1. Introduction
According to the website
www.top500.org, the supercomputer Fugaku from the Fujitsu RIKEN Center for Computational Science in Japan consists of 7,299,072 processing units. The above gives an outstanding parallel computing power. However, without accurate and efficient scheduling methods, parallel programs can be very computationally inefficient. In this paper, we approach the precedence-constraint task scheduling of parallel programs on systems formed by heterogeneous processing units to minimize the final computing time [
1]. Scheduling is a well-known NP-hard optimization problem [
2], as well as the task scheduling for parallel systems [
3]. Therefore, different scheduling approaches were developed for this problem: Heuristics [
4,
5,
6,
7], Local Searches [
8,
9,
10], and Metaheuristics [
11,
12,
13,
14,
15]. Unfortunately, the wide variety of works in the state-of-the-art differs in their objective definitions and uses different sets of instances. From the relevant works in the state-of-the-art, we highlight [
11]. To our knowledge, it is the only work that compares the obtained results against the optimal values for their synthetic instances, which are fourteen scheduling problem instances that are easily reproducible. In [
11], four high-performance Iterated Local Search (ILS) algorithms are proposed, the best ILS nearly reaches all the optimal values, obtaining an approximation factor of 1.018 (desirable values are near to 1.0). Thus, we assess our proposal with the best-proposed algorithm in [
11].
Scheduling precedence-constraint tasks for heterogeneous systems has been addressed with a lot of variants: energy-aware [
16], idle energy-aware [
8,
17], energy constraint [
18], communication delays and energy [
19], budget constraint [
20], fault-tolerant [
21], security-aware [
22], volunteer computing systems [
23], among others. A related problem is the job shop problem [
24]. However, in a parallel program, scheduling is a single job (the parallel program) without dedicated machines to a single task. On the other hand, in scheduling, any machine can compute any task, similar to the job shop’s flexible problem [
25] but with a single job. In
Section 2, we detail our studied version of scheduling precedence-constraint tasks on heterogeneous systems.
In this paper, we use a recent metaheuristic optimization framework called Cellular Processing Algorithm (CPA) [
26,
27]. CPAs are more like a framework than a strict algorithm. The main idea is to cycle between exploring the search space with multiple limited-effort algorithms (Processing Cells) and sharing information (communication) among these Processing Cells. The limited-effort algorithms can explore the search space independently from one another and communicate their findings using shared memory or other combining methods. However, despite the communication, the Processing Cells should keep looking independently and not as a whole algorithm. In this way, we avoid the computational cost of converging the whole population (when the solutions reach the same search space area) or exploring the search space with a single solution algorithm (like Greedy Randomized Adaptive Search Procedure (GRASP) or Iterated Local Search).
As stated before, CPAs are flexible, e.g., a cellular processing algorithm can initialize each Processing Cell with different heuristics to ensure the splitting of the search space among the Processing Cells [
28]. Additionally, the Processing Cells can be homogeneous or heterogeneous, which means that the Processing Cells can be multiple instances of the same algorithm [
29] or completely different algorithms [
30]. Furthermore, we can create a soft-heterogeneous CPA with differently-configured instances of the same algorithm. Thus, with all its flexibility, there is still much to research for CPAs and its applications.
The remainder of the paper is organized as follows.
Section 2 details the studied precedence-constraint task scheduling problem on heterogeneous systems. In
Section 3, we introduce the related and proposed algorithms for our experimentation.
Section 4 contains the experimental setup, and parameter settings.
Section 5 analyzes the experimental results according to the achieved median values using non-parametric statistical tests. Finally,
Section 6 gives our conclusions and future work on scheduling precedence-constraint tasks on heterogeneous systems and the Cellular Processing Algorithms.
2. Problem Description
The High-Performance Computing systems (HPC) addressed in this paper consist of a set of heterogeneous machines M completely interconnected. Every machine has different hardware characteristics, which yields different processing times for the same task. Without loss of generality, we make the following assumptions:
Every machine has a connection link with any other machine.
The communication links have no conflicts.
All the communication links operate at the same speed.
Every machine can send/receive information to/from another while executing a task.
The communication cost between tasks in the same machine is depreciated.
2.1. Instance of the Problem
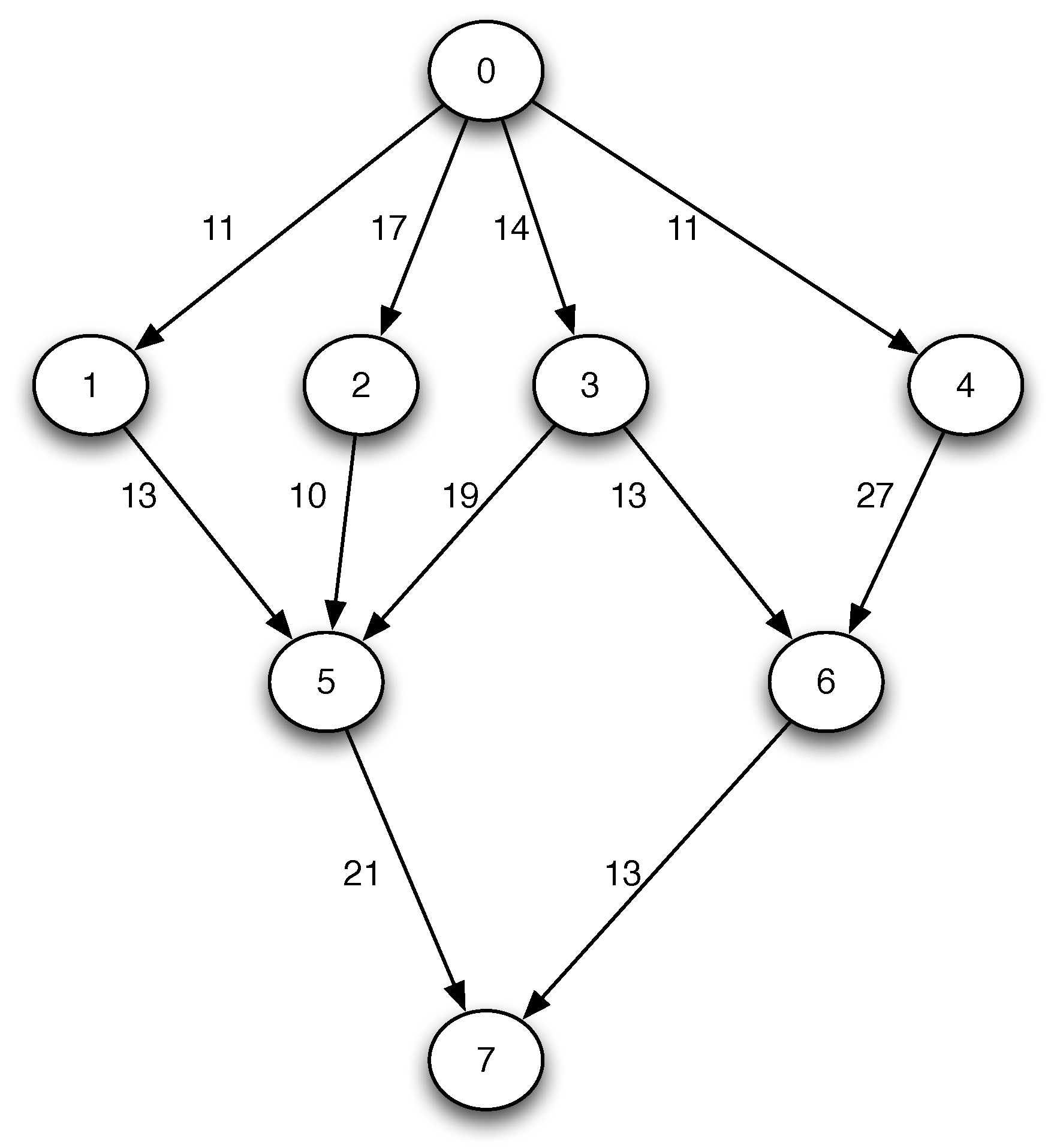
An instance of the problem is made up of two parts, a Directed Acyclic Graph (DAG) and the computation cost of the tasks in every machine. We represent the set of tasks of a parallel computing program and their precedencies as a DAG. Therefore, the parallel program is represented as the graph
where
T is the set of tasks (vertices) and
C is the set of communication costs between tasks (edges) (see
Figure 1). The complete instance of the problem is formed by
G and the computational costs
of each task
in every machine
(see
Table 1).
Any task cannot be initiated until its precedent tasks finalize their executions and communications . However, when any pair of tasks are scheduled in the same machine, the actual communication cost between them is depreciated.
2.2. Objective Function
In this work, we follow the approach of list scheduling algorithms. List scheduling algorithms are a family of heuristics in which tasks are ordered according to a particular priority criterion. The task execution order is equivalent to a DAG
topological order from the task graph, without violating the precedence constraints.
Table 2 shows an example of a feasible order for the task graph from
Figure 1.
Although the task order of execution is not indispensable for the scheduling, it simplifies the objective function computation [
1], i.e., because it is not necessary to compute different combinations of the tasks, starting and finish times, to compute the minimum makespan [
3,
15,
17]. However, this approach has the deficiency that the optimal value may not be possible in every task execution order. Algorithm 1 details the computation of the makespan objective function, using the computation times
from
Table 1 and a time counter (
) for each machine, to keep track of the last executed task in each machine.
| Algorithm 1 Makespan objective function |
| Input: , computational costs , and an order execution of the tasks . |
| Output: |
| 1: , |
| 2: for to do |
| 3: = |
| 4: the index of the machine assign to |
| 5: if then |
| 6: |
| 7: |
| 8: |
| 9: else |
| 10: |
| 11: |
| 12: + |
| 13: |
| 14: end if |
| 15: end for |
| 16: return |
Finally, the parallel program makespan (computation time) is the difference between the start and the ending of the first and last tasks. The makespan objective function uses the auxiliary variables (the starting time of task i), (the finish time of task i), and which is the communication cost that is zero if the tasks are executed in the same machine. The objective is to compute the tasks, from the first to the last of the feasible execution order. Finally, the parallel program makespan (computation time) is the difference between the start and end of the first and last tasks. The complexity of the Algorithm 1 is , although, in practice, it is remarkably lower than that, because not all the edges in G are connected to every node.
3. Algorithms Descriptions
This section introduces the generic metaheuristic frameworks (
Section 3.1 and
Section 3.2), as well as a high-performance algorithm in the state-of-the-art (
Section 3.3). Finally, our proposed algorithm is detailed in
Section 3.4.
3.1. Iterated Local Search (ILS)
The ILS is a multi-start metaheuristic search based on local improvements (
) and solution alterations (
) [
31], see Algorithm 2. This algorithm starts initializing the current solution
with a random solution, which is also assigned to the best solution
(see lines 3 and 4). The main loop of the algorithm iterates over the solution
applying a perturbation followed by a Local Search [
32], if the ILS detects a new best-known solution, then
is updated (see line 7). The above process continues until the stopping criterion is reached, usually a maximum Central Processing Unit (CPU) time or a fixed number of objective function evaluations.
| Algorithm 2 Iterated Local Search. |
| Input: Problem to solve |
| Output:
|
| 1: Random initial solution |
| 2: |
| 3: while Stopping criterion not reached do |
| 4: |
| 5: |
| 6: if then |
| 7: |
| 8: end if |
| 9: end while |
3.2. Greedy Randomized Adaptive Search Procedure (GRASP)
GRASP is a multi-start metaheuristic algorithm that builds a solution by selecting one promising fragment of the solution at a time [
33], see Algorithm 3. The inner loop of the GRASP, in line 5 builds a
by adding random individual elements from a Restricted Candidate List (
) (see line 11). In order to build the
, the algorithm evaluates the increase of the partial objective and stores its maximum and minimum values (see lines 7 and 8) to set a limit for the original candidate list (
) (see line 9), thus creating the
(see line 10); this process occurs at every step of the construction.
| Algorithm 3 Greedy Randomized Adaptive Search Procedure. |
| Input: Problem to solve |
| Output: |
| 1: Random initial solution |
| 2: while Stopping criterion not reached do |
| 3: | ▹ An empty initial solution |
| 4: |
| 5: while is not complete do |
| 6: |
| 7: |
| 8: |
| 9: |
| 10: |
| 11: | ▹ Add to a random element from the |
| 12: |
| 13: end while |
| 14: | ▹ The Local Search procedure is optional |
| 15: if then |
| 16: |
| 17: end if |
| 18:
end while |
The only includes candidate tasks whose incremental costs are bounded by in line 9. Where and are the maximum and minimum incremental cost of the objective function, for all the candidate elements , which is calculated with a modification of Algorithm 1 named that evaluates up to the last element in the partial solution. Additionally, defines the greedy level of the algorithm; where defines a completely greedy search, and defines a completely random search. Additionally, the candidate list () must be created or updated every iteration of the inner loop (see line 6). Once the is constructed, an optional procedure can be used to improve the current (see line 14). Furthermore, is updated every time a complete outperforms the objective value of (see line 16). Finally, the outer loop in line 2 restarts the and iterates until the algorithm reaches the stopping criterion.
3.3. State-of-the-Art (Earliest Finish Time) EFT-ILS
In [
11], the authors introduce an ILS, which will be called Earliest Finish Time (EFT)-ILS (in this paper), see Algorithm 4. EFT-ILS consists of two phases; the first explores random feasible execution orders of the tasks’ graph from lines 3 to 10. After each new ordering
, the algorithm assigns the machines to the tasks that produce their Earliest Finish Time (EFT) (see line 5 and Algorithm 5). For heavy computational instances, we suggest using an external stopping criterion as CPU time, see line 10. The second phase initializes an ILS described in
Section 3.1, using the best order
and solution
, found by the first phase, as initial solution. The next subsection details the Local Search and perturbation processes.
| Algorithm 4 Earliest Finish Time-Iterated Local Search. |
| Input:
, computational costs . |
| Output:
, |
| 1: Random initial solution |
| 2: |
| 3: for to do |
| 4: Random DAG G topological order |
| 5: |
| 6: if then |
| 7: |
| 8: |
| 9: end if |
| 10: end for | ▹ If the external stopping criterion is reach stop the for loop |
| 11: |
| Algorithm 5 Earliest Finish Time Function |
| Input:
An order execution of the tasks |
| Output:
An assignation of machines to tasks |
| 1: for to do |
| 2: Assign to the task the machine which produce their minimum finish time. |
| 3: end for |
3.3.1. EFT-ILS Local Search
The Local Search (LS) in EFT-ILS is based on the first improvement pivoting rule, see Algorithm 6. This algorithm evaluates the tasks in the execution order
O (see line 2). The algorithm generates neighbors
assigning machines
to the current task
, if a neighbor improves solution
s then
s is updated (see line 7), as consequence the search is reinitialized in line 8. Finally, the algorithm verifies an auxiliary external stopping criterion before continuing with the neighbor generation process to avoid exceeding the maximum CPU time or objective function evaluations.
| Algorithm 6 EFT-ILS Local Search procedure. |
| Input:
Solution to improve s, and an order execution of the tasks |
| Output:
s |
| 1: for to do |
| 2: | ▹ Assigns the task in the execution order as the current task |
| 3: for to do |
| 4: |
| 5: Assign in to the machine |
| 6: if then |
| 7: |
| 8: , |
| 9: end if |
| 10: end for | ▹ If the external stopping criterion is reach stop the Local Search |
| 11:
end for |
3.3.2. EFT-ILS Perturbation
EFT-ILS uses a perturbation process based on a probability. Every task
of the solution has a probability to be changed from its current machine. If the probability occurs the task
will be moved from its current machine and assigned to a new random one. For our experiment, we use a probability of 5% which is the best probability presented in [
11].
3.4. Proposed GRASP-Cellular Processing Algorithm (GRASP-CPA)
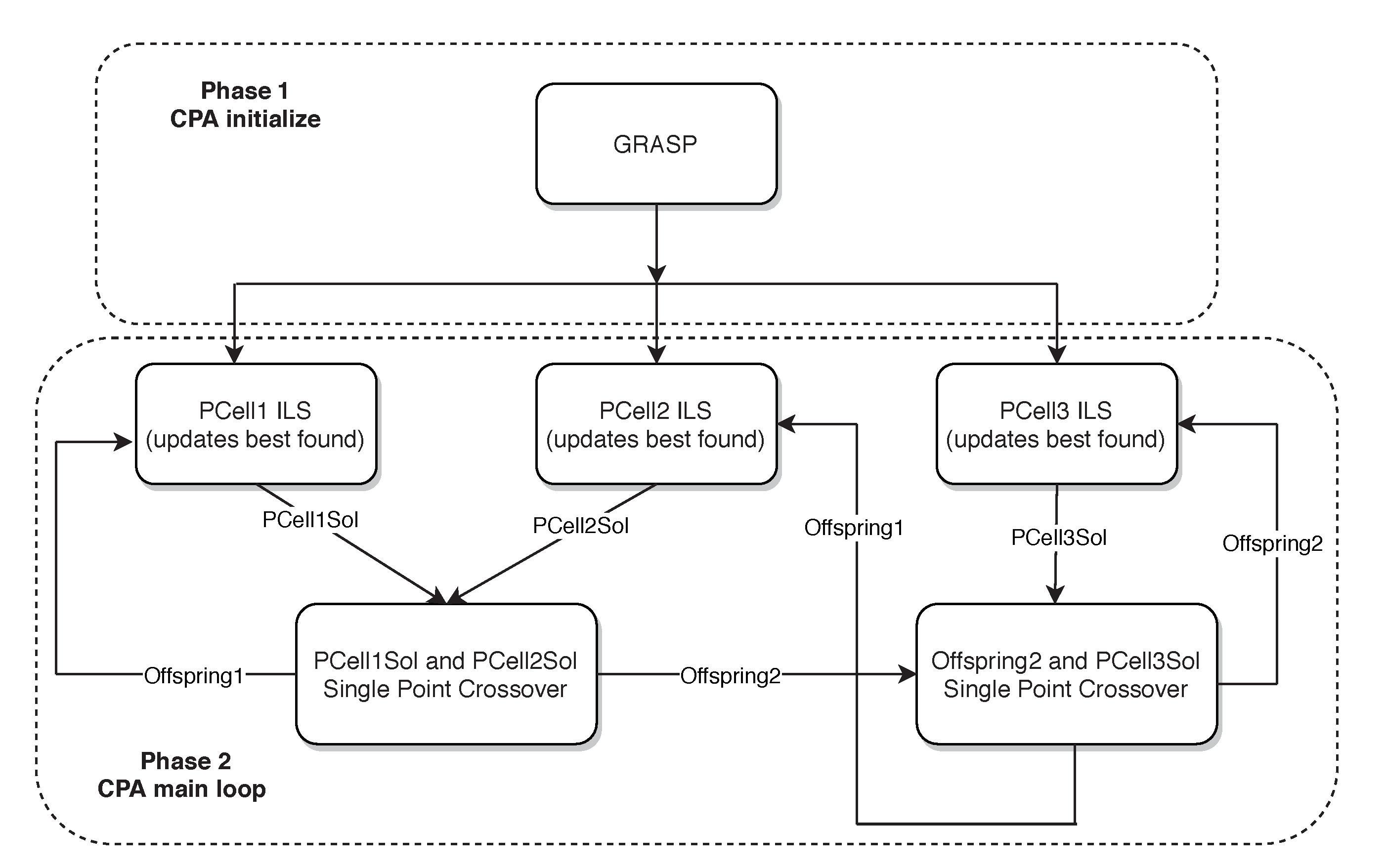
In a similar manner as in EFT-ILS, our proposed algorithm GRASP-CPA consists of two phases (see
Figure 2). First, a GRASP explores feasible tasks’ orders for the next phase of the algorithm. In the second phase, the algorithm uses the best order
and solution
found by GRASP, in a homogeneous Cellular Processing Algorithm (CPA). The algorithm is composed by three ILS Processing Cells (PCells), the PCells have two functions that are independent from their ILS procedure. The first is to update the global best solution
if the PCell finds a better solution. The second is to update their current solutions through the communication processes. The communication is performed using the well-known single point-crossover from Genetic Algorithms (GAs), where two solutions from different PCells split and combine their information [
12,
34]. This phase continues until a fixed number of iterations or CPU seconds is reached.
Algorithm 7 describes our GRASP-CPA proposal, where the
produces feasible orderings
that are evaluated using
to produce the solution
(see lines 5 and 6). Here, we can see that the algorithm uses a
that receives an
value that can be either 0.9 or 1 with the same probability. This
value is used to restrict the candidate list (see lines 9 and 10 from Algorithm 3). GRASP algorithms usually use
values between 0.1 and 0.3. However, preliminary experimentation proved that the our proposed
values where the ones with the best performance for the instances used. Finally, line 12 executes the cellular processing section of the algorithm.
| Algorithm 7 GRASP-CPA |
| Input:
, computational costs . |
| Output:
, |
| 1: Random initial solution |
| 2: |
| 3: for to do |
| 4: |
| 5: |
| 6: . |
| 7: if then |
| 8: |
| 9: |
| 10: end if |
| 11: end for | ▹ If the external stopping criterion is reach stop the for loop |
| 12: . |
| Algorithm 8 Cellular Processing Algorithm section of the algorithm (GRASP-CPA) |
| Input:
, |
| Output:
|
| 1:
|
| 2:
|
| 3:
|
| 4: while stopping criterion not reached do |
| 5: |
| 6: |
| 7: |
| 8: |
| 9:
end while |
Algorithm 8 shows the general idea of the function. Here, the execution of the ILS Processing Cells (see lines 5 and 7) iterate five times each one, which limits the inner computational effort of the Processing Cells. After the Processing Cells’ execution, the processes the current solutions, recombining the of PCell1 with the of PCell2, the first offspring becomes the new current solution in PCell1. At the same time, the second offspring is used for a second recombination with the of PCell3. The resulting offsprings from the second recombination become the new current solution of PCell2 and PCell3. This process continues until the stopping criterion is reached (see line 4).
5. Results
First, we start analyzing the results of the large benchmark set of 400 scheduling problems. Focusing on the Fpppp instance set (see
Table 4), GRASP-CPA outperformed with statistical significance EFT-ILS in 53 instances, not statistically outperforming in any instance with 8 and 16 machines. However, for the instances with 32 and 64 machines, EFT-ILS outperformed GRASP-CPA in 3 and 11 instances, respectively.
Regarding the LIGO benchmark results from
Table 5, GRASP-CPA outperformed EFT-ILS in 45 instances. EFT-ILS only outperformed GRASP-CPA in 13 instances, distributed as follows: two, three, five, and three for the instances with 8, 16, 32, and 64 machines, respectively.
For the Robot benchmark (see
Table 6), GRASP-CPA outperformed EFT-ILS with statistical significance in 48 cases, while EFT-ILS only outperformed GRASP-CPA in 12 instances, where most of them occurred for the instances with 16 machines.
The results for the Sparse benchmark from
Table 7 show that GRASP-CPA outperformed EFT-ILS with statistical significance in 33 instances, while EFT-ILS outperformed GRASP-CPA in 10 instances.
Finally, for these instances sets, GRASP-CPA achieved 265% more best median values found than EFT-ILS, with statistical significance. Therefore, we consider that GRASP-CPA is superior to EFT-ILS in a relevant proportion of the studied cases.
Furthermore, we analyze the results from the small benchmark of 14 synthetic instances in
Table 8. For the 14 synthetic problems, GRASP-CPA achieves the best median value in all the cases, with statistical significance in ten cases. In addition,
Table 8 shows the average computing time of the enumerative optimal algorithm (Time
), EFT-ILS (Time
), and GRASP-CPA (Time
) in CPU seconds on a Macbook pro 13-inch late 2011.
Table 9 presents the best solution found by EFT-ILS and GRASP-CPA, where EFT-ILS computes twelve optimal values, while GRASP-CPA computes 13. Additionally, GRASP-CPA achieves an IQR of
in six cases where the algorithm reached the optimal value in the median.

 ,
, 



{kind=link}
{kind=link}