. Detecting Planets from Direct-imaging Observations Using Common Spatial Pattern Filtering. Astron. J. 2019, 158, 125. [Google Scholar] [CrossRef]
- Kuehne, H.; Jhuang, H.; Garrote, E.; Poggio, T.; Serre, T. HMDB: A large video database for human motion recognition. In Proceedings of the International Conference on Computer Vision (ICCV), Barcelona, Spain, 6–13 November 2011. [Google Scholar]
- Mendialdua, I.; Martínez-Otzeta, J.M.; Rodriguez-Rodriguez, I.; Ruiz-Vazquez, T.; Sierra, B. Dynamic selection of the best base classifier in one versus one. Knowl. Based Syst. 2015, 85, 298–306. [Google Scholar] [CrossRef]
- Farnebäck, G. Two-frame motion estimation based on polynomial expansion. In Scandinavian Conference on Image Analysis; Springer: Berlin/Heidelberg, Germany, 2003; pp. 363–370. [Google Scholar]
- Nemenyi, P. Distribution-free multiple comparisons (Doctoral Dissertation, Princeton University, 1963). Diss. Abstr. Int. 1963, 25, 1233. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Videos | Frames/Video | Frames/Class | |
|---|---|---|---|
| Brush hair | 107 | 648 | 69,336 |
| Fencing | 116 | 301 | 34,916 |
| Walk | 282 | 534 | 150,588 |
| Punch | 126 | 502 | 63,252 |
| Smoke | 109 | 445 | 48,505 |
| Cartwheel | 103 | 132 | 13,596 |
| KNN | Fencing | Walk | Punch | Smoke | Cartwheel |
|---|---|---|---|---|---|
| Brush_hair | HOF: 0.7424 | HOF: 0.7679 | HOF: 0.8125 | HOF: 0.5606 | HOF: 0.8915 |
| Variance: | Variance: | Variance: | Variance: | Variance: | |
| q = 3: 0.8730 | q = 3: 0.7857 | q = 3: 0.8016 | q = 3: 0.7143 | q = 3: 0.9683 | |
| q = 5: 0.8492 | q = 5: 0.7381 | q = 5: 0.8095 | q = 5: 0.7460 | q = 5: 0.9603 | |
| q = 10: 0.8492 | q = 10: 0.7778 | q = 10: 0.8095 | q = 10: 0.7460 | q = 10: 0.9762 | |
| More info: | More info: | More info: | More info: | More info: | |
| q = 3: 0.8889 | q = 3: 0.7857 | q = 3: 0.8174 | q = 3: 0.7222 | q = 3: 0.9921 | |
| q = 5: 0.8809 | q = 5: 0.7540 | q = 5: 0.7778 | q = 5: 0.7301 | q = 5: 0.9524 | |
| q = 10: 0.8810 | q = 10: 0.7619 | q = 10: 0.7778 | q = 10: 0.7460 | q = 10: 0.9365 | |
| Fencing | HOF: 0.5865 | HOF: 0.7778 | HOF: 0.6212 | HOF: 0.8605 | |
| Variance: | Variance: | Variance: | Variance: | ||
| q = 3: 0.6594 | q = 3: 0.8043 | q = 3: 0.6742 | q = 3: 0.8254 | ||
| q = 5: 0.6812 | q = 5: 0.6667 | q = 5: 0.6364 | q = 5: 0.8571 | ||
| q = 10: 0.6304 | q = 10: 0.7246 | q = 10: 0.5454 | q = 10: 0.8571 | ||
| More info: | More info: | More info: | More info: | ||
| q = 3: 0.6739 | q = 3: 0.7681 | q = 3: 0.7273 | q = 3: 0.9127 | ||
| q = 5: 0.6739 | q = 5: 0.7464 | q = 5: 0.6364 | q = 5: 0.7698 | ||
| q = 10: 0.5797 | q = 10: 0.7681 | q = 10: 0.5303 | q = 10: 0.8333 | ||
| Walk | HOF: 0.6827 | HOF: 0.7637 | HOF: 0.8248 | ||
| Variance: | Variance: | Variance: | |||
| q = 3: 0.5800 | q = 3: 0.5530 | q = 3: 0.8174 | |||
| q = 5: 0.6600 | q = 5: 0.6061 | q = 5: 0.7857 | |||
| q = 10: 0.6067 | q = 10: 0.5682 | q = 10: 0.7222 | |||
| More info: | More info: | More info: | |||
| q = 3: 0.6333 | q = 3: 0.5303 | q = 3: 0.8016 | |||
| q = 5: 0.6867 | q = 5: 0.6818 | q = 5: 0.8174 | |||
| q = 10: 0.5800 | q = 10: 0.5000 | q = 10: 0.7778 | |||
| Punch | HOF: 0.6805 | HOF: 0.9078 | |||
| Variance: | Variance: | ||||
| q = 3: 0.5682 | q = 3: 0.8730 | ||||
| q = 5: 0.5757 | q = 5: 0.8651 | ||||
| q = 10: 0.5303 | q = 10: 0.8968 | ||||
| More info: | More info: | ||||
| q = 3: 0.6061 | q = 3: 0.8492 | ||||
| q = 5: 0.6364 | q = 5: 0.8730 | ||||
| q = 10: 0.5227 | q = 10: 0.8492 | ||||
| Smoke | HOF: 0.8295 | ||||
| Variance: | |||||
| q = 3: 0.7778 | |||||
| q = 5: 0.8016 | |||||
| q = 10: 0.7460 | |||||
| More info: | |||||
| q = 3: 0.8254 | |||||
| q = 5: 0.7619 | |||||
| q = 10: 0.7698 |
| LDA | Fencing | Walk | Punch | Smoke | Cartwheel |
|---|---|---|---|---|---|
| Brush_hair | HOF: 0.6591 | HOF: 0.6920 | HOF: 0.6180 | HOF: 0.6288 | HOF: 0.7752 |
| Variance: | Variance: | Variance: | Variance: | Variance: | |
| q = 3: 0.8492 | q = 3: 0.7143 | q = 3: 0.8333 | q = 3: 0.7460 | q = 3: 0.9365 | |
| q = 5: 0.7302 | q = 5: 0.7540 | q = 5: 0.8016 | q = 5: 0.7778 | q = 5: 0.9603 | |
| q = 10: 0.8809 | q = 10: 0.7698 | q = 10: 0.7699 | q = 10: 0.6826 | q = 10: 0.9365 | |
| More info: | More info: | More info: | More info: | More info: | |
| q = 3: 0.9445 | q = 3: 0.6984 | q = 3: 0.8174 | q = 3: 0.7699 | q = 3: 0.9921 | |
| q = 5: 0.9683 | q = 5: 0.7540 | q = 5: 0.7936 | q = 5: 0.7936 | q = 5: 0.9921 | |
| q = 10: 0.9683 | q = 10: 0.7857 | q = 10: 0.8016 | q = 10: 0.8254 | q = 10: 0.9921 | |
| Fencing | HOF: 0.6414 | HOF: 0.7083 | HOF: 0.7803 | HOF: 0.7984 | |
| Variance: | Variance: | Variance: | Variance: | ||
| q = 3: 0.6522 | q = 3: 0.7174 | q = 3: 0.6818 | q = 3: 0.8571 | ||
| q = 5: 0.6377 | q = 5: 0.6957 | q = 5: 0.6667 | q = 5: 0.8651 | ||
| q = 10: 0.6739 | q = 10: 0.7246 | q = 10: 0.6212 | q = 10: 0.9048 | ||
| More info: | More info: | More info: | More info: | ||
| q = 3: 0.8188 | q = 3: 0.8768 | q = 3: 0.8030 | q = 3: 0.9921 | ||
| q = 5: 0.7826 | q = 5: 0.9058 | q = 5: 0.7651 | q = 5: 0.9286 | ||
| q = 10: 0.8188 | q = 10: 0.8406 | q = 10: 0.8182 | q = 10: 0.9603 | ||
| Walk | HOF: 0.6546 | HOF: 0.6287 | HOF: 0.8889 | ||
| Variance: | Variance: | Variance: | |||
| q = 3: 0.6000 | q = 3: 0.5379 | q = 3: 0.7381 | |||
| q = 5: 0.6267 | q = 5: 0.5303 | q = 5: 0.7778 | |||
| q = 10: 0.6067 | q = 10: 0.6061 | q = 10: 0.7460 | |||
| More info: | More info: | More info: | |||
| q = 3: 0.7000 | q = 3: 0.6136 | q = 3: 0.9524 | |||
| q = 5: 0.6667 | q = 5: 0.7046 | q = 5: 0.9524 | |||
| q = 10: 0.5600 | q = 10: 0.6515 | q = 10: 0.9603 | |||
| Punch | HOF: 0.7847 | HOF: 0.9007 | |||
| Variance: | Variance: | ||||
| q = 3: 0.5757 | q = 3: 0.8969 | ||||
| q = 5: 0.6667 | q = 5: 0.9127 | ||||
| q = 10: 0.5076 | q = 10: 0.8413 | ||||
| More info: | More info: | ||||
| q = 3: 0.7046 | q = 3: 0.9841 | ||||
| q = 5: 0.7197 | q = 5: 0.9921 | ||||
| q = 10: 0.7273 | q = 10: 0.9445 | ||||
| Smoke | HOF: 0.7985 | ||||
| Variance: | |||||
| q = 3: 0.7778 | |||||
| q = 5: 0.7698 | |||||
| q = 10: 0.8412 | |||||
| More info: | |||||
| q = 3: 0.9841 | |||||
| q = 5: 0.9762 | |||||
| q = 10: 0.9683 |
| RF | Fencing | Walk | Punch | Smoke | Cartwheel |
|---|---|---|---|---|---|
| Brush_hair | HOF: 0.7576 | HOF: 0.8607 | HOF: 0.8680 | HOF: 0.6894 | HOF: 0.9535 |
| Variance: | Variance: | Variance: | Variance: | Variance: | |
| q = 3: 0.8413 | q = 3: 0.7540 | q = 3: 0.8095 | q = 3: 0.7143 | q = 3: 0.9286 | |
| q = 5: 0.8730 | q = 5: 0.6984 | q = 5: 0.8254 | q = 5: 0.6587 | q = 5: 0.9445 | |
| q = 10: 0.8651 | q = 10: 0.7698 | q = 10: 0.8254 | q = 10: 0.7302 | q = 10: 0.9445 | |
| More info: | More info: | More info: | More info: | More info: | |
| q = 3: 0.9683 | q = 3: 0.7460 | q = 3: 0.8492 | q = 3: 0.8016 | q = 3: 0.9841 | |
| q = 5: 0.9603 | q = 5: 0.7222 | q = 5: 0.8016 | q = 5: 0.7619 | q = 5: 0.9762 | |
| q = 10: 0.9445 | q = 10: 0.8174 | q = 10: 0.8254 | q = 10: 0.7857 | q = 10: 0.9762 | |
| Fencing | HOF: 0.7553 | HOF: 0.8889 | HOF: 0.8106 | HOF: 0.9380 | |
| Variance: | Variance: | Variance: | Variance: | ||
| q = 3: 0.7391 | q = 3: 0.7681 | q = 3: 0.7576 | q = 3: 0.8571 | ||
| q = 5: 0.7391 | q = 5: 0.7464 | q = 5: 0.7348 | q = 5: 0.8016 | ||
| q = 10: 0.7391 | q = 10: 0.7391 | q = 10: 0.8030 | q = 10: 0.8889 | ||
| More info: | More info: | More info: | More info: | ||
| q = 3: 0.9058 | q = 3: 0.8406 | q = 3: 0.8561 | q = 3: 0.9445 | ||
| q = 5: 0.8913 | q = 5: 0.8696 | q = 5: 0.8561 | q = 5: 0.8889 | ||
| q = 10: 0.9130 | q = 10: 0.9058 | q = 10: 0.8712 | q = 10: 0.8412 | ||
| Walk | HOF: 0.7912 | HOF: 0.7384 | HOF: 0.9103 | ||
| Variance: | Variance: | Variance: | |||
| q = 3: 0.6800 | q = 3: 0.4924 | q = 3: 0.8413 | |||
| q = 5: 0.6667 | q = 5: 0.6288 | q = 5: 0.8730 | |||
| q = 10: 0.6000 | q = 10: 0.5909 | q = 10: 0.7937 | |||
| More info: | More info: | More info: | |||
| q = 3: 0.6467 | q = 3: 0.6212 | q = 3: 0.9841 | |||
| q = 5: 0.6733 | q = 5: 0.6439 | q = 5: 0.9683 | |||
| q = 10: 0.6667 | q = 10: 0.5758 | q = 10: 0.9445 | |||
| Punch | HOF: 0.8403 | HOF: 0.9504 | |||
| Variance: | Variance: | ||||
| q = 3: 0.6742 | q = 3: 0.8651 | ||||
| q = 5: 0.7500 | q = 5: 0.8968 | ||||
| q = 10: 0.7348 | q = 10: 0.8492 | ||||
| More info: | More info: | ||||
| q = 3: 0.6894 | q = 3: 0.9841 | ||||
| q = 5: 0.7500 | q = 5: 0.9762 | ||||
| q = 10: 0.7424 | q = 10: 0.9841 | ||||
| Smoke | HOF: 0.8992 | ||||
| Variance: | |||||
| q = 3: 0.8095 | |||||
| q = 5: 0.9048 | |||||
| q = 10: 0.8730 | |||||
| More info: | |||||
| q = 3: 0.9445 | |||||
| q = 5: 0.9762 | |||||
| q = 10: 0.9762 |
| Variance | More Info | HOF | |||
|---|---|---|---|---|---|
| Best | Mean Best | Best | Mean Best | ||
| KNN | 0.7572 | 0.7355 | 0.7752 | 0.7503 | 0.754 |
| LDA | 0.7571 | 0.7273 | 0.85 | 0.8298 | 0.7305 |
| RF | 0.7902 | 0.7646 | 0.8567 | 0.8365 | 0.8435 |
| HOF-KNN | HOF-LDA | HOF-RF | |
|---|---|---|---|
| CSP3_var-KNN | 1.00000 | 1.00000 | 0.10176 |
| CSP3_var-LDA | 0.99995 | 1.00000 | 0.02410 |
| CSP3_var-RF | 1.00000 | 1.00000 | 0.23000 |
| CSP5_var-KNN | 1.00000 | 1.00000 | 0.08550 |
| CSP5_var-LDA | 1.00000 | 1.00000 | 0.04669 |
| CSP5_var-RF | 1.00000 | 0.99417 | 0.79919 |
| CSP10_var-KNN | 0.99995 | 1.00000 | 0.02410 |
| CSP10_var-LDA | 0.99980 | 1.00000 | 0.01651 |
| CSP10_var-RF | 1.00000 | 0.99594 | 0.77079 |
| CSP3-KNN | 1.00000 | 0.99345 | 0.80825 |
| CSP3-LDA | 0.33847 | 0.01115 | 1.00000 |
| CSP3-RF | 0.23807 | 0.00584 | 1.00000 |
| CSP5-KNN | 1.00000 | 1.00000 | 0.19239 |
| CSP5-LDA | 0.32851 | 0.01053 | 1.00000 |
| CSP5-RF | 0.50285 | 0.02541 | 1.00000 |
| CSP10-KNN | 0.95234 | 1.00000 | 0.00104 |
| CSP10-LDA | 0.39047 | 0.01478 | 1.00000 |
| CSP10-RF | 0.25475 | 0.00659 | 1.00000 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Rodríguez-Moreno, I.; Martínez-Otzeta, J.M.; Sierra, B.; Irigoien, I.; Rodriguez-Rodriguez, I.; Goienetxea, I. Using Common Spatial Patterns to Select Relevant Pixels for Video Activity Recognition. Appl. Sci. 2020, 10, 8075. https://doi.org/10.3390/app10228075
Rodríguez-Moreno I, Martínez-Otzeta JM, Sierra B, Irigoien I, Rodriguez-Rodriguez I, Goienetxea I. Using Common Spatial Patterns to Select Relevant Pixels for Video Activity Recognition. Applied Sciences. 2020; 10(22):8075. https://doi.org/10.3390/app10228075
Chicago/Turabian StyleRodríguez-Moreno, Itsaso, José María Martínez-Otzeta, Basilio Sierra, Itziar Irigoien, Igor Rodriguez-Rodriguez, and Izaro Goienetxea. 2020. "Using Common Spatial Patterns to Select Relevant Pixels for Video Activity Recognition" Applied Sciences 10, no. 22: 8075. https://doi.org/10.3390/app10228075
APA StyleRodríguez-Moreno, I., Martínez-Otzeta, J. M., Sierra, B., Irigoien, I., Rodriguez-Rodriguez, I., & Goienetxea, I. (2020). Using Common Spatial Patterns to Select Relevant Pixels for Video Activity Recognition. Applied Sciences, 10(22), 8075. https://doi.org/10.3390/app10228075