Audio–Visual Speech Recognition Based on Dual Cross-Modality Attentions with the Transformer Model



Abstract
1. Introduction
2. Related Work
2.1. AVSR
2.2. Attention Mechanism
2.3. Modality Fusion with Attention Mechanism
2.4. Speech Recognition with a Hybrid CTC/Attention Architecture
3. Proposed AVSR Method Based on DCM Attention
3.1. Input Features
3.1.1. Audio Features
3.1.2. Video Features
3.2. Seq2seq Transformer
3.2.1. Positional Encoding
3.2.2. Self-Attention Encoder
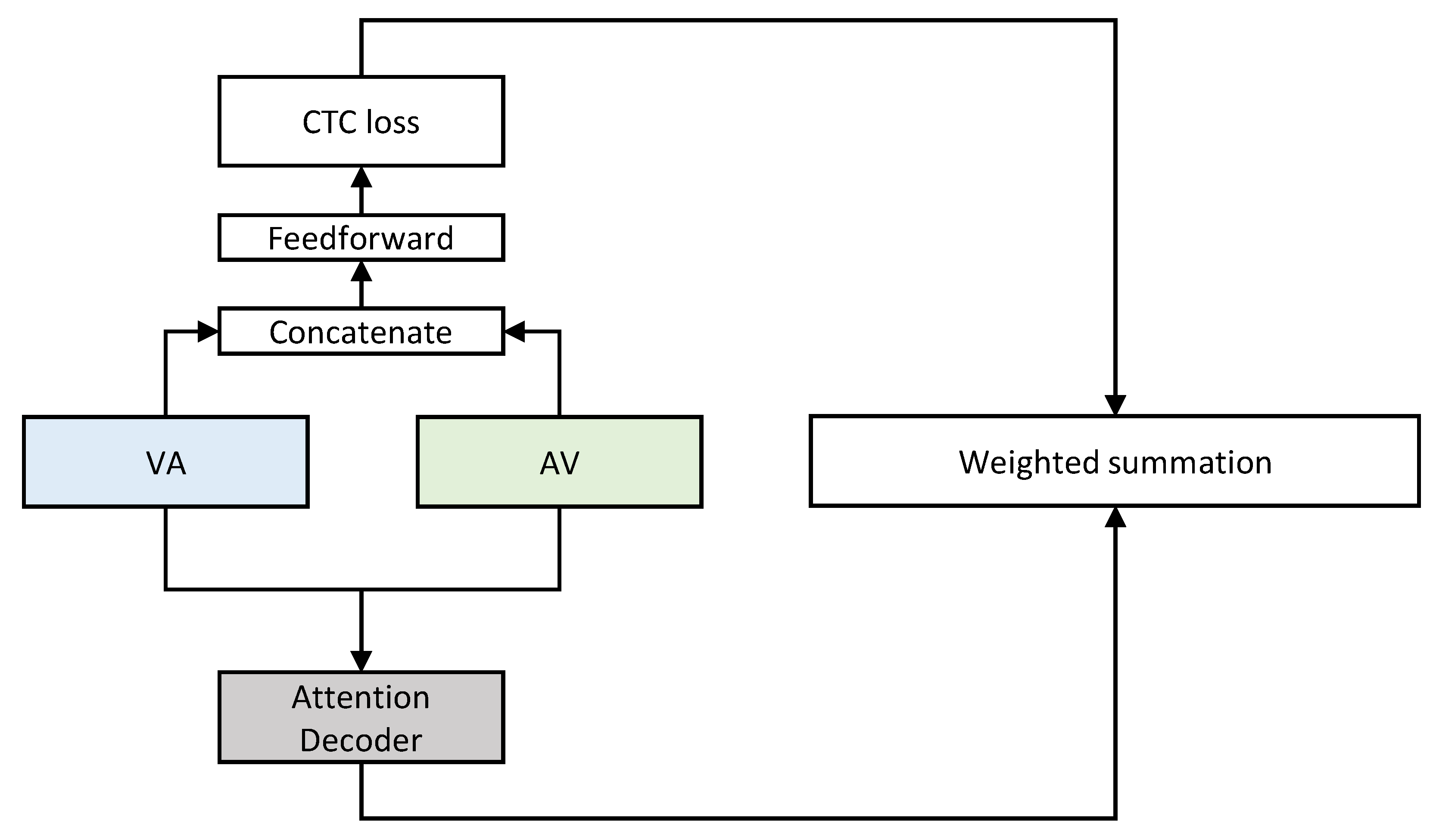
3.2.3. DCM Attention
3.2.4. Bi-Modal Self-Attention Decoder
3.3. Training and Decoding with a Hybrid CTC/Attention Architecture
| Algorithm 1: Hybrid CTC/attention training |
 |
4. Experimental Results and Discussions
4.1. Datasets
4.2. Evaluation Measure
4.3. Training Strategies
- Clean short sentences with three or four words in the pre-train set.
- Clean sentences in the pre-train and train-val sets.
- Clean and noisy reverberant sentences (as described in Section 4.1) in the train-val set.
- Clean and noisy reverberant sentences in the train-val set of either LRS2-BBC or LRS3-TED dataset for fine tuning on either dataset.
4.4. Attention Visualization
4.5. WER Results
4.6. Decoding Examples
4.7. Decoding on Sentences of Various Lengths
4.8. Decoding on Out-of-Sync Data
4.9. Comparison with Simple Concatenation of Audio and Video Encoder Outputs
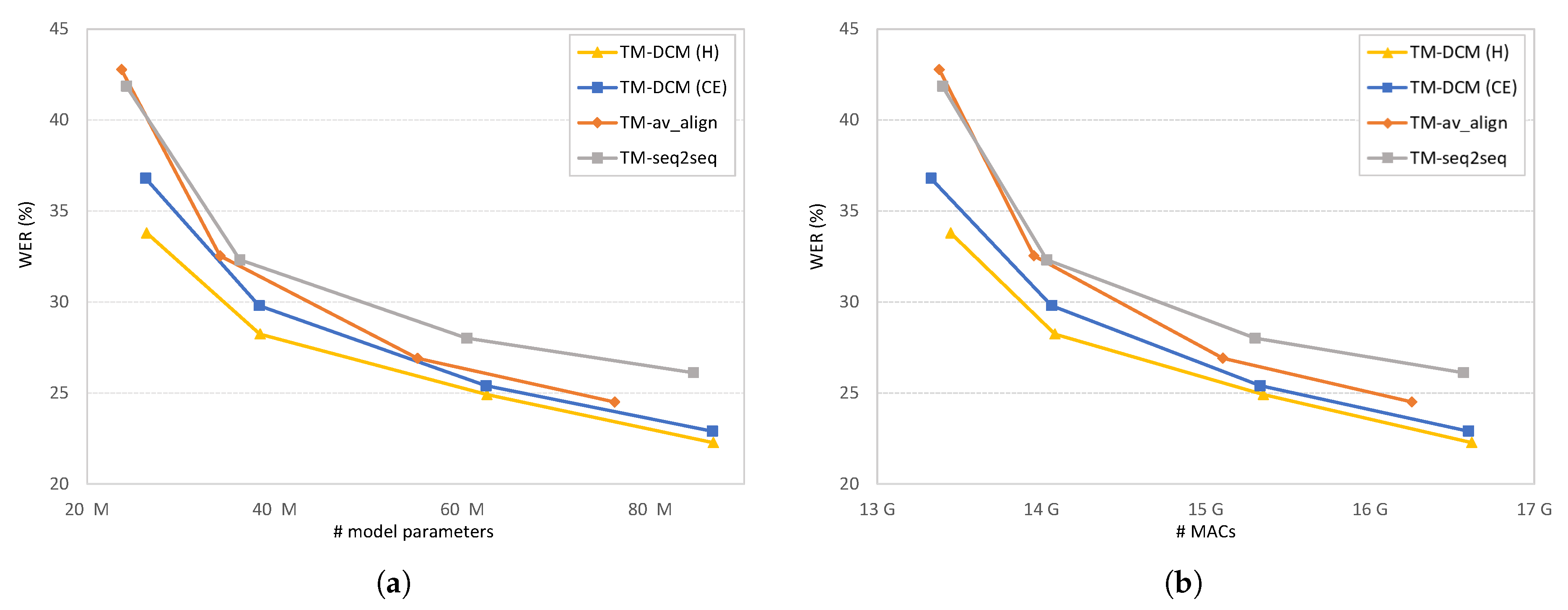
4.10. Model Parameter Sensitiveness and Run-Time Complexity
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
Abbreviations
| LSTM | long short-term memory |
| seq2seq | sequence-to-sequence |
| AVSR | audio–visual speech recognition |
| DCM | dual cross-modality |
| CTC | connectionist-temporal-classification |
| ASR | automatic speech recognition |
| SNR | signal-to-noise ratio |
| CNN | convolutional neural network |
| AV align | cross-modality attention that computes the video context using audio query |
| VA align | cross-modality attention that computes the audio context using video query |
| DNN | deep neural network |
| DCT | discrete-cosine-transform |
| MFCC | mel-frequency cepstral coefficient |
| MLP | multi-layer perceptron |
| sos | start of a sentence |
| eos | end of a sentence |
| reverberation time | |
| WER | word error rate |
| TM | transformer model |
References
- Virtanen, T.; Singh, R.; Raj, B. (Eds.) Techniques for Noise Robustness in Automatic Speech Recognition; John Wiley & Sons, Ltd.: Hoboken, NJ, USA, 2012. [Google Scholar]
- Wölfel, M.; McDonough, J. Distant Speech Recognition; John Wiley & Sons, Ltd.: Hoboken, NJ, USA, 2009. [Google Scholar]
- Droppo, J.; Acero, A. Environmental Robustness. In Handbook of Speech Processing; Springer: Berlin, Germany, 2008. [Google Scholar]
- Raj, B.; Parikh, V.; Stern, R.M. The effects of background music on speech recognition accuracy. In Proceedings of the IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP), Munich, Germany, 21–24 April 1997; Volume 2, pp. 851–854. [Google Scholar]
- Cho, J.W.; Park, J.H.; Chang, J.H.; Park, H.M. Bayesian feature enhancement using independent vector analysis and reverberation parameter re-estimation for noisy reverberant speech recognition. Comput. Speech Lang. 2017, 46, 496–516. [Google Scholar] [CrossRef]
- Zhou, Z.; Zhao, G.; Hong, X.; Pietikäinen, M. A review of recent advances in visual speech decoding. Image Vis. Comput. 2014, 32, 590–605. [Google Scholar] [CrossRef]
- Chung, J.S.; Senior, A.; Vinyals, O.; Zisserman, A. Lip reading sentences in the wild. In Proceedings of the IEEE Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 3444–3453. [Google Scholar]
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the IEEE Computer Vision and Pattern Recognition (CVPR), San Diego, CA, USA, 20–26 June 2005; Volume 1, pp. 886–893. [Google Scholar]
- Ahonen, T.; Hadid, A.; Pietikainen, M. Face description with local binary patterns: Application to face recognition. IEEE Trans. Pattern Anal. Mach. Intell. (TPAMI) 2006, 28, 2037–2041. [Google Scholar] [CrossRef] [PubMed]
- Lowe, D.G. Distinctive image features from scale-invariant keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Jang, D.W.; Kim, H.I.; Je, C.; Park, R.H.; Park, H.M. Lip Reading Using Committee Networks With Two Different Types of Concatenated Frame Images. IEEE Access 2019, 7, 90125–90131. [Google Scholar] [CrossRef]
- Noda, K.; Yamaguchi, Y.; Nakadai, K.; Okuno, H.G.; Ogata, T. Audio-visual speech recognition using deep learning. Appl. Intell. 2015, 42, 722–737. [Google Scholar] [CrossRef]
- Sterpu, G.; Saam, C.; Harte, N. Attention-based audio-visual fusion for robust automatic speech recognition. In Proceedings of the International Conference on Multimodal Interaction, Boulder, CO, USA, 16–20 October 2018; Volume 5, pp. 111–115. [Google Scholar]
- Petridis, S.; Stafylakis, T.; Ma, P.; Cai, F.; Tzimiropoulos, G.; Pantic, M. End-to-end audiovisual speech recognition. In Proceedings of the IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018; pp. 6548–6552. [Google Scholar]
- Shillingford, B.; Assael, Y.; Hoffman, M.W.; Paine, T.; Hughes, C.; Prabhu, U.; Liao, H.; Sak, H.; Rao, K.; Bennett, L.; et al. Large-Scale Visual Speech Recognition. In Interspeech; 2019; pp. 4135–4139. Available online: https://arxiv.org/pdf/1807.05162.pdf (accessed on 20 September 2020).
- Zhou, P.; Yang, W.; Chen, W.; Wang, Y.; Jia, J. Modality attention for end-to-end audio-visual speech recognition. In Proceedings of the IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; pp. 6565–6569. [Google Scholar]
- Bahdanau, D.; Cho, K.; Bengio, Y. Neural Machine Translation by Jointly Learning to Align and Translate. In Proceedings of the International Conference on Learning Representations (ICLR), San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Zeyer, A.; Bahar, P.; Irie, K.; Schlüter, R.; Ney, H. A comparison of transformer and LSTM encoder decoder models for ASR. In Proceedings of the IEEE Automatic Speech Recognition and Understanding (ASRU) Workshop, Sentosa, Singapore, 14–18 December 2019; pp. 8–15. [Google Scholar]
- Petridis, S.; Stafylakis, T.; Ma, P.; Tzimiropoulos, G.; Pantic, M. Audio-visual speech recognition with a hybrid CTC/attention architecture. In Proceedings of the IEEE Spoken Language Technology Workshop (SLT), Athens, Greece, 18–21 December 2018; pp. 513–520. [Google Scholar]
- Afouras, T.; Chung, J.S.; Senior, A.; Vinyals, O.; Zisserman, A. Deep audio-visual speech recognition. IEEE Trans. Pattern Anal. Mach. Intell. (TPAMI) 2018. [Google Scholar] [CrossRef] [PubMed]
- Mroueh, Y.; Marcheret, E.; Goel, V. Deep multimodal learning for Audio-Visual Speech Recognition. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), South Brisbane, Australia, 19–24 April 2015; pp. 2130–2134. [Google Scholar]
- Tamura, S.; Ninomiya, H.; Kitaoka, N.; Osuga, S.; Iribe, Y.; Takeda, K.; Hayamizu, S. Audio-visual speech recognition using deep bottleneck features and high-performance lipreading. In Proceedings of the Asia-Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA), Hong Kong, China, 16–19 December 2015; pp. 575–582. [Google Scholar]
- Galatas, G.; Potamianos, G.; Makedon, F. Audio-visual speech recognition incorporating facial depth information captured by the Kinect. In Proceedings of the 20th European Signal Processing Conference (EUSIPCO), Bucharest, Romania, 27–31 August 2012; pp. 2714–2717. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the Advances in Neural Information Processing Systems (NeurIPS), Long Beach, CA, USA, 4–9 December 2017; pp. 5998–6008. [Google Scholar]
- Wang, Y.; Mohamed, A.; Le, D.; Liu, C.; Xiao, A.; Mahadeokar, J.; Huang, H.; Tjandra, A.; Zhang, X.; Zhang, F.; et al. Transformer-based acoustic modeling for hybrid speech recognition. arXiv 2019, arXiv:1910.09799. [Google Scholar]
- Yeh, C.F.; Mahadeokar, J.; Kalgaonkar, K.; Wang, Y.; Le, D.; Jain, M.; Schubert, K.; Fuegen, C.; Seltzer, M.L. Transformer-Transducer: End-to-End Speech Recognition with Self-Attention. arXiv 2019, arXiv:1910.12977. [Google Scholar]
- Paraskevopoulos, G.; Parthasarathy, S.; Khare, A.; Sundaram, S. Multimodal and Multiresolution Speech Recognition with Transformers. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Seattle, DC, USA, 6–8 July 2020; pp. 2381–2387. [Google Scholar]
- Sterpu, G.; Saam, C.; Harte, N. Should we hard-code the recurrence concept or learn it instead? Exploring the Transformer architecture for Audio-Visual Speech Recognition. arXiv 2020, arXiv:2005.09297. [Google Scholar]
- Boes, W.; Van hamme, H. Audiovisual Transformer Architectures for Large-Scale Classification and Synchronization of Weakly Labeled Audio Events. In Proceedings of the 27th ACM International Conference on Multimedia, Nice, France, 21–25 October 2019; pp. 1961–1969. [Google Scholar]
- Li, Z.; Li, Z.; Zhang, J.; Feng, Y.; Niu, C.; Zhou, J. Bridging Text and Video: A Universal Multimodal Transformer for Video-Audio Scene-Aware Dialog. arXiv 2020, arXiv:2002.00163. [Google Scholar]
- Le, H.; Sahoo, D.; Chen, N.; Hoi, S. Multimodal Transformer Networks for End-to-End Video-Grounded Dialogue Systems. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019; Volume 2, pp. 5612–5623. [Google Scholar]
- Tsai, Y.H.H.; Bai, S.; Liang, P.P.; Kolter, J.Z.; Morency, L.P.; Salakhutdinov, R. Multimodal Transformer for Unaligned Multimodal Language Sequences. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019; Volume 2019, pp. 6558–6569. [Google Scholar]
- Chan, W.; Jaitly, N.; Le, Q.; Vinyals, O. Listen, attend and spell: A neural network for large vocabulary conversational speech recognition. In Proceedings of the IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP), Shanghai, China, 20–25 March 2016; pp. 4960–4964. [Google Scholar]
- Luong, M.T.; Pham, H.; Manning, C.D. Effective Approaches to Attention-based Neural Machine Translation. In Proceedings of the Conference on Empirical Methods in Natural Language Processing (EMNLP), Lisbon, Portugal, 17–21 September 2015; pp. 1412–1421. [Google Scholar]
- Watanabe, S.; Hori, T.; Kim, S.; Hershey, J.R.; Hayashi, T. Hybrid CTC/attention architecture for end-to-end speech recognition. IEEE J. Sel. Top. Signal Process. 2017, 11, 1240–1253. [Google Scholar] [CrossRef]
- Xu, K.; Li, D.; Cassimatis, N.; Wang, X. LCANet: End-to-end lipreading with cascaded attention-CTC. In Proceedings of the 13th IEEE International Conference on Automatic Face & Gesture Recognition (FG 2018), Xi’an, China, 15–19 May 2018; pp. 548–555. [Google Scholar]
- Mohamed, A.; Okhonko, D.; Zettlemoyer, L. Transformers with convolutional context for ASR. arXiv 2019, arXiv:1904.11660. [Google Scholar]
- Chung, J.S.; Zisserman, A. Out of time: Automated lip sync in the wild. In Asian Conference on Computer Vision (ACCV); Springer: Berlin, Germany, 2016; pp. 251–263. [Google Scholar]
- Chatfield, K.; Simonyan, K.; Vedaldi, A.; Zisserman, A. Return of the devil in the details: Delving deep into convolutional nets. In Proceedings of the British Machine Vision Conference (BMVC), Nottingham, UK, 1–5 September 2014. [Google Scholar]
- Chung, J.S.; Zisserman, A. Lip Reading in Profile. In Proceedings of the British Machine Vision Conference (BMVC), London, UK, 4–7 September 2017. [Google Scholar]
- Allen, J.B.; Berkley, D.A. Image method for efficiently simulating small-room acoustics. J. Acoust. Soc. Am. 1979, 65, 943–950. [Google Scholar] [CrossRef]
- Paszke, A.; Gross, S.; Chintala, S.; Chanan, G.; Yang, E.; DeVito, Z.; Lin, Z.; Desmaison, A.; Antiga, L.; Lerer, A. Automatic differentiation in PyTorch. In Proceedings of the Neural Information Processing Systems (NeurIPS) Workshop, Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Ott, M.; Edunov, S.; Baevski, A.; Fan, A.; Gross, S.; Ng, N.; Grangier, D.; Auli, M. fairseq: A Fast, Extensible Toolkit for Sequence Modeling. In Proceedings of the Conference of the North American Chapter of the Association for Computational Linguistics (Demonstrations), Minneapolis, MN, USA, 2–7 June 2019; pp. 48–53. [Google Scholar]
- Zeiler, M.D. ADADELTA: An Adaptive Learning Rate Method. arXiv 2012, arXiv:1212.5701. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Modality | Objective | #Params | Dataset | Clean | Noisy Reverberant | Avg. | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| LRS2-BBC | LRS3-TED | SNR (dB) | |||||||||||
| 20 | 15 | 10 | 5 | 0 | |||||||||
| TM-seq2seq | V | CE | 54.2 M | ✓ | 59.7 | ||||||||
| ✓ | 67.3 | ||||||||||||
| TM-seq2seq | A | CE | 47.3 M | ✓ | 9.8 | 21.7 | 23.3 | 25.7 | 33.7 | 47.6 | 68.9 | 33.0 | |
| ✓ | 10.1 | 21.4 | 23.5 | 26.1 | 33.8 | 48.1 | 69.6 | 33.2 | |||||
| TM-seq2seq | AV | CE | 84.6 M | ✓ | 10.5 | 19.7 | 19.8 | 23.0 | 25.1 | 34.0 | 43.7 | 25.1 | |
| ✓ | 10.8 | 20.0 | 20.2 | 23.5 | 27.6 | 36.4 | 51.3 | 27.1 | |||||
| TM-av_align | AV | CE | 76.2 M | ✓ | 11.5 | 18.8 | 19.3 | 22.6 | 25.0 | 31.2 | 43.4 | 22.6 | |
| ✓ | 11.7 | 18.1 | 18.9 | 21.8 | 25.8 | 34.1 | 47.1 | 25.4 | |||||
| TM-DCM | AV | CE | 86.7 M | ✓ | 8.7 | 17.3 | 17.5 | 19.2 | 22.0 | 29.2 | 41.2 | 22.2 | |
| ✓ | 9.0 | 17.8 | 18.0 | 19.8 | 22.9 | 31.5 | 45.8 | 23.5 | |||||
| TM-DCM | AV | H | 86.7 M | ✓ | 8.6 | 16.8 | 16.9 | 18.8 | 22.0 | 28.9 | 40.7 | 21.8 | |
| ✓ | 8.8 | 17.1 | 17.3 | 19.2 | 22.2 | 30.9 | 43.6 | 22.7 | |||||
| Model | TM-seq2seq | TM-av_align | TM-DCM |
|---|---|---|---|
| Modality attention | None | Audio–Video | Audio–Video and Video–Audio |
| (Query-Key/Value) |
| Models | Modality | Objective | Transcription |
|---|---|---|---|
| Ground truth | and it’s even rarer to find one that hasn’t been dug into by antiquarans | ||
| TM-seq2seq | V | CE | and it’s even rarer to find one that hasn’t bin diagnosed by asking quarries |
| TM-seq2seq | A | CE | and it’s equal rare two find one that hasn’t been dug into by anti crayons |
| TM-seq2seq | AV | CE | and it’s even rarer to find one that hasn’t been dug into by antique areas |
| TM-av_align | AV | CE | and it’s even rarer to find one that hasn’t been dug into by antiquarists |
| TM-DCM | AV | CE | and it’s even rarer to find one that hasn’t been dug into by antiquate risks |
| TM-DCM | AV | H | and it’s even rarer to find one that hasn’t been dug into by antiquarans |
| Ground truth | home to an animal that is right at the top of the food chain | ||
| TM-seq2seq | V | CE | home to an animal has raised in some of the future in |
| TM-seq2seq | A | CE | home to an animal bad is rights into top off a food chain |
| TM-seq2seq | AV | CE | home to an animal that is right at the top over food chain |
| TM-av_align | AV | CE | home to an animal that is right at the top of a food chain |
| TM-DCM | AV | CE | home to an animal that is right at the top of the food chain |
| TM-DCM | AV | H | home to an animal that is right at the top of the food chain |
| Ground truth | and would eventually marry her after his wife | ||
| TM-seq2seq | V | CE | and would eventually the most american hundreds of |
| TM-seq2seq | A | CE | and would eventually marry him got the his wife |
| TM-seq2seq | AV | CE | and would emit actually marry her after his wife |
| TM-av_align | AV | CE | and would emitting her after his wife |
| TM-DCM | AV | CE | and would eventually marry her after his wife |
| TM-DCM | AV | H | and would eventually marry her after his wife |
| Fusion Method | Concatenation | TM-DCM | |||
|---|---|---|---|---|---|
| Objective | CE | CE | H | ||
| Clean | 9.6 | 8.8 | 8.7 | ||
| Noisy reverberant | SNR (dB) | 20 | 18.2 | 17.5 | 16.9 |
| 15 | 18.9 | 17.7 | 17.0 | ||
| 10 | 21.2 | 19.4 | 18.9 | ||
| 5 | 25.2 | 22.3 | 22.1 | ||
| 0 | 33.5 | 30.0 | 29.5 | ||
| 47.3 | 42.7 | 41.7 | |||
| Avg. | 24.8 | 22.6 | 22.1 | ||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lee, Y.-H.; Jang, D.-W.; Kim, J.-B.; Park, R.-H.; Park, H.-M. Audio–Visual Speech Recognition Based on Dual Cross-Modality Attentions with the Transformer Model. Appl. Sci. 2020, 10, 7263. https://doi.org/10.3390/app10207263
Lee Y-H, Jang D-W, Kim J-B, Park R-H, Park H-M. Audio–Visual Speech Recognition Based on Dual Cross-Modality Attentions with the Transformer Model. Applied Sciences. 2020; 10(20):7263. https://doi.org/10.3390/app10207263
Chicago/Turabian StyleLee, Yong-Hyeok, Dong-Won Jang, Jae-Bin Kim, Rae-Hong Park, and Hyung-Min Park. 2020. "Audio–Visual Speech Recognition Based on Dual Cross-Modality Attentions with the Transformer Model" Applied Sciences 10, no. 20: 7263. https://doi.org/10.3390/app10207263
APA StyleLee, Y.-H., Jang, D.-W., Kim, J.-B., Park, R.-H., & Park, H.-M. (2020). Audio–Visual Speech Recognition Based on Dual Cross-Modality Attentions with the Transformer Model. Applied Sciences, 10(20), 7263. https://doi.org/10.3390/app10207263